Si alguna vez te has preguntado cómo las empresas convierten una montaña de datos en bruto y dispersos en paneles elegantes y análisis impulsados por IA, no eres el único. ¿El ingrediente secreto? Todo empieza con la ingesta de datos, la heroína silenciosa que está al comienzo de cada proceso empresarial basado en datos. En un mundo en el que estamos generando (eso son 21 ceros, por si los estabas contando), llevar los datos del punto A al punto B —rápido, con precisión y en un formato utilizable— nunca ha sido tan crítico.
Llevo años trabajando en SaaS y automatización, y he visto de primera mano cómo la estrategia adecuada de ingesta de datos puede hacer que un negocio triunfe o fracase. Tanto si estás gestionando leads de ventas, monitorizando tendencias del mercado o simplemente intentando que tus operaciones funcionen sin fricciones, entender cómo funciona la ingesta de datos (y cómo está evolucionando) es el primer paso para desbloquear valor real para el negocio. Así que vamos al grano: ¿qué es la ingesta de datos, por qué importa y cómo están cambiando las reglas de juego herramientas modernas —como — para todo el mundo, desde analistas hasta emprendedores?
¿Qué es la ingesta de datos? La base del negocio impulsado por datos
En esencia, la ingesta de datos es el proceso de recopilar, importar y cargar datos desde múltiples fuentes en un sistema central —piensa en una base de datos, un almacén de datos o un lago de datos— para que puedan analizarse, visualizarse o utilizarse para impulsar decisiones de negocio. Imagínala como la “puerta de entrada” de tu canal de datos: así es como llevas todos esos ingredientes en bruto (hojas de cálculo, APIs, registros, páginas web, flujos de sensores) a tu cocina antes de empezar a preparar información útil.
La ingesta de datos es la primera etapa de cualquier canal de datos (), ya que rompe los silos y garantiza que haya datos de alta calidad y oportunos disponibles para analítica, business intelligence y machine learning. Sin ella, tu información valiosa se queda atrapada en sistemas aislados —“invisible para las personas que la necesitan”, como dijo un experto del sector.
Así encaja en el panorama general:
- Ingesta de datos: recopila datos en bruto de varias fuentes y los lleva a un repositorio central.
- Integración de datos: combina y alinea datos de distintas fuentes para que funcionen juntos.
- Transformación de datos: limpia, da formato y enriquece los datos para dejarlos listos para el análisis.
Piensa en la ingesta como llevar todos los víveres a casa desde distintas tiendas. La integración es organizarlos en la despensa, y la transformación es preparar y cocinar la comida.
Por qué la ingesta de datos importa para las organizaciones modernas
Seamos claros: en el mundo empresarial actual, los datos oportunos y bien ingeridos son un activo estratégico. Las empresas que dominan la ingesta de datos pueden derribar silos, habilitar análisis en tiempo real y tomar decisiones más rápidas e inteligentes. Por el contrario, una ingesta deficiente significa informes lentos, oportunidades perdidas y decisiones basadas en datos obsoletos o incompletos.
Aquí tienes formas concretas en las que una ingesta de datos eficiente aporta valor al negocio:
| Caso de uso | Cómo ayuda una ingesta de datos eficiente |
|---|---|
| Generación de leads de ventas | Consolida leads de formularios web, redes sociales y bases de datos en un solo sistema casi en tiempo real, para que los equipos de ventas respondan más rápido y mejoren sus tasas de conversión. |
| Paneles operativos | Alimenta de forma continua los datos de los sistemas de producción en plataformas de analítica, ofreciendo KPI actualizados a la dirección y permitiendo actuar con rapidez ante cualquier problema. |
| Vista 360° del cliente | Integra datos de clientes procedentes de CRM, soporte, e-commerce y redes sociales para crear perfiles unificados que permitan marketing personalizado y un servicio proactivo (Cake.ai). |
| Mantenimiento predictivo | Ingiere grandes volúmenes de datos de sensores e IoT, lo que permite a los modelos analíticos detectar anomalías y prever fallos antes de que ocurran, reduciendo tiempos de inactividad y costes. |
| Analítica de riesgo financiero | Transmite datos de transacciones y feeds de mercado a modelos de riesgo, ofreciendo a bancos y traders una visión en tiempo real de la exposición y permitiendo detectar fraudes al instante. |
Y los números no mienten: , pero esas inversiones solo dan frutos si los datos pueden ingerirse y confiar en ellos.
Ingesta de datos vs. integración de datos y transformación de datos: aclarando la confusión
Es fácil enredarse con la jerga, así que vamos a dejarlo claro:
- Ingesta de datos: el paso inicial de recopilar e importar datos en bruto desde los sistemas de origen. Piensa: “llevarlo todo a la cocina”.
- Integración de datos: combinar y alinear datos de distintas fuentes, asegurando consistencia y una visión unificada. Piensa: “organizar la despensa”.
- Transformación de datos: convertir los datos de brutos a utilizables, limpiándolos, dándoles formato, agregándolos y enriqueciéndolos. Piensa: “preparar y cocinar la comida”.
Una confusión habitual es pensar que la ingesta y ETL (Extract, Transform, Load) son lo mismo. En realidad, la ingesta es solo la parte de “extract”: extraer los datos en bruto. Después vienen la integración y la transformación, que dejan los datos listos para el análisis ().
¿Por qué importa esto? Si solo necesitas un conjunto de datos rápido desde una página web, puede que te baste con una herramienta ligera de ingesta. Pero si vas a combinar y limpiar datos de cinco sistemas distintos, también necesitarás integración y transformación.
Métodos tradicionales de ingesta de datos: ETL y sus limitaciones
Durante décadas, el método más habitual para la ingesta de datos fue ETL (Extract, Transform, Load). Los ingenieros de datos escribían scripts o utilizaban software especializado para extraer periódicamente datos de los sistemas de origen, limpiarlos y darles formato, y cargarlos en un almacén de datos. Normalmente funcionaba con una programación por lotes —piensa en actualizaciones nocturnas.
Pero a medida que el volumen y la variedad de datos crecieron, el ETL tradicional empezó a mostrar su edad:
- Configuración compleja y que consume mucho tiempo: crear y mantener canalizaciones ETL requería bastante programación y habilidades especializadas. Los equipos no técnicos tenían que esperar a que TI lo dejara todo listo ().
- Cuellos de botella del procesamiento por lotes: los trabajos ETL se ejecutaban en lotes, lo que retrasaba la disponibilidad de los datos. En un mundo en el que importan las ideas instantáneas, esperar horas o días simplemente no sirve ().
- Problemas de escalabilidad y velocidad: las canalizaciones heredadas a menudo no podían con los enormes volúmenes de datos actuales y requerían ajustes y actualizaciones constantes.
- Rigidez y poca flexibilidad: añadir nuevas fuentes de datos o cambiar esquemas era un dolor de cabeza, y a menudo rompía la canalización o exigía rehacer mucho trabajo.
- Alto coste de mantenimiento: las canalizaciones podían fallar por todo tipo de razones, lo que exigía atención continua por parte de los ingenieros.
- Limitado a datos estructurados: el ETL clásico se diseñó para filas y columnas ordenadas, no para los datos desordenados y no estructurados (como páginas web o imágenes) que hoy representan .
En resumen: ETL era genial para una época más simple, pero le está costando seguir el ritmo de la velocidad, la escala y la diversidad de los datos modernos.
El auge de la ingesta de datos moderna: soluciones automatizadas impulsadas por IA
Llega la nueva era: herramientas modernas de ingesta de datos que aprovechan la automatización, la escalabilidad en la nube y la IA para hacer que la recopilación de datos sea más rápida, sencilla y flexible.
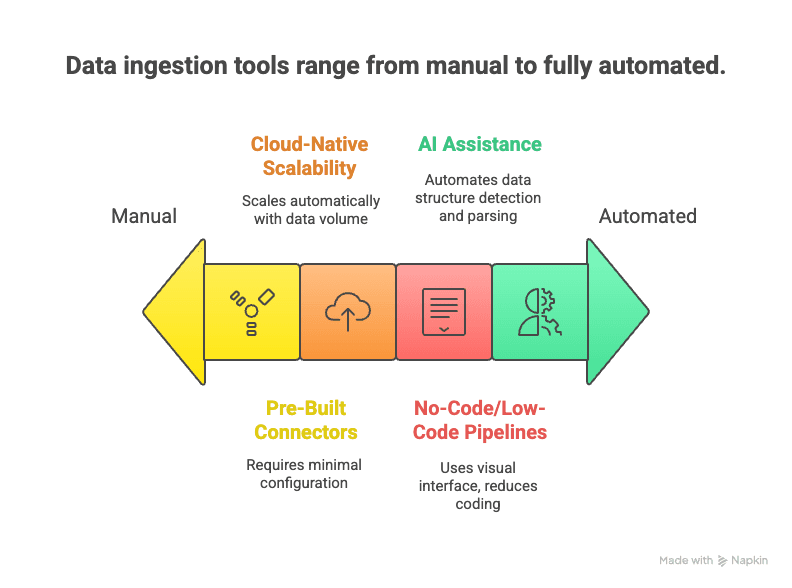
Esto es lo que las diferencia:
- Canalizaciones sin código o con poco código: interfaces de arrastrar y soltar y asistentes de IA permiten configurar flujos de datos sin escribir código ().
- Conectores prediseñados: cientos de conectores listos para usar para fuentes de datos populares; solo tienes que introducir tus credenciales y empezar.
- Escalabilidad nativa en la nube: los servicios elásticos en la nube pueden manejar enormes flujos de datos en tiempo real ().
- Compatibilidad con tiempo real y streaming: las herramientas modernas admiten tanto ingesta en streaming como por lotes, para que elijas lo que mejor se adapte a tus necesidades ().
- Asistencia de IA: la IA puede detectar automáticamente estructuras de datos, recomendar reglas de parseo e incluso realizar comprobaciones de calidad de datos sobre la marcha ().
- Compatibilidad con datos no estructurados: técnicas de NLP y visión por ordenador pueden convertir páginas web, PDFs o imágenes desordenadas en tablas estructuradas.
- Menor mantenimiento: los servicios gestionados se encargan de la monitorización, la escalabilidad y las actualizaciones, para que puedas centrarte en usar los datos y no en vigilar canalizaciones.
¿El resultado? Una ingesta de datos más rápida de configurar, más fácil de modificar y capaz de manejar el mundo caótico de los datos actuales.
La ingesta de datos en acción: aplicaciones sectoriales y desafíos
Veamos cómo se aplica la ingesta de datos en el mundo real y qué retos afrontan distintos sectores.
Retail y e-commerce
Los minoristas ingieren datos de sistemas de punto de venta, tiendas online, apps de fidelización e incluso sensores en tienda. Al consolidar transacciones de ventas, clics en la web y registros de inventario, pueden obtener una visión en tiempo real de los niveles de stock y las tendencias de compra. ¿El reto? Manejar datos rápidos y de gran volumen, especialmente en periodos de máxima demanda, e integrar datos entre canales online y offline.
Finanzas y banca
Los bancos y las firmas de trading ingieren flujos de datos de transacciones, feeds de mercado e interacciones con clientes. La ingesta en tiempo real es crucial para la detección de fraude y la gestión del riesgo. Pero con estrictos requisitos de cumplimiento y seguridad, cualquier fallo en el proceso de ingesta puede tener consecuencias graves.
Empresas tecnológicas e internet
Los gigantes tecnológicos ingieren enormes flujos de eventos en tiempo real (cada clic, like o compartir) para analizar el comportamiento de los usuarios y alimentar motores de recomendación. La escala es inmensa, y el reto está en separar la señal del ruido, garantizando la calidad y la coherencia de los datos.
Sanidad
Los hospitales ingieren datos de historiales clínicos electrónicos, sistemas de laboratorio y dispositivos médicos para crear registros unificados de pacientes y habilitar analítica predictiva. ¿Los grandes obstáculos? La interoperabilidad (distintos sistemas que hablan “idiomas” diferentes) y la privacidad del paciente.
