Déjame contarte cómo era mi día a día cuando empecé como product manager: conseguir datos era convencer a un desarrollador con un café o pasar horas copiando y pegando tablas en Excel. (Todavía tengo pesadillas con esas eternas sesiones de Ctrl+C y Ctrl+V). Hoy, estamos rodeados de datos: solo el mercado de software de raspado web se calcula que llegará a los para 2036. Pero aquí está el detalle: la mayoría de esos datos están atrapados en pantallas, repartidos entre webs, PDFs y apps que no te lo ponen nada fácil para exportar.
Aquí es donde entra el screen scraping IA: una técnica clásica que ha recibido un empujón gracias a la inteligencia artificial. Ya sea que trabajes en ventas, e-commerce, inmobiliaria o simplemente seas fan de las hojas de cálculo (sin juzgar), entender cómo funciona el screen scraping moderno —y cómo herramientas con IA como lo ponen al alcance de cualquiera— puede cambiar tu forma de trabajar. Vamos a verlo en detalle.
¿Qué es el Screen Scraping? Explicación sencilla de la extracción de datos
El screen scraping, básicamente, es como mirar una pantalla y apuntar lo que ves, pero dejando que un robot lo haga por ti. Se trata de extraer datos de la interfaz visual de una app, página web o incluso un PDF, y convertirlos en información útil para otros usos ().
Piénsalo así: si alguna vez copiaste una tabla de una web a Excel, ya hiciste screen scraping a mano. La diferencia es que, con automatización, no desgastas las teclas Ctrl y V. En vez de eso, usas un software que “lee” lo que aparece en pantalla, a veces incluso con visión por computadora u OCR si el texto no se puede seleccionar.
El screen scraping suele confundirse con el raspado web y la extracción de datos. Aquí va una explicación rápida:
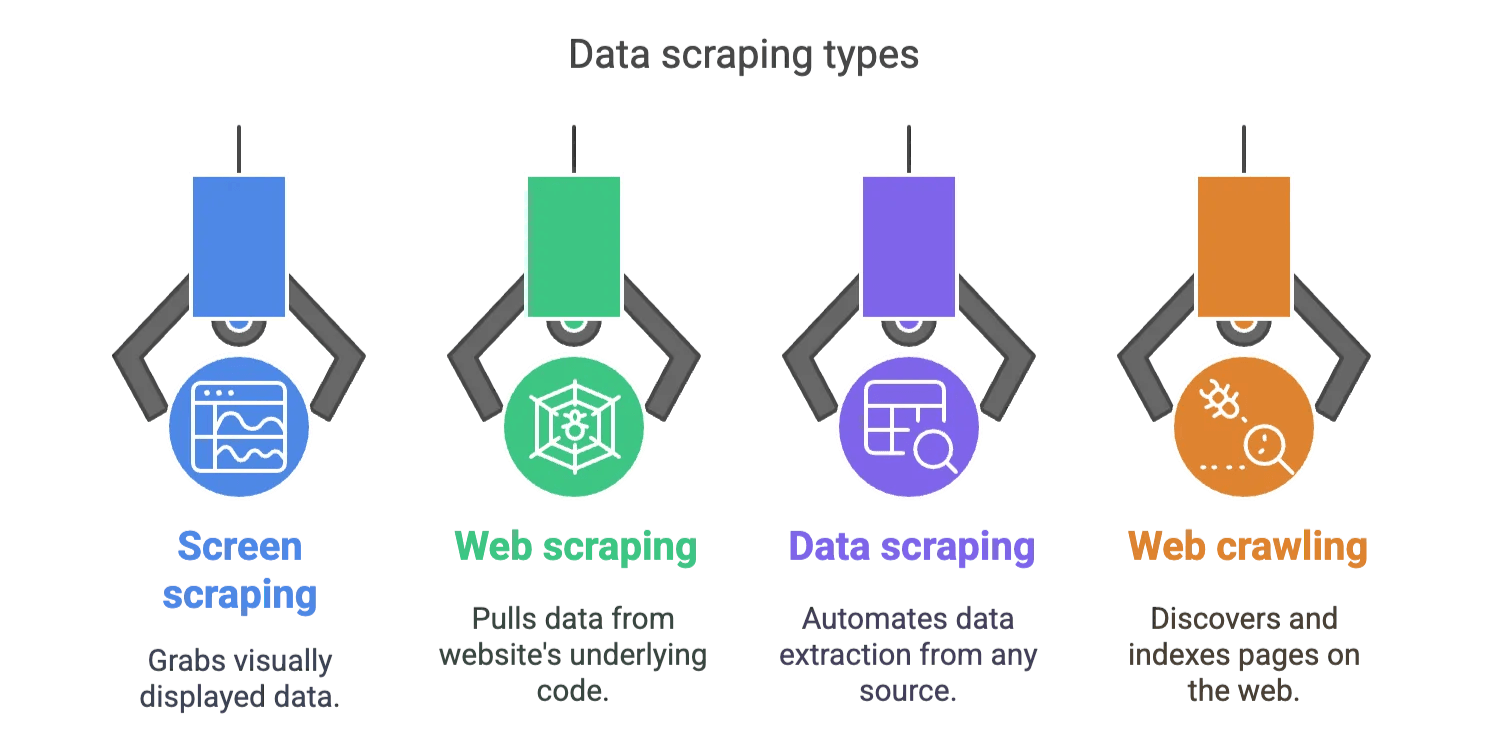
- Screen scraping: Captura lo que ves en pantalla.
