Raspador Web de IDCrawl
Confiado por profesionales de empresas líderes














Datos de Idcrawl que siguen siendo útiles
Usa idcrawl para extraer datos más rápido, con más limpieza y a gran escala con Thunderbit.
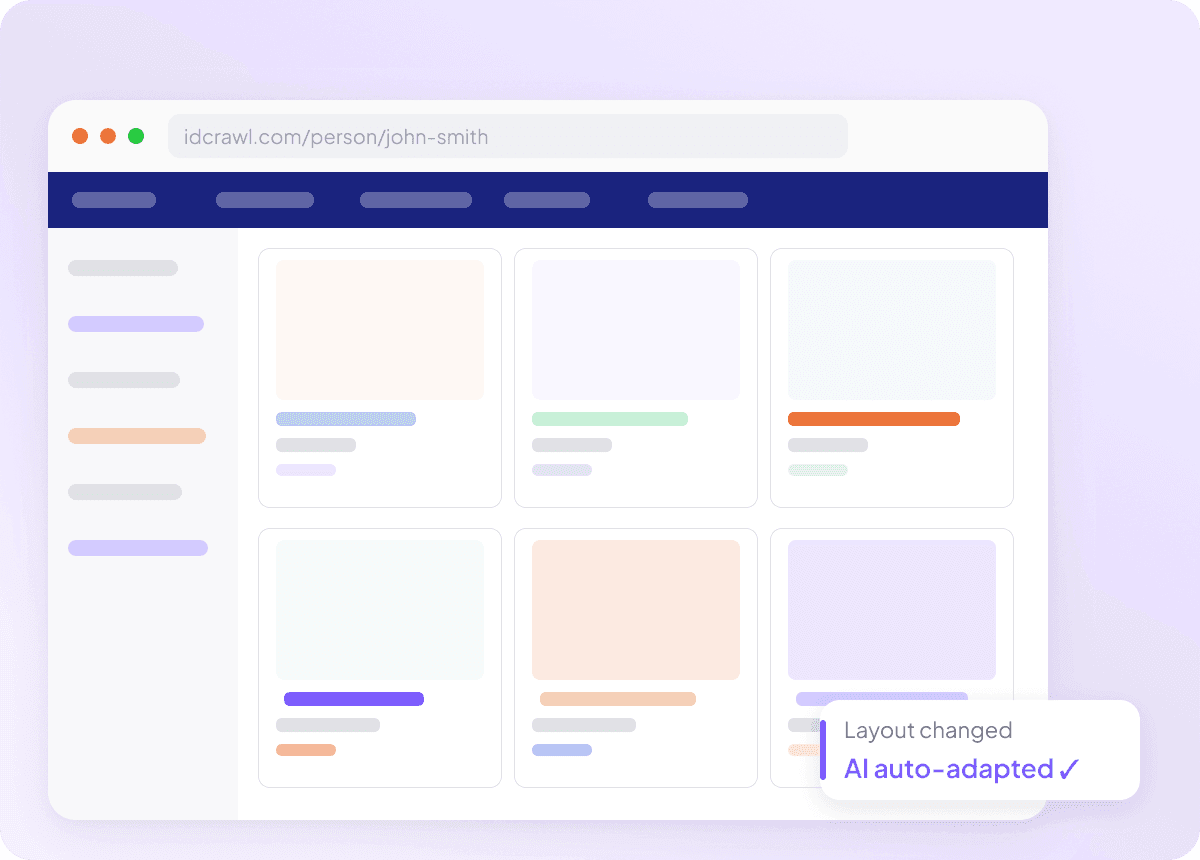
Se adapta cuando Idcrawl cambia
Los raspadores que se rompen con cada actualización del sitio no sirven de mucho, sobre todo cuando intentas obtener nombre completo, cargo, nombre de la empresa, correo electrónico, número de teléfono y perfil de LinkedIn desde idcrawl. Thunderbit lee la página por su significado, no por selectores fijos, así que puede adaptarse cuando cambia el diseño. Pasas menos tiempo arreglando raspadores y más tiempo consiguiendo los datos que necesitas.
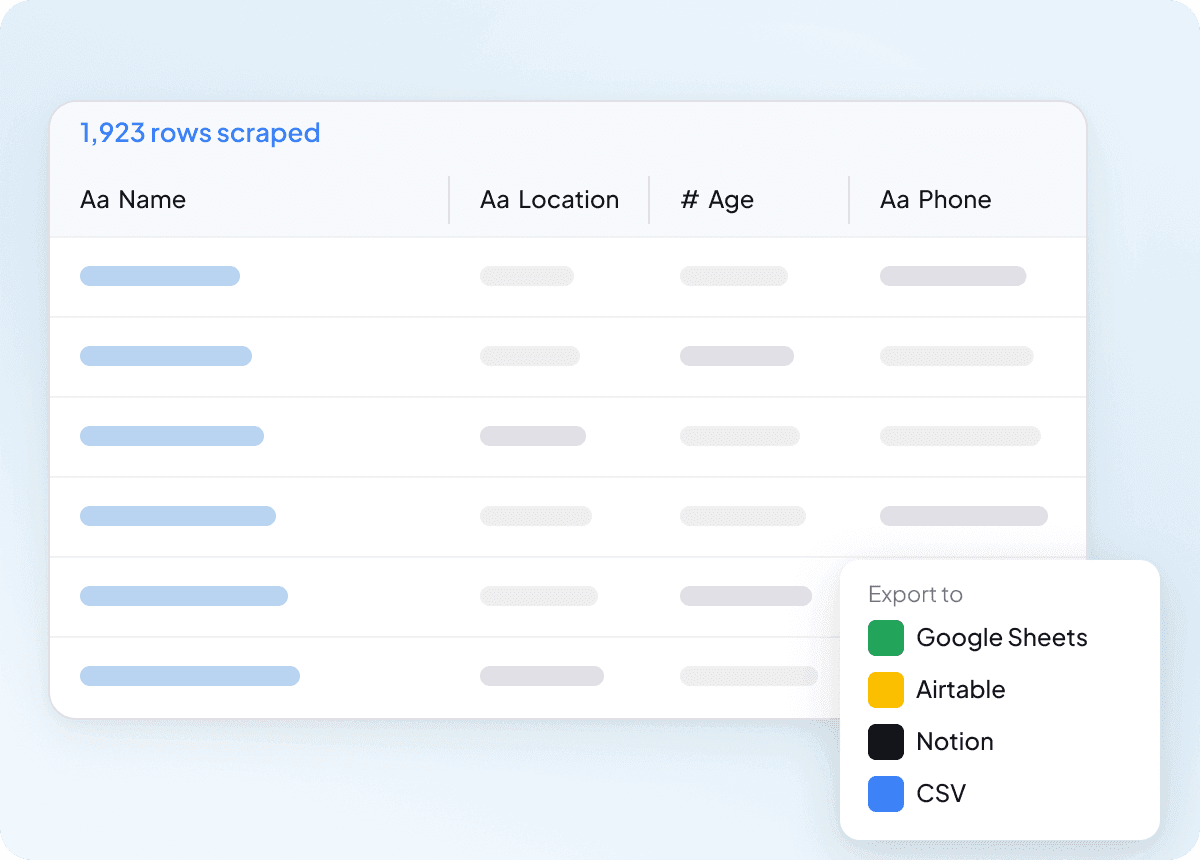
Datos limpios desde el principio
Los datos en bruto son solo el inicio del trabajo real, y los resultados de idcrawl suelen necesitar limpieza antes de ser útiles. Thunderbit estructura y da formato a los datos durante la extracción, así que lo que exportas ya está limpio y listo para usar. Eso significa menos ordenación, menos retrabajo y una entrega más fluida a tu equipo.
Extrae Idcrawl por lotes de una sola vez
Extraer una página de idcrawl a la vez no escala cuando necesitas una lista larga de contactos. Thunderbit puede extraer por lotes cientos de páginas de una sola vez, así que puedes darle una lista de URL y obtener nombre completo, cargo, nombre de la empresa, correo electrónico, número de teléfono y perfil de LinkedIn en todas ellas. Es una forma mucho más sencilla de convertir una lista grande en datos útiles.

