Todavía me acuerdo de la primera vez que intenté sacar datos de productos de una web. Tenía delante una lista de zapatillas deportivas y pensé: “¿Qué tan complicado puede ser pasar todos estos nombres y precios a una hoja de cálculo?” Unas horas después, ya estaba peleando con errores de JavaScript, selectores que no entendía y una nueva admiración por quienes han creado un Raspador Web desde cero.
Si alguna vez te has visto en esa, ya sea en ventas, ecommerce u operaciones y solo quieres datos frescos para tomar mejores decisiones, créeme: no eres el único. La demanda de web scraping se ha disparado en los últimos años. De hecho, el y se espera que se duplique para 2030. Pero aquí va el truco: la mayoría de las herramientas clásicas requieren saber de tecnología. Por eso quiero enseñarte dos caminos distintos: uno práctico y con código usando Cypress, y otro mucho más sencillo y sin código, potenciado por IA, con . Usaremos la como ejemplo.
Tanto si eres desarrollador y quieres poner a prueba tus habilidades en JavaScript, como si eres de negocio y prefieres no tocar ni una línea de código, esta guía te ayudará a conseguir los datos que buscas—sin perder la paciencia (ni tu finde).
¿Qué es el Web Scraping y por qué es importante para los negocios?
Vamos a lo básico: el raspado web es el proceso de sacar datos automáticamente de páginas web. En vez de copiar y pegar nombres de productos, precios o contactos uno por uno, usas un software que hace el trabajo duro por ti.
¿Y por qué esto es importante para las empresas? Porque los datos son el nuevo oro (o la nueva leche de avena, según lo que tomes). Empresas de ventas, ecommerce y operaciones usan el raspado web para:
- Generar leads sacando información de contacto de directorios o perfiles sociales.
- Vigilar precios de la competencia y tendencias de productos—alrededor del .
- Analizar la opinión de los clientes extrayendo reseñas y valoraciones.
- Automatizar investigaciones repetitivas que, de otra forma, te llevarían horas o días haciéndolo a mano.
Y el retorno es real: dicen que los datos públicos de la web les ayudan a decidir más rápido y mejor. En resumen, si no usas web scraping, probablemente estés dejando dinero—y oportunidades—en la mesa.
Presentando Cypress: Una herramienta popular para Web Scraping
Vamos a hablar de herramientas. Cypress es un framework open-source pensado originalmente para hacer pruebas end-to-end en webs. Imagina un robot que puede hacer clic, rellenar formularios y comprobar si tu web funciona bien. Pero aquí viene la sorpresa: como Cypress se ejecuta en un navegador real y puede interactuar con webs llenas de JavaScript, también se ha vuelto una opción útil (aunque poco común) para el raspado web.
¿Cómo se compara Cypress con otras herramientas, sobre todo las de Python (como BeautifulSoup o Scrapy)? Aquí va un resumen rápido:
- Cypress: Perfecto para sacar contenido dinámico generado por JavaScript. Necesitas saber JavaScript y sentirte cómodo con Node.js. Es flexible y potente, pero claramente pensado para desarrolladores.
- Raspadores en Python: Herramientas como BeautifulSoup o Scrapy están hechas para rastrear grandes cantidades de HTML estático. Tienen un ecosistema enorme, pero pueden fallar con webs que requieren un navegador real para cargar el contenido.
Si ya tienes experiencia con JavaScript o pruebas de QA, Cypress puede ser sorprendentemente eficaz para extraer datos. Pero si el código no es lo tuyo, tranquilo—enseguida te muestro una alternativa sin código.
Paso a paso: Web Scraping con Cypress (Ejemplo: Zapatillas Adidas para hombre)
Vamos a ponernos manos a la obra y crear un raspador con Cypress para la . El objetivo: sacar nombres de productos, precios, imágenes y enlaces en un archivo bien ordenado.
1. Configurando tu entorno de Cypress
Primero, necesitas tener y npm instalados. Una vez listos, abre la terminal y ejecuta:
1mkdir adidas-scraper
2cd adidas-scraper
3npm init -y
4npm install cypress --save-devEsto crea un nuevo proyecto e instala Cypress localmente. Para abrir Cypress por primera vez:
1npx cypress openCypress generará una carpeta cypress/ con ejemplos de pruebas. Puedes borrarlos y crear tu propio archivo, por ejemplo, cypress/e2e/adidas-scraper.cy.js.
2. Inspeccionando la web e identificando los datos a extraer
Toca investigar. Abre la en tu navegador, haz clic derecho sobre un producto y selecciona “Inspeccionar”. Verás que cada producto está dentro de una tarjeta, con elementos para el nombre, precio, imagen y enlace.
Por ejemplo, podrías ver algo así:
1<div class="product-card">
2 <a href="/us/adizero-sl2-running-shoes/XYZ123.html">
3 <img src="..." alt="Adizero SL2 Running Shoes"/>
4 <div class="product-price">$130</div>
5 <div class="product-name">Adizero SL2 Running Shoes -- Men's Running</div>
6 </a>
7</div>Fíjate en los nombres de clase como .gl-price para los precios y busca patrones que se repitan en el HTML. Aquí es donde le dirás a Cypress qué debe sacar.
3. Escribiendo el código de Cypress para extraer datos
Aquí tienes un ejemplo de script para empezar:
1// cypress/e2e/adidas-scraper.cy.js
2describe('Scrape Adidas Running Shoes', () => {
3 it('collects product name, price, image, and link', () => {
4 cy.visit('<https://www.adidas.com/us/men-running-shoes>');
5 const products = [];
6 cy.get('a[href*="/us/"][href*="running-shoes"]').each(($el) => {
7 const name = $el.find('*:contains("Running Shoes")').text().trim();
8 const price = $el.find('.gl-price').text().trim();
9 const imageUrl = $el.find('img').attr('src');
10 const link = $el.attr('href');
11 products.push({ name, price, image: imageUrl, link: `https://www.adidas.com$\{link\}` });
12 }).then(() => {
13 cy.writeFile('cypress/output/adidas_products.json', products);
14 });
15 });
16});¿Qué hace este código?
cy.visit()carga la página.cy.get()selecciona todos los enlaces de productos que coinciden con el patrón de Adidas..each()recorre cada producto y saca nombre, precio, imagen y enlace.- Los datos se guardan en un array y se escriben en un archivo JSON.
Tendrás que ajustar los selectores si Adidas cambia su web, pero esto te servirá como base.
4. Exportando y usando los datos extraídos
Cuando ejecutes el script (desde la interfaz de Cypress o con npx cypress run), revisa el archivo cypress/output/adidas_products.json. Verás un array de objetos como este:
1[
2 {
3 "name": "Adizero SL2 Running Shoes Men's Running",
4 "price": "$130",
5 "image": "<https://assets.adidas.com/images/w_280,h_280,f_auto,q_auto:sensitive/.../adizero-SL2-shoes.jpg>",
6 "link": "<https://www.adidas.com/us/adizero-sl2-running-shoes/XYZ123.html>"
7 },
8 ...
9]Desde aquí, puedes convertir el JSON a CSV, analizarlo en Excel o cargarlo en tu herramienta de BI favorita. Incluso puedes automatizar el proceso para que se ejecute a diario y monitorizar precios.
Retos comunes al hacer Web Scraping con Cypress
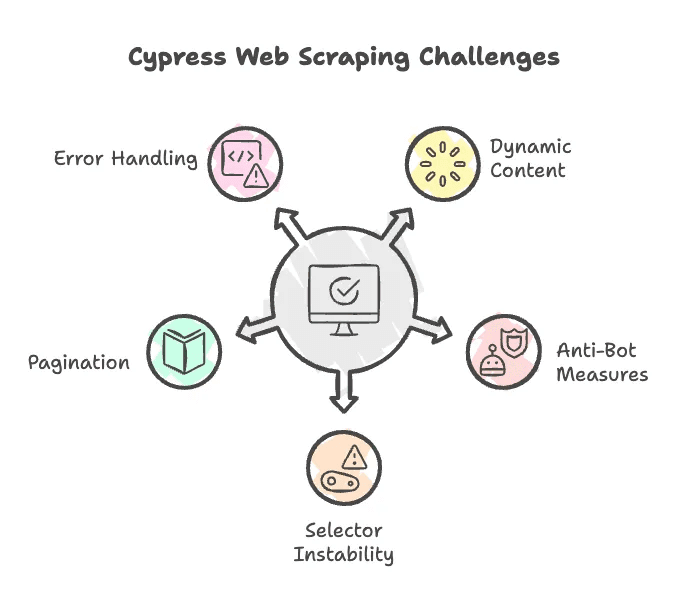
Seamos sinceros: el raspado web no siempre es un paseo. Estos son algunos de los obstáculos más comunes con Cypress (y cómo sortearlos):
- Contenido generado por JavaScript: Cypress maneja bien el contenido dinámico, pero puede que tengas que esperar a que los elementos carguen o hacer scroll para activar la carga diferida. Usa
cy.wait()o comandos de scroll cuando haga falta. - Defensas anti-bots: Algunos sitios bloquean bots revisando el user agent o limitando la frecuencia de peticiones. Cypress se ejecuta en un navegador real, lo que ayuda, pero si el bloqueo es fuerte, quizá necesites técnicas más avanzadas (como proxies rotativos o modificar cabeceras).
- Selectores inestables: Si Adidas cambia la estructura HTML o los nombres de clase, tu script puede romperse. Prepárate para actualizar los selectores de vez en cuando.
- Paginación: Muchas páginas de productos tienen varias páginas. Tendrás que programar la lógica para hacer clic en “Siguiente” y juntar los resultados de todas las páginas.
- Manejo de errores: Cypress está pensado para testing, así que suele fallar de forma ruidosa si falta algo. Añade comprobaciones para gestionar elementos ausentes sin que todo se detenga.
Si empiezas a sentir que necesitas un máster en informática solo para sacar una lista de zapatillas, no eres el único. Por eso creamos Thunderbit.
¿Demasiado complicado? Prueba Thunderbit para Web Scraping en 2 clics
Supón que no quieres pelearte con Node.js, selectores ni depurar JavaScript. Aquí entra , nuestra extensión de Chrome para raspado web con IA. Está pensada para usuarios de negocio que solo quieren los datos—sin código, sin instalaciones raras, sin dolores de cabeza.
¿Qué hace diferente a Thunderbit?
- Sin código ni selectores: Solo apuntas, haces clic y dejas que la IA haga el resto.
- Una plantilla, muchos sitios: La IA de Thunderbit se adapta a diferentes diseños de página, así que no tienes que reconfigurar para cada web.
- Raspado en navegador y en la nube: Elige el modo que mejor te venga según velocidad y precisión.
- Gestiona paginación y subpáginas: Thunderbit puede navegar por varias páginas y visitar páginas de detalle para enriquecer tus datos.
- Exportación gratuita: Descarga tus datos a Excel, Google Sheets, Airtable o Notion—sin sorpresas ni muros de pago.
Veamos cómo extraer datos de la página de Adidas con Thunderbit.
Paso a paso: Web Scraping con Thunderbit (Ejemplo Adidas)
1. Instalar la extensión de Chrome Thunderbit
Primero, instala . Tardarás menos de un minuto, menos de lo que tardo yo en encontrar mi taza de café por la mañana.
Regístrate gratis—Thunderbit te da una prueba gratuita (10 páginas) y un plan gratuito (6 páginas al mes), así que puedes probarlo en tareas reales sin sacar la tarjeta.
2. Extraer datos con IA y sugerencia de campos
- Abre la .
- Haz clic en el icono de Thunderbit en tu navegador. Se abrirá la barra lateral.
- Pulsa “IA Sugerir Campos”. La IA de Thunderbit analiza la página y detecta automáticamente los campos de nombre, precio, imagen y enlace. Verás una tabla de vista previa con las primeras filas.
- ¿Quieres ajustar las columnas? Puedes renombrarlas o añadir nuevos campos con un clic. Incluso puedes pedirle a Thunderbit, en lenguaje natural, que saque otros datos como “también extrae el número de colores disponibles”.
- Haz clic en “Extraer”. Thunderbit recopila todos los datos, navegando automáticamente por la paginación si hay varias páginas. Si quieres más detalles de cada producto, usa la función de subpáginas—Thunderbit visitará cada producto y enriquecerá tu tabla.
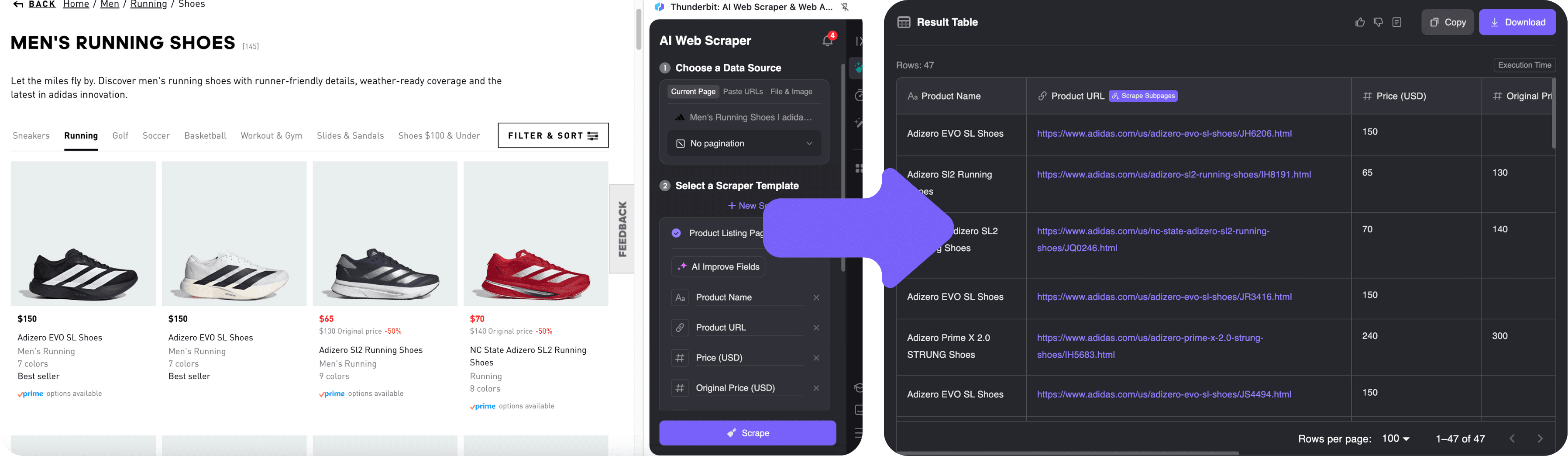
3. Exportar y usar tus datos
Cuando termine la extracción, revisa la tabla en la barra lateral de Thunderbit. Puedes:
- Exportar a Excel, Google Sheets, Airtable o Notion con un solo clic.
- Descargar como CSV o JSON.
- Exportar imágenes, emails, teléfonos y más—Thunderbit soporta todos los tipos de datos habituales.
Y sí, la exportación es totalmente gratuita. Sin sustos ni cobros inesperados.
Para más consejos, revisa nuestra o explora el para más tutoriales de scraping.
Comparando Cypress y Thunderbit: ¿Qué herramienta de Web Scraping te conviene?
Pongamos Cypress y Thunderbit frente a frente. Aquí tienes una tabla comparativa:
| Aspecto | Cypress (Raspador con código) | Thunderbit (Raspador IA sin código) |
|---|---|---|
| Dificultad de configuración | Requiere Node.js, npm y conocimientos de JavaScript. La configuración inicial puede ser lenta para no desarrolladores. | Instala la extensión de Chrome, inicia sesión y listo en minutos. No necesitas programar. |
| Habilidades técnicas necesarias | Debes saber JavaScript y selectores DOM/CSS. Barrera alta para quienes no programan. | No necesitas programar. Interfaz de lenguaje natural y clics. |
| Velocidad de implementación | Escribir y depurar scripts puede llevar horas, sobre todo en páginas complejas o con paginación. | Configura y ejecuta una extracción en un par de clics. Gestiona paginación y subpáginas automáticamente. |
| Flexibilidad | Extremadamente flexible—puedes programar cualquier lógica, gestionar logins, resolver captchas e integrar APIs. | Pensado para patrones estándar. La IA cubre la mayoría de sitios, pero flujos muy únicos o complejos pueden requerir intervención manual. |
| Robustez ante cambios | Los scripts son frágiles—si cambia el HTML, tendrás que actualizar el código. | Más robusto—la IA se adapta a pequeños cambios de diseño. Los modelos de Thunderbit se actualizan continuamente para nuevos patrones. |
| Escalabilidad | Puede manejar volumen moderado, pero el raspado en navegador es más lento a gran escala. | El raspado en la nube puede manejar cientos de páginas. El sistema de créditos lo hace manejable para empresas. |
| Ideal para | Desarrolladores o usuarios técnicos que necesitan precisión y lógica personalizada. Perfecto para extracciones puntuales o flujos complejos. | Usuarios de negocio que quieren scraping rápido y sin código para tareas repetitivas como monitorizar precios, generar leads o extraer listados. Ideal para prototipos y sitios estándar de ecommerce, directorios o reseñas. |
En resumen: Cypress te da control, Thunderbit te da velocidad y sencillez. Si eres desarrollador y te gusta experimentar, Cypress es tu campo de juego. Si solo quieres los datos (y tu jefe los quiere para la hora de la comida), Thunderbit es tu mejor aliado.
Conclusiones: ¿Qué enfoque de Web Scraping elegir?
- El web scraping es clave para los negocios modernos—ya sea para seguir a la competencia, generar leads o analizar tendencias de mercado.
- Cypress es una herramienta potente y flexible para desarrolladores que quieren programar sus propios raspadores. Es ideal para sitios dinámicos y flujos personalizados, pero requiere curva de aprendizaje y mantenimiento.
- Thunderbit está pensado para todos los demás. Es una que hace el scraping tan fácil como dos clics—sin código, sin instalaciones, sin complicaciones. Gestiona paginación, subpáginas y exporta gratis a tus herramientas favoritas.
- Elige Cypress si necesitas máxima flexibilidad y no te importa ensuciarte las manos con código.
- Elige Thunderbit si quieres ahorrar tiempo, evitar líos técnicos y obtener datos limpios rápidamente—especialmente si trabajas en ventas, ecommerce, marketing u operaciones.
Si quieres ver más, visita nuestro para tutoriales sobre , y mucho más.
Y si alguna vez te encuentras frente a una página llena de zapatillas preguntándote cómo pasar todos esos datos a una hoja de cálculo—recuerda que tienes opciones. ¡Feliz scraping!
Preguntas frecuentes
1. ¿Qué es Cypress y cómo se puede usar para web scraping?
Cypress es una herramienta de testing basada en JavaScript que puede interactuar con sitios web dinámicos, lo que la hace útil para extraer contenido generado por JavaScript.
2. ¿Cuáles son los principales retos al extraer datos con Cypress?
Los problemas más comunes incluyen cambios en la estructura HTML, carga diferida, defensas anti-bots y la gestión de paginación o elementos ausentes en páginas complejas.
3. ¿Existe una forma más sencilla de extraer datos sin programar?
Sí, Thunderbit es una extensión de Chrome impulsada por IA que extrae datos en unos pocos clics—sin código, sin configuración ni ajustes de selectores.
Más información: