Raspador de noticias

Con la confianza de profesionales en empresas líderes














Datos de noticias, capturados más rápido
Extrae datos de noticias limpios desde artículos, listados y fuentes sin el trabajo manual pesado.
Obtén el detalle completo del artículo
Las páginas de listado de noticias solo te dan un adelanto. Thunderbit visita cada subpágina del artículo y recupera el panorama completo, incluyendo titular, resumen del artículo, autor, fecha de publicación, fuente de noticias y sección. Así puedes pasar de una simple lista de historias a un conjunto de datos completo en menos pasos.
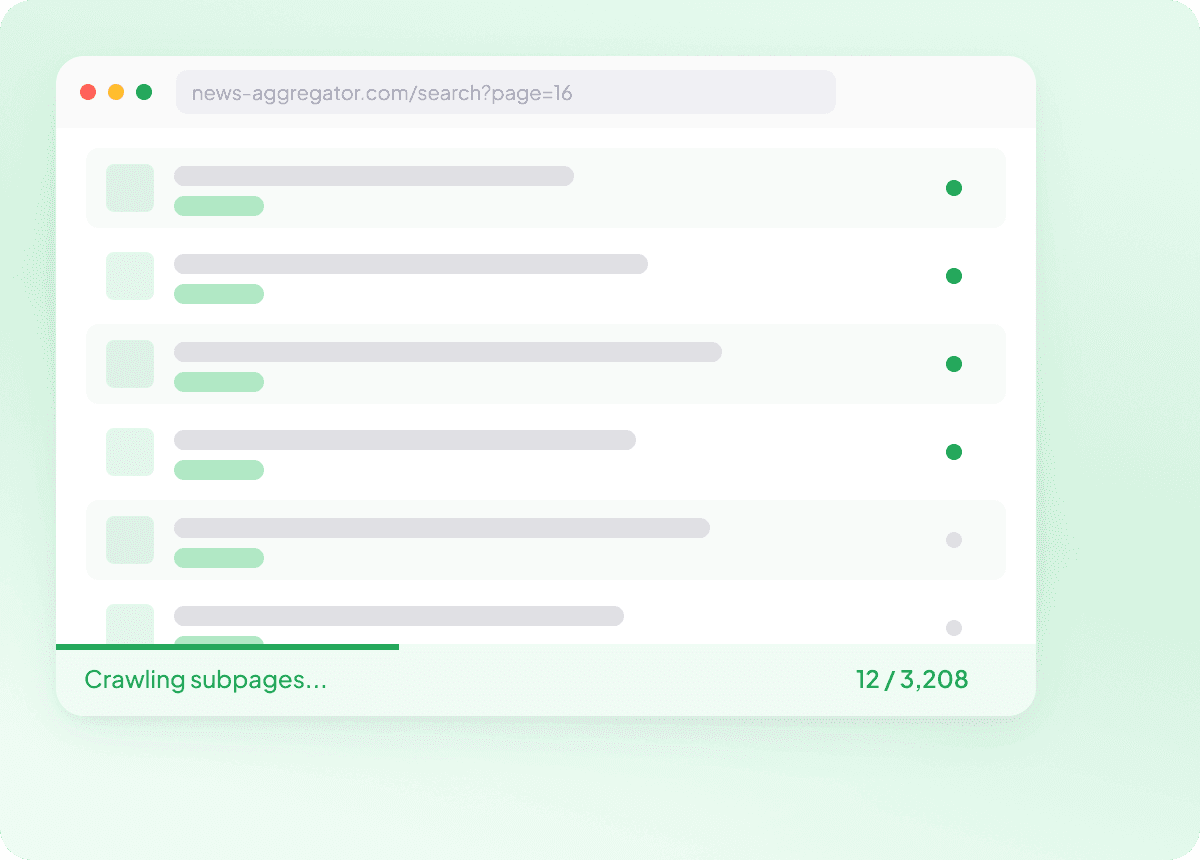
Extrae en masa listas de URLs de noticias
Extraer noticias página por página se vuelve lento muy rápido. Con Thunderbit, puedes darle una lista de URLs de artículos y extraer en masa cientos de páginas de una sola vez, para capturar cada historia con los campos que necesitas. Es una forma práctica de recopilar grandes conjuntos de datos de noticias sin repetir el mismo trabajo.

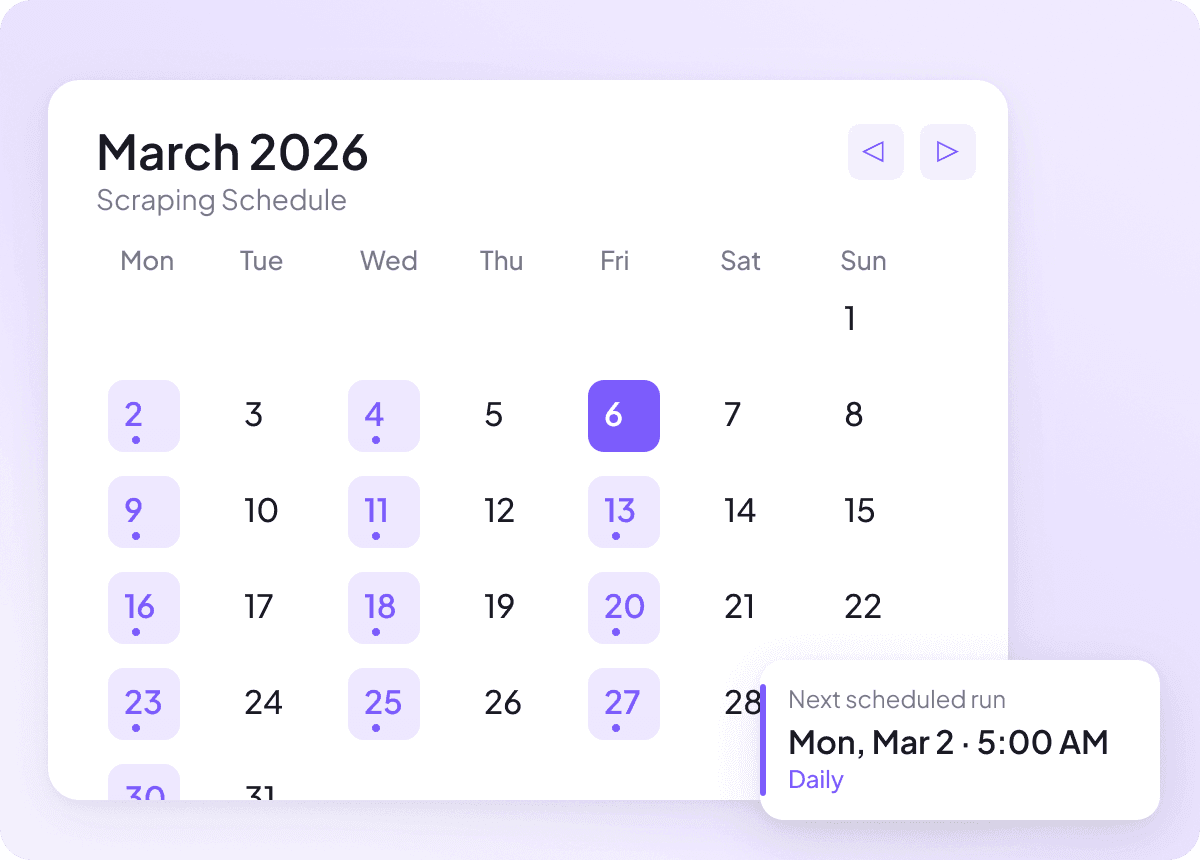
Mantén frescos los datos de noticias
Las noticias cambian a diario y los datos obsoletos no sirven. Configura el raspado programado para que Thunderbit funcione en piloto automático y mantenga tu hoja de cálculo actualizada con titulares, resúmenes, autores, fechas de publicación, fuentes de noticias y secciones. Recibes actualizaciones recurrentes sin tener que recordar la tarea tú mismo.
¿Por qué Thunderbit es diferente de los raspadores de noticias tradicionales?
Una forma más rápida de recopilar datos de noticias desordenados sin fallos constantes.
Raspadores tradicionales
La forma antigua de hacer las cosasThunderbit AI
El enfoque más inteligenteNo te quedes solo con nuestra palabra
Mira lo que dicen nuestros usuarios sobre Thunderbit.






Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.

Raspador de Páginas Blancas
El Raspador Web de White Pages de Thunderbit te permite extraer datos de listados telefónicos y comerciales de White Pages con sugerencias de campos impulsadas por IA. Recopila nombres, teléfonos, direcciones y URLs de sitios web para generación de leads, marketing o investigación en cuestión de segundos.
Más información ->Raspador de Substack
Obtén los recuentos de suscriptores de Substack, los títulos de los artículos y las descripciones de las publicaciones en una hoja de cálculo limpia: sin código; la IA se encarga de estructurarlo.
Más información ->Raspador Web de On the Beach
El Raspador Web de On the Beach de Thunderbit te permite extraer listados de vacaciones y hoteles, precios, valoraciones y mucho más de On the Beach en solo dos clics. Aprovecha las sugerencias inteligentes de campos impulsadas por IA para recopilar y organizar datos de viajes de forma rápida, ya sea para análisis, comparación o planificación. Perfecto para profesionales del sector turístico, analistas y quienes organizan vacaciones.
Más información ->Raspador de PeopleWhiz
El raspador de PeopleWhiz de Thunderbit te permite extraer datos de resultados de búsqueda y perfiles de PeopleWhiz con sugerencias de campos impulsadas por IA. Reúne nombres, datos de contacto, ubicaciones y más para investigación, marketing o generación de leads. Convierte rápidamente los datos de PeopleWhiz en conjuntos estructurados y eficientes.
Más información ->
Raspador Web de HKTVmall
Obtén nombres de productos, precios e incluso valoraciones de clientes de los listados de HKTVmall en solo un par de clics, sin necesidad de configuraciones complicadas.
Más información ->
Raspador de United Airlines
Haz clic y selecciona para recopilar datos de vuelos de United Airlines, como número de vuelo, hora de llegada y aeropuerto de salida: Thunderbit AI se encarga del resto.
Más información ->¿Listo para potenciar tu extracción de datos?
Únete a más de 100,000 profesionales que ya usan Thunderbit para automatizar sus flujos de web scraping.
La prueba gratis ofrece créditos ilimitados para 8 páginas web.