
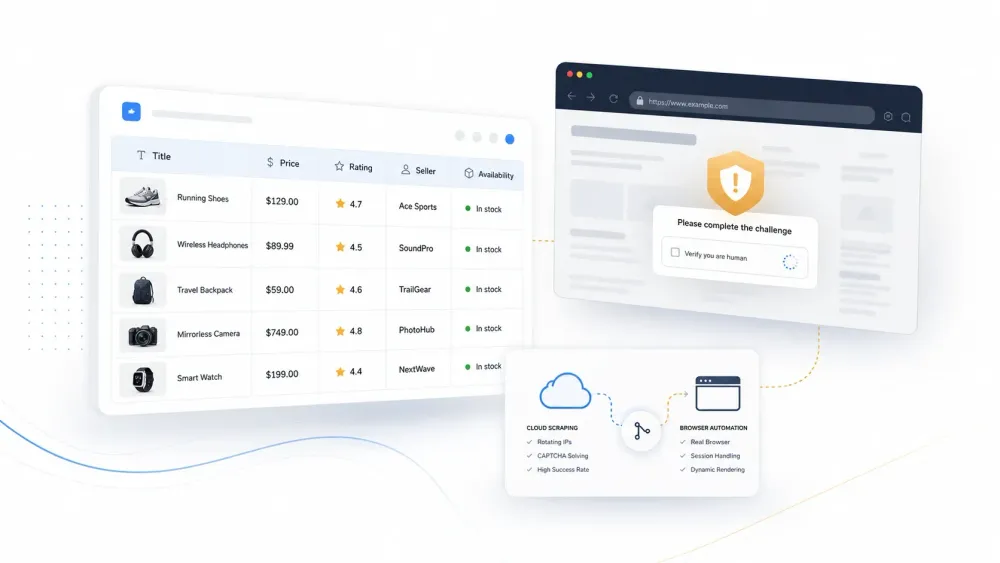
Jokainen AI web scraper näyttää tuote-esittelyssä loistavalta. Sitten osoitat sen oikealle sivustolle, jossa on Cloudflare-suojaus, ja se palauttaa challenge-sivun väittäen samalla itsevarmasti löytäneensä 47 tuotelistauksen.
Olen viettänyt viimeiset useat kuukaudet arvioiden scraping-työkaluja Thunderbitin tiimille. Ero demoissa näkyvän suorituskyvyn ja tuotantokäytön luotettavuuden välillä on jatkuvasti suurin turhautumisen lähde, jonka näen yhteisöissä. Yksi Reddit-käyttäjä tiivisti sen täydellisesti: "Mikä kestää tuotannossa ja mikä toimii vain demon ajan ennen kuin kuolee kahden viikon päästä?" Kun pelkästään web scraping -kategoriassa on 31 tuotetta Capterrassa ja lisäksi kymmeniä Chrome-laajennuksia, API-toimittajia ja actor-markkinapaikkoja, valinnan paradoksi on todellinen. Testasin siis 12 niistä.
Tässä artikkelissa arvioidaan 12 AI web scraper -työkalua tuotantovalmiuden näkökulmasta: bot-suojauksen käsittely, skaalautuvuus, rakenteellisen ulostulon laatu, kustannustehokkuus, dynaamisten sivustojen tuki ja kehittäjien joustavuus. Ei ominaisuuslistoja. Ei markkinointikuvakaappauksia. Vain se, mikä oikeasti toimii sen jälkeen, kun demo on ohi.
Katso, miltä tuotantovalmis AI Web Scraper näyttää
Miksi useimmat AI Web Scraperit epäonnistuvat demon jälkeen
Kaava on ennustettava. Työkalun markkinointisivusto näyttää sen poimivan siistit sarakkeet yksinkertaiselta tuotelistauksen sivulta. Asennat sen, kokeilet suojatulla verkkokauppasivustolla, ja saat jonkin näistä:
200 OK-vastauksen, joka sisältää Cloudflare-challenge-sivun oikean datan sijaan- Siistit tulokset ensimmäisiltä 5 sivulta, ja sen jälkeen hiljaisia virheitä tai keksittyjä rivejä
- Täydellinen poiminta tänään, mutta rikkoutuneet selectorit ensi viikolla pienen asettelumuutoksen jälkeen
Nämä eivät ole reunatapauksia. Ne ovat normaali tila.
Kuten yksi tekijä sanoi Redditissä: "Scraper palauttaa 200-vastauksen Cloudflare-challenge-sivulla, agenttisi yrittää järkeillä sen yli, hallusinoi, eikä sinulla ole aavistustakaan miksi."
Juuri ongelman ydin on arkkitehtuurissa. Useimmat demot esittelevät parsimiskerrosta puhtailla julkisilla sivuilla, kun taas oikea työ epäonnistuu hakukerroksessa. Tuotantosivustot lisäävät bot-suojauksen, dynaamisen renderöinnin, sisäkkäiset detail-sivut, loputtoman scrollauksen, kirjautumistilan, kieli- ja aluekohtaiset vaihtelut sekä muuttuvat asettelut.
Työkalu voi näyttää upealta tuote-esittelyssä ja silti romahtaa jo ensimmäisessä oikeassa asiakasprosessissa.
Siksi arvioin jokaisen työkalun tuotantovalmiuden näkökulmasta enkä ominaisuuslistan perusteella. Käyttämäni kuusi kriteeriä:
| Kriteeri | Miksi sillä on merkitystä |
|---|---|
| Bot-suojauksen/CAPTCHA:n käsittely | Suojatut sivut epäonnistuvat ennen kuin poiminnan laatu edes ehtii merkitä |
| Skaalautuvuus demon ohi | Eräajot ja rinnakkaiset ajot paljastavat toiminnalliset rajat |
| Rakenteellisen ulostulon laatu | Käyttäjät tarvitsevat siistiä JSONia/CSV:tä, eivät raakaa HTML:ää, joka vaatii manuaalista siivousta |
| Token-/kustannustehokkuus | AI-poiminnasta voi tulla kalliimpaa kuin itse scrapingista |
| Dynaamisten/JS-painotteisten sivustojen tuki | Nykyaikaiset sivut tarvitsevat renderöidyn DOMin, eivät staattista HTML:ää |
| No-code vs. API-joustavuus | Myyntitiimeillä ja data-insinööreillä on erilaiset tarpeet |
Jos haluat nopean markkinatason katsauksen siihen, miten web scraping muuttui viimeisen kahden vuoden aikana, tämä Browserlessin puhe on hyvä lähtökohta ennen kuin vertaat työkaluja yksi kerrallaan.
Missä AI oikeasti auttaa scraping-putkessa (ja missä ei)
Tällä markkinalla elää sitkeä myytti, että "AI web scraper" tarkoittaa, että AI hoitaa kaiken alusta loppuun. Yhteisön konsensus on poikkeuksellisen selvä: scraper ensin, LLM toisena. Yhden käyttäjän suorasukainen näkemys: "Käytät AI:ta lukemaan verkkosivun kuvakaappausta. Et käytä AI:ta kirjoittamaan itse scraperia."
Scraping-putkessa on kolme eri kerrosta, ja AI:n arvo vaihtelee niissä valtavasti:
Crawling ja fetching: infrastruktuurikerros
Tässä tapahtuvat pyynnöt: proxyt, headless-selaimet, sessionhallinta, CAPTCHA:n ratkaisu, uudelleenyritykset. AI ei tee tässä juuri mitään hyödyllistä. Tarvitset edelleen proxy-poolit, selaimen fingerprinting-suojauksen ja unblocking-infrastruktuurin. Juuri tässä useimmat työkalut kaatuvat ensimmäisenä tuotannossa.
Parsinta ja poiminta: AI loistaa tässä
Kun sinulla on siisti sivusisältö, AI on erinomainen muuttamaan jäsentymättömän HTML:n rakenteellisiksi kentiksi. Skeemaan perustuva poiminta, mukautuva kenttien tunnistus ja asettelumuutosten käsittely ilman hauraiden XPath-selectorien käyttöä ovat AI:n vahvinta aluetta scrapingissa.
Jälkikäsittely: luokittelu, kääntäminen, kategorisointi
Poiminnan jälkeen AI tuo arvoa luokittelemalla tuotteita, kääntämällä tekstiä, normalisoimalla puhelinnumeroita tai tiivistämällä kuvauksia. Tämä sopii hyvin, mutta vain jos poimittu data on jo valmiiksi oikein.
Näin 12 työkalua sijoittuvat näiden kerrosten mukaan:
| Työkalu | Crawling/fetching | Parsinta/poiminta | Jälkikäsittely | Paras kuvaus |
|---|---|---|---|---|
| Thunderbit | Vahva | Vahva | Vahva | Täyden pinon no-code AI scraper |
| Octoparse | Vahva | Keskitaso | Matala | Sääntöpohjainen visuaalinen scraper pilvi-infrastruktuurilla |
| Browse AI | Keskitaso | Keskitaso | Keskitaso | Valvontaan painottuva pilvirobotti-alusta |
| Firecrawl | Keskitaso | Vahva | Matala-keskitaso | Kehittäjien poiminta-API |
| Apify | Vahva | Keskitaso-vahva | Keskitaso | Actor-markkinapaikka ja orkestrointi |
| Gumloop | Keskitaso | Keskitaso | Vahva | Työnkulkuautomaatio scraper-nodeilla |
| Bright Data | Erittäin vahva | Keskitaso | Matala-keskitaso | Yritystason infrastruktuuripino |
| Bardeen | Keskitaso | Keskitaso | Vahva | Selainautomaatio GTM-työnkulkuihin |
| Diffbot | Matala-keskitaso | Erittäin vahva | Keskitaso | Esikoulutettu poiminta ja knowledge graph |
| ScrapingBee | Vahva | Matala-keskitaso | Matala | Fetching- ja unblocking-API |
| Instant Data Scraper | Matala | Keskitaso (yksinkertaiset sivut) | Matala | Heuristinen selaimen sisäinen nopea scraper |
| ParseHub | Keskitaso | Keskitaso | Matala | Työpöydän visuaalinen scraper monimutkaisiin vuorovaikutuksiin |
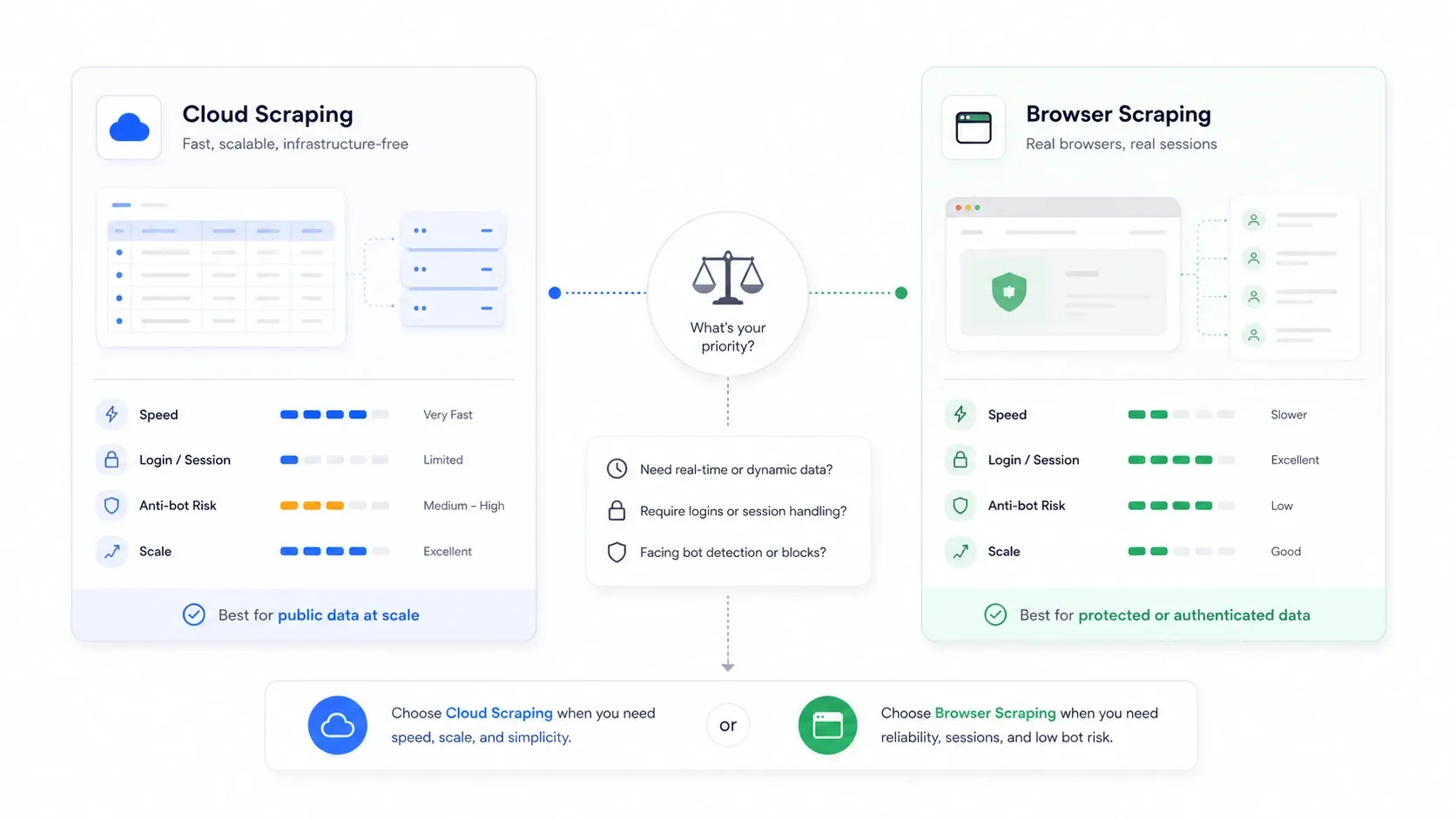
Cloud scraping vs. browser scraping: valinta, jota kukaan ei selitä
Tämä on arkkitehtuuripäätös, jonka useimmat vertailuartikkelit ohittavat täysin, ja se on usein tärkeämpi kuin se, minkä työkalun valitset.
