

Hay algo atemporal en abrir una terminal, escribir un solo comando y ver cómo los datos web en bruto llegan como si acabaras de abrir la Matrix. Para desarrolladores y usuarios técnicos avanzados, cURL es esa varita mágica: una herramienta discreta de línea de comandos que lleva años funcionando en miles de millones de dispositivos, desde servidores en la nube hasta tu frigorífico inteligente. Y aun en 2026, con todas las herramientas sin código y de scraping con IA que existen, el raspado web con cURL sigue siendo una opción de referencia para cualquiera que busque velocidad, control y capacidad de automatización.
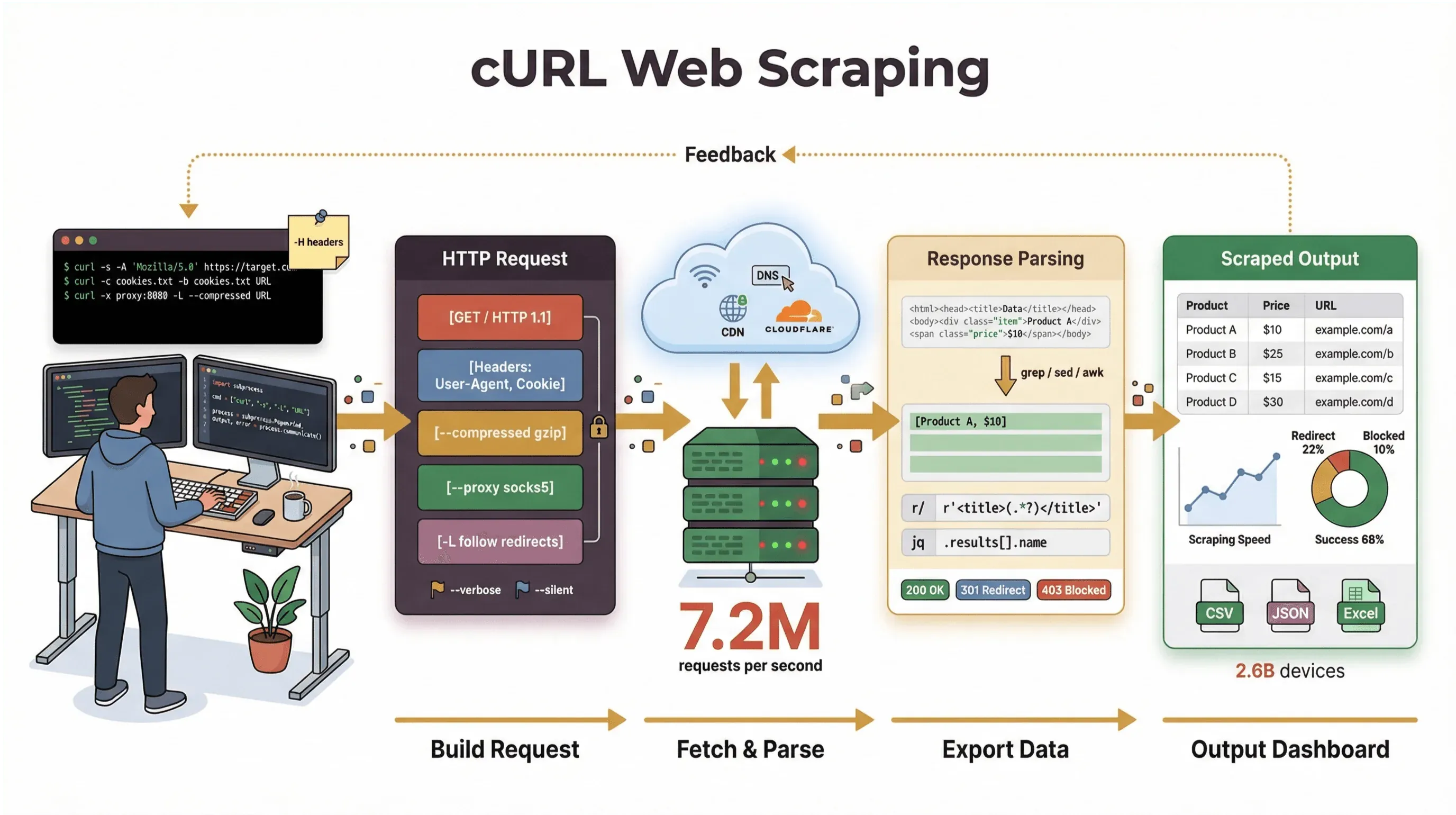 He pasado años creando herramientas de automatización y ayudando a equipos a gestionar datos web, y todavía recurro a cURL cuando necesito recuperar una página, depurar una API o prototipar un flujo de trabajo de scraping. En esta guía, te llevaré por un tutorial de raspado web con cURL que cubre tanto lo básico como los trucos avanzados: con ejemplos reales de comandos, consejos prácticos y una mirada clara a dónde brilla cURL (y dónde se queda corto). Y si eres más bien un usuario de negocio que prefiere no tocar la línea de comandos, te mostraré cómo Thunderbit, nuestro raspador web con IA, puede llevarte de “necesito estos datos” a “aquí está mi hoja de cálculo” en dos clics, sin necesidad de código.
He pasado años creando herramientas de automatización y ayudando a equipos a gestionar datos web, y todavía recurro a cURL cuando necesito recuperar una página, depurar una API o prototipar un flujo de trabajo de scraping. En esta guía, te llevaré por un tutorial de raspado web con cURL que cubre tanto lo básico como los trucos avanzados: con ejemplos reales de comandos, consejos prácticos y una mirada clara a dónde brilla cURL (y dónde se queda corto). Y si eres más bien un usuario de negocio que prefiere no tocar la línea de comandos, te mostraré cómo Thunderbit, nuestro raspador web con IA, puede llevarte de “necesito estos datos” a “aquí está mi hoja de cálculo” en dos clics, sin necesidad de código.
Vamos a profundizar y ver por qué cURL sigue siendo relevante para el raspado web en 2026, cómo usarlo con eficacia y cuándo conviene recurrir a algo aún más potente.
¿Qué es cURL? La base del raspado web con cURL
En esencia, cURL es una herramienta de línea de comandos y una biblioteca para transferir datos mediante URL. Lleva casi 30 años existiendo (sí, de verdad) y está en todas partes: integrado en sistemas operativos, alimentando scripts y gestionando en silencio transferencias de datos en más de veinte mil millones de instalaciones. Si alguna vez has ejecutado un comando rápido para obtener una página web, probar una API o descargar un archivo, es muy probable que hayas usado cURL.
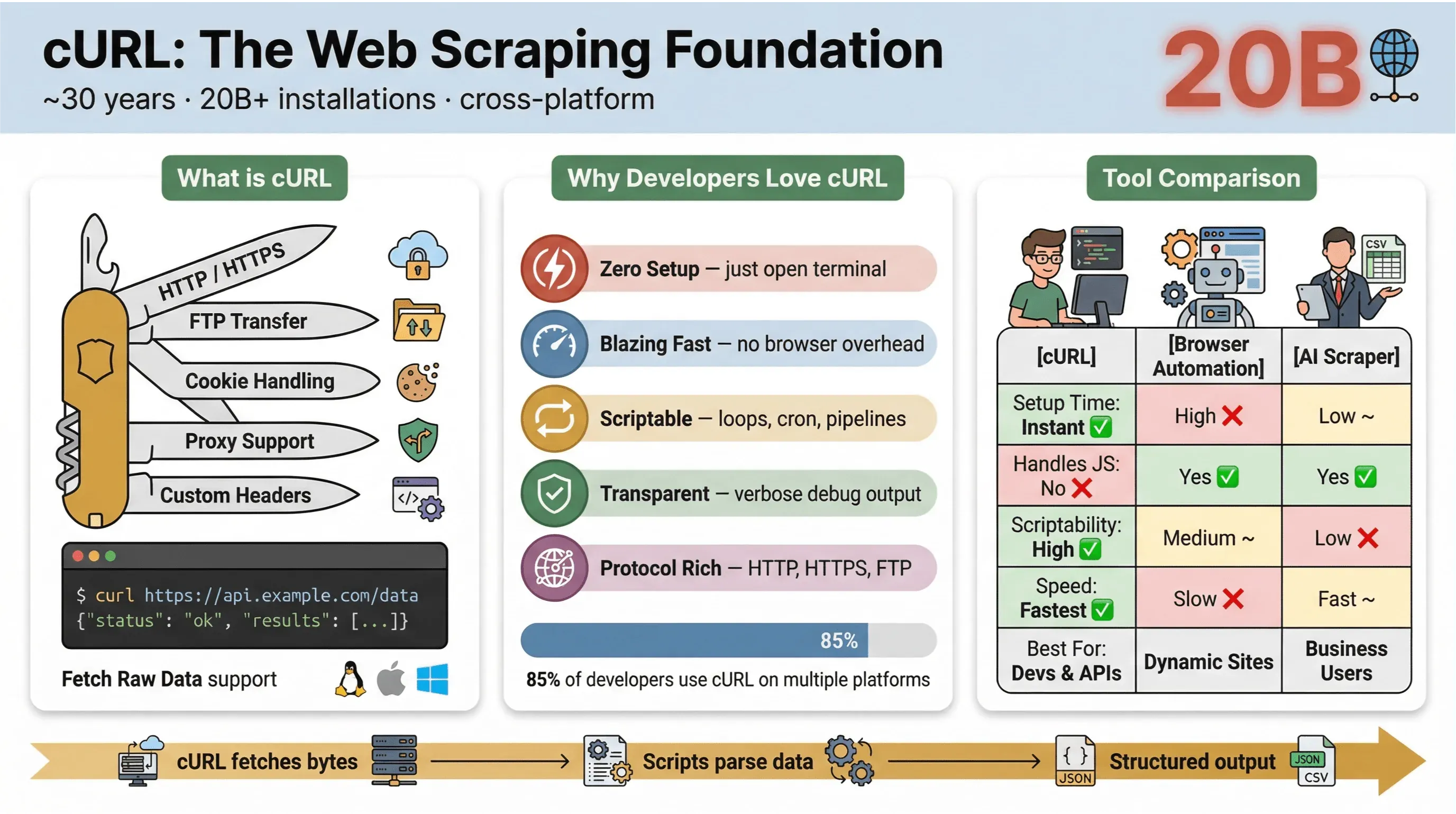 Esto es lo que hace que cURL sea tan popular para el raspado web:
Esto es lo que hace que cURL sea tan popular para el raspado web:
- Ligero y multiplataforma: funciona en Linux, macOS, Windows e incluso en dispositivos embebidos.
- Compatible con protocolos: maneja HTTP, HTTPS, FTP y más.
- Automatizable con scripts: perfecto para automatización, tareas cron y código auxiliar.
- No requiere interacción del usuario: está diseñado para usos no interactivos, ideal para trabajos por lotes y canalizaciones.
Pero seamos claros: la tarea principal de cURL es obtener datos en bruto: HTML, JSON, imágenes, lo que sea. No analiza, renderiza ni estructura esos datos por ti. Piensa en cURL como el “primer tramo” del raspado web: te entrega los bytes, pero necesitarás otras herramientas (como scripts de Python, grep/sed/awk o un raspador web con IA) para convertirlos en información estructurada.
Si quieres ver la documentación oficial, consulta la guía de scripting HTTP de cURL.
¿Por qué usar cURL para el raspado web? (tutorial de raspado web con cURL)
Entonces, ¿por qué desarrolladores y usuarios técnicos siguen volviendo a cURL para el raspado web, incluso con todas las herramientas nuevas que hay? Esto es lo que lo hace destacar:
- Configuración mínima: sin instalaciones ni dependencias; solo abre la terminal y listo.
- Velocidad: obtiene datos al instante, sin esperar a que cargue un navegador.
- Automatización con scripts: recorre URL en bucle, automatiza solicitudes y encadena comandos con facilidad.
- Compatibilidad con protocolos y funciones: gestiona cookies, proxies, redirecciones, encabezados personalizados y más.
- Transparencia: ves exactamente lo que ocurre con la salida detallada o de depuración.
En la encuesta de usuarios de cURL de 2025, el 85,7 % de los encuestados dijo usar la herramienta de línea de comandos cURL, y el 96,2 % informó usarla en Linux, que sigue siendo de lejos la plataforma principal para cURL.
--- Sigue siendo la navaja suiza para solicitudes HTTP, capturas rápidas de datos y resolución de problemas.
Aquí tienes una comparación rápida entre cURL y otros métodos de scraping:
| Función | cURL | Automatización del navegador (p. ej., Selenium) | Raspador Web IA (p. ej., Thunderbit) |
|---|---|---|---|
| Tiempo de configuración | Inmediato | Alto | Bajo |
| Automación con scripts | Alto | Medio | Bajo (no se necesita código) |
| Maneja JavaScript | No | Sí | Sí (Thunderbit: mediante navegador) |
| Compatibilidad con cookies/sesiones | Manual | Automática | Automática |
| Estructuración de datos | Manual (hay que analizar después) | Manual (hay que analizar después) | Basada en IA/plantillas |
| Ideal para | Desarrolladores, capturas rápidas | Sitios complejos y dinámicos | Usuarios de negocio, exportación estructurada |
En resumen: cURL es imbatible para capturas de datos rápidas y automatizables, especialmente en páginas estáticas, APIs o cuando quieres automatizar flujos sencillos. Pero en cuanto necesitas analizar HTML complejo, manejar JavaScript o exportar datos estructurados, querrás algo más especializado.
Empezar: ejemplos básicos de comandos de raspado web con cURL
Vamos a ponernos manos a la obra. Así es como usar cURL para tareas básicas de raspado web, paso a paso.
Obtener HTML en bruto con cURL
El caso de uso más sencillo: recuperar el HTML de una página web.
curl https://books.toscrape.com/
Este comando obtiene la página de inicio de Books to Scrape, un sitio de demostración público para raspado web. Verás la salida HTML en bruto en tu terminal; busca etiquetas como <title> o fragmentos como “In stock”.
Guardar la salida en un archivo
¿Quieres guardar ese HTML para analizarlo más tarde? Usa la opción -o:
curl -o page.html https://books.toscrape.com/
Ahora tendrás un archivo page.html con el contenido HTML completo. Esto es perfecto para hacer análisis posteriores o procesarlo con otras herramientas.
Enviar solicitudes POST con cURL
¿Necesitas enviar un formulario o interactuar con una API? Usa la opción -d para solicitudes POST. Aquí tienes un ejemplo con httpbin, un sitio diseñado para pruebas HTTP:
curl -X POST https://httpbin.org/post -d "key1=value1&key2=value2"
Recibirás una respuesta JSON que refleja los datos enviados, ideal para pruebas y prototipos.
Inspeccionar encabezados y depurar
A veces quieres ver los encabezados de la respuesta o depurar la solicitud:
-
Solo encabezados (solicitud HEAD):
curl -I https://books.toscrape.com/ -
Incluir encabezados con el cuerpo:
curl -i https://httpbin.org/get -
Salida detallada/de depuración:
curl -v https://books.toscrape.com/
Estas opciones te ayudan a entender qué está pasando por debajo, algo esencial para resolver problemas.
Aquí tienes una tabla de referencia rápida para estos comandos:
| Tarea | Ejemplo de comando | Notas |
|---|---|---|
| Obtener HTML | curl URL | Muestra el HTML en la terminal |
| Guardar en archivo | curl -o archivo.html URL | Escribe la salida en un archivo |
| Inspeccionar encabezados | curl -I URL o curl -i URL | -I solo para HEAD, -i incluye encabezados con el cuerpo |
| Enviar datos de formulario | curl -d "a=1&b=2" URL | Envía datos codificados como formulario |
| Depurar solicitud/respuesta | curl -v URL | Muestra información detallada de la solicitud y la respuesta |
Para ver más ejemplos, consulta la documentación oficial de scripting de cURL.
Sube de nivel: raspado web avanzado con cURL (web-scraping-with-curl)
Cuando ya dominas lo básico, cURL abre un mundo de funciones avanzadas para tareas de scraping más complejas.
Gestionar cookies y sesiones
Muchos sitios requieren cookies para mantener sesiones de inicio de sesión o hacer seguimiento de usuarios. Con cURL, puedes guardar y reutilizar cookies entre solicitudes:
# Guardar cookies después de iniciar sesión
curl -c cookies.txt https://example.com/login
# Usar cookies en solicitudes posteriores
curl -b cookies.txt https://example.com/account
Esto te permite imitar sesiones de navegador y acceder a páginas protegidas por inicio de sesión, siempre que no haya un desafío de JavaScript.
Suplantar el User-Agent y encabezados personalizados
Algunos sitios muestran contenido diferente según tu User-Agent u otros encabezados. De forma predeterminada, cURL se identifica como “curl/VERSION”, lo que puede activar bloqueos o contenido alternativo. Para imitar un navegador:
curl -A "Mozilla/5.0 (Windows NT 10.0; Win64; x64)" https://example.com/
También puedes definir encabezados personalizados, como preferencias de idioma:
curl -H "Accept-Language: en-US,en;q=0.9" https://example.com/
Esto te ayuda a obtener el mismo contenido que vería un navegador real.
Usar proxies para el raspado web
¿Necesitas enrutar tus solicitudes a través de un proxy (para pruebas geográficas o para evitar bloqueos de IP)? Usa la opción -x:
curl -x http://proxy.example.org:4321 https://remote.example.org/
Solo asegúrate de usar proxies de forma responsable y dentro de los términos de servicio del sitio.
Automatizar el raspado de varias páginas
¿Quieres extraer varias páginas, como listados de productos paginados? Usa un simple bucle de shell:
for p in $(seq 2 5); do
curl -s -o "books-page-${p}.html" \
"https://books.toscrape.com/catalogue/category/books_1/page-${p}.html"
sleep 1
done
Esto recupera las páginas 2 a 5 del catálogo de Books to Scrape y guarda cada una en un archivo separado. (La página 1 es la página principal.)
Limitaciones del raspado web con cURL: lo que necesitas saber
Por mucho que me guste cURL, no es una solución mágica. Aquí es donde se queda corto:
- No ejecuta JavaScript: cURL no puede manejar páginas que requieren JavaScript para renderizar contenido o superar desafíos antibot (developers.cloudflare.com).
- Requiere análisis manual: obtienes HTML o JSON en bruto, pero tendrás que procesarlo tú mismo, a menudo con scripts o herramientas adicionales.
- Gestión limitada de sesiones: administrar inicios de sesión complejos, tokens o formularios de varios pasos puede volverse un lío rápidamente.
- Sin estructuración de datos integrada: cURL no convierte páginas web en filas, tablas ni hojas de cálculo.
- Vulnerable a la detección antibot: muchos sitios usan ahora defensas avanzadas contra bots (JavaScript, fingerprinting, CAPTCHAs) que cURL simplemente no puede eludir (datadome.co).
Aquí tienes una tabla comparativa rápida:
| Limitación | Solo cURL | Herramientas modernas de scraping (p. ej., Thunderbit) |
|---|---|---|
| Compatibilidad con JavaScript | No | Sí |
| Estructuración de datos | Manual | Automática (IA/plantilla) |
| Gestión de sesiones | Manual | Automática |
| Omitir protección antibot | Limitada | Avanzada (basada en navegador/IA) |
| Facilidad de uso | Técnica | Sin conocimientos técnicos |
Para páginas estáticas y APIs, cURL es fantástico. Para cualquier cosa más dinámica o protegida, tendrás que subir de nivel en la cadena de herramientas.
Thunderbit frente a cURL: la mejor opción de raspado web para usuarios no técnicos
Ahora hablemos de Thunderbit, nuestra extensión de Chrome para raspado web con IA. Si eres comercial, profesional de marketing u operaciones y solo quieres llevar datos de un sitio web a Excel, Google Sheets o Notion, sin tocar la línea de comandos, Thunderbit está hecho para ti.
Así compara Thunderbit con cURL:
| Función | cURL | Thunderbit |
|---|---|---|
| Interfaz de usuario | Línea de comandos | Clic y listo (extensión de Chrome) |
| Sugerencia de campos con IA | No | Sí (la IA lee la página y sugiere columnas) |
| Maneja paginación/subpáginas | Script manual | Automático (la IA lo detecta y lo extrae) |
| Exportación de datos | Manual (analizar + guardar) | Directa a Excel, Google Sheets, Notion, Airtable |
| Páginas con JavaScript/protegidas | No | Sí (scraping basado en navegador) |
| Sin necesidad de código | No (requiere scripts) | Sí (cualquiera puede usarlo) |
| Plan gratuito | Siempre gratis | Gratis hasta 6 páginas (10 con impulso de prueba) |
Con Thunderbit, solo abres la extensión, haces clic en “AI Suggest Fields” y dejas que la IA determine qué datos extraer. Puedes extraer tablas, listas, detalles de productos e incluso visitar subpáginas automáticamente. Luego exportas tus datos directamente a tus herramientas de negocio favoritas, sin análisis manual ni dolores de cabeza.
Thunderbit cuenta con la confianza de más de 100.000 usuarios en todo el mundo, y es especialmente popular entre equipos de ventas, ecommerce e inmobiliario que necesitan datos estructurados con rapidez.
Prueba la extensión de Chrome de Thunderbit para raspado web
¿Quieres probarlo? Descarga aquí la extensión de Chrome.
Combinar cURL y Thunderbit: estrategias flexibles de raspado web
Si eres un usuario técnico, no hace falta elegir solo una herramienta. De hecho, muchos equipos usan cURL y Thunderbit juntos para obtener la máxima flexibilidad:
- Prototipa con cURL: usa cURL para probar rápidamente endpoints, inspeccionar encabezados y entender cómo responde un sitio.
- Escala con Thunderbit: cuando necesites datos estructurados, scraping de varias páginas o un flujo de trabajo repetible, cambia a Thunderbit para extraer con clics y exportar directamente.
Aquí tienes un flujo de trabajo de ejemplo para investigación de mercado:
- Usa cURL para recuperar unas cuantas páginas e inspeccionar la estructura HTML.
- Identifica los campos de datos que quieres (por ejemplo, nombres de productos, precios, reseñas).
- Abre Thunderbit, haz clic en “AI Suggest Fields” y deja que la IA configure el raspador.
- Extrae todas las páginas (incluidas subpáginas o listas paginadas) y exporta a Google Sheets.
- Analiza, comparte y actúa sobre tus datos, sin necesidad de análisis manual.
Aquí tienes una tabla rápida de decisión:
| Escenario | Usar cURL | Usar Thunderbit | Usar ambos |
|---|---|---|---|
| Obtención rápida de una API o página estática | ✅ | ||
| Necesitas datos estructurados en una hoja de cálculo | ✅ | ||
| Depuración de encabezados/cookies | ✅ | ||
| Raspado de páginas dinámicas/con mucho JS | ✅ | ||
| Crear un flujo de trabajo repetible sin código | ✅ | ||
| Prototipar y luego escalar | ✅ | ✅ | Flujo de trabajo híbrido |
Retos y errores comunes en el raspado web con cURL
Antes de lanzarte de lleno con cURL, hablemos de los retos reales a los que te enfrentarás:
- Sistemas antibot: muchos sitios usan ahora defensas avanzadas (desafíos JavaScript, CAPTCHAs, fingerprinting) que cURL no puede eludir (developers.cloudflare.com).
- Problemas de calidad de datos: cambios en el HTML, campos faltantes o diseños inconsistentes pueden romper tus scripts.
- Sobrecarga de mantenimiento: cada vez que un sitio cambia, tendrás que actualizar tu lógica de análisis.
- Riesgos legales y de cumplimiento: comprueba siempre los términos de servicio del sitio, robots.txt y las leyes aplicables antes de extraer datos. Que la información sea pública no significa que puedas usarla libremente (calawyers.org, polsinelli.com).
- Límites de escala: cURL es excelente para trabajos pequeños, pero para scraping a gran escala tendrás que gestionar proxies, límites de velocidad y manejo de errores.
Consejos para depurar y mantener el cumplimiento:
- Empieza siempre con sitios de demostración o con permiso, como Books to Scrape.
- Respeta los límites de velocidad; no satures los endpoints.
- Evita extraer datos personales salvo que tengas una base legal.
- Si te encuentras con barreras de JavaScript o CAPTCHA, considera cambiar a una herramienta basada en navegador como Thunderbit.
Resumen paso a paso: cómo extraer sitios web con cURL
Aquí tienes tu lista de verificación rápida para el raspado web con cURL:
- Identifica la(s) URL de destino: empieza con una página estática o un endpoint de API.
- Obtén la página:
curl URL - Guarda la salida en un archivo:
curl -o file.html URL - Inspecciona encabezados/depura:
curl -I URL,curl -v URL - Envía datos POST:
curl -d "a=1&b=2" URL - Gestiona cookies/sesiones:
curl -c cookies.txt ...,curl -b cookies.txt ... - Define encabezados personalizados/User-Agent:
curl -A "..." -H "..." URL - Sigue redirecciones:
curl -L URL - Usa proxies (si hace falta):
curl -x proxy:port URL - Automatiza el raspado de varias páginas: usa bucles de shell o scripts.
- Analiza y estructura los datos: usa herramientas o scripts adicionales según sea necesario.
- Cambia a Thunderbit para raspado estructurado, sin código o en páginas dinámicas.
Conclusión y conclusiones clave: elegir la herramienta de raspado web adecuada
Extrae datos de cualquier sitio web usando IA Get Started Free
El raspado web con cURL sigue siendo una habilidad muy potente para usuarios técnicos en 2026, especialmente para capturas rápidas de datos, prototipado y automatización. La velocidad, la automatización mediante scripts y la ubicuidad de cURL lo convierten en una pieza básica de la caja de herramientas de cualquier desarrollador. Pero a medida que la web se vuelve más dinámica y más protegida, y los usuarios de negocio exigen datos estructurados sin código, herramientas como Thunderbit están redefiniendo lo que es posible.
Conclusiones clave:
- Usa cURL para páginas estáticas, APIs y prototipos rápidos, especialmente cuando quieras control total.
- Cambia a Thunderbit (o a otros raspadores web con IA similares) cuando necesites datos estructurados, páginas dinámicas o con mucho JavaScript, o un flujo de trabajo sin código y apto para negocio.
- Combina ambos para lograr la máxima flexibilidad: prototipa con cURL y escala y estructura con Thunderbit.
- Extrae datos siempre de forma responsable: respeta los términos del sitio, los límites de velocidad y los límites legales.
¿Tienes curiosidad por ver lo fácil que puede ser el raspado web? Prueba la extensión gratuita de Chrome de Thunderbit y experimenta por ti mismo la extracción de datos con IA. Y si quieres profundizar, visita el blog de Thunderbit para más tutoriales, consejos y análisis del sector. También te puede interesar:
- Cómo extraer cualquier sitio web usando IA
- Cómo extraer datos de un sitio web a Excel usando IA
- Qué es el raspado de datos y cómo hacerlo en 2025
¡Feliz raspado, y que tus datos estén siempre limpios, estructurados y a solo un comando o un clic de distancia!
Explora los planes de Thunderbit para raspado web escalable
Preguntas frecuentes
1. ¿Puede cURL manejar páginas web renderizadas con JavaScript?
No, cURL no puede ejecutar JavaScript. Obtiene el HTML en bruto tal como lo entrega el servidor. Si una página requiere JavaScript para renderizar contenido o superar desafíos antibot, cURL no podrá acceder a los datos. En esos casos, usa herramientas basadas en navegador como Thunderbit.
2. ¿Cómo guardo la salida de cURL directamente en un archivo?
Usa la opción -o: curl -o filename.html URL. Esto escribe el cuerpo de la respuesta en un archivo en lugar de mostrarlo en la terminal.
3. ¿Cuál es la diferencia entre cURL y Thunderbit para el raspado web?
cURL es una herramienta de línea de comandos para obtener datos web en bruto, ideal para usuarios técnicos y automatización. Thunderbit es una extensión de Chrome impulsada por IA, diseñada para usuarios de negocio que quieren extraer datos estructurados de cualquier sitio web, gestionar páginas dinámicas y exportar directamente a herramientas como Excel o Google Sheets, sin necesidad de código.
4. ¿Es legal extraer sitios web con cURL?
Extraer datos públicos suele ser legal en EE. UU. según sentencias recientes, pero siempre revisa los términos de servicio del sitio, robots.txt y la legislación aplicable. Evita extraer datos personales o protegidos sin permiso y respeta los límites de velocidad y las pautas éticas (calawyers.org, polsinelli.com).
5. ¿Cuándo debería pasar de cURL a una herramienta más avanzada como Thunderbit?
Si necesitas extraer páginas dinámicas o con mucho JavaScript, quieres datos estructurados en una hoja de cálculo o prefieres un flujo de trabajo sin código, Thunderbit es la mejor opción. Usa cURL para tareas rápidas y técnicas; usa Thunderbit para una extracción de datos repetible y apta para negocio.
Para más consejos y tutoriales sobre raspado web, visita el blog de Thunderbit o consulta nuestro canal de YouTube.
Prueba el Raspador Web IA de Thunderbit Get Started Free




