“Puedes tener datos sin información, pero no puedes tener información sin datos.” — *
Las estimaciones recientes sugieren que hay más de de sitios web en internet, con alrededor de 2 millones de nuevas publicaciones cada día. Este océano de datos esconde información valiosa para tomar decisiones, pero hay un problema: cerca del no está estructurado, así que necesita un procesamiento extra para resultar útil. Ahí es donde entran las herramientas de web scraping, que se vuelven esenciales para cualquiera que quiera aprovechar los datos en línea.
Si eres nuevo en el web scraping, términos como y pueden sonar un poco intimidantes. Pero, en la era de la IA, estos retos son mucho más fáciles de superar. Las herramientas de scraping impulsadas por IA de hoy en día te ayudan a empezar sin necesidad de conocimientos técnicos profundos. Permiten recopilar y procesar datos rápidamente, sin necesidad de saber programar.
Las mejores herramientas y software de web scraping
- para un raspador web IA fácil de usar y con los mejores resultados
- para monitorización en tiempo real y extracción masiva de datos
- para automatización sin código con amplias integraciones de apps
- para un web scraping visual más profesional
- para un potente scraping sin código que evita el bloqueo de IP y la detección de bots
- para una API avanzada de extracción de datos con IA y grafos de conocimiento
Prueba la IA para hacer web scraping
¡Pruébalo! Puedes hacer clic, explorar y ejecutar el flujo de trabajo mientras lo ves.
¿Cómo funciona el web scraping?
El web scraping consiste, básicamente, en extraer datos de sitios web. Le das a una herramienta un conjunto de instrucciones y esta se encarga de extraer texto, imágenes o lo que necesites de una página web para llevarlo a una tabla. Esto resulta útil para todo, desde seguir precios en sitios de comercio electrónico hasta recopilar datos de investigación o incluso simplemente montar una buena hoja de cálculo de Excel o Google Sheets.
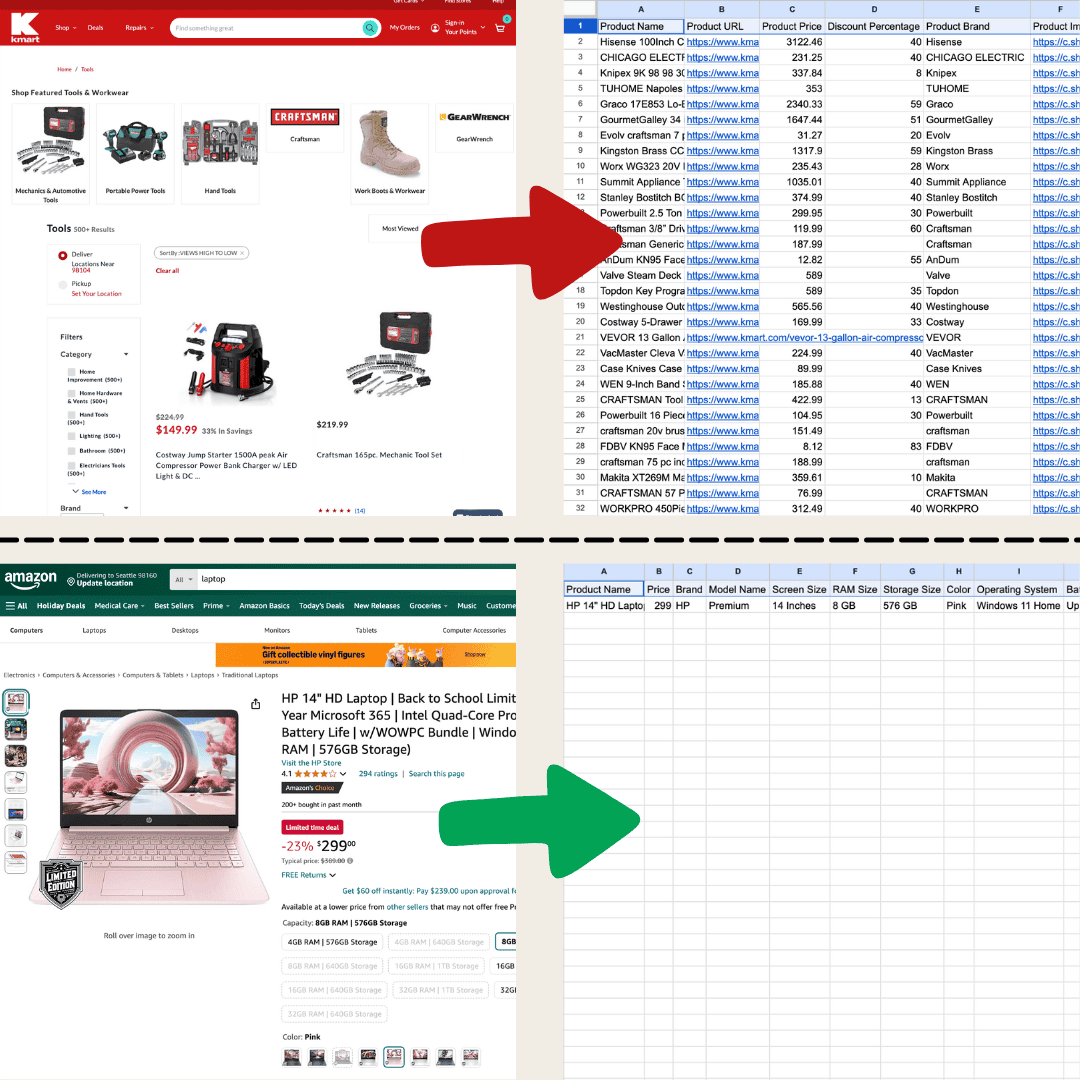 Hice esto con Thunderbit usando el Raspador Web IA.
Hice esto con Thunderbit usando el Raspador Web IA.
Hay varias formas de hacerlo. En el nivel más básico, podrías copiar y pegar todo manualmente, pero eso da muchísimo trabajo si hay muchos datos. Por eso, la mayoría de la gente usa uno de estos tres métodos: raspadores web tradicionales, raspadores web IA o código personalizado.
Los raspadores web tradicionales funcionan definiendo reglas concretas sobre qué datos extraer según la estructura de la página. Por ejemplo, puedes configurarlos para capturar nombres de productos o precios a partir de ciertas etiquetas HTML. Funcionan mejor en sitios que no cambian demasiado, porque cualquier ajuste en el diseño obliga a volver y modificar el raspador.
 Usar un raspador tradicional lleva bastante tiempo de aprendizaje y probablemente te costará decenas de clics completar la configuración.
Usar un raspador tradicional lleva bastante tiempo de aprendizaje y probablemente te costará decenas de clics completar la configuración.
Los raspadores web IA vienen a significar, básicamente, que ChatGPT lee todo el sitio web y luego extrae el contenido según lo que necesites. Puede encargarse de la extracción de datos, la traducción y el resumen al mismo tiempo. Usan procesamiento de lenguaje natural para analizar y entender la estructura del sitio, lo que les permite adaptarse mejor a los cambios. Si el sitio reorganiza un poco sus secciones, un raspador web IA podría ajustarse sin que tengas que reescribir nada. Por eso son ideales para sitios que cambian con frecuencia o tienen estructuras más complejas.
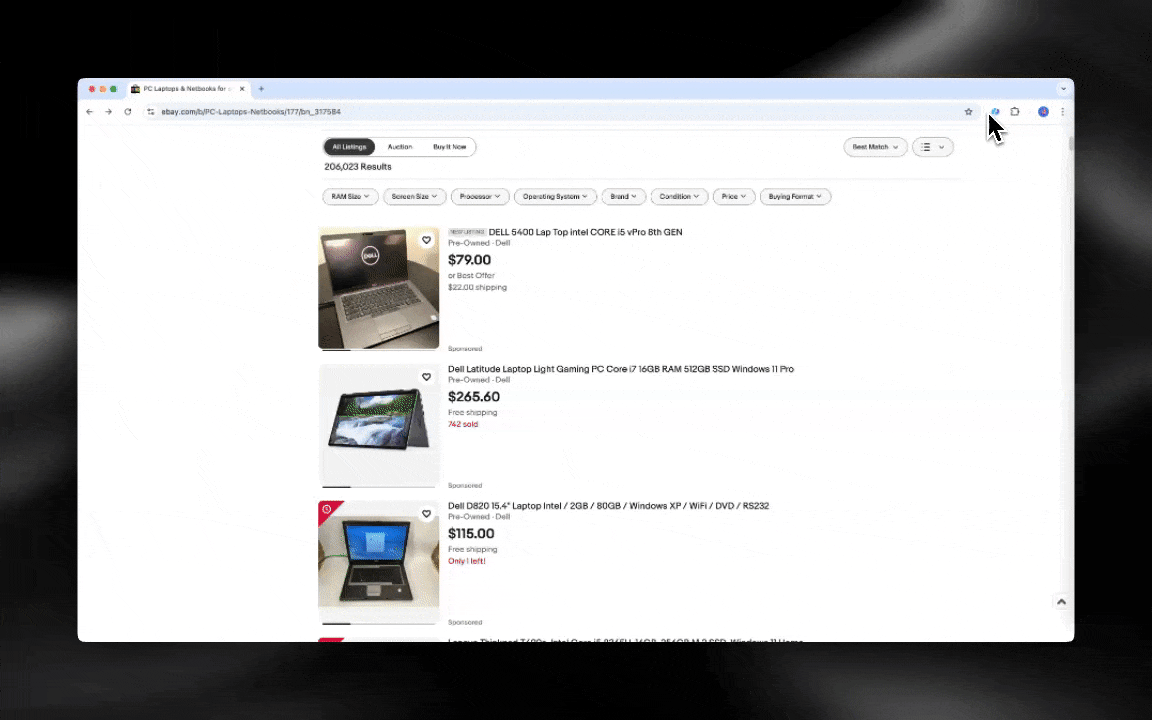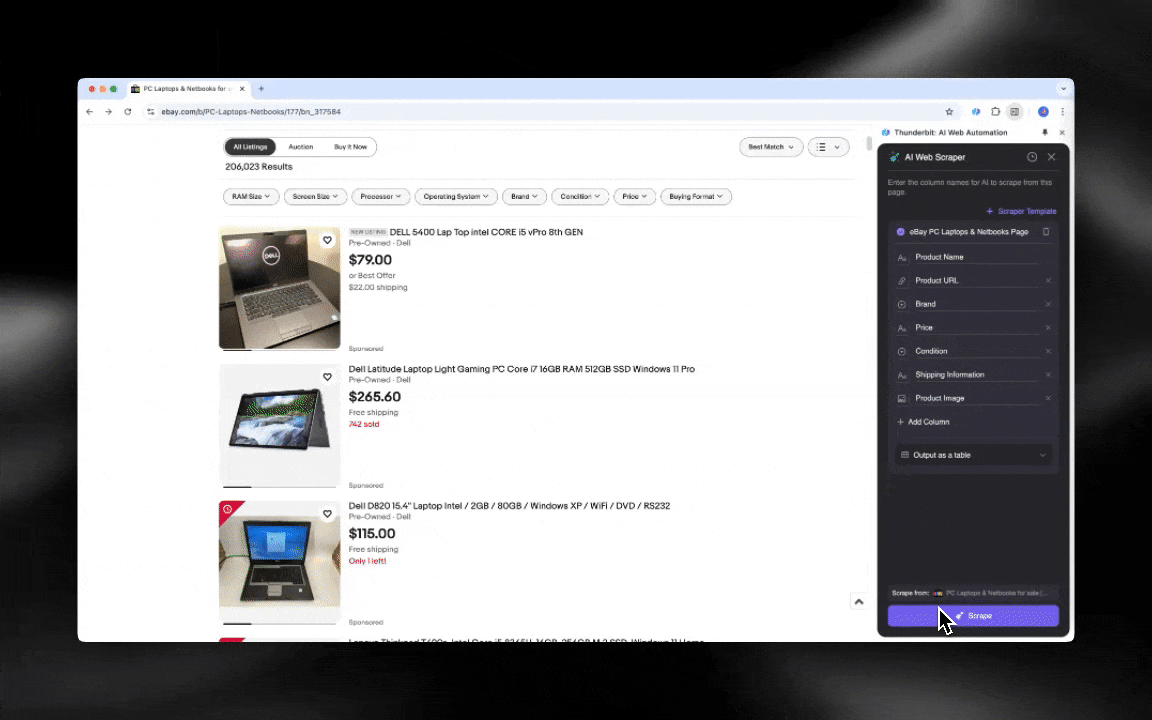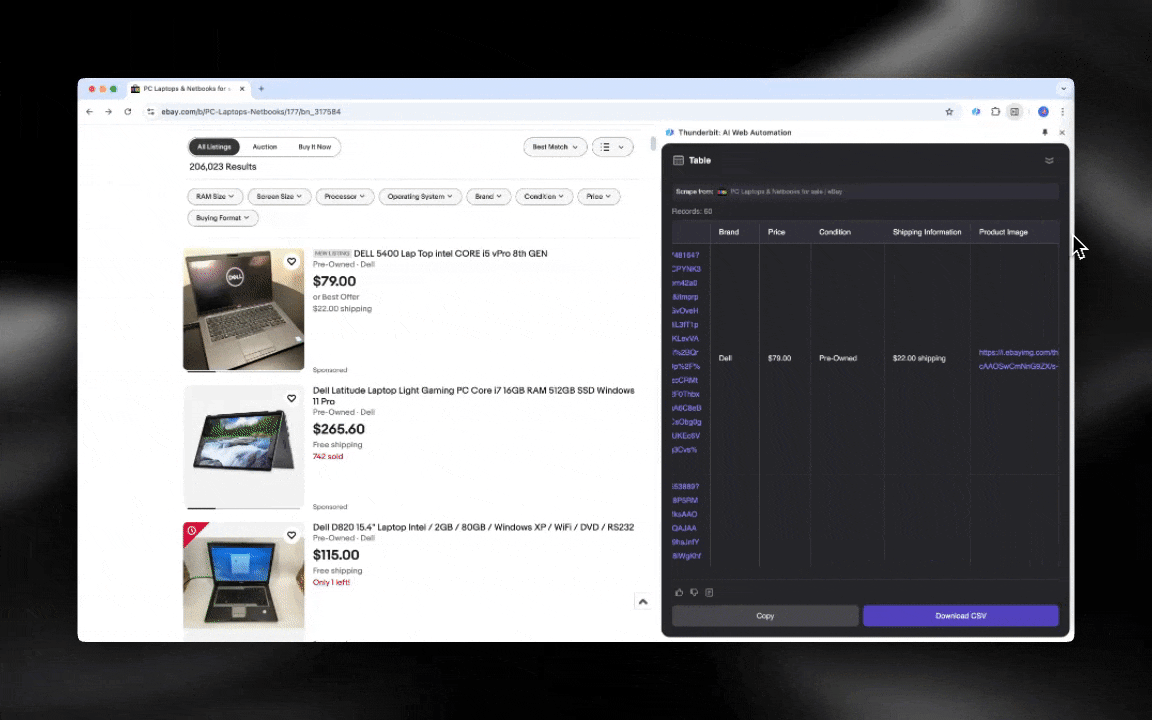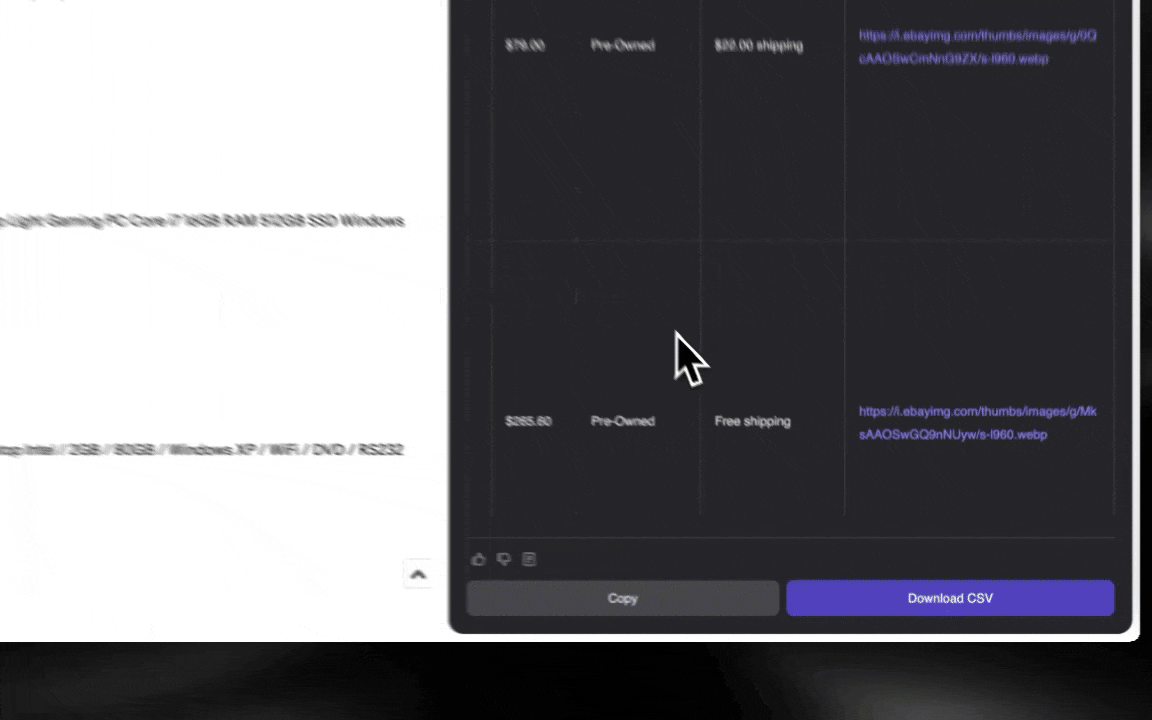 ¡El Raspador Web IA es fácil de empezar a usar y te ofrece datos detallados en solo unos clics!
¡El Raspador Web IA es fácil de empezar a usar y te ofrece datos detallados en solo unos clics!
¿Cuál deberías elegir? Depende. Si te sientes cómodo tocando código o necesitas recopilar grandes volúmenes de datos en un sitio popular, los raspadores tradicionales pueden ser muy eficientes. Pero si eres nuevo en el web scraping o quieres algo que se adapte a las actualizaciones del sitio, los raspadores web IA suelen ser la mejor opción. ¡Consulta la tabla de abajo para ver escenarios más detallados!
| Escenario | Mejor opción |
|---|---|
| Scraping ligero en páginas como directorios, tiendas en línea o cualquier sitio con listados | Raspador Web IA |
| La página tiene menos de 200 filas de datos y crear un raspador con uno tradicional lleva demasiado tiempo | Raspador Web IA |
| Los datos que necesitas extraer deben tener un formato concreto para subirlos a otro sitio. Por ejemplo: extraer información de contacto para subirla a HubSpot. | Raspador Web IA |
| Sitios de uso masivo, como decenas de miles de páginas de productos de Amazon o listados inmobiliarios de Zillow. | Raspador Web tradicional |
Las mejores herramientas y software de web scraping de un vistazo
| Herramienta | Precio | Funciones clave | Ventajas | Desventajas |
|---|---|---|---|---|
| Thunderbit | Desde 9 $/mes, con plan gratuito disponible | Raspador web IA, detecta y formatea datos automáticamente, admite varios formatos, exportación con un clic, interfaz fácil de usar. | Sin código, compatibilidad con IA, integraciones con apps como Google Sheets | El scraping a gran escala puede ser lento, y las funciones avanzadas pueden costar más |
| Browse AI | Desde 48,75 $/mes, con plan gratuito disponible | Interfaz sin código, monitorización en tiempo real, extracción masiva de datos, integración de flujos de trabajo. | Fácil de usar, se integra con Google Sheets y Zapier | Las páginas complejas necesitan configuración extra, el scraping masivo puede provocar tiempos de espera |
| Bardeen AI | Desde 60 $/mes, con plan gratuito disponible | Automatización sin código, se integra con más de 130 apps, MagicBox convierte tareas en flujos de trabajo. | Amplias integraciones, escalable para empresas | Curva de aprendizaje pronunciada para nuevos usuarios, configuración que lleva tiempo |
| Web Scraper | Gratis para uso local, 50 $/mes para la nube | Creación visual de tareas, admite sitios dinámicos (AJAX/JavaScript), scraping en la nube. | Funciona muy bien en sitios dinámicos | Requiere conocimientos técnicos para una configuración óptima |
| Octoparse | Desde 119 $/mes, con plan gratuito disponible | Scraping sin código, detección automática de elementos de la página, scraping en la nube con tareas programadas, biblioteca de plantillas para sitios comunes. | Funciones potentes para sitios dinámicos, gestiona restricciones | Los sitios complejos requieren aprendizaje |
| Diffbot | Desde 299 $/mes | API de extracción de datos, API sin reglas, NLP para texto no estructurado, amplio grafo de conocimiento. | Potente extracción con IA, amplia integración por API, scraping a gran escala | Curva de aprendizaje para usuarios no técnicos, tiempo de configuración |
El mejor raspador web en la era de la IA
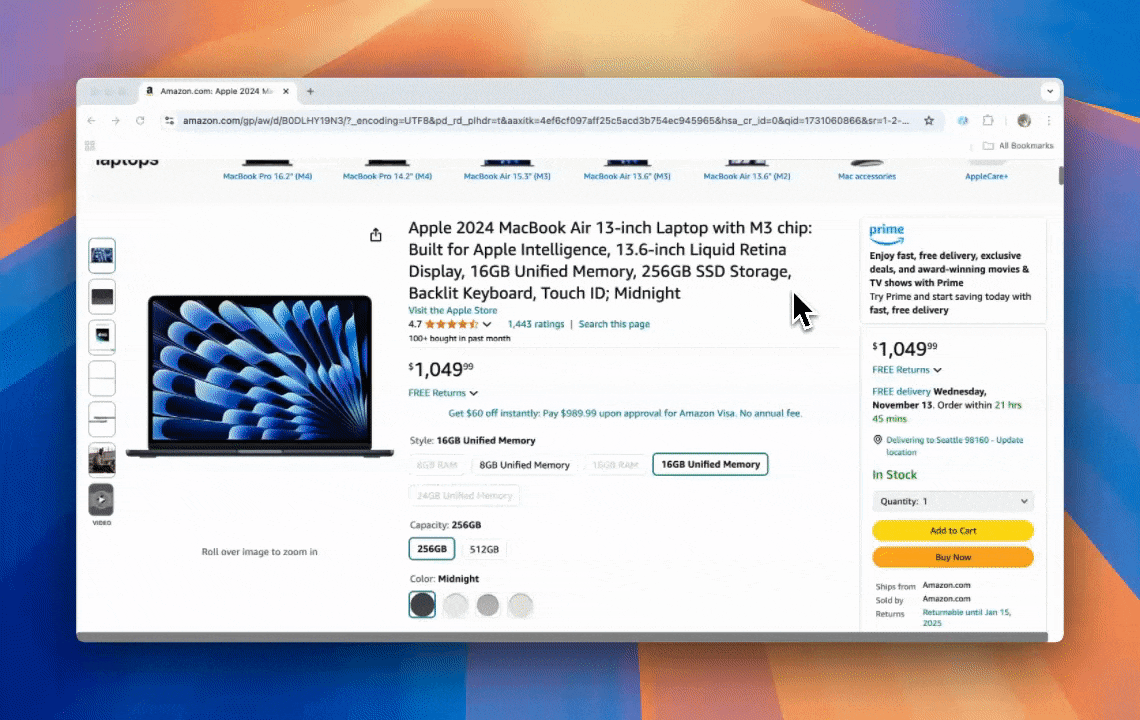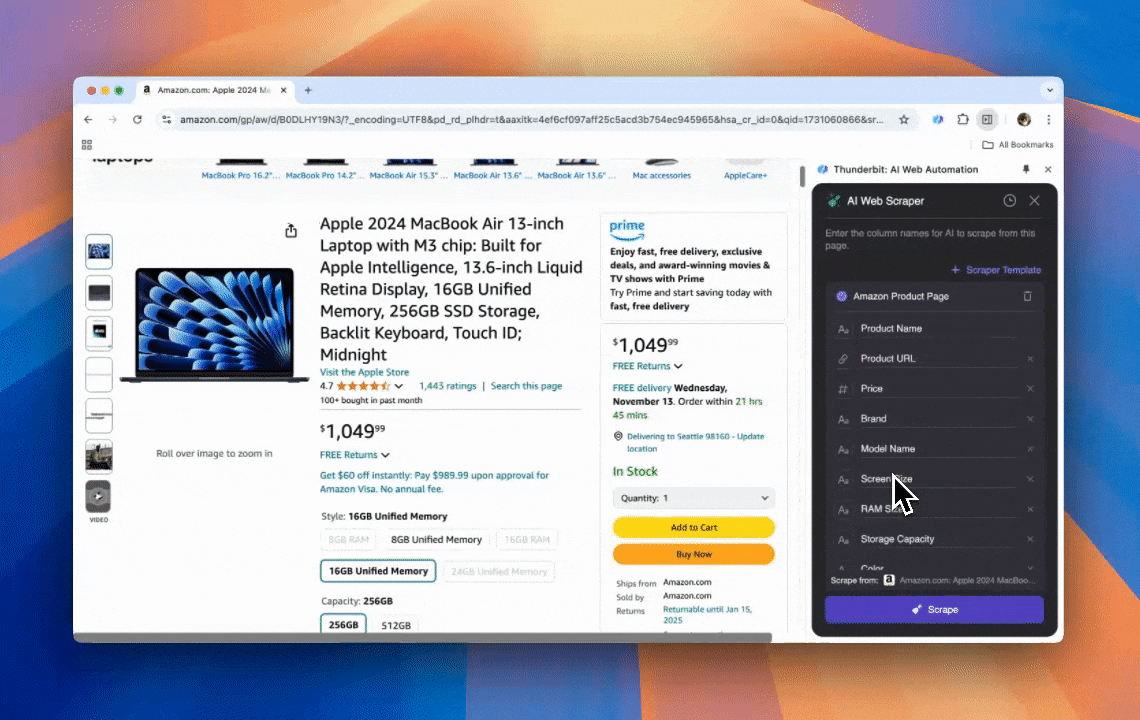