¿Por qué Thunderbit es diferente de los raspadores de idcrawl tradicionales?
Una forma más sencilla de extraer datos de idcrawl sin correcciones constantes.
Raspadores tradicionales
La forma antigua de hacerloThunderbit IA
El enfoque más inteligenteNo te quedes solo con nuestra palabra
Mira lo que dicen nuestros usuarios sobre Thunderbit.





Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.

Raspador de ReverseAustralia
El Raspador Web de ReverseAustralia de Thunderbit te permite extraer datos de las páginas de quejas y comentarios de ReverseAustralia. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente números de teléfono, descripciones de quejas, textos de comentarios, nombres de usuarios y mucho más, ya sea para análisis o investigación. Es la herramienta ideal para profesionales de marketing, investigadores y empresas que buscan datos estructurados de retroalimentación.
Más información ->Raspador DialIndia
El Raspador DialIndia de Thunderbit te permite extraer datos de los perfiles de negocios y directorios de viajes de DialIndia con sugerencias de campos impulsadas por IA. Recopila nombres de empresas, datos de contacto, ubicaciones y descripciones para investigación, marketing o generación de prospectos en solo unos clics.
Más información ->Raspador de Substack
Obtén los recuentos de suscriptores de Substack, los títulos de los artículos y las descripciones de las publicaciones en una hoja de cálculo limpia: sin código; la IA se encarga de estructurarlo.
Más información ->
Raspador de Trustpilot
Convierte las páginas de Trustpilot en una hoja de cálculo limpia con reseñas, valoraciones y nombres de los usuarios que opinan. Nosotros leemos cada página por ti, así que no necesitas código ni copiar y pegar.
Más información ->
Raspador de Tieba
El Raspador Tieba de Thunderbit te permite obtener datos de Baidu Tieba, incluyendo temas en tendencia y categorías de foros. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de temas, URLs, número de publicaciones y actividad de usuarios, ideal para investigación, marketing o creación de contenido. Perfecto para analizar tendencias y conversaciones en redes sociales dentro de Tieba.
Más información ->Raspador de PeopleWhiz
El raspador de PeopleWhiz de Thunderbit te permite extraer datos de resultados de búsqueda y perfiles de PeopleWhiz con sugerencias de campos impulsadas por IA. Reúne nombres, datos de contacto, ubicaciones y más para investigación, marketing o generación de leads. Convierte rápidamente los datos de PeopleWhiz en conjuntos estructurados y eficientes.
Más información ->¿Listo para potenciar al máximo tu extracción de datos?
Únete a los más de 100,000 profesionales que ya usan Thunderbit para automatizar sus flujos de trabajo de web scraping.
La prueba gratis ofrece créditos ilimitados para 8 páginas web.