Raspador de Tumblr
Confiado por profesionales de empresas líderes














Descubre los datos de Tumblr con Thunderbit
Extrae sin esfuerzo datos de Tumblr, como el contenido de las publicaciones y el número de “likes”.
Obtén la historia completa de Tumblr
Las páginas de listado de Tumblr solo muestran fragmentos. Para ver el panorama completo, necesitas el contenido íntegro de la publicación, los datos del autor y toda la información relacionada. Thunderbit visita automáticamente cada subpágina enlazada, extrae los detalles y los añade como nuevas columnas, para que puedas obtener fácilmente post_id, post_date y mucho más sin hacer clic manualmente.
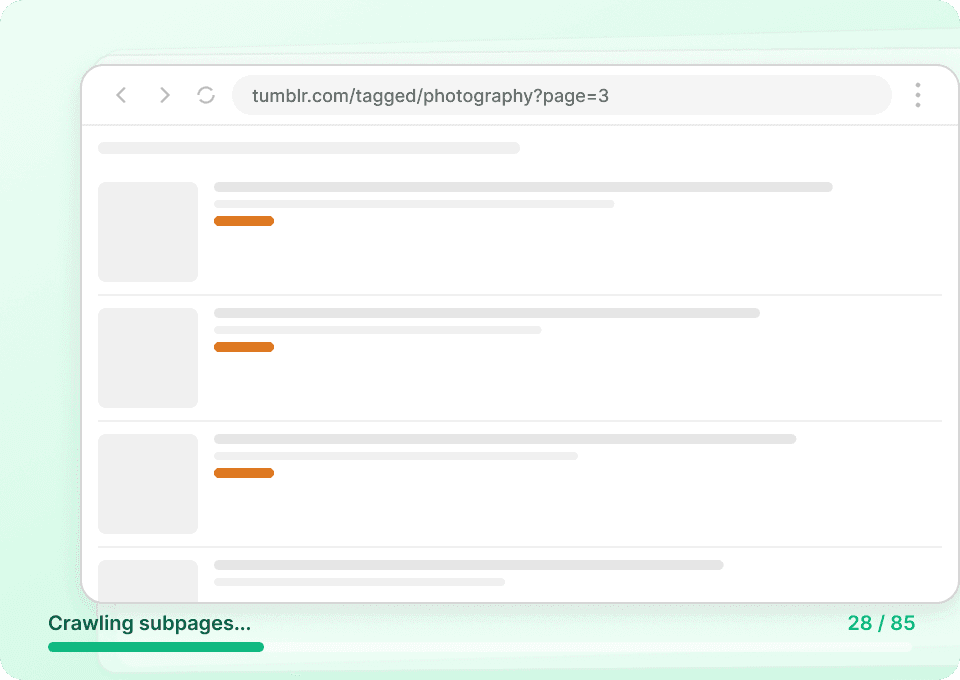
Automatiza la recopilación de datos de Tumblr
Los datos de Tumblr cambian constantemente. Extraer manualmente los mismos blogs una y otra vez es una tarea pesada. Con la extracción programada de Thunderbit, puedes configurar tareas recurrentes en piloto automático. Recibe datos actualizados como like_count y post_content directamente en Google Sheets sin mover un dedo.
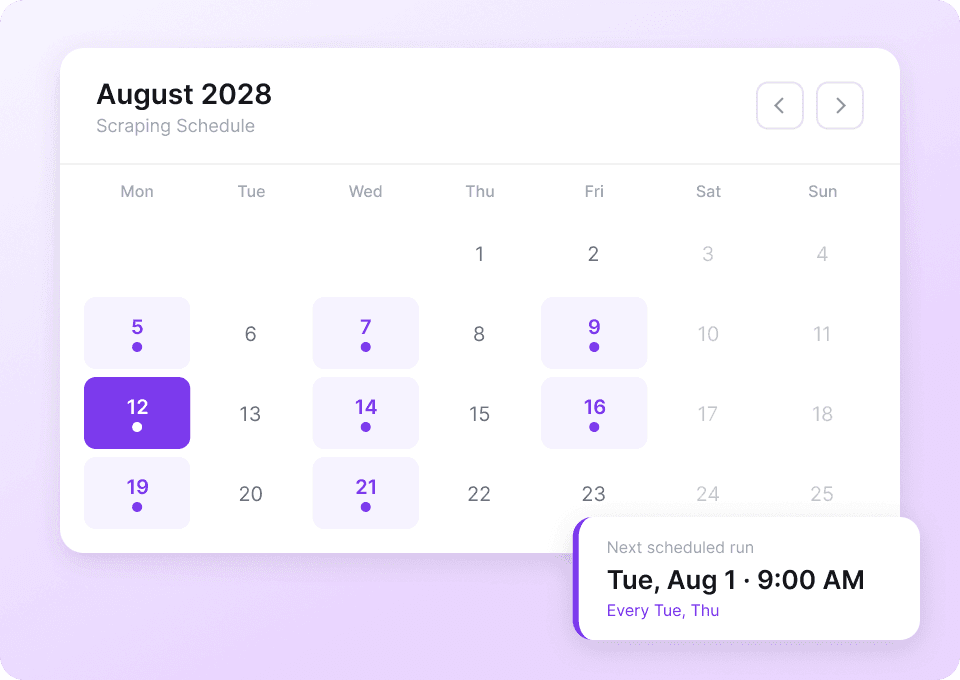
Extrae publicaciones de Tumblr en dos clics
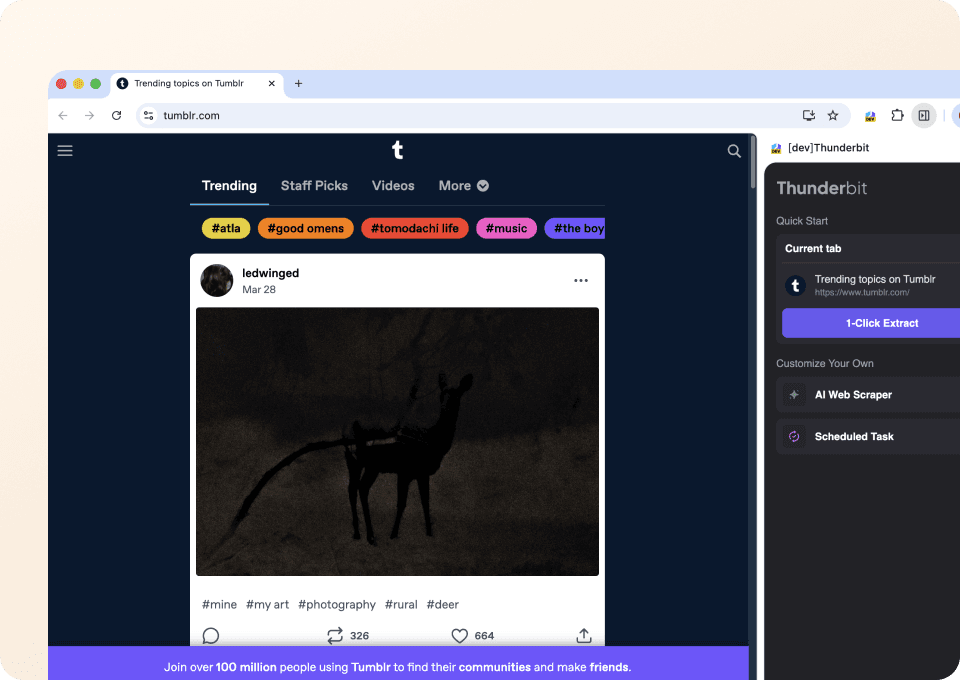
Olvídate del código complicado o de los selectores CSS. Thunderbit te permite extraer datos de Tumblr en solo dos clics. Solo señala los datos que quieres y la IA semántica de Thunderbit detectará los campos relevantes, como post_type y post_author, y los extraerá. No necesitas programar para conseguir los datos que buscas en Tumblr.
¿Por qué Thunderbit es diferente de los raspadores de Tumblr tradicionales?
Extrae datos de Tumblr sin esfuerzo, incluso cuando los diseños cambian o se modifican de forma inesperada.
Raspadores tradicionales
La forma clásica de hacerloThunderbit IA
La forma más inteligente de hacerloNo te quedes solo con nuestra palabra
Mira lo que dicen nuestros usuarios sobre Thunderbit.






Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.
Raspador Web de Tradera
El Raspador Web de Tradera de Thunderbit te permite extraer información de listados y páginas de productos en Tradera de forma sencilla. Gracias a las sugerencias inteligentes impulsadas por IA, puedes recopilar nombres de productos, precios, categorías, imágenes y descripciones para análisis o gestión de inventario. Es la herramienta ideal para vendedores de e-commerce, coleccionistas e investigadores que buscan datos estructurados de Tradera.
Más información ->
Raspador de Trustpilot
Convierte las páginas de Trustpilot en una hoja de cálculo limpia con reseñas, valoraciones y nombres de los usuarios que opinan. Nosotros leemos cada página por ti, así que no necesitas código ni copiar y pegar.
Más información ->
Raspador de Búsqueda de Personas
El Raspador Web de Búsqueda de Personas de Thunderbit te permite extraer datos estructurados de perfiles de Búsqueda de Personas y páginas de búsqueda inversa de teléfonos. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres, ubicaciones, números de teléfono, correos electrónicos y más, ideal para investigaciones, marketing o generación de leads. Perfecto para profesionales de marketing, investigadores y empresas que buscan registros públicos y datos de contacto.
Más información ->
Raspador de Amarillas.com
El Raspador Amarillas.com de Thunderbit te permite extraer datos estructurados de Amarillas.com, incluyendo listados de moteles y restaurantes. Aprovecha las sugerencias inteligentes de campos impulsadas por IA para recopilar rápidamente nombres de negocios, ubicaciones, teléfonos, calificaciones y reseñas, ideal para investigación, marketing o generación de prospectos.
Más información ->
Raspador de Tieba
El Raspador Tieba de Thunderbit te permite obtener datos de Baidu Tieba, incluyendo temas en tendencia y categorías de foros. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de temas, URLs, número de publicaciones y actividad de usuarios, ideal para investigación, marketing o creación de contenido. Perfecto para analizar tendencias y conversaciones en redes sociales dentro de Tieba.
Más información ->
Raspador Web de HKTVmall
Obtén nombres de productos, precios e incluso valoraciones de clientes de los listados de HKTVmall en solo un par de clics, sin necesidad de configuraciones complicadas.
Más información ->¿Listo para potenciar al máximo tu extracción de datos?
Únete a los más de 100,000 profesionales que ya usan Thunderbit para automatizar sus flujos de trabajo de web scraping.
La prueba gratis ofrece créditos ilimitados para 8 páginas web.