

YouTubessa on yli 2 miljardia kuukausittaista käyttäjää ja yli 500 tuntia videota ladataan joka minuutti. Se on myös yksi vaikeimmista alustoista scrape-ta ilman, että vastaan tulee CAPTCHA, 429-virheitä tai suoria IP-banneja.
Jos olet joskus yrittänyt hakea kanavatietoja, kommentteja tai transkripteja yhtään suuremmassa mittakaavassa, tiedät jo, miten turhauttavaa se on. Saat ehkä muutaman sadan tuloksen, ja sitten YouTube lyö oven kiinni. Olen käyttänyt paljon aikaa arvioidakseni, miten erilaiset scraping-tavat kestävät YouTuben kehittyviä bottisuojauksia, ja ero luotettavasti toimivien työkalujen ja sellaisten työkalujen välillä, jotka estetään minuuteissa, on valtava.
Tämä opas käy läpi 6 parasta YouTube-scraperia vuodelle 2026 — työkaluja, jotka on oikeasti rakennettu selviytymään YouTuben vihamielisessä ympäristössä ilman, että IP-osoite tai työnkulku palaa loppuun. Olitpa markkinoija seuraamassa kilpailijoiden kanavia, myyntitiimi etsimässä tekijöiden yhteystietoja tai kehittäjä rakentamassa dataputkea, täältä löytyy sopiva vaihtoehto.
Mitä YouTube oikeasti estää vuonna 2026 (ja miksi useimmat scraperit epäonnistuvat)
YouTuben bottisuoja ei ole yksi ainoa muuri — se on kerroksittainen järjestelmä. Sen ymmärtäminen on ensimmäinen askel siihen, ettei tule estetyksi.
Tässä on, mitä YouTube tekee vuonna 2026 havaitakseen ja pysäyttääkseen automatisoidun käytön:

- IP-maineen ja nopeuden tarkistukset: Toistuvat pyynnöt datakeskus-IP-osoitteista, VPN:istä tai jaetuista proxyeista liputetaan nopeasti. Näet 403-virheitä, 429-rate limit -rajoituksia tai "kirjaudu sisään vahvistaaksesi, ettet ole botti" -näyttöjä.
- Selain- ja JavaScript-jäljitettävyys: YouTube tarkistaa, käyttäytyykö asiakas kuin oikea selain — suorittaako se skriptejä, renderöikö se elementit ja säilyttääkö se odotetun tilan. Headless-selaimet ja suorat HTTP-asiakkaat epäonnistuvat usein näissä testeissä hiljaisesti (saat vain tyhjää tai osittaista dataa).
- Evästeiden ja istunnon luottamus: Jos pyyntösi eivät tule tunnistetusta, pitkäikäisestä selainistunnosta, YouTube kiristää varmennusta. Kirjautuneet istunnot, joilla on selaushistoriaa, ovat luotettavampia kuin uudet anonyymit istunnot.
- Käyttäytymisanalyysi: Tasaiset pyyntöväliat, liian nopea scrollaus tai toistuvat sivukuviot laukaisevat rajoitukset. YouTube etsii navigointia, jota mikään ihminen ei tekisi.
- CAPTCHA-portit: Kun riski on korkea, YouTube pakottaa ihmisen tekemän varmennuksen — erityisesti hakutuloksissa ja kommenttiosioissa.
- API-kiintiöiden valvonta: Virallinen YouTube Data API noudattaa projektikohtaisia päiväkiintiöitä (oletuksena 10 000 yksikköä/päivä), ja hakupainotteiset työnkulut kuluttavat ne loppuun minuuteissa.
Tyypillinen käyttökokemus: alat scrape-ta, saat muutaman sadan tuloksen, ja sitten osut Error 429:ään, CAPTCHA-seinään tai hiljaa heikentyneeseen dataan. Datakeskus-IP:istä toimivat pilvipohjaiset scraperit ovat erityisen haavoittuvia.
| Havaintotapa | Mitä se tekee | Käyttäjän oire | Työkalut, jotka vähentävät riskiä |
|---|---|---|---|
| IP-maine/nopeus | Liputtaa datakeskus-, VPN- ja jaetut IP:t | 403, 429, bottivarmennus | Selainistuntoon perustuva scraping, residential-proxyt |
| JS-jäljitettävyys | Tarkistaa oikean selaimen suorittamisen | Hiljainen puuttuva data, CAPTCHA | Oikea selainlaajennus, täysi renderöinti |
| Eväste-/istuntoluottamus | Vertaa kirjautuneisiin profiileihin | "Kirjaudu sisään vahvistaaksesi" | Käyttäjän evästeet, todennettu istunto |
| Käyttäytymisanalyysi | Havaitsee epäinhimilliset kaavat | Rajoitukset noin 200 rivin jälkeen | Inhimilliset viiveet, satunnaistaminen, pienet erät |
| API-kiintiöiden valvonta | Rajoittaa päiväkohtaiset API-yksiköt | 403 quotaExceeded | Käytä scrappereita hakuun/kommentteihin, API:ta kohdennettuihin hakuihin |
| CAPTCHA-portit | Pakottaa ihmisen varmennuksen | Poiminta pysähtyy kesken ajon | Selainistunto, proxy/unblocker, hitaampi rytmi |
Ydinpointti: työkalut, jotka toimivat oikeassa selainistunnossa (kuten Thunderbit), kiertävät luonnostaan monia näistä tarkistuksista, koska pyyntö näyttää täsmälleen samalta kuin ihmisen selaaminen YouTubessa. Pelkästään pilvessä toimivat scraperit tarvitsevat proxy-kierrätystä, CAPTCHA-ratkaisua ja tarkkaa rytmitystä selviytyäkseen.
Kokeile Thunderbitia YouTube-scrapingiin
YouTube API vs. parhaat YouTube-scraperit: käytännöllinen päätösmalli
YouTube Data API v3 on "virallinen" tapa käyttää YouTuben dataa ohjelmallisesti. Se on luotettava perusmetadatan hakemiseen pienillä volyymeilla — mutta sen kiintiömalli tekee siitä epäkäytännöllisen useimmille oikean maailman kilpailutiedustelun ja tutkimuksen työnkuluille.
