Raspador de Flickr
Confiado por profesionales de empresas líderes














Extrae datos de Flickr en dos clics
Thunderbit simplifica la extracción de datos de Flickr, sin necesidad de programar.
Dos clics para obtener datos de Flickr
Copiar manualmente títulos de fotos, nombres de usuario de autores o fechas de subida desde Flickr es una tarea tediosa. Thunderbit te ahorra ese copiar y pegar. Solo señala el dato que quieras —como la descripción de la foto o el tipo de licencia— y nuestra IA se encarga del resto. Con dos clics estarás extrayendo datos sin escribir ni una sola línea de código.
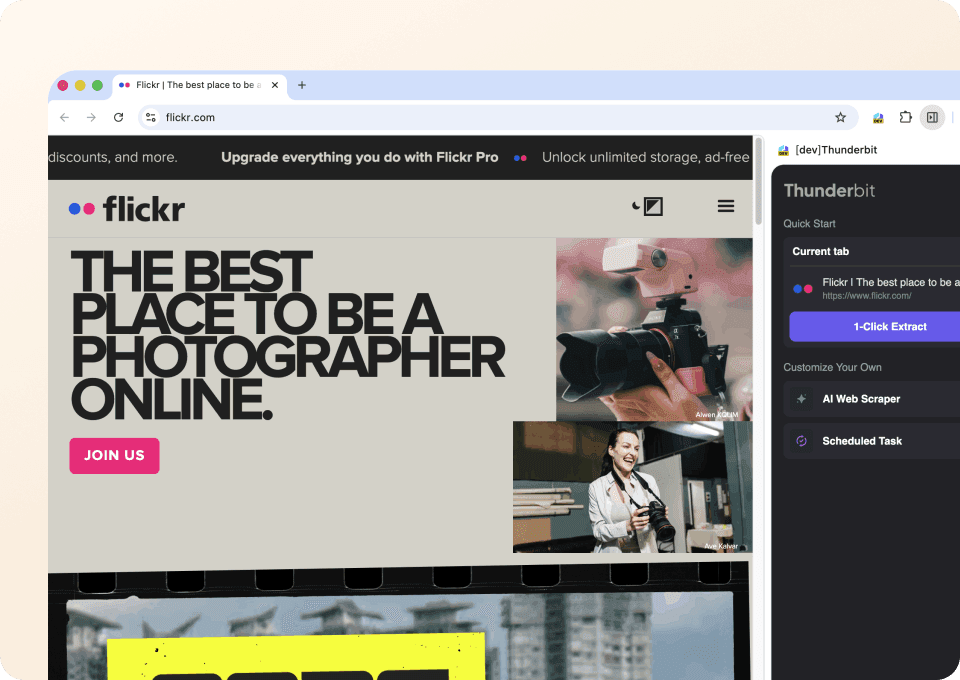
Obtén todos los detalles de las fotos de Flickr
Las páginas de búsqueda o galerías de Flickr solo muestran información básica. Para ver el panorama completo, necesitas los detalles de cada página individual de la foto. Thunderbit puede visitar automáticamente cada subpágina enlazada, recopilar la descripción, las etiquetas y otros detalles, y añadirlos como nuevas columnas en tu exportación de datos. Se acabó hacer clic y copiar página por página manualmente.
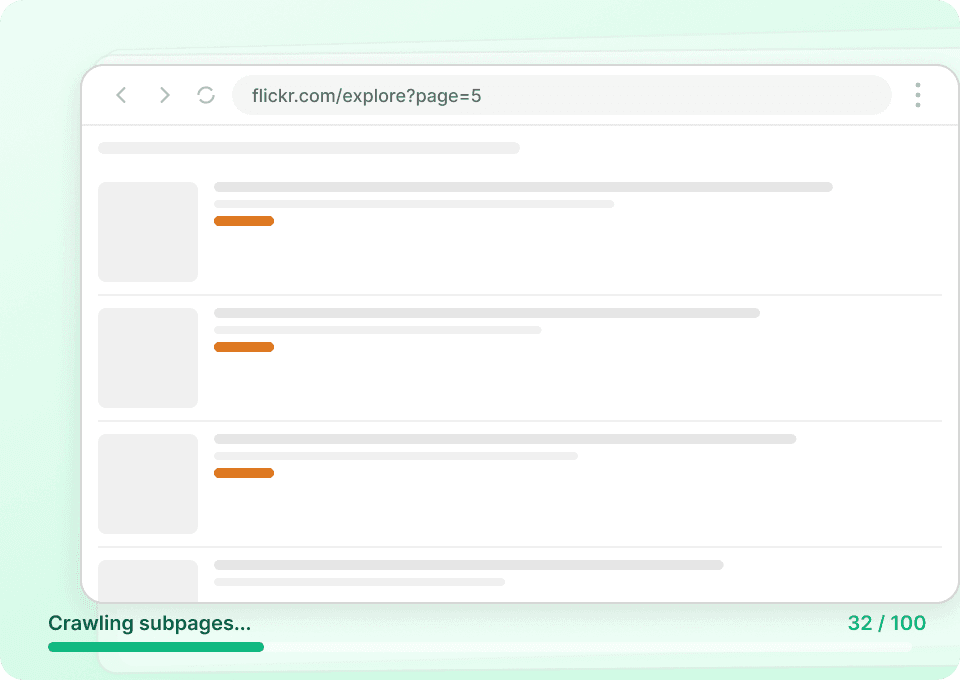
Extracción masiva de datos de Flickr
Extraer datos de Flickr foto por foto es lento y poco práctico. En lugar de navegar manualmente y recopilar datos de páginas individuales, Thunderbit te permite introducir varias URLs de Flickr. Luego visita cada página, extrae el título de la foto, el nombre de usuario del autor y otros datos, y lo consolida todo por ti.

