Raspador Reddit Simple
Confiado por profesionales de empresas líderes














Desbloquea datos de Reddit en dos clics
Extrae datos de Reddit en dos clics
¿Cansado de scrapers complicados que requieren programación? Thunderbit te permite obtener datos de Reddit como títulos de publicaciones, texto, autores, subreddits y votos positivos con solo dos clics. Solo señala los datos que necesitas y Thunderbit reconoce al instante los campos y los extrae. Sin código, sin selectores CSS, sin dolores de cabeza.
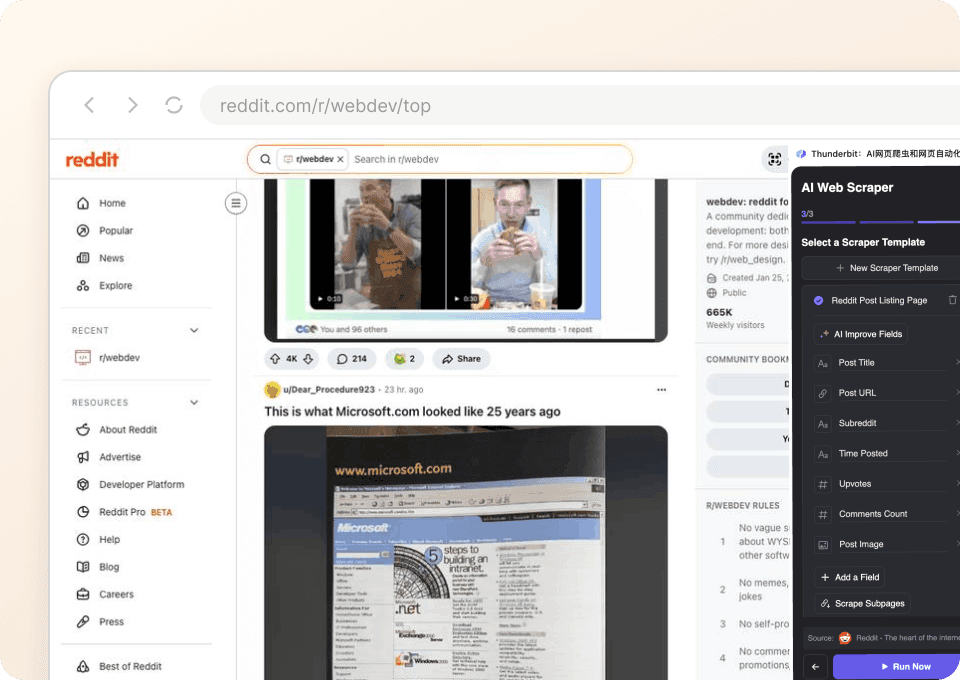
Se adapta a los cambios de diseño de Reddit
El diseño de Reddit cambia y la mayoría de los scrapers dejan de funcionar. Thunderbit usa IA semántica para entender el significado de la página, no solo selectores fijos. Eso significa que se adapta automáticamente a los cambios de diseño, para que puedas seguir extrayendo datos de publicaciones, información de autores y detalles de subreddits sin interrupciones.
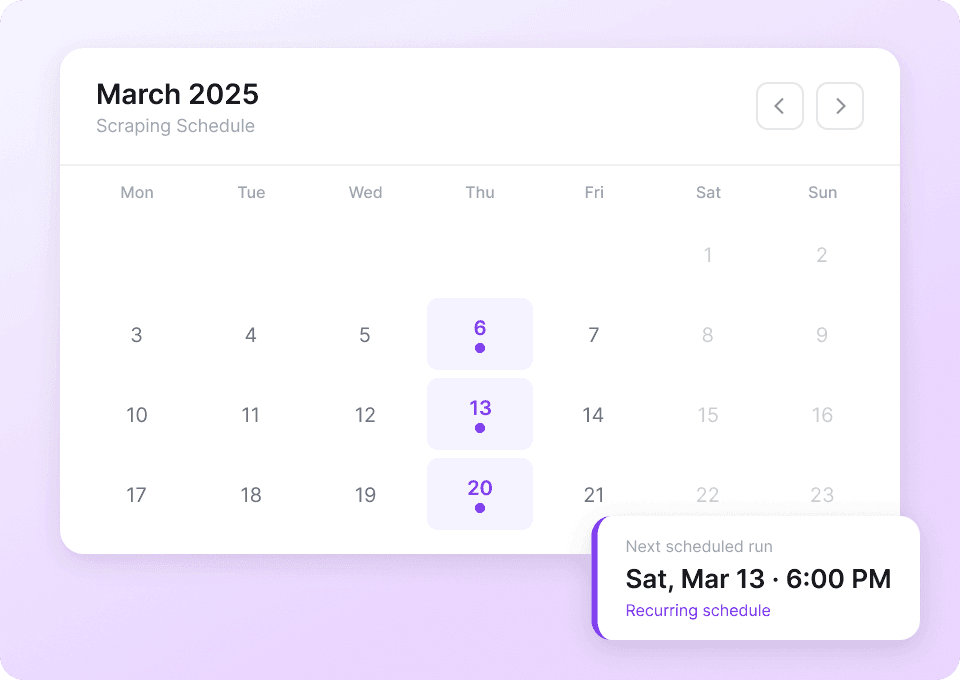
Automatiza la recolección de datos de Reddit
Los datos de Reddit se actualizan constantemente. Thunderbit te permite programar tareas de scraping recurrentes en piloto automático. Recibe los últimos títulos de publicaciones, votos positivos y más directamente en Google Sheets, Notion o Airtable, sin tener que ejecutar el scraper manualmente. Mantén tus datos siempre actualizados sin mover un dedo.
¿Cansado de los dolores de cabeza al extraer datos de Redfin?
Descubre por qué Thunderbit es la forma más fácil de extraer datos de Redfin.
Raspadores tradicionales
La forma clásica de hacerloThunderbit
El enfoque más inteligenteNo te quedes solo con nuestra palabra
Mira lo que dicen nuestros usuarios sobre Thunderbit.







Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.
Raspador Web de Tradera
El Raspador Web de Tradera de Thunderbit te permite extraer información de listados y páginas de productos en Tradera de forma sencilla. Gracias a las sugerencias inteligentes impulsadas por IA, puedes recopilar nombres de productos, precios, categorías, imágenes y descripciones para análisis o gestión de inventario. Es la herramienta ideal para vendedores de e-commerce, coleccionistas e investigadores que buscan datos estructurados de Tradera.
Más información ->
Raspador Web de HKTVmall
Obtén nombres de productos, precios e incluso valoraciones de clientes de los listados de HKTVmall en solo un par de clics, sin necesidad de configuraciones complicadas.
Más información ->Raspador de PeopleWhiz
El raspador de PeopleWhiz de Thunderbit te permite extraer datos de resultados de búsqueda y perfiles de PeopleWhiz con sugerencias de campos impulsadas por IA. Reúne nombres, datos de contacto, ubicaciones y más para investigación, marketing o generación de leads. Convierte rápidamente los datos de PeopleWhiz en conjuntos estructurados y eficientes.
Más información ->
Raspador Web de UNIQLO
Extrae datos de productos de Uniqlo, como nombres, precios y tallas disponibles, con solo 2 clics gracias a la extensión de Chrome de Thunderbit.
Más información ->
Raspador de Listados de Negocios de TripAdvisor
El Raspador de Listados de Negocios de TripAdvisor de Thunderbit te permite extraer información de los listados de negocios, el centro de recursos y el foro de propietarios de TripAdvisor. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de recursos, URLs, descripciones, temas de foros, autores y contenido de publicaciones para investigación, marketing o análisis.
Más información ->Raspador Web de On the Beach
El Raspador Web de On the Beach de Thunderbit te permite extraer listados de vacaciones y hoteles, precios, valoraciones y mucho más de On the Beach en solo dos clics. Aprovecha las sugerencias inteligentes de campos impulsadas por IA para recopilar y organizar datos de viajes de forma rápida, ya sea para análisis, comparación o planificación. Perfecto para profesionales del sector turístico, analistas y quienes organizan vacaciones.
Más información ->¿Listo para potenciar al máximo tu extracción de datos?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
La prueba gratis ofrece créditos ilimitados para 8 páginas web.