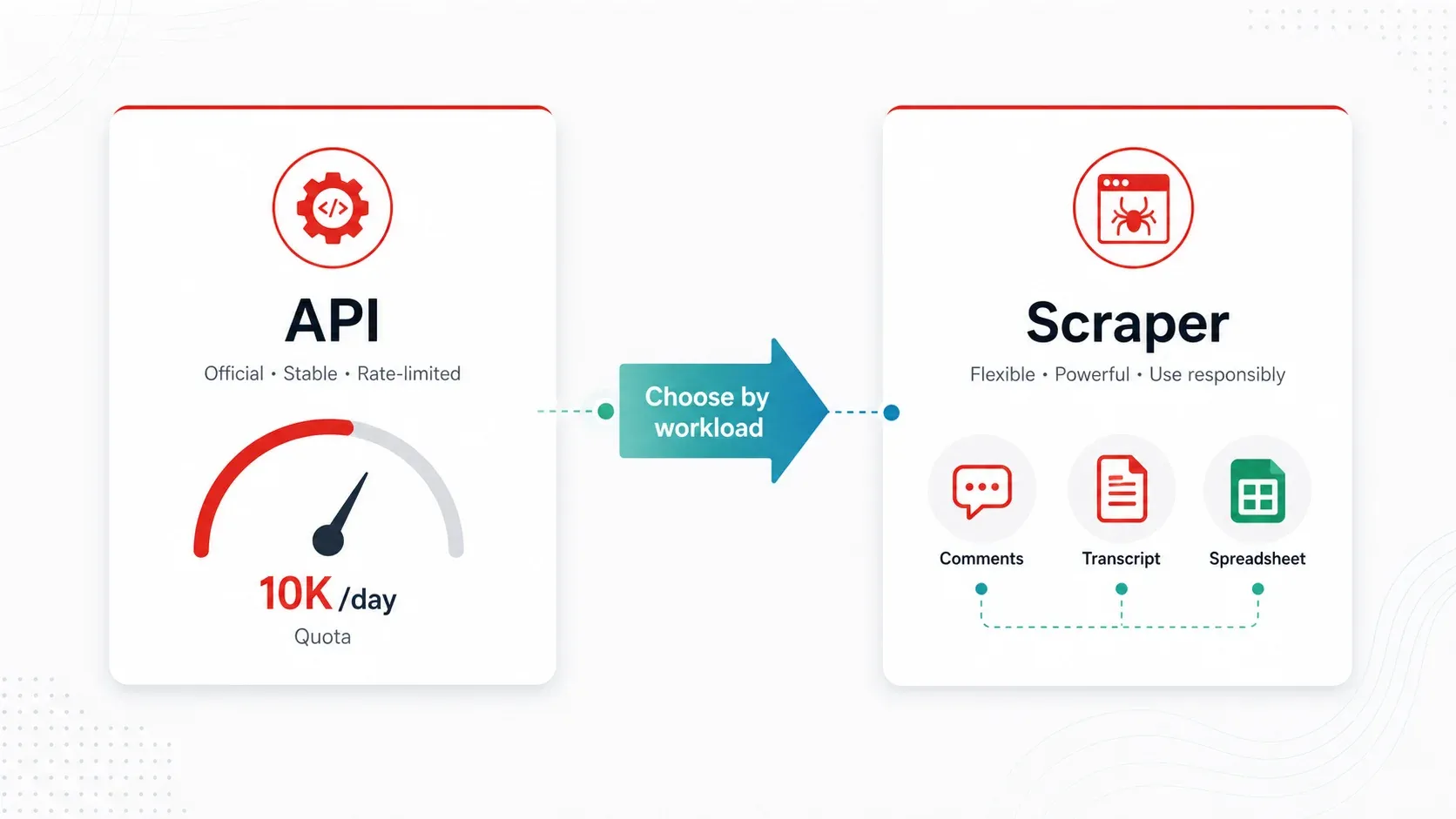
Tässä matematiikka. Jokainen API-projekti saa 10 000 kiintiöyksikköä päivässä. Keskeiset endpoint-kustannukset:
search.list= 100 yksikköä per sivu (enintään 50 tulosta per sivu)videos.list= 1 yksikkö per kutsu (enintään 50 video-ID:tä per kutsu)commentThreads.list= 1 yksikkö per kutsu (enintään 100 ketjua per kutsu)
Jos siis suoritat 100 avainsanahakua päivässä, olet käyttänyt koko päiväkiintiösi ennen kuin olet rikastanut yhtäkään videota. Kommenttipainotteinen työnkulku on kutsukohtaisesti edullisempi, mutta käytännön sivutus, kommenttien poiskytkentä ja vastausten laajennus syövät kapasiteettia nopeasti.
Milloin API riittää:
- Tarvitset alle 100 videota/päivä ja vain julkista metadataa (otsikko, katselut, tykkäykset, kesto)
- Kehittäjä voi ottaa OAuthin käyttöön ja hallita kiintiöitä
Milloin scraper on parempi:
- Tarvitset kommentteja mittakaavassa (API toimii, mutta kiintiökitka on todellinen)
- Tarvitset transkripteja/tekstityksiä tekstimuodossa (API ei paljasta tekstitystekstiä helposti massakäyttöön)
- Seuraat säännöllisesti yli 100 kanavaa (kiintiö kasvaa, ajoitus on manuaalista)
- Tarvitset rikastettua tai merkittyä dataa (luokittelu, käännös tai AI-pohjainen kenttien tunnistus)
- Olet ei-tekninen käyttäjä ja haluat vain taulukon
API ei myöskään paljasta kaikkea sitä, mitä näkisit verkossa: Shorts-hyllydata, julkiset sähköpostit kanavakuvauksista, yhteisöpostaukset ja osa kanavametadatasta ovat saatavilla vain scrappaamalla varsinaiset YouTube-sivut.
