
Todo el mundo habla de tomar decisiones con datos, pero casi nadie menciona la parte menos vistosa: conseguir esos datos a tiempo y con suficiente calidad. Si alguna vez has reunido información a mano, ya sabes lo rápido que se vuelve repetitivo. En muchas empresas, la estrategia basada en datos se frena no por falta de ideas, sino por procesos de recopilación lentos, frágiles o demasiado manuales. Este artículo va de eso: cómo hacer scraping de datos de forma más práctica y qué cambia cuando entra la IA.
💡 En este artículo repasamos qué es el data scraping, por qué los métodos tradicionales se quedan cortos y cómo las herramientas con IA están cambiando el trabajo diario. También verás casos de uso concretos, funciones avanzadas y consejos para limpiar datos desde el propio flujo de extracción.
¿Qué es el Data Scraping?
El data scraping, también conocido como web scraping, es el proceso de extraer información estructurada de páginas web con ayuda de herramientas, normalmente en forma de tablas. Su valor está en que permite recopilar grandes volúmenes de datos en mucho menos tiempo que con copiar y pegar. Por ejemplo, puedes obtener datos públicos de Google Maps para generar leads, extraer SKUs de e-commerce desde Amazon para reventa o análisis de mercado, o recopilar reseñas de redes sociales en Yelp para entender mejor lo que dicen los clientes.
El cambio tecnológico en el Data Scraping
Durante mucho tiempo, recopilar datos de la web parecía una tarea para perfiles técnicos, o una rutina interminable de copiar y pegar. Pero en 2025 el panorama es distinto: la IA ya forma parte del flujo. El data scraping dejó de ser solo una cuestión de programación o automatizaciones rígidas.
Los métodos tradicionales ya no dan la talla
Las webs actuales son más complejas: cargan contenido de forma dinámica con frameworks como React o Vue, mezclan texto, vídeo e imágenes, y usan estructuras poco estandarizadas incluso dentro del mismo sitio. Estudios recientes apuntan a tres problemas principales de los métodos tradicionales de web scraping:
-
Un pozo sin fondo en costes de mantenimiento Los scrapers web tradicionales exigen mantenimiento manual constante, unas 3-5 horas al mes por sitio. Cuando una web se actualiza o cambia su framework front-end, el 60% de los selectores XPath dejan de funcionar. Las herramientas de IA, gracias a los modelos de lenguaje y a su capacidad para interpretar código, pueden adaptarse automáticamente al 90% de los cambios estructurales, reduciendo los costes de mantenimiento entre un 60% y un 80%. En sitios modernos creados con React/Vue, las herramientas de IA mantienen estable la extracción porque entienden la semántica de la página, incluso si cambian los nombres de las clases.
-
Dimensiones de datos limitadas Los métodos tradicionales suelen quedarse en datos estructurados y dejan fuera información que también puede ser importante, como:
- Datos dentro de imágenes
- Texto contenido en artículos
- Datos no estructurados sin etiquetas HTML
-
Problemas de calidad de datos Los métodos tradicionales tienen dificultades con el contenido dinámico, lo que termina generando datos incompletos o poco fiables:
- En datos paginados, como listas de productos de e-commerce, los scrapers tradicionales solo capturan entre el 30% y el 50% del contenido visible en la primera pantalla.
- En páginas con desplazamiento infinito, como feeds de redes sociales, se pierde más del 60% de los datos críticos.
- Las tasas de error al emparejar datos no estructurados son altas, y eso provoca listas desalineadas.
Aquí es donde entran herramientas impulsadas por IA como Thunderbit. Más abajo te explico dónde aportan valor.
El auge del data scraping con IA
Extrae datos de cualquier sitio web usando IA Get Started Free
En 2025, la IA, especialmente los modelos de lenguaje grande (LLM), ya ha demostrado capacidades muy sólidas. Estos modelos pueden entender y generar lenguaje natural, resolver tareas complejas de análisis de datos y ofrecer flujos mucho más eficientes. Hoy, muchas herramientas de data scraping usan LLM para superar los límites de los métodos tradicionales. Después de probar 13 herramientas de data scraping durante los últimos meses, recomiendo Thunderbit AI Web Scraper.
Estas son las razones por las que Thunderbit destaca:
-
Interacción revolucionaria: Puedes escribir instrucciones sencillas en lenguaje natural y el sistema crea automáticamente un plan de extracción. Frente a herramientas tradicionales, esto reduce el tiempo de configuración en un 87%.
-
Ventajas claras del scraping local: Como extensión de navegador, Thunderbit permite trabajar directamente sobre la página que tienes abierta:
- Extracción de datos al instante
- Scraping de páginas dinámicas y con desplazamiento infinito
- Extracción de páginas que requieren inicio de sesión
-
Potente procesamiento de datos multimodales: Thunderbit puede trabajar con distintos tipos de datos, por ejemplo:
- Extraer información de texto dentro de artículos
- Extraer tablas de datos financieros desde PDFs
- Reconocer información de varias imágenes y convertirla en tablas
- Extraer subtítulos de vídeos y resumirlos
Con Thunderbit, puedes cubrir distintos escenarios de recopilación de datos sin montar un flujo técnico desde cero. Veamos cómo usarlo.
Cómo hacer Data Scraping usando IA
Sigue estos cuatro pasos para aprovechar las capacidades de web scraping con IA de Thunderbit:
-
Instala la extensión para navegador Entra en la web de Thunderbit y descarga la extensión desde Chrome Web Store. Cuando la tengas instalada, fíjala en la barra de herramientas del navegador para acceder rápido.
-
Regístrate y consigue créditos gratis Crea una cuenta desde la extensión para obtener créditos de prueba. Te servirán para probar funciones como el web scraping con IA, el autocompletado de formularios y el resumen inteligente. Antes de gastar créditos, conviene explorar la herramienta gratis en el playground y ver qué puede hacer con tus páginas.
-
Inicia el scraping inteligente Abre una plantilla desde la barra lateral de Thunderbit. Describe en lenguaje natural qué contenido necesitas y qué tipo de datos quieres obtener, define formatos concretos de extracción o ajusta otros detalles. Después, pulsa el botón de scrape para iniciar la extracción.
Funciones avanzadas de scraping (plan Pro)
Al suscribirte al plan Pro de Thunderbit o empezar una prueba gratis, desbloquearás estas funciones:
-
Procesamiento de datos multimodales Permite resolver escenarios complejos como análisis de documentos PDF (informes financieros/manuales de producto), extracción de datos desde imágenes (etiquetas de precio/fichas técnicas) y scraping de subtítulos de vídeo. El sistema estandariza automáticamente los datos no estructurados.
-
Scraping profundo de subpáginas Puede acceder opcionalmente a todos los subenlaces de una página, como páginas de detalle de producto o páginas de reseñas de usuarios, reconocer de forma inteligente los datos relacionados y fusionarlos automáticamente en la tabla principal. Es especialmente útil para catálogos de e-commerce, listados inmobiliarios y casos similares.
-
Biblioteca de plantillas preconfiguradas Puedes usar al instante plantillas de scraping optimizadas para más de 30 plataformas como TikTok, Amazon y Zillow, con adaptación automática a cambios en la estructura de la página. Los nuevos usuarios ahorran de media un 83% del tiempo de configuración.
-
Tareas de scraping en lote Ejecuta varias tareas de scraping a la vez, con soporte para importar listas de URLs y hacer scraping por lotes.
-
Gestión inteligente de paginación Reconoce y extrae automáticamente contenido paginado, incluidos botones de "cargar más" y navegación entre páginas, con soporte para páginas de desplazamiento infinito. Se ha probado para extraer por completo más de 200 páginas de listados de productos de e-commerce.
Guía práctica de Thunderbit
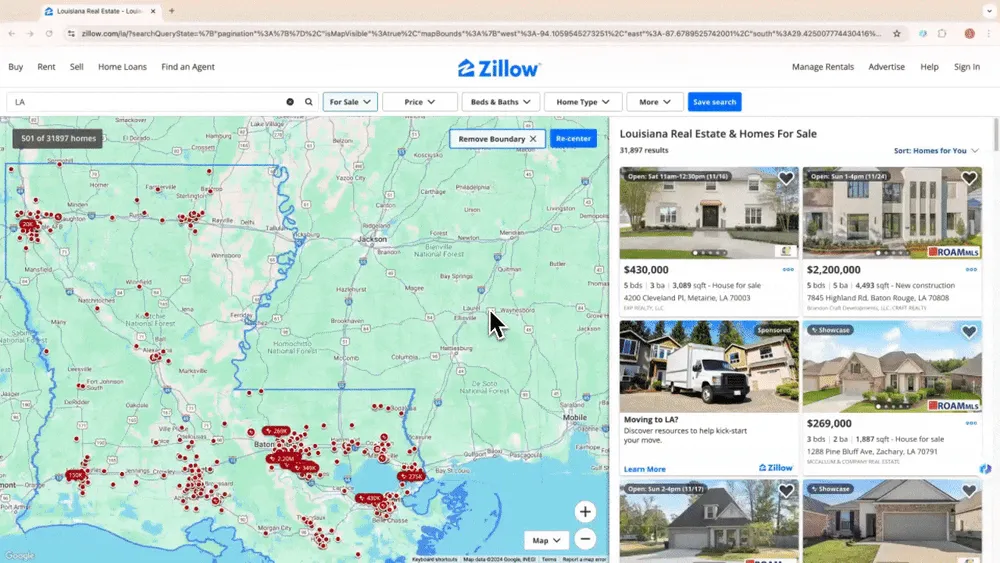
Escenario 1: recopilación de datos inmobiliarios
Si eres agente inmobiliario y necesitas recopilar datos de propiedades en Zillow, o si inviertes y buscas oportunidades rentables, un web scraper fiable puede ahorrarte muchas horas. El AI web scraper de Thunderbit te permite extraer información clave de propiedades desde Zillow para seguir el mercado y reaccionar antes. También puedes ver un tutorial en vídeo sobre cómo hacer scraping de Zillow con Thunderbit.
Escenario 2: búsqueda de talento y clientes potenciales
Si trabajas en RR. HH. y buscas talento, o si estás en ventas y necesitas nuevos leads, un web scraper fiable puede quitarte mucho trabajo manual. Thunderbit te ayuda a extraer datos útiles de contacto y de empresas desde webs públicas, directorios y páginas de perfil, para acelerar la búsqueda de talento y la gestión de leads sin depender de copiar y pegar. Si quieres un flujo listo para usar, empieza con el Website Contact Scraper.
Escenario 3: análisis de mercado y segmentación de clientes
Si tienes un negocio y recopilas datos geográficos para análisis de mercado, o si trabajas en ventas y buscas leads de negocios locales, un web scraper fiable puede cambiar mucho el ritmo del trabajo. Thunderbit permite extraer datos clave de Google Maps, para tomar decisiones mejor informadas y afinar la prospección.
