
Seamos sinceros: si alguna vez has intentado hacerte con datos empresariales, seguro que te has topado con el debate de “web scraping vs. data mining”. He visto a equipos dar vueltas sin parar: uno quiere sacar toda la información posible de la web, el otro quiere analizarla para obtener insights profundos, y a veces ambos acaban mirando una hoja de cálculo y preguntándose: “Espera, ¿qué estamos haciendo exactamente aquí?”. Si te suena, no estás solo.
Como alguien que ha pasado años creando SaaS y herramientas de automatización —y ahora cofundador de —, he visto esta confusión por todas partes, desde equipos de ventas hasta salas de juntas. Así que vayamos al grano: ¿cuál es la verdadera diferencia entre el web scraping y el data mining, quién usa cada uno y, sobre todo, cómo puedes hacer que trabajen juntos para generar resultados para tu equipo?
Web Scraping vs. Data Mining: definiciones rápidas para equipos ocupados
Empecemos por lo sencillo, sin necesidad de abrir un diccionario técnico.
- Web Scraping: es el proceso de recopilar datos de sitios web; piensa en ello como una forma automatizada de copiar y pegar información de la web en una hoja de cálculo. Las herramientas de web scraping rastrean páginas web, extraen información concreta (como precios de productos, nombres de empresas o artículos) y la organizan en un formato estructurado (filas y columnas). En esta fase no se analiza nada: todo se centra en obtener los datos en bruto que necesitas.
- Data Mining: aquí es donde empieza el valor real una vez que ya tienes los datos. Data mining significa analizar conjuntos de datos —usando estadísticas, algoritmos o IA— para descubrir tendencias, patrones e insights. Es como coger esa hoja de cálculo gigante y averiguar qué significa: segmentar clientes, prever ventas o detectar fraude.
La analogía que siempre uso:
El web scraping es ir a comprar ingredientes; el data mining es cocinarlos para convertirlos en una comida. Necesitas ambos si quieres que la cena sea algo más que un montón de compras.
¿Quién usa el web scraping y el data mining, y por qué?
Aquí es donde la cosa se pone interesante. La diferencia no es solo “recopilar vs. analizar”: también tiene que ver con quién hace qué y por qué.
¿Quién usa el web scraping?
Usuarios típicos:
- Equipos de ventas (crear listas de leads, obtener información de contacto)
- Equipos de marketing (inteligencia de mercado, seguimiento de la competencia)
- Operaciones (seguimiento de precios, insights sobre la cadena de suministro)
- Equipos de investigación (inmobiliario, finanzas, etc.)
Su objetivo:
Conseguir datos nuevos y externos, rápido. Ya sea extraer miles de precios de productos, hacer scraping de LinkedIn para encontrar leads o vigilar lanzamientos de la competencia, estas personas necesitan información actualizada para tomar decisiones del día a día (, ).
¿Quién usa el data mining?
Usuarios típicos:
- Analistas de datos y equipos de business intelligence (BI)
- Científicos de datos
- Product managers y equipos de estrategia
Su objetivo:
Encontrar significado en los datos. Estas personas toman la información en bruto —ya sea extraída de la web o sacada de sistemas internos— y buscan patrones, tendencias e insights accionables. Les importa menos cómo se recopilaron los datos y más qué pueden decirles ().
Tabla de escenarios: ¿quién hace qué?
| Rol | Ejemplo de web scraping | Ejemplo de data mining |
|---|---|---|
| Ventas | Hacer scraping de directorios empresariales para obtener leads | Analizar qué leads convierten mejor |
| Marketing | Hacer scraping de lanzamientos de productos de la competencia | Segmentar clientes por comportamiento de compra |
| Operaciones | Hacer scraping de precios de proveedores a diario | Prever la demanda y optimizar inventario |
| BI/Ciencia de datos | (Por lo general no hacen scraping ellos mismos) | Crear modelos predictivos, encontrar tendencias |
| Gestión de producto | Hacer scraping de reseñas de app stores para obtener feedback | Identificar carencias de funciones y priorizar la hoja de ruta |
Web Scraping: convertir sitios web en datos listos para el negocio
Seamos realistas: internet es una mina de oro de datos empresariales, pero la mayor parte está atrapada en páginas web desordenadas y sin estructura. El web scraping es la llave que te permite desbloquear esos datos y convertirlos en algo que tu equipo pueda usar de verdad.