Scrapea YouTuben dataa AI:lla Get Started Free
Useimmille liiketoimintakäyttäjille, jotka tekevät kilpailututkimusta, etsivät tekijöitä tai suunnittelevat sisältöä, scraper-työkalu on käytännöllisempi kuin API.
Miten valitsimme 6 parasta YouTube-scraperia
Jokainen tämän listan työkalu arvioitiin samoilla kriteereillä — painotettuna siihen, mikä oikeasti merkitsee, kun YouTube yrittää aktiivisesti estää sinua:
| Kriteeri | Miksi se on tärkeä |
|---|---|
| Banien vastainen luotettavuus | Käyttäjien #1 kipupiste — rate limiting ja IP-bannit suuressa mittakaavassa |
| Hinta per 1 000 tulosta | Normalisoitu hinnoittelu auttaa budjettitietoisia käyttäjiä vertaamaan omenoita omenoihin |
| Tuetut datatyypit | Metadata, kommentit, transkriptiot, Shortsit, pikkukuvat — vaihtelee paljon työkalusta riippuen |
| Skaalautuvuus | Pystyykö se käsittelemään yli 100 kanavaa tai yli 10 000 videota kaatumatta? |
| Käytön helppous | Ensikertalaiset tarvitsevat toimivia, no-code-ystävällisiä vaihtoehtoja |
| Vientimuodot | CSV, JSON, Google Sheets, Airtable — eri työnkulut tarvitsevat eri ulostulot |
| Ylläpitotaakka | YouTuben muutokset rikkovat työkaluja; kuka korjaa ne? |
Kaikki työkalut arvioitiin senhetkisiä YouTuben estokuvioita vasten, joita käyttäjät kohtaavat vuonna 2026.
1. Thunderbit
Thunderbit on AI:lla toimiva Chrome-laajennus, joka muuttaa YouTube-sivut rakenteiseksi dataksi noin kahdella klikkauksella. Sen sijaan, että se toimisi pilvipalvelimelta (jonka YouTube havaitsee helposti), Thunderbit toimii omassa selainistunnossasi — joten YouTuben silmissä näytät siltä kuin selaisit normaalisti.
Ydinworkflow YouTubelle: asenna Thunderbit Chrome Extension, avaa YouTube-kanava, hakutulossivu tai videon sivu ja klikkaa "AI Suggest Fields." AI lukee sivun ja ehdottaa sarakkeita — videon otsikko, URL, katselut, latauspäivä, kuvaus, pikkukuvan URL, kommenttiteksti, kirjoittaja, tykkäykset ja muuta. Tarkistat, klikkaat "Scrape" ja viet tiedot suoraan Google Sheetsiin, Exceliin, Airtableen, Notioniin, CSV:hen tai JSONiin. Ei koodia, ei valitsimia, ei API-avaimia.
Keskeiset ominaisuudet YouTube-scrapingiin:
- AI-kenttätunnistus: Thunderbitin AI lukee minkä tahansa YouTube-sivun ja ehdottaa automaattisesti relevantit sarakkeet. CSS-valitsimia tai XPatheja ei tarvitse mapata käsin.
- Alasivujen scraping: Poimi kanavan videolista ja avaa sitten jokainen videon sivu rikastaaksesi tiedot kommenteilla, kuvauksilla, tageilla ja transkripteilla (jos näkyvissä).
- Ajastettu scraping: Luo toistuvia ajoja kanavien viikoittaiseen seurantaan ilman manuaalista puuttumista.
- Selaintila: Toimii todennetussa selainistunnossasi, mikä vähentää "pilvidatakeskus-IP"-jälkeä, joka laukaisee useimmat YouTuben estot.
- Ilmainen vienti: Data menee Google Sheetsiin, Exceliin, Airtableen tai Notioniin ilman vientimaksuseinää.
Banien vastainen lähestymistapa: Selainpohjainen istuntopohjainen scraping käyttäjän omalla todennetulla istunnolla. YouTube näkee oikean selaimen, oikeat evästeet ja oikean istuntohistorian. Suurissa ajoissa pienemmissä ajastetuissa erissä riski pienenee entisestään.
Hinnoittelu: Ilmainen taso (6 sivua), kokeilubonus (10 sivua). Maksulliset suunnitelmat ovat krediittipohjaisia. Tarkista Thunderbitin hinnoittelu ajantasaiset luvut.
Paras käyttäjille: Markkinoijat, myyntitiimit, sisällön strategit ja operatiiviset käyttäjät, jotka haluavat nopeaa kanava-/haku-/kommenttitutkimusta ilman teknistä käyttöönottoa.
Näin scrappaat YouTuben Thunderbitillä (vaihe vaiheelta)
- Asenna Thunderbit Chrome Extension.
- Siirry YouTube-kanavan sivulle, hakutuloksiin, soittolistaan tai videon sivulle.
- Klikkaa "AI Suggest Fields" — AI lukee sivun ja ehdottaa sarakkeet (otsikko, URL, katselut, päivämäärä, kuvaus, pikkukuva jne.).
- Tarkista ja säädä ehdotettuja kenttiä tarvittaessa.
- Klikkaa "Scrape" — data poimitaan rakenteiseksi taulukoksi.
- Vie Google Sheetsiin, Exceliin, Airtableen, Notioniin, CSV:hen tai JSONiin.
Syvempää poimintaa varten (esim. kommenttien hakeminen jokaisesta kanavan videosta) käytä alasivujen scrapingia: poimi ensin videolista ja anna sitten Thunderbitin vierailla jokaisella videon sivulla ja hakea kommenttidataa, kuvauksia tai transkription saatavuutta.
Koko prosessi vie tyypillisen kanavatutkimustehtävän kohdalla alle kaksi minuuttia. Ei API-avaimia, ei proxyjen asennusta, ei koodia.
