

Características de una API REST explicadas (y lo que la mayoría hace mal)
Cada vez que sincronizas tu CRM, consultas actualizaciones de envíos o conectas dos herramientas SaaS, hay una API REST haciendo el trabajo pesado entre bastidores. La mayoría de la gente ni se fija en ello, hasta que algo se rompe.
Lo curioso es que, incluso entre desarrolladores, sigue habiendo bastante confusión sobre qué hace que una API sea "RESTful". El término se usa con tanta ligereza que en un hilo de Reddit alguien lo dijo sin rodeos: "No creo haber creado ni una sola API verdaderamente RESTful basada en la definición de Roy Fielding." Y lo decía un desarrollador, no un usuario de negocio. El concepto nació en la tesis doctoral de 2000 de Roy Fielding en UC Irvine, donde describió REST como un estilo arquitectónico —un conjunto de restricciones de diseño—, no como un protocolo, ni como un producto, ni como una especificación que descargas. Sin embargo, según el informe Postman 2025 State of the API, el uso de REST alcanza el 93% entre los profesionales de API. Así que casi todo el mundo lo usa, pero aun así muchos equipos no tienen claro lo que realmente exige. Este artículo te guiará por las 6 características esenciales de una API REST con un lenguaje claro, te mostrará cuáles suelen fallar más, te presentará un modelo de madurez para autoevaluarte y comparará REST con sus alternativas: SOAP, GraphQL y gRPC.
¿Qué es una API REST? (Una definición sencilla)
REST (Representational State Transfer) es un conjunto de reglas de diseño sobre cómo deben comunicarse los sistemas de software a través de una red.
Dicho de forma más precisa, es un estilo arquitectónico que define restricciones —como la ausencia de estado, la capacidad de caché y una interfaz uniforme— que marcan cómo interactúan los clientes (tu navegador, la app móvil o una herramienta de automatización) con los servidores (donde viven los datos). REST suele ejecutarse sobre HTTP y normalmente devuelve JSON, pero REST en sí no está atado a ningún protocolo ni a un formato de datos concreto.
Piensa en ello como las normas de etiqueta de una cena. REST no te dice qué comida sirves ni qué idioma hablas: define cómo pasas los platos, cómo pides más y cómo indicas que ya has terminado. Dos sistemas que siguen la misma etiqueta pueden comunicarse de forma predecible, aunque nunca se hayan conocido.
Lo que REST NO es: REST no es un producto que instalas. Tampoco es un protocolo como HTTP o SOAP. Y llamar a una API "RESTful" no significa que cumpla por completo las restricciones originales de Fielding; normalmente solo quiere decir que la API usa URLs de recursos y métodos HTTP. La diferencia entre "más o menos REST" y "verdaderamente RESTful" es una de las mayores fuentes de confusión del sector, y la veremos enseguida.
Las 6 características de una API REST de un vistazo
Antes de entrar en materia, aquí tienes una chuleta rápida. Fielding definió 6 restricciones que una API debe seguir para considerarse RESTful. Cinco son obligatorias; una es opcional.
| Restricción | Idea central | Beneficio clave | Ejemplo concreto |
|---|---|---|---|
| Cliente-servidor | Separar la interfaz del almacenamiento de datos | El front-end y el back-end evolucionan de forma independiente | Una SPA en React llamando a una API REST |
| Sin estado | Cada solicitud lleva todo el contexto necesario | Escalabilidad horizontal, sin afinidad de sesión | Un token de autenticación enviado en cada encabezado de solicitud |
| Con caché | Las respuestas declaran si se pueden almacenar en caché | Menor latencia y menor carga en el servidor | Cache-Control: max-age=3600 en una respuesta GET |
| Interfaz uniforme | Interacción estandarizada con los recursos | Superficie de API predecible y fácil de aprender | GET /users/42, DELETE /users/42 |
| Sistema en capas | El cliente no puede saber si habla directamente con el servidor | Permite insertar CDN, gateway y balanceador de carga | Cliente → CDN → API Gateway → servidor de aplicación |
| Code-on-Demand (opcional) | El servidor puede enviar código ejecutable para ampliar el cliente | Funcionalidad extendida del cliente bajo demanda | Una API que devuelve un fragmento de widget en JavaScript |
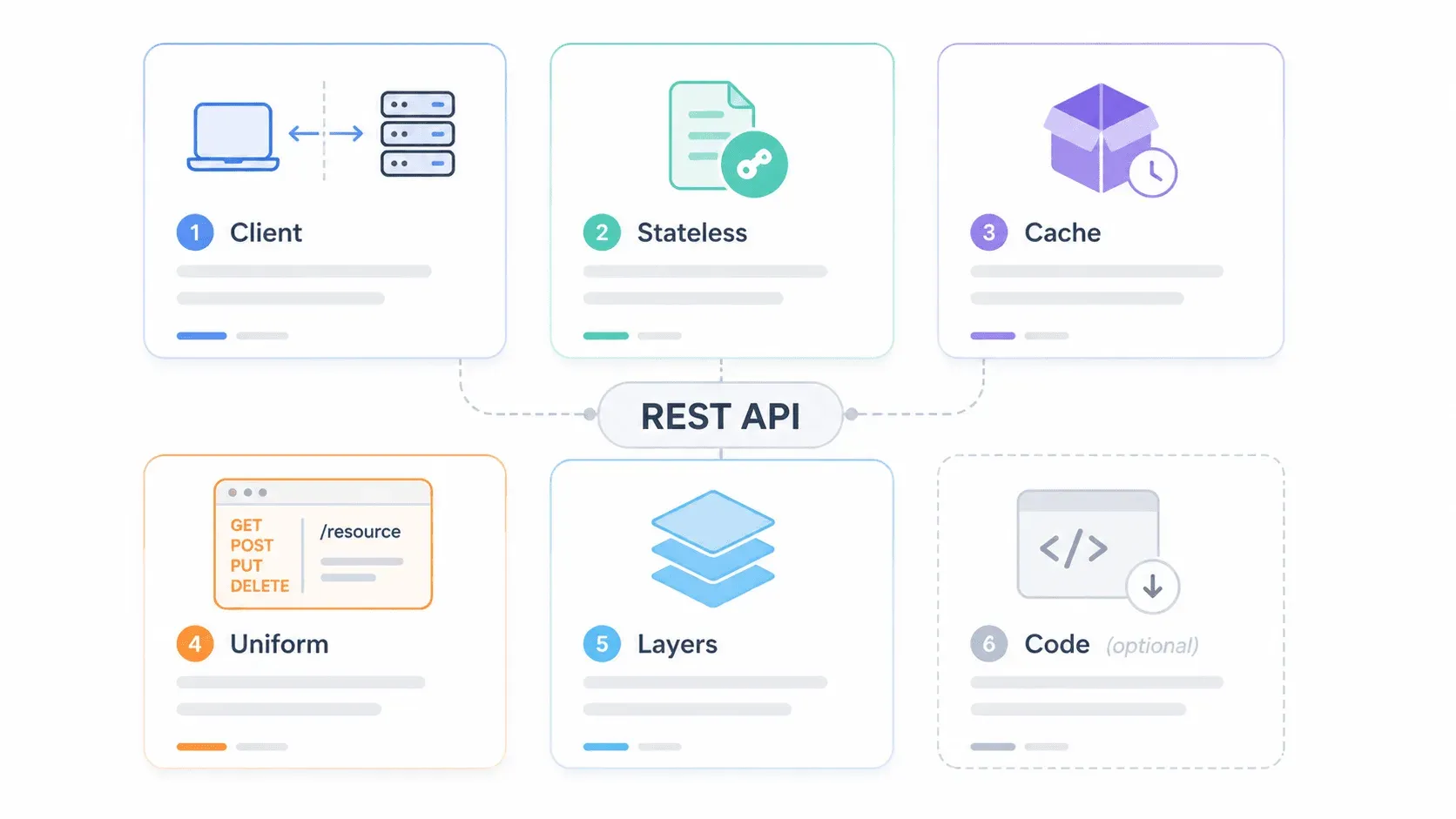
Para ver cómo encajan estas restricciones en un sistema real, imagina esta arquitectura por capas:
Cliente / App móvil
↓
CDN / caché perimetral (por ejemplo, Cloudflare)
↓
API Gateway (limitación de tasa, auth, CORS)
↓
Balanceador de carga
↓
Servidores de aplicación
↓
Base de datos / servicios internos
El cliente solo habla con la capa CDN. No sabe cuántas capas hay detrás. Ahí se ve la restricción de sistema en capas en acción, y también dónde entran la seguridad, la caché y la escalabilidad sin que el cliente tenga que saberlo.
Ahora sí, vamos con el detalle.
Características de una API REST explicadas, una por una
Separación cliente-servidor
La primera restricción de Fielding: el cliente (con lo que interactúan los usuarios) y el servidor (donde viven los datos y se ejecuta la lógica) deben estar separados. Él lo llamó separación de responsabilidades.
¿Por qué importa esto en la práctica? Porque significa que una app móvil de banca puede recibir un rediseño visual completo sin que el banco toque su base de datos de cuentas ni su motor de transacciones. La Salesforce Marketing Cloud REST API, por ejemplo, expone contactos, campañas, journeys y notificaciones push mediante endpoints de recursos. Tanto si creas un panel personalizado, una app móvil o conectas una herramienta de terceros, el back-end sigue siendo el mismo.
Para los equipos de negocio, esto se traduce en una iteración más rápida. Tus diseñadores de front-end y tus ingenieros de back-end no tienen que ir al mismo ritmo de lanzamiento. Mientras el contrato de la API se mantenga estable, ambas partes pueden avanzar por separado.
Sin estado
Sin memoria entre solicitudes. Cada llamada del cliente al servidor debe incluir toda la información que el servidor necesita para procesarla: el servidor no conserva nada de interacciones anteriores.
Me gusta pensarlo como llamar a una línea de soporte en la que tienes que volver a explicar tu problema cada vez. ¿Molesto? Sí. Pero la ventaja es enorme: cualquier agente disponible puede ayudarte, y el centro de atención puede sumar 500 agentes más sin rediseñar nada. Eso es escalabilidad horizontal.
En términos técnicos, la ausencia de estado significa que no hay sesiones pegajosas. Un balanceador de carga puede enviar tu siguiente solicitud a cualquier servidor sano. Si uno cae, otro toma el relevo sin perder el ritmo. La tesis de Fielding lo señala explícitamente: la ausencia de estado mejora la visibilidad (las herramientas de monitoreo pueden entender cada solicitud de forma aislada), la fiabilidad (los fallos no corrompen el estado compartido de la sesión) y la escalabilidad (los servidores pueden liberar recursos entre solicitudes).
La salvedad práctica: los sistemas reales siguen teniendo tokens de autenticación, carritos de compra y flujos OAuth. La idea no es que no exista ningún estado en ninguna parte, sino que el servidor no almacene en su propia memoria el estado de sesión del cliente entre solicitudes. En su lugar, eso lo gestionan los tokens, las bases de datos y las cachés compartidas.
Capacidad de caché
¿Se puede reutilizar esta respuesta? Esa es la pregunta que responde la capacidad de caché. Las respuestas deben declarar explícitamente si pueden almacenarse en caché y, si es así, los clientes e intermediarios (como las CDN) las reutilizan para solicitudes futuras equivalentes, reduciendo la carga del servidor y mejorando la velocidad.
El mecanismo HTTP es sencillo: encabezados como Cache-Control, ETag, Last-Modified y Expires indican a las cachés cuánto tiempo es válida una respuesta y cuándo deben volver a comprobarla. Para alguien de negocio, piénsalo como una etiqueta en la respuesta que dice "esta respuesta sirve durante la próxima hora" o "pregúntame siempre de nuevo".
El impacto en rendimiento es real. Las pruebas de Regional Tiered Cache de Cloudflare informaron una mejora de 50–100 ms en los tiempos de respuesta de cola para aciertos de caché. Y la propia tesis de Fielding documenta cómo el tráfico web pasó de 100.000 solicitudes/día en 1994 a 600.000.000 solicitudes/día en 1999, con la caché como un factor de diseño crítico.
Lo que normalmente sí se puede cachear: catálogos de productos, contenido público de blog, listas de países/monedas, documentación de API.
Lo que normalmente no se debe cachear: paneles personales, totales de pago, saldos bancarios, informes administrativos.
Interfaz uniforme
Esta es la restricción que el propio Fielding llamó la característica central que distingue REST de otros estilos arquitectónicos. Estandariza cómo interactúan los clientes con los recursos, haciendo que las APIs sean predecibles.
Bajo este paraguas hay cuatro subrestricciones:
- Identificación de recursos: Cada recurso obtiene una URI estable.
/customers/123es un cliente./orders/456es un pedido. - Manipulación mediante representaciones: Los clientes trabajan con representaciones (JSON, XML, HTML) de los recursos, no con los objetos internos del servidor.
- Mensajes autodescriptivos: Las solicitudes y respuestas llevan suficiente metadato —método, código de estado, tipo de contenido, detalles del error— para que cualquier intermediario o cliente pueda entenderlas.
- HATEOAS (Hypermedia as the Engine of Application State): Las respuestas incluyen enlaces a acciones y recursos relacionados, de modo que los clientes puedan descubrir qué hacer después sin codificar a mano cada endpoint.
La correspondencia de métodos HTTP es la parte más visible de la interfaz uniforme:
| Método HTTP | Significado CRUD | ¿Seguro? | ¿Idempotente? | Ejemplo |
|---|---|---|---|---|
| GET | Leer | Sí | Sí | GET /products/42 |
| POST | Crear / acción | No | No | POST /orders |
| PUT | Reemplazar el recurso completo | No | Sí | PUT /users/42 |
| PATCH | Actualización parcial | No | No garantizado | PATCH /users/42 |
| DELETE | Eliminar | No | Sí | DELETE /sessions/abc |
Las guías HTTP de Google Cloud indican explícitamente que GET debe ser seguro, y que GET, PUT y DELETE deben ser idempotentes. APIs conocidas de GitHub, Stripe y Spotify siguen estos patrones de cerca, por eso los desarrolladores que aprenden una pueden adaptarse a otra con rapidez.
Sistema en capas
Tu cliente no tiene ni idea de si está hablando con el servidor de origen, una caché CDN, un API gateway o un balanceador de carga. Y ese es el punto: cada componente solo ve la capa que tiene al lado.
Esto es lo que permite:
- CDN como Cloudflare delante de tu API para almacenar en caché y acelerar respuestas
- API gateways (AWS API Gateway, Kong, Apigee) que gestionan autenticación, limitación de tasa y cuotas
- Balanceadores de carga que distribuyen solicitudes sin estado entre varios servidores de aplicación
El informe Postman 2025 señala que el 47% de las organizaciones usa AWS API Gateway, el 26% usa el gateway de Azure y el 31% usa varios gateways a la vez. La arquitectura en capas no es teoría: así funcionan de verdad los sistemas en producción.
La contrapartida es que cada capa añade una pequeña latencia. Pero Fielding argumentó que la caché compartida en capas intermedias compensa con creces ese coste en la mayoría de los sistemas reales.
Code-on-Demand (opcional)
Esta es la rara excepción. Code-on-Demand es la única restricción REST opcional: el servidor puede enviar código ejecutable —como JavaScript— para ampliar la funcionalidad del cliente sobre la marcha.
El ejemplo más común en la vida real es simplemente una página web cargando JavaScript desde un servidor. Pero en las APIs REST JSON típicas consumidas por apps móviles, tareas de back-end o herramientas de automatización, code-on-demand casi nunca se usa. En general, los clientes de API no quieren ejecutar código arbitrario procedente de un servidor remoto.
Para la mayoría de los lectores, esta restricción es una nota al pie. Está en el modelo de Fielding por completitud, pero no influirá en tus evaluaciones diarias de API.
Lo que la mayoría entiende mal: ¿la mayoría de las APIs REST son realmente RESTful?
Aquí está la parte de la que nadie quiere hablar: la mayoría de las APIs de producción que se llaman "RESTful" en realidad son APIs HTTP JSON con convenciones parecidas a REST. Usan URLs de recursos, métodos HTTP y códigos de estado, y poco más. Un hilo de Reddit en r/softwarearchitecture tenía desarrolladores admitiendo que nunca habían creado una API REST realmente conforme con Fielding. Otra discusión en r/learnprogramming acabó convirtiéndose en una pelea sobre si alguien puede ponerse de acuerdo siquiera sobre qué significa "RESTful".
Un estudio de 2026 en el que se entrevistó a 16 expertos en APIs REST concluyó que, aunque las guías mejoran la usabilidad, los desarrolladores muestran una resistencia notable a las reglas REST estrictas, citando el tamaño de las guías y lo mal que encajan en su organización como obstáculos.
Entonces, ¿dónde aterrizan realmente las restricciones en la práctica?
| Restricción | Adopción en la práctica | Por qué |
|---|---|---|
| Cliente-servidor | ✅ Casi universal | Fundamental para la arquitectura web; difícil de evitar |
| Sin estado | ✅ Casi universal | Necesario para la escalabilidad horizontal; práctica estándar |
| Interfaz uniforme (básica) | ✅ Común | Las URI de recursos + los verbos HTTP son el patrón por defecto |
| Capacidad de caché | ⚠️ Inconsistente | Muchos equipos omiten por completo los encabezados Cache-Control |
| Sistema en capas | ⚠️ Implícito | Existen CDN y gateways, pero no siempre se diseñan de forma deliberada |
| HATEOAS | ❌ Raro | La mayoría de los clientes codifica endpoints a mano; el descubrimiento por enlaces añade complejidad |
| Code-on-Demand | ❌ Muy raro | Es opcional por definición; casi nunca se implementa en APIs JSON |
Por qué los equipos se saltan HATEOAS: Los desarrolladores de cliente prefieren leer documentación OpenAPI y usar SDKs antes que seguir enlaces dinámicos en tiempo de ejecución. HATEOAS requiere tipos de medios estables, definiciones de relaciones de enlace y modelado de flujos de trabajo: el coste a corto plazo es alto y el beneficio no está claro para la mayoría de los equipos.
La conclusión práctica: una API no necesita cumplir al 100% con Fielding para ser útil. Pero saber qué restricciones te has saltado —y qué pierdes al hacerlo— te ayuda a tomar mejores decisiones de diseño e integración.
El Richardson Maturity Model: ¿qué tan RESTful es realmente tu API?
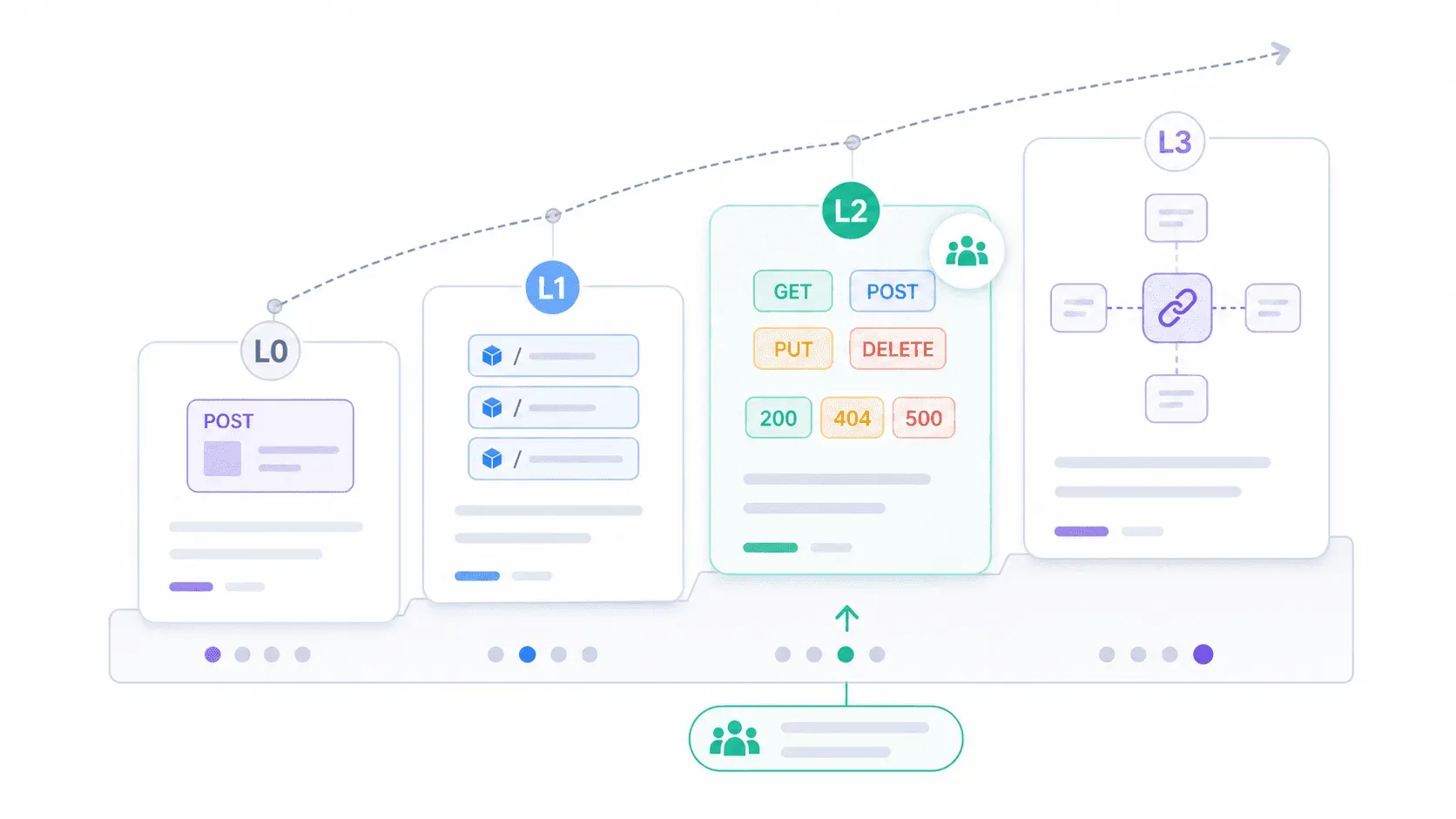
Si la pregunta binaria "¿es RESTful o no?" no te resulta útil, el Richardson Maturity Model ofrece un marco más práctico. Propuesto por Leonard Richardson y explicado por Martin Fowler, divide la adopción de REST en cuatro niveles.
| Nivel | Nombre | Descripción | Ejemplo real |
|---|---|---|---|
| 0 | El pantano de POX | Una sola URI, un solo verbo HTTP (normalmente POST) | Endpoints heredados SOAP sobre HTTP; POST /api con { "action": "getUser" } |
| 1 | Recursos | Varias URI (una por recurso), pero sigue usando sobre todo POST | POST /users/123/getProfile, POST /orders/456/cancel |
| 2 | Verbos HTTP | Uso correcto de GET, POST, PUT, DELETE + códigos de estado adecuados | La mayoría de las APIs "REST" de producción hoy |
| 3 | Hipermedia (HATEOAS) | Las respuestas incluyen enlaces a acciones/recursos relacionados | Spring Data REST, APIs basadas en HAL; muy pocas APIs públicas en la práctica |
La mayoría de las APIs que encontrarás en el mundo real están en el Nivel 2. Usan correctamente recursos, verbos y códigos de estado. Eso es suficiente para ser prácticas, interoperables y estar bien soportadas por herramientas. El Nivel 3 es la visión completa de Fielding, pero su adopción sigue siendo escasa.
¿En qué nivel está tu API? Pregúntate:
- ¿La API tiene un único endpoint para todo? (Nivel 0)
- ¿Cada objeto de negocio tiene su propia URI? (Nivel 1+)
- ¿Se usan correctamente los métodos HTTP y los códigos de estado? (Nivel 2)
- ¿Las respuestas le dicen al cliente qué puede hacer a continuación sin depender de documentación externa? (Nivel 3)
Este modelo es la herramienta más útil que he encontrado para salir del debate de "¿es REST o no?". Sustituye una decisión binaria por un espectro.
Errores comunes en APIs REST (y cómo evitarlos)
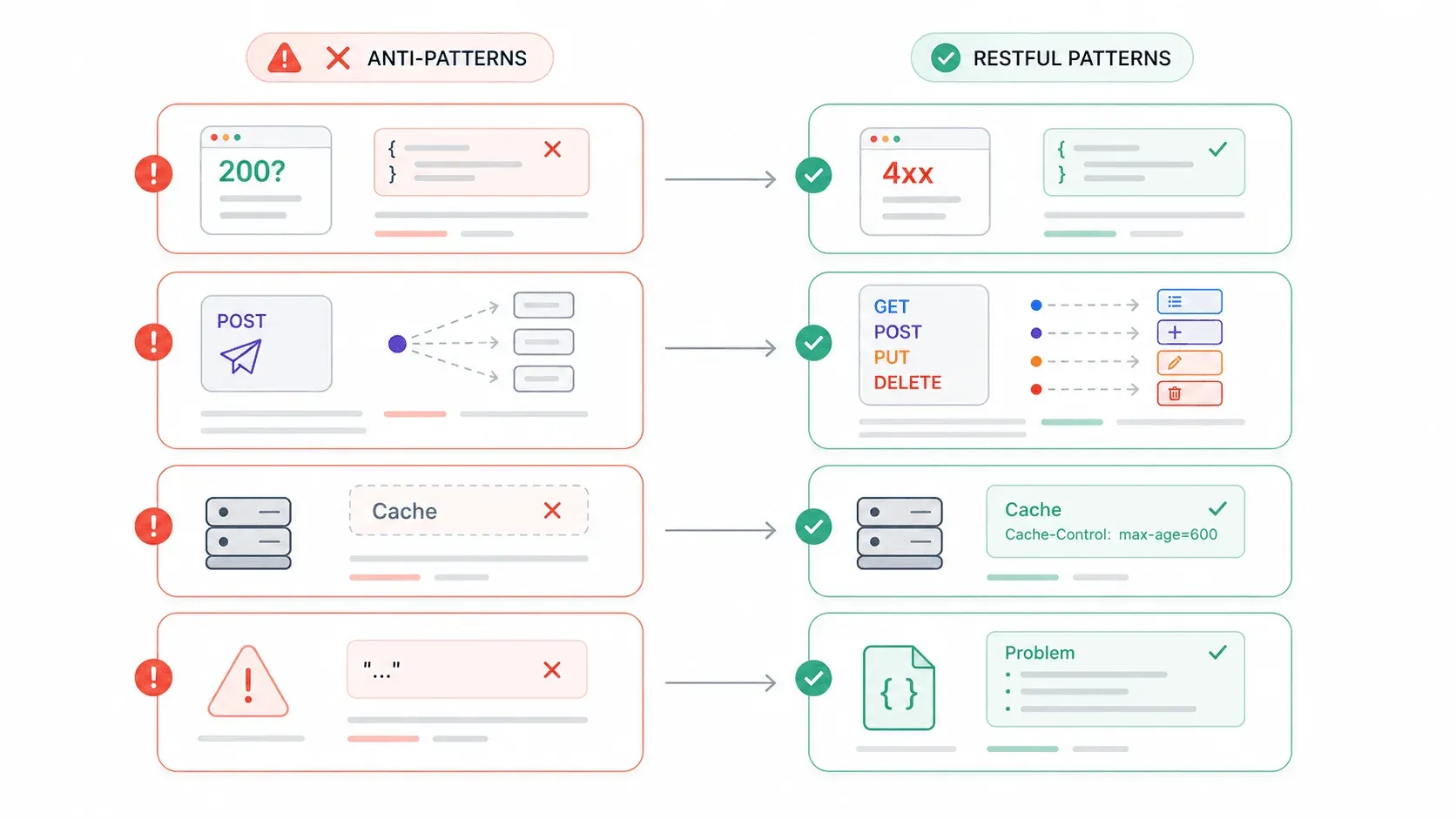
He pasado suficiente tiempo integrando APIs de terceros como para tener una lista interminable de frustraciones. Y, por lo que veo en los foros de desarrolladores, no soy el único. Aquí están los anti-patrones que aparecen con más frecuencia, y cada uno se relaciona directamente con una violación de una restricción REST.
| Anti-patrón | Por qué rompe REST | Qué hacer en su lugar |
|---|---|---|---|
| HTTP 200 con cuerpo de error ({ "error": "Invalid username" }) | Viola los mensajes autodescriptivos; los clientes no pueden confiar en los códigos de estado | Usa códigos 4xx/5xx adecuados + un cuerpo de error estructurado (por ejemplo, application/problem+json) |
| POST para todo | Ignora la interfaz uniforme; pierde la semántica de seguridad/idempotencia | Asigna CRUD a GET/POST/PUT(PATCH)/DELETE |
| Sin encabezados Cache-Control | Desaprovecha por completo la restricción de caché | Define directivas de caché explícitas, incluso no-store para datos sensibles |
| Respuestas de error vagas ("error 409") | Ni humanos ni máquinas pueden determinar qué salió mal | Incluye tipo de error, mensaje legible y un enlace a la documentación |
| No forzar HTTPS | Los tokens bearer y las claves de API viajan en texto plano | Aplica TLS en todas partes; las Google APIs usan HTTPS solo por defecto |
| Versionado en el cuerpo de la solicitud | Rompe la identificación de recursos; los gateways y las cachés no pueden enrutar correctamente | Usa versionado en la ruta de la URI (/v1/) o versionado mediante el encabezado Accept |
Las Zalando RESTful API Guidelines exigen códigos de estado HTTP oficiales y recomiendan Problem JSON para las respuestas de error. Las Adidas API Guidelines especifican que Problem Detail solo debe usarse para 4xx/5xx, nunca mezclado con 2xx. No son preferencias académicas: son estándares de producción de equipos que operan APIs a gran escala.
Un hilo de Reddit en r/learnprogramming mostraba a un desarrollador preguntando en serio si está bien devolver siempre HTTP 200 incluso cuando hay errores. Que esa pregunta siga apareciendo en 2026 te dice lo persistentes que siguen siendo estos anti-patrones.
REST vs SOAP vs GraphQL vs gRPC: cómo se comparan las características de una API REST
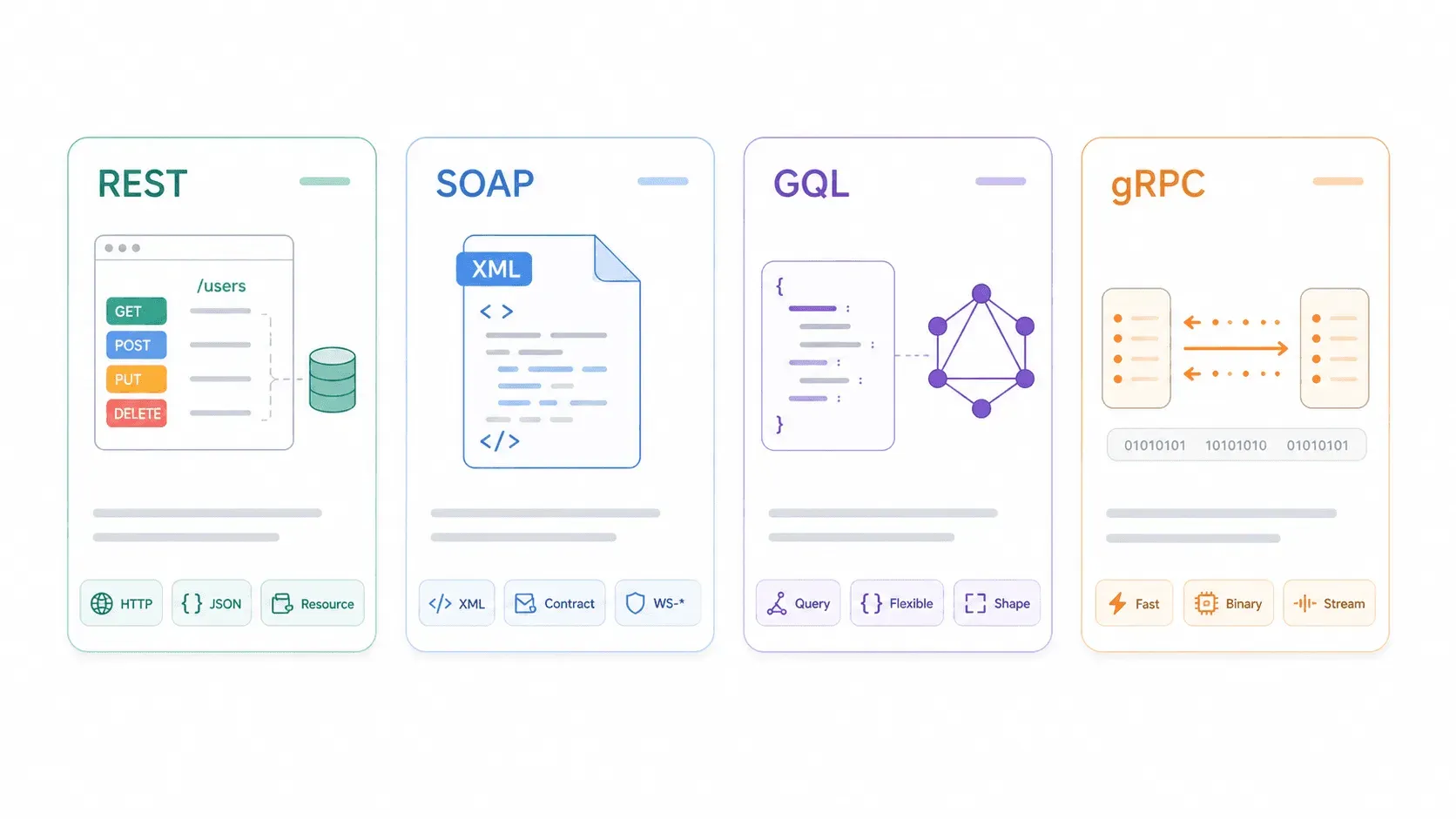
Entender REST de forma aislada es útil. Entenderlo en relación con las alternativas es mejor.
| Dimensión | REST | SOAP | GraphQL | gRPC |
|---|---|---|---|---|
| Protocolo / transporte | Estilo arquitectónico, normalmente HTTP | Protocolo de mensajería basado en XML; HTTP, SMTP, etc. | Lenguaje/runtime de consulta, normalmente sobre HTTP | Framework RPC sobre HTTP/2 |
| Formato de datos | JSON (normalmente), también XML/HTML | Solo XML (contratos WSDL) | JSON que coincide con la forma de la consulta | Protocol Buffers (binario) |
| Caché | ✅ Caché HTTP nativa cuando está bien diseñado | ❌ Complejo; poco compatible con la caché HTTP | ⚠️ Más difícil (POST + único endpoint + variación de consulta) | ❌ No orientado a la caché HTTP |
| Soporte en tiempo real | ❌ Polling/webhooks | ❌ Patrones de mensajería empresarial | ✅ Suscripciones | ✅ Streaming, baja latencia |
| Curva de aprendizaje | Baja a media | Alta | Media | Media a alta |
| Mejor para | APIs públicas, CRUD, integraciones web/móvil | Empresa/legado, contratos estrictos, cumplimiento | Consultas complejas, front-ends flexibles, apps móviles | Comunicación microservicio a microservicio, alto rendimiento interno |
La comparación de estilos arquitectónicos de API de Postman recomienda elegir según compatibilidad, forma de los datos, operaciones y herramientas para los usuarios.
Cuándo elegir cada uno:
- REST gana cuando necesitas amplia compatibilidad, operaciones CRUD sencillas y caché HTTP. Es la opción por defecto para APIs públicas e integraciones web/móvil.
- SOAP sigue teniendo sentido para sistemas empresariales con contratos estrictos, requisitos de WS-Security o integraciones heredadas que no van a desaparecer.
- GraphQL destaca cuando tu front-end necesita consultas flexibles y anidadas, y quieres evitar traer más o menos datos de los necesarios; algo común en apps móviles complejas.
- gRPC está pensado para la comunicación interna entre microservicios, donde la baja latencia y la serialización binaria importan más que la compatibilidad con navegadores.
Como ejemplo real de REST: la Open API de Thunderbit usa endpoints POST sencillos (/distill y /extract), cuerpos de solicitud y respuesta en JSON, autenticación mediante bearer token y códigos de estado HTTP estándar (400, 401, 402, 408, 422, 429, 500, 502, 503, 504). Muestra características REST en un producto de IA real sin exigir contratos SOAP ni la complejidad de gRPC. No es un escaparate de HATEOAS, pero sí una API práctica de Nivel 2 que los equipos de negocio y los desarrolladores pueden integrar con facilidad.
Por qué importan las características de una API REST para los equipos de negocio
Ventas, Operaciones, Ecommerce: ninguno de estos equipos escribe código de API. Pero sí eliges proveedores, conectas herramientas y construyes flujos de automatización, y la calidad de una API REST influye directamente en lo dolorosas —o no— que serán esas integraciones.
Integración de herramientas: cuando tu CRM se sincroniza con una plataforma de automatización de marketing, el diseño de la API REST determina si esa sincronización es fiable o frágil. La Salesforce Marketing Cloud REST API gestiona contactos, campañas, journeys y notificaciones push mediante endpoints de recursos predecibles. Si esos endpoints siguen las convenciones REST, tu equipo de RevOps puede automatizar sin apaños.
Operaciones de ecommerce: los recursos REST de fulfillment de Shopify gestionan pedidos de fulfillment, números de seguimiento y estados de envío. Las apps de envío y las herramientas de fulfillment dependen de esa capa. Cuando la API está bien diseñada —códigos de estado correctos, datos de catálogo cacheables, mensajes de error claros— tu canal logístico funciona sin problemas. Cuando no lo está, aparecen fallos misteriosos a las 2 de la mañana.
Evaluación de proveedores: conocer las 6 restricciones te da una lista de comprobación práctica:
- ¿La API usa códigos de estado estándar o cualquier fallo parece un 200 OK?
- ¿Los errores son lo bastante específicos como para que tu herramienta de automatización pueda recuperarse?
- ¿Hay documentación clara sobre límites de tasa, paginación y autenticación?
- ¿Se pueden cachear las respuestas habituales para reducir la carga?
Extracción de datos y automatización: herramientas como Thunderbit usan una arquitectura basada en REST para permitir que usuarios de negocio extraigan datos estructurados de sitios web, PDFs e imágenes, y luego los exporten a Google Sheets, Airtable, Notion o Excel. La extensión Chrome AI Web Scraper de Thunderbit maneja la complejidad detrás de una interfaz de 2 clics, pero por debajo son los principios REST —solicitudes sin estado, respuestas JSON, errores estándar— los que hacen fiable la capa de integración.
Otro dato importante: el informe Postman 2025 encontró que solo el 24% de los desarrolladores diseña APIs pensando activamente en agentes de IA, mientras que el 51% se preocupa por llamadas no autorizadas o excesivas de agentes de IA. A medida que la automatización y los flujos impulsados por IA se vuelven estándar en los equipos de negocio, los patrones REST predecibles, las claves de API con privilegios mínimos y los límites de tasa ya no son solo preocupaciones de desarrolladores: son factores de riesgo operativos.
Cómo aplica Thunderbit los principios REST para usuarios de negocio
Creamos Thunderbit partiendo de la idea de que la mayoría de nuestros usuarios nunca leería una especificación REST, ni debería tener que hacerlo. Pero las decisiones de diseño que hacen que Thunderbit sea fácil de usar se basan en las mismas características REST que cubre este artículo.
Aquí tienes un recorrido rápido de cómo funciona en la práctica:
- Instala la extensión de Chrome desde la Chrome Web Store y abre cualquier sitio web, PDF o imagen de los que quieras extraer datos.
- Haz clic en "AI Suggest Fields" y la IA de Thunderbit leerá la página y propondrá una tabla estructurada de columnas: nombres de producto, precios, correos electrónicos, lo que contenga la página.
- Ajusta las columnas si hace falta y luego haz clic en "Scrape". Thunderbit se encarga automáticamente de la paginación, las subpáginas y el contenido dinámico.
- Exporta tus datos a Google Sheets, Airtable, Notion, CSV o Excel, gratis y sin muro de pago.
Para desarrolladores y flujos de automatización, la Open API de Thunderbit expone /distill (extracción limpia de Markdown) y /extract (extracción de datos estructurados) como endpoints POST al estilo REST, con cuerpos JSON y códigos de error HTTP estándar. En términos del Richardson Maturity Model, eso es un sólido Nivel 2: recursos, métodos correctos y códigos de estado con significado.
Si estás explorando el web scraping o la extracción de datos de forma más amplia, hemos escrito guías más profundas sobre web scraping con IA, web scraping sin programar y qué es realmente el web scraping.
Conclusiones clave
- REST es un estilo arquitectónico, no un protocolo. Define 6 restricciones —cliente-servidor, sin estado, con caché, interfaz uniforme, sistema en capas y code-on-demand opcional— que guían el diseño de APIs.
- La mayoría de las APIs "RESTful" no son totalmente RESTful. La mayoría se sitúa en el Nivel 2 de Richardson (recursos + verbos HTTP + códigos de estado). HATEOAS y code-on-demand rara vez se implementan.
- El Richardson Maturity Model es la mejor herramienta de autoevaluación. Sustituye la pregunta binaria "¿es REST o no?" por un espectro práctico (niveles 0–3).
- Los errores comunes —HTTP 200 para errores, POST para todo, ausencia de encabezados de caché— siguen siendo muy frecuentes. Conocer las restricciones te ayuda a detectar y corregir estos anti-patrones.
- REST vs SOAP vs GraphQL vs gRPC no va de cuál es "mejor", sino de cuál encaja. REST domina en APIs públicas e integraciones CRUD. GraphQL es ideal para front-ends complejos. gRPC sobresale en microservicios internos. SOAP persiste en contextos empresariales y heredados.
- Los equipos de negocio se benefician de entender las características REST al evaluar proveedores, conectar herramientas y crear flujos de automatización. Herramientas como Thunderbit aplican principios REST para hacer la extracción de datos accesible sin exigir experiencia técnica.
Preguntas frecuentes
¿Cuáles son las 6 características de una API REST?
Las 6 restricciones REST son: (1) separación cliente-servidor, (2) ausencia de estado, (3) capacidad de caché, (4) interfaz uniforme, (5) sistema en capas y (6) code-on-demand (opcional). Las cinco primeras son obligatorias para que una API se considere RESTful según la definición original de Fielding.
¿Cuál es la diferencia entre REST y RESTful?
REST es el estilo arquitectónico, es decir, el conjunto de restricciones de diseño definido por Roy Fielding. "RESTful" describe una API que sigue esas restricciones. En la práctica, muchas APIs etiquetadas como "RESTful" solo las cumplen parcialmente: suelen implementar recursos, métodos HTTP y códigos de estado, pero omiten HATEOAS y code-on-demand.
¿Todas las APIs REST siguen todas las restricciones REST?
No. La mayoría de las APIs de producción siguen la separación cliente-servidor, la ausencia de estado y una interfaz uniforme básica (recursos + verbos HTTP). La capacidad de caché y el diseño en capas se aplican de forma irregular. HATEOAS es raro, y code-on-demand casi nunca se usa en APIs JSON.
¿Cuál es la diferencia entre REST y GraphQL?
REST expone recursos mediante múltiples endpoints con métodos HTTP estándar (GET, POST, PUT, DELETE). GraphQL suele usar un único endpoint donde los clientes especifican exactamente qué campos quieren en una consulta. REST tiene una caché HTTP nativa más sólida; GraphQL ofrece más flexibilidad para necesidades de datos complejas y anidadas, y reduce el exceso o la falta de datos.
¿Qué es HATEOAS y alguien lo usa de verdad?
HATEOAS (Hypermedia as the Engine of Application State) significa que las respuestas de la API incluyen enlaces que indican al cliente qué acciones están disponibles a continuación, de modo que pueda navegar por la API sin codificar a mano cada endpoint. Es central en la visión de REST de Fielding (Nivel 3 de Richardson), pero en la práctica muy pocas APIs públicas lo implementan. La mayoría de los equipos se quedan en el Nivel 2 y dependen de la documentación y los SDK.
Prueba Thunderbit para web scraping con IA
Prueba Thunderbit para web scraping con IA Get Started Free
Más información