Cloud scraping tarkoittaa, että etäpalvelimet hakevat sivut puolestasi. Browser scraping tarkoittaa, että poiminta tapahtuu omassa selainistunnossasi, käyttäen omia evästeitäsi, IP-osoitettasi ja kirjautunutta tilaasi.
| Tilanne | Parempi tila | Miksi |
|---|---|---|
| Julkiset verkkokauppa- ja listaussivustot suurina määrinä | Cloud | Nopeampi rinnakkaisuus eikä paikallisen koneen pullonkaulaa |
| Sivustot, jotka vaativat kirjautumisen tai tunnistautumisen | Browser | Käyttää uudelleen oikeita istuntoevästeitäsi |
| Sivustot, jotka rankaisevat datakeskus-IP-osoitteita | Browser | Näyttää tavalliselta käyttäjäliikenteeltä |
| Suuret toistuvat valvontatyöt | Cloud | Helpompi aikataulutus ja jatkuvuus |
| Kertaluonteiset, herkät ja bot-suojaukselle alttiit työt | Browser | Helpompi nähdä, mitä sivu oikeasti renderöi |
Tällä on myös taloudellinen merkitys. Apifyn vuoden 2026 State of Web Scraping -raportin mukaan 65,8 % tekijöistä lisäsi proxyjen käyttöä vuodentakaiseen verrattuna, ja 62 %+ raportoi infrastruktuurikulujen kasvaneen. Bot-suojaus ei ole vain tekninen ongelma. Se on budjettiongelma.
Useimmat työkalut tarjoavat vain toisen tilan. Tässä erittely:
| Työkalu | Cloud | Browser | Molemmat |
|---|---|---|---|
| Thunderbit | ✅ | ✅ | ✅ |
| Octoparse | ✅ | ✅ (local) | ✅ |
| Browse AI | ✅ | Vain käyttöönotto | — |
| Firecrawl | ✅ | API interaktiiviseen käyttöön | — |
| Apify | ✅ | ✅ (actorien kautta) | ✅ |
| Gumloop | ✅ | ✅ (Web Agent) | ✅ |
| Bright Data | ✅ | ✅ | ✅ |
| Bardeen | Rajoitettu (julkiset sivut) | ✅ | Osittain |
| Diffbot | ✅ | — | — |
| ScrapingBee | ✅ | — | — |
| Instant Data Scraper | — | ✅ | — |
| ParseHub | ✅ (maksullinen) | ✅ (desktop) | ✅ |
12 AI Web Scraperia yhdellä silmäyksellä
Tässä on kokovertailu kaikista 12 työkalusta:
| Työkalu | Paras käyttö | Ilmainen taso | Cloud/Browser | API-käyttö | Ajoitettu scraping | Bot-suojauksen käsittely |
|---|---|---|---|---|---|---|
| Thunderbit | Ei-tekniset tiimit | ✅ (6 sivua) | Molemmat | ✅ | ✅ | Vahva |
| Octoparse | Template-painotteinen scraping | ✅ (rajoitettu) | Molemmat | ✅ | ✅ | Kohtalainen-vahva |
| Browse AI | Muutosten valvonta | ✅ (rajoitettu) | Pääosin cloud | ✅ | ✅ | Kohtalainen |
| Firecrawl | Kehittäjien poimintaputket | ✅ (1 000 krediittiä/kk) | Cloud + browser API | ✅ | Ei | Kohtalainen |
| Apify | Kehittäjätiimit + markkinapaikka | ✅ (5 $ ilmaiskäyttö) | Molemmat | ✅ | ✅ | Vahva lisäosilla |
| Gumloop | Työnkulkuautomaatio | ✅ (5 000 krediittiä/kk) | Molemmat | ✅ | ✅ | Keskitaso |
| Bright Data | Yritystason datan saatavuus | Kokeilu / krediitit | Molemmat | ✅ | Ulkoinen | Erittäin vahva |
| Bardeen | Myynti- ja ops-selaimiautomaatio | ✅ (100 krediittiä) | Browser-first | Rajoitettu | ✅ | Keskitaso-matala |
| Diffbot | Rakenteellisen poiminnan API:t | ✅ (10 000 krediittiä) | Cloud | ✅ | Ei | Matala hakupuolella / korkea poiminnassa |
| ScrapingBee | Kehittäjien fetching ja unblocking | ✅ (1 000 krediittiä) | Cloud | ✅ | Ei | Vahva |
| Instant Data Scraper | Ilmaiset kertaluonteiset scrapet | ✅ (täysin ilmainen) | Vain browser | Ei | Ei | Matala |
| ParseHub | Monimutkaiset visuaaliset työnkulut | ✅ (5 projektia) | Desktop + cloud | ✅ | ✅ (maksullinen) | Keskitaso |
Ymmärrä, miten AI-poiminta sopii oikeaan scraping-putkeen
1. Thunderbit
Thunderbit on AI web scraper, jonka rakensimme erityisesti ei-teknisille tiimeille, jotka tarvitsevat tuotantotasoista dataa ilman koodausta tai infrastruktuurin hallintaa. Ydintyönkulku on aidosti kahden klikin mittainen: AI Suggest Fields lukee sivun ja ehdottaa sarakkeita, ja sitten Scrape suorittaa poiminnan cloud- tai browser-tilassa.
