

El web scraping se ha vuelto el as bajo la manga para los equipos empresariales modernos. Ya sea que trabajes en ventas, operaciones o marketing, poder recolectar datos de la web de manera rápida puede marcar la diferencia en el éxito de tu próximo gran proyecto. Con la importancia cada vez mayor de tomar decisiones basadas en datos, las empresas buscan herramientas que no solo sean veloces, sino también confiables y que puedan crecer con el negocio. Aquí es donde Rust entra en escena: un lenguaje de programación moderno que está ganando popularidad en el mundo del raspador web rust, sobre todo para equipos que buscan velocidad y seguridad.
No es solo una tendencia pasajera: Rust ha sido elegido como el “lenguaje de programación más querido” en la Encuesta de Desarrolladores de Stack Overflow durante varios años seguidos, y cada vez más se usa en backend e ingeniería de datos. Pero, ¿qué significa realmente web scraping en rust para quienes trabajan en negocio? ¿Y cómo se compara con soluciones sin código como Thunderbit, pensadas para equipos que no son técnicos? Te lo explico fácil—no necesitas ser programador para entenderlo.
¿Qué es el Web Scraping con Rust? Conceptos Básicos
En pocas palabras, el raspador web rust es el proceso de extraer datos automáticamente de páginas web. Imagina que tienes un asistente digital que visita cientos o miles de páginas, copia la información que te interesa—como precios, contactos o reseñas—y te la entrega en un formato ordenado. Esto ahorra muchísimo tiempo a las empresas que necesitan datos frescos para generar leads, hacer estudios de mercado, monitorear precios y mucho más.
Rust es un lenguaje de programación conocido por su velocidad, su seguridad en el manejo de memoria y su fiabilidad. A diferencia de lenguajes más viejos que pueden ser lentos o propensos a errores, Rust está diseñado para detectar fallos antes de que el código corra. Para el raspador web rust, esto significa que puedes crear herramientas súper rápidas y menos propensas a caídas o fugas de memoria—una ventaja enorme cuando necesitas extraer grandes cantidades de datos.
Pero aquí está el detalle: aunque Rust es el favorito de muchos programadores, sus beneficios también llegan a los equipos de negocio. Un scraping más rápido y seguro significa datos más actualizados, menos errores y análisis más confiables para tu equipo.
¿Por Qué Elegir Rust para Web Scraping? Ventajas Clave para Empresas
Entonces, ¿por qué cada vez más equipos se animan a usar Rust para web scraping, cuando Python y JavaScript han sido los clásicos de siempre? Aquí tienes las ventajas principales:
- Velocidad brutal: Rust se compila directamente a código de máquina, así que es mucho más rápido que lenguajes interpretados como Python o JavaScript. Si tienes que scrapear millones de páginas, esa velocidad se traduce en valor real para tu negocio.
- Seguridad en memoria: El sistema de manejo de memoria de Rust (sin recolector de basura y con reglas estrictas de propiedad) reduce los errores y los bloqueos. Tus tareas de scraping tienen menos chances de fallar a mitad de camino, ahorrando tiempo y dolores de cabeza.
- Fiabilidad: El compilador de Rust exige chequeos estrictos de tipos y manejo de errores, detectando muchos problemas antes de que el código corra. Esto se traduce en flujos de scraping más estables y predecibles.
- Concurrencia: Rust facilita escribir código que hace muchas cosas a la vez (más sobre esto en la siguiente sección), lo cual es clave para scrapear muchas páginas en paralelo.
¿Y cómo se compara con Python o JavaScript? Aunque estos lenguajes son más fáciles para empezar, pueden quedarse cortos en velocidad y fiabilidad cuando el scraping es a gran escala. Las ventajas técnicas de Rust te permiten recolectar más datos, más rápido y con menos líos—dándole a tu empresa una ventaja real.
El Poder Asíncrono de Rust: Web Scraping Eficiente a Gran Escala
Aquí es donde Rust realmente brilla: la programación asíncrona. En palabras simples, el código asíncrono permite que tu raspador web rust obtenga datos de muchos sitios a la vez, sin tener que esperar a que cada uno termine antes de empezar el siguiente. Esto es un cambio total cuando necesitas recolectar grandes volúmenes de datos rápido.