- Web scraping: Extrae datos del código fuente (HTML, JSON, etc.) de una web.
- Data scraping: Término general para automatizar la extracción de datos de cualquier fuente (web, apps, archivos, etc.).
- Web crawling: Descubre e indexa páginas, pero no necesariamente extrae datos de ellas.
Así que, si necesitas información de una app antigua, un PDF bloqueado o una web que no deja exportar, el screen scraping es tu mejor amigo.
Screen Scraping vs. Web Scraping vs. Data Scraping: ¿En qué se diferencian?
Estos términos suelen usarse como si fueran lo mismo, pero no lo son. Aquí tienes una tabla para aclararlo:
| Técnica | Qué hace | Dónde funciona | Cómo funciona | Usos comunes |
|---|---|---|---|---|
| Screen Scraping | Extrae datos de lo que se muestra en pantalla | Apps, sistemas antiguos, PDFs, webs | Lee píxeles, usa OCR o automatización de interfaz | Migración de datos, RPA, sistemas legacy |
| Web Scraping | Extrae datos del código de la web (HTML/DOM) | Páginas web | Analiza HTML, usa peticiones HTTP, navega el DOM | Monitoreo de precios, generación de leads, investigación |
| Data Scraping | Automatiza la extracción de cualquier fuente de datos | Web, archivos, bases de datos, logs, etc. | Cualquier método automatizado (scraping, parsing, queries) | Integración de datos, analítica |
| Web Crawling | Descubre e indexa páginas web | Internet | Sigue enlaces, construye listas de URLs | Motores de búsqueda, mapas de sitios |
¿Por qué tanta confusión? Porque muchas veces estas técnicas se mezclan. Por ejemplo, un crawler encuentra todas las páginas de un sitio, luego un raspador extrae los datos, y si solo están visibles en pantalla (no en el código), ahí entra el screen scraping.
¿Por qué el Screen Scraping es importante para los negocios? Casos de uso reales
Vamos a lo práctico: ¿por qué las empresas se interesan por el screen scraping, raspado web y extracción de datos? Porque los datos son poder, y casi nunca te los dan en bandeja.
Algunos ejemplos reales:
| Equipo | Caso de uso | Beneficio | Ejemplo de ROI |
|---|---|---|---|
| Ventas | Generación de leads desde directorios | Más prospectos, menos trabajo manual | +5 horas/semana ahorradas por comercial (Usuarios de Thunderbit) |
| E-commerce | Monitoreo de precios de la competencia | Precios dinámicos, mayor margen | 4% de aumento en ventas (John Lewis) |
| Inmobiliaria | Agregación de anuncios de propiedades | Análisis de mercado más rápido | Más operaciones, mejores decisiones de inversión |
| Marketing | Extracción de reseñas/datos sociales | Análisis de sentimiento, ROI de campañas | Mejor segmentación, respuesta más ágil |
| Operaciones | Extracción de datos de portales de proveedores | Reportes automáticos, menos errores | Menos entrada manual, menos fallos |
Y esto es solo el principio. He visto equipos usar scraping para migrar contenido, monitorear cumplimiento o crear dashboards internos que harían envidiar a cualquier analista de datos.
Herramientas tradicionales de Screen Scraping: cómo funcionan y sus limitaciones
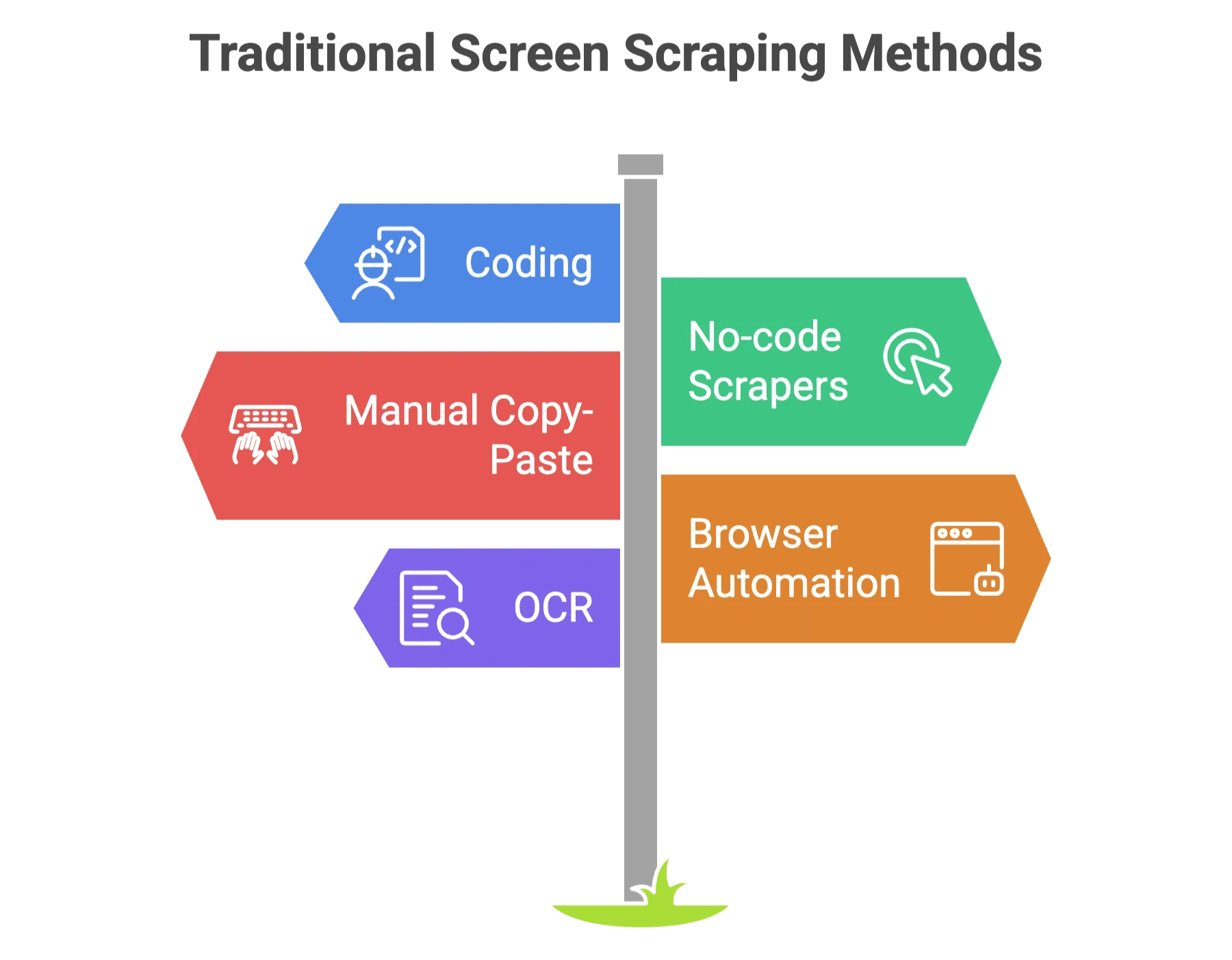
Antes de la IA, el screen scraping era como armar un mueble sin instrucciones. Tenías dos opciones principales:
- Programar: Escribir scripts a medida (Python, JavaScript, etc.) para obtener y procesar datos. Ideal si te gusta depurar código a las 2 de la mañana.
- Scrapers sin código: Herramientas visuales donde seleccionas manualmente qué extraer. Más sencillo, pero si la web cambia, tu configuración puede romperse en un instante.
Otros métodos clásicos:
- Copiar y pegar a mano: Lento, propenso a errores y agotador.
- Automatización de navegador (Selenium, Playwright): Simula un usuario real, pero requiere conocimientos técnicos.
- OCR: Cuando los datos están en imágenes o PDFs escaneados.
¿Los principales problemas?
- La configuración es lenta y técnica.
- El mantenimiento es un dolor de cabeza: cualquier cambio en la web puede romper tu raspador.
- Transformar los datos es limitado: obtienes datos en bruto y tú te encargas de darles utilidad.
- Los usuarios no técnicos quedan fuera.
Si alguna vez has pasado más tiempo arreglando un raspador que usando los datos, sabes de lo que hablo.
Llega el Screen Scraping con IA: cómo la inteligencia artificial cambia el juego
Aquí es donde la cosa se pone interesante. El screen scraping con IA cambia las reglas. En vez de pelearte con selectores o escribir código frágil, dejas que un agente de IA haga el trabajo pesado.
¿Cómo funciona esto?
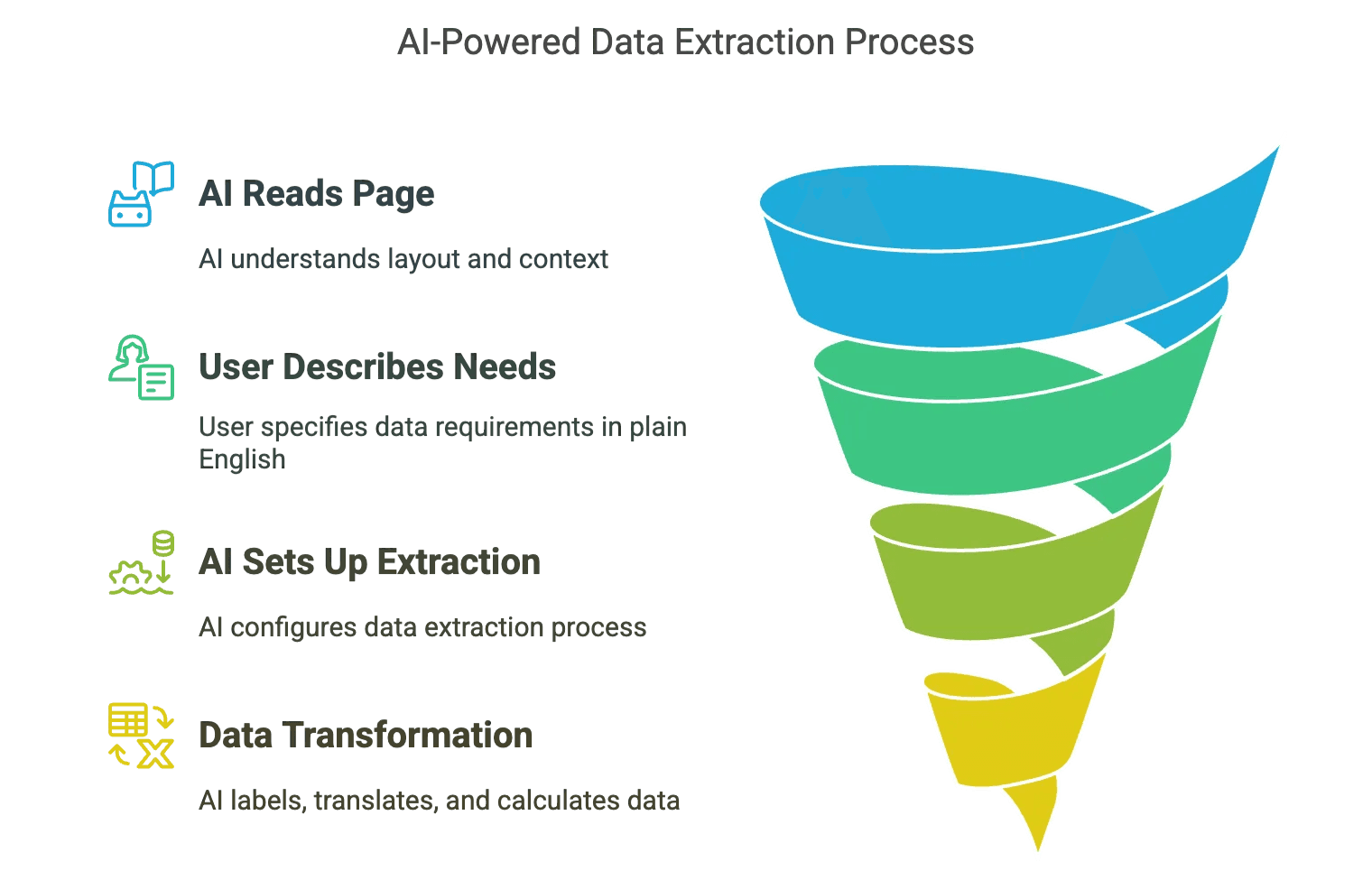
- La IA “lee” la página como una persona: Analiza el diseño, entiende el contexto y detecta lo importante, incluso si la web cambia.
- Tú describes lo que quieres en lenguaje natural: “Quiero los nombres de los productos, precios e imágenes”, y la IA configura la extracción.
- La transformación de datos es automática: Etiquetado, traducción, cálculos... la IA lo gestiona mientras extrae.
Esto significa:
- Olvídate de configuraciones manuales.
- No más mantenimiento constante.
- Cualquiera puede hacerlo, no solo los desarrolladores.
Por ejemplo, con , puedes extraer datos de cualquier web, sin importar su estructura, porque la IA se adapta en tiempo real. ¿Necesitas transformar o etiquetar datos sobre la marcha? Thunderbit lo hace fácil. ¿Lo mejor? Es realmente sencillo de usar.
Thunderbit: El Raspador Web IA más fácil para todos
Ahora, un poco de autopromoción, pero sinceramente, por esto creamos :
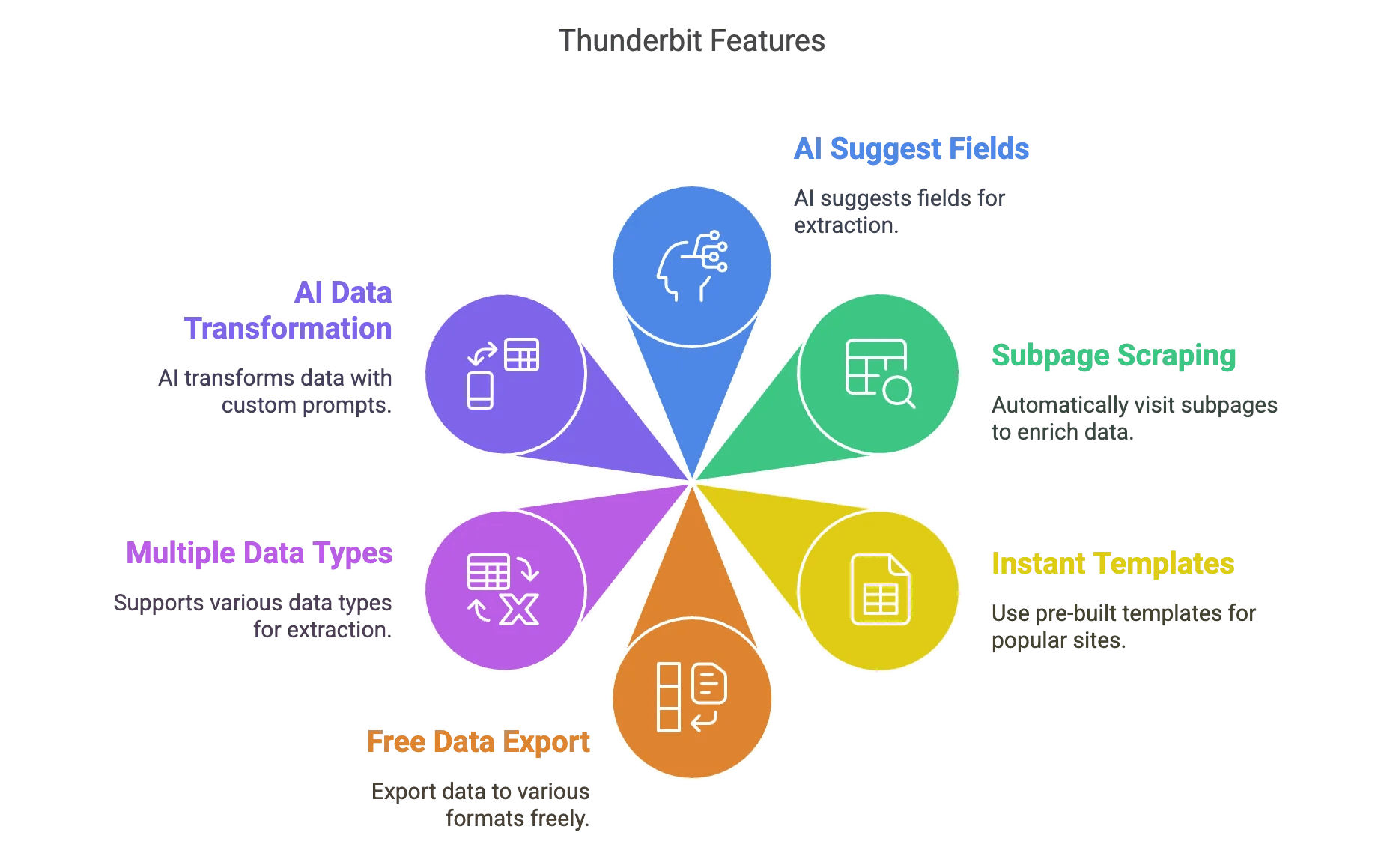
- Sugerencia de campos con IA: Un solo clic y la IA de Thunderbit analiza la página y te sugiere los mejores campos para extraer. Sin adivinar ni pelearte con selectores.
- Extracción en subpáginas: ¿Necesitas más detalles? Thunderbit puede visitar automáticamente cada subpágina (como fichas de productos o perfiles) y enriquecer tu base de datos.
- Plantillas instantáneas: Para sitios populares (Amazon, Zillow, Instagram, Shopify, etc.), usa plantillas predefinidas y obtén los datos en un clic.
- Exportación gratuita de datos: Exporta a Excel, Google Sheets, Airtable, Notion, CSV o JSON, sin costes extra.
- Múltiples tipos de datos: Texto, números, fechas, URLs, emails, teléfonos, imágenes... lo que necesites.
- Transformación de datos con IA: Añade prompts personalizados para etiquetar, formatear o traducir datos mientras los extraes.
Y sí, todo esto está en una que realmente es fácil y hasta entretenida de usar (al menos, tanto como puede serlo la extracción de datos).
Cómo funciona el Screen Scraping con IA: paso a paso
Así es un flujo de trabajo típico de screen scraping con IA usando Thunderbit:
- Instala la extensión de Chrome de Thunderbit.
- Descárgala desde la .
- Ve a la web o PDF que quieres extraer.
- Thunderbit funciona con webs, PDFs e incluso imágenes.
- Haz clic en “Sugerir campos con IA”.
- La IA analiza la página y sugiere columnas (por ejemplo, Nombre, Precio, Email, Imagen).
- Revisa y ajusta los campos si es necesario.
- Añade o renombra columnas, define tipos de datos o agrega prompts personalizados para etiquetar o traducir.
- Haz clic en “Extraer”.
- Thunderbit obtiene los datos y los muestra en una tabla estructurada.
- (Opcional) Extrae subpáginas.
- Si quieres más detalles, deja que Thunderbit visite cada enlace y recoja información adicional.
- Exporta tus datos.
- Descarga en CSV, Excel o envía directamente a Google Sheets, Airtable o Notion.
Consejos para mejores resultados:
- Usa nombres de campo claros (ejemplo: “Nombre del producto”, “Precio en USD”).
- Añade prompts para formatos especiales o traducción.
- Elige el tipo de dato adecuado para cada campo.
Para más tutoriales paso a paso, visita nuestro o nuestro .
Ejemplo práctico: Extracción de leads de una web con Thunderbit
Supón que eres comercial y buscas leads en un directorio sectorial. Así lo haría yo:
- Abre la página del directorio.
- Haz clic en la extensión de Thunderbit y pulsa “Sugerir campos con IA”.
- Thunderbit sugiere: Nombre, Empresa, Email, Teléfono, Web.
- Ajusto las columnas, añadiendo por ejemplo “Ubicación” o “Sector”.
- Pulso “Extraer”. Thunderbit recopila todos los leads visibles en una tabla.
- Algunos leads tienen perfiles detallados. Pulso “Extraer subpáginas” y Thunderbit visita cada uno, obteniendo info extra como URLs de LinkedIn o biografías.
- Exporto la lista a Excel o Google Sheets, lista para contactar.
Sin código, sin complicaciones y sin tener que sobornar a desarrolladores con café.
Más allá del texto: scraping avanzado con IA (imágenes, etiquetas, traducciones y más)
Los raspadores modernos con IA no solo extraen texto. Con Thunderbit puedes:
- Extraer imágenes: Perfecto para catálogos de productos o anuncios inmobiliarios.
- Obtener emails y teléfonos: Thunderbit detecta y formatea estos campos automáticamente.
- Traducir datos al instante: Extrae de una web en francés y obtén los datos en español.
- Etiquetar o categorizar datos: Usa prompts de IA para clasificar, resumir o agrupar entradas.
- Integrar con Notion, Airtable y más: Envía tus datos directamente a tus herramientas favoritas.
Esto es una gran ventaja para equipos de negocio. Imagina enriquecer tu CRM con imágenes, datos multilingües o leads clasificados, todo de una vez.
Para flujos de trabajo avanzados, consulta y .
Legalidad y seguridad: lo que las empresas deben saber
El screen scraping es potente, pero hay que hacerlo bien. Mis recomendaciones:
- Revisa los términos de uso de la web: Algunas prohíben el scraping. Si tienes dudas, pide permiso o busca una API oficial.
- Respeta el robots.txt: No es legalmente vinculante, pero es una buena práctica y ayuda a evitar bloqueos.
- Evita extraer datos tras login (salvo que sean tuyos): Aquí empiezan los problemas legales.
- Cuida los datos personales: GDPR, CCPA y otras leyes de privacidad aplican si extraes nombres, emails, etc.
- No sobrecargues los servidores: Usa límites de velocidad y sé un buen ciudadano digital.
Para un análisis legal más profundo, consulta ¿Es legal extraer datos de LinkedIn? y .
Resumen: el futuro del Screen Scraping con IA
El screen scraping ha evolucionado: de ser una tarea manual y tediosa a una solución inteligente gracias a la IA. Herramientas como Thunderbit permiten a cualquiera extraer, transformar y aprovechar datos de casi cualquier fuente, sin apenas configuración y sin programar.
Lo más importante:
- El screen scraping permite acceder a datos donde las APIs no llegan.
- Las herramientas con IA lo hacen accesible para todos, no solo para desarrolladores.
- Los equipos de negocio pueden automatizar generación de leads, monitoreo de precios, investigación de mercado y más, en pocos clics.
- El uso legal y ético es fundamental: respeta siempre la fuente y la normativa.
Si quieres dejar atrás la recolección manual de datos (donde debe estar), prueba . Tus teclas Ctrl y V te lo agradecerán.
¿Quieres saber más? Visita nuestro para guías sobre , y mucho más. O instala la y comprueba lo fácil que puede ser el screen scraping.
Y si aún sigues copiando y pegando datos a mano... créeme, hay una forma mucho mejor.
Preguntas frecuentes
-
¿Funciona el screen scraping en apps móviles? Sí, el screen scraping puede aplicarse a apps móviles, sobre todo en sistemas antiguos o cerrados. Normalmente requiere automatización de la interfaz o herramientas específicas para extraer datos de la pantalla de la app.
-
¿Puede el screen scraping extraer imágenes o contenido visual? El screen scraping no se limita al texto: también puede capturar imágenes, gráficos o elementos de la interfaz, ya sea capturando regiones de la pantalla o usando visión por computadora para detectar y etiquetar contenido visual.
-
¿Qué herramientas necesito para empezar con screen scraping? Puedes comenzar con herramientas de scripting como Python y librerías como Selenium o Playwright. Para quienes no programan, existen raspadores visuales o herramientas con IA que ofrecen alternativas de apuntar y hacer clic con mínima configuración.
-
¿Cuáles son los riesgos del screen scraping? Los riesgos incluyen problemas legales, bloqueos de IP o errores en los datos. Cambios en el diseño de la pantalla pueden romper los raspadores, y extraer datos personales puede violar normativas de privacidad si no se gestiona correctamente.
Más información