Por qué importa el web scraping (especialmente para equipos no técnicos)
- Ahorra tiempo: se acabaron los becarios copiando y pegando durante días. Un scraper puede extraer miles de puntos de datos en minutos.
- Escala: ¿quieres supervisar 50 sitios de la competencia cada día? El scraping lo hace posible.
- Te mantiene al día: obtén actualizaciones en tiempo real sobre precios, inventario o noticias, sin esfuerzo manual.
La foto general es clara: el sitúa el mercado de web scraping en 1,17 mil millones de USD en 2026, con una proyección de 2,23 mil millones de USD para 2031. Y, según una encuesta de BrowserCat de 2024 citada en ese informe, el 65 % de las empresas ya utilizaban web scraping para alimentar proyectos de IA y machine learning, que es precisamente la parte del flujo de trabajo que está impulsando la adopción fuera de TI y dentro de los equipos de ventas, marketing y operaciones.
Casos de uso prácticos
- Generación de leads: hacer scraping de directorios públicos o redes sociales para obtener nombres, correos electrónicos y números de teléfono.
- Seguimiento de precios: monitorizar precios de la competencia o la disponibilidad de productos en tiempo real. La adopción ya se ha generalizado: informa de que el 81 % de los minoristas de EE. UU. ya usa scraping automatizado de precios para la fijación dinámica, frente al 34 % en 2020 (encuesta original de Actowiz Solutions).
- Investigación de mercado: agrupar reseñas online, hacer scraping de redes sociales para analizar el sentimiento o vigilar sitios de noticias en busca de tendencias.
- Enriquecimiento de datos: ampliar tu CRM con información nueva de sitios web de empresas o de LinkedIn.
- Inmobiliario y finanzas: hacer scraping de anuncios de propiedades, noticias financieras o datos alternativos para investigación de inversiones ().
Y aquí está el punto clave: ya no necesitas ser programador. Cada vez más herramientas de scraping nuevas —Octoparse, Browse AI, Bardeen, Thunderbit— vienen con configuración de arrastrar y soltar o de apuntar y hacer clic como opción predeterminada, no como un modo secundario para desarrolladores. Eso, por sí solo, ha sacado el scraping de la cola de trabajo de ingeniería y lo ha llevado a los escritorios de ventas y operaciones.
Cómo Thunderbit simplifica el web scraping para todos
Lo admito: cuando empezamos a construir , nuestro objetivo era simple: hacer que el web scraping fuera tan fácil como pedirle a un becario que copie y pegue datos, salvo que el “becario” es un agente de IA que no duerme, no se queja y nunca se distrae con vídeos de gatos.
Así es como Thunderbit conecta la recopilación de datos con el análisis de negocio:
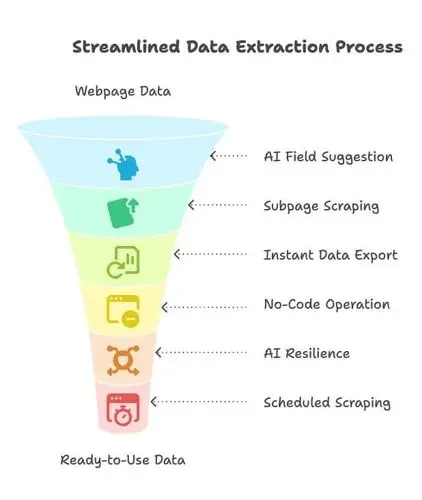
- Sugerir campos con IA: solo tienes que hacer clic en “AI Suggest Fields” y la IA de Thunderbit escanea la página, recomienda qué campos de datos extraer y propone nombres de columnas. Se acabó pelearte con HTML o selectores: solo elige lo que necesitas ().
- Scraping de subpáginas: ¿necesitas más detalles de subpáginas, como fichas de producto o descripciones de empleo? Thunderbit puede hacer clic automáticamente, recopilar la información extra y añadirla a tu conjunto de datos.
- Exportación instantánea de datos: exporta con un clic a Excel, Google Sheets, Airtable, Notion o CSV/JSON. Sin cargos ocultos, sin pasos innecesarios: tus datos quedan listos al instante.
- Sin código, con apuntar y hacer clic: Thunderbit vive en tu navegador. Selecciona lo que quieres y listo. Incluso si nunca has hecho scraping, estarás en marcha en minutos.
- Resiliencia impulsada por IA: los sitios web cambian todo el tiempo, pero la IA de Thunderbit se adapta automáticamente a muchos cambios de diseño. Menos mantenimiento, menos frustración.
- Scraping programado y AI Autofill: programa extracciones para que se ejecuten de forma periódica o deja que la IA rellene formularios e inicios de sesión por ti. Thunderbit incluso gestiona PDFs, imágenes, correos electrónicos y números de teléfono con un solo clic.
¿El resultado? Thunderbit reduce la brecha de habilidades. Ahora, operaciones de ventas, marketing o incluso tu director general pueden configurar un scraping sin llamar a TI. Es la “capa intermedia” que conecta datos web desordenados con las herramientas que realmente usas para analizar.
¿Quieres verlo en acción? Echa un vistazo a nuestra o profundiza en más casos de uso en el .
Data Mining: descubrir insights a partir de los datos que has recopilado
Bien, ya has extraído una montaña de datos. ¿Y ahora qué? Aquí es donde entra el data mining.
¿Qué es el data mining? (en lenguaje llano)
El data mining es el proceso de analizar grandes conjuntos de datos para encontrar patrones ocultos, correlaciones o anomalías que puedan aportar información para el negocio. Se trata de convertir números en bruto en conocimiento accionable: por ejemplo, descubrir que los clientes que compran el producto A también suelen comprar el producto B, o que ciertos comportamientos indican un alto riesgo de abandono.
Objetivos empresariales habituales
- Descubrimiento de tendencias y previsión: detectar tendencias de ventas, estacionalidad o cambios de mercado y predecir lo que vendrá después.
- Segmentación de clientes: agrupar clientes según su comportamiento o datos demográficos para campañas de marketing más precisas.
- Detección de anomalías: encontrar valores atípicos que puedan indicar fraude, riesgo u oportunidades nuevas.
- Insights estratégicos: combinar varios conjuntos de datos (internos + extraídos) para tomar grandes decisiones, como entrar en un nuevo mercado o ajustar precios.
Aquí está el inconveniente: el data mining solo es tan bueno como los datos que le das. El viejo dicho “si entra basura, sale basura” es dolorosamente cierto. De hecho, los analistas suelen dedicar hasta solo a limpiar y preparar datos antes de poder analizarlos de verdad.
Por eso el web scraping estructurado —como el que genera Thunderbit— es tan valioso: te entrega un conjunto de datos limpio y listo para analizar, para que tus analistas vayan directos a lo importante.
Web Scraping vs. Data Mining: comparación lado a lado
Pongámoslos frente a frente para que veas exactamente en qué se diferencian y dónde se solapan.
| Aspecto | Web Scraping | Data Mining |
|---|---|---|
| Propósito principal | Recopilar datos en bruto de sitios web (extracción de datos) | Analizar conjuntos de datos para descubrir patrones e insights (análisis de datos) |
| Usuarios típicos | Ventas, marketing, operaciones, investigación (a menudo no técnicos, expertos de dominio) | Analistas de datos, equipos BI, científicos de datos, responsables de estrategia (roles analíticos/técnicos) |
| Fuentes de datos | Páginas web, fuentes online, directorios públicos, APIs | Conjuntos de datos estructurados: datos extraídos, bases de datos internas, CSV, data warehouses |
| Proceso y herramientas | Rastreo, extracción (herramientas sin código como Thunderbit, extensiones de navegador) | Análisis de datos (herramientas BI, Python/R, SQL, plataformas de machine learning) |
| Resultado | Conjunto de datos estructurado (CSV, hoja de cálculo, tabla de base de datos) | Insights, informes, paneles, modelos predictivos |
| Casos de uso de ejemplo | Compilar precios de la competencia, hacer scraping de menciones sociales, extraer listados | Segmentar clientes, predecir abandono, puntuar leads |
| Retos principales | Cambios en sitios web, defensas anti-scraping, calidad de datos, aspectos legales/éticos | Datos sucios o incompletos, elegir los modelos adecuados, privacidad, interpretación de resultados |
Conclusión clave:
El web scraping es el “combustible” (los datos), y el data mining es el “motor” (el insight). Necesitas ambos para llegar a cualquier sitio.
Cómo trabajan juntos el web scraping y el data mining en el negocio
Aquí es donde ocurre la verdadera magia: el web scraping y el data mining no compiten, sino que son compañeros de equipo. Piensa en ellos como la parte aguas arriba y aguas abajo de tu flujo de datos.
Escenario 1: inteligencia de mercado
- Paso 1: hacer scraping de listados de productos, precios y reseñas de la competencia en varios sitios.
- Paso 2: minar los datos para encontrar tendencias: detectar huecos en el mercado, identificar quejas frecuentes de los clientes o seguir la evolución de los precios con el tiempo.
- Resultado: obtienes insights accionables para orientar la estrategia de producto o los precios.
Escenario 2: puntuación de leads de ventas
- Paso 1: hacer scraping de LinkedIn o de directorios empresariales para enriquecer tu base de leads con tamaño de empresa, sector y noticias recientes.
- Paso 2: analizar qué atributos se correlacionan con tasas de conversión altas y priorizar los leads en consecuencia.
- Resultado: tu equipo de ventas se centra en los prospectos con mejor encaje, no solo en la lista más grande.
Escenario 3: optimización de precios
- Paso 1: hacer scraping de precios e inventario de la competencia en tiempo real.
- Paso 2: introducir esos datos en tus algoritmos de precios para ajustar los tuyos de forma dinámica.
- Resultado: te mantienes competitivo y maximizas los ingresos.
¿El riesgo de tratarlos como actividades aisladas?
Si solo haces scraping y nunca analizas, te ahogas en datos pero te mueres de hambre de insights. Si solo analizas datos internos, te falta el contexto del mercado más amplio. Los mejores equipos usan ambos: scraping para obtener un conjunto de datos completo y data mining para extraer insights significativos ().
Cómo superar los retos comunes del web scraping y el data mining
Seamos sinceros: tanto el web scraping como el data mining traen sus propios quebraderos de cabeza. Aquí te explico cómo afrontar los más importantes y cómo ayuda Thunderbit:
1. Calidad y limpieza de datos
- Problema: los datos extraídos pueden venir sucios: campos faltantes, formatos incoherentes, duplicados.
- Solución: usa herramientas que permitan limpiar durante la extracción. Thunderbit puede formatear y categorizar datos sobre la marcha con IA, para que el resultado quede listo para analizar (). Comprueba siempre una muestra de tus datos antes de lanzarte al análisis.
2. Cambios en sitios web y medidas anti-scraping
- Problema: los sitios cambian de diseño, añaden CAPTCHAs o bloquean bots.
- Solución: usa scrapers impulsados por IA como Thunderbit, que se adaptan automáticamente a los cambios de diseño. Respeta
robots.txt, evita sobrecargar los sitios y considera usar proxies si hace falta ().
3. Aspectos legales y éticos
- Problema: hacer scraping de datos públicos suele ser legal, pero las leyes de privacidad y las condiciones de uso importan.
- Solución: revisa siempre los términos del sitio, céntrate en datos públicos, anonimiza cuando sea posible y cumple con el RGPD/CCPA. Sé un “ciudadano ético de los datos”; tu reputación vale más que cualquier conjunto de datos ().
4. De los datos a insights accionables
- Problema: los equipos recopilan datos pero les cuesta convertirlos en decisiones.
- Solución: empieza con preguntas de negocio claras, utiliza visualización e involucra a expertos del dominio al interpretar los resultados. Integra los insights en los flujos de trabajo (por ejemplo, marcando clientes en riesgo en tu CRM).
5. Herramientas y brecha de habilidades
- Problema: no todos los equipos tienen programadores o científicos de datos.
- Solución: aprovecha herramientas sin código y fáciles de usar como Thunderbit para el scraping, y plataformas BI modernas para el mining. Invierte en formación básica en alfabetización de datos: a veces una simple tabla dinámica es todo lo que necesitas.
Cómo elegir el enfoque adecuado: ¿web scraping, data mining o ambos?
Entonces, ¿cómo decides qué necesitas? Aquí tienes una guía rápida:
- ¿Tienes los datos que necesitas?
- No: empieza con web scraping para recopilarlos.
- Sí: pasa al data mining para extraer insights.
- ¿Tus preguntas son sobre el mundo externo o sobre patrones internos?
- Externas (competidores, mercado, leads): web scraping.
- Internas (comportamiento de clientes, tendencias de ventas): data mining.
- ¿Necesitas ambos?
- ¡La mayoría de los proyectos reales sí! Haz scraping de datos externos y luego analízalos —junto con tus datos internos— para tener la visión completa.
- Capacidades del equipo:
- ¿Sin conocimientos de programación? Usa herramientas de scraping sin código como Thunderbit.
- ¿Sin científicos de datos? Usa herramientas BI fáciles de usar o empieza con análisis básicos.
- Sensibilidad al tiempo:
- ¿Necesitas tiempo real? Configura scraping y análisis continuos.
- ¿Proyecto puntual? Haz un scraping único y luego analízalo.
Lista de verificación:
- “¿Tengo internamente todos los datos que necesito?” Si no, haz scraping.
- “¿Entiendo los datos que ya tengo?” Si no, analízalos.
- “¿El problema es lo bastante grande como para combinar enfoques?” Si sí, haz ambos.
- “¿Mi equipo tiene las habilidades necesarias?” Si no, usa herramientas sin código o busca ayuda.
Y recuerda: no tienes que hacerlo todo de una vez. Empieza pequeño, haz una prueba piloto y escala a medida que veas resultados.
Conclusiones clave: cómo hacer que los datos trabajen para tu equipo
Recapitulemos lo esencial:
- El web scraping y el data mining son dos pasos de un mismo viaje. El scraping recopila los datos —especialmente de fuentes externas— y el mining los analiza para obtener insights.
- Distintos roles, distintos objetivos: ventas, marketing y operaciones usan el scraping para obtener datos; analistas y equipos BI los minan para encontrar significado.
- Son complementarios, no competidores: los mejores resultados llegan cuando combinas ambos: scraping para conseguir un conjunto de datos rico y mining para obtener insights accionables.
- Las herramientas sin código y la IA han bajado la barrera: Thunderbit y herramientas similares hacen que el scraping sea accesible para todos. Las plataformas BI modernas también facilitan el mining.
- La calidad de los datos y la ética importan: limpia tus datos, respeta la privacidad y actúa siempre con ética.
- Deja que tu caso de uso guíe el enfoque: empieza con la pregunta de negocio y luego decide qué datos necesitas y cómo analizarlos.
- Empieza pequeño y luego escala: usa planes gratuitos, proyectos piloto y victorias rápidas para generar impulso.
Al final del día, el objetivo es capacitar a tu equipo para tomar mejores decisiones con datos. Quizá eso signifique que tu equipo de ventas dedique menos tiempo a la investigación manual (gracias al scraping), o que tus reuniones de estrategia estén impulsadas por insights reales (gracias al mining). En cualquier caso, combinar ambos enfoques es la forma en que los equipos modernos ganan ventaja competitiva.
Así que recopila esos ingredientes de datos web, cocina algunos insights y sirve a tu equipo la inteligencia accionable que necesita. Y si necesitas ayuda en la cocina, está aquí para facilitarte la preparación.
¿Te apetece probarlo? Descarga la y comprueba lo fácil que puede ser el web scraping. Para más consejos e historias desde la primera línea de los datos, visita el .
Preguntas frecuentes
1. ¿Cuál es la principal diferencia entre el web scraping y el data mining?
El web scraping es el proceso de recopilar datos en bruto de sitios web, mientras que el data mining consiste en analizar esos datos para descubrir patrones, insights o tendencias. Piensa en el scraping como reunir ingredientes y en el mining como cocinar la comida.
2. ¿Quién suele usar el web scraping frente al data mining?
El web scraping lo usan sobre todo equipos de ventas, marketing, operaciones e investigación que necesitan datos externos nuevos con rapidez. El data mining lo usan analistas, científicos de datos y equipos de producto que buscan obtener insights estratégicos a partir de los datos.
3. ¿Necesito saber programar para hacer web scraping?
Ya no. Herramientas como ofrecen interfaces sin código impulsadas por IA que permiten a cualquiera —sin importar su formación técnica— extraer datos con acciones de apuntar y hacer clic y funciones de exportación instantánea.
4. ¿Cómo trabajan juntos el web scraping y el data mining?
El web scraping proporciona los datos brutos y estructurados de los que depende el data mining. Juntos crean una canalización: recopilas datos externos con scraping y luego los analizas con mining para orientar las decisiones de negocio.
5. ¿Cuáles son algunos casos de uso reales de cada uno?
El web scraping se usa para tareas como la generación de leads, el seguimiento de precios y la supervisión de la competencia. El data mining apoya la segmentación de clientes, la previsión de tendencias, la detección de fraude y la planificación estratégica basada en los datos extraídos.