Raspador de Artículos














Desbloquea datos de artículos con facilidad
Extrae los puntos clave de los artículos sin necesidad de saber programar.
Se mantiene actualizado automáticamente
¿Cansado de que los extractores dejen de funcionar cada vez que un sitio de noticias rediseña su diseño? Thunderbit entiende el significado de la página, no solo posiciones fijas de elementos. Extrae títulos, autores y contenido de forma fiable, incluso cuando los sitios actualizan su estructura.

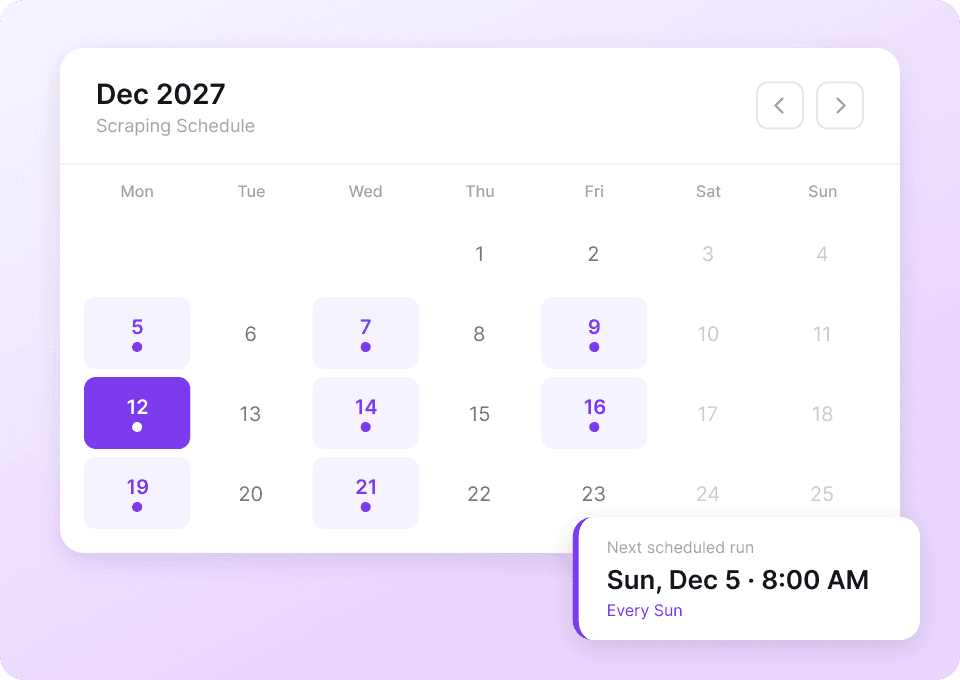
Automatiza la recopilación de datos de artículos
Los metadatos de los artículos, como fechas de publicación, palabras clave y categorías, cambian constantemente. Programa Thunderbit para extraer datos en piloto automático y recibe contenido actualizado directamente en Google Sheets, Notion o Airtable, sin trabajo manual.
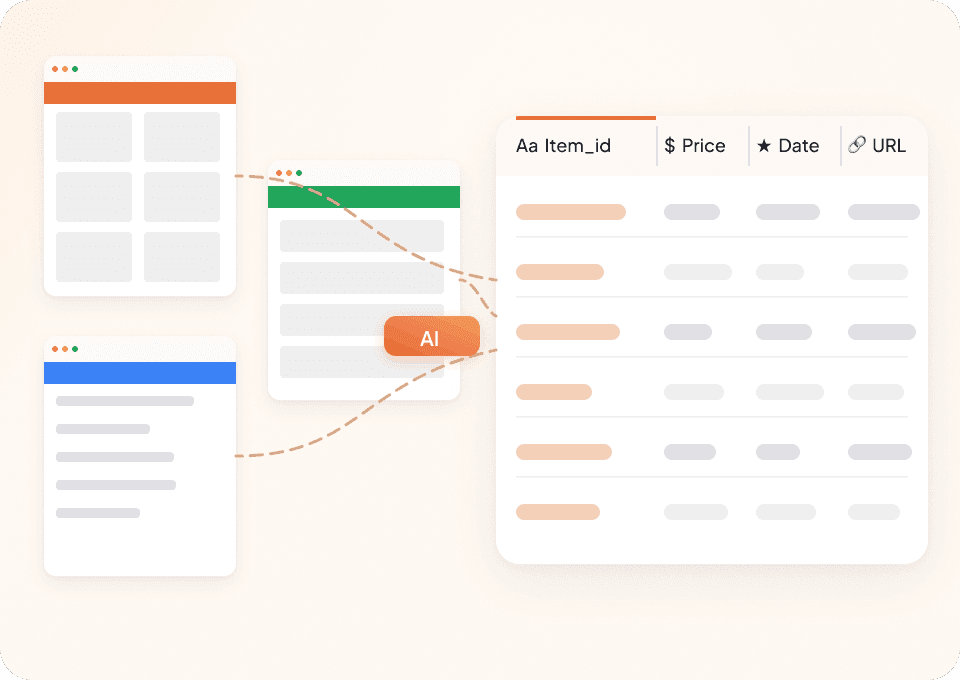
Extrae datos de cualquier sitio web
¿Por qué usar un extractor distinto para cada medio de noticias? Thunderbit funciona en cualquier sitio desde el primer momento. Con más de 50 plantillas preconfiguradas, recopilar datos de artículos —sin importar la publicación— solo requiere unos pocos clics.
¿Por qué Thunderbit es diferente de los extractores de artículos tradicionales?
Thunderbit utiliza IA para extraer datos de artículos de forma rápida y fiable.
Extractores tradicionales
La forma antigua de hacerloThunderbit AI
El enfoque más inteligenteNo te quedes solo con nuestra palabra
Mira lo que nuestros usuarios dicen sobre Thunderbit.






Preguntas frecuentes
Relacionados casos de uso
Explora más casos de uso del web scraper de Thunderbit.

Raspador de iBegin
El Raspador Web de iBegin de Thunderbit te permite extraer resultados de búsqueda de negocios e información detallada de empresas desde el sitio web de iBegin. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar rápidamente nombres de negocios, datos de contacto, direcciones, valoraciones y mucho más, ideal para generación de leads, investigación o análisis de marketing.
Más información ->
Raspador Web de HKTVmall
Extrae nombres de productos, precios, valoraciones y más de los listados de HKTVmall en solo 2 clics, sin necesidad de programar. Exporta directamente a Excel, Google Sheets o Notion y convierte los datos de HKTVmall en información útil y accionable.
Más información ->Raspador de Substack
Extrae en 2 clics el número de suscriptores de Substack, títulos de artículos y descripciones de publicaciones — y luego expórtalos a Excel, Google Sheets o Notion. No necesitas programar; la IA de Thunderbit se encarga de estructurarlo todo por ti.
Más información ->
Raspador de Amarillas.com
El Raspador Amarillas.com de Thunderbit te permite extraer datos estructurados de Amarillas.com, incluyendo listados de moteles y restaurantes. Aprovecha las sugerencias inteligentes de campos impulsadas por IA para recopilar rápidamente nombres de negocios, ubicaciones, teléfonos, calificaciones y reseñas, ideal para investigación, marketing o generación de prospectos.
Más información ->
Raspador de Herold
El Raspador Herold de Thunderbit te permite extraer datos de los resultados de búsqueda de empresas y personas en Herold en apenas 2 clics. Aprovecha las sugerencias inteligentes impulsadas por IA para recopilar nombres de empresas, direcciones, teléfonos, correos electrónicos y mucho más, ideal para generación de leads, investigación o marketing. Perfecto para equipos de ventas, marketing e investigadores que necesitan datos estructurados de Herold.
Más información ->Raspador DialIndia
El Raspador DialIndia de Thunderbit te permite extraer datos de los perfiles de negocios y directorios de viajes de DialIndia con sugerencias de campos impulsadas por IA. Recopila nombres de empresas, datos de contacto, ubicaciones y descripciones para investigación, marketing o generación de prospectos en solo unos clics.
Más información ->¿Listo para potenciar tu extracción de datos?
Join 200,000+ professionals already using Thunderbit to automate their web scraping workflows.
La prueba gratuita ofrece créditos ilimitados para 8 páginas web.



