

Déjame llevarte a un pasado no tan lejano: estoy sentado en mi escritorio, con café en mano, mirando una hoja de cálculo más vacía que mi nevera un domingo por la noche. El equipo de ventas quiere datos de precios de la competencia, el equipo de marketing quiere leads frescos y operaciones quiere listados de productos de una docena de sitios... para ayer. Sé que los datos están ahí fuera, pero conseguirlos es el verdadero reto. Si alguna vez has sentido que estabas jugando al golpear al topo digital con copiar y pegar, no estás solo.
Avancemos hasta hoy y el panorama ha cambiado. El web scraping pasó de ser un proyecto friki de fin de semana a una estrategia empresarial clave. JavaScript y Node.js están ahora en primera línea, impulsando desde scripts puntuales hasta pipelines de datos completos. Pero hay un detalle: aunque las herramientas son más potentes que nunca, la curva de aprendizaje todavía puede sentirse como subir el Everest con chanclas. Así que, tanto si eres un usuario de negocio, un entusiasta de los datos o simplemente alguien cansado de introducir datos manualmente, esta guía es para ti. Voy a desglosar el ecosistema, las bibliotecas esenciales, los puntos de dolor y por qué, a veces, la decisión más inteligente es dejar que la IA haga el trabajo pesado.
Por qué importa el web scraping con JavaScript y Node.js para las empresas
Empecemos por el “por qué”. En 2026, los datos web no son solo un extra útil: son críticos para el negocio. Según investigaciones recientes, el 73% de las empresas atribuye a los datos web públicos la posibilidad de tomar decisiones más rápidas y precisas, y alrededor del 42% de los presupuestos de datos empresariales ya se destina a la recopilación de datos web. El mercado de datos alternativos, que incluye el web scraping, ya es una industria de 4,9 mil millones de dólares y sigue creciendo a buen ritmo.
Entonces, ¿qué impulsa esta fiebre del oro? Estos son algunos de los casos de uso empresarial más comunes:
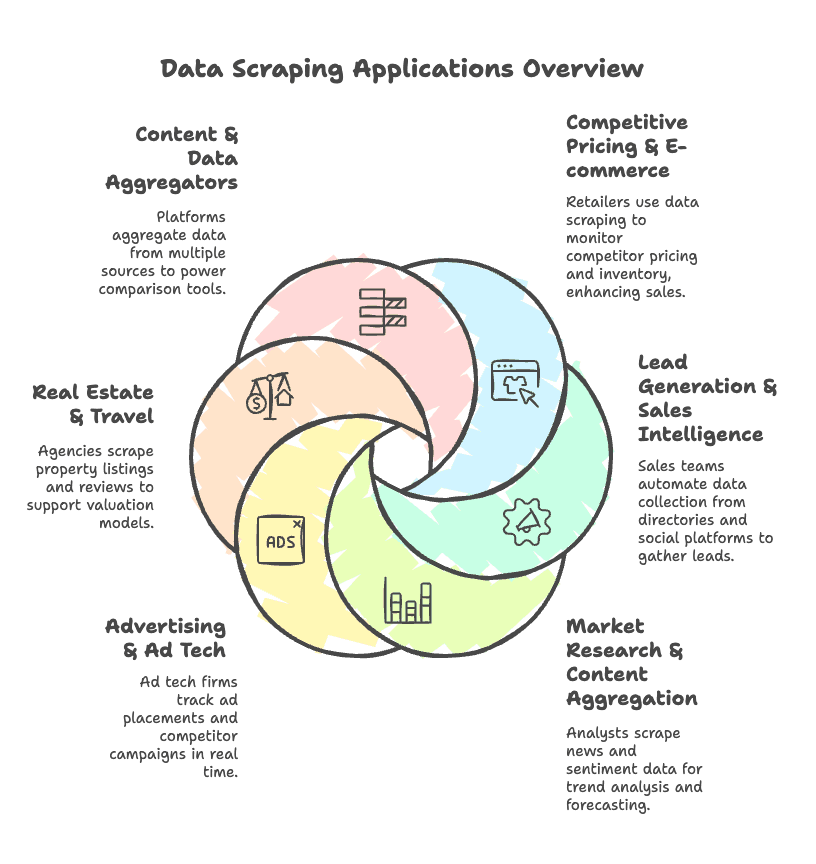
- Precios competitivos y comercio electrónico: los minoristas extraen datos de sitios de la competencia sobre precios e inventario, y a veces logran aumentar las ventas en un 4% o más.
- Generación de leads e inteligencia de ventas: los equipos de ventas automatizan la recopilación de correos electrónicos, números de teléfono y datos de empresas desde directorios y plataformas sociales.
- Investigación de mercado y agregación de contenido: los analistas extraen noticias, reseñas y datos de sentimiento para detectar tendencias y hacer previsiones.
- Publicidad y ad tech: las empresas de ad tech siguen en tiempo real la ubicación de anuncios y las campañas de la competencia.
- Sector inmobiliario y viajes: las agencias extraen listados de propiedades, precios y reseñas para alimentar modelos de valoración y análisis de mercado.
- Agregadores de contenido y datos: las plataformas agregan datos de múltiples fuentes para potenciar herramientas de comparación y paneles.
JavaScript y Node.js se han convertido en la pila predilecta para estas tareas, sobre todo porque cada vez más sitios dependen de contenido dinámico renderizado con JavaScript. Node.js destaca en operaciones asíncronas, lo que lo convierte en una opción natural para extraer datos a escala. Y, gracias a un ecosistema de bibliotecas muy sólido, puedes construir desde scripts rápidos hasta scrapers robustos y listos para producción.
Qué es el data scraping y cómo hacerlo en 2025 Get Started Free
El flujo de trabajo básico: cómo funciona el web scraping con JavaScript y Node.js
Vamos a desmitificar el flujo de trabajo típico del web scraping. Tanto si extraes datos de un blog sencillo como de un sitio de comercio electrónico cargado de JavaScript, los pasos suelen ser bastante consistentes:
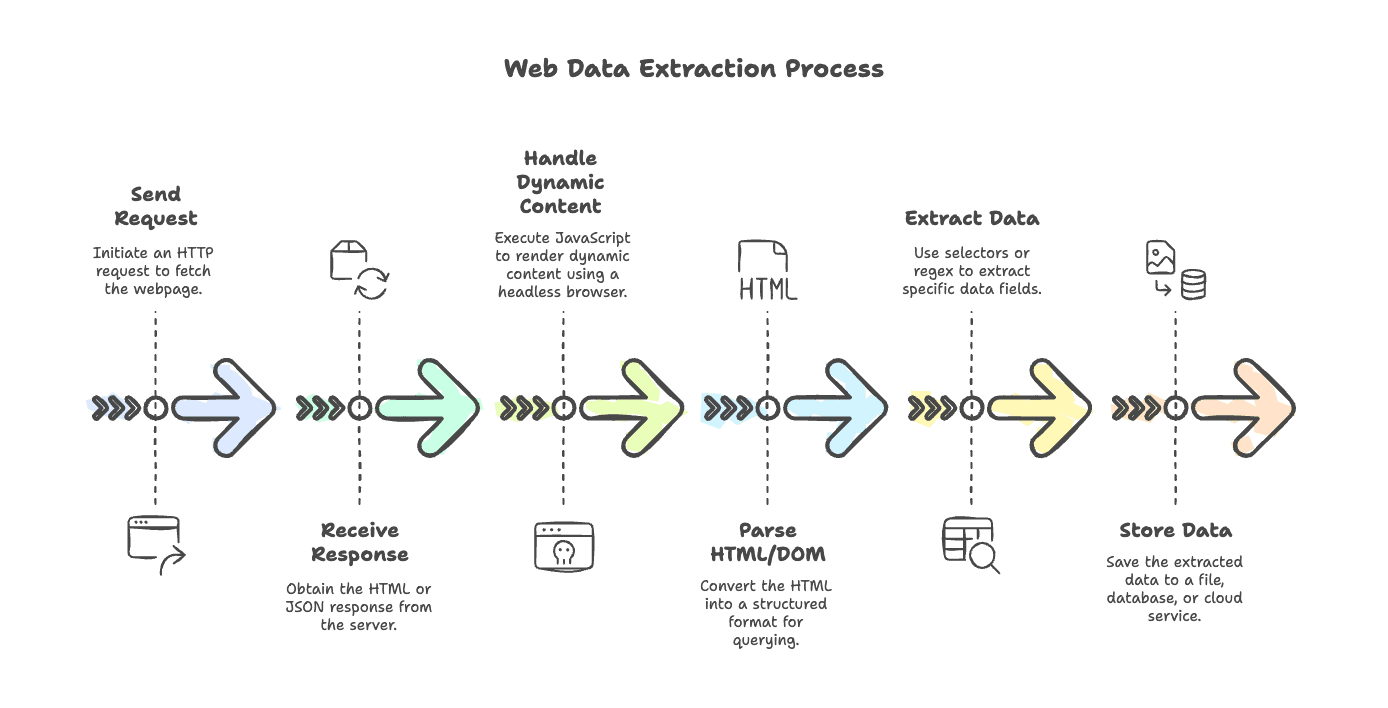
- Enviar la solicitud: usa un cliente HTTP para obtener la página (piensa en
axios,node-fetchogot). - Recibir la respuesta: obtener el HTML (o a veces JSON) que devuelve el servidor.
- Gestionar contenido dinámico: si la página se renderiza con JavaScript, usa un navegador sin interfaz gráfica, como Puppeteer o Playwright, para ejecutar scripts y obtener el contenido final.
- Analizar HTML/DOM: usa un parser (
cheerio,jsdom) para convertir el HTML en una estructura que puedas consultar. - Extraer datos: usa selectores o expresiones regulares para sacar los campos que necesitas.
- Guardar los datos: guarda los resultados en un archivo, una base de datos o un servicio en la nube.
Cada paso tiene sus propias herramientas y buenas prácticas, y eso es lo que veremos a continuación.
Bibliotecas HTTP esenciales para web scraping en JavaScript
El primer paso en cualquier scraper es hacer solicitudes HTTP. Node.js te ofrece un montón de opciones, algunas clásicas y otras modernas. Aquí va un repaso de las bibliotecas más populares:
1. Axios
Un cliente HTTP basado en promesas para Node y navegadores. Es la “navaja suiza” para la mayoría de necesidades de scraping.
const axios = require('axios');
const response = await axios.get('https://example.com/api/items', { timeout: 5000 });
console.log(response.data);
Ventajas: muy completo, compatible con async/await, análisis automático de JSON, interceptores y soporte de proxy.
Desventajas: algo más pesado y, a veces, un poco “mágico” en cómo maneja los datos.
2. node-fetch
Implementa la API fetch del navegador en Node.js. Minimalista y moderno.
import fetch from 'node-fetch';
const res = await fetch('https://api.github.com/users/github');
const data = await res.json();
console.log(data);
Ventajas: ligero, API familiar para quienes vienen de JS frontend.
Desventajas: pocas funciones, manejo de errores manual y configuración de proxies algo verbosa.
3. SuperAgent
Una veterana biblioteca HTTP con una API encadenable.
const superagent = require('superagent');
const res = await superagent.get('https://example.com/data');
console.log(res.body);
Ventajas: madura, soporta formularios, subida de archivos y plugins.
Desventajas: la API se siente algo anticuada y la dependencia es más grande.
4. Unirest
Un cliente HTTP sencillo y agnóstico del lenguaje.
const unirest = require('unirest');
unirest.get('https://httpbin.org/get?query=web')
.end(response => {
console.log(response.body);
});
Ventajas: sintaxis fácil, ideal para scripts rápidos.
Desventajas: menos funciones y una comunidad menos activa.
5. Got
Un cliente HTTP para Node.js potente y rápido, con funciones avanzadas.
import got from 'got';
const html = await got('https://example.com/page').text();
console.log(html.length);
Ventajas: rápido, compatible con HTTP/2, reintentos y streams.
Desventajas: solo funciona en Node y su API puede resultar un poco densa para principiantes.
6. El http/https integrado de Node
Siempre puedes volver a lo clásico:
const https = require('https');
https.get('https://example.com/data', (res) => {
let data = '';
res.on('data', chunk => { data += chunk; });
res.on('end', () => {
console.log('Longitud de la respuesta:', data.length);
});
});
Ventajas: sin dependencias.
Desventajas: verboso, basado en callbacks y sin promesas.
Ver una comparación detallada de funciones y ejemplos de código aquí.
Cómo elegir el cliente HTTP adecuado para tu proyecto
¿Cómo eliges la herramienta correcta para el trabajo? Esto es lo que suelo buscar:
- Facilidad de uso: Axios y Got son excelentes para async/await y una sintaxis limpia.
- Rendimiento: Got y node-fetch son ligeros y rápidos para scraping con mucha concurrencia.
- Compatibilidad con proxies: Axios y Got facilitan la rotación de proxies.
- Manejo de errores: Axios lanza errores HTTP por defecto; node-fetch requiere comprobaciones manuales.
- Comunidad: Axios y Got tienen comunidades activas y muchos ejemplos.
Mis recomendaciones rápidas:
- Scripts rápidos o prototipos: node-fetch o Unirest.
- Scraping en producción: Axios (por sus funciones) o Got (por rendimiento).
- Automatización del navegador: Puppeteer o Playwright gestionan las solicitudes internamente.
Análisis de HTML y extracción de datos: Cheerio, jsdom y más
Una vez que has obtenido el HTML, necesitas convertirlo en algo con lo que puedas trabajar de verdad. Ahí es donde entran los parsers.
Cheerio
Piensa en Cheerio como jQuery para el servidor. Es rápido, ligero y perfecto para HTML estático.
const cheerio = require('cheerio');
const $ = cheerio.load('<ul><li class="item">Item 1</li></ul>');
$('.item').each((i, el) => {
console.log($(el).text());
});
Ventajas: rapidísimo, API familiar, maneja HTML desordenado.
Desventajas: no ejecuta JavaScript; solo ve lo que hay en el HTML.
Más información sobre la velocidad y los casos de uso de Cheerio.
jsdom
jsdom simula un DOM parecido al de un navegador dentro de Node.js. Puede ejecutar scripts sencillos y es más “parecido a un navegador” que Cheerio.
const { JSDOM } = require('jsdom');
const dom = new JSDOM(`<p id="greet">Hello</p><script>document.querySelector('#greet').textContent += ", world!";</script>`);
console.log(dom.window.document.querySelector('#greet').textContent);
Ventajas: puede ejecutar scripts y soporta la API completa del DOM.
Desventajas: más lento y pesado que Cheerio; no es un navegador completo.
Compara Cheerio y jsdom en detalle.
Cuándo usar expresiones regulares u otros métodos de análisis
Las regex en web scraping son como la salsa picante: estupendas con moderación, pero no deberías echárselas a todo. Las regex son útiles para:
- Extraer patrones de texto (correos electrónicos, números de teléfono, precios).
- Limpiar o validar datos extraídos.
- Sacar datos de bloques de texto o etiquetas
script.
Ejemplo: extraer un número de texto
const text = "Ventas totales: 1,234 unidades";
const match = text.match(/([\d,]+)\s*unidades/);
if (match) {
const units = parseInt(match[1].replace(/,/g, ''));
console.log("Unidades vendidas:", units);
}
Pero no intentes analizar HTML completo con regex: para eso usa un parser de DOM. Más consejos sobre regex para scraping.
Cómo gestionar sitios dinámicos: Puppeteer, Playwright y navegadores sin interfaz gráfica
A los sitios modernos les encanta JavaScript. A veces, los datos que quieres no están en el HTML inicial: los renderizan scripts después de cargar la página. Ahí entran los navegadores sin interfaz gráfica.
Puppeteer
Una biblioteca de Node.js de Google que controla Chrome/Chromium. Es como tener un robot que hace clic y navega por las páginas por ti.
const puppeteer = require('puppeteer');
const browser = await puppeteer.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const title = await page.$eval('h1', el => el.textContent);
console.log(title);
await browser.close();
Ventajas: renderizado completo de Chrome, API sencilla, ideal para contenido dinámico.
Desventajas: solo Chromium y mayor consumo de recursos.
Lee más sobre los puntos fuertes de Puppeteer.
Playwright
Una biblioteca más reciente de Microsoft. Playwright es compatible con Chromium, Firefox y WebKit. Es como el primo más moderno y multiplataforma de Puppeteer.
const { chromium } = require('playwright');
const browser = await chromium.launch();
const page = await browser.newPage();
await page.goto('https://example.com');
const content = await page.textContent('h1');
console.log(content);
await browser.close();
Ventajas: multiplataforma, contextos paralelos y espera automática de elementos.
Desventajas: curva de aprendizaje algo más pronunciada y una instalación más grande.
Por qué Playwright está ganando terreno.
Nightmare
Una herramienta de automatización basada en Electron que fue popular hace años. El repositorio se movió a la organización de GitHub segment-boneyard, el “cementerio” de Segment para proyectos que dejaron de mantener, y la última publicación en npm fue en 2019. No la elegiría para nada nuevo en 2026; si heredas un script que todavía la usa, bien, pero para un proyecto nuevo ve directamente a Playwright o Puppeteer.
Comparación de soluciones de navegadores sin interfaz gráfica
| Aspecto | Puppeteer (Chrome) | Playwright (multinavegador) | Nightmare (Electron) |
|---|---|---|---|
| Compatibilidad con navegadores | Chrome/Edge | Chrome, Firefox, WebKit | Chrome (antiguo) |
| Rendimiento y escala | Rápido, pero pesado | Rápido, mejor paralelismo | Más lento, menos estable |
| Scraping dinámico | Excelente | Excelente + más funciones | Correcto para sitios simples |
| Mantenimiento | Bien mantenido | Muy activo | Archivado (segment-boneyard, última publicación en npm en 2019) |
| Ideal para | Scraping en Chrome | Casos complejos y multiplataforma | Tareas simples y heredadas |
Mi consejo: usa Playwright para proyectos nuevos y complejos. Puppeteer sigue siendo excelente para tareas solo con Chrome. Nightmare es más bien para la nostalgia o para scripts antiguos.
Herramientas de apoyo: programación, entorno, CLI y almacenamiento de datos
Un scraper real no es solo obtener y analizar. Estas son algunas herramientas de apoyo que suelo usar:
Programación: node-cron
Programa scrapers para que se ejecuten automáticamente.
const cron = require('node-cron');
cron.schedule('0 9 * * MON', () => {
console.log('Extrayendo datos a las 9:00 cada lunes');
});
Node-cron es perfecto para automatizar tareas repetitivas.
Gestión del entorno: dotenv
Mantén los secretos y la configuración fuera de tu código.
require('dotenv').config();
const apiKey = process.env.API_KEY;
Herramientas CLI: chalk, commander, inquirer
- chalk: da color a la salida de la consola.
- commander: analiza opciones de línea de comandos.
- inquirer: muestra prompts interactivos para la entrada del usuario.
Almacenamiento de datos
- fs: escribir en archivos (JSON, CSV).
- lowdb: base de datos JSON ligera.
- sqlite3: base de datos SQL local.
- mongodb: base de datos NoSQL para proyectos más grandes.
Ejemplo: guardar datos en JSON
const fs = require('fs');
fs.writeFileSync('output.json', JSON.stringify(data, null, 2));
Los puntos débiles del web scraping tradicional con JavaScript y Node.js
Seamos sinceros: el scraping tradicional no es solo sol y arcoíris. Estos son los mayores dolores de cabeza que he visto (y sentido):

- Curva de aprendizaje alta: necesitas entender el DOM, los selectores, la lógica asíncrona y, a veces, las peculiaridades del navegador.
- Carga de mantenimiento: los sitios cambian, los selectores se rompen y estás corrigiendo código constantemente.
- Escalabilidad limitada: cada sitio necesita su propio script; nada es realmente “de talla única”.
- Complejidad en la limpieza de datos: los datos extraídos suelen venir sucios; limpiarlos, formatearlos y eliminar duplicados es un trabajo en sí mismo.
- Límites de rendimiento: la automatización del navegador es lenta y consume muchos recursos en tareas a gran escala.
- Bloqueos y medidas anti-bot: los sitios bloquean scrapers, lanzan CAPTCHAs u ocultan datos detrás de inicios de sesión.
- Zonas grises legales y éticas: hay que navegar términos de servicio, privacidad y cumplimiento.
Lee más sobre estos puntos débiles y estadísticas reales.
Thunderbit frente al web scraping tradicional: una revolución en productividad
Ahora, hablemos del elefante en la habitación: ¿y si pudieras saltarte todo el código, los selectores y el mantenimiento?
Ahí es donde entra Thunderbit. Como cofundador y director ejecutivo, soy un poco parcial, pero déjame explicarte: Thunderbit está pensado para usuarios de negocio que quieren datos, no dolores de cabeza.
Cómo se compara Thunderbit
| Aspecto | Thunderbit (IA sin código) | Scraping tradicional con JS/Node |
|---|---|---|
| Configuración | 2 clics, sin código | Escribir scripts, depurar |
| Contenido dinámico | Gestionado en el navegador | Automatización con navegador sin interfaz gráfica |
| Mantenimiento | La IA se adapta a los cambios | Actualizaciones manuales de código |
| Extracción de datos | Sugerencia de campos con IA | Selectores manuales |
| Scraping de subpáginas | Integrado, 1 clic | Bucle y código por sitio |
| Exportación | Excel, Sheets, Notion | Integración manual con archivos o bases de datos |
| Postprocesado | Resumir, etiquetar, formatear | Código o herramientas extra |
| Quién puede usarlo | Cualquiera con un navegador | Solo desarrolladores |
La IA de Thunderbit lee la página, sugiere campos y extrae datos en apenas un par de clics. Gestiona subpáginas, se adapta a cambios de diseño e incluso puede resumir, etiquetar o traducir datos mientras los extrae. Puedes exportar a Excel, Google Sheets, Airtable o Notion, sin configuración técnica.
Casos de uso en los que Thunderbit destaca:
- Equipos de comercio electrónico que siguen SKUs y precios de la competencia
- Equipos de ventas que extraen leads e información de contacto
- Investigadores de mercado que agregan noticias o reseñas
- Agentes inmobiliarios que obtienen listados y detalles de propiedades
Para scraping frecuente y crítico para el negocio, Thunderbit ahorra muchísimo tiempo. Para proyectos personalizados, a gran escala o con integraciones profundas, el scripting tradicional sigue teniendo su lugar; pero para la mayoría de los equipos, Thunderbit es la forma más rápida de pasar de “necesito datos” a “ya tengo datos”.
Ve la extensión de Chrome de Thunderbit en acción o consulta más casos de uso en el blog de Thunderbit.
Probar Thunderbit AI Web Scraper
Referencia rápida: bibliotecas populares de web scraping con JavaScript y Node.js
Aquí tienes tu chuleta del ecosistema de scraping en JavaScript para 2026:
Solicitudes HTTP
- Axios: cliente HTTP basado en promesas y con muchas funciones.
- node-fetch: API Fetch para Node.js.
- Got: cliente HTTP rápido y avanzado.
- SuperAgent: solicitudes HTTP maduras y encadenables.
- Unirest: cliente sencillo y agnóstico del lenguaje.
Análisis de HTML
- Cheerio: analizador HTML rápido, similar a jQuery.
- jsdom: DOM similar al de un navegador en Node.js.
Contenido dinámico
- Puppeteer: automatización de Chrome sin interfaz gráfica.
- Playwright: automatización multinavegador.
- Nightmare: automatización de navegador basada en Electron y heredada.
Programación
- node-cron: tareas cron en Node.js.
CLI y utilidades
- chalk: estilo de cadenas en la terminal.
- commander: analizador de argumentos CLI.
- inquirer: prompts interactivos de CLI.
- dotenv: cargador de variables de entorno.
Almacenamiento
- fs: sistema de archivos integrado.
- lowdb: pequeña base de datos JSON local.
- sqlite3: base de datos SQL local.
- mongodb: base de datos NoSQL.
Frameworks
- Crawlee: framework de crawling y scraping de alto nivel de Apify. La versión JavaScript/TypeScript está en v3.16 a mayo de 2026 y es la rama más madura (el puerto a Python es más reciente). Envuelve Puppeteer, Playwright, Cheerio y JSDOM en una sola API, con rotación de proxies y colas integradas, algo muy útil si acabas reconstruyendo siempre la misma base alrededor de tus scrapers.
(Comprueba siempre la documentación y los repositorios de GitHub más recientes para ver actualizaciones.)
Recursos recomendados para dominar el web scraping con JavaScript
¿Quieres profundizar más? Aquí tienes una lista seleccionada de recursos para mejorar tus habilidades de scraping:
Documentación oficial y guías
- MDN Web Docs: Web Scraping
- Documentación de Puppeteer
- Documentación de Playwright
- Documentación de Crawlee
- Apify Web Scraping Academy
Tutoriales y cursos
- freeCodeCamp: La guía definitiva para web scraping con Node.js
- YouTube: Web Scraping con Node.js (freeCodeCamp)
- DigitalOcean: cómo extraer datos de un sitio web usando Node.js y Puppeteer
Proyectos y ejemplos de código abierto
Comunidad y foros
- Stack Overflow: Web Scraping
- Reddit: r/webscraping
- Discord de la comunidad de Apify
- Blog de Thunderbit
Libros y guías completas
- “Web Scraping with Python” de O’Reilly (para conceptos aplicables a distintos lenguajes)
- Cursos de Udemy/Coursera: “Web Scraping in Node.js”
(Comprueba siempre las ediciones y actualizaciones más recientes.)
Cómo extraer cualquier sitio web usando IA Get Started Free
Conclusión: elegir el enfoque adecuado para tu equipo
Esta es la idea principal: JavaScript y Node.js te dan una potencia y flexibilidad increíbles para hacer web scraping. Puedes construir de todo, desde scripts rápidos y sucios hasta rastreadores robustos y escalables. Pero con gran poder viene una gran... carga de mantenimiento. El scripting tradicional es ideal para proyectos personalizados y exigentes a nivel de ingeniería, donde necesitas control total y estás preparado para un mantenimiento continuo.
Para todos los demás —usuarios de negocio, analistas, marketers y cualquiera que simplemente quiera los datos— las soluciones modernas sin código como Thunderbit son un soplo de aire fresco. La extensión de Chrome impulsada por IA de Thunderbit te permite extraer, estructurar y exportar datos en minutos, no en días. Sin código, sin selectores, sin dolores de cabeza.
Entonces, ¿cuál es el enfoque correcto? Si tu equipo tiene músculo de ingeniería y requisitos únicos, sumérgete en la caja de herramientas de Node.js. Si buscas velocidad, simplicidad y la libertad de centrarte en las ideas en lugar de en la infraestructura, prueba Thunderbit. En cualquier caso, la web es tu base de datos: ve a por esos datos.
Y si alguna vez te atascas, recuerda: incluso los mejores scrapers empezaron con una página en blanco y una buena taza de café. Feliz scraping.
¿Quieres aprender más sobre scraping impulsado por IA o ver Thunderbit en acción?
- Sitio web oficial de Thunderbit
- Descargar la extensión de Chrome de Thunderbit
- Blog de Thunderbit
- Cómo extraer cualquier sitio web usando IA
- Qué es el data scraping y cómo hacerlo en 2025
Si tienes preguntas, historias o tus anécdotas favoritas de scraping, déjalas en los comentarios o escríbeme. Me encanta ver cómo la gente convierte la web en su propio patio de juegos de datos.
Mantente curioso, mantente cafeinado y sigue haciendo scraping de forma más inteligente, no más dura.
Descargar la extensión de Chrome de Thunderbit
Probar Raspador Web IA Get Started Free
FAQ:
1. ¿Por qué usar JavaScript y Node.js para el web scraping en 2025?
Porque la mayoría de los sitios web modernos están construidos con JavaScript. Node.js es rápido, funciona muy bien con asincronía y tiene un ecosistema muy rico (por ejemplo, Axios, Cheerio y Puppeteer) que cubre desde solicitudes simples hasta la extracción de contenido dinámico a escala.
2. ¿Cuál es el flujo de trabajo típico para extraer datos de un sitio web con Node.js?
Normalmente se ve así:
Solicitud → Gestionar respuesta → (Ejecución opcional de JS) → Analizar HTML → Extraer datos → Guardar o exportar
Cada paso puede gestionarse con herramientas dedicadas como axios, cheerio o puppeteer.
3. ¿Cómo se extraen páginas dinámicas renderizadas con JavaScript?
Usa navegadores sin interfaz gráfica como Puppeteer o Playwright. Cargan la página completa, incluido el JS, lo que permite extraer lo que realmente ven los usuarios.
4. ¿Cuáles son los mayores retos del scraping tradicional?
- Cambios en la estructura del sitio
- Detección anti-bot
- Costes de recursos del navegador
- Limpieza manual de datos
- Alto mantenimiento con el tiempo
Todo esto hace que el scraping a gran escala o para personas no técnicas sea difícil de sostener.
5. ¿Cuándo debería usar algo como Thunderbit en lugar de código?
Usa Thunderbit si necesitas velocidad, simplicidad y no quieres escribir ni mantener código. Es ideal para equipos de ventas, marketing o investigación que quieren extraer y estructurar datos rápidamente, especialmente de sitios complejos o con varias páginas.




