

La web rebosa de datos valiosos: tanto si trabajas en ventas, ecommerce o investigación de mercado, el web scraping es la herramienta secreta para generar leads, monitorizar precios y hacer análisis de la competencia. Pero aquí está el problema: a medida que más empresas se apoyan en el scraping, los sitios web responden con más fuerza que nunca. El cambio es real: un análisis de ppc.land de 2024 descubrió que más de un tercio de los 1.000 sitios principales ya bloquean solo el crawler de OpenAI, y el conjunto más amplio de bloqueos de IP, CAPTCHAs y fingerprinting del navegador ya es la norma, no la excepción.
Si alguna vez has visto cómo tu script en Python funcionaba sin problemas durante 20 minutos y, de repente, se topaba con una pared de errores 403, ya sabes lo frustrante que puede llegar a ser.
Llevo años trabajando en SaaS y automatización, y he visto de primera mano cómo un proyecto de scraping puede pasar de “vaya, esto es fácil” a “¿por qué me bloquean en todos lados?” en un abrir y cerrar de ojos. Así que vamos a lo práctico: te mostraré cómo hacer web scraping sin que te bloqueen en Python, compartiré las mejores técnicas y fragmentos de código, y te enseñaré cuándo conviene plantearse alternativas impulsadas por IA como Thunderbit. Tanto si dominas Python como si apenas vas saliendo adelante con el scraping (sí, va con doble sentido), te llevarás un kit de herramientas para extraer datos de forma fiable y sin bloqueos.
¿Qué es hacer web scraping sin que te bloqueen en Python?
En esencia, hacer web scraping sin que te bloqueen significa extraer datos de sitios web de una forma que no active sus defensas anti-bot. En el mundo de Python, esto implica algo más que escribir un bucle requests.get(); se trata de pasar desapercibido, imitar a usuarios reales y mantenerse un paso por delante de los sistemas de detección.
¿Por qué Python? Python es el lenguaje más popular para web scraping gracias a su sintaxis sencilla, su enorme ecosistema (piensa en requests, BeautifulSoup, Scrapy, Selenium) y su flexibilidad para todo, desde scripts rápidos hasta crawlers distribuidos. Pero la popularidad tiene un precio: muchos sistemas anti-bot ya están afinados para detectar patrones de scraping basados en Python.
Así que, si quieres hacer scraping de forma fiable, necesitas ir más allá de lo básico. Eso significa entender cómo detectan los bots los sitios web y cómo puedes adelantarte a ellos, sin cruzar ninguna línea ética o legal.
Por qué evitar bloqueos importa en los proyectos de web scraping con Python
Que te bloqueen no es solo un tropiezo técnico: puede desbaratar flujos de trabajo enteros del negocio. Veámoslo por partes:
| Caso de uso | Impacto de ser bloqueado |
|---|---|
| Generación de leads | Listas de prospectos incompletas o desactualizadas, pérdida de ventas |
| Monitorización de precios | Cambios de precios de la competencia que pasan desapercibidos, malas decisiones de precios |
| Agregación de contenido | Huecos en noticias, reseñas o datos de investigación |
| Inteligencia de mercado | Puntos ciegos en el seguimiento de competidores o del sector |
| Anuncios inmobiliarios | Datos de propiedades inexactos o desactualizados, oportunidades perdidas |
Cuando un scraper se bloquea, no solo dejas de obtener datos: también desperdicias recursos, corres riesgos de cumplimiento y, potencialmente, tomas malas decisiones de negocio basadas en información incompleta. En un mundo en el que el 79% de las empresas depende del web scraping para la generación de leads, la fiabilidad lo es todo.
Cómo detectan y bloquean los sitios web a los scrapers de Python
Los sitios web se han vuelto muy listos a la hora de detectar bots. Estas son las defensas anti-scraping más comunes con las que te encontrarás (Medium, Bright Data):
- Lista negra de direcciones IP: ¿Demasiadas solicitudes desde una misma IP? Bloqueado.
- Comprobaciones de User-Agent y cabeceras: Las solicitudes con cabeceras ausentes o genéricas (como
python-requests/2.25.1por defecto en Python) llaman la atención. - Limitación de velocidad: Demasiadas solicitudes en poco tiempo activan el throttling o el bloqueo.
- CAPTCHAs: Rompecabezas de “demuestra que eres humano” que los bots no pueden resolver fácilmente.
- Análisis de comportamiento: Los sitios vigilan patrones robóticos, como hacer clic en el mismo botón a intervalos idénticos.
- Honeypots: Enlaces o campos ocultos con los que solo interactúan los bots.
- Fingerprinting del navegador: Recopilar detalles de tu navegador y dispositivo para detectar herramientas de automatización.
- Seguimiento de cookies y sesiones: Los bots que no gestionan bien cookies o sesiones quedan marcados.
Piensa en ello como el control de seguridad de un aeropuerto: si aparentas, actúas y te mueves como todo el mundo, pasas sin problemas. Si apareces con gabardina y gafas de sol, prepárate para más preguntas.
Técnicas esenciales de Python para hacer web scraping sin que te bloqueen
Vamos con lo bueno: cómo evitar realmente los bloqueos al hacer scraping con Python. Estas son las estrategias básicas que todo scraper debería conocer:

Proxies rotativos y direcciones IP
Por qué importa: si todas tus solicitudes salen de la misma IP, eres un blanco fácil para bloqueos por IP. Los proxies rotativos te permiten distribuir las solicitudes entre muchas IP, lo que dificulta mucho más que te bloqueen.
Cómo hacerlo en Python:
import requests
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# ...más proxies
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
response = requests.get(url, proxies=proxy)
# procesar la respuesta
Puedes usar servicios de proxies de pago (como proxies residenciales o rotativos) para obtener más fiabilidad (ScrapingBee).
Configurar User-Agent y cabeceras personalizadas
Por qué importa: las cabeceras predeterminadas de Python gritan “soy un bot”. Imita navegadores reales configurando el user-agent y otras cabeceras.
Código de ejemplo:
headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Connection": "keep-alive"
}
response = requests.get(url, headers=headers)
Rota los user-agents para ganar aún más sigilo (ZenRows).
Aleatorizar el tiempo y los patrones de las solicitudes
Por qué importa: los bots son rápidos y previsibles; las personas son más lentas y aleatorias. Añade pausas y varía tu navegación.
Consejo en Python:
import time, random
for url in urls:
response = requests.get(url)
time.sleep(random.uniform(2, 7)) # Esperar entre 2 y 7 segundos
También puedes aleatorizar las rutas de clic y los patrones de desplazamiento si usas Selenium.
Gestionar cookies y sesiones
Por qué importa: muchos sitios requieren cookies o tokens de sesión para acceder al contenido. Los bots que ignoran esto acaban bloqueados.
Cómo gestionarlo en Python:
import requests
session = requests.Session()
response = session.get(url)
# la sesión gestionará las cookies automáticamente
Para flujos más complejos, usa Selenium para capturar y reutilizar cookies.
Simular comportamiento humano con navegadores sin interfaz
Por qué importa: algunos sitios usan JavaScript, movimientos del ratón o desplazamiento como señales de usuarios reales. Los navegadores sin interfaz, como Selenium o Playwright, pueden imitar esas acciones.
Ejemplo con Selenium:
from selenium import webdriver
from selenium.webdriver.common.action_chains import ActionChains
import random, time
driver = webdriver.Chrome()
driver.get(url)
actions = ActionChains(driver)
actions.move_by_offset(random.randint(0, 100), random.randint(0, 100)).perform()
time.sleep(random.uniform(2, 5))
Esto te ayuda a sortear el análisis de comportamiento y el contenido dinámico (ScrapingBee).
Estrategias avanzadas: cómo saltarse CAPTCHAs y honeypots en Python
Los CAPTCHAs están diseñados para detener a los bots en seco. Aunque algunas bibliotecas de Python pueden resolver CAPTCHAs sencillos, la mayoría de los scrapers serios dependen de servicios de terceros (como 2Captcha o Anti-Captcha) para resolverlos pagando una tarifa (Medium).
Integración de ejemplo:
# Pseudocódigo para usar la API de 2Captcha
import requests
captcha_id = requests.post("<https://2captcha.com/in.php>", data={...}).text
# Esperar la solución y luego enviarla con tu solicitud
Los honeypots son campos o enlaces ocultos con los que solo interactúan los bots. Evita hacer clic o enviar cualquier cosa que no sea visible en un navegador real (ZenRows).
Diseñar cabeceras de solicitud robustas con bibliotecas de Python
Más allá del user-agent, puedes rotar y aleatorizar otras cabeceras (como Referer, Accept, Origin, etc.) para pasar todavía más desapercibido.
Con Scrapy:
class MySpider(scrapy.Spider):
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'User-Agent': '...',
'Accept-Language': 'en-US,en;q=0.9',
# Más cabeceras
}
}
Con Selenium: usa perfiles del navegador o extensiones para configurar cabeceras, o inyéctalas mediante JavaScript.
Mantén actualizada tu lista de cabeceras: copia solicitudes reales del navegador con las DevTools como inspiración.
Cuando el scraping tradicional con Python no basta: el auge de la tecnología anti-bot
Esta es la realidad: a medida que el scraping se vuelve más popular, también lo hacen las mejoras anti-bot. Los grandes sitios ahora bloquean no solo a los bots obvios, sino incluso a navegadores sin interfaz sofisticados y proxies rotativos. La detección impulsada por IA, los umbrales dinámicos de solicitudes y el fingerprinting del navegador están haciendo más difícil que nunca que incluso scripts avanzados en Python sigan sin ser detectados (Medium).
A veces, por muy inteligente que sea tu código, acabarás chocando con un muro. Ahí es cuando conviene considerar otro enfoque.
Thunderbit: una alternativa de Raspador Web IA al scraping con Python
Cuando Python llega a su límite, Thunderbit entra en escena como un raspador web sin código, impulsado por IA y pensado para usuarios de negocio, no solo para desarrolladores. En lugar de pelearte con proxies, cabeceras y CAPTCHAs, el agente de IA de Thunderbit lee el sitio web, sugiere los mejores campos para extraer y se encarga de todo, desde la navegación por subpáginas hasta la exportación de datos.
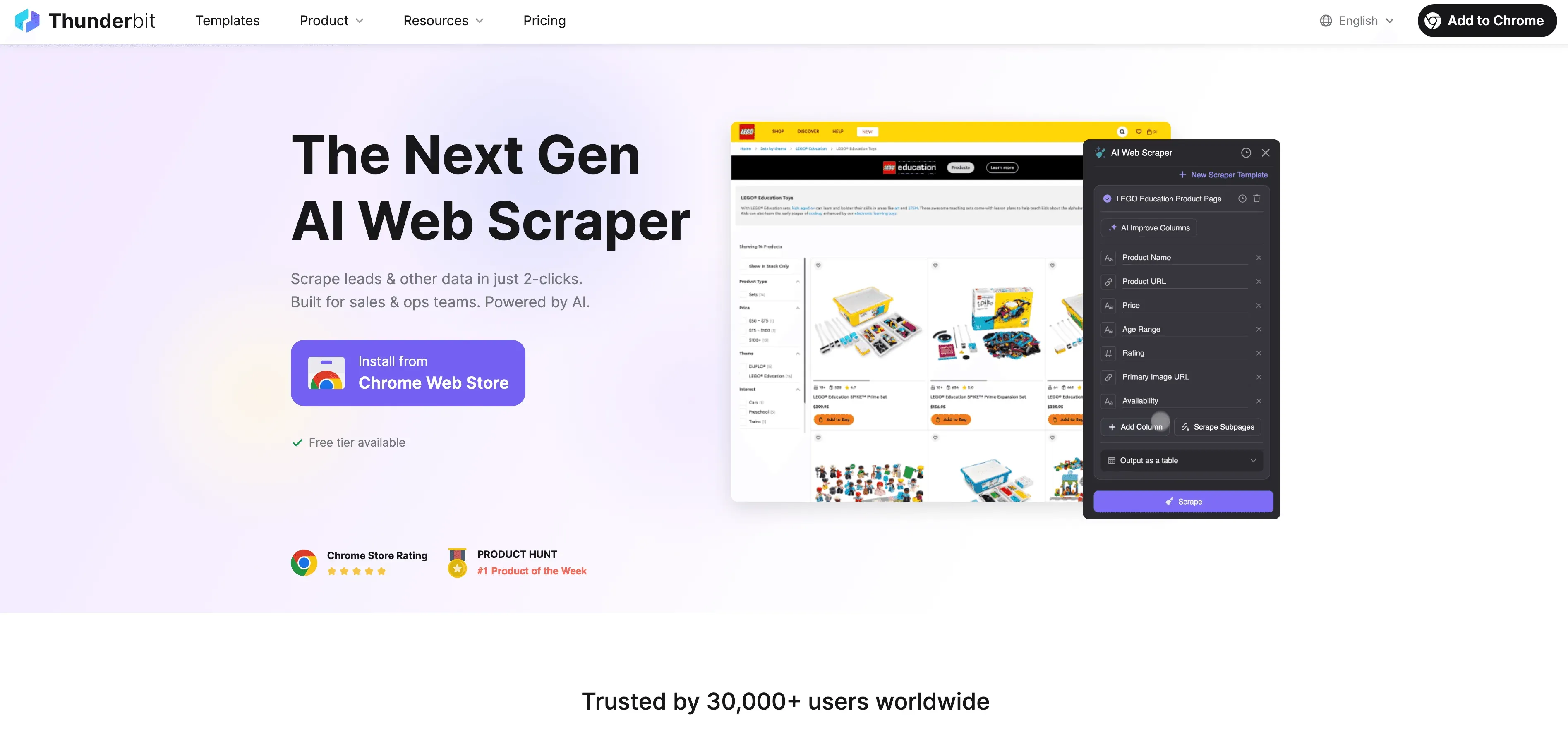
¿Qué hace diferente a Thunderbit?
- Sugerencia de campos con IA: haz clic en “AI Suggest Fields” y Thunderbit analiza la página, recomienda columnas e incluso genera instrucciones de extracción.
- Scraping de subpáginas: Thunderbit puede visitar cada subpágina (como detalles de producto o perfiles de LinkedIn) y enriquecer tu tabla automáticamente.
- Scraping en la nube o en el navegador: elige la opción más rápida: nube para sitios públicos, navegador para páginas protegidas con inicio de sesión.
- Scraping programado: configúralo una vez y olvídate; Thunderbit puede extraer datos según un horario para que la información esté siempre actualizada.
- Plantillas instantáneas: para sitios populares (Amazon, Zillow, Shopify, etc.), Thunderbit ofrece plantillas con un solo clic, sin configuración.
- Exportación de datos gratuita: exporta a Excel, Google Sheets, Airtable o Notion, sin costes extra.
Thunderbit cuenta con la confianza de más de 100.000 usuarios en todo el mundo, y no necesitas escribir ni una sola línea de código.
Extrae datos de cualquier sitio web usando IA Get Started Free
Cómo ayuda Thunderbit a los usuarios a evitar bloqueos y automatizar la extracción de datos
La IA de Thunderbit no solo imita el comportamiento humano: se adapta a cada sitio en tiempo real, reduciendo el riesgo de bloqueo. Así es como lo hace:
- La IA se adapta a los cambios de diseño: menos retrabajo cuando un sitio actualiza su diseño; no tienes que volver a ajustar selectores cada semana.
- Gestión de subpáginas y paginación: Thunderbit sigue enlaces y listas paginadas por ti, igual que lo haría una persona navegando manualmente.
- Scraping en la nube por lotes: ejecuta trabajos desde la nube de Thunderbit en lugar de tu portátil, con tamaños de lote definidos según el plan (consulta la página de precios para ver los límites actuales).
- Menos código que mantener: no eres tú quien persigue selectores rotos a medianoche cuando un sitio cambia; la IA vuelve a leer la página.
Para profundizar más, echa un vistazo a Cómo extraer cualquier sitio web usando IA.
Comparando el scraping con Python frente a Thunderbit: ¿cuál deberías elegir?
Vamos a ponerlos uno al lado del otro:
| Función | Scraping con Python | Thunderbit |
|---|---|---|
| Tiempo de configuración | Medio–alto (scripts, proxies, etc.) | Bajo (2 clics, la IA hace el resto) |
| Habilidad técnica | Requiere programar | No hace falta programar |
| Fiabilidad | Variable (se rompe con facilidad) | Alta (la IA se adapta a los cambios) |
| Riesgo de bloqueos | Medio–alto | Bajo (la IA imita al usuario y se adapta) |
| Escalabilidad | Necesita código personalizado/configuración en la nube | Scraping en la nube y por lotes integrado |
| Mantenimiento | Frecuente (cambios de sitio, bloqueos) | Mínimo (la IA se ajusta automáticamente) |
| Opciones de exportación | Manual (CSV, BD) | Directo a Sheets, Notion, Airtable, CSV |
| Coste | Gratis (pero consume mucho tiempo) | Plan gratuito, planes de pago para escalar |
Cuándo usar Python:
- Necesitas control total, lógica personalizada o integración con otros flujos de trabajo en Python.
- Estás extrayendo datos de sitios con defensas anti-bot mínimas.
Cuándo usar Thunderbit:
- Quieres velocidad, fiabilidad y cero configuración.
- Estás extrayendo datos de sitios complejos o que cambian con frecuencia.
- No quieres lidiar con proxies, CAPTCHAs ni código.
Prueba gratis el Raspador Web IA de Thunderbit
Guía paso a paso: configurar un web scraping sin que te bloqueen en Python
Veamos un ejemplo práctico: extraer datos de productos de un sitio de ejemplo aplicando buenas prácticas anti-bloqueo.
1. Instala las bibliotecas necesarias
pip install requests beautifulsoup4 fake-useragent
2. Prepara tu script
import requests
from bs4 import BeautifulSoup
from fake_useragent import UserAgent
import time, random
ua = UserAgent()
urls = ["<https://example.com/product/1>", "<https://example.com/product/2>"] # Sustituye por tus URL
for url in urls:
headers = {
"User-Agent": ua.random,
"Accept-Language": "en-US,en;q=0.9"
}
response = requests.get(url, headers=headers)
if response.status_code == 200:
soup = BeautifulSoup(response.text, "html.parser")
# Extraer datos aquí
print(soup.title.text)
else:
print(f"Bloqueado o error en {url}: {response.status_code}")
time.sleep(random.uniform(2, 6)) # Retraso aleatorio
3. Añade rotación de proxies (opcional)
proxies = [
"<http://proxy1.example.com:8000>",
"<http://proxy2.example.com:8000>",
# Más proxies
]
for i, url in enumerate(urls):
proxy = {"http": proxies[i % len(proxies)]}
headers = {"User-Agent": ua.random}
response = requests.get(url, headers=headers, proxies=proxy)
# ...resto del código
4. Gestiona cookies y sesiones
session = requests.Session()
for url in urls:
response = session.get(url, headers=headers)
# ...resto del código
5. Consejos para solucionar problemas
- Si ves muchos errores 403/429, reduce la velocidad de tus solicitudes o prueba con nuevos proxies.
- Si te encuentras con CAPTCHAs, considera usar Selenium o un servicio de resolución de CAPTCHAs.
- Comprueba siempre el
robots.txtdel sitio y sus condiciones de servicio.
Conclusión y conclusiones clave
El web scraping en Python es potente, pero que te bloqueen siempre es un riesgo a medida que evoluciona la tecnología anti-bot. ¿La mejor forma de evitar bloqueos? Combinar buenas prácticas técnicas (proxies rotativos, cabeceras inteligentes, retrasos aleatorios, gestión de sesiones y navegadores sin interfaz) con un respeto sano por las normas y la ética del sitio.
Pero a veces, ni siquiera los mejores trucos de Python bastan. Ahí es donde entran herramientas de IA como Thunderbit: sin código, pensadas para gestionar los cambios de diseño y la paginación que hacen tropezar a los scripts rígidos, y orientadas a usuarios de negocio que prefieren no pasar las noches vigilando un trabajo de Selenium.
¿Quieres ver lo fácil que puede ser extraer datos? Descarga la extensión de Chrome de Thunderbit y pruébala tú mismo, o visita nuestro blog para más consejos y tutoriales de scraping.
Extrae datos sin que te bloqueen
Preguntas frecuentes
1. ¿Por qué los sitios web bloquean los scrapers de Python?
Los sitios web bloquean scrapers para proteger sus datos, evitar la sobrecarga de los servidores y frenar a los bots automatizados que abusan de sus servicios. Los scripts en Python son fáciles de detectar si usan cabeceras predeterminadas, no gestionan cookies o envían demasiadas solicitudes demasiado rápido.
2. ¿Cuáles son las formas más efectivas de evitar bloqueos al hacer scraping con Python?
Usa proxies rotativos, configura un user-agent y cabeceras realistas, aleatoriza el tiempo de las solicitudes, gestiona cookies y sesiones, y simula comportamiento humano con herramientas como Selenium o Playwright.
3. ¿Cómo ayuda Thunderbit a evitar bloqueos en comparación con los scripts de Python?
Thunderbit usa IA para adaptarse a la estructura de los sitios, imitar la navegación humana y gestionar automáticamente subpáginas y paginación. Reduce el riesgo de bloqueos al pasar desapercibido y ajustar su enfoque en tiempo real, sin necesidad de código ni proxies.
4. ¿Cuándo debería usar scraping con Python frente a una herramienta de IA como Thunderbit?
Usa Python cuando necesites lógica personalizada, integración con otro código en Python o estés extrayendo datos de sitios sencillos. Usa Thunderbit para un scraping rápido, fiable y escalable, especialmente cuando los sitios sean complejos, cambien con frecuencia o bloqueen scripts de forma agresiva.
5. ¿Es legal el web scraping?
El web scraping es legal para datos disponibles públicamente, pero debes respetar los términos de servicio, las políticas de privacidad y las leyes aplicables de cada sitio. Nunca extraigas datos sensibles o privados y actúa siempre de forma ética y responsable.
¿Listo para hacer scraping de forma más inteligente, no más dura? Prueba Thunderbit y deja atrás los bloqueos.
Más información:
- Scraping de Google News con Python: guía paso a paso
- Crear una herramienta de seguimiento de precios de Best Buy con Python
- 14 formas de hacer web scraping sin que te bloqueen
- 10 mejores consejos para no ser bloqueado al hacer web scraping
Prueba el Raspador Web IA Get Started Free