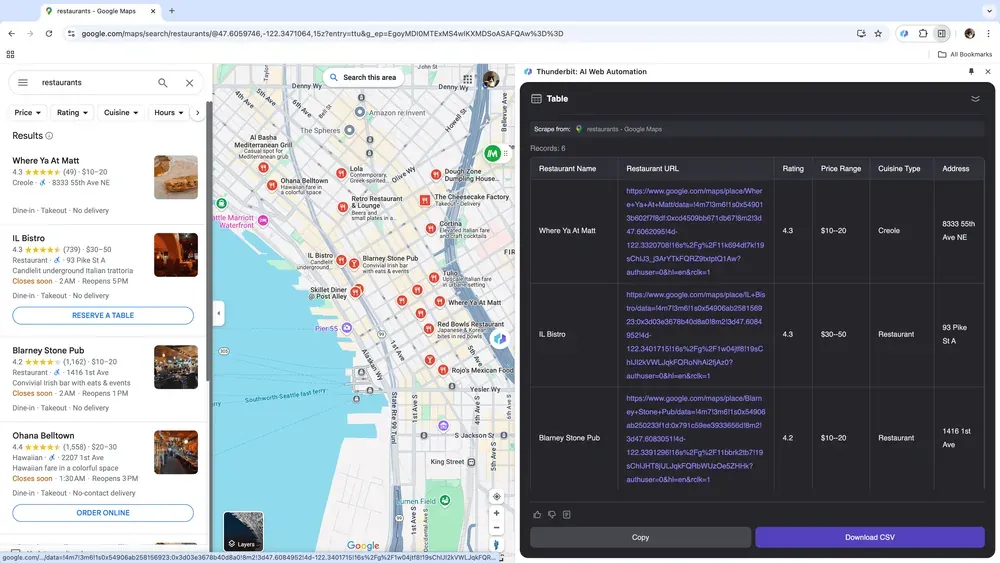
Escenario 4: análisis de datos de e-commerce
Si vendes online y quieres entender mejor a tu competencia, o si estás siguiendo tendencias de mercado para lanzar nuevos productos, Thunderbit también encaja bien. Puede recopilar datos de productos desde Amazon, incluidas descripciones detalladas, precios y reseñas de usuarios.
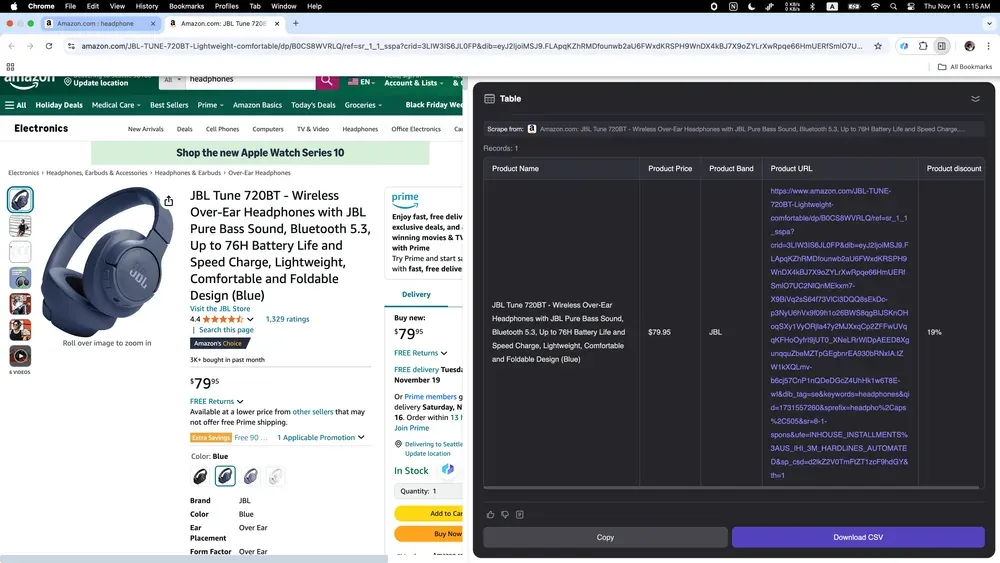
Thunderbit AI web scraper cambia la forma en que los equipos de negocio recopilan datos: el proceso se vuelve más rápido, más sencillo y menos dependiente de tareas repetitivas. Tanto si analizas propiedades inmobiliarias, como si buscas clientes potenciales o estudias tendencias de e-commerce, los web scrapers con IA pueden ahorrarte muchas horas y reducir errores. Usar IA en el web scraping no va solo de ir más rápido; también ayuda a convertir datos dispersos en información accionable. ¿Listo para empezar? Prueba Thunderbit y da el primer paso hacia un web scraping más inteligente.
Prueba Thunderbit AI Web Scraper
Consejos exclusivos para limpiar datos
Con los scrapers tradicionales, el trabajo difícil suele empezar después de la extracción: limpiar, normalizar y revisar los datos. La IA de Thunderbit puede hacer parte de esa limpieza durante el propio scraping usando LLM, lo que reduce la carga de trabajo en un 83% gracias a estas funciones:
Consejo 1: alineación inteligente de campos
Cuando combinas datos heterogéneos de varias fuentes, por ejemplo directorios públicos, páginas de contacto y Zillow, la IA de Thunderbit establece automáticamente relaciones de mapeo semántico:
- Identifica correspondencias entre campos de distintas fuentes de datos (por ejemplo, "price" ↔ "售价" ↔ "Price")
- Fusiona de forma inteligente campos similares (por ejemplo, "area" y "square feet")
- Estandariza datos entre plataformas (por ejemplo, "cargo actual" de un perfil público y "property status" de Zillow se unifican como datos de etiqueta)
Consejo 2: completado con contexto
Con la capacidad de comprensión contextual de los modelos de lenguaje grande, Thunderbit alcanza una tasa de completado de datos líder en el sector del 99%:
- Completado de direcciones: rellena automáticamente ciudad/estado a partir del código postal (por ejemplo, introducir 10001 → New York City, NY)
- Inferencia de trayectoria profesional: predice posibles experiencias laborales a partir de información pública de perfiles profesionales
Consejo 3: optimización de datos
- Traducción multilingüe (compatible con traducción en tiempo real en 12 idiomas, incluidos inglés, chino y japonés)
- Resumen inteligente (convierte una descripción de producto de 500 palabras en tres puntos clave de venta)
- Unificación de unidades (convierte automáticamente square feet ↔ square meters, Fahrenheit ↔ Celsius)
- Estandarización de formato (fechas unificadas a YYYY-MM-DD, moneda unificada a USD)
Consejo 4: verificación de calidad
- Corrección inteligente de errores: arregla automáticamente errores de formato (por ejemplo, phone number +01 138-1234-5678 → +113812345678)
- Validación lógica: garantiza que "year built" sea anterior a "last renovation time"
Consejo 5: etiquetado con IA
Genera automáticamente etiquetas inteligentes mediante procesamiento de lenguaje natural:
- Etiquetas de análisis de sentimiento (clasifica automáticamente las reseñas de clientes como positivas/negativas/neutrales)
- Etiquetas de valor comercial (marca automáticamente "clientes con alto potencial"/"propiedades para seguimiento")
- Etiquetas de clasificación por sector (añade automáticamente a perfiles públicos etiquetas como "tech|finance|healthcare")
La desventaja del data scraping
Aunque el data scraping aporta mucho valor, también conviene tener claros sus límites. Las consideraciones legales son lo primero: normativas como GDPR y CCPA imponen requisitos estrictos sobre la recopilación de datos, así que hay que cumplir con cuidado la legislación de privacidad. Además, muchos sitios web despliegan defensas avanzadas como Cloudflare para detectar y bloquear actividades de scraping mediante restricciones de IP.
El futuro del data scraping en la era de la IA
La evolución de la IA está convirtiendo el web scraping en una solución empresarial mucho más intuitiva. Imagina que introduces un dominio, como zillow.com, y una petición, como "extraer todos los listados de propiedades en New York City"; la IA podría mapear automáticamente cada punto de datos relevante, desde detalles de la propiedad hasta tendencias de precios, sin configuración manual. Estos sistemas inteligentes integrarán los datos extraídos en los flujos de trabajo del negocio, enviando automáticamente información de prospectos desde sitios públicos y directorios a los CRM o volcándola en paneles de analítica. El reconocimiento avanzado de patrones permitirá funciones de scraping predictivo para monitorizar de forma proactiva cambios de inventario o tendencias de mercado emergentes. Y, sobre todo, la IA podrá gestionar el cumplimiento normativo de forma dinámica, ajustando los parámetros de scraping en tiempo real para adaptarse a regulaciones cambiantes y mantener registros de auditoría transparentes.
Este cambio impulsado por IA no solo democratiza el acceso a inteligencia de negocio crítica; también replantea cómo las organizaciones trabajan con los datos web. A medida que estas tecnologías maduren, quienes adopten antes soluciones de scraping con IA como Thunderbit podrán obtener ventajas competitivas reales en la toma de decisiones basada en datos.
Preguntas frecuentes
-
¿Qué es Thunderbit? Thunderbit es una extensión inteligente para navegador basada en modelos de lenguaje grande (LLM), diseñada para las necesidades modernas de recopilación de datos. No solo ofrece capacidades de AI web scraping, sino que también integra procesamiento de datos multimodales y permite extraer datos de forma completa desde páginas web dinámicas, documentos PDF, imágenes y vídeos. Como solución de navegador local, puede trabajar directamente con páginas a las que ya accedes con tu sesión, como portales internos o aplicaciones SaaS, y adaptarse automáticamente a los cambios de frameworks front-end modernos.
-
¿Cómo funciona el AI web scraper de Thunderbit? El AI web scraper de Thunderbit usa IA para extraer datos estructurados de sitios web. Puedes hacer clic en "AI Suggest Columns" para que la IA sugiera cómo extraer los datos del sitio actual y después pulsar "Scrape" para recopilar la información. Puede procesar datos de cualquier sitio web, PDF o imagen en solo dos clics.
-
¿Cuál es la diferencia entre el scraping de listas y el scraping de subpáginas? El scraping de listas está optimizado para escenarios con paginación, como listas de productos de e-commerce, porque reconoce automáticamente la lógica de paginación y extrae miles de registros. El scraping de subpáginas utiliza un modo de recopilación con estructura en árbol, como listados de propiedades en Zillow → páginas de detalle → planos, y establece automáticamente relaciones entre tabla principal y subtabla mediante asociación semántica.
-
¿Pueden usar Thunderbit personas sin conocimientos de programación? Thunderbit incorpora una interacción en lenguaje natural: basta con describir lo que necesitas, por ejemplo "name, email, phone", y el sistema genera automáticamente un plan de scraping. Nuestros datos de prueba muestran que el 85% de los usuarios completa su primera recopilación de datos en menos de 10 minutos, sin conocimientos de programación web.
-
¿Qué tipos de datos puede manejar Thunderbit? Thunderbit admite el reconocimiento inteligente de muchos tipos de datos:
- Datos estructurados: tablas, listas (por ejemplo, especificaciones de productos de Amazon)
- Datos no estructurados: texto de reseñas, documentos PDF (reconocimiento automático)
- Datos multimodales: etiquetas de precio en imágenes, extracción de subtítulos de vídeo
- Datos dinámicos: contenido con desplazamiento infinito, imágenes con carga diferida
- Datos relacionados: mapeo de relaciones entre páginas (por ejemplo, contactos en páginas públicas/directorios → información de la empresa)
-
¿Cómo empezar a usar Thunderbit? Descubre más sobre nuestras capacidades de scraping o explora nuestra biblioteca de plantillas para empezar de inmediato.
Más información:
- Las mejores herramientas y software de web scraping en 2025
- Cómo hacer scraping de cualquier sitio web usando IA
- Cómo configurar Thunderbit
Prueba AI Web Scraper Get Started Free