Mikä tekee siitä erilaisen muihin no-code scrappereihin verrattuna, on arkkitehtuuri. Thunderbit erottaa crawling-asiat, kuten pilvi-infrastruktuurin, proxy-vaihdon, bot-suojauksen käsittelyn ja JavaScript-renderöinnin, AI-poiminnasta, joka lukee HTML:n ja tuottaa rakenteelliset sarakkeet. Tämä vastaa asiantuntijoiden suosittelemaa "scraper ensin, LLM toisena" -mallia, mutta Chrome-laajennuksen muodossa, jota myyntiedustajat ja operatiiviset tiimit voivat oikeasti käyttää.
Keskeiset vahvuudet
- Sekä cloud- että browser scraping samassa käyttöliittymässä. Vaihda tilojen välillä sen mukaan, onko kohdesivusto julkinen vai vaatiiko se kirjautuneen istuntosi. Cloud-tila käsittelee jopa 50 sivua rinnakkain.
- AI lukee sivurakenteen uudelleen joka kerta. Ei XPathin ylläpitoa. Kun sivusto päivittää asettelunsa, Thunderbit mukautuu automaattisesti seuraavalla ajokerralla.
- Alasivujen scraping. AI vierailee linkitetyillä detail-sivuilla ja rikastaa päätietotaulukkoa ilman manuaalista määritystä.
- Field AI Prompts. Mukautettu luokittelu, kääntäminen ja kategorisointi poiminnan aikana erillisenä jälkikäsittelyvaiheena sijaan.
- Ilmaiset viennit Google Sheetsiin, Exceliin, Airtableen ja Notioniin.
- Välittömät scraper-templatet suosituilla sivustoilla, kuten Amazon, Zillow ja LinkedIn.
- Luonnollisen kielen aikataulutus. Kerro sille "scrape every Monday at 9am", ja se muuntaa sen toistuvaksi aikatauluksi.
- Avoin API Distill- ja Extract-päätepisteillä, eräkäsittely jopa 100 URL-osoitteelle sekä julkaistu rinnakkaisuus 2:sta ilmaisella tasolla 50:een Pro 1:ssä.
Missä sitä voisi parantaa
- Ilmainen taso on tarkoituksella pieni.
- Chrome-laajennuskeskeinen no-code-kokemus. Kehittäjien, jotka haluavat vain API-pohjaisia työnkulkuja, on käytettävä Open API:a erikseen.
- Ei oikea työkalu, jos pääasiallinen tarpeesi on pelkkä proxy-infrastruktuuri ilman poimintaa.
Hinnoittelu
Ilmainen taso saatavilla. No-code-paketit alkavat 9 $/kk vuosilaskutuksella tai 15 $/kk kuukausilaskutuksella Starterille. API-hinnoittelu on erikseen: kerran ilmaiseksi 600 yksikköä, sitten 16 $/kk vuosilaskutuksella Starter API:lle ja 40 $/kk vuosilaskutuksella Pro 1 API:lle. Katso Thunderbit Pricing ja API Pricing.
Paras käyttö: Myynti-, verkkokauppa- ja operatiiviset tiimit, jotka tarvitsevat rakenteellista verkkodataa ilman insinööritukea.
2. Octoparse
Octoparse on visuaalinen työnkulkurakentaja web scrapingiin, ja sillä on laaja valikoima valmiita templateja. Se on ollut markkinoilla tarpeeksi kauan, jotta sillä on kypsä pilvi-infrastruktuuri, ja se käsittelee sivutusta hyvin rakenteellisilla ja ennustettavilla verkkosivustoilla.
Keskeiset vahvuudet
- Laaja valikoima valmiita scraping-templateja suosituista sivustoista
- Cloud-poiminta ajoitetuilla ajoilla
- IP-vaihto ja CAPTCHA:n ratkaisu maksullisina lisäosina
- API-käyttö korkeammilla paketeilla
Missä sitä voisi parantaa
- AI-ominaisuudet ovat kevyempiä kuin LLM-natiivissa työkaluissa. Kenttäsuositukset nojaavat yhä enemmän templateihin kuin mukautuvaan lukemiseen.
- Monimutkaiset tai poikkeavat asettelut vaativat paljon manuaalista hienosäätöä visuaalisessa editorissa.
- Oppimiskäyrä jyrkkenee, kun tarvitset ehtologiikkaa tai estoja kiertäviä ratkaisuja.
Hinnoittelu
Saatavilla on ikuisesti ilmainen suunnitelma. Virallinen tukikeskuksen hinnoittelu viittaa tällä hetkellä Standard-pakettiin alkaen 75 $/kk vuosittain ja Professional-pakettiin alkaen 208 $/kk vuosittain, vaikka joillakin lokalisoiduilla sivuilla ja päivityspoluilla näkyy korkeampia kuukausivastaavia hintoja. Olennaista on, että Octoparsen hinnoittelu yhdistää nyt tilauspaketteja ja maksullisia lisäosia, kuten residential proxyt ja CAPTCHA:n ratkaisun.
Paras käyttö: Analyytikot ja ops-tiimit, jotka scrapaavat rakenteellisia, template-ystävällisiä sivustoja kohtuullisessa mittakaavassa.
3. Browse AI
Browse AI on pilvipohjainen no-code-alusta, joka on rakennettu ensisijaisesti verkkosivujen muutosten valvontaan ajan kuluessa, kuten kilpailijoiden hinnoitteluun, varastotilanteeseen ja sisältöpäivityksiin. Scraping on osa tuotetta, mutta todellinen erottautumistekijä on toistuva seuranta- ja hälytysjärjestelmä.
Keskeiset vahvuudet
- Sisäänrakennettu muutosten tunnistus ja hälytykset
- No-code-robotti, jonka voi ottaa käyttöön klikkaamalla kohtaa sivulla
- Valmiita botteja suosittuihin sivustoihin
- Premium-proxy-tuki korkeammilla paketeilla
Missä sitä voisi parantaa
- Krediittipohjainen hinnoittelu kallistuu nopeasti, kun detail-sivuja valvotaan laajassa mittakaavassa
- Vähemmän vakuuttava suurten kertaluonteisten poimintojen työkaluna kuin API-first-ratkaisut
- Kohtalainen bot-suojauksen käsittely; jotkin sivustot vaativat yhä premium-proxyja tai kiertotapoja
Hinnoittelu
Ilmainen tili saatavilla. Maksulliset paketit alkavat noin 19 $/kk vuosilaskutuksella Starterille, ja sen yläpuolella on korkeampia krediitti- ja valvontatasoja.
Paras käyttö: Tiimit, jotka tarvitsevat jatkuvaa kilpailijahintojen, sisältömuutosten tai varastotasojen seurantaa yhden kertaluonteisen massapoiminnan sijaan.