Inmobiliario
Las empresas inmobiliarias ingieren datos de servicios de anuncios, portales de propiedades y registros públicos para construir bases de datos completas. El reto consiste en fusionar datos de múltiples fuentes —a menudo no estructurados— y mantenerlos actualizados a medida que los anuncios cambian con rapidez.
Los desafíos comunes en todos los sectores incluyen:
- Gestionar la variedad de datos (estructurados, semiestructurados y no estructurados)
- Equilibrar necesidades de tiempo real frente a por lotes
- Garantizar la calidad y coherencia de los datos
- Cumplir los requisitos de seguridad y conformidad
- Escalar para manejar volúmenes crecientes de datos
Superar estos retos es clave para lograr mejores resultados de negocio: análisis más precisos, toma de decisiones en tiempo real y un cumplimiento más sólido.
Thunderbit: simplificando la ingesta de datos con AI Web Scraper
Ahora hablemos de dónde encaja Thunderbit en todo esto. es una extensión de Chrome de AI Web Scraper diseñada para hacer que la ingesta de datos web sea accesible para todo el mundo, incluso si no sabes nada de código.
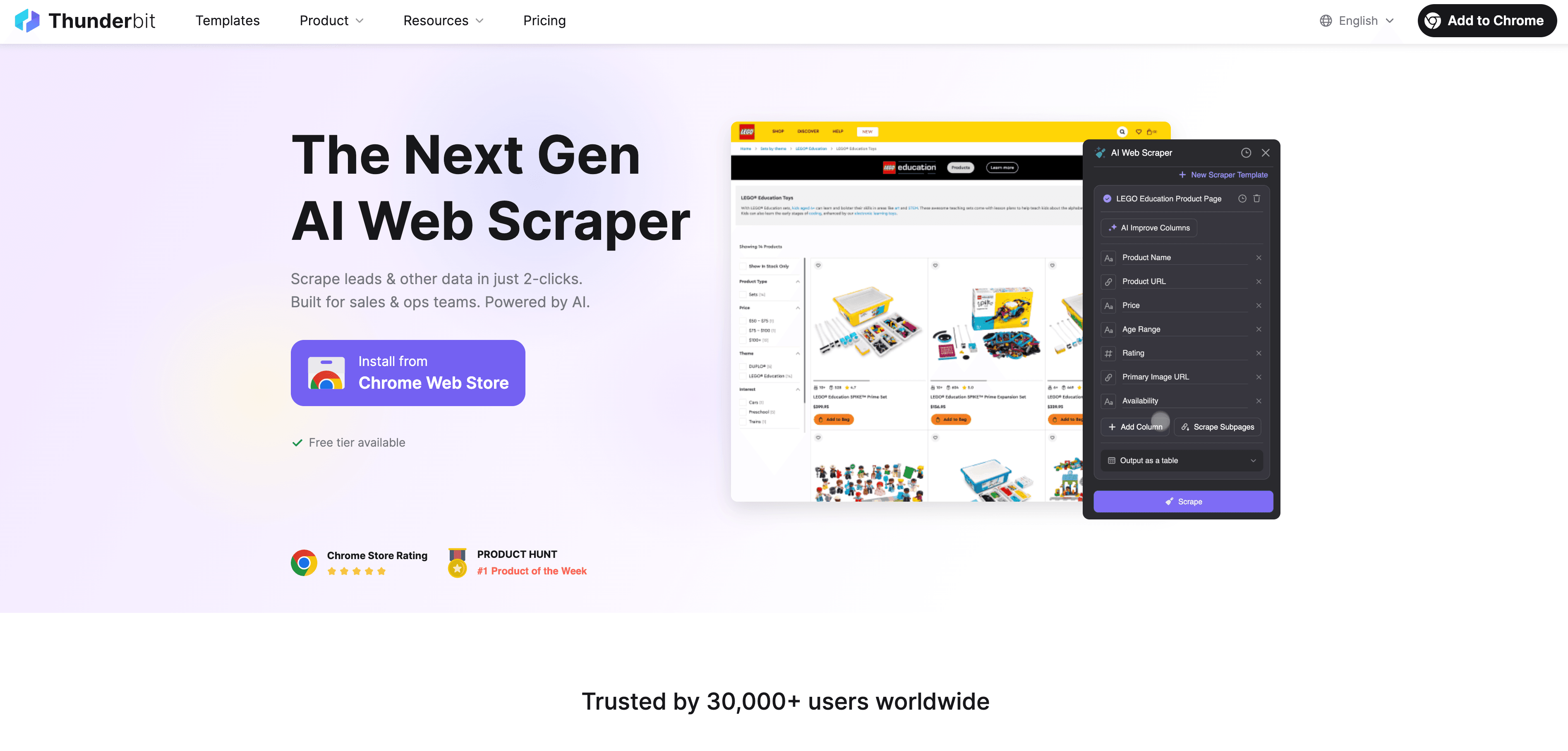
Estas son las razones por las que Thunderbit cambia las reglas del juego para los usuarios de negocio:
- Extracción web en 2 clics: pasa de una página web caótica a un conjunto de datos estructurado en dos clics. Haz clic en “AI Suggest Fields” y luego en “Scrape”, y listo.