Kokeile Thunderbitia YouTubessa kahdella klikkauksella
2. Apify
Apify on pilvipohjainen scraping-alusta, jossa on valmiita YouTube-"Actors"-toimintoja — erikoistuneita scrappereita videoille, kommenteille, kanaville, Shortseille ja transkripteille. Se on suunniteltu kehittäjille, jotka haluavat rakentaa automaattisia dataputkia yhden kertaluonteisen tutkimuksen sijaan.
Apifyn YouTube-ekosysteemi sisältää erilliset Actors-toiminnot eri tehtäviin. Hyvin ylläpidetty Actor nimeltä "YouTube Scraper — Videos, Comments & Transcripts" hyväksyy kanavia, soittolistoja, hakuja ja suoria video-URL-osoitteita. Se tukee Shorts-suodatusta, kommenttien poimintaa ja aikaleimallisia transkripteja.
Keskeiset ominaisuudet:
- Erilliset Actors-toiminnot videoille, kommenteille, kanaville, Shortseille ja transkripteille
- Hyväksyy syötteinä hakutermit, kanava-URL:t ja soittolistan ID:t
- Pilviajoitus ja webhook-integraatiot
- Vienti JSONiin, CSV:hen, Exceliin tai tietokantoihin API:n kautta
- Actor-tason nopeudensäätö ja proxy-kierrätys
Banien vastainen lähestymistapa: Actor-kohtainen rytmitys, Apifyn proxy-infrastruktuuri ja YouTuben sisäisen API:n (Innertube) käyttö soveltuvin osin. Jokainen Actor toteuttaa oman uudelleenyritys- ja rate-limit-logiikkansa.
Hinnoittelu: Mainittu YouTube Scraper Actor listaa noin 15 dollaria per 1 000 videota, 8 dollaria per 1 000 kommenttia ja 5 dollaria per transkripti. Alustapaketit alkavat 49 dollarista/kk.
Haitat: Käyttökustannukset kasvavat nopeasti suurissa ajoissa. Käyttöliittymä on kehittäjälähtöinen — ei-tekniset käyttäjät voivat kokea sen monimutkaiseksi. Ulostuloskeemat vaihtelevat Actorien välillä, joten datan siivousta tarvitaan usein. Actorien laatu vaihtelee markkinapaikalla.
Paras käyttäjille: Kehittäjät, jotka rakentavat automaattisia dataputkia, tiimit, jotka tarvitsevat ajastettua poimintaa API:hin tai tietokantoihin, sekä marketing ops -tiimit, jotka ajavat toistuvia kommenttien tunneanalyysityönkulkuja.
3. Bright Data
Bright Data on enterprise-tason datainfrastruktuurialusta, jolla on alan suurin residential-proxy-verkko ja omat YouTube-scraperit. Jos sinun täytyy scrape-ta YouTubea valtavassa mittakaavassa eri maantieteellisillä alueilla, tämä on raskasta kalustoa.
Bright Data tarjoaa useita YouTube-scrapereita (kanavaprofiilit, videot, kommentit) sekä valmiita YouTube-datasettejä ostettavaksi. Heidän hallinnoitu scraping-palvelunsa tarkoittaa, että he rakentavat ja ylläpitävät scrapersi puolestasi.
Keskeiset ominaisuudet:
- 150M+ residential-IP:tä 195 maassa
- YouTube-kohtaiset scraperit kanaville, videoille ja kommenteille
- Täysi selaimen renderöinti ja CAPTCHA-ratkaisu
- Maantieteellisesti kohdennettu scraping (vertailu maiden välillä)
- Hallinnoitu palveluvaihtoehto (he hoitavat ylläpidon)
- Eräajo jopa 5 000 URL:lle per pyyntö
Banien vastainen lähestymistapa: Massiivinen residential-proxy-pooli, automaattinen IP-kierto, selainjäljen emulointi ja integroitu CAPTCHA-ratkaisu. Tämä on listan vahvin estojen vastainen infrastruktuuri.
Hinnoittelu: Ilmainen kokeilu (1 000 pyyntöä yhden viikon ajan), pay-as-you-go 3,50 dollarilla per 1 000 riviä, Scale-paketti 499 dollarilla/kk sisältäen 384 000 riviä ja 2,30 dollaria per 1 000 lisäriviä.
Haitat: Ylikorkea pienille projekteille. Monimutkainen hinnoittelu (kaista + pyynnöt + IP:t voivat aiheuttaa "laskushokin", jos rajoja ei aseteta). Alusta vaatii enemmän käyttöönottoa kuin Chrome-laajennus.
Paras käyttäjille: Suuret yritykset, satoja kanavia seuraavat toimistot ja tiimit, jotka tarvitsevat maakohtaista YouTube-dataa enterprise-mittakaavassa.
4. Octoparse
Octoparse on työpöytä- ja pilviscraping-työkalu, jossa on point-and-click-visuaalinen käyttöliittymä. Rakennat YouTube-poimintatyönkulut klikkaamalla sivun elementtejä — koodia ei tarvita, mutta räätälöintiä on enemmän kuin yksinkertaisessa laajennuksessa.
Octoparsessa on valmiita YouTube-pohjia, mukaan lukien YouTube Comments & Replies Scraper, joka päivitettiin huhtikuussa 2026. Se poimii käyttäjätunnukset, kommenttitekstin, tykkäykset, julkaisuajan ja vastausketjut video-URL-osoitteista.
Keskeiset ominaisuudet:
- No-code-visuaalinen työnkulun rakentaja — klikkaa elementtejä määrittääksesi scraping-logiikan
- Valmiit YouTube-pohjat kommenteille, hakutuloksille ja videometadatalle
- Pilviajoitus automaattisella proxy-kierrätyksellä
- Vienti Exceliin, CSV:hen, JSONiin ja tietokantayhteyksiin
- Sisäänrakennettu IP-kierto ja anti-detection pilvitasoilla
Banien vastainen lähestymistapa: Pilvessä suoritettava ajo, jossa on sisäänrakennettu IP-kierto ja anti-detection-toimet. Pohjat käsittelevät ääretöntä scrollausta ja dynaamista latausta yleisillä YouTube-sivuilla.