4. Firecrawl
Firecrawl on kehittäjäystävällinen API, joka muuntaa verkkosivut siistiksi Markdowniksi tai rakenteelliseksi JSONiksi. Se sijoittuu pääosin poimintakerrokseen ja on erinomainen tiimeille, jotka rakentavat RAG-putkia tai syöttävät verkkosisältöä LLM-malleihin.
Keskeiset vahvuudet
- Erinomainen Markdown-ulostulon laatu jatko-LLM-työnkulkuja varten
- Siisti API, jossa on scrape, crawl, map, search, extract ja browser actions
- Eräkäsittelyn tuki
- Rinnakkaisuus 2:sta ilmaisella tasolla 100:aan Growthissa
Missä sitä voisi parantaa
- Ei no-code-käyttöliittymää ja vaatii kehittäjäosaamista
- Sisäänrakennettua proxy- ja bot-suojausapua on olemassa, mutta Firecrawl ei asemoidu omaksi unblocking-toimittajakseen
- Ei ensimmäisen osapuolen ajastinta toistuviin ajoihin
- Ei kustannustehokas ei-kehittäjille, jotka haluavat vain taulukon datasta
Hinnoittelu
Ilmainen suunnitelma sisältää 1 000 krediittiä kuukaudessa. Maksulliset paketit alkavat 16 $/kk vuosilaskutuksella Hobby-paketissa ja skaalautuvat suuremmilla krediiteillä, rinnakkaisuudella ja selaimen käytöllä. Selainistunnot laskutetaan erikseen krediiteissä.
Paras käyttö: Kehittäjät, jotka rakentavat LLM-putkia, RAG-järjestelmiä tai räätälöityjä poimintatyönkulkuja ja tarvitsevat siistiä Markdownia tai JSONia verkkosivuilta.
5. Apify
Apify on alusta, jossa on markkinapaikka valmiille scraping-actoreille sekä työkalut omien rakentamiseen. Ajattele sitä orkestrointikerroksena, jossa valitset tai rakennat erikoistuneita scrappereita tiettyihin sivustoihin ja ajastat sekä hallitset niitä yhtenäisen API:n kautta.
Keskeiset vahvuudet
- Laaja actor-markkinapaikka yhteisön rakentamille scrappereille sadoille sivustoille
- Vahva API ja SDK kehittäjille
- Sisäänrakennettu proxyjen hallinta ja aikataulutus
- Integroituu moniin jatkotyökaluihin
Missä sitä voisi parantaa
- "No-code" on vain osittain totta, kun poistut markkinapaikasta ja tarvitset omaa logiikkaa
- Actorien luotettavuus riippuu yhteisön ylläpidosta
- Hinnoittelu voi kasvaa, koska compute-, actor- ja proxy-kulut kasautuvat
Hinnoittelu
Ilmainen taso sisältää 5 $ kuukausittaista platform-krediittiä. Maksulliset paketit alkavat 39 $/kk Starterille, ja skaalaukseen tarkoitetut tasot ovat tämän yläpuolella.
Paras käyttö: Kehittäjätiimit, jotka haluavat uudelleenkäytettäviä, ajastettavia scraping-työnkulkuja suurella valmiiden ratkaisujen ekosysteemillä.
6. Gumloop
Gumloop on no-code-työnkulkuautomaation alusta, joka sisältää web scraping -noden. Todellinen arvo ei ole pelkässä scrapingissa. Se on poiminnan yhdistäminen LLM-malleihin, Google Sheetsiin, CRM-järjestelmiin ja muihin työkaluihin yhdessä visuaalisessa kanvaasissa.
Keskeiset vahvuudet
- Visuaalinen drag-and-drop-työnkulkurakentaja
- Yhdistää scrapingin LLM-malleihin ja liiketoimintatyökaluihin yhdessä virrassa
- Ilmainen suunnitelma, jota mainostetaan tällä hetkellä 5 000 krediitillä/kk
- Aikaperusteinen aikataulutus toistuville työnkuluille
- Perusscraping ja interaktiivinen Web Agent -tila kattavat sekä yksinkertaiset että rikkaammat työnkulut
Missä sitä voisi parantaa
- Scraping-moottori on vähemmän vankka kuin erikoistuneet AI web scraper -työkalut
- Rajallinen bot-suojauksen ja proxyjen syvyys verrattuna erikoistoimittajiin
- Rinnakkaisuus- ja trigger-rajoitukset ovat tiukemmat ilmaisilla paketeilla
- Ei ihanteellinen suurten volyymien scrapingiin ensisijaisena käyttötapauksena
Hinnoittelu
Ilmainen suunnitelma saatavilla. Gumloop yhdisti vanhat Solo- ja Team-rakenteensa Pro-paketiksi loppuvuonna 2025, ja julkinen viestintä keskittyy sen jälkeen avokätisempiin ilmaiskrediitteihin ja yhdistettyihin maksullisiin tasoihin scraper-ensimmäisen hinnoittelun sijaan.
Paras käyttö: Tiimit, jotka haluavat scrapingin yhdeksi vaiheeksi laajemmassa automaatiotyönkulussa: scrape, analysoi ja siirrä liiketoimintatyökaluihin.
Jos haluat nähdä, miltä AI-natiivi poimintatyönkulku tuntuu käytännössä ennen kuin luet loppulistan, tämä Thunderbitin läpikäynti on osuvin tuotedemo ei-teknisille tiimeille.
7. Bright Data
Bright Data on tämän listan yritystason infrastruktuuripino. Jos ongelmasi on "en pääse tämän sivuston bot-suojauksen läpi, mitä tahansa yritänkin", Bright Data on todennäköisesti vastaus, mutta se tulee yritystason monimutkaisuuden ja hinnoittelun kanssa.
Keskeiset vahvuudet
- Alan johtava proxyverkko residential-, datacenter- ja mobile-IP-osoitteiden välillä
- Web Unlocker bot-suojauksen ja CAPTCHA:n kiertämiseen
- Scraping Browser sisäänrakennetulla unblockingilla
- Valmiiksi kerättyjä datasettejä ostettavissa
- Täysi ohjelmallinen hallinta API:n ja SDK:n kautta
Missä sitä voisi parantaa
- Ei suunniteltu ei-teknisille käyttäjille
- Hinnoittelu heijastaa yritysasemointia
- AI-poiminta ei ole alustan ostamisen pääsyy
Hinnoittelu
Browser API alkaa 8 $/GB pay as you go -hinnoittelulla, ja suuremmilla kuukausisitoumuksilla per-GB-hinnat laskevat. Muilla Bright Datan tuotteilla, kuten Unlockerilla, Scraper API:lla, dataseteillä ja proxy-poolilla, on omat hinnoitteluyksikkönsä.
Paras käyttö: Yritysten data-tiimit, joiden täytyy scrapata vahvasti suojattuja sivustoja laajassa mittakaavassa ja joilla on teknistä henkilökuntaa infrastruktuurin hallintaan.
8. Bardeen
Bardeen on selainautomaatio-työkalu, joka keskittyy klikkauksiin, lomakkeiden täyttämiseen ja scrapingiin AI-pohjaisen datapoiminnan kanssa. Sitä on parasta pitää GTM-työnkulkutyökaluna, joka sattuu myös scrapaamaan, eikä scraping-työkaluna, joka sattuu tekemään GTM:ää.
Keskeiset vahvuudet
- Intuitiivinen playbook-tyylinen automaatio, jossa scraping on yksi vaihe
- Bardeenin tiimin ylläpitämiä virallisia scrappereita suosittuihin sivustoihin
- Vahvat integraatiot CRM:ään, Google Sheetsiin, Slackiin ja muihin liiketoimintatyökaluihin
- Hyvä lead-scrapingiin, enrichmentiin ja CRM-vientiä varten rakennettuihin työnkulkuihin
Missä sitä voisi parantaa
- Browser-first-arkkitehtuuri rajoittaa suurivolyymista valvomatta ajettavaa scrapingia
- Cloud scraping toimii vain julkisilla sivuilla, ei suojatuilla
- Bot-suojauksen käsittely on pääosin sitä, mitä selainistuntosi jo valmiiksi tarjoaa
- AI-poiminta voi takellella monimutkaisissa tai epästandardeissa sivuasetteluissa
Hinnoittelu
Ilmainen suunnitelma sisältää 100 kuukausittaista krediittiä. Julkinen tukidokumentaatio viittaa vanhaan 15 $/kk Pro -hinnoitteluun olemassa oleville käyttäjille, kun taas nykyinen Bardeenin kaupallinen paketoituminen on enemmän yritys- ja työnkulkuorientoitunutta kuin perinteistä edullista scraper-hinnoittelua.
Paras käyttö: Myynti- ja ops-tiimit, jotka tarvitsevat scrapingia osana laajempaa selainautomaatio-työnkulkua.
9. Diffbot
Diffbot käyttää tietokonenäköä ja NLP:tä lukeakseen verkkosivuja kuin ihminen ja tuottaa rakenteellista dataa artikkeleista, tuotteista, keskusteluista ja organisaatioista. Se on yksi laadukkaimmista saatavilla olevista poiminta-API:sta, jos sivusi sopivat sen esikoulutettuihin malleihin.
Keskeiset vahvuudet
- Esikoulutetut poimintamallit artikkeleille, tuotteille, keskusteluille ja muulle
- Knowledge Graph, jossa on miljardeja entiteettejä datan rikastamiseen
- Vahva rakenteellisen ulostulon laatu tuetuilla sivutyypeillä
- Selkeä kehittäjä-API, jossa on julkaistut rate limitit
Missä sitä voisi parantaa
- Ei no-code-käyttöliittymää
- Ei sisäänrakennettua crawlingia, proxyjen hallintaa tai bot-suojauksen käsittelyä
- Kallis pienille tiimeille
- Vähemmän joustava epästandardien sivutyyppien kanssa kuin skeemapromptiin perustuvat extractorit
Hinnoittelu
Ilmainen suunnitelma sisältää 10 000 krediittiä. Startup on 299 $/kk 250 000 krediitille, ja Plus on 899 $/kk 1 000 000 krediitille.
Paras käyttö: Kehittäjätiimit, jotka tarvitsevat erittäin tarkkaa rakenteellista poimintaa standardeista sivutyypeistä ja ovat valmiita hoitamaan hakupuolen erikseen.
10. ScrapingBee
ScrapingBee on web scraping -API, joka keskittyy fetching- ja unblocking-kerrokseen. Lähetät sille URL-osoitteen, se hoitaa proxyt, headless-selaimen renderöinnin ja bot-suojauksen, ja palauttaa HTML:n tai valinnaisesti poimitun datan.
Keskeiset vahvuudet
- Sisäänrakennettu proxyjen vaihto ja bot-suojauksen käsittely
- JavaScript-renderöinnin tuki
- Yksinkertainen REST API
- Google Search -scraping-päätepiste
- Julkaistu rinnakkaisuus paketin mukaan
Missä sitä voisi parantaa
- AI-poimintaominaisuudet ovat rajalliset
- Ei no-code-käyttöliittymää
- Ei sisäänrakennettua aikataulutusta tai seurantaa
200-vastaus eston sisältävällä sivulla voi silti laskea onnistuneeksi pyynnöksi
Hinnoittelu
Ilmainen suunnitelma sisältää 1 000 API-krediittiä. Maksulliset paketit alkavat 49 $/kk ja skaalautuvat suuremmalla rinnakkaisuudella ja pyyntömäärällä.
Paras käyttö: Kehittäjät, jotka tarvitsevat ensisijaisesti luotettavaa sivujen hakua bot-suojauksen ohi ja hoitavat poiminnan omalla koodilla tai erillisellä työkalulla.
11. Instant Data Scraper
Instant Data Scraper on ilmainen Chrome-laajennus, jolla on yli 1 000 000 käyttäjää. Se tunnistaa automaattisesti sivun datamallit ja antaa viedä tulokset CSV- tai Excel-muotoon. LLM-tyylisiä AI-kenttäehdotuksia ei ole. Se käyttää heuristista mallintunnistusta.
Keskeiset vahvuudet
- Täysin ilmainen, ei tiliä vaadita
- Yhden klikin datan tunnistus monilla listaus- ja taulukkosivuilla
- Käsittelee sivutusta joillakin sivustoilla
- Erittäin matala aloituskynnys
- Yhä ylläpidetty, Chrome Web Storen päivityksiä vuonna 2026
Missä sitä voisi parantaa
- Ei AI-pohjaista kenttäsuositusta tai datan luokittelua
- Ei cloud scrapingia, aikataulutusta tai API:a
- Taistelee monimutkaisten asettelujen, dynaamisen sisällön ja JS-painotteisten sivustojen kanssa
- Ei bot-suojauksen käsittelyä sen enempää kuin selain muutenkaan pystyy lataamaan
- Vienti rajoittuu CSV:hen ja Exceliin
Hinnoittelu
Ilmainen. Ikuisesti.
Paras käyttö: Kenelle tahansa, joka tarvitsee nopean kertaluonteisen scrapen yksinkertaiselta listaussivulta eikä halua tehdä tiliä tai maksaa mitään.
12. ParseHub
ParseHub on työpöytäsovellus, jossa on visuaalinen point-and-click-käyttöliittymä scraping-projektien rakentamiseen. Se pystyy käsittelemään monimutkaista sisäkkäistä dataa, AJAXilla ladattua sisältöä, loputonta scrollausta ja pudotusvalikkovuorovaikutuksia, jotka yksinkertaisemmat laajennukset usein missaavat.
Keskeiset vahvuudet
- Visuaalinen selector-käyttöliittymä poimintasääntöjen määrittämiseen
- Käsittelee sisäkkäistä dataa, pudotusvalikoita, loputonta scrollausta ja AJAX-sisältöä
- Ilmainen taso jopa 5 projektille
- Vienti JSON-, CSV- ja Excel-muotoon
- Cloud-aikataulutus ja IP-vaihto maksullisilla paketeilla
Missä sitä voisi parantaa
- Vain desktop-työnkulku, ei selainlaajennuksen mukavuutta
- Hitaampi suorituskyky kuin cloud-natiiveilla työkaluilla
- Projektit rikkoutuvat, kun sivuston asettelu muuttuu, koska AI-lukekerrosta ei ole
- Rajalliset AI-ominaisuudet ja enemmän vanhan koulukunnan visuaalisen scraperin tuntu
Hinnoittelu
Ilmainen suunnitelma saatavilla, sisältää 5 projektia ja 200 sivua ajoa kohden. Maksulliset paketit alkavat 189 $/kk ja sisältävät aikataulutuksen, IP-vaihdon ja suuremmat rajat.
Paras käyttö: Ei-tekniset käyttäjät, joiden täytyy scrapata monimutkaisia interaktiivisia sivustoja ja jotka ovat valmiita käyttämään aikaa visuaalisen työnkulun rakentamiseen.
Näin aloitat AI Web Scraperin käytön 5 vaiheessa
Jokaisella tämän listan työkalulla on erilainen käyttöönotto. Käytän konkreettisena esimerkkinä Thunderbitia, koska se vastaa parhaiten hakutarkoitusta "tarvitsen tämän vain toimimaan oikealla sivulla".
Vaihe 1: Asenna ja siirry sivulle
Asenna Thunderbit Chrome Extension ja siirry sivulle, jonka haluat scrapata: tuotelistaukseen, hakemistoon tai kiinteistöportaaliin.
Vaihe 2: Anna AI:n ehdottaa datakentät
Klikkaa AI Suggest Fields. AI lukee nykyisen sivun ja ehdottaa sarakenimiä sekä tietotyyppejä. Tuotesivulla se voi ehdottaa esimerkiksi tuotteen nimeä, hintaa, arvosanaa, kuvan URL-osoitetta ja kuvausta.
Vaihe 3: Mukauta kenttiä AI-prompteilla
Säädä sarakkeita, jos oletukset eivät ole aivan kohdallaan. Lisää Field AI Prompts mukautettuja muunnoksia varten, kuten "käännä kuvaus espanjaksi", "luokittele kategoriat Electronics, Home tai Fashion" tai "poimi vain numeerinen hinta".
Vaihe 4: Valitse cloud- tai browser-tila ja scrapea
Valitse cloud scraping julkisille sivuille tai browser scraping kirjautuneille tai vahvasti suojatuille kohteille. Klikkaa sitten Scrape.
Vaihe 5: Vie data minne tahansa
Vie tulokset Google Sheetiin, Exceliin, Airtableen tai Notioniin. Viennit ovat ilmaisia.
Entä jos sivun asettelu muuttuu?
Tämä on AI-natiivien extractorien keskeinen tuotantoetu sääntöpohjaisiin työkaluihin verrattuna. Perinteiset scrapperit, kuten ParseHub ja vanhemmat Octoparse-työnkulut, nojaavat XPath-selectoreihin tai CSS-polkuihin. Kun sivusto päivittää HTML-rakennettaan, selectorit rikkoutuvat ja olet takaisin manuaalisen uudelleenkonfiguroinnin äärellä.
Thunderbitin kaltaiset AI-pohjaiset extractorit lukevat sivurakenteen uudelleen joka kerta. Se tarkoittaa, ettei XPathin ylläpitoa tarvita eikä hauraista selectoreista ole huolta. AI mukautuu asettelumuutoksiin automaattisesti seuraavalla ajokerralla.
Ajastettu scraping ja API-käyttö: teho-ominaisuudet, joita kukaan ei arvostele
Kertaluonteinen scraping käy tutkimukseen. Tuotantokäyttötapaukset, kuten hintaseuranta, liidilistojen päivitys ja varaston seuranta, vaativat toistuvaa poimintaa ja ohjelmallista käyttöä. Nämä ominaisuudet erottavat lelut työkaluista.
Aikataulutustuki
| Työkalu | Natiivi aikataulutus | Huomioita |
|---|---|---|
| Thunderbit | ✅ | Luonnollisen kielen asetus |
| Octoparse | ✅ | Cloud-ajastetut ajot |
| Browse AI | ✅ | Ydintuotteen ominaisuus |
| Firecrawl | ❌ | Käytä ulkoista cronia |
| Apify | ✅ | Täydet cron-lausekkeet |
| Gumloop | ✅ | Aikaperusteiset työnkulun triggerit |
| Bright Data | Ulkoinen | Yleensä orkestraatio asiakasjärjestelmien kautta |
| Bardeen | ✅ | Playbook-aikataulutus |
| Diffbot | ❌ | API-first, ulkoinen orkestrointi |
| ScrapingBee | ❌ | Vain API |
| Instant Data Scraper | ❌ | Manuaalinen selaintyökalu |
| ParseHub | ✅ (maksullinen) | Premium-ominaisuus |
Kehittäjä-API-vertailu
| Työkalu | Rinnakkaisuus tai nopeusindikaattori | Hinnoittelumalli |
|---|---|---|
| Thunderbit | 2 → 50 rinnakkaista | Krediittipohjainen |
| Firecrawl | 2 → 100 rinnakkaista | Krediittipohjainen |
| Apify | Pakettiriippuvainen | Compute-yksiköt |
| Gumloop | Pakettirajoitettu työnkulun rinnakkaisuus | Krediittipohjainen |
| Diffbot | 5 kutsua/min → 25 kutsua/s | Krediittipohjainen |
| ScrapingBee | 10 → 200 rinnakkaista | API-krediittipohjainen |
| Bright Data | Browser API mainostaa rajattomia rinnakkaisia pyyntöjä | GB-pohjainen |
Jos käyttötapauksesi on teknisempi ja yrität päättää, kuinka paljon infrastruktuuria haluat itse omistaa, tämä Firecrawl-läpikäynti on hyödyllinen toteutuspainotteinen täydennys yllä oleviin vertailuihin.
Miten valita oikea AI Web Scraper
Testattuani kaikki 12 työkalua, näin valitsisin:
- Ei-tekninen tiimi, joka tarvitsee dataa nopeasti: Aloita Thunderbitilla. Kahden klikin työnkulku, ilmaiset viennit ja browser-cloud-vaihto kattavat suurimman osan liiketoiminnan scraping-tarpeista ilman insinööritukea.
- Tarvitset jatkuvaa seurantaa ja hälytyksiä: Browse AI on tähän suunniteltu. Se ei ole vahvin kertaluonteinen extractor, mutta muutosten tunnistus on sen ensiluokkainen ominaisuus.
- Kehittäjä, joka rakentaa LLM-putkea: Firecrawl Markdown- tai JSON-poimintaan, tai Diffbot esikoulutettuun rakenteelliseen poimintaan. Yhdistä jompikumpi ScrapingBeehen tai Bright Dataan, jos tarvitset vakavaa bot-suojauksen käsittelyä hakukerroksessa.
- Tarvitset markkinapaikan valmiille scrappereille: Apifylla on suurin actor-ekosysteemi. Varaudu vain ylläpitoon, kun actorit rikkoutuvat.
- Yritystason, vahvasti suojatut kohteet: Bright Data. Mikään muu ei vastaa sen proxy-infrastruktuuria, mutta budjetoi ja resursoi tekninen henkilöstö sen mukaan.
- Haluat scrapingin osaksi suurempaa automaatiota: Gumloop tai Bardeen sen mukaan, automatisoitko työnkulkuja vai selainpohjaisia GTM-tehtäviä.
- Tarvitset vain nopean ilmaisen scrubin: Instant Data Scraper. Ei asetuksia, ei kustannuksia, ei monimutkaisuutta, mutta ei myöskään aikataulutusta, AI:ta tai cloudia.
- Monimutkaiset interaktiiviset sivut, joissa on pudotusvalikoita ja AJAXia: ParseHub käsittelee nämä yhä useimpia laajennuksia paremmin, vaikka ylläpitotaakka on todellinen.
Testaa Thunderbitia oikealla sivulla ennen kuin sitoudut suurempaan pinoon
Yhteenveto
AI web scraper -markkina vuonna 2026 on täynnä työkaluja, jotka näyttävät vaikuttavilta demoissa ja tuottavat pettymyksen tuotannossa. Ero "toimii markkinointikuvakaappauksessa" -tilan ja "toimii suojatulla verkkokauppasivustolla kello 3 aamulla aikataulun mukaan" -tilan välillä on juuri se paikka, jossa useimmat ostajat hukkaavat aikaa ja rahaa.
Keskeinen oivallus kaikkien 12 työkalun arvioinnista on yksinkertainen: hakukerros on yhä vaikein osa. AI on erinomainen poiminnassa ja jälkikäsittelyssä, mutta se ei korvaa proxy-infrastruktuuria, bot-suojauksen käsittelyä tai sessionhallintaa. Parhaat työkalut joko ratkaisevat molemmat kerrokset, kuten Thunderbit ja Bright Data, tai kertovat rehellisesti, minkä kerroksen ne kattavat, kuten Firecrawl poiminnassa ja ScrapingBee hakupuolella.
Jos haluat nähdä, miltä tuotantovalmis AI web scraper näyttää kirjoittamatta koodia, kokeile Thunderbitia. Ilmainen taso riittää koko työnkulun testaamiseen oikeilla sivuilla. Jos tarpeesi ovat enemmän kehittäjäpainotteisia, yhdistä poiminta-API erilliseen fetching-palveluun ja säästä itsesi turhautumiselta, joka syntyy siitä, että odottaa yhden työkalun tekevän kaiken.
Usein kysytyt kysymykset
Miksi useimmat AI web scraperit epäonnistuvat oikeilla verkkosivustoilla, vaikka ne toimivat demoissa hyvin?
Demot näyttävät tyypillisesti poimintaa puhtailla, suojaamattomilla sivuilla. Oikeat sivustot lisäävät Cloudflare-suojauksen, dynaamisen JavaScript-renderöinnin, sivutuksen, kirjautumisvaatimukset ja usein muuttuvat asettelut. Useimmat työkalut hoitavat parsimis- ja poimintakerroksen hyvin, mutta niiltä puuttuu vankka infrastruktuuri hakukerrosta varten.
Mikä ero on cloud scrapingilla ja browser scrapingilla, ja milloin kumpaa pitäisi käyttää?
Cloud scraping käyttää etäpalvelimia sivujen hakemiseen, joten se on nopeampi, rinnakkaisempi ja skaalautuvampi. Browser scraping tapahtuu omassa selainistunnossasi ja sopii paremmin kirjautuneille sivustoille tai niille, joissa on aggressiivinen bot-tunnistus. Thunderbit on yksi harvoista työkaluista, jotka tarjoavat molemmat tilat samassa käyttöliittymässä.
Voinko käyttää AI web scrapersia toistuviin tehtäviin, kuten hintaseurantaan?
Kyllä, mutta vain jos työkalu tukee ajastettua scrapingia. Thunderbit, Octoparse, Browse AI, Apify, Gumloop, Bardeen ja ParseHub maksullisilla paketeilla tarjoavat kaikki aikataulutuksen.
Mikä AI web scraper on paras, jos minulla ei ole koodaustaitoja?
Thunderbit tarjoaa nopeimman tien käyttökelpoiseen dataan ei-teknisille käyttäjille. Instant Data Scraper on täysin ilmainen, mutta se rajoittuu yksinkertaisiin sivuihin. Browse AI ja Octoparse tarjoavat visuaalisia käyttöliittymiä, mutta vaativat enemmän käyttöönottoa. ParseHub on tehokas monimutkaisille interaktiivisille sivustoille, mutta sen oppimiskäyrä on jyrkempi.
Paljonko tuotantotason AI web scraping oikeasti maksaa?
Haarukka on laaja. Instant Data Scraper on ilmainen. Thunderbit, Firecrawl ja Browse AI tarjoavat ilmaisia aloituspisteitä sekä edullisia maksullisia paketteja. Keskitasoiset työkalut, kuten Octoparse, ParseHub ja ScrapingBee, voivat maksaa noin 49–189 dollaria kuukaudessa. Yritysratkaisut, kuten Bright Data ja Diffbot, lähtevät paljon korkeammalta.




