Raspador de Goodreads
Confiado por profesionales de empresas líderes














Extrae datos de Goodreads en segundos, no en horas
Dos clics para extraer datos de Goodreads
¿Cansado de copiar manualmente títulos de libros, nombres de autores, valoraciones y número de páginas desde Goodreads? Thunderbit te permite extraer datos en solo dos clics. No necesitas programación ni configuraciones complicadas. Solo señala los datos que quieres y nuestra IA detectará y extraerá automáticamente los campos.
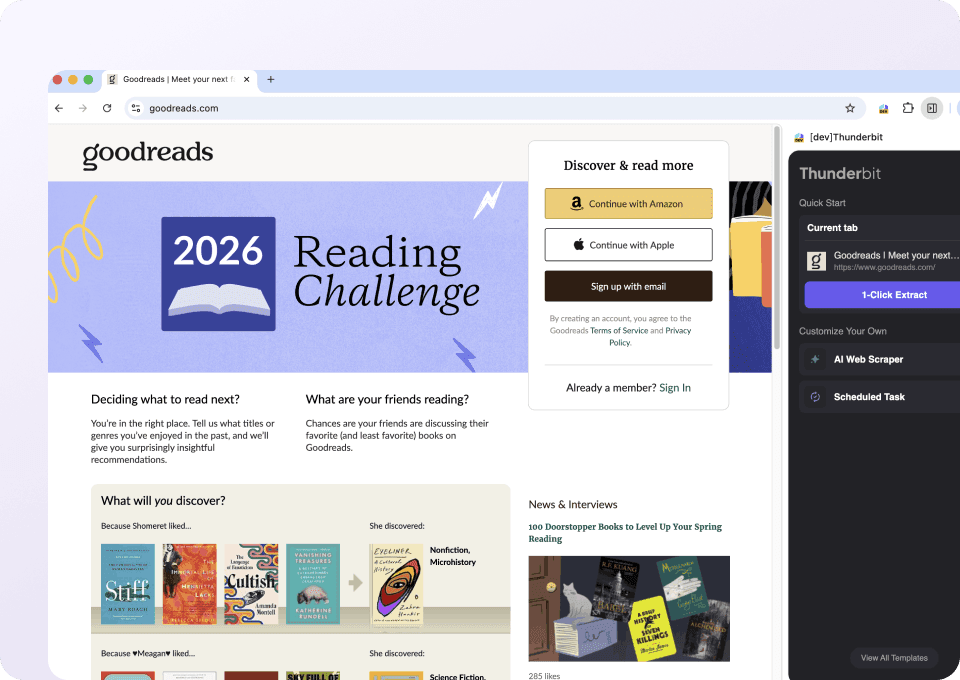
Datos de Goodreads limpios y listos para usar
Los datos de Goodreads pueden ser desordenados. Thunderbit los limpia y estructura automáticamente mientras los extrae. Imagina recibir una hoja de Google Sheets perfectamente formateada con títulos de libros, autores, valoración media, número de reseñas y número de páginas, todo listo para tu análisis, sin limpiezas manuales.
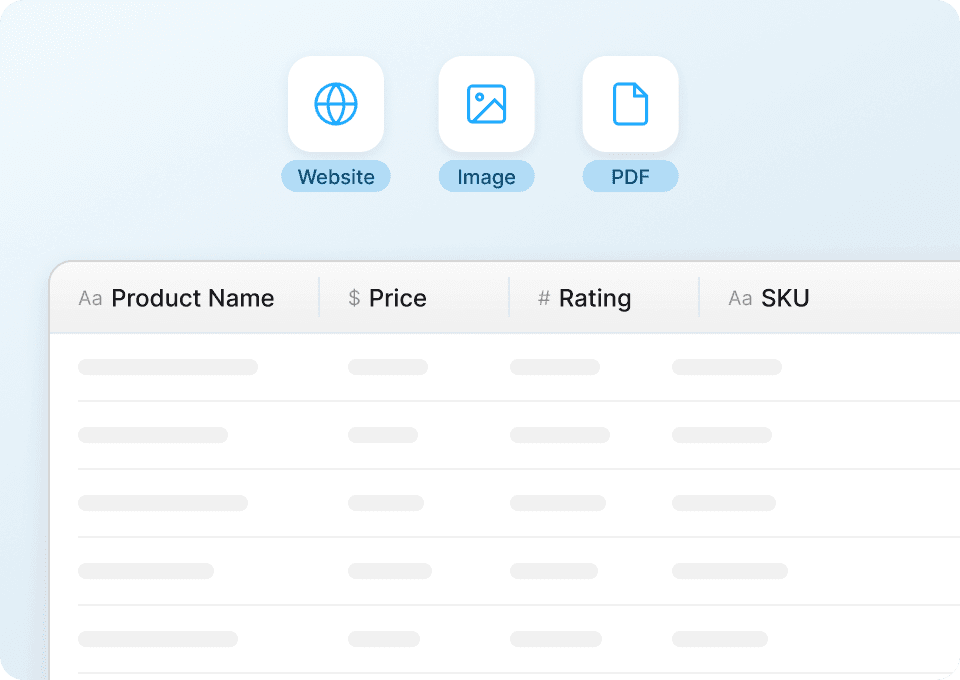
Extrae cientos de páginas de Goodreads
Extraer manualmente Goodreads, página por página, es tedioso y consume mucho tiempo. Thunderbit puede extraer automáticamente cientos de páginas de Goodreads a la vez. Solo dale una lista de URLs y extraerá datos de libros, autores o cualquier otra información que necesites, de forma rápida y eficiente.

¿La extracción de Goodreads te está dando problemas?
Mira cómo Thunderbit simplifica la extracción de datos de Goodreads.
Raspadores tradicionales
La forma antigua de hacer las cosasThunderbit
El enfoque más inteligenteNo te quedes solo con nuestra palabra
Mira lo que dicen nuestros usuarios sobre Thunderbit.






Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.

Raspador de Páginas Blancas
El Raspador Web de White Pages de Thunderbit te permite extraer datos de listados telefónicos y comerciales de White Pages con sugerencias de campos impulsadas por IA. Recopila nombres, teléfonos, direcciones y URLs de sitios web para generación de leads, marketing o investigación en cuestión de segundos.
Más información ->Raspador de Substack
Obtén los recuentos de suscriptores de Substack, los títulos de los artículos y las descripciones de las publicaciones en una hoja de cálculo limpia: sin código; la IA se encarga de estructurarlo.
Más información ->
Raspador de Tieba
El Raspador Tieba de Thunderbit te permite obtener datos de Baidu Tieba, incluyendo temas en tendencia y categorías de foros. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de temas, URLs, número de publicaciones y actividad de usuarios, ideal para investigación, marketing o creación de contenido. Perfecto para analizar tendencias y conversaciones en redes sociales dentro de Tieba.
Más información ->
Raspador de ReverseAustralia
El Raspador Web de ReverseAustralia de Thunderbit te permite extraer datos de las páginas de quejas y comentarios de ReverseAustralia. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente números de teléfono, descripciones de quejas, textos de comentarios, nombres de usuarios y mucho más, ya sea para análisis o investigación. Es la herramienta ideal para profesionales de marketing, investigadores y empresas que buscan datos estructurados de retroalimentación.
Más información ->
Raspador Web de BestPrice GR
El Raspador Web de BestPrice GR con IA de Thunderbit te permite extraer listados de productos, precios e información detallada de BestPrice.gr en solo unos clics. Es la herramienta ideal para equipos de ventas, marketing y comercio electrónico que necesitan recopilar datos estructurados de forma rápida y eficiente.
Más información ->
Raspador de Rakuten Travel
El Raspador Web de Rakuten Travel de Thunderbit te permite extraer información de los listados y páginas de detalles de hoteles en Rakuten Travel. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de hoteles, precios, valoraciones, tipos de habitación y servicios, ya sea para investigación o planificación de viajes. Perfecto para agentes de viajes, investigadores y empresas que necesitan datos turísticos estructurados.
Más información ->¿Listo para potenciar al máximo tu extracción de datos?
Únete a los más de 100,000 profesionales que ya usan Thunderbit para automatizar sus flujos de trabajo de web scraping.
La prueba gratis ofrece créditos ilimitados para 8 páginas web.