Hinnoittelu: YouTube comments -pohja listataan 0,20 dollarilla per 1 000 riviä. Alustapaketit alkavat noin 75 dollarista/kk (Standard, laskutus vuosittain), sisältäen pilvipalvelimet, ajoituksen ja proxy-vaihtoehdot.
Haitat: Monimutkaiset YouTube-sivut (ääretön scrollaus, laiskasti ladatut kommentit, Shorts-välilehdet) voivat vaatia odotusaikojen ja scrollauskäyttäytymisen säätämistä. Transkriptien/tekstitysten poiminta on rajoitetumpaa kuin yt-dlp:llä tai erillisillä transkriptitoiminnoilla. Oppimiskäyrä on jyrkempi edistyneissä työnkuluissa.
Paras käyttäjille: Markkina-analyytikot ja liiketoimintatutkijat, jotka suosivat visuaalisia työnkulkuvälineitä mutta tarvitsevat enemmän räätälöintiä kuin Chrome-laajennus tarjoaa.
5. YT-DLP
YT-DLP (saatavilla GitHubissa) on avoimen lähdekoodin komentorivityökalu, joka poimii videometadataa, tekstityksiä, transkripteja ja muuta YouTubesta (ja yli 1 000 muulta sivustolta). Se on teknisille käyttäjille Sveitsin armeijan linkkuveitsi, kun halutaan maksimaalinen kontrolli ja nolla tilauskustannusta.
Scraping-tyyliseen käyttöön yt-dlp voi poimia metadataa lataamatta videotiedostoja käyttämällä lippuja kuten --skip-download, --write-info-json, --dump-json ja --flat-playlist. Se erottaa automaattisesti luodut ja ihmisen kirjoittamat tekstitykset — ero, jonka useimmat muut työkalut missaavat.
Keskeiset ominaisuudet:
- Poimi videometadata (otsikko, katselut, tykkäykset, latauspäivä, kuvaus, tagit) ilman videon lataamista
- Lataa kokonaiset soittolistat ja kanavat massana
- Pääsy tekstityksiin/transkripteihin (sekä automaattisesti luotuihin että ihmisen kirjoittamiin, erikseen)
- Eräajo mukautetuilla ulostulopohjilla
- Eväste-/autentikointituki istuntopohjaiseen käyttöön
- Täysin ilmainen, aktiivinen avoimen lähdekoodin yhteisö
Banien vastainen lähestymistapa: Käyttäjän evästeet autentikointiin (--cookies-from-browser), säädettävät throttlausasetukset sekä yhteisön ylläpitämät extractor-päivitykset, jotka mukautuvat YouTuben muutoksiin.
Hinnoittelu: Ilmainen.
Haitat: Vaatii komentorivitaidot. Ei visuaalista käyttöliittymää. Rikkoontuu, kun YouTube muuttuu (yhteisö korjaa nopeasti, mutta sinun täytyy silti päivittää ja selvittää ongelmat). Ei sisäänrakennettua ajoitusta tai vientiä taulukoihin — rakennat oman putkesi itse.
Paras käyttäjille: Kehittäjät, data scientistit ja tekniset tiimit, jotka tarvitsevat maksimaalista kontrollia metadata- ja transkriptipoimintaan eivätkä säikähdä terminaalikomentoja.
6. Phantombuster
Phantombuster on pilviautomaatioplatformi, jossa on YouTube-kohtaiset "Phantomit" — suunniteltu enemmän growth marketingiin ja liidien generointiin kuin puhtaaseen datavarastointiin. Se on valinta, kun tavoitteesi on löytää tekijöiden yhteystietoja ja rakentaa outreach-listoja.
Phantombusterin YouTube Channel Video Extractor poimii kanavatiedot, videolistat ja julkiset sähköpostit kanavakuvauksista. Sen virallinen rate-limit-dokumentaatio sanoo, että YouTube Channel Video Extractor tukee enintään 100 videota per käynnistys ja varoittaa, että epätavallinen toiminta voi silti laukaista YouTuben rajoitukset.
Keskeiset ominaisuudet:
- YouTube-kanavascraper (tilaajamäärä, videolista, kanavatiedot, julkiset sähköpostit)
- Video- ja kommenttien poiminta kilpailija-analyysiin
- Integraatio CRM- ja outreach-työkaluihin
- Ajoitus ja työnkulun automaatio
- 14 päivän ilmainen kokeilu, Start-paketti 56 dollarilla/kk (laskutus vuosittain, 20 h/kk suoritus)
Banien vastainen lähestymistapa: Sisäänrakennetut viiveet toimintojen välillä, phantom-selainistunnot, pilviajo rytmitetyllä automaatiolla. Suunniteltu turvallisesti rytmitettyihin työnkulkuihin eikä nopeaan massapoimintaan.
Hinnoittelu: Start-paketti 56 dollarilla/kk (vuosilaskutus), Grow 128 dollarilla/kk, Scale 352 dollarilla/kk. Hinta per 1 000 tulosta vaihtelee suoritusajan mukaan eikä per-rivi-hinnoitteluna.
Haitat: Hitaampi kuin putkipainotteiset työkalut. Hinnoittelu perustuu suoritustunteihin ja krediitteihin, ei siistiin rivikohtaiseen hintaan. Rajoitettu transkriptien/tekstitysten tuki. 100 videon per käynnistys -raja tarkoittaa, että suuret kanavat vaativat useita ajoja.
Paras käyttäjille: Growth-markkinoijat, jotka tekevät vaikuttajatutkimusta, myyntitiimit, jotka poimivat tekijöiden yhteystietoja, sekä toimistot, jotka seuraavat kilpailijoiden YouTube-toimintaa.