¿Por qué Thunderbit es diferente de los scrapers de Flickr tradicionales?
Extrae datos de Flickr sin las complicaciones del scraping tradicional.
Scrapers tradicionales
La forma clásica de hacerloThunderbit IA
La opción más inteligenteNo te quedes solo con nuestra palabra
Mira lo que dicen nuestros usuarios sobre Thunderbit.





Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.

Raspador de United Airlines
Haz clic y selecciona para recopilar datos de vuelos de United Airlines, como número de vuelo, hora de llegada y aeropuerto de salida: Thunderbit AI se encarga del resto.
Más información ->Raspador de Substack
Obtén los recuentos de suscriptores de Substack, los títulos de los artículos y las descripciones de las publicaciones en una hoja de cálculo limpia: sin código; la IA se encarga de estructurarlo.
Más información ->Raspador Web de On the Beach
El Raspador Web de On the Beach de Thunderbit te permite extraer listados de vacaciones y hoteles, precios, valoraciones y mucho más de On the Beach en solo dos clics. Aprovecha las sugerencias inteligentes de campos impulsadas por IA para recopilar y organizar datos de viajes de forma rápida, ya sea para análisis, comparación o planificación. Perfecto para profesionales del sector turístico, analistas y quienes organizan vacaciones.
Más información ->
Raspador Web de UNIQLO
Extrae datos de productos de Uniqlo, como nombres, precios y tallas disponibles, con solo 2 clics gracias a la extensión de Chrome de Thunderbit.
Más información ->
Raspador de Amarillas.com
El Raspador Amarillas.com de Thunderbit te permite extraer datos estructurados de Amarillas.com, incluyendo listados de moteles y restaurantes. Aprovecha las sugerencias inteligentes de campos impulsadas por IA para recopilar rápidamente nombres de negocios, ubicaciones, teléfonos, calificaciones y reseñas, ideal para investigación, marketing o generación de prospectos.
Más información ->Raspador DialIndia
El Raspador DialIndia de Thunderbit te permite extraer datos de los perfiles de negocios y directorios de viajes de DialIndia con sugerencias de campos impulsadas por IA. Recopila nombres de empresas, datos de contacto, ubicaciones y descripciones para investigación, marketing o generación de prospectos en solo unos clics.
Más información ->¿Listo para potenciar al máximo tu extracción de datos?
Únete a los más de 100,000 profesionales que ya usan Thunderbit para automatizar sus flujos de trabajo de web scraping.
La prueba gratis ofrece créditos ilimitados para 8 páginas web.