
Käpyyn perustuva tutkimus siitä, miten paljon liikennettä saavat verkkosivustot julkaisevat koneelle luettavaa ohjeistusta suurille kielimalleille, miltä varhaiset toteutukset näyttävät ja miksi käyttöönoton mittaaminen vaatii enemmän kuin HTTP 200 -vastausten laskemista.
- Aineisto:
data/llms_probe_results_top_10000.csv - Tranco-lista ladattu: 6. toukokuuta 2026
- Rajaus: juuritason
/llms.txtja/llms-full.txt
Keskeiset mittarit
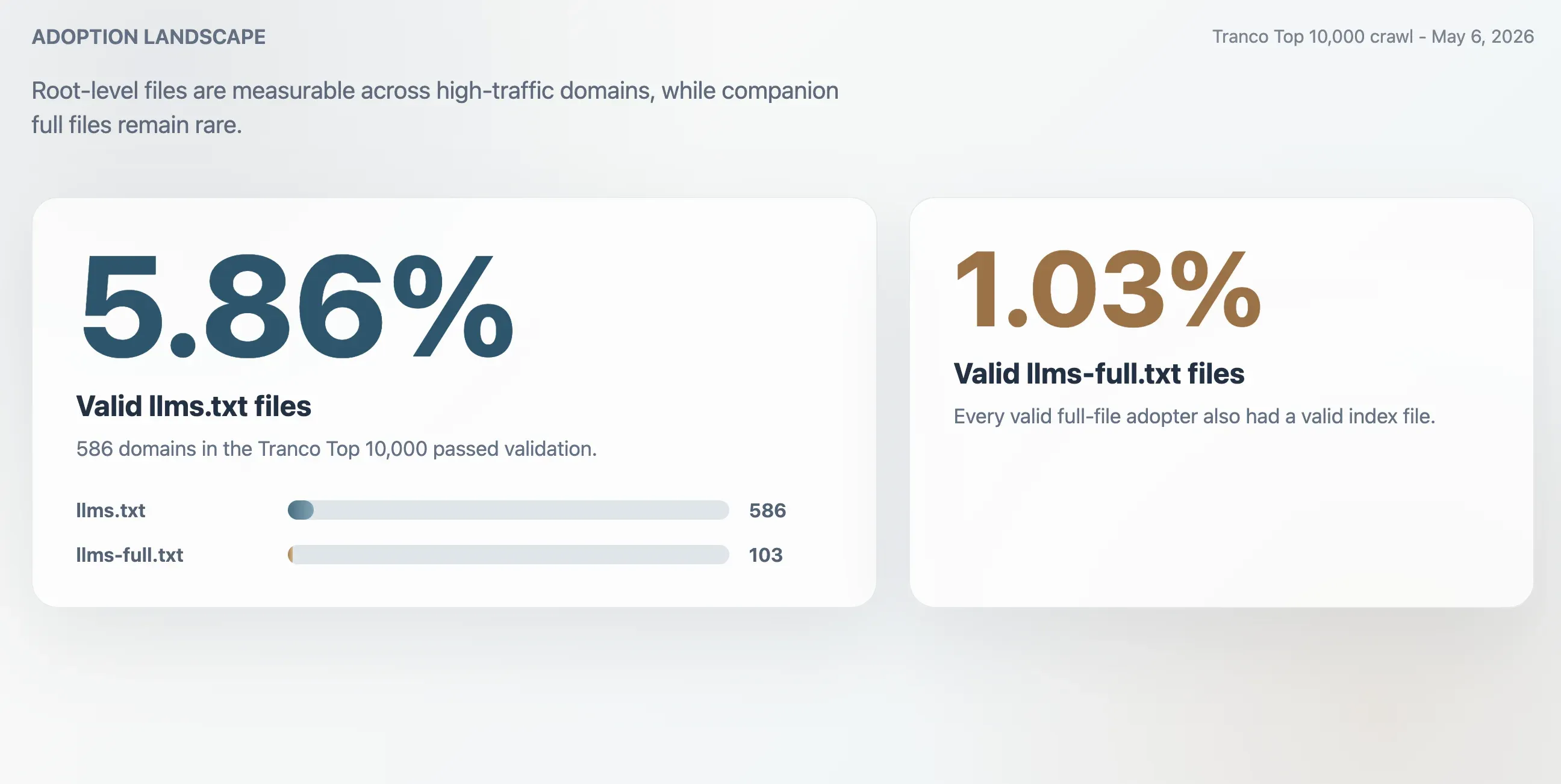
- 5,86 %: Kelvollinen
llms.txt-käyttöönotto Tranco Top 10 000 -listalla, yhteensä 586 verkkotunnusta. - 1,03 %: Kelvollinen
llms-full.txt-käyttöönotto, yhteensä 103 verkkotunnusta. Jokaisella kelvollisella täyden tiedoston käyttäjällä oli myös kelvollinen hakemistotiedosto. - 63,51 %: Osuus
/llms.txt-polun HTTP 200 -vastauksista, jotka epäonnistuivat validoinnissa. - 2,74x: Arvioitu yliarvio, jos käyttöönottoa mitataan pelkkien HTTP 200 -vastausten perusteella.
Tiivistelmä
llms.txt on yhä varhainen verkkokäytäntö, mutta se ei ole enää pelkkä marginaalinen kokeilu. 6. toukokuuta 2026 tehdyssä Tranco Top 10 000 -verkkotunnusten crawlissa löytyi 586 kelvollista llms.txt-tiedostoa, mikä tarkoittaa 5,86 prosentin havaittua käyttöönottoa. Kumppanina toimiva llms-full.txt-tiedosto oli paljon harvinaisempi: 103 verkkotunnuksella oli kelvollinen täysi tiedosto, eli käyttöönottoaste oli 1,03 %.
Tärkein metodologinen havainto on, että tilakoodit ovat huono proxy käyttöönotolle. Crawl löysi 1 606 HTTP 200 -vastausta polusta /llms.txt, mutta vain 586 läpäisi validoinnin. Loput 1 020 olivat enimmäkseen väärään kohteeseen ohjautuvia uudelleenohjauksia, yleisiä HTML-sivuja, tyhjiä vastauksia tai muita virheellisiä vastauksia. Naiivi tarkastelija, joka laskee jokaisen 200-vastauksen käyttöönotoksi, yliarvioisi kelvollisen käyttöönoton noin 2,74-kertaisesti.
Kelvollisten käyttäjien joukossa toteutusten laatu on parempi kuin pelkkä paikkamerkki-ajatus antaisi ymmärtää. Kelvollisen tiedoston mediaanikoko oli noin 7,1 kt, 61,77 % kelvollisista tiedostoista oli yli 5 kt, 70,82 % sisälsi vähintään kuusi Markdown-osiota ja 77,47 % sisälsi vähintään 11 Markdown-linkkiä. Varhaisten käyttäjien joukossa ovat Cloudflare, Azure, GitHub, DigiCert, WordPress.org, Adobe, Dropbox, PayPal, Stripe, Salesforce, Slack, Zendesk, Okta, Datadog ja Cloudinary.
llms.txtkannattaa ymmärtää AI-järjestelmille suunnattuna selittävänä ja navigointia helpottavana signaalina, eirobots.txt:n korvaajana. Sen arvo ei ole vain siinä, että tiedosto on olemassa, vaan siinä, auttaako se koneita löytämään auktoritatiivista, tiivistä ja ajantasaista tietoa.
Tausta: verkko lisää AI:lle suunnattuja signaaleja
Verkkosivustot ovat pitkään käyttäneet robots.txt-tiedostoa crawlereiden toiveiden ilmaisemiseen, sitemap.xml:ää URL-löydettävyyden parantamiseen ja jäsenneltyä dataa sivujen tulkinnan helpottamiseen haku- ja alustajärjestelmille. Generatiivinen AI tuo ongelmaan uuden ulottuvuuden. Sisältöä voidaan käyttää opetukseen, haun tukemiseen, tiivistämiseen, agenttiselaamiseen, koodiavustukseen, asiakastukeen ja vastausten tuottamiseen. Tämä luo kaksi samanaikaista tarvetta: julkaisijat haluavat enemmän hallintaa automaattisesta käytöstä, mutta samalla heidän on helpotettava AI-järjestelmien pääsyä oikeaan, kanoniseen tietoon silloin kun nämä järjestelmät vierailevat sivustoilla.
Alkuperäinen llms.txt-ehdotus, jonka Jeremy Howard esitti vuonna 2024, kuvaa tiedoston Markdown-dokumentiksi, joka sijoitetaan verkkosivuston juureen ja joka tarjoaa LLM-ystävällistä tietoa päättelyvaiheessa. Ehdotuksen mukaan HTML-sivut sisältävät usein navigaatiota, mainoksia, skriptejä ja muuta kohinaa, joka vaikeuttaa kielimallien käsittelyä. Tiivis Markdown-tiedosto voi ohjata mallit tärkeimmille sivuille, dokumentaatioon, API:en, esimerkkeihin, käytäntöihin ja tuotetietoihin.
Ulkopuolinen verkkotutkimus tarjoaa laajemman taustan. Data Provenance Initiativen “Consent in Crisis” kuvaa AI:hin liittyvien rajoitusten nopeaa lisääntymistä robots.txt:ssä ja käyttöehdoissa sekä argumentoi, että nykyiset verkkosuostumusmekanismit eivät ole suunniteltuja suuren mittakaavan AI-datan uudelleenkäyttöön. Cloudflare Radar AI Insights on myös tehnyt AI-crawlerin ja robots.txt:n mallit näkyviksi Top 10 000 -tasolla. Tässä ympäristössä llms.txt sijoittuu AI-signaaloinnin rakentavalle puolelle: ei “älä käy täällä”, vaan “jos sinun täytyy ymmärtää tämä sivusto, aloita tästä”.
Ulkoinen näyttö ja käyttöönottoa koskeva keskustelu
Julkinen keskustelu llms.txt:stä jakautuu kahteen väitteeseen. Optimistisen näkemyksen mukaan tiedosto antaa AI-järjestelmille siistimmän ja tehokkaamman reitin auktoritatiiviseen sisältöön. Skeptisen näkemyksen mukaan yksikään suuri LLM-toimittaja ei ole julkisesti sitoutunut käyttämään sitä ranking-, crawl- tai viitesignaalina, joten julkaisijoiden ei pitäisi odottaa tiedoston yksinään tuovan liikennettä. Tämän päivityksen kolme ulkoista lähdettä tukevat vivahteikkaampaa johtopäätöstä: llms.txt on hyödyllistä infrastruktuuria, mutta todisteet suorasta liikennevaikutuksesta ovat yhä rajalliset ja kontekstisidonnaiset.
Ulkoiset käyttöönoton vertailupisteet muuttuvat nopeasti
Rankabilityn käyttöönotonseuranta raportoi 0,3 prosentin käyttöönottoasteen Top 1 000 -verkkosivustolla 22. kesäkuuta 2025, eli 3 sivustoa 1 000:sta. Se kuvaa kuukausittaista automaattista domain.com/llms.txt-skannausta, jossa validointi sulkee pois uudelleenohjaukset ja HTML-vastaukset. Menetelmä on suunnaltaan samanlainen kuin tämän tutkimuksen varovainen validointitapa.
Tulosten ero on suuri: tämä tutkimus löysi 75 kelvollista llms.txt-tiedostoa Tranco Top 1 000 -listalla 6. toukokuuta 2026, eli 7,50 %. Näitä kahta lukua ei pidä tulkita tiukaksi aikasarjaksi, koska ranking-lähde, toteutuksen yksityiskohdat, validointilogiikka ja crawlauksen ajoitus voivat poiketa toisistaan. Silti kontrasti viittaa siihen, että käyttöönotto muuttui olennaisesti kesän 2025 ja toukokuun 2026 välillä, erityisesti kehittäjien, SaaS:n, pilven, tietoturvan ja dokumentaatiopainotteisten sivustojen keskuudessa.
| Lähde | Ajankohta | Otos | Raportoitu kelvollinen käyttöönotto | Tulkinta |
|---|---|---|---|---|
| Rankability | 22. kesäkuuta 2025 | Top 1 000 -verkkosivustoa | 0,3 % | Varhainen julkinen vertailu, joka osoitti vähäistä käyttöönottoa kesällä 2025. |
| Tämä tutkimus | 6. toukokuuta 2026 | Tranco Top 1 000 | 7,50 % | Myöhempi crawl, joka osoitti näkyvää käyttöönottoa paljon liikennettä saavilla sivustoilla. |
| Tämä tutkimus | 6. toukokuuta 2026 | Tranco Top 10 000 | 5,86 % | Laajempi otos, joka osoittaa käyttöönoton olevan mitattavissa, mutta ei valtavirtaa. |
Liikennekokeiden tulokset ovat yhä ristiriitaisia
Search Engine Land julkaisi tammikuussa 2026 10 sivuston analyysin, jossa sivustoja seurattiin 90 päivää ennen toteutusta ja 90 päivää sen jälkeen. Artikkelin mukaan kahden sivuston AI-liikenne kasvoi 12,5 % ja 25 %, kahdeksalla ei tapahtunut mitattavaa parannusta ja yhden lasku oli 19,7 %. Keskeinen tulkinta oli kausaalinen varovaisuus: kaksi näennäistä onnistumista julkaisivat samalla uusia sivupohjia, rakensivat resurssikeskuksia uudelleen, lisäsivät poimittavia vertailutaulukoita, saivat mediahuomiota, korjasivat teknisiä ongelmia tai julkaisivat uusia FAQ-tyylisiä sisältöjä. Tässä kehyksessä llms.txt dokumentoi vahvempaa sisältö- ja teknistä työtä; ei vaikuttanut olevan kasvun yksittäinen syy.
Renat Alimbekovin henkilökohtainen blogikoe päätyi pienemmästä sivustokohtaisesta havainnosta myönteisempään johtopäätökseen. Siinä vertailtiin kahta neljän kuukauden jaksoa Yandex.Metrica-tilastoissa sen jälkeen, kun sekä llms.txt että llms-full.txt oli lisätty. LLM-läheteistuntojen määrä kasvoi 75:stä 92:een, eli 23 %, ja käyttäjien määrä 51:stä 64:ään. Perplexity-istunnot kasvoivat 29:stä 55:een, kun taas ChatGPT-istunnot laskivat 31:stä 26:een. Samassa kirjoituksessa todetaan myös, että koko suositteluliikenne kasvoi nopeammin, 160:stä 290 istuntoon, joten LLM-istuntojen osuus laski 47 prosentista 32 prosenttiin.
| Näytön tyyppi | Havaittu tulos | Keskeinen varaus | Miten se vaikuttaa tähän raporttiin |
|---|---|---|---|
| Search Engine Landin 10 sivuston ennen/jälkeen-tutkimus | Kaksi sivustoa kasvoi, kahdeksalla ei ollut mitattavaa muutosta, yksi laski. | Myönteisissä tapauksissa samaan aikaan tehtiin sisältö-, PR- ja teknisiä muutoksia. | Tukee näkemystä, että llms.txt on infrastruktuuria, ei yksittäinen kasvuvipu. |
| Alimbekovin henkilökohtaisen blogin ennen/jälkeen-havainto | LLM-läheteistunnot kasvoivat 23 % jälkijaksolla. | Kontrolliryhmää ei ollut; kokonaisliikenne kasvoi 81 %, ja LLM-osuus laski. | Viittaa mahdolliseen hyötyyn teknisille blogeille, etenkin Perplexityn kautta, mutta kausaliteetti ei ole eristetty. |
| Tämä crawl-pohjainen käyttöönototutkimus | 586 kelvollista tiedostoa ja monia jäsenneltyjä toteutuksia. | Mittaa olemassaoloa ja rakennetta, ei alaspäin suuntautuvaa liikennevaikutusta. | Osoittaa käyttöönottoa ja toteutuksen kypsyyttä, mutta ei yksin ROI:ta. |
Mitä keskustelu selkeyttää
Ulkoinen näyttö tarkentaa tämän aineiston tulkintaa. Hyvin jäsennelty llms.txt-tiedosto voi vähentää koneellisen käsittelyn kitkaa, erityisesti kehittäjädokumentaatiossa, API-viitteissä ja tietokantatyylisessä sisällössä. Mutta vahvimmat liikennetapaukset näyttävät silti riippuvan sisällöstä, joka on hyödyllistä, poimittavaa, auktoritatiivista ja löydettävissä myös tiedoston ulkopuolella. Siksi käytännön kysymys ei ole yksinään “onko llms.txt tärkeä?”, vaan kuuluuko tiedosto laajempaan AI:lle luettavaan sisältöjärjestelmään.
Päivitetty tulkinta:
llms.txtkannattaa toteuttaa vähäkuluisena AI:lle suunnattuna infrastruktuurina. Sitä ei pidä asemoida paremman dokumentaation, jäsennellyn sisällön, teknisen saavutettavuuden, viittausten, linkkien tai brändi-auktoriteetin korvaajaksi.
Kokeile Thunderbitiä AI-verkkokaavintaan
Menetelmä
Tässä tutkimuksessa otoksena käytettiin Tranco Top 10 000 -verkkotunnuksia. Tranco on tutkimuskäyttöön tarkoitettu huipputason sivustojen ranking, joka on suunniteltu vakaammaksi ja manipulointia kestävämmäksi kuin monet perinteiset listat. Tranco-lähdetiedosto ladattiin 6. toukokuuta 2026, ja lähteen Last-Modified-aikaleima oli 5. toukokuuta 2026 klo 22:17:59 GMT.
Crawler tarkasti jokaiselle verkkotunnukselle kaksi juuritason polkua:
https://example.com/llms.txt, tarvittaessa HTTP-varalla.https://example.com/llms-full.txt, tarvittaessa HTTP-varalla.
Jokaisesta tarkistuksesta tallennettiin tilakoodi, lopullinen URL, hakutapa, vastausbytesit, sisältötyyppi, virheilmoitus, kulunut aika ja validointitulos. Onnistuneet vastausrunkojen kopiot tallennettiin hakemistoon raw_llms_txt/ tarkastelua ja jatkoanalyysiä varten.
Validointisäännöt
Vastaus laskettiin kelvolliseksi tiedostoksi vain, jos se palautti onnistuneen rungon eikä näyttänyt yleiseltä verkkosivun vararatkaisulta. Lopullisen URL-polun piti pysyä muodossa /llms.txt tai /llms-full.txt. Tyhjät rungot hylättiin. Ilmeiset HTML-dokumentit ja sovelluskuoret hylättiin. Sisältötyyppiä pidettiin tukevana vihjeenä, ei ainoana sääntönä, koska pieni määrä kelvollisia tekstimäisiä tiedostoja palveltiin epätavallisilla sisältötyypeillä.
Käyttöönoton näkymä
Crawl löysi 586 kelvollista llms.txt-tiedostoa Tranco Top 10 000 -listalla. Tämä tuottaa 5,86 prosentin kelvollisen käyttöönottoasteen. Pienempi llms-full.txt-kumppanitiedosto oli olemassa ja kelvollinen 103 verkkotunnuksella, eli 1,03 prosentilla otoksesta.
| Mittari | Määrä | Osuus Top 10 000 -listasta |
|---|---|---|
| Kävityt verkkotunnukset | 10 000 | 100,00 % |
| Kelvolliset llms.txt-tiedostot | 586 | 5,86 % |
| Kelvolliset llms-full.txt-tiedostot | 103 | 1,03 % |
| HTTP 200 -vastaukset polulle /llms.txt | 1 606 | 16,06 % |
| Kelvottomina hylätyt HTTP 200 -vastaukset | 1 020 | 10,20 % |
Käyttöönotto ei ole pelkästään kärkipainotteista
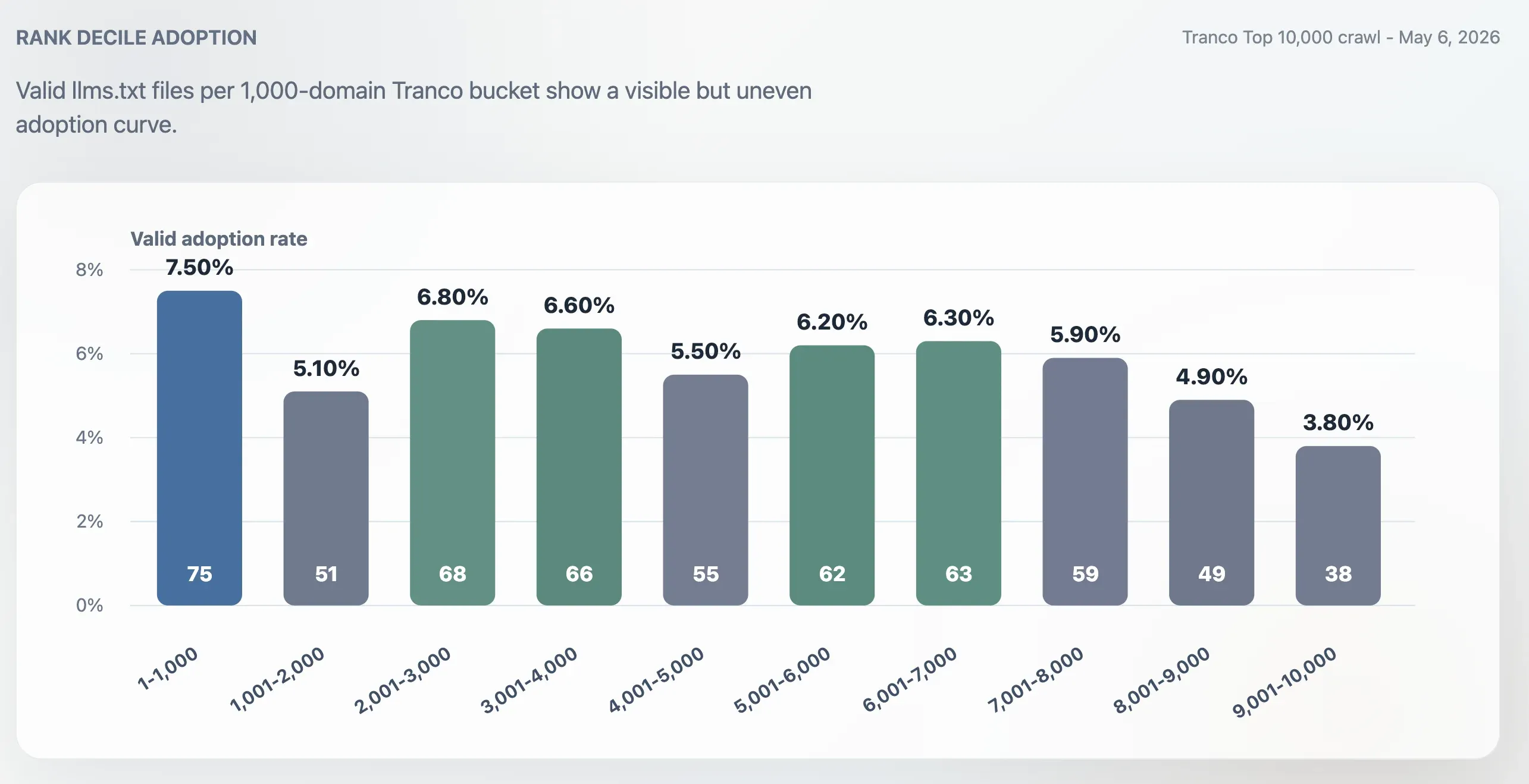
Käyttöönotto oli korkeampaa Top 1 000 -joukossa kuin koko Top 10 000 -listalla, mutta se ei rajoittunut aivan suurimpiin sivustoihin. Top 1 000 -käyttöönottoaste oli 7,50 %. Viimeinen 1 000 verkkotunnuksen lohko, sijat 9 001–10 000, putosi 3,80 prosenttiin. Rankingin keskiosa pysyi aktiivisena: lohkot 2 001–3 000, 3 001–4 000, 5 001–6 000 ja 6 001–7 000 asettuivat kaikki noin 6 prosenttiin.
Varhaiset käyttäjät
Korkeimmin sijoittunut kelvollinen käyttäjä oli Cloudflare sijalla 4. Muita korkealle sijoittuneita käyttäjiä olivat Azure, GitHub, DigiCert, WordPress.org, Adobe, Sentry, Dropbox, PayPal, Shopify, Taboola, Avast, Weather.com, Oxylabs, SourceForge, Cisco, Stripe, Slack, Dell, NVIDIA, Indeed, Zendesk, Calendly, Palo Alto Networks, Okta, Braze, Klaviyo, Intercom, Datadog, Cloudinary, ClassLink ja OneSignal.
Nämä käyttäjät eivät ole satunnaisia. Heillä on usein laajat dokumentaatioalueet, tuotelinjat, jotka vaativat selittämistä, API:t tai kehittäjäekosysteemit, tukisisältöä, hinnoittelusivuja, tietoturva- ja tietosuojamateriaaleja sekä riittävästi brändi-auktoriteettia välittääkseen siitä, miten AI-järjestelmät tulkitsevat heidän sivustojaan.
| Sija | Verkkotunnus | Tiedostokoko | Havaittu rakenne |
|---|---|---|---|
| 4 | cloudflare.com | 4 225 B | Tiivis tuote-, kehittäjä-, yritys- ja hinnoitteluindeksi. |
| 26 | azure.com | 47 037 B | Kehittäjätyökalut, AI, laskenta, tallennus, tietoturva, valvonta ja valinnaiset resurssit. |
| 28 | github.com | 27 108 B | Ohjelmallinen käyttö, Copilot, MCP, REST API, Actions, repositoriot ja CLI-linkit. |
| 248 | stripe.com | 64 229 B | Maksut, Connect, Checkout, Billing, Tax, Atlas, Radar ja kehittäjädokumentaatio. |
| 265 | salesforce.com | 1,02 MB | Massiivinen tuote- ja Agentforce-linkkikatalogi ilman Markdown-osiotasoja. |
Top 1 000 -käyttäjien kategoriat
Tässä tutkimuksessa luokiteltiin Tranco Top 1 000 -listan 75 kelvollista käyttäjää verkkotunnuksen kontekstin, ensimmäisten otsikoiden, raakatiedoston rakenteen ja sisältöavainten perusteella. Suurin ryhmä oli markkinointi, media ja adtech 22,67 prosentin osuudella. Pilvi-, kehittäjä- ja infrastruktuurisivustot muodostivat 20,00 %. SaaS-, tuottavuus- ja asiakasoperaatiosivustot muodostivat 17,33 %. Tietoturva-, identiteetti- ja yksityisyyssivustot muodostivat 12,00 %.