Kaikki YouTubesta poimittavat datatyypit (työkalu työkalulta)
Eri työkalut tukevat eri YouTube-datatyyppejä. Ennen kuin sitoudut työkaluun, sinun pitää tietää tarkalleen, mitä saat. Tässä erittely:
| Datatyyppi | Thunderbit | Apify | Bright Data | Octoparse | YT-DLP | Phantombuster |
|---|---|---|---|---|---|---|
| Videometadata (otsikko, katselut, tykkäykset, kesto, päivämäärä) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Kommentit (massana, kirjoittaja, aikaleima, tykkäykset) | ✅ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Kommenttivastaukset | ⚠️ | ✅ | ✅ | ✅ | ❌ | ⚠️ |
| Transkriptiot/tekstitykset | ⚠️ (riippuu sivusta) | ✅ | ⚠️ | ⚠️ | ✅ | ❌ |
| Automaattiset vs. manuaaliset tekstitykset (eroteltuina) | ⚠️ | ✅ | ⚠️ | ❌ | ✅ | ❌ |
| Shorts-mittarit | ✅ | ✅ | ✅ | ⚠️ | ✅ | ⚠️ |
| Kanava-analytiikka (tilaajat, kokonaiskatselut, liittymispäivä) | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Pikkukuvat/kuvat | ✅ | ✅ | ✅ | ✅ | ✅ | ✅ |
| Julkiset sähköpostit kanavakuvauksista | ✅ (jos näkyvissä) | Actor-kohtainen | ⚠️ | ⚠️ | ❌ | ✅ |
Liiketoimintakäyttötapauksen arvokkain data:
- Kommentit → tunneanalyysi, vastaväitteiden tunnistaminen, kilpailijoiden valitukset, yleisötutkimus
- Transkriptiot → LLM/RAG-putket, kilpailijaviestinnän analyysi, sisällön uudelleenkäyttö
- Kanavametadata → tekijöiden etsintä, kilpailijaseuranta, myynti-/vaikuttajaprospestointi
- Videometadata → sisältöstrategia, otsikko-/pikkukuva-analyysi, julkaisurytmi, SEO-ideointi
- Julkiset sähköpostit → tekijöiden outreach (käytä vastuullisesti ja sähköposti- sekä yksityisyyssääntöjen mukaisesti)
Parhaat YouTube-scraperit vertailussa: rinnakkainen taulukko
| Työkalu | Tyyppi | Banien vastainen lähestymistapa | Kustannus/1K tulosta | Paras käyttötapa | Asennus | Vientimuodot | Skaala |
|---|---|---|---|---|---|---|---|
| Thunderbit | AI Chrome -laajennus | Selainistunto, AI-kenttätunnistus | Ilmainen taso (6 sivua); maksullinen krediittipohjainen | No-code-kanava-/hakututkimus | Erittäin helppo | Sheets, Excel, Airtable, Notion, CSV/JSON | Pieni–keskisuuri, ajastettu |
| Apify | Pilvi-Actor-alusta | Actor-kohtainen rytmitys, proxyt, Innertube | ~5–15 $/1K (vaihtelee Actorin mukaan) | Kehittäjäputket | Keskitaso | JSON, CSV, Excel, API, webhooks | Keskisuuri–suuri |
| Bright Data | Enterprise-scraperi/proxy | 150M+ residential-IP:tä, CAPTCHA-ratkaisu | 3,50 $/1K riviä (PAYG) | Enterprise-poiminta | Keskitaso–vaikea | JSON, NDJSON, CSV, webhooks | Erittäin suuri |
| Octoparse | Visuaalinen työnkulun rakentaja | Pilvi-IP-kierto, anti-detection | ~0,20 $/1K riviä (pohja) + paketti | Visuaaliset räätälöidyt työnkulut | Keskitaso | Excel, CSV, JSON, DB | Keskisuuri |
| YT-DLP | Avoimen lähdekoodin CLI | Evästeet, throttle-asetukset, yhteisöpäivitykset | Ilmainen | Tekninen metadata-/transkriptipoiminta | Vaikea (ei-teknisille) | JSON, tekstitykset, mukautettu ulostulo | Riippuu käyttäjän asetuksista |
| Phantombuster | Pilvipohjainen growth-automaatiokalu | Sisäänrakennetut viiveet, rytmitetyt istunnot | Pakettipohjainen (56 $+/kk); ~100 videota/käynnistys | Tekijäliidit, growth-työnkulut | Helppo–keskitaso | CSV/JSON/API/CRM | Keskisuuri, rytmitetty |
Kategorian voittajat:
- Paras ei-teknisille käyttäjille: Thunderbit
- Paras kehittäjäputkiin: Apify
- Paras enterprise-mittakaavaan: Bright Data
- Paras visuaalinen rakentaja: Octoparse
- Paras ilmainen tekninen vaihtoehto: YT-DLP
- Paras growth-markkinoinnin työnkulku: Phantombuster
Ilmaiset vs. maksulliset YouTube-scraperit: milloin ilmaiset työkalut riittävät
Ilmaiset työkalut toimivat, kun tehtävä on rajattu, harvinainen ja olet valmis tekniseen ylläpitoon. Näin päätät, milloin pysyä ilmaisessa ja milloin maksaa:
| Skenaario | Paras ilmainen vaihtoehto | Milloin siirtyä maksulliseen | Miksi |
|---|---|---|---|
| Yksittäinen transkriptin lataus | YT-DLP | Tarvitset 500+ videota tai ei-teknisiä tiimikavereita | CLI-asennus ja evästeiden hallinta tuovat kitkaa |
| Nopea kilpailijakanavan tarkistus | Thunderbitin ilmainen taso (6 sivua) | Säännöllinen seuranta tai yli 10 sivua | Ajastettu scraping säästää tunteja viikossa |
| LLM-koulutusdatan rakentaminen | YT-DLP + omat skriptit | Tarvitset automaattista/manuaalista tekstityssuodatusta mittakaavassa | Apifyn erikois-Actorit hoitavat reunatapaukset |
| Yli 10 kanavan viikkoseuranta | — | Heti | Ajoitus ja skeeman uudelleenkäyttö säästävät oikeasti aikaa |
| Markkinointitiimi, joka poimii tekijäliidejä | Thunderbitin ilmainen kokeilu | Yli 10 kanavaa viikossa | Krediittipohjainen skaalaus on halvempaa kuin skriptaamiseen käytetty aika |
Rehellinen arvio: ilmaiset työkalut kuten YT-DLP ovat tehokkaita, mutta ne vaativat jatkuvaa teknistä ylläpitoa. YouTuben ulkoasun muutokset, evästeiden vanheneminen, throttlausasetukset ja ulostulomuotoilu vaativat kaikki manuaalista huomiota. Skripti, joka hajoaa kahden viikon välein, voi maksaa enemmän insinööritunteina kuin maksullinen scraper-tilaus.