- Sugerencias de campos impulsadas por IA: la IA de Thunderbit lee la página y recomienda las mejores columnas para extraer, ya sea un directorio de empresas, un listado de productos o un perfil de LinkedIn.
- Extracción automática de subpáginas: ¿necesitas más detalles? Thunderbit puede visitar cada subpágina (como fichas de producto o perfiles individuales) y enriquecer tu tabla automáticamente.
- Gestión de paginación: puede manejar listas paginadas y páginas con scroll infinito, para que no se te escape ningún dato.
- Plantillas prediseñadas: para sitios populares como Amazon, Zillow o Shopify, Thunderbit ofrece plantillas de 1 clic, sin configuración previa.
- Exportación gratuita de datos: exporta tus datos directamente a Excel, Google Sheets, Airtable o Notion, sin coste adicional.
- Extracción programada: configura trabajos de scraping para ejecutarlos automáticamente con cualquier intervalo (por ejemplo, revisiones diarias de precios de la competencia).
- AI Autofill: automatiza también el relleno de formularios y tareas web repetitivas.
Thunderbit es perfecto para equipos de ventas que extraen leads, analistas de e-commerce que monitorizan precios o agentes inmobiliarios que recopilan anuncios de propiedades. Se trata de convertir datos web no estructurados en información accionable, y hacerlo rápido.
Si quieres ver Thunderbit en acción, echa un vistazo a nuestro o explora nuestro para ver más guías.
Comparación de soluciones de ingesta de datos: enfoques tradicionales vs. modernos
Aquí tienes una comparación rápida lado a lado:
| Criterio | Herramientas ETL tradicionales | Herramientas modernas de IA/nube | Thunderbit (AI Web Scraper) |
|---|---|---|---|
| Experiencia del usuario | Alta (requiere programación/TI) | Media (low-code, algo de configuración) | Baja (2 clics, sin necesidad de programar) |
| Fuentes de datos | Estructuradas (bases de datos, CSV) | Amplias (bases de datos, SaaS, APIs) | Cualquier sitio web, datos no estructurados |
| Velocidad de implementación | Lenta (semanas/meses) | Más rápida (días) | Inmediata (minutos) |
| Compatibilidad con tiempo real | Limitada (por lotes) | Alta (streaming/por lotes) | Bajo demanda y programada |
| Escalabilidad | Complicada | Alta (nativa en la nube) | Media/alta (scraping en la nube) |
| Mantenimiento | Alto (canalizaciones frágiles) | Medio (servicios gestionados) | Bajo (la IA se adapta a los cambios) |
| Transformación | Rígida, previa | Flexible, posterior a la carga | Básica (indicaciones de campos por IA) |
| Mejor caso de uso | Integración interna por lotes | Canales de analítica | Datos web, fuentes externas |
¿La conclusión? Elige la herramienta según la tarea. Para datos web o fuentes no estructuradas, Thunderbit suele ser la opción más rápida y sencilla.
El futuro de la ingesta de datos: automatización y estrategias cloud-first
De cara al futuro, la ingesta de datos solo será más inteligente y más automatizada. Esto es lo que se avecina:
- Tiempo real por defecto: el antiguo paradigma por lotes está desapareciendo. Cada vez se crean más canalizaciones para datos en tiempo real y guiados por eventos ().
- Cloud-first y “Zero ETL”: las plataformas en la nube facilitan conectar orígenes y destinos sin canalizaciones manuales.
- Automatización impulsada por IA: el machine learning tendrá un papel más importante al configurar, monitorizar y optimizar canalizaciones, detectando anomalías, corrigiendo errores e incluso enriqueciendo datos sobre la marcha.
- Sin código y autoservicio: más herramientas permitirán a usuarios de negocio configurar flujos de datos con lenguaje natural o interfaces visuales.
- Ingesta en edge e IoT: a medida que se genere más datos en el edge, la ingesta se hará más cerca de la fuente, con filtrado y agregación inteligentes.
- Gobernanza y metadatos: el etiquetado automático, el seguimiento de linaje y el cumplimiento estarán integrados en cada paso.
En resumen: el futuro consiste en hacer que la ingesta de datos sea más rápida, más accesible y más fiable, para que puedas centrarte en los insights y no en la infraestructura.
Conclusión: conclusiones clave para usuarios de negocio
- La ingesta de datos es el primer paso crítico en cualquier iniciativa basada en datos. Si quieres insights, primero tienes que meter los datos dentro, rápido y de forma fiable.
- Las herramientas modernas impulsadas por IA, como Thunderbit, hacen que la ingesta de datos sea accesible para todo el mundo, no solo para los profesionales de TI. Con extracción en 2 clics, sugerencias de campos por IA y tareas programadas, puedes convertir datos web desordenados en oro para el negocio.
- Elegir la herramienta adecuada importa: usa ETL tradicional para datos internos estables y estructurados; herramientas modernas en la nube para analítica general; y Thunderbit para datos web y no estructurados.
- Mantente a la vanguardia: la automatización, la nube y la IA están haciendo que la ingesta de datos sea más inteligente y más fácil. No te quedes anclado en el pasado: explora nuevas soluciones y prepara tu estrategia de datos para el futuro.
Preguntas frecuentes
1. ¿Qué es la ingesta de datos, en palabras sencillas?
La ingesta de datos es el proceso de recopilar e importar datos de distintas fuentes (como sitios web, bases de datos o archivos) a un sistema central para poder analizarlos o utilizarlos en decisiones de negocio. Es el primer paso de cualquier canal de datos.
2. ¿En qué se diferencia la ingesta de datos de la integración y la transformación de datos?
La ingesta de datos consiste en traer datos en bruto. La integración de datos combina y alinea datos de distintas fuentes, mientras que la transformación de datos los limpia y les da formato para analizarlos. Piensa: ingesta = recopilar, integración = organizar, transformación = preparar y cocinar.
3. ¿Cuáles son los mayores retos de los métodos tradicionales de ingesta de datos?
Los métodos tradicionales como ETL tardan en configurarse, requieren mucha programación, tienen dificultades con datos no estructurados y no pueden seguir el ritmo de las necesidades de tiempo real actuales. Además, su mantenimiento es alto y son poco flexibles cuando cambian las fuentes de datos.
4. ¿Cómo hace Thunderbit que la ingesta de datos sea más fácil?
Thunderbit usa IA para que cualquier persona pueda extraer y estructurar datos web en solo dos clics, sin necesidad de programar. Puede manejar subpáginas, paginación e incluso programar tareas recurrentes, exportando directamente a Excel, Google Sheets, Airtable o Notion.
5. ¿Cuál es el futuro de la ingesta de datos?
El futuro gira en torno a la automatización, las estrategias cloud-first y las canalizaciones impulsadas por IA. Veremos más flujos de datos en tiempo real, una gestión de errores más inteligente y herramientas que permitan a los usuarios de negocio configurar la ingesta de datos con lenguaje natural o interfaces visuales.
Más información: