Raspador de Pixiv
Confiado por profesionales de empresas líderes














Extracción de datos de Pixiv, simplificada
Extrae datos de Pixiv como titulares, autores y detalles de secciones sin copiar y pegar manualmente.
Extrae datos de Pixiv en bloque y a escala
Recopilar datos de Pixiv página por página manualmente se vuelve lento enseguida, sobre todo cuando necesitas docenas o cientos de titulares, resúmenes de artículos, autores, fechas de publicación, fuentes de noticias y secciones. Thunderbit te permite extraer una lista de URLs de una sola vez, para que pases de unas pocas páginas a un gran conjunto de registros de Pixiv sin perder tiempo en tareas repetitivas.

Captura los detalles completos de las subpáginas de Pixiv
Las páginas de listado en Pixiv suelen mostrar solo lo básico, mientras que los detalles reales están dentro de cada subpágina de artículo o publicación. Thunderbit visita cada subpágina enlazada y recupera la información completa, dándote datos más ricos como el resumen del artículo, el autor, la fecha de publicación, la fuente de noticias y la sección en una estructura limpia.
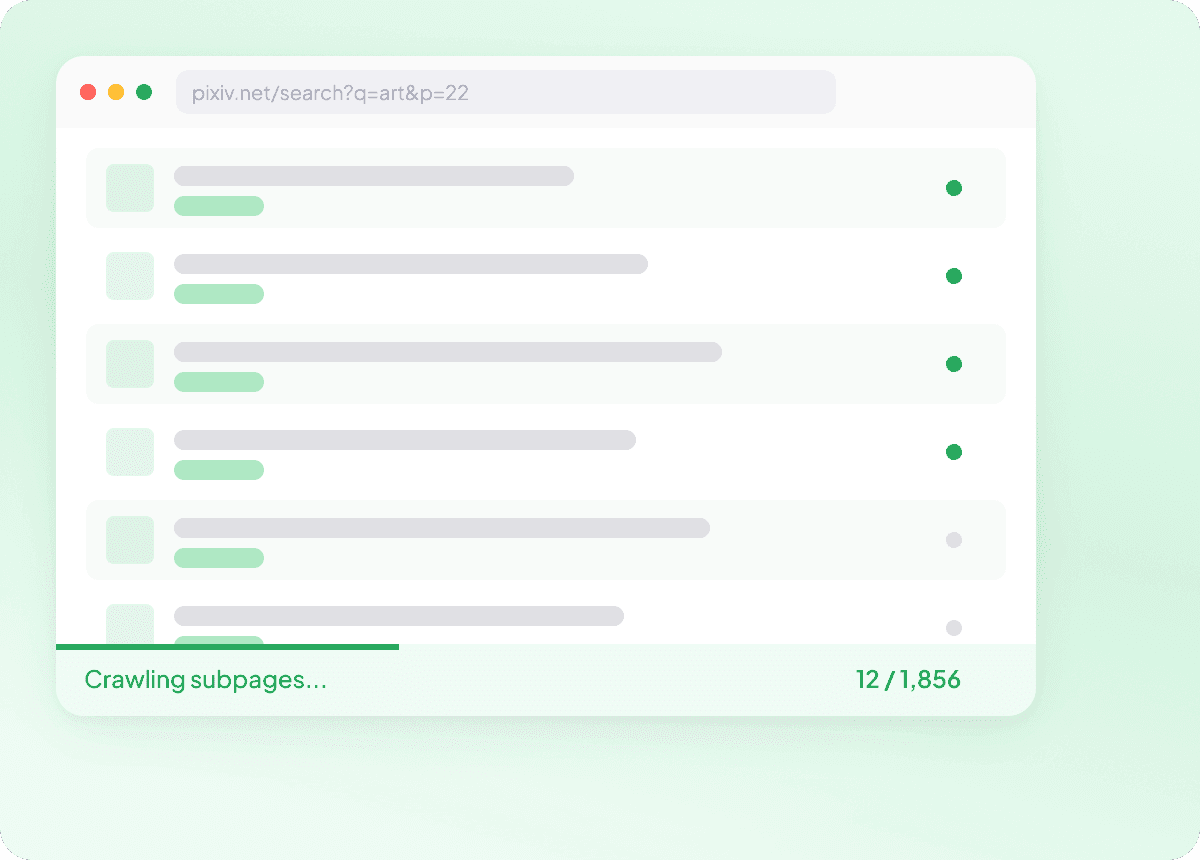
Mantén los datos de Pixiv actualizados en piloto automático
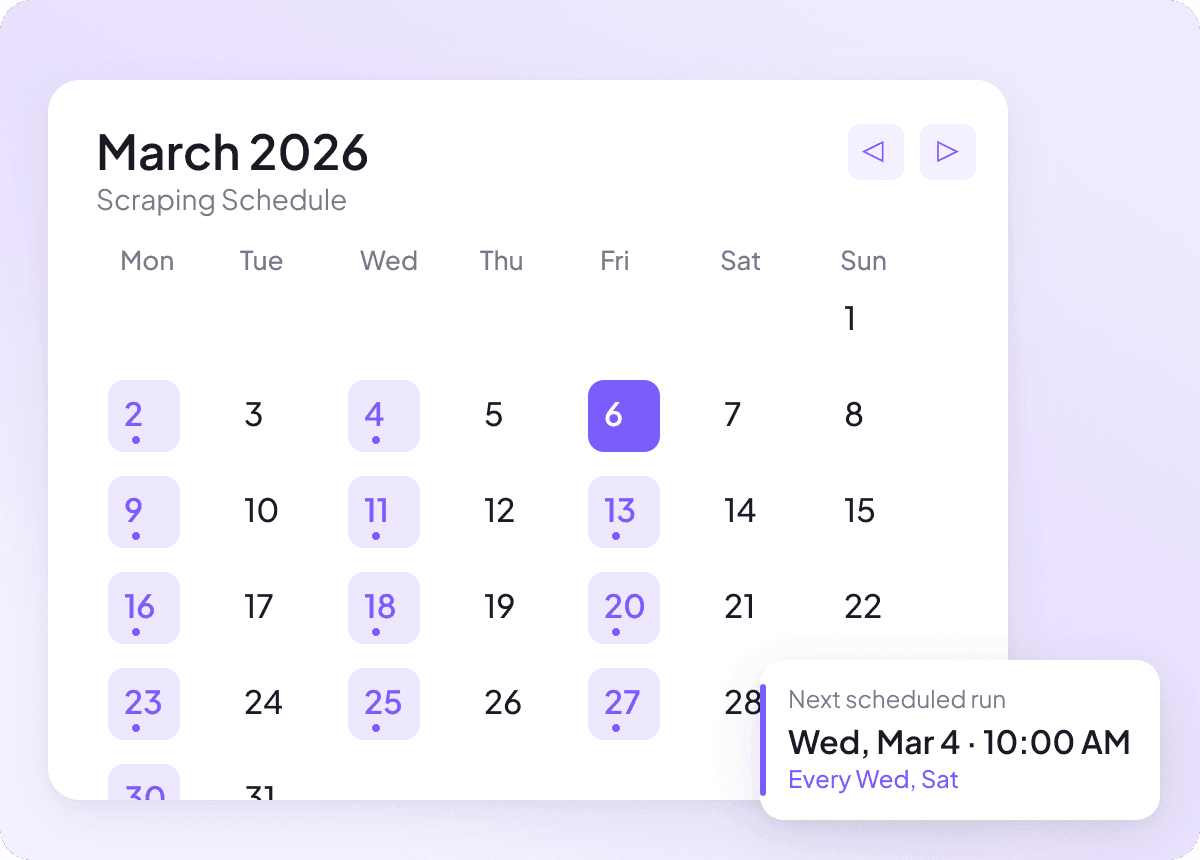
El contenido de Pixiv puede cambiar a diario, y seguirlo manualmente significa revisar las mismas páginas una y otra vez. Con la extracción programada, Thunderbit funciona en piloto automático y entrega datos frescos de Pixiv a tu hoja de cálculo de forma recurrente, para que el seguimiento de titulares, autores y secciones se mantenga al día sin que tengas que hacer nada.
¿Por qué Thunderbit es diferente de los raspadores de Pixiv tradicionales?
Una forma más sencilla de extraer Pixiv sin selectores frágiles ni limpieza adicional.
Raspadores tradicionales
La forma antigua de hacer las cosasThunderbit IA
El enfoque más inteligenteNo te quedes solo con nuestra palabra
Mira lo que dicen nuestros usuarios sobre Thunderbit.





Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.

Raspador Web de UNIQLO
Extrae datos de productos de Uniqlo, como nombres, precios y tallas disponibles, con solo 2 clics gracias a la extensión de Chrome de Thunderbit.
Más información ->
Raspador de Rakuten Travel
El Raspador Web de Rakuten Travel de Thunderbit te permite extraer información de los listados y páginas de detalles de hoteles en Rakuten Travel. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de hoteles, precios, valoraciones, tipos de habitación y servicios, ya sea para investigación o planificación de viajes. Perfecto para agentes de viajes, investigadores y empresas que necesitan datos turísticos estructurados.
Más información ->
Raspador de Listados de Negocios de TripAdvisor
El Raspador de Listados de Negocios de TripAdvisor de Thunderbit te permite extraer información de los listados de negocios, el centro de recursos y el foro de propietarios de TripAdvisor. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de recursos, URLs, descripciones, temas de foros, autores y contenido de publicaciones para investigación, marketing o análisis.
Más información ->
Raspador de ReverseAustralia
El Raspador Web de ReverseAustralia de Thunderbit te permite extraer datos de las páginas de quejas y comentarios de ReverseAustralia. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente números de teléfono, descripciones de quejas, textos de comentarios, nombres de usuarios y mucho más, ya sea para análisis o investigación. Es la herramienta ideal para profesionales de marketing, investigadores y empresas que buscan datos estructurados de retroalimentación.
Más información ->
Raspador de Tieba
El Raspador Tieba de Thunderbit te permite obtener datos de Baidu Tieba, incluyendo temas en tendencia y categorías de foros. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de temas, URLs, número de publicaciones y actividad de usuarios, ideal para investigación, marketing o creación de contenido. Perfecto para analizar tendencias y conversaciones en redes sociales dentro de Tieba.
Más información ->Raspador Web de On the Beach
El Raspador Web de On the Beach de Thunderbit te permite extraer listados de vacaciones y hoteles, precios, valoraciones y mucho más de On the Beach en solo dos clics. Aprovecha las sugerencias inteligentes de campos impulsadas por IA para recopilar y organizar datos de viajes de forma rápida, ya sea para análisis, comparación o planificación. Perfecto para profesionales del sector turístico, analistas y quienes organizan vacaciones.
Más información ->¿Listo para potenciar al máximo tu extracción de datos?
Únete a los más de 100,000 profesionales que ya usan Thunderbit para automatizar sus flujos de trabajo de web scraping.
La prueba gratis ofrece créditos ilimitados para 8 páginas web.