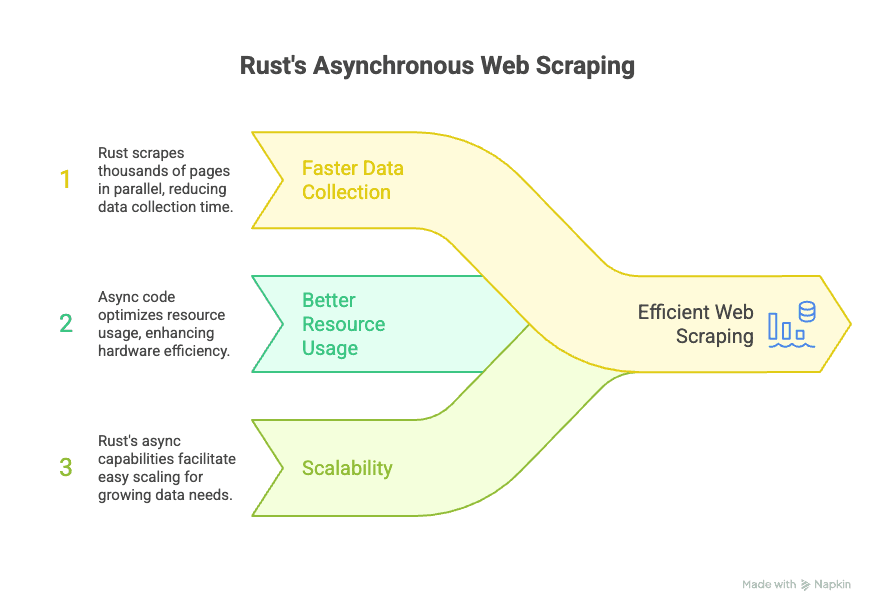
El ecosistema asíncrono de Rust se apoya en librerías como Tokio y async-std, que permiten que tu raspador maneje miles de solicitudes al mismo tiempo sin trabar el proceso principal. Para los equipos de negocio, esto significa:
- Recopilación de datos más veloz: Extrae miles de páginas en paralelo, reduciendo muchísimo el tiempo para armar tu base de datos.
- Mejor uso de recursos: El código asíncrono es más eficiente, así que puedes hacer más con menos computadoras.
- Escalabilidad: Si tus necesidades de datos crecen, las capacidades asíncronas de Rust facilitan escalar sin tener que rehacer todo tu flujo de trabajo.
En la práctica, esto permite que tu equipo reaccione a cambios del mercado, monitoree a la competencia o genere leads en tiempo real—sin tener que esperar horas (o días) a que termine la descarga de datos.
¿Cómo Funciona el Web Scraping con Rust? Paso a Paso
¿Te da curiosidad cómo es un flujo típico de raspador web rust? Aquí va una visión general, sin tecnicismos:
- Preparación: Decides qué datos quieres y de qué sitios web.
- Obtención de datos: Usas librerías como Reqwest (para hacer solicitudes HTTP) para descargar las páginas.
- Análisis del contenido: Utilizas Scraper o Select para extraer información específica (como nombres de productos, precios, emails) del HTML.
- Gestión de paginación/subpáginas: Escribes lógica para navegar por varias páginas o seguir enlaces a subpáginas (más sobre esto abajo).
- Exportación de datos: Guardas los datos extraídos en un formato ordenado—CSV, Excel o directo a una base de datos—para que tu equipo los use al instante.
Cada librería cumple su función: Reqwest se encarga de la “obtención”, Scraper/Select del “análisis”, y puedes usar funciones nativas de Rust o librerías externas para exportar y organizar los resultados.
Navegando Sitios Complejos: Cómo Rust Maneja la Paginación y Subpáginas
Muchas tareas de scraping empresarial no se quedan en una sola página. Puede que necesites:
- Extraer todos los productos de un catálogo con varias páginas
- Recopilar reseñas repartidas en diferentes subpáginas
- Obtener datos de contacto de directorios anidados
Rust es ideal para estos desafíos. Su sistema de tipos y manejo de errores hace fácil escribir código capaz de:
- Detectar y seguir automáticamente botones de “Siguiente” o enlaces de paginación
- Visitar subpáginas (como detalles de productos o biografías de autores) y juntar esos datos en tu base principal
- Gestionar cambios inesperados (como páginas que faltan o enlaces rotos) sin que el raspador se caiga
Por ejemplo, un raspador web rust puede empezar en una lista principal de productos, seguir cada enlace de paginación y luego visitar la página de detalle de cada producto—recopilando precio, descripción y reseñas en el proceso. ¿El resultado? Un set de datos completo y actualizado, listo para analizar.
Thunderbit vs. Programar en Rust: La Ventaja No-Code para Empresas
Ahora, hablemos de lo obvio: no todo el mundo tiene tiempo (ni conocimientos técnicos) para crear un raspador web rust desde cero. Aquí es donde entra Thunderbit.
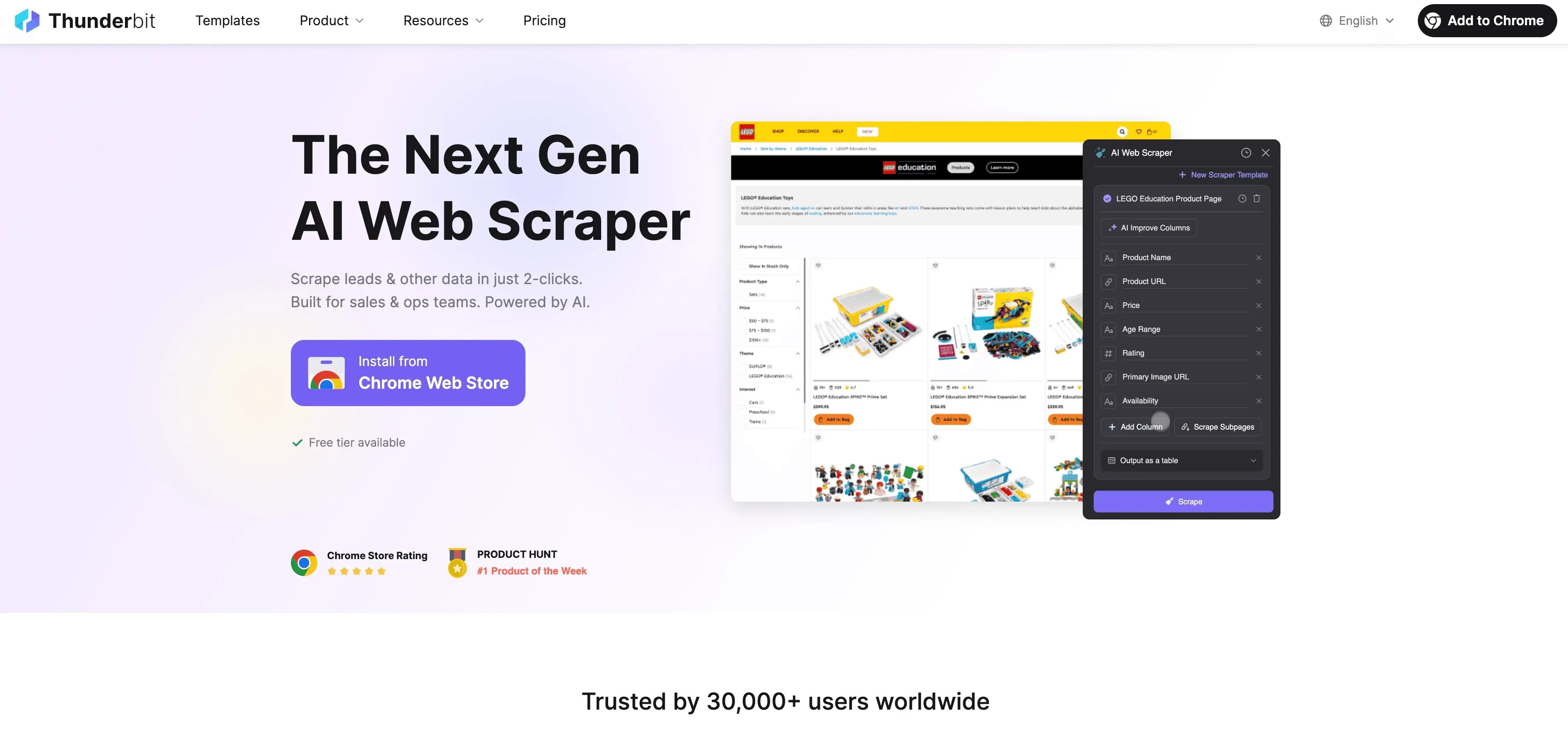
Thunderbit es un raspador web IA sin código pensado para usuarios de negocio. En vez de programar, solo tienes que:
- Abrir la extensión de Chrome de Thunderbit
- Ir al sitio web que quieres extraer
- Hacer clic en “AI Suggest Fields” y dejar que la IA de Thunderbit te recomiende qué datos extraer
- Pulsar “Scrape” y exportar los resultados directo a Excel, Google Sheets, Airtable o Notion
Sin plantillas, sin código, sin mantenimiento. Thunderbit incluso gestiona paginación y subpáginas automáticamente—igual que un raspador web rust personalizado, pero con una interfaz de apuntar y hacer clic.
Prueba Thunderbit AI Web Scraper Gratis
¿Cuándo Usar Thunderbit en Lugar de Rust? Elige la Herramienta Adecuada
Entonces, ¿qué opción le conviene más a tu equipo? Aquí tienes una guía rápida:
| Escenario | Thunderbit | Rust |
|---|---|---|
| Generación rápida de leads para ventas | ✅ Más fácil y rápido | Posible, pero excesivo |
| Monitoreo de precios de la competencia (ecommerce) | ✅ Sin código, programable | ✅ Para integraciones personalizadas |
| Scraping de flujos complejos y personalizados | Posible, pero limitado | ✅ Control total, altamente personalizable |
| Grandes volúmenes y pipelines de datos integrados | Posible (con API) | ✅ Lo mejor para integración profunda |
| Usuarios no técnicos (ventas, operaciones, marketing) | ✅ Pensado para ti | ❌ Requiere conocimientos de programación |
| Prototipos rápidos o tareas puntuales | ✅ Configuración en 2 clics | Posible, pero más lento de arrancar |
En resumen: Thunderbit es ideal para usuarios de negocio que quieren extraer datos de forma rápida y confiable, sin enredos técnicos. Rust es la mejor opción cuando necesitas control total, lógica personalizada o scraping a gran escala.
Ejemplo Práctico: Web Scraping con Rust en Acción
Veamos un caso real. Imagina que eres analista de mercado y necesitas recolectar datos de todos los portátiles listados en un gran ecommerce. El sitio tiene paginación (varias páginas de productos) y cada producto tiene una página de detalles con especificaciones y reseñas.
Con Rust, harías lo siguiente:
- Usar Reqwest para obtener la página principal de productos
- Analizar el HTML con Scraper para extraer los enlaces de los productos
- Detectar y seguir el botón de “Siguiente” para scrapear todas las páginas
- Para cada producto, visitar la página de detalles y extraer especificaciones y reseñas
- Gestionar errores (como páginas que faltan) de forma robusta, reintentando si hace falta
- Exportar el set final de datos a CSV o a tu plataforma de análisis
¿El valor para el negocio? Obtienes una visión completa y actualizada del mercado—lo que te permite tomar mejores decisiones de precios, inventario y marketing.
Retos y Consideraciones Clave del Web Scraping con Rust
Por supuesto, incluso con las ventajas de Rust, el raspador web rust no siempre es un paseo. Aquí algunos retos comunes (y cómo Rust ayuda):
- Cambios en el sitio web: Si la estructura del sitio cambia, tu raspador puede fallar. El tipado estricto de Rust ayuda a detectar estos problemas rápido, pero tendrás que actualizar el código.
- Medidas anti-bots: Muchos sitios usan CAPTCHAs o límites de velocidad. La rapidez de Rust puede ayudarte a pasar desapercibido, pero quizá debas añadir retrasos o usar proxies.
- Formato de datos: No todos los datos están limpios—las potentes herramientas de análisis de Rust facilitan tratar con HTML desordenado o inconsistente.
- Mantenimiento: Los raspadores personalizados requieren mantenimiento constante. Para equipos de negocio, esto implica trabajar con técnicos o considerar herramientas sin código como Thunderbit para tareas rutinarias.
¿Qué es el Data Scraping y Cómo Hacerlo en 2025 Get Started Free
Tip profesional: Ya uses Rust o Thunderbit, respeta siempre los términos de servicio y las leyes de privacidad de los sitios web al extraer datos.
Conclusión: Potencia Empresarial con Web Scraping en Rust (y Más Allá)
El raspador web rust ya es una capacidad imprescindible para cualquier empresa que quiera destacar en un mundo donde los datos mandan. Rust ofrece velocidad, seguridad y fiabilidad inigualables para equipos que necesitan soluciones personalizadas y a gran escala—sobre todo cuando la rapidez y la estabilidad son clave. Pero para la mayoría de usuarios de negocio, la barrera técnica es real.
Ahí es donde Thunderbit brilla: lleva el poder del raspador web rust a todos, con una interfaz sin código impulsada por IA que resuelve hasta tareas complejas como la paginación y la extracción de subpáginas. Ya seas comercial armando listas de leads, gestor ecommerce monitoreando precios o analista recolectando inteligencia de mercado, Thunderbit te permite conseguir los datos que necesitas—rápido.
Puntos clave:
- Rust es ideal para scraping personalizado y a gran escala—perfecto para equipos técnicos.
- Thunderbit democratiza el raspador web rust, haciéndolo accesible a usuarios sin conocimientos técnicos.
- Elige la herramienta adecuada: Rust para máxima personalización, Thunderbit para rapidez y sencillez.
Extrae datos de cualquier sitio web usando IA Get Started Free
¿Quieres probar el raspador web rust en tu empresa? Descarga Thunderbit y descubre lo fácil que es extraer datos. O, si buscas una solución a medida, explora el ecosistema de Rust para scraping de alto rendimiento.
Prueba AI Web Scraper Get Started Free
Preguntas Frecuentes
1. ¿Qué es el web scraping con Rust y en qué se diferencia de otros lenguajes?
El raspador web rust consiste en usar este lenguaje para automatizar la extracción de datos de sitios web. Rust destaca por su velocidad, seguridad en memoria y fiabilidad frente a lenguajes como Python o JavaScript, lo que lo hace ideal para scraping a gran escala o crítico para el negocio.
2. ¿Es Rust adecuado para usuarios de negocio sin conocimientos técnicos que necesitan web scraping?
Rust es muy potente, pero requiere saber programar. Para usuarios no técnicos, herramientas como Thunderbit ofrecen una solución sin código y basada en IA, haciendo que la extracción de datos sea accesible para todos.
3. ¿Cómo gestiona Rust tareas complejas como la paginación o las subpáginas?
El sistema de tipos y las librerías asíncronas de Rust facilitan escribir código que navega automáticamente por listados paginados, sigue enlaces a subpáginas y gestiona errores—logrando sets de datos más completos y confiables.
4. ¿Cuándo debería usar Thunderbit en vez de crear un raspador personalizado en Rust?
Usa Thunderbit cuando necesites extraer datos de forma rápida y sencilla, sin programar—ideal para equipos de ventas, marketing y operaciones. Elige Rust para flujos de scraping muy personalizados, a gran escala o que requieran integración técnica avanzada.
5. ¿Cuáles son los principales retos del web scraping con Rust y cómo se pueden gestionar?
Los retos habituales incluyen cambios en los sitios web, medidas anti-bots y mantenimiento constante. Las características de seguridad de Rust ayudan a detectar errores rápido, pero tendrás que actualizar el código a medida que los sitios evolucionan. Para scraping rutinario en empresas, una herramienta sin código como Thunderbit ahorra tiempo y evita complicaciones.
Más información:




