
Seamos realistas: la web es un universo sin fin que crece a toda velocidad. Cada día surgen más de 252,000 sitios nuevos, y solo el índice de Google ya suma más de 30 mil millones de páginas. Si alguna vez te has preguntado cómo hacen los buscadores para no perderse—o cómo las empresas encuentran lo que buscan entre tanto contenido—créeme, no eres el único. Llevo años metido en SaaS y automatización, y todavía me preguntan: “¿En qué se diferencia el web crawling del web scraping? ¿No es lo mismo?” Spoiler: no, y confundirlos puede hacer que tu proyecto se vaya por el camino equivocado.
Así que, tanto si eres de ventas buscando leads, llevas un ecommerce y quieres vigilar precios, o simplemente quieres lucirte en la próxima reunión, vamos a dejar claro qué hace realmente un raspador web, en qué se distingue de un scraper y por qué elegir bien la herramienta (como Thunderbit) puede ahorrarte muchos dolores de cabeza—y hasta salvarte el finde.
Conceptos básicos: ¿Qué es un raspador web?

Imagina al bibliotecario más obsesivo del planeta, uno que no solo ordena los libros, sino que revisa cada estante todos los días para ver si hay novedades. Eso es, básicamente, lo que hace un raspador web: en vez de libros, recorre miles de millones de páginas online. Un raspador web (también llamado spider o bot) es un programa automático que explora la web de forma sistemática, saltando de enlace en enlace y registrando lo que encuentra. Así es como buscadores como Google y Bing arman sus enormes índices, permitiendo que todos podamos buscar lo que sea.
Si te suenan nombres como “Googlebot” o “Bingbot”, son simplemente raspadores web famosos que trabajan tras bambalinas. También hay herramientas más modernas como Firecrawl, que permiten a desarrolladores y empresas rastrear sitios enteros y convertirlos en datos estructurados para IA o análisis.
Pero aquí va lo importante: el web crawling va de descubrir—encontrar e indexar páginas, no de extraer datos concretos. Para eso está el scraping (de eso hablamos en un momento).
¿Cómo funciona el web crawling?
Vamos a ver cómo se mueve un raspador web. Piensa en él como un explorador digital con una mochila llena de “URLs semilla”—los puntos de partida. Así va el proceso:
- URLs semilla: El raspador arranca con una lista de direcciones web conocidas.
- Obtener y analizar: Visita cada URL, descarga la página y busca enlaces dentro.
- Seguir enlaces: Cada nuevo enlace encontrado se suma a la lista de pendientes (la “frontera de URLs”).
- Indexación: Mientras avanza, el raspador guarda información de cada página—a veces todo el contenido, a veces solo metadatos.
- Respeto: Consulta el archivo robots.txt de cada web para ver si puede rastrear, y espera entre peticiones para no saturar el servidor.
- Actualización constante: Como la web cambia todo el tiempo, los raspadores vuelven a visitar páginas para mantener el índice al día.
Es como recorrer una ciudad a pie, apuntando cada nuevo local y actualizando tu mapa cada vez que algo cambia.
Componentes clave de un raspador web
Aunque no seas técnico, viene bien saber qué hay detrás:
- Frontera de URLs (cola): La lista principal de URLs por visitar.
- Descargador: La parte que realmente baja la página web.
- Analizador: El “lector” que saca enlaces y, a veces, otra info de la página.
- Filtro y deduplicación: Evita que el raspador entre en bucles o repita páginas.
- Almacenamiento/Índice de datos: Donde se guarda todo lo que se descubre para usarlo después.
Imagínatelo como una cadena de montaje: uno recoge el periódico, otro subraya los titulares, otro archiva los recortes y alguien lleva el control de qué periódicos faltan.
Cómo rastrear un sitio web: herramientas y métodos
Si eres usuario de negocio, puede que te tiente crear tu propio raspador. Mi consejo: ni lo intentes. A menos que quieras montar el próximo Google, hay muchas herramientas que ya hacen el trabajo duro por ti.
Herramientas populares de web crawling:
- Scrapy: De código abierto, pensada para desarrolladores, ideal para proyectos grandes.
- Apache Nutch: Usada para indexar big data e investigación.
- Heritrix: Herramienta de Internet Archive para guardar la web.
- Screaming Frog SEO Spider: Muy usada por expertos SEO para rastrear y auditar webs.
- Firecrawl: Moderna, basada en API, permite rastrear y extraer datos estructurados de sitios enteros.
Ojo: La mayoría de estas herramientas requieren algo de maña técnica. Incluso las opciones “sin código” pueden tener su curva de aprendizaje—como elegir elementos HTML, adaptarse a cambios en la web o lidiar con contenido dinámico. Si solo necesitas datos de unas pocas páginas, probablemente no te hace falta un raspador completo.
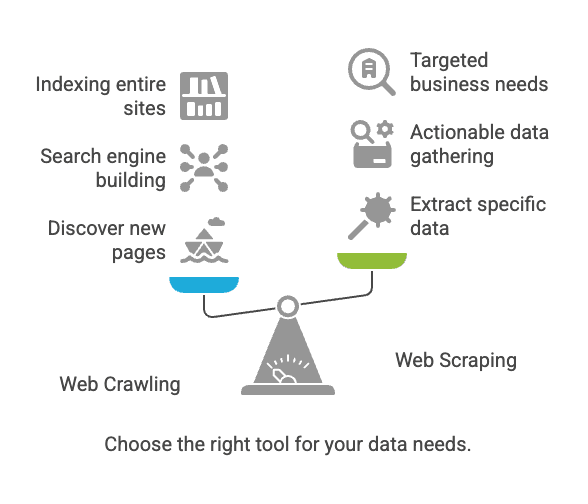
Web crawling vs. web scraping: ¿en qué se diferencian?
Aquí es donde suele haber lío. El crawling y el scraping están relacionados, pero no son lo mismo.
| Aspecto | Web Crawling | Web Scraping |
|---|---|---|
| Objetivo | Descubrir e indexar páginas web | Extraer datos específicos de páginas web |
| Analogía | Bibliotecario catalogando todos los libros | Copiar información clave de algunas páginas |
| Resultado | Lista de URLs, contenido de páginas, mapa del sitio | Datos estructurados (CSV, Excel, JSON, etc.) |
| Usado por | Motores de búsqueda, herramientas SEO, archivadores | Ventas, ecommerce, analistas, investigadores |
| Escala típica | Miles de millones de páginas (cobertura amplia) | Docenas a miles de páginas (enfoque selectivo) |
En resumen: El crawling es para encontrar páginas; el scraping es para sacar los datos que te interesan (nimbleway.com).
Retos comunes y buenas prácticas en crawling y scraping
Retos habituales
- Cambios en la estructura del sitio: Un pequeño rediseño puede romper tu herramienta (octoparse.com).
- Contenido dinámico: Muchos sitios cargan datos con JavaScript, lo que los raspadores básicos no ven.
- Medidas anti-bots: CAPTCHAs, bloqueos de IP y logins pueden frenarte en seco.
- Escalabilidad: Rastrear miles de páginas puede saturar tu equipo (o hacer que te bloqueen la IP).
- Cuestiones legales/éticas: Extraer datos públicos suele estar bien, pero revisa siempre los términos del sitio y la ley de privacidad (web.instantapi.ai).
Buenas prácticas
- Elige la herramienta adecuada: Si no eres programador, empieza con un raspador sin código.
- Define bien tus objetivos: Ten claro qué datos necesitas y para qué.
- Respeta las normas del sitio: Consulta siempre el
robots.txty los términos de uso. - No sobrecargues los sitios: Añade pausas entre peticiones; no satures los servidores.
- Planifica el mantenimiento: Las webs cambian—prepárate para ajustar tu configuración de vez en cuando.
- Cuida tus datos: Guarda los resultados de forma segura y revisa duplicados o errores.
Casos de uso típicos: crawling vs. scraping
Web Crawling
- Indexación de buscadores: Googlebot y Bingbot rastrean la web para mantener los resultados al día (en.wikipedia.org).
- Archivado web: Internet Archive rastrea sitios para la Wayback Machine.
- Auditoría SEO: Herramientas que rastrean tu web para detectar enlaces rotos o etiquetas que faltan.
Web Scraping
- Monitoreo de precios: Tiendas extraen datos de productos de la competencia para ajustar precios (nextgeninvent.com).
- Generación de leads: Equipos de ventas sacan información de contacto de directorios.
- Agregación de contenido: Sitios de noticias o empleo recopilan listados de varias fuentes.
- Investigación de mercado: Analistas extraen reseñas o publicaciones en redes sociales para análisis de sentimiento.
Dato curioso: Más del 82% de las empresas de ecommerce usan web scraping para conseguir datos externos. Si tú no lo haces, seguro tu competencia sí.
¿Cuándo usar web crawling y cuándo scraping?
Aquí tienes una guía rápida para decidir:
-
¿Necesitas descubrir nuevas páginas o indexar un sitio entero?
→ Usa web crawling.
-
¿Ya sabes dónde están los datos que buscas (páginas o secciones concretas)?
→ Usa web scraping.
-
¿Estás montando un buscador o archivando la web?
→ El crawling es tu amigo.
-
¿Buscas datos útiles para ventas, precios o investigación?
→ El scraping es lo tuyo.
-
¿No lo tienes claro?
→ Empieza por scraping. La mayoría de necesidades de negocio no requieren crawling a gran escala.
Si eres usuario de negocio, lo más probable es que necesites scraping—datos estructurados y listos para usar.
Web scraping para empresas: la ventaja de Thunderbit
Ahora, veamos por qué la mayoría de los usuarios de negocio—sobre todo los que no programan—deberían centrarse en el scraping, y por qué Thunderbit está hecho para ti.
He visto demasiados equipos perder días (o semanas) peleando con herramientas de scraping “fáciles” que luego resultan ser un lío. Por eso creamos Thunderbit: para que extraer datos web sea tan fácil como dos clics.
¿Por qué Thunderbit es diferente?
- Flujo de trabajo en dos clics: Haz clic en “AI Suggest Fields” y luego en “Scrape”. Así de fácil. Sin código ni líos técnicos.
- Soporte para URLs y PDFs en lote: ¿Necesitas extraer datos de una lista de URLs o incluso de PDFs? Thunderbit lo hace sencillo.
- Exporta a donde quieras: Manda tus datos directo a Google Sheets, Airtable, Notion o descárgalos en CSV/JSON. Sin costes extra.
- Scraping de subpáginas: Thunderbit puede visitar automáticamente subpáginas (como detalles de productos) y enriquecer tu tabla de datos.
- Relleno automático con IA: Automatiza el llenado de formularios y tareas repetitivas en la web—como tener un asistente digital para lo pesado.
- Extractores gratuitos de email y teléfono: Saca toda la info de contacto de una página con un solo clic.
- Scraping en la nube o en el navegador: Elige lo que más te convenga—Thunderbit puede extraer datos en la nube (muy rápido) o en tu navegador (ideal para páginas con sesión iniciada).
- Sin curva de aprendizaje: Pensado para equipos de ventas, ecommerce y marketing que solo quieren resultados.
Si quieres ver ejemplos reales, revisa nuestras guías sobre cómo extraer productos de Amazon, cómo extraer resultados de Google Search o cómo extraer datos web a Excel.
Extrae datos de cualquier web con IA en 2 clics
Thunderbit vs. un raspador web tradicional
Comparativa directa para usuarios de negocio:
| Funcionalidad/Necesidad | Thunderbit | Raspador Web Tradicional (ej. Scrapy, Nutch) |
|---|---|---|
| Configuración | 2 clics, sin código | Configuración técnica, suele requerir scripts |
| Curva de aprendizaje | Mínima | Pronunciada (especialmente para no programadores) |
| Gestión de subpáginas | Automática, impulsada por IA | Manual, requiere scripts o configuración avanzada |
| URLs/PDFs en lote | Soporte integrado | Generalmente no soportado de serie |
| Formatos de salida | Google Sheets, Airtable, Notion, CSV | CSV, JSON (integración manual habitualmente) |
| Adaptabilidad | La IA se adapta a cambios en el sitio | Requiere actualizaciones manuales ante cambios |
| Casos de negocio | Ventas, ecommerce, SEO, operaciones | Indexación, investigación, archivado |
| Programación de tareas | Lenguaje natural | Cron jobs o programadores externos |
| Precio | Desde $15/mes, plan gratuito disponible | Gratis/código abierto, pero mayor coste de configuración/mantenimiento |
| Soporte | Enfocado al usuario, interfaz moderna | Basado en comunidad, orientado a desarrolladores |
Thunderbit está pensado para que pases de “necesito estos datos” a “aquí está mi hoja de cálculo” en el menor tiempo posible—sin depender de IT.
Conclusión: elige el enfoque adecuado para tu empresa

En resumen:
- Web crawling sirve para descubrir e indexar páginas—ideal para buscadores y auditorías de sitios.
- Web scraping es para extraer datos concretos y útiles—como leads de ventas, monitoreo de precios o agregación de contenido.
- Para la mayoría de usuarios de negocio, lo que necesitas es scraping. Y no hace falta saber programar.
La web no para de crecer y complicarse. Pero con el enfoque y la herramienta adecuados, puedes convertir ese caos en información útil. Si estás harto de pelearte con scrapers complicados o de esperar a IT, prueba Thunderbit. Te sorprenderá lo que puedes hacer en solo dos clics (y quizás hasta recuperes tu finde).
Si quieres ver Thunderbit en acción, instala nuestra extensión de Chrome, o descubre más consejos y guías en el Blog de Thunderbit.
Instalar la extensión de Chrome de Thunderbit
¡Feliz scraping (y deja el crawling para quien quiera montar el próximo Google)!
Preguntas frecuentes
1. ¿Necesito tanto un raspador web como un scraper para mi empresa?
No necesariamente. Si ya sabes en qué páginas está la información que buscas, un raspador web como Thunderbit es suficiente. Los raspadores son útiles cuando necesitas descubrir nuevas páginas—por ejemplo, para mapear un sitio entero o hacer auditorías SEO.
2. ¿Es legal el web scraping?
En general, extraer datos públicos es legal—sobre todo si no te saltas inicios de sesión, no violas los términos de uso ni recopilas información sensible. Sin embargo, siempre es recomendable revisar el archivo robots.txt y la política de privacidad del sitio, especialmente para usos comerciales.
3. ¿En qué se diferencia Thunderbit de otras herramientas de scraping?
Thunderbit está pensado para usuarios de negocio que no programan. A diferencia de los scrapers tradicionales que requieren conocimientos de HTML o configuraciones manuales, Thunderbit usa IA para identificar campos, navegar subpáginas y exportar los datos en el formato que necesitas—todo en solo dos clics.
4. ¿Thunderbit puede manejar sitios dinámicos y páginas con sesión iniciada?
Sí. Thunderbit ofrece scraping en el navegador para sesiones iniciadas y contenido dinámico, así como scraping en la nube para mayor velocidad y escala. Puedes elegir el modo que mejor se adapte a tus necesidades.
Lecturas recomendadas
- ¿Qué es el data scraping y cómo hacerlo en 2025?
- ¿Cuántos sitios web existen en el mundo?
- ¿Qué es un rastreador web? | Cómo funcionan los spiders | Cloudflare
Prueba el Raspador Web IA gratis Get Started Free