AI-pohjaiset työkalut kuten Thunderbit lukevat sivut aina tuoreina ja mukautuvat ulkoasun muutoksiin automaattisesti. Tuo piilevä ylläpitokustannus on syy, miksi maksulliset työkalut ovat useimmille liiketoimintatiimeille perusteltuja.
Miltä scrapatun YouTube-datan oikeasti pitäisi näyttää (oikeita esimerkkitulosteita)
Yksi suurimmista aukoista scraper-arvosteluissa on se, että kukaan ei näytä, mitä oikeasti saat. Tässä realistisia esimerkkejä scrapatusta YouTube-tulosteesta:
Esimerkki 1: Kanavametadata
| channel_name | handle | subscribers | total_views | video_count | join_date | description_snippet | public_email |
|---|---|---|---|---|---|---|---|
| Example SaaS Tutorials | @examplesaas | 184K | 22.4M | 412 | 2018-06-14 | Viikoittaisia tuoteoppaita ja työnkulkuopastuksia | partnerships@example.com |
| Data Ops Weekly | @dataopsweekly | 92K | 8.7M | 215 | 2020-01-03 | Analytiikkaa, automaatiota ja AI-työnkulku-demoja | Ei näkyvissä |
Esimerkki 2: Kommenttivienti
| video_url | timestamp | author | comment_text | likes | reply_count |
|---|---|---|---|---|---|
| youtube.com/watch?v=abc123 | 2026-04-18 | @workflowfan | Tämä vastasi hinnoittelukysymykseen paremmin kuin toimittajan sivu. | 28 | 3 |
| youtube.com/watch?v=abc123 | 2026-04-18 | @opslead | Haluaisin jatko-osan, jossa tätä verrataan Apifyyn. | 11 | 0 |
| youtube.com/watch?v=abc123 | 2026-04-19 | @examplesaas | Hyvä huomio, testaamme sitä seuraavaksi. | 4 | 0 |
Esimerkki 3: Transkription poiminta
00:00:00.000 - 00:00:04.200 Tänään vertaamme kuutta YouTube-scraping-työnkulkua markkinoijille.
00:00:04.200 - 00:00:09.800 Suurin ero on siinä, tarvitsetko metatietoja, kommentteja vai transkripteja.
00:00:09.800 - 00:00:15.300 Ei-teknisille käyttäjille selainpohjainen scraperi on yleensä helpompi ylläpitää.
Yleisiä siivousongelmia, joita kannattaa odottaa:
- Katselumäärissä voi olla lokalisoituja päätteitä (K, M) tai ei-englanninkielisiä tunnuksia
- Latauspäivät ovat joskus suhteellisia ("3 vuotta sitten") ISO-päivämäärien sijaan
- Kommentit voivat oletuksena olla lajiteltu Topin eikä New’n mukaan
- Piilotetut vastaukset ja laiskasti ladatut kommentit vaativat scrollausta tai sivutusta
- Julkiset sähköpostikentät voivat olla piilotettuina vuorovaikutuksen tai tilirajoitusten taakse
- Transkriptiot voivat puuttua, olla automaattisesti luotuja tai olla odottamattomalla kielellä
Thunderbitin kohdalla työnkulku on: AI Suggest Fields → Scrape → Export to Google Sheets. AI hoitaa kenttätunnistuksen, joten sinun ei tarvitse määritellä käsin, miltä "views" tai "upload date" sivulla näyttää.
Onko YouTuben scraping laillista vuonna 2026?
Lyhyt vastaus: julkisesti saatavilla olevan YouTube-datan scraping on yleensä matalamman riskin toimintaa kuin yksityisen datan käsittely, mutta se ei ole mikään vapaa-for-all.
YouTuben käyttöehdot kieltävät nimenomaisesti automatisoidun käytön, paitsi julkisilta hakukoneilta, jotka noudattavat robots.txt:tä tai joilla on YouTuben etukäteen antama kirjallinen lupa. Toisaalta laillinen valvonta oikeutettua liiketoimintatutkimusta vastaan on harvinaista — YouTube kohdistaa toimensa lähinnä laajamittaiseen väärinkäyttöön, sisällön piratismiin ja yksityisyysloukkauksiin.
Yhdysvaltain oikeuskäytäntö tarjoaa jonkin verran selkeyttä. Ninth Circuitin hiQ v. LinkedIn -ratkaisu totesi, että on vakavia kysymyksiä siitä, rikkooko julkisesti saatavilla olevan datan scraping CFAA:ta. EFF on argumentoinut, että julkisten verkkosivustojen scraping ei ole rikos. Silti alustan käyttöehdot, tekijänoikeudet, yksityisyys ja anti-spam-lait ovat edelleen voimassa.
