
¿Alguna vez te has visto intentando seguirle el ritmo a cientos de páginas web de la competencia, solo para darte cuenta de que necesitarías un batallón (o litros de café) para copiar y pegar toda esa info a mano? Créeme, no eres el único. Hoy en día, los datos web son oro puro para ventas, marketing, investigación o cualquier operación. De hecho, el raspado web ya representa más de un tercio del tráfico en internet, y el 81% de los minoristas en EE. UU. usan raspadores automáticos para monitorear precios (scrap.io). Eso son muchísimos bots haciendo el trabajo sucio.
Pero, ¿cómo funcionan realmente estos bots? ¿Y por qué tantos equipos apuestan por Node.js—el motor de JavaScript que mueve buena parte de la web moderna—para crear su propio raspador web node? Después de años metido en el mundo SaaS y la automatización (y como CEO de Thunderbit), he visto cómo las herramientas adecuadas pueden convertir el caos de los datos web en una ventaja competitiva. Vamos a ver qué es exactamente un raspador web node, cómo funciona y cómo incluso quienes no programan pueden sacarle partido.
Raspador Web Node: Conceptos Básicos
¿Qué es el Data Scraping y Cómo Hacerlo en 2025 Get Started Free
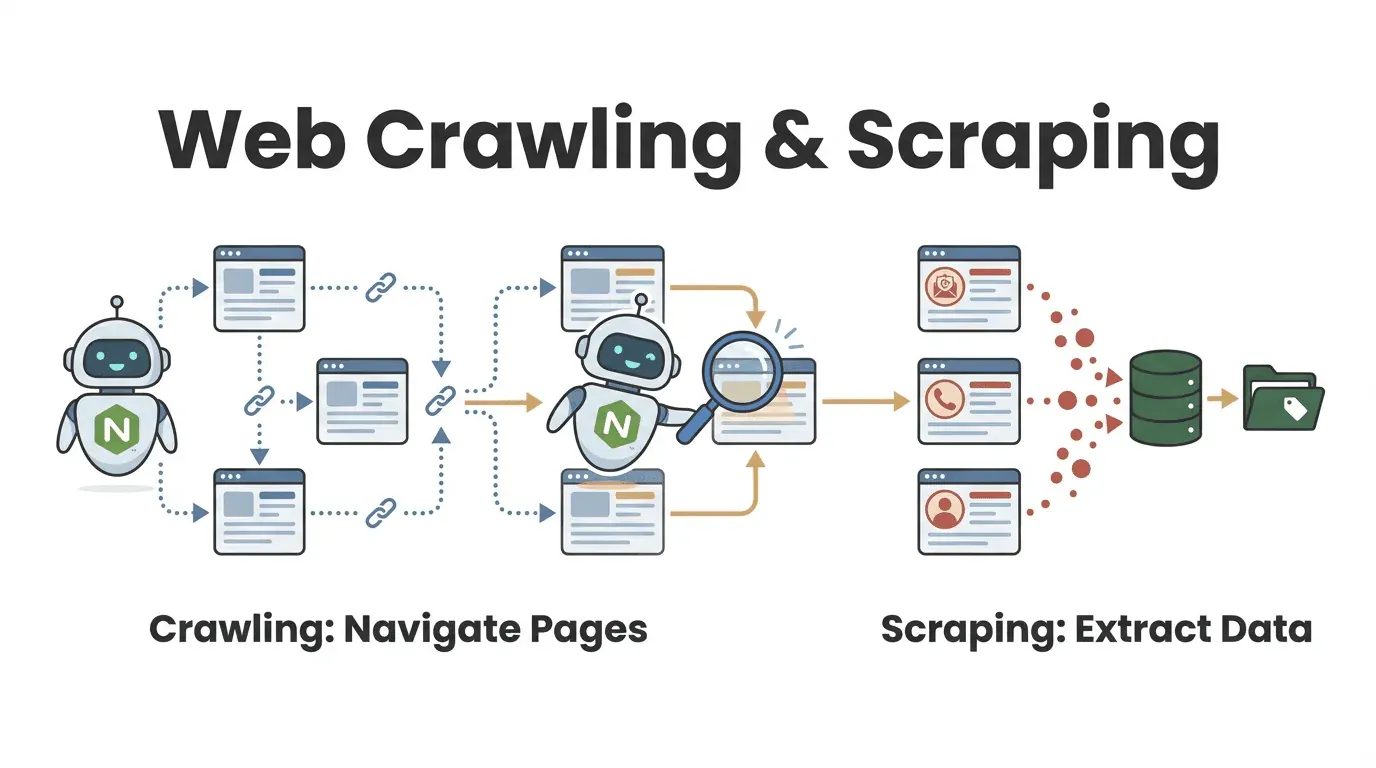
Vamos a lo básico. Un raspador web node es un programa—hecho con Node.js—que visita páginas web de forma automática, sigue enlaces y saca la información que te interesa. Imagina un asistente digital que nunca se cansa: le das una URL de inicio y va navegando por las páginas, recogiendo los datos que necesitas, hasta cubrir todo el sitio (o solo las partes que te interesan).
Pero ojo, ¿cuál es la diferencia entre web crawling y web scraping? Es una duda muy común, sobre todo si vienes del mundo de negocio:
- Web crawling es descubrir y recorrer muchas páginas. Es como pasearte por toda la biblioteca para encontrar los libros que te interesan.
- Web scraping es extraer información específica de esas páginas—como copiar las frases clave de cada libro.
En la práctica, la mayoría de los raspadores web node hacen ambas cosas: encuentran las páginas que necesitas y extraen los datos relevantes (oxylabs.io). Por ejemplo, un equipo de ventas podría rastrear un directorio para ubicar todos los perfiles de empresas y luego sacar los datos de contacto de cada una.
¿Cómo Funciona un Raspador Web Node?
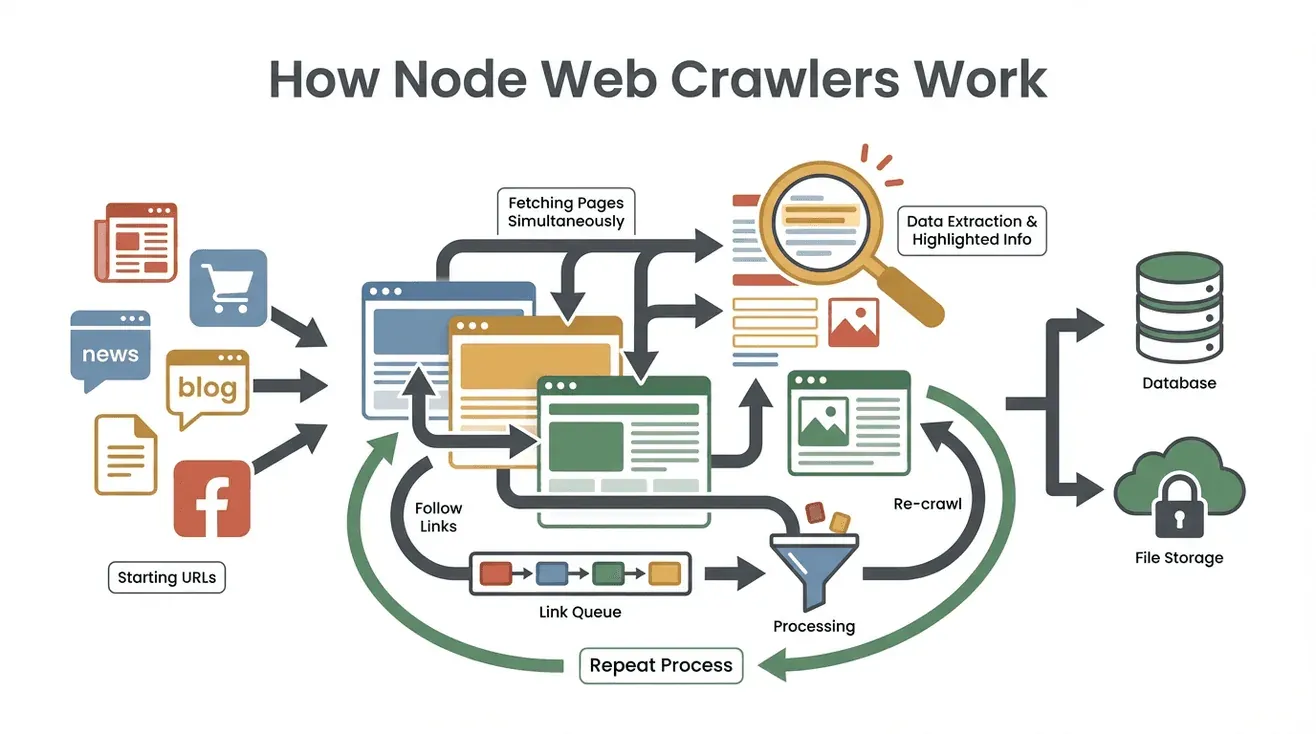 Vamos a desmenuzar el proceso. Así trabaja un raspador web node típico, paso a paso:
Vamos a desmenuzar el proceso. Así trabaja un raspador web node típico, paso a paso:
- Empieza con URLs Semilla: Le das al raspador uno o varios puntos de partida (como la home o un listado de productos).
- Descarga el Contenido de la Página: El raspador obtiene el HTML de cada página—igual que tu navegador, pero sin cargar imágenes ni estilos.
- Extrae los Datos Útiles: Usando herramientas como Cheerio (que funciona como jQuery para Node), selecciona la info que te interesa—nombres, precios, emails, lo que sea.
- Encuentra y Añade Nuevos Enlaces: Analiza cada página buscando enlaces (como “Siguiente página” o detalles de productos) y los suma a una lista de tareas (el “frente de rastreo”).
- Repite el Proceso: El raspador sigue visitando nuevos enlaces, extrayendo datos y ampliando su alcance hasta cubrir todo lo que le indicaste.
- Guarda los Resultados: Todos los datos extraídos se guardan—normalmente en CSV, JSON o directo en una base de datos.
- Finaliza al Terminar: El raspador termina cuando ya no hay más enlaces nuevos o cuando llega a un límite que tú defines.
Un ejemplo real: imagina que quieres recopilar todas las ofertas de empleo de un portal de carreras. Empiezas por la página de listados, extraes los enlaces de cada vacante, visitas cada una, recoges los detalles y sigues el enlace de “Siguiente” hasta tener la lista completa.
¿El truco detrás de todo esto? La arquitectura orientada a eventos y no bloqueante de Node.js permite que el raspador procese muchas páginas a la vez, sin quedarse esperando a que cargue cada sitio. Es como tener un equipo de asistentes trabajando en paralelo—pero sin gastar en pizzas.
¿Por Qué Node.js es Tan Popular para Raspadores Web?
Entonces, ¿por qué Node.js? ¿Por qué no Python, Java u otro lenguaje? Estas son las razones por las que Node.js es el favorito para el web crawling:
- I/O No Bloqueante y Orientado a Eventos: Node.js puede manejar decenas (o cientos) de solicitudes de páginas al mismo tiempo, sin atascarse. Mientras una página carga, ya está trabajando en otras (blog.apify.com).
- Alto Rendimiento: Node corre sobre el motor V8 de Google (el mismo de Chrome), lo que lo hace rapidísimo, sobre todo para procesar grandes volúmenes de datos web.
- Ecosistema Rico: Hay librerías Node para todo: Cheerio para analizar HTML, Got para peticiones HTTP, Puppeteer para navegación sin interfaz, y frameworks como Crawlee para gestionar grandes rastreos (scrapingdog.com).
- Sinergia con JavaScript: Como la mayoría de los sitios usan JavaScript, Node.js puede interactuar con ellos de forma nativa. Además, es facilísimo manejar datos en JSON, que están por todos lados en la web.
- Capacidad en Tiempo Real: ¿Necesitas monitorear decenas de sitios para detectar cambios de precio o noticias? La concurrencia de Node te lo permite casi en tiempo real.
No es raro que herramientas basadas en Node como Crawlee y Cheerio sean usadas por más de un tercio de los desarrolladores de web scraping.
Funciones y Características Clave de un Raspador Web Node
Los raspadores web node son como navajas suizas para los datos online. Estas son sus funciones más comunes—y cómo se aplican a necesidades reales de negocio:
| Función/Característica | Cómo Funciona en Raspadores Node | Ejemplo de Uso Empresarial |
|---|---|---|
| Navegación Automática | Sigue enlaces y páginas paginadas de forma automática | Generación de leads: rastrea todas las páginas de un directorio online |
| Extracción de Datos | Extrae campos específicos (nombre, precio, contacto) usando selectores o patrones | Monitoreo de precios: extrae precios de productos en sitios de la competencia |
| Manejo Concurrente de Múltiples Páginas | Procesa muchas páginas en paralelo (gracias a la asincronía de Node.js) | Actualizaciones en tiempo real: monitorea varios sitios de noticias a la vez |
| Salida de Datos Estructurada | Guarda resultados en CSV, JSON o directamente en una base de datos | Analítica: alimenta dashboards BI o CRMs con los datos extraídos |
| Lógica y Filtros Personalizables | Permite reglas, filtros o limpieza de datos a medida en el código | Control de calidad: omite páginas desactualizadas, transforma formatos de datos |
Por ejemplo, un equipo de marketing podría usar un raspador node para recopilar todos los posts de blogs del sector, extraer títulos y URLs, y exportarlos a Google Sheets para planificar contenidos.
Thunderbit: Alternativa Sin Código a los Raspadores Web Node
Prueba Thunderbit AI Web Scraper Extrae datos de cualquier sitio web en 2 clics—sin programar. Get Started Free
Aquí es donde la cosa se pone buena (y mucho más divertida para quienes no programan). Thunderbit es una extensión de Chrome con IA que te permite extraer datos web—sin escribir ni una línea de código.
¿Cómo funciona? Abres la extensión, haces clic en “Sugerir Campos con IA” y la IA de Thunderbit analiza la página, te sugiere qué datos extraer y los organiza en una tabla. ¿Quieres sacar todos los nombres y precios de productos de un sitio? Solo pídeselo a Thunderbit en lenguaje natural y él se encarga del resto. ¿Necesitas raspar subpáginas o manejar paginación? Thunderbit lo hace con un clic.
Algunas de mis funciones favoritas de Thunderbit:
- Interfaz en Lenguaje Natural: Describe lo que necesitas y la IA se encarga de la parte técnica.
- Sugerencias de Campos Generadas por IA: Thunderbit analiza la página y propone las mejores columnas para extraer.
- Raspado de Subpáginas Sin Código: Extrae datos de páginas de detalle (como productos o perfiles) y los combina automáticamente.
- Exportación Estructurada: Envía tus datos al instante a Excel, Google Sheets, Airtable o Notion.
- Exportación de Datos Gratuita: Descarga tus resultados sin costes ocultos.
- Automatización y Programación: Programa extracciones recurrentes usando lenguaje natural (“cada lunes a las 9am”).
- Extracción de Contactos: Extrae emails, teléfonos e imágenes con un solo clic—totalmente gratis.
Para usuarios de negocio, esto significa pasar de “necesito estos datos” a “aquí está mi hoja de cálculo” en minutos, no días. Y según las opiniones de usuarios, incluso quienes no son técnicos están creando listas de leads, monitoreando precios y haciendo investigaciones—sin tocar código.
Prueba Thunderbit Gratis en Chrome
Comparativa: Raspadores Web Node vs. Thunderbit para Empresas
Entonces, ¿qué opción te conviene más? Aquí tienes una comparativa directa:
| Criterio | Raspador Web Node.js (Código Propio) | Thunderbit (Raspador IA Sin Código) |
|---|---|---|
| Tiempo de Configuración | De horas a días (programar, depurar, configurar) | Minutos (instalar, hacer clic, extraer) |
| Habilidad Técnica | Requiere programación (Node.js, HTML, selectores) | No necesitas programar; lenguaje natural y clics |
| Personalización | Extremadamente flexible; cualquier lógica o flujo | Limitado a las funciones y capacidades de la IA |
| Escalabilidad | Puede escalar mucho (requiere servidores, proxies, etc.) | Raspado en la nube integrado para trabajos medianos o grandes |
| Mantenimiento | Continuo (actualizar código si cambian los sitios, errores) | Mínimo (la IA de Thunderbit se adapta a los cambios) |
| Manejo Anti-Bots | Debes implementar proxies, retrasos, navegación sin interfaz | Thunderbit lo gestiona automáticamente en su backend |
| Integración | Integración profunda posible (APIs, bases de datos, flujos) | Exporta a Sheets, Notion, Airtable, Excel, CSV |
| Coste | Herramientas gratuitas, pero tiempo de desarrollo y servidores | Plan gratuito, luego pago por uso o suscripción |
Cuándo usar Node.js:
- Si necesitas lógica o integración muy personalizada.
- Si tienes desarrolladores y quieres control total.
- Si vas a raspar a gran escala o crear un producto basado en datos web.
Cuándo usar Thunderbit:
- Si quieres resultados rápidos y sin complicaciones.
- Si no eres programador (o no quieres serlo).
- Si necesitas extraer datos de varios sitios para tareas diarias de negocio.
- Si valoras la facilidad de uso y la adaptabilidad de la IA.
De hecho, muchos equipos arrancan con Thunderbit para obtener resultados rápidos y luego invierten en raspadores node personalizados si sus necesidades se vuelven más complejas o de mayor escala.
Retos Comunes al Usar Raspadores Web Node
Los raspadores web node son potentes, pero no están exentos de retos. Estos son los principales (y cómo enfrentarlos):
- Defensas Anti-Scraping: Los sitios usan CAPTCHAs, bloqueos de IP y detección de bots. Necesitarás rotar proxies, aleatorizar cabeceras y, a veces, usar navegadores sin interfaz como Puppeteer (blog.apify.com).
- Contenido Dinámico: Muchos sitios cargan datos con JavaScript o scroll infinito. El simple análisis de HTML no basta—puede que debas simular navegación real o acceder a APIs.
- Análisis y Limpieza de Datos: No todas las páginas web son ordenadas. Tendrás que lidiar con formatos inconsistentes, datos faltantes y codificaciones raras.
- Mantenimiento: Los sitios cambian. Tu código puede romperse. Prepárate para actualizaciones y manejo de errores frecuentes.
- Cuestiones Legales y Éticas: Respeta siempre el
robots.txt, los términos del sitio y las leyes de privacidad. No extraigas datos sensibles o protegidos por derechos de autor.
Buenas prácticas:
- Usa frameworks como Crawlee que resuelven muchos de estos problemas de serie.
- Implementa reintentos, retrasos y registros de errores.
- Revisa y actualiza tus raspadores regularmente.
- Raspa de forma responsable—no sobrecargues sitios ni incumplas sus normas.
Integrando Raspadores Web Node con Servicios en la Nube
Para proyectos serios y continuos de extracción de datos web, ejecutar tu raspador node en tu portátil no es suficiente. Aquí es donde entra la integración en la nube:
- Funciones Serverless: Despliega tu raspador node como una función Lambda de AWS o Google Cloud Function. Programa su ejecución automática (por ejemplo, diaria u horaria) y guarda los resultados en almacenamiento en la nube como S3 o BigQuery (docs.aws.amazon.com).
- Raspadores en Contenedores: Empaqueta tu raspador en Docker y ejecútalo en AWS Fargate, Google Cloud Run o Kubernetes. Así puedes escalar para rastrear miles de páginas en paralelo.
- Flujos de Trabajo Automatizados: Usa planificadores en la nube (como AWS EventBridge) para lanzar rastreos, almacenar resultados y alimentar dashboards analíticos o modelos de machine learning.
¿Las ventajas? Escalabilidad, fiabilidad y automatización “olvídate y listo”. De hecho, el 68% del web scraping ya se realiza en la nube—y esa cifra sigue subiendo.
¿Cuándo Elegir un Raspador Web Node o una Solución Sin Código?
¿Aún tienes dudas? Aquí tienes una guía rápida para decidir:
-
¿Necesitas personalización profunda, flujos únicos o integración con sistemas internos?
→ Raspador web node.js -
¿Eres usuario de negocio y necesitas datos rápido, sin programar?
→ Thunderbit (u otra herramienta sin código) -
¿Es una tarea puntual o poco frecuente?
→ Thunderbit -
¿Es una operación crítica, continua y a gran escala?
→ Node.js (con integración en la nube) -
¿Tienes desarrolladores y tiempo para mantenimiento?
→ Node.js -
¿Quieres que tu equipo no técnico pueda obtener datos por sí mismo?
→ Thunderbit
¿Mi consejo? Empieza con una solución sin código para obtener resultados rápidos y prototipos. Si tus necesidades crecen, siempre puedes invertir en un raspador node personalizado más adelante. Muchos equipos descubren que Thunderbit cubre el 90% de sus casos de uso—y ahorra mucho tiempo y dolores de cabeza.
Empieza con Thunderbit AI Web Scraper
Conclusión: Libera el Potencial de los Datos Web para tu Negocio
 La extracción de datos web ya no es solo cosa de “techies”—es una necesidad empresarial. Ya sea que crees tu propio raspador web node o uses una herramienta con IA como Thunderbit, el objetivo es el mismo: transformar el caos de la web en información estructurada y útil.
La extracción de datos web ya no es solo cosa de “techies”—es una necesidad empresarial. Ya sea que crees tu propio raspador web node o uses una herramienta con IA como Thunderbit, el objetivo es el mismo: transformar el caos de la web en información estructurada y útil.
Node.js te da máxima flexibilidad y potencia, sobre todo para proyectos complejos o de gran escala. Pero para la mayoría de los usuarios de negocio, la llegada de herramientas sin código y con IA significa que puedes obtener los datos que necesitas—rápido, fiable y sin programar.
A medida que casi el 97% de las organizaciones invierten en Big Data e IA, los equipos que dominen los datos web serán los que lideren el mercado. Así que, seas desarrollador, marketero o simplemente alguien cansado de copiar y pegar, nunca ha habido mejor momento para aprovechar el web crawling.
¿Te animas a probarlo? Descarga Thunderbit gratis y descubre lo fácil que es extraer datos web. Y si quieres aprender más, visita el Blog de Thunderbit para más guías, consejos e historias sobre automatización web.
Prueba AI Web Scraper Gratis Get Started Free
Preguntas Frecuentes
1. ¿Cuál es la diferencia entre un raspador web node y un web scraper?
Un raspador web node descubre y navega páginas automáticamente (como una araña recorriendo la web), mientras que un web scraper extrae datos específicos de esas páginas. La mayoría de los raspadores node hacen ambas cosas: encuentran páginas y extraen la información que necesitas.
2. ¿Por qué Node.js es popular para crear raspadores web?
Node.js es orientado a eventos y no bloqueante, lo que le permite gestionar muchas solicitudes de páginas a la vez. Es rápido, tiene un ecosistema enorme de librerías y es ideal para extracción de datos en tiempo real o a gran escala.
3. ¿Cuáles son los principales retos de los raspadores web node?
Los problemas más comunes son las defensas anti-bots (CAPTCHAs, bloqueos de IP), contenido dinámico (sitios con mucho JavaScript), limpieza de datos y el mantenimiento constante a medida que los sitios cambian. Usar frameworks y buenas prácticas ayuda, pero requiere conocimientos técnicos.
4. ¿En qué se diferencia Thunderbit de un raspador web node?
Thunderbit es un raspador web con IA y sin código. En vez de programar, usas una extensión de Chrome y lenguaje natural para extraer datos. Es ideal para usuarios de negocio que quieren resultados rápidos, sin programar.
5. ¿Cuándo debo usar un raspador web node y cuándo Thunderbit?
Usa Node.js para proyectos muy personalizados, a gran escala o con integración profunda—especialmente si tienes desarrolladores. Usa Thunderbit para tareas rápidas y cotidianas, o si quieres que tu equipo no técnico obtenga datos por sí mismo.
¿Listo para llevar tus datos web al siguiente nivel? Prueba Thunderbit o explora más en el Blog de Thunderbit. ¡Feliz extracción!
Más información




