
En 2025, los datos que se pueden sacar de la web ya no son solo un “plus”, sino el motor que mueve la estrategia de cualquier negocio. Desde los grandes del e-commerce que chequean los precios de la competencia al instante, hasta los equipos de ventas que llenan sus listas con leads frescos, las empresas ven los datos públicos online como el nuevo oro digital. Y los números lo dejan claro: casi , y más del . Aunque Python suele llevarse los reflectores, , sobre todo en empresas donde la estabilidad y la integración son lo más importante.
 Después de años metido en SaaS y automatización, he visto de cerca cómo el raspado web con Java puede cambiar la forma de trabajar de una empresa. Pero también he visto equipos trabados en detalles técnicos o frustrados por webs dinámicas y bloqueos anti-bots. Por eso, quiero compartirte una guía práctica y paso a paso para que domines el raspado web con Java en 2025, poniendo el foco en cómo mezclar código con herramientas modernas potenciadas por IA como . Seas desarrollador, encargado de operaciones o alguien de negocio que solo quiere datos sin líos, esta guía es para ti.
Después de años metido en SaaS y automatización, he visto de cerca cómo el raspado web con Java puede cambiar la forma de trabajar de una empresa. Pero también he visto equipos trabados en detalles técnicos o frustrados por webs dinámicas y bloqueos anti-bots. Por eso, quiero compartirte una guía práctica y paso a paso para que domines el raspado web con Java en 2025, poniendo el foco en cómo mezclar código con herramientas modernas potenciadas por IA como . Seas desarrollador, encargado de operaciones o alguien de negocio que solo quiere datos sin líos, esta guía es para ti.
¿Qué es el raspado web con Java? Explicado fácil
Vamos a quitarle el rollo técnico: el raspado web con Java es simplemente usar código Java para sacar información automáticamente de páginas web. Imagínate tener un asistente virtual rapidísimo que puede leer miles de páginas y copiar los datos que necesitas a una hoja de cálculo—solo que este asistente nunca se cansa, no se equivoca y va tan rápido como tu internet.
Así de simple funciona:
- Le manda una solicitud a una web (como si abrieras la página en tu navegador).
- Descarga el HTML (el código fuente de la página).
- Analiza ese HTML y lo convierte en algo que tu programa entiende.
- Saca los datos que te interesan (nombres de productos, precios, emails, lo que sea).
- Guarda los resultados en el formato que más te sirva: CSV, Excel, una base de datos o hasta Google Sheets.
No hace falta ser un crack de la programación para entender lo básico. Con las herramientas correctas y un poco de guía, hasta los usuarios de negocio pueden automatizar la recolección de datos y convertir páginas caóticas en información útil.
¿Por qué el raspado web con Java es clave para las empresas en 2025?
El raspado web ya no es solo cosa de techies: es una necesidad para cualquier empresa. Veamos cómo las empresas usan Java para sacar ventaja y por qué realmente marca la diferencia.
| Caso de uso de raspado web | Beneficios empresariales (ROI) | Industrias de ejemplo |
|---|---|---|
| Monitorización de precios | Inteligencia de precios en tiempo real; incrementos de ventas de 20%+ al reaccionar rápido al mercado | E-commerce, Retail |
| Generación de leads e inteligencia | Listas de prospectos automáticas y actualizadas; 70% menos tiempo en investigación manual | Ventas B2B, Marketing, Reclutamiento |
| Investigación de mercado y tendencias | Detección temprana de tendencias; 5–15% más ingresos y 10–20% mejor ROI en marketing | Consumo, Agencias de marketing |
| Datos financieros y de inversión | Datos alternativos para trading; mercado de más de $5B en “alt-data” extraída de la web | Finanzas, Hedge Funds, Fintech |
| Automatización y monitoreo | Recolección rutinaria automatizada; 73% de ahorro y 85% más rapidez en despliegue | Inmobiliario, Supply Chain, Gobierno |
()
¿Por qué Java? Porque está hecho para escalar, es confiable y se integra sin dramas. Muchas infraestructuras de datos empresariales ya corren sobre Java, así que sumar un raspador web es lo más natural. Además, el multithreading y la gestión de errores de Java lo hacen ideal para manejar grandes volúmenes—piensa en miles de páginas al día, no solo unas cuantas.
¿Cómo funciona el raspado web con Java? Principios y ventajas
Vamos a desmenuzar cómo trabaja un raspador web típico en Java:
- Solicitudes HTTP: Java usa librerías como JSoup o Apache HttpClient para pedir páginas web. Puedes personalizar cabeceras, usar proxies y simular navegadores reales para evitar bloqueos.
- Análisis HTML: Librerías como JSoup convierten el HTML en un “DOM” (una estructura tipo árbol), lo que hace fácil encontrar los datos usando selectores CSS.
- Extracción de datos: Defines reglas (por ejemplo, “saca todos los
<span class='price'>”) para obtener la info que buscas. - Almacenamiento: Guarda los resultados en CSV, Excel, JSON o una base de datos.
¿Qué hace especial a Java para el raspado web?
- Multithreading: Java puede procesar muchas páginas a la vez, acelerando el scraping masivo. El GIL de Python puede ser un cuello de botella, pero los hilos de Java sí corren en paralelo de verdad.
- Rendimiento: Al ser compilado, Java aguanta tareas pesadas y uso intensivo de memoria sin despeinarse.
- Integración empresarial: Los raspadores en Java se conectan fácil con sistemas que ya tienes—CRMs, ERPs, bases de datos—sin líos.
- Gestión de errores: El tipado fuerte y manejo de excepciones de Java hacen que los raspadores sean más sólidos y fáciles de mantener a largo plazo.
Si necesitas una canalización de datos crítica, la estabilidad y escalabilidad de Java son difíciles de igualar.
Librerías y frameworks clave para el raspado web con Java: ¿cuál elegir?
Hay muchas librerías Java para scraping, pero tres son las que más recomiendo para la mayoría de empresas: JSoup, HtmlUnit y Selenium. Así se comparan:
| Librería | ¿Soporta JavaScript? | Facilidad de uso | Rendimiento | Ideal para |
|---|---|---|---|---|
| JSoup | ❌ (No JS) | Muy fácil | Alto | Páginas estáticas, tareas rápidas, trabajos ligeros |
| HtmlUnit | ⚠️ Parcial | Moderada | Media | JS simple, formularios, scraping sin navegador |
| Selenium | ✅ Sí (Completo) | Media/Difícil | Menor (por página) | Sitios con mucho JS, páginas interactivas |
()
JSoup: la opción rápida para HTML sencillo
es mi favorita para la mayoría de tareas. Es ligera, fácil de usar y perfecta para páginas estáticas donde los datos están en el HTML.
Ejemplo:
1Document doc = Jsoup.connect("https://www.scrapingcourse.com/ecommerce/").get();
2String bannerTitle = doc.select("div.site-title").text();
3System.out.println("Banner: " + bannerTitle);Así de fácil. Si necesitas sacar posts de blogs, listados de productos o directorios sin JavaScript, JSoup es tu mejor amiga.
HtmlUnit: simula un navegador para tareas más complejas
es un navegador sin interfaz gráfica hecho en Java. Puede ejecutar algo de JavaScript, rellenar formularios y hacer clic en botones, todo sin abrir una ventana real.
Cuándo usarlo: Si necesitas iniciar sesión o tratar con contenido dinámico básico, pero no quieres la sobrecarga de Selenium.
Ejemplo:
1WebClient webClient = new WebClient();
2HtmlPage page = webClient.getPage("https://example.com/login");
3// ... rellenar formulario y enviar ...Selenium: para páginas interactivas y con mucho JavaScript
es la herramienta más potente. Controla un navegador real (como Chrome o Firefox), así que puede con cualquier sitio, incluso los hechos completamente en JavaScript.
Cuándo usarlo: Para scraping de aplicaciones web modernas, sitios con scroll infinito o que requieren interacción como si fueras un usuario real.
Ejemplo:
1WebDriver driver = new ChromeDriver();
2driver.get("https://www.scrapingcourse.com/ecommerce/");
3List<WebElement> products = driver.findElements(By.cssSelector("li.product"));
4// ... extraer datos ...
5driver.quit();Potencia el raspado web con Java usando Thunderbit: automatización visual y código
Aquí es donde la cosa se pone buena—sobre todo para equipos de negocio que no quieren vivir en el código. es un Raspador Web IA sin código que te deja definir tareas de scraping de forma visual (directo en tu navegador) y exportar los datos a Excel, Google Sheets, Airtable o Notion.
¿Por qué combinar Thunderbit con Java?
- Campos sugeridos por IA: La función “AI Suggest Fields” de Thunderbit lee la página y te recomienda qué extraer—sin que tengas que buscar en el HTML ni escribir selectores.
- Raspado de subpáginas: ¿Necesitas más detalles? Thunderbit puede visitar automáticamente cada subpágina (como fichas de producto) y enriquecer tu dataset.
- Plantillas instantáneas: Para sitios populares (Amazon, Zillow, LinkedIn), Thunderbit tiene plantillas de un clic—sin configurar nada.
- Exportación fácil: Una vez extraídos, exporta tus datos en segundos—listos para que tu código Java los procese, analice o integre.
Thunderbit te ahorra un montón de tiempo en prototipos, sitios complejos o para empoderar a usuarios no técnicos. Y para los desarrolladores, es ideal para delegar las partes repetitivas o frágiles del scraping y enfocarse en la lógica de negocio.
Cómo combinar Thunderbit y Java en proyectos complejos
Este es el flujo de trabajo que te recomiendo:
- Prototipa con Thunderbit: Usa la extensión de Chrome para configurar tu scraping de forma visual. Deja que la IA sugiera campos, gestione la paginación y exporte los datos a Google Sheets o CSV.
- Procesa en Java: Escribe código Java para leer los datos exportados (de Sheets, CSV o Airtable) y haz el post-procesamiento, análisis o integración con tus sistemas empresariales.
- Automatiza y programa: Usa el programador de Thunderbit para mantener tus datos frescos y haz que tu pipeline Java recoja las últimas exportaciones automáticamente.
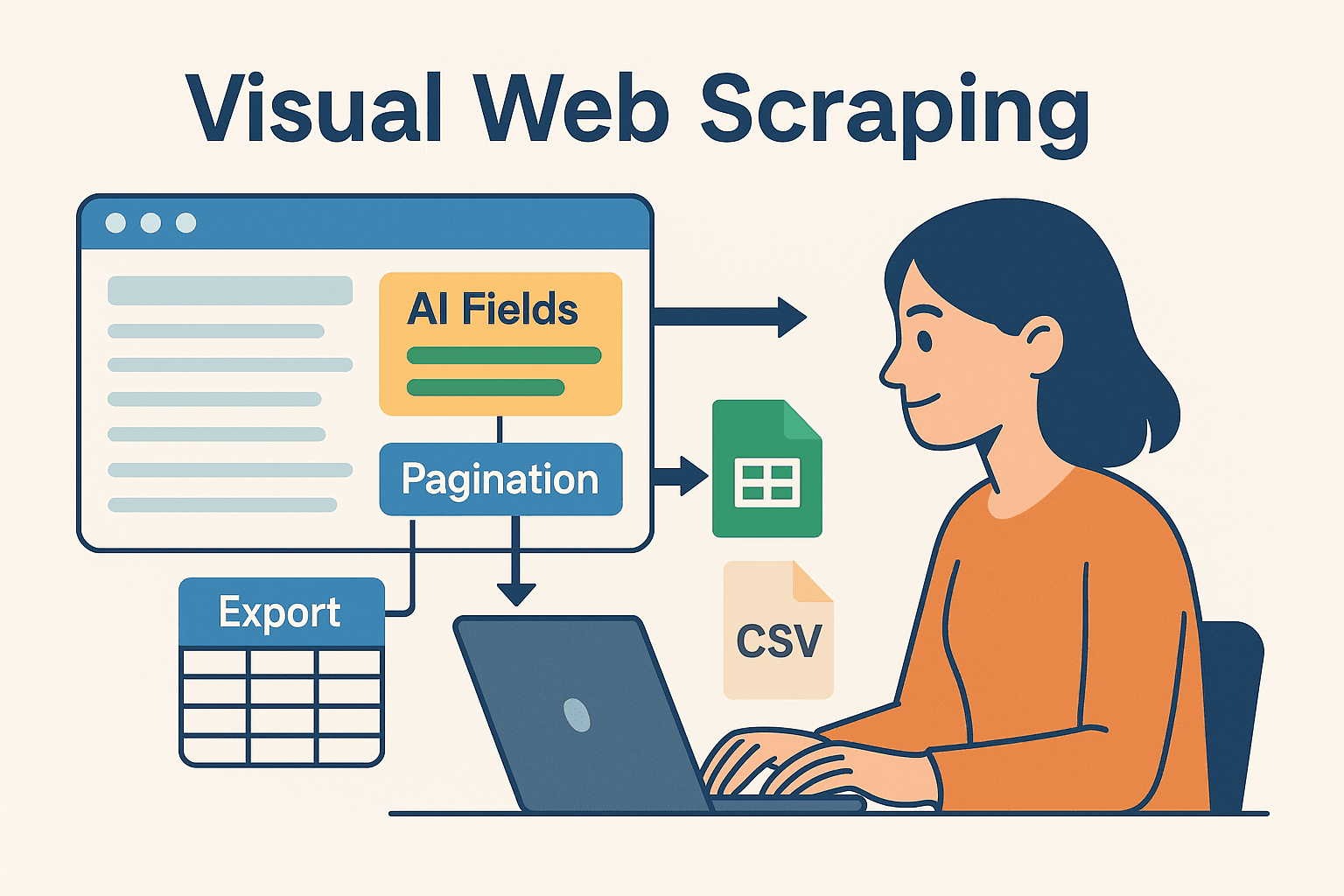 Este enfoque mixto te da lo mejor de los dos mundos: la velocidad y flexibilidad del scraping sin código potenciado por IA, y la potencia y fiabilidad de Java para el procesamiento posterior.
Este enfoque mixto te da lo mejor de los dos mundos: la velocidad y flexibilidad del scraping sin código potenciado por IA, y la potencia y fiabilidad de Java para el procesamiento posterior.
Guía paso a paso: crea tu primer raspador web en Java
Vamos a lo práctico. Así puedes armar un raspador web sencillo en Java desde cero.
Prepara tu entorno Java
- Instala Java (JDK): Usa Java 17 o 21 para máxima compatibilidad.
- Configura Maven: Así gestionas las dependencias sin líos.
- Elige un IDE: IntelliJ IDEA, Eclipse o VSCode van de lujo.
- Agrega JSoup a tu
pom.xml:1<dependency> 2 <groupId>org.jsoup</groupId> 3 <artifactId>jsoup</artifactId> 4 <version>1.16.1</version> 5</dependency>
Escribe y ejecuta tu raspador
Vamos a sacar nombres y precios de productos de un e-commerce de prueba.
1import org.jsoup.Jsoup;
2import org.jsoup.nodes.Document;
3import org.jsoup.select.Elements;
4import org.jsoup.nodes.Element;
5public class ProductScraper {
6 public static void main(String[] args) {
7 String url = "https://www.scrapingcourse.com/ecommerce/";
8 try {
9 Document doc = Jsoup.connect(url)
10 .userAgent("Mozilla/5.0")
11 .get();
12 Elements productElements = doc.select("li.product");
13 for (Element productEl : productElements) {
14 String name = productEl.selectFirst("h2").text();
15 String price = productEl.selectFirst("span.price").text();
16 System.out.println(name + " -> " + price);
17 }
18 } catch (Exception e) {
19 e.printStackTrace();
20 }
21 }
22}Tip: Siempre pon un user-agent para simular un navegador real. Algunos sitios bloquean el user-agent por defecto de Java.
Exporta y usa tus datos
- Exportar a CSV: Usa
FileWritero una librería como OpenCSV para guardar los resultados. - Exportar a Excel: Usa Apache POI para archivos .xls/.xlsx.
- Integración con bases de datos: Usa JDBC para insertar datos directamente.
- Google Sheets: Exporta desde Thunderbit y lee con la API de Google Sheets para Java.
Cómo superar los retos más comunes del raspado web con Java
El scraping no siempre es un paseo. Estos son los problemas más típicos y cómo puedes resolverlos:
- Bloqueo de IP y límites de velocidad: Baja la frecuencia de tus solicitudes (
Thread.sleep()), rota proxies y aleatoriza los tiempos. Para grandes volúmenes, usa servicios de proxy. - CAPTCHAs y detección de bots: Usa Selenium para simular comportamiento humano o recurre a APIs anti-bot. A veces, el scraping en la nube de Thunderbit puede saltarse estos obstáculos.
- Contenido dinámico: Si JSoup no encuentra datos, probablemente se cargan con JavaScript. Cambia a Selenium o HtmlUnit, o busca la API interna del sitio.
- Cambios en la estructura web: Escribe código flexible con selectores adaptables. Supervisa tus raspadores y actualízalos cuando cambie la web. La IA de Thunderbit se adapta rápido—solo vuelve a ejecutar “AI Suggest Fields”.
- Gestión de sesiones: Para scraping autenticado, maneja cookies y sesiones con cuidado. Selenium y Thunderbit (si estás logueado en Chrome) pueden con páginas protegidas.
Consejos avanzados para mejorar la eficiencia del raspado web con Java
¿Listo para subir de nivel? Aquí van algunos trucos de pro:
- Multithreading: Usa
ExecutorServicede Java para raspar varias páginas a la vez. ¡Pero no te pases o te bloquearán! - Programación de tareas: Usa Quartz Scheduler en Java, o deja que Thunderbit programe en la nube con lenguaje natural (“cada lunes a las 9am”).
- Escalado en la nube: Para trabajos grandes, corre navegadores sin cabeza en la nube o reparte tareas entre varias máquinas.
- Flujos híbridos: Usa Thunderbit para los sitios más complicados y código Java para el resto. Junta los resultados en tu data warehouse.
- Monitoreo y logs: Usa frameworks de logging de Java para vigilar la salud de tus raspadores, detectar errores y lanzar alertas si algo falla.
Conclusión y puntos clave
Los datos web son el nuevo oro, y Java sigue siendo una de las mejores herramientas—sobre todo para equipos que buscan fiabilidad, escalabilidad e integración. El flujo básico es sencillo: obtener, analizar, extraer y exportar. Con librerías como JSoup, HtmlUnit y Selenium, puedes atacar desde directorios simples hasta webs modernas llenas de JavaScript.
Pero no tienes que hacerlo todo a mano. Herramientas como suman IA y automatización visual, permitiéndote prototipar, adaptar y escalar tus proyectos de scraping más rápido que nunca. ¿Mi consejo? No tengas miedo de mezclar código y no-código. Usa Thunderbit para configurar y mantener rápido, y deja que tu pipeline Java haga el trabajo pesado.
¿Quieres ver cómo Thunderbit puede mejorar tu flujo de trabajo? y prueba a raspar tu primer sitio en minutos. Y si quieres más, pásate por el para tutoriales, guías y lo último en automatización de scraping.
¡Feliz scraping! Que tus datos siempre estén ordenados, frescos y listos para usar.
Preguntas frecuentes
1. ¿Java sigue siendo relevante para el raspado web en 2025?
Totalmente. Aunque Python es popular para scripts rápidos, Java sigue siendo la opción top para proyectos empresariales, confiables y de largo plazo—sobre todo donde la integración y el multithreading importan.
2. ¿Cuándo usar JSoup, HtmlUnit o Selenium?
Usa JSoup para páginas estáticas, HtmlUnit para contenido dinámico sencillo o formularios, y Selenium para sitios interactivos o con mucho JavaScript. Elige según lo complicado que sea el sitio.
3. ¿Cómo evitar bloqueos al hacer scraping?
Baja la velocidad de tus solicitudes, usa proxies rotativos, pon user-agents realistas y simula comportamiento humano. Para sitios difíciles, prueba el scraping en la nube de Thunderbit o APIs anti-bot.
4. ¿Pueden trabajar juntos Thunderbit y Java?
Claro. Usa Thunderbit para definir y programar scrapes de forma visual, exporta los datos y luego procésalos o intégralos con tu código Java. Es una combinación potente tanto para usuarios de negocio como para desarrolladores.
5. ¿Cuál es la forma más rápida de empezar con el raspado web en Java?
Prepara Java y Maven, añade JSoup y prueba a raspar un sitio sencillo. Para tareas más complejas o prototipos rápidos, instala y deja que la IA haga el trabajo pesado—luego integra los resultados en tu flujo Java.
¿Quieres más consejos, ejemplos de código o trucos de automatización? Explora el o suscríbete a nuestro para tutoriales prácticos y lo último en tecnología de scraping. Más información