¿Te ha pasado alguna vez que entras a una web y apenas encuentras información, obligándote a pinchar en un montón de enlaces para conseguir lo que buscas? Es desesperante, sobre todo porque cada vez más páginas esconden datos importantes en subpáginas. Esto complica mucho la vida a quienes necesitan recolectar grandes cantidades de datos. Los que saben programar acaban gastando horas montando scripts para navegar por esas subpáginas, mientras que quienes no programan tienen que ir uno por uno, clic a clic. Pero tranquilo, hay soluciones: el list crawling (también conocido como raspado masivo) y el subpage scraping.
List Crawling y Subpage Scraping en pocas palabras
| Herramienta | Facilidad de uso | Calidad de los datos | Mejor caso de uso |
|---|---|---|---|
| List Crawling | ★★ | ★★★ | Sitios web de gran tamaño |
| Subpage Scraping | ★★★★★ | ★★★★ | Raspado ligero, formatos de datos específicos |
¿Qué es el List Crawling?
El list crawling, o raspado masivo, es una técnica de raspador web que saca datos a partir de una lista de URLs. Para arrancar, necesitas una lista de enlaces, que normalmente se consigue usando otro raspador web. El éxito de este método depende mucho de la calidad de esa lista inicial. Si las URLs llevan a páginas con formatos diferentes, los resultados pueden salir desordenados y te tocará limpiar mucho los datos. Este método es perfecto para empresas, investigadores y analistas de datos que necesitan recolectar grandes volúmenes de información estructurada y homogénea. Eso sí, normalmente hay que limpiar y organizar los datos a mano para que sean realmente útiles.
¿Cómo funciona?

El proceso de list crawling suele seguir estos pasos:
- Preparar una lista de URLs: Empieza con una lista de enlaces de las páginas que te interesan.
- Enviar solicitudes HTTP: El sistema accede a esas URLs para conseguir el HTML.
- Extraer los datos: Se usan técnicas como BeautifulSoup, XPath o expresiones regulares para sacar la información que buscas (texto, imágenes, enlaces, etc.).
- Guardar los datos: Organiza y almacena los datos extraídos en una base de datos o una hoja de cálculo para analizarlos después.
Una vez tienes los datos, es clave limpiarlos y analizarlos usando métodos como estadísticas descriptivas, análisis de series temporales, correlaciones o clustering. La IA puede ayudarte mucho en este proceso, automatizando tareas y mejorando la calidad de los datos.
Descubre la función de Raspado Masivo en Thunderbit Raspador Web IA para que todo sea mucho más sencillo.
Herramientas recomendadas
-
- Ventajas: Muy fácil de usar, análisis flexible, funciones avanzadas
- Desventajas: Hay que usarlo localmente y depende del navegador
- Ideal para: Recopilar datos de alta calidad donde la precisión es clave
- Scrapy
- Ventajas: Potente, súper personalizable, aguanta grandes volúmenes
- Desventajas: Curva de aprendizaje alta, necesitas saber programar
- Ideal para: Proyectos de scraping a gran escala
- Beautiful Soup
- Ventajas: Sencillo, bien documentado, flexible
- Desventajas: Rendimiento medio, no soporta operaciones asíncronas
- Ideal para: Raspados pequeños y análisis de datos
- Selenium
- Ventajas: Perfecto para páginas dinámicas, simula el comportamiento humano
- Desventajas: Es lento y consume bastantes recursos
- Ideal para: Páginas que cargan contenido con JavaScript
Explorando el Subpage Scraping

¿Qué es el Subpage Scraping?
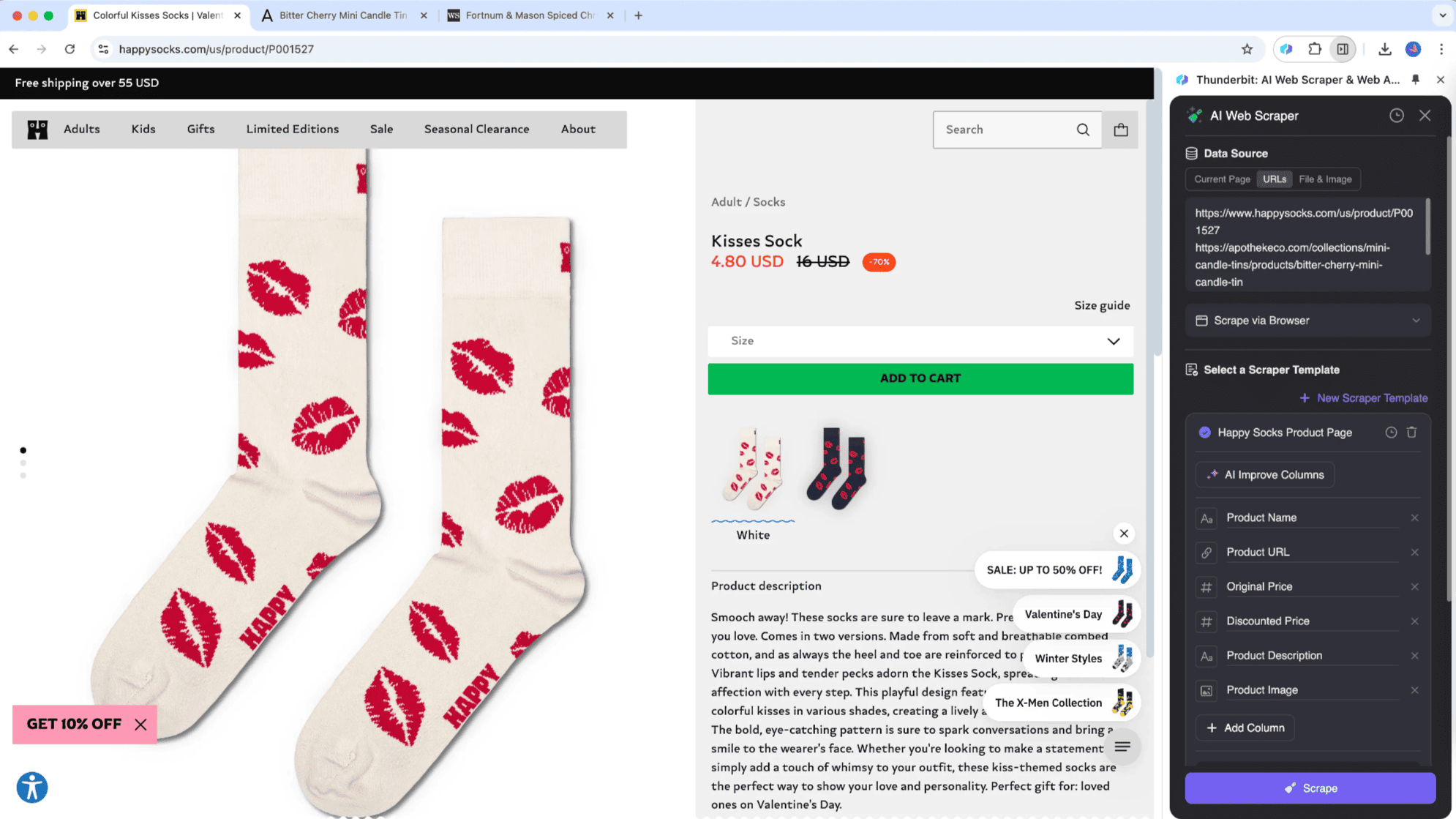
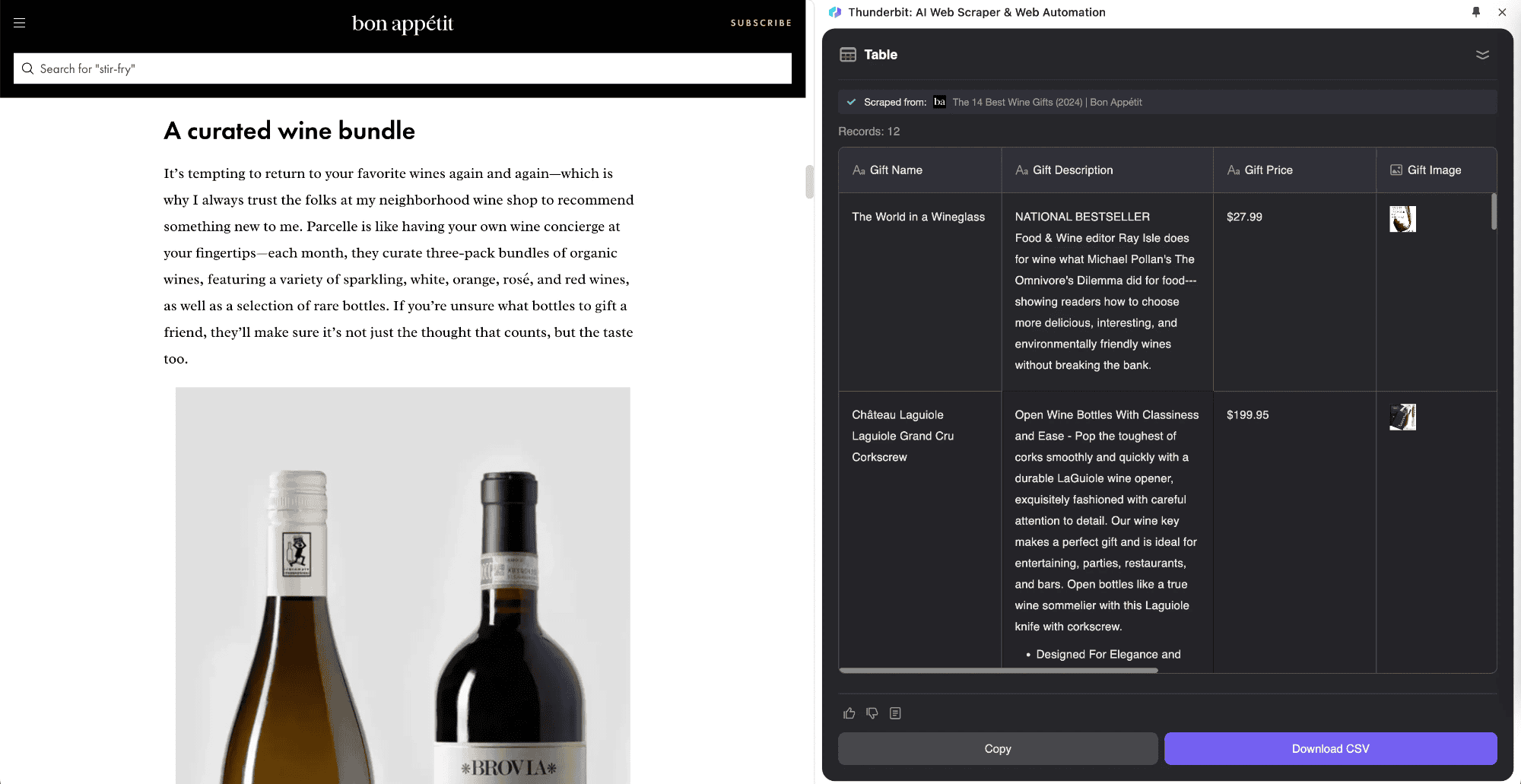
El subpage scraping es una técnica que saca datos de listas en una sola página web y junta la información de las subpáginas en una tabla principal. Thunderbit ha revolucionado este proceso gracias a la IA de su Raspador Web IA. Es ideal para páginas con subpáginas, como fichas de productos, blogs o webs de navegación. Su mayor ventaja es que puede recopilar y procesar información de subpáginas de forma inteligente, integrándola en la tabla principal.