Käytännön ohjeet:
- Kerää vain julkista dataa, jota tilisi saa nähdä
- Älä scrape-ta henkilötietoja tarpeettomassa mittakaavassa
- Älä kierrä pääsynhallintaa tai maksumuureja
- Kunnioita tekijänoikeuksia — älä julkaise transkripteja tai videon sisältöä sellaisenaan uudelleen
- Rajoita pyyntöjä ja vältä YouTuben palvelimien kuormittamista
- Noudattaaksesi outreachissa CAN-SPAMia, GDPR:ää ja paikallisia sääntöjä
- Käänny lakiasiantuntijan puoleen korkean riskin käyttötapauksissa
Tämän listan työkalut sisältävät kaikki rate limitingin ja harkitun rytmityksen suunnittelussaan. Se ei ole vain hyvää etiikkaa — se on se, mikä pitää scrapingin toiminnassa pitkällä aikavälillä.
Minkä YouTube-scraperin sinun pitäisi valita?
Tässä nopea päätösopas:
- Thunderbit → Paras ei-teknisille käyttäjille, jotka haluavat nopean, banien vastaisen YouTube-scrapingin taulukoihin. Aloita tästä, jos olet markkinoija, myyjä tai sisällön strategisti.
- Apify → Paras kehittäjille, jotka rakentavat automaattisia putkia ajastetuilla ajoilla, webhooks-toiminnoilla ja API-toimituksella.
- Bright Data → Paras enterprise-mittakaavan poimintaan eri maantieteellisillä alueilla hallinnoidulla estojen vastaisella infrastruktuurilla.
- Octoparse → Paras analyytikoille, jotka haluavat visuaalisen työnkulun rakentamisen ja enemmän räätälöintiä kuin Chrome-laajennus tarjoaa.
- YT-DLP → Paras ilmainen vaihtoehto teknisille käyttäjille, jotka tarvitsevat maksimaalista kontrollia metadataan ja transkripteihin.
- Phantombuster → Paras growth-markkinoijille, jotka tekevät tekijähankintaa ja YouTube-pohjaista liidigeneraatiota.
Avain siihen, ettei tule bannatuksi, ei ole mikään yksi salainen temppu — vaan työkalun valitseminen niin, että siinä on älykäs anti-detection valmiina. Selainpohjainen istuntoscraippaus, proxy-kierto, rytmitys ja ajastetut pienet erät vähentävät kaikki riskiä. Tuhansien pyyntöjen brute force yhdestä pilvi-IP:stä on se, mikä saa sinut estetyksi.
Jos haluat nähdä, miltä moderni YouTube-scraping näyttää ilman koodia, kokeile Thunderbitin ilmaista tasoa. Kaksi klikkausta rakenteiseen dataan. Ja jos tarpeesi ovat teknisemmät tai enterprise-mittakaavaiset, muut tämän listan työkalut kattavat ne. Lisää web scraping -lähestymistavoista löydät oppaistamme parhaista automatisoiduista web scraping -työkaluista ja datan scrappaamisesta verkkosivustoilta Exceliin. Voit myös katsoa opetusvideoita Thunderbit YouTube Channelilla.
Kokeile Thunderbitia YouTube-scrapingiin Get Started Free
Usein kysytyt kysymykset
Mitä dataa YouTube-kanavasta voi scrape-ta?
Poimittavaa julkista dataa ovat videon otsikot, URL:t, pikkukuvat, katselut, tykkäykset (kun näkyvissä), latauspäivät, kuvaukset, kesto, kommentit, vastaukset, kommentoijien nimet/handle-tunnukset, kommenttien tykkäykset, transkriptiot/tekstitykset (automaattisesti luodut ja ihmisen kirjoittamat), Shorts-merkit, kanavan nimi, handle, tilaajamäärä, videomäärä, kokonaiskatselut, kuvaus, linkit ja julkiset sähköpostit, jos ne näkyvät kanavasivulla.
Kuinka monta YouTube-videota voin scrape-ta päivässä joutumatta bannatuksi?
Yleispätevää lukua ei ole. Selainpohjaiset työkalut kuten Thunderbit ovat matalamman riskin vaihtoehtoja käyttäjämäisissä työnkuluissa, koska ne toimivat oikeassa istunnossa. Phantombusterin YouTube Channel Video Extractor tukee enintään 100 videota per käynnistys. Pilvialustat, joissa on proxy-kierto, voivat käsitellä tuhansia videoita oikealla rytmityksellä. Raakapohjaiset skriptit pilvipalvelimilta ilman rate limitingiä estetään nopeasti. Turvallisin lähestymistapa on pienet, ajastetut erät yhden valtavan ajon sijaan.
Voinko scrape-ta YouTube-kommentteja tunneanalyysiin?
Kyllä. Thunderbit, Apify, Bright Data ja Octoparse tukevat kaikki kommenttien massapoimintaa kirjoittajan, aikaleiman, tykkäysten ja vastausmäärien kanssa. Vie tiedot Google Sheetsiin tai CSV:hen analyysiä varten. Apifyn YouTube-Actor tukee nimenomaisesti määritettävää enimmäismäärää kommentteja per video tätä käyttötapaa varten.
Onko olemassa ilmaista YouTube-scraperia, joka oikeasti toimii vuonna 2026?
YT-DLP on paras ilmainen vaihtoehto teknisille käyttäjille — erityisesti metadataan ja transkripteihin. Thunderbit tarjoaa ilmaisen tason ei-teknisille käyttäjille (6 sivua, kokeilubonuksella 10 sivuun), ja se vie tiedot suoraan Google Sheetsiin. Molemmat toimivat, mutta YT-DLP vaatii komentorivitaitoja, kun taas Thunderbitille riittää selain.
Miten YouTube-scraperit välttävät estot?
Eri työkalut käyttävät eri lähestymistapoja: selainpohjainen istuntoscraippaus (Thunderbit) käyttää käyttäjän todennettua selainkontekstia; residential-proxyjen kierto (Bright Data, Apify) jakaa pyynnöt miljoonien IP:iden yli; evästeautentikointi (YT-DLP) ylläpitää istuntoluottamusta; sisäänrakennetut viiveet ja rytmitys (Phantombuster) välttävät käyttäytymishavainnointia. Luotettavin lähestymistapa yhdistää oikean selainkontekstin varovaisen rytmityksen ja ajastetut pienemmät ajot.
Lue lisää