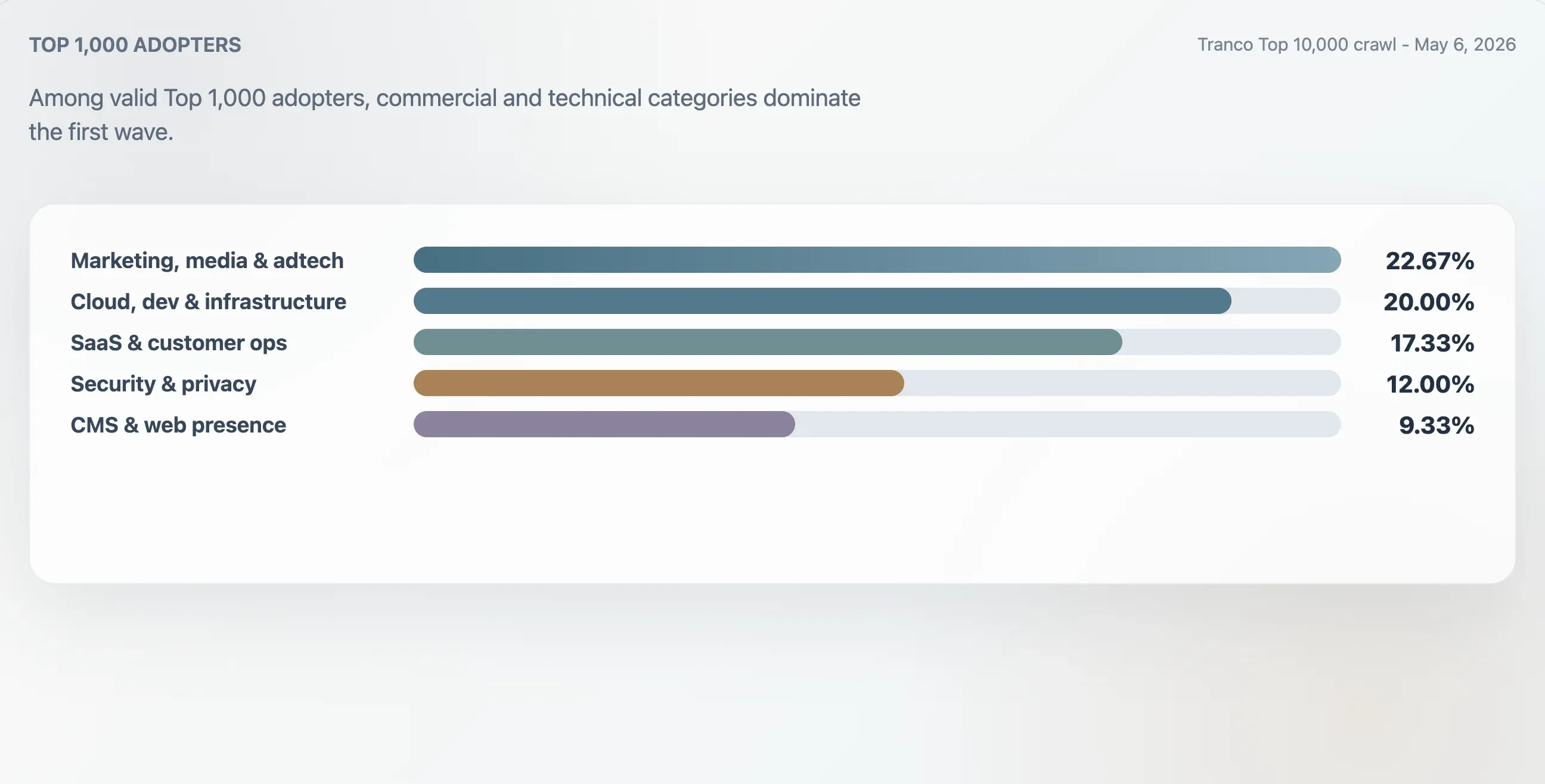
| Kategoria | Verkkotunnukset | Osuus Top 1 000 -käyttäjistä | Mediaanilaatupisteet | Medianilinkit |
|---|---|---|---|---|
| Markkinointi, media & adtech | 17 | 22,67 % | 94 | 25 |
| Pilvi, kehitys & infrastruktuuri | 15 | 20,00 % | 94 | 62 |
| SaaS, tuottavuus & asiakasoperaatiot | 13 | 17,33 % | 94 | 46 |
| Tietoturva, identiteetti & yksityisyys | 9 | 12,00 % | 98 | 78 |
| CMS, hosting & verkkoläsnäolo | 7 | 9,33 % | 100 | 24 |
TLD-mallit
Ylätason verkkotunnukset eivät ole toimialatunnisteita, mutta ne antavat hyödyllisiä suuntaa-antavia vihjeitä. Niistä TLD:istä, joissa oli vähintään 50 verkkotunnusta otoksessa, .io:lla oli korkein kelvollinen käyttöönottoaste, 14,44 %. .com seurasi 8,19 prosentilla. Alempi käyttöönotto .gov-, .edu- ja .net-päätteissä viittaa siihen, että varhaiset käyttäjät ovat enemmän kaupallisia ja teknisiä kuin institutionaalisia.
Toteutuksen laatu
Kelvollinen käyttöönotto ei tarkoita yhdenmukaista toteutuslaatua. Jotkin tiedostot ovat tiiviitä, hyvin osioituja hakemistoja. Osa on lähinnä proosaa. Osa on raakaa linkkiluetteloa. Osa on lähes tyhjiä paikkamerkkejä. Osa on monen megatavun sisältökaatopaikkoja, jotka voivat olla täydellisiä mutta kalliita hakea ja jäsentää.
Kelvollisista llms.txt-tiedostoista 362 oli yli 5 kt, eli 61,77 % kelvollisista käyttäjistä. Mediaanikoko oli noin 7,1 kt. P90-tiedostokoko oli 156 kt, P95 oli 356 kt, P99 oli 2,54 Mt ja suurin havaittu tiedosto oli 7,97 Mt.
Yleiset sisältösignaalit
Avainsanatasoinen tarkastus kelvollisista tiedostoista osoitti, että monet sivustot eivät ainoastaan julkaise julistusta; ne ohjaavat malleja kohti operatiivisesti hyödyllistä materiaalia. Tuki- tai ohjetermit esiintyivät 70,31 prosentissa kelvollisista tiedostoista. Blogi-, opas- tai tutoriaalitermit esiintyivät 67,92 prosentissa. Turvallisuus-, yksityisyys-, compliance- tai ehtotermit esiintyivät 61,43 prosentissa. Hinnoittelu esiintyi 53,92 prosentissa, dokumentaatio 52,22 prosentissa, API-termit 33,96 prosentissa ja changelog- tai release-signaalit 27,30 prosentissa.
Laatupisteytys ja arkkityypit
Siirtyäkseen pelkästä olemassaolosta kypsyyteen tämä tutkimus loi kevyen toteutuspisteytyksen. Pisteytys huomioi sisältötyypin, tiedostokoon, Markdown-rakenteen, linkkien määrän, aihepeiton sekä varoitusmerkit, kuten puuttuvat otsikot, Markdown-linkkien puuttumisen, epätavalliset sisältötyypit, pienet tiedostot, erittäin suuret tiedostot ja linkkien dumppauskäyttäytymisen. Tämä ei ole virallinen standardi. Se on tutkimuspisteytysmalli havaittujen toteutusten vertailuun.
Tällä mallilla 416 kelvollista tiedostoa luokiteltiin vahvoiksi jäsennellyiksi hakemistoiksi, 107 käyttökelpoisiksi hakemistoiksi, 24 ohuiksi tai epäsäännöllisiksi ja 39 symbolisiksi tai vähähyötyisiksi. Erillinen arkkityyppianalyysi löysi 296 jäsenneltyä hakemistoa, 113 osioitua tekstitiedostoa, 63 linkkikatalogia, 52 ohutta hakemistoa, 50 symbolista tai paikkamerkkitiedostoa ja 12 massiivista sisältödumppia.
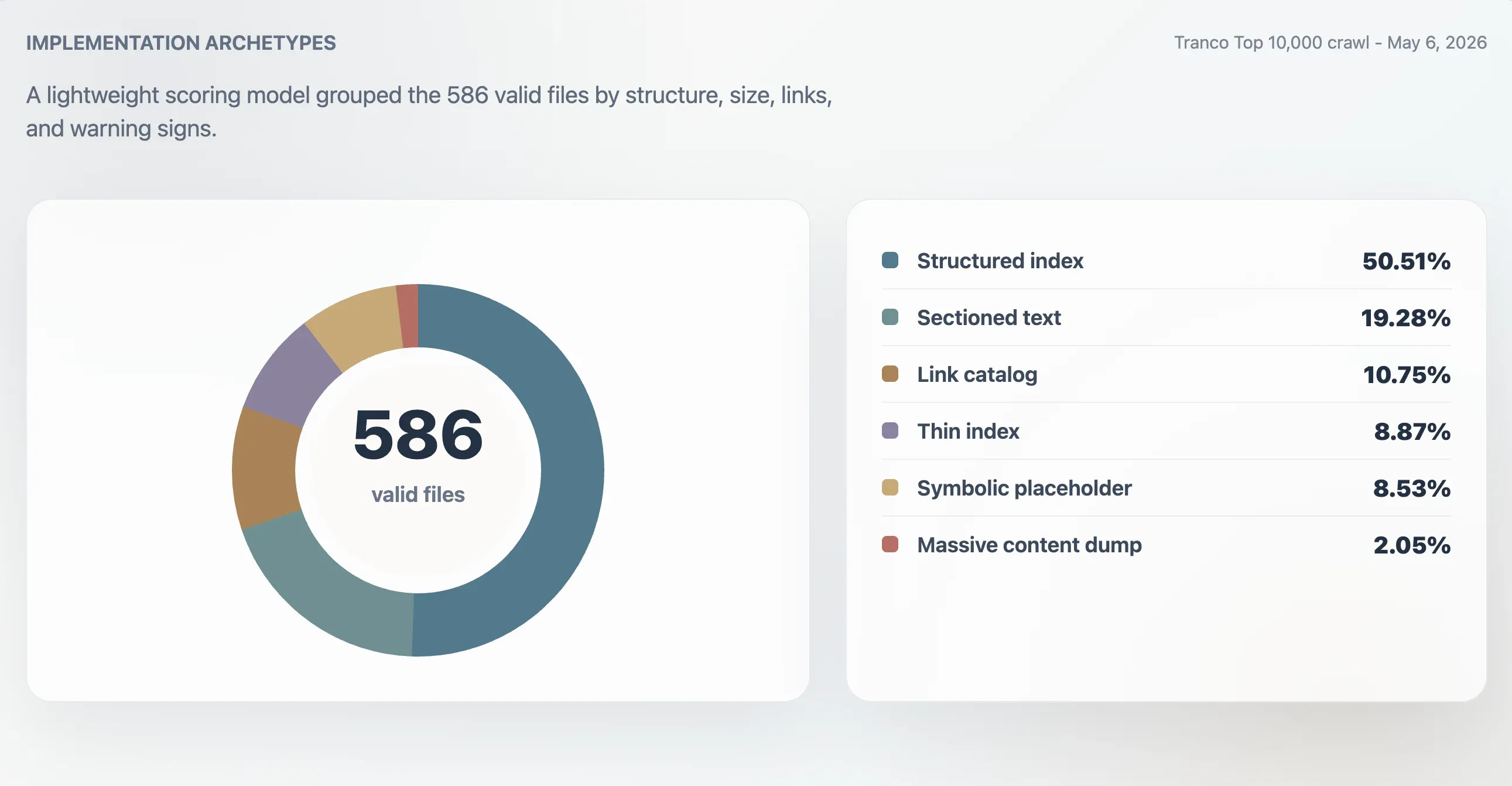
| Arkkityyppi | Verkkotunnukset | Osuus kelvollisista tiedostoista | Mediaanipisteet | Mediaanitiedostokoko | Medianilinkit |
|---|---|---|---|---|---|
| Jäsennelty hakemisto | 296 | 50,51 % | 98 | 11 241 B | 61,5 |
| Osioitu teksti | 113 | 19,28 % | 78 | 4 718 B | 0 |
| Linkkikatalogi | 63 | 10,75 % | 86 | 4 160 B | 23 |
| Ohut hakemisto | 52 | 8,87 % | 66 | 2 814 B | 0 |
| Symbolinen tai paikkamerkki | 50 | 8,53 % | 27 | 15 B | 0 |
| Massiivinen sisältödumppi | 12 | 2,05 % | 74 | 2,84 MB | 7 259,5 |
Top-käyttäjillä on tiiviimmät toteutukset
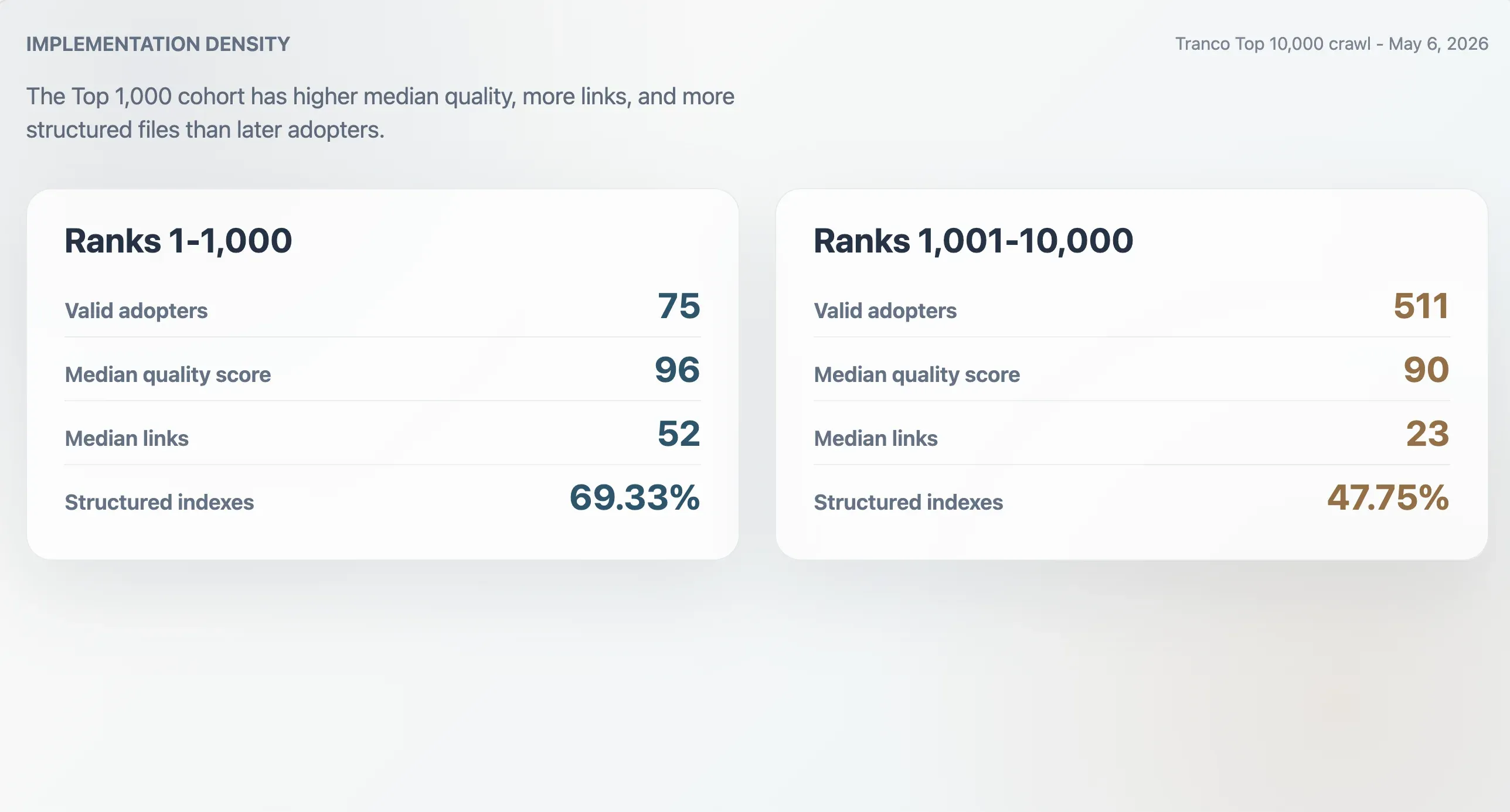
Tranco Top 1 000 -listan 75 kelvollisella käyttäjällä mediaanilaatupisteet olivat 96, mediaanitiedostokoko 9 068 tavua, mediaani Markdown-linkkimäärä 52 ja mediaani osiomäärä 11. Myöhemmin sijoittuneiden 511 käyttäjän, sijat 1 001–10 000, mediaanit olivat alemmat: pisteet 90, tiedostokoko 6 506 tavua, 23 Markdown-linkkiä ja 9 osiota. Top 1 000 -käyttäjät olivat myös todennäköisemmin jäsenneltyjä hakemistoja: 69,33 % verrattuna myöhemmän ryhmän 47,75 %:iin.
Väärien positiivisten ongelma

Suurin mittausriski on väärät positiiviset. Niistä 1 606 verkkotunnuksesta, jotka palauttivat HTTP 200:n polussa /llms.txt, 1 020 epäonnistui validoinnissa. Yleisin kelvoton syy oli väärään kohteeseen ohjautuva uudelleenohjaus, 618 tapausta. Toinen 367 vastausta oli yleisiä HTML-dokumentteja. 29 palautti tyhjän rungon ja kuusi oli muita tai luokittelemattomia virheellisiä vastauksia.
Tämä on tärkeää, koska monet suuret sivustot ohjaavat tuntemattomat polut kirjautumissivuille, etusivuille, sovelluskuoriin, aluekohtaisille sivuille, suostumuskerroksiin tai markkinointivaraustiloihin. Nämä vastaukset voivat näyttää kunnossa olevilta tilakoodin perusteella, mutta ne eivät sisällä kelvollista llms.txt-signaalia.
llms-full.txt: harvinaisempi ja epätasaisempi
Kumppanitiedosto llms-full.txt oli paljon harvinaisempi kuin llms.txt. Crawl löysi 103 kelvollista täyttä tiedostoa, mikä vastaa 17,58 prosenttia kelvollisista llms.txt-käyttäjistä ja 1,03 prosenttia koko Top 10 000 -otoksesta.
Täyden tiedoston toteutukset olivat epätasaisia. 103 kahden tiedoston käyttäjästä 57:llä llms-full.txt oli hakemistotiedostoa suurempi, mutta 46:lla täysi tiedosto oli joko enintään hakemistotiedoston kokoinen tai alle 100 tavua. Mediaaninen täysi/hakemisto-kokosuhde oli 1,43, mutta ääripäät olivat paljon suurempia. Supabasen täysi tiedosto oli noin 7 139-kertainen sen hakemistotiedostoon verrattuna. Made-in-China.comilla oli 89,89 Mt:n täysi tiedosto.
| Verkkotunnus | llms.txt | llms-full.txt | Suhde |
|---|---|---|---|
| made-in-china.com | 4,49 MB | 89,89 MB | 20,0x |
| sendbird.com | 281,86 KB | 11,99 MB | 42,5x |
| taboola.com | 286,78 KB | 11,73 MB | 40,9x |
| supabase.co | 1,26 KB | 8,98 MB | 7 139,3x |
| neon.tech | 27,44 KB | 5,01 MB | 182,7x |
Suositus: julkaise
llms-full.txtvain silloin, kun sivustolla on jo vakaa dokumentaatioputki, versionhallinnan kurinalaisuus ja selvä syy altistaa suuri määrä sisältöä yhdessä koneelle luettavassa tiedostossa.
llms.txt, robots.txt ja sitemap.xml
llms.txt:ää ei pidä käsitellä uutena robots.txt:nä. Molemmat ovat juuritason koneelle luettavia tiedostoja, mutta ne viestivät eri asioita. robots.txt on crawlereiden toive- ja pääsynhallintasignaali. sitemap.xml on URL-löydettävyyssignaali. llms.txt on selittävä ja navigoiva signaali.
| Signaali | Päärooli | Tyypillinen lukija | Tulkinta tässä tutkimuksessa |
|---|---|---|---|
robots.txt | Ilmaisee crawlereiden toiveet ja polkutason rajoitukset. | Hakucrawlerit, AI-crawlerit, arkistocrawlerit, yleiset botit. | Hallinta- ja pääsysignaali. |
sitemap.xml | Listaa löydettävät URL-osoitteet indeksointijärjestelmille. | Hakukoneet ja indeksointiputket. | Löydettävyssignaali. |
llms.txt | Tarjoaa tiiviin sivustokontekstin, tärkeät linkit, dokumentaation, API:t, esimerkit ja käytäntöviitteet. | LLM-sovellukset, AI-agentit, kehittäjätyökalut, hakujärjestelmät. | Selitys- ja navigointisignaali. |
Suositukset
Sivustoille, jotka harkitsevat llms.txt:ää, tämän aineiston vahvimmat toteutukset ja ulkoinen liikennenäyttö viittaavat käytännölliseen malliin:
- Julkaise
/llms.txtjuureen ja pidä se käytettävissä ilman kirjautumista, JavaScriptin suorittamista, suostumusmuureja tai väärän polun uudelleenohjauksia. - Tarjoa se mieluiten muodossa
text/plaintaitext/markdown. - Aloita lyhyellä kuvauksella sivustosta ja ryhmittele sitten linkit tuotteen, dokumentaation, API:n, hinnoittelun, changelogin, esimerkkien, tuen, käytäntöjen ja yritysresurssien mukaan.
- Suosi kanonisia linkkejä loputtomien URL-listojen sijaan.
- Vältä tyhjiä symbolisia tiedostoja; ne ovat parhaimmillaankin heikko signaali.
- Vältä massiivisia, jäsentymättömiä dumppauksia, ellei niille ole vahvaa konekulutustarvetta ja luotettavaa generointiputkea.
- Vahvista julkaisemisen jälkeen lopullinen URL, vastausrunko, sisältötyyppi, Markdown-rakenne, linkkien määrä ja tiedostokoko.
Tiimien kannattaa myös asettaa odotukset huolellisesti. Saatavilla olevat julkiset kokeet eivät todista, että llms.txt lisäisi itsenäisesti AI-läheteistä liikennettä. Jos tiimi haluaa testata liiketoimintavaikutusta, sen tulisi seurata LLM-lähetteitä, viitattuja sivuja, bottipyyntöjä, indeksin tuoreutta ja sisältömuutoksia yhdessä. Hyödyllinen koe vertaisi kohdistettuja sivuryhmiä, pitäisi sisältöpäivitykset mahdollisimman vakioituina ja erottaisi alustakohtaisen liikenteen kuten Perplexityn, ChatGPT:n, Geminin, Clauden ja Bing/Copilotin.
Rajoitukset
Tämä on crawl-pohjainen tilannekuva, ei pysyvä totuus. Verkkosivustot voivat lisätä, poistaa tai muuttaa llms.txt-tiedostojaan milloin tahansa. Jotkin verkkotunnukset voivat estää automaattiset pyynnöt tai toimia eri tavoin maantieteen, TLS-konfiguraation, uudelleenohjauslogiikan, user agentin tai bottien torjunnan mukaan. Tutkimus testasi vain juuritason tiedostoja eikä etsinyt aliverkkotunnuksia tai epästandardisia polkuja.
Laatupisteytys ja arkkityypit ovat tutkimustyökaluja, eivät virallisia vaatimustenmukaisuusmerkintöjä. Aiheanalyysi perustuu avainsanoihin ja sitä tulisi lukea suuntaa-antavana. Tutkimus ei todista, että mikään tietty AI-alusta tällä hetkellä lukisi, noudattaisi tai käyttäisi llms.txt:ää tuotannossa.
Tässä versiossa tarkastellulla ulkoisella liikennönäytöllä on myös rajoituksensa. Search Engine Landin analyysi on vahvempi varoittavana usean sivuston havaintona kuin satunnaistettuna kokeena. Alimbekovin tulos on hyödyllinen läpinäkyvänä sivustotason tapaustutkimuksena, mutta siitä puuttuu kontrolliryhmä, ja siihen sisältyy ajanjakso, jolloin koko suositteluliikenne kasvoi merkittävästi. Nämä viitteet auttavat kehystämään keskustelua, mutta ne eivät tee tästä crawlista kausaalista liikennetutkimusta.
Tiedostot ja toistettavuus
| Tiedosto | Tarkoitus |
|---|---|
crawl_llms_txt.py | Crawler poluille /llms.txt ja /llms-full.txt. |
analyze_llms_txt.py | Pääasiallinen käyttöönottoanalyysi ja kaavioiden generointi. |
deep_analyze_llms_txt.py | Jatkoanalyysi ranking-desiiileille, TLD:ille, aihesignaaleille, laatupisteille, arkkityypeille ja kahden tiedoston käyttäytymiselle. |
deep_dive_early_quality.py | Varhaisten käyttäjien luokittelu ja toteutuslaadun syväanalyysi. |
data/llms_probe_results_top_10000.csv | Pääasiallinen crawl-tulosaineisto. |
data/deep_analysis_top_10000.json | Jatkoanalyysin yhteenveto. |
data/deep_early_quality_analysis.json | Varhaisten käyttäjien kategoriat, laaturyhmien vertailu, arkkityyppien yksityiskohdat ja tapaustutkimukset. |
Lähteet
- The /llms.txt file, Jeremy Howard, 2024.
- HTTP Archive Web Almanac 2024 Methodology.
- Cloudflare Radar: Expanded AI insights.
- Cloudflare Radar AI Insights.
- Consent in Crisis: The Rapid Decline of the AI Data Commons, Data Provenance Initiative.
- Tranco: A Research-Oriented Top Sites Ranking Hardened Against Manipulation.
- Does llms.txt matter?, Search Engine Land, tammikuu 2026.
- The State of llms.txt Adoption, Rankability, kesäkuu 2025.
- How LLMS.txt Increased AI Chat Traffic by 23%, Renat Alimbekov.
Menetelmäkorjaukset, aineisto-ongelmat ja jatkoanalyysit ovat tervetulleita osoitteeseen support@thunderbit.com. Tämä raportti julkaistaan riippumatta Thunderbitin kaupallisesta asemasta. Tämän raportin data puhuu puolestaan. — Thunderbitin tutkimustiimi, toukokuu 2026.
Kokeile Thunderbitiä web-datan kaavintaan ja analysointiin Get Started Free