Por ejemplo, si estás leyendo un artículo de "Bolsa Hoy" y quieres sacar una lista de todas las cotizaciones, puedes usar . Solo tienes que definir tu tabla y la herramienta extraerá automáticamente las cotizaciones, abrirá las páginas en tiempo real y fusionará los datos en tu tabla principal. Así puedes guardar información precisa mientras lees las noticias. El Raspador Web IA de Thunderbit se adapta a diferentes páginas, algo que las herramientas clásicas no pueden hacer.
¿Por qué usarlo?
Thunderbit Raspador Web IA viene cargado de funciones que mejoran la eficiencia y la precisión al recopilar datos.
Extracción inteligente de datos
Thunderbit Raspador Web IA usa IA para extraer datos de forma inteligente, adaptándose solo a los cambios en la estructura de las páginas. Los usuarios pueden describir en lenguaje natural los datos que necesitan y el sistema genera las reglas de extracción. Así, cualquiera puede recopilar datos fácilmente, sin complicaciones técnicas. Thunderbit soporta varios tipos de datos, como texto, enlaces e imágenes, cubriendo un montón de necesidades.
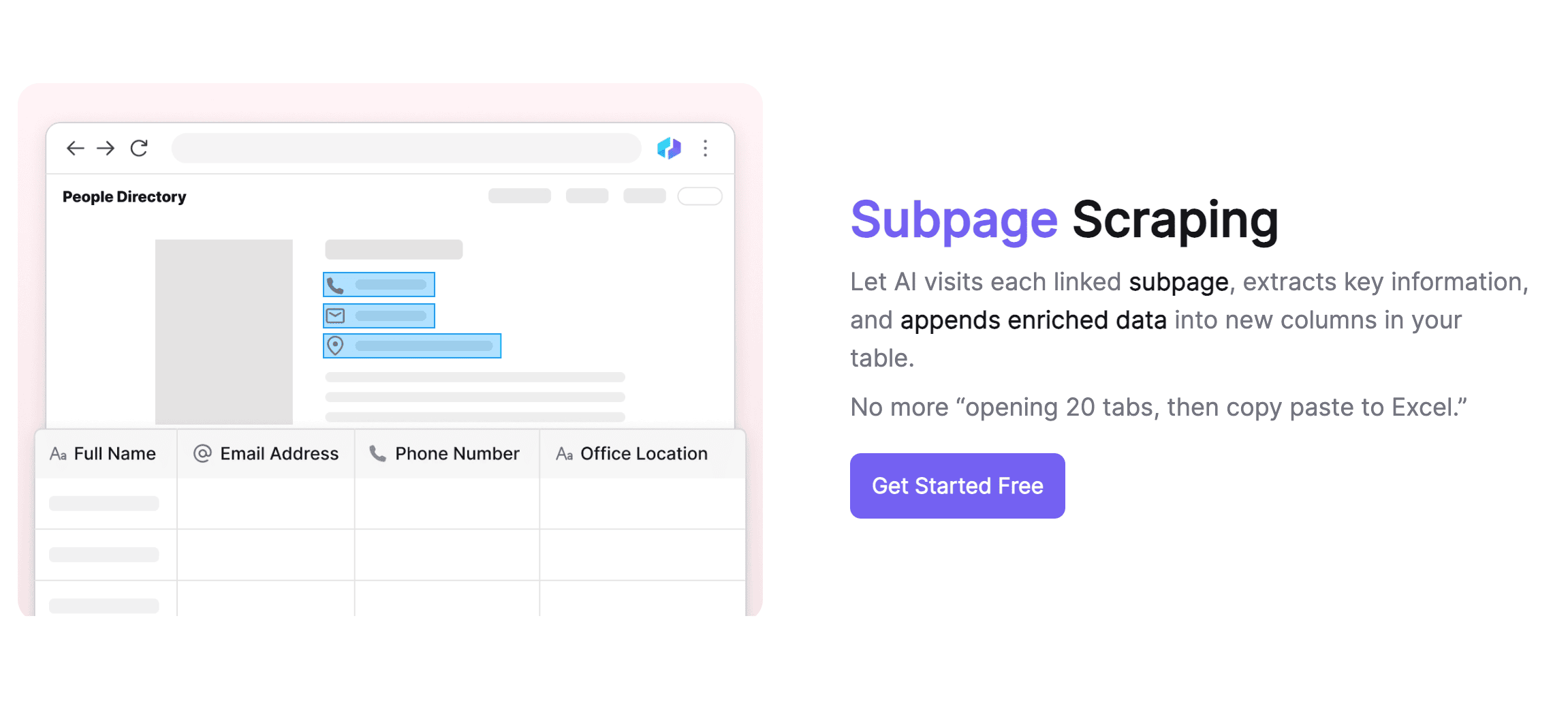
Gestión inteligente de subpáginas
Thunderbit es especialmente bueno gestionando subpáginas. Detecta y accede a subpáginas automáticamente, usando una sola plantilla para diferentes estructuras. La IA se adapta a los cambios en la web, así que no tienes que preocuparte por extraer datos de subpáginas distintas. Thunderbit fusiona automáticamente el contenido de las subpáginas en la tabla principal, ayudando a organizar mejor la información. Además, funciona como un asistente de IA para limpiar y formatear los datos, automatizando tareas repetitivas como el etiquetado.
Gestión eficiente de datos
Thunderbit ofrece funciones avanzadas para gestionar datos, permitiendo exportar en varios formatos y conectar con plataformas como Google Sheets, Airtable y Notion. Puedes vincular una plantilla de raspado a una hoja de Google para centralizar los datos, o a Notion para organizarlos en su base de datos. Estas opciones flexibles te permiten elegir el método de almacenamiento que más te convenga. El etiquetado y la clasificación de datos también se adaptan automáticamente al formato de la plataforma de gestión, facilitando la organización posterior.
Plantillas prácticas predefinidas
Para ahorrar tiempo, Thunderbit tiene un montón de plantillas listas para usar. Cubren la recopilación de datos de e-commerce (como , ), información inmobiliaria (como ), análisis de redes sociales (como , ) y recopilación de información empresarial (webs de empresas, directorios). Estas plantillas te ahorran tiempo y aseguran que los datos sean consistentes y precisos.
Guía paso a paso
Cómo implementar Subpage Scraping
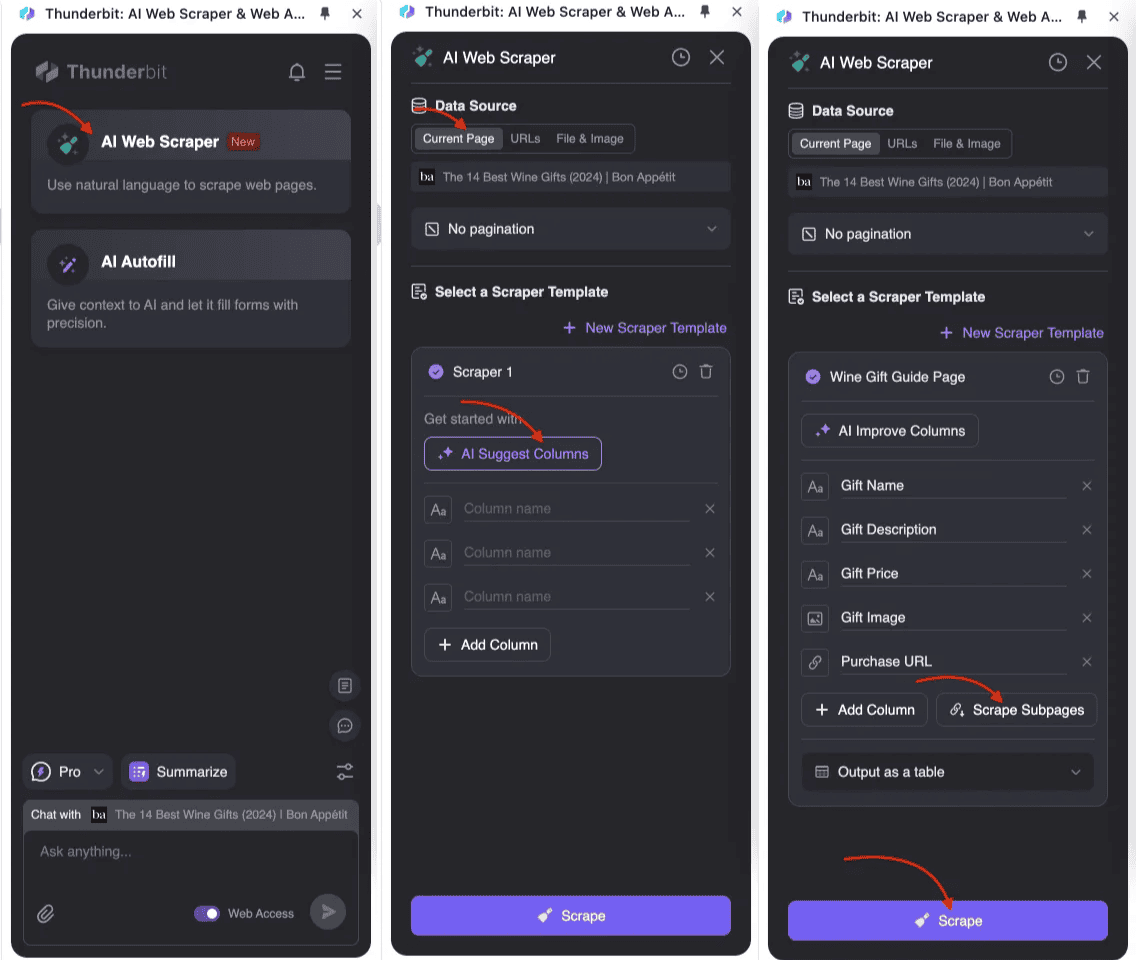
- : Abre Thunderbit Raspador Web IA y crea una nueva plantilla de raspado.
- Define la estructura de tu tabla principal: En la configuración de la tabla, añade los campos que quieres recopilar, como título, precio y descripción. Para los datos de subpáginas, crea los campos correspondientes y activa el subpage scraping.
- Ejecuta el raspador: Thunderbit primero extraerá los datos de la página principal, luego visitará automáticamente cada subpágina, extraerá la información relevante y la integrará en la tabla principal. Todo el proceso es impulsado por IA, sin necesidad de programar.
Cómo implementar List Crawling
Para quienes programan, hay varios lenguajes y herramientas para hacer list crawling. Python es el rey por su sencillez y la cantidad de librerías que tiene. Aquí tienes un ejemplo básico usando requests y BeautifulSoup para sacar datos:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4def scrape_urls(urls):
5 data = []
6 for url in urls:
7 response = requests.get(url)
8 soup = BeautifulSoup(response.text, 'html.parser')
9 titles = soup.find_all('h2', class_='product-title')
10 prices = soup.find_all('span', class_='product-price')
11 for title, price in zip(titles, prices):
12 data.append({
13 'title': title.get_text(),
14 'price': price.get_text()
15 })
16 return pd.DataFrame(data)
17# Ejemplo de uso
18urls = ['<http://example.com/product1>', '<http://example.com/product2>']
19data_frame = scrape_urls(urls)
20print(data_frame)Conclusión
Hoy en día, los datos son el motor de cualquier negocio. Quien sabe recopilar y analizar información tiene una ventaja enorme. Los datos ayudan a las empresas a entender tendencias del mercado y necesidades de los clientes, aportando información clave para crear productos y definir estrategias de marketing. Pero recolectar y organizar bien la enorme cantidad de datos que hay en internet es todo un reto.
Con herramientas como Thunderbit, las empresas ya no tienen que preocuparse por la recopilación de datos. Es como tener un asistente de confianza que te ayuda a encontrar información valiosa entre montones de datos, facilitando la toma de decisiones. Gracias a sus capacidades inteligentes de recopilación y procesamiento, las empresas pueden acceder fácilmente a información de la competencia, tendencias de mercado, opiniones de usuarios y otros datos clave para tomar mejores decisiones.
