
El web scraping se ha vuelto el arma secreta de los equipos empresariales modernos. Ya sea que estés en ventas, operaciones o simplemente quieras estar al tanto de lo que hace la competencia, saber cómo hacer extracción de datos de páginas web es una habilidad que hoy en día no puede faltar. ¿Qué ha cambiado últimamente? La web ahora es mucho más dinámica: paneles interactivos, scroll infinito y contenido que solo aparece después de hacer clic. Y en el centro de todo esto está JavaScript, el lenguaje que le da vida a la mayoría de los sitios web, tanto lo que ves como lo que está detrás de cámaras.
Con varios años de experiencia en SaaS y automatización, he visto cómo JavaScript y Node.js pasaron de ser herramientas opcionales para desarrolladores a convertirse en piezas clave para la extracción de datos en empresas. Los números lo dicen todo: , y se espera que el mercado global de web scraping siga creciendo a doble dígito hasta 2030 (). En esta guía te cuento qué significa realmente hacer web scraping con JavaScript y Node.js, por qué es tan importante y, sobre todo, cómo incluso quienes no programan pueden aprovecharlo con herramientas como . Seas técnico o no, nunca hubo mejor momento para transformar el caos de la web en oro para tu negocio.
¿Qué es el Web Scraping con JavaScript? Conceptos básicos
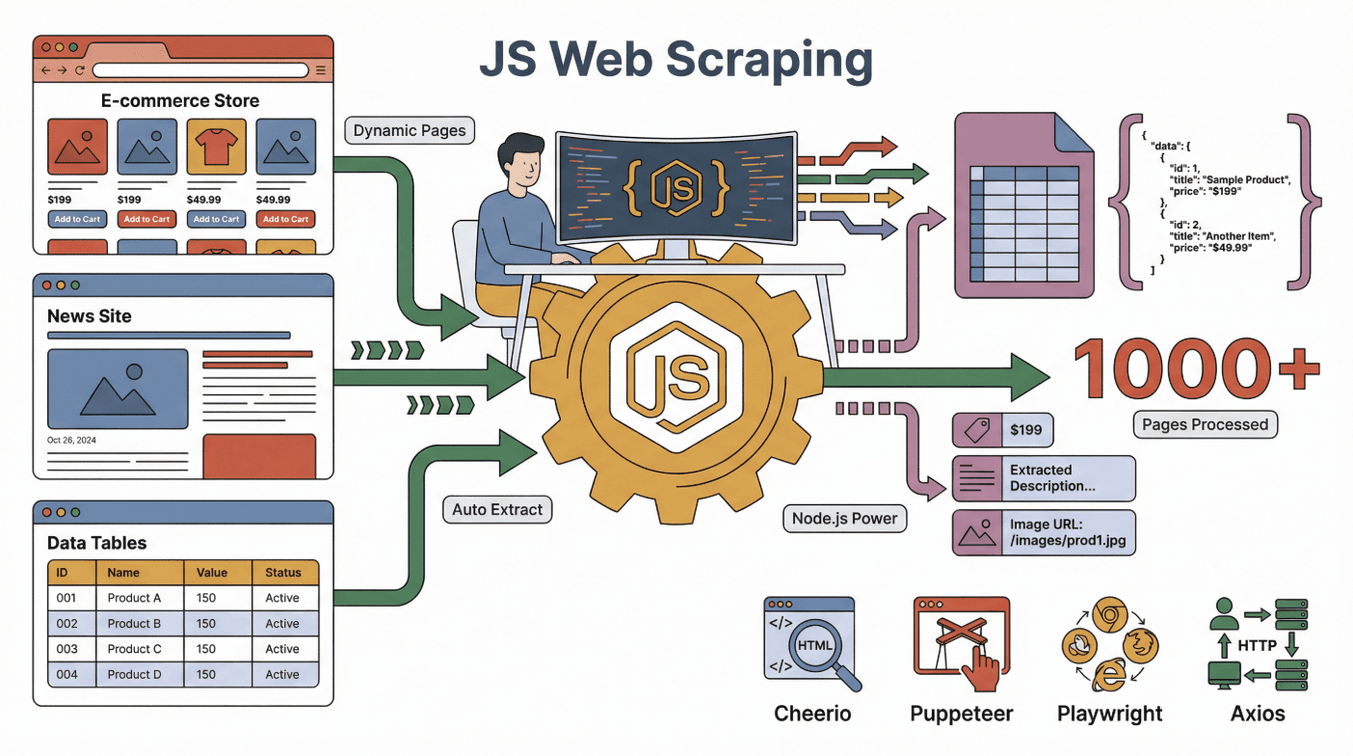 Vamos a lo básico. El web scraping con JavaScript es usar JavaScript (normalmente junto a Node.js) para extraer datos automáticamente de páginas web. Imagina que envías un asistente digital a un sitio, que lee la página y copia la información que te interesa en una hoja de cálculo—pero este asistente puede procesar miles de páginas, nunca se cansa y hasta puede interactuar con botones y formularios.
Vamos a lo básico. El web scraping con JavaScript es usar JavaScript (normalmente junto a Node.js) para extraer datos automáticamente de páginas web. Imagina que envías un asistente digital a un sitio, que lee la página y copia la información que te interesa en una hoja de cálculo—pero este asistente puede procesar miles de páginas, nunca se cansa y hasta puede interactuar con botones y formularios.
JavaScript es especialmente poderoso porque es el lenguaje que usan los navegadores para construir y actualizar las páginas. Node.js permite ejecutar JavaScript fuera del navegador, así puedes automatizar tareas como:
- Cargar una página web (aunque sea dinámica o interactiva)
- Hacer clic en botones, desplazarse o esperar a que aparezca contenido
- Extraer textos, imágenes, precios, correos electrónicos o cualquier dato visible en la página
Algunas de las herramientas más populares para scraping con JavaScript son:
- : Perfecto para analizar y extraer datos de páginas HTML estáticas (como un jQuery para el servidor).
- : Automatiza un navegador Chrome real, ideal para sitios dinámicos que requieren interacción.
- : Similar a Puppeteer, pero aún más potente para automatización en diferentes plataformas.
- : Hace peticiones HTTP para obtener páginas web o APIs.
La magia está en combinar estas herramientas: Axios o Puppeteer obtiene la página, Cheerio analiza el HTML y Node.js coordina todo el proceso.
Páginas estáticas vs. dinámicas: Por qué importa JavaScript
- Páginas estáticas: El contenido es fijo y se carga junto con la página. Son fáciles de extraer con herramientas sencillas.
- Páginas dinámicas: El contenido aparece después de la carga inicial, normalmente gracias a JavaScript. Aquí necesitas automatización de navegador (como Puppeteer) para ver y extraer los datos ().
Con tantos sitios usando contenido dinámico (piensa en Amazon, LinkedIn, Zillow), el scraping basado en JavaScript es ahora la norma para conseguir los datos que realmente necesitas.
¿Por qué elegir JavaScript para Web Scraping? Ventajas frente a otros lenguajes
Si te das una vuelta por foros de desarrolladores, verás debates eternos: JavaScript vs. Python vs. Ruby vs. Go para web scraping. Aquí va mi opinión después de años en esto:
Los superpoderes de JavaScript
- Manejo nativo de contenido dinámico: JavaScript es el idioma del navegador, así que está hecho para interactuar con sitios modernos llenos de JavaScript ().
- Automatización de navegador: Herramientas como Puppeteer y Playwright pueden hacer clics, desplazarse y rellenar formularios—igual que una persona.
- Familiaridad para equipos front-end: Si tu equipo ya trabaja con JavaScript, puedes aprovechar ese conocimiento para scraping ().
- Concurrencia y velocidad: Node.js maneja muchas tareas a la vez, ideal para extraer datos de muchas páginas rápido ().
- Ecosistema gigante: Miles de librerías, tutoriales y ayuda de la comunidad.
¿Cómo se compara JavaScript con Python, Ruby y Go?
| Lenguaje | Contenido Dinámico | Automatización de Navegador | Comunidad | Velocidad | Ideal para |
|---|---|---|---|---|---|
| JavaScript | Excelente | Excelente | Enorme | Rápido | Sitios interactivos, equipos front-end |
| Python | Bueno (con Selenium/Playwright) | Bueno | Enorme | Rápido | APIs, sitios estáticos, ciencia de datos |
| Ruby | Regular | Limitado | Nicho | Media | Scraping simple de sitios estáticos |
| Go | Limitado | Limitado | En crecimiento | Muy rápido | Scraping a gran escala, backend |
Para extraer datos de sitios modernos e interactivos, JavaScript (con Node.js) suele ser tu mejor aliado (). Python es una gran opción, pero si la página depende mucho de JavaScript, nada le gana a JavaScript ().
Herramientas clave para Web Scraping con JavaScript y Node.js
Vamos a los protagonistas del kit de scraping en JavaScript:
- Node.js: El motor que ejecuta JavaScript fuera del navegador. Es tu centro de operaciones.
- Cheerio: Analiza el HTML y te permite seleccionar elementos (por ejemplo, "dame todos los nombres de productos de esta página").
- Puppeteer/Playwright: Automatizan un navegador real para manejar contenido dinámico, inicios de sesión e interacciones complejas.
- Axios/Fetch: Obtienen páginas web o APIs directamente.
- Otros complementos: Librerías para exportar datos (CSV, Excel), gestionar proxies o programar extracciones.
¿Cómo trabajan juntos? Imagina a Puppeteer como tu navegador robot, Cheerio como el detective de datos y Node.js como el jefe que coordina todo el equipo.
¿Cómo funciona el Web Scraping con JavaScript? Paso a paso
Vamos a desmitificar el proceso. Así suele ser un flujo típico de scraping con JavaScript:
- Enviar una solicitud: Usa Axios o Puppeteer para cargar la página web.
- Esperar el contenido: Si la página es dinámica, espera a que JavaScript termine de cargar (Puppeteer puede "ver" la página final).
- Extraer los datos: Usa Cheerio o las APIs del navegador para seleccionar y copiar la información que buscas.
- Gestionar paginación/subpáginas: Haz clic en “Siguiente” o sigue enlaces para conseguir más datos.
- Exportar los datos: Guarda los resultados en CSV, Excel, Google Sheets o una base de datos.
Analogía: Es como mandar a un becario ultra eficiente a visitar cada página, tomar notas y organizarlas en una hoja de cálculo.
Contenido estático vs. dinámico: ¿En qué se diferencian?
- Ejemplo de sitio estático: Un blog donde todos los artículos están en el HTML. Cheerio + Axios funcionan perfecto.
- Ejemplo de sitio dinámico: Una tienda online donde los precios aparecen al hacer scroll. Aquí necesitas Puppeteer o Playwright para “ver” los precios finales ().
Tip: Si al extraer ves una página en blanco, probablemente es dinámica—es momento de usar Puppeteer.
Thunderbit: Web Scraping sin código con la potencia de JavaScript
Aquí es donde la cosa se pone buena—sobre todo si no eres desarrollador. En , nuestro objetivo es que el scraping al nivel de JavaScript esté al alcance de todos, no solo de los programadores.
Nuestra filosofía: Tu 웹 스크래퍼 debe “entender tareas como un becario”—tú describes lo que quieres y la IA se encarga de averiguar cómo conseguirlo.
Cómo Thunderbit acerca el scraping en JavaScript a todos
- Sugerencia de campos por IA: Haz clic una vez y la IA de Thunderbit analiza la página, sugiere qué datos extraer y configura el 웹 스크래퍼 por ti.
- Extracción en subpáginas: ¿Necesitas más detalles? Thunderbit puede visitar cada subpágina (como fichas de producto o perfiles) y enriquecer tu tabla automáticamente.
- Plantillas instantáneas: Para sitios populares (Amazon, Zillow, Shopify), solo elige una plantilla y listo—sin configuraciones.
- Exportación gratuita de datos: Envía tus datos directamente a Excel, Google Sheets, Airtable o Notion—sin costes extra.
Ejemplo real: He visto equipos de ventas usar Thunderbit para conseguir cientos de leads de un directorio dinámico, con correos y teléfonos, en solo unos clics—sin código ni complicaciones. Es como tener un desarrollador JavaScript en tu equipo, pero sin tener que contratarlo.
Casos de uso populares: Web Scraping con JavaScript en ventas y operaciones
El web scraping con JavaScript no es solo para técnicos. Así lo usan equipos reales cada día:
| Equipo | Caso de uso | Resultado |
|---|---|---|
| Ventas | Generación de leads en directorios | 10x más leads, listos para importar al CRM |
| Ecommerce | Monitoreo de precios de la competencia | Precios dinámicos, respuesta rápida al mercado |
| Operaciones | Unificación de inventario | Vista centralizada de SKUs entre proveedores |
| Inmobiliario | Agregación de anuncios de propiedades | Datos de mercado actualizados en una sola hoja |
| Marketing | Análisis de reseñas y sentimiento | Insights rápidos, mejor segmentación de campañas |
Ejemplo: Un equipo de ecommerce nos contó que ahorró más de 20 horas semanales extrayendo precios de la competencia con Thunderbit, lo que les permitió ajustar sus precios casi en tiempo real ().
Consideraciones éticas y legales en el Web Scraping con JavaScript
Vamos a lo delicado: ¿Es legal el web scraping? La respuesta corta: normalmente sí, si extraes datos públicos y respetas las normas del sitio (). Pero hay reglas importantes:
- Respeta robots.txt: Si un sitio dice “no extraer”, respétalo.
- Cumple los Términos de Servicio: Algunos sitios prohíben explícitamente el scraping.
- Cuida la privacidad: No recojas ni uses datos personales de forma indebida.
- No sobrecargues los servidores: Extrae datos a una velocidad razonable.
Las decisiones judiciales recientes suelen favorecer la extracción de datos públicos, pero las leyes de copyright y privacidad siguen aplicando (). Si tienes dudas, consulta a un experto legal.
Mejor práctica: Solo extrae datos que compartirías públicamente y siempre cita tus fuentes.
El futuro del Web Scraping con JavaScript: IA y automatización
 Aquí es donde la innovación va a toda velocidad. La IA está transformando el scraping de una tarea manual y técnica a un proceso inteligente y automatizado. Las empresas que usan 웹 스크래퍼 impulsados por IA reportan , mayor precisión y capacidad para manejar hasta los sitios dinámicos más complejos ().
Aquí es donde la innovación va a toda velocidad. La IA está transformando el scraping de una tarea manual y técnica a un proceso inteligente y automatizado. Las empresas que usan 웹 스크래퍼 impulsados por IA reportan , mayor precisión y capacidad para manejar hasta los sitios dinámicos más complejos ().
¿Cómo se ve esto en la práctica?
- Agentes de IA pueden leer instrucciones en lenguaje natural, adaptarse a cambios en los sitios y recuperarse de errores ().
- Programación automática: Obtén datos frescos cada día, sin intervención manual.
- Enriquecimiento de datos: La IA puede categorizar, resumir e incluso traducir los datos extraídos al instante.
Thunderbit está a la cabeza de esta tendencia, permitiendo que cualquiera cree y ejecute 웹 스크래퍼 con IA—sin código ni mantenimiento.
¿Quieres saber más sobre el futuro del web scraping con IA? Descubre nuestra guía completa sobre .
Primeros pasos: Consejos prácticos para usuarios de negocio
¿Listo para probar el web scraping con JavaScript (o el enfoque sin código de Thunderbit)? Así puedes empezar:
- Define tu objetivo: ¿Qué datos necesitas y para qué?
- Elige tu herramienta: Si tienes conocimientos técnicos, prueba Node.js con Puppeteer o Cheerio. Si no, y deja que la IA haga el trabajo pesado.
- Empieza en pequeño: Haz pruebas con unas pocas páginas antes de escalar.
- Exporta y analiza: Envía tus datos a Google Sheets, Excel o Notion para analizarlos.
- Sé ético: Respeta siempre la privacidad, los términos de uso y los límites de datos.
¿Quieres aprender más? Consulta tutoriales para principiantes en el , o únete a comunidades online como Stack Overflow o Reddit r/webscraping para recibir ayuda.
Conclusión: Potencia tu negocio con Web Scraping y JavaScript
En resumen: JavaScript y Node.js se han convertido en la base del web scraping moderno, especialmente para sitios dinámicos e interactivos. Seas desarrollador o usuario de negocio, la combinación de automatización de navegador, un ecosistema gigante y ahora herramientas impulsadas por IA te permite extraer los datos que necesitas—más rápido y con mayor precisión que nunca.
Y con soluciones sin código como , no necesitas programar ni una línea para aprovechar el scraping con JavaScript. Solo describe lo que buscas, haz clic y observa cómo aparecen tus datos—listos para análisis, generación de leads o lo que tu empresa necesite.
Si quieres transformar el caos de la web en información estructurada y útil, este es el momento de lanzarte. ¡Feliz scraping! Que tus datos sean siempre limpios, legales y un paso adelante de la competencia.
Preguntas frecuentes
1. ¿Qué es el web scraping con JavaScript y Node.js?
Hacer web scraping con JavaScript y Node.js significa usar código JavaScript (normalmente ejecutado en Node.js) para extraer datos automáticamente de sitios web. Este método es especialmente potente para páginas dinámicas que cargan contenido con JavaScript.
2. ¿Por qué JavaScript es mejor que Python o Ruby para extraer datos de sitios dinámicos?
JavaScript es el lenguaje que usan los navegadores para mostrar y actualizar páginas, así que puede interactuar con contenido dinámico de forma más natural. Herramientas como Puppeteer y Playwright permiten automatizar navegadores reales, facilitando la extracción en sitios que dependen de JavaScript.
3. ¿Pueden los usuarios sin conocimientos técnicos hacer web scraping con JavaScript?
Por supuesto. Herramientas sin código como llevan la potencia del scraping en JavaScript a cualquier persona. Solo usa instrucciones en lenguaje natural y deja que la IA se encargue de lo técnico.
4. ¿Es legal el web scraping?
En general, extraer datos públicos es legal, pero debes respetar los términos de uso del sitio, el archivo robots.txt y las leyes de privacidad. Evita extraer datos personales o protegidos por derechos de autor sin permiso.
5. ¿Cómo está cambiando la IA el web scraping con JavaScript?
La IA está haciendo el scraping más inteligente y accesible. Puede adaptarse a cambios en los sitios, gestionar errores y hasta procesar y enriquecer los datos al vuelo—ahorrando tiempo y mejorando la precisión. Thunderbit es un ejemplo líder de esta nueva generación de scraping con IA.
Para más guías y consejos, visita el o suscríbete a nuestro .
Más información