Thunderbit no solo facilita la recopilación, sino que también ofrece potentes funciones de procesamiento y análisis. Puede limpiar y estructurar los datos automáticamente, generando informes visuales que ayudan a descubrir oportunidades ocultas. Para empresas que necesitan monitorizar el mercado de forma continua, la función de recopilación automática de Thunderbit es una opción eficiente y que ahorra tiempo.
En esta era donde los datos lo son todo, contar con una herramienta como Thunderbit es una gran ventaja. Mejora mucho la eficiencia en la recopilación y apoya la transformación digital de las empresas. A medida que los datos ganan protagonismo en la toma de decisiones, herramientas inteligentes como Thunderbit serán imprescindibles para cualquier organización.
Preguntas frecuentes
-
¿Qué es Thunderbit? es una extensión de Chrome pensada para ayudar a usuarios de empresa a automatizar tareas web. Ofrece funciones como Raspador Web IA, Portapapeles IA y Chat Web IA para extraer datos, rellenar formularios y usando inteligencia artificial. Es una herramienta de productividad que ahorra tiempo y simplifica tareas repetitivas online.
-
¿Cómo funciona el Raspador Web IA de Thunderbit? El Raspador Web IA de Thunderbit usa IA para extraer datos estructurados de sitios web. Los usuarios pueden hacer clic en "Sugerir columnas con IA" para que la herramienta proponga cómo extraer los datos de la web actual, y luego hacer clic en "Raspar" para recopilar la información. Puede manejar datos de cualquier web, PDF o imagen en solo dos clics.
-
¿Cuál es la diferencia entre list crawling y subpage scraping? El list crawling, o raspado masivo, consiste en extraer datos de una lista de URLs, ideal para webs grandes. El subpage scraping, en cambio, saca datos de una página y sus subpáginas, fusionando la información en una tabla principal. El Raspador Web IA de Thunderbit destaca en ambos métodos, ofreciendo extracción y gestión inteligente de datos.
-
¿Pueden usar Thunderbit quienes no programan? ¡Claro! Thunderbit está pensado para ser fácil de usar, incluso para quienes no tienen conocimientos técnicos. Sus funciones con IA permiten describir los datos que necesitas en lenguaje natural, y el sistema genera las reglas de extracción, haciéndolo accesible para todos.
-
¿Qué tipos de datos puede manejar Thunderbit? Thunderbit soporta varios tipos de datos, como texto, enlaces e imágenes. Se adapta a distintas necesidades, siendo útil para recopilar datos de e-commerce, información inmobiliaria, análisis de redes sociales y recopilación de datos empresariales.
-
¿Cómo empiezo a usar Thunderbit? Para empezar, descarga la extensión de Chrome de Thunderbit desde la . Una vez instalada, explora funciones como el Raspador Web IA, Portapapeles IA y Chat Web IA para mejorar tu productividad online.
-
¿Thunderbit ofrece plantillas predefinidas? Sí, Thunderbit tiene una variedad de listas para usar. Cubren áreas como e-commerce, inmobiliaria, redes sociales e información empresarial, ahorrando tiempo y asegurando consistencia y precisión en la recopilación de datos.
-
¿Cómo garantiza Thunderbit la calidad de los datos? Thunderbit utiliza IA para extraer y procesar datos de forma inteligente, adaptándose automáticamente a los cambios en la estructura de las páginas. También ofrece funciones de limpieza y formateo, actuando como un asistente que automatiza tareas repetitivas y mejora la calidad de los datos.
-
Casos de uso del raspado web Hay muchísimas aplicaciones prácticas para las . Por ejemplo, puedes para estudios de mercado, o para análisis documental. Muchas empresas necesitan para analizarlos. Con herramientas con IA, ahora puedes sin programar. Para análisis en redes sociales, puedes usar herramientas especializadas como o para recopilar datos relevantes para tus campañas de marketing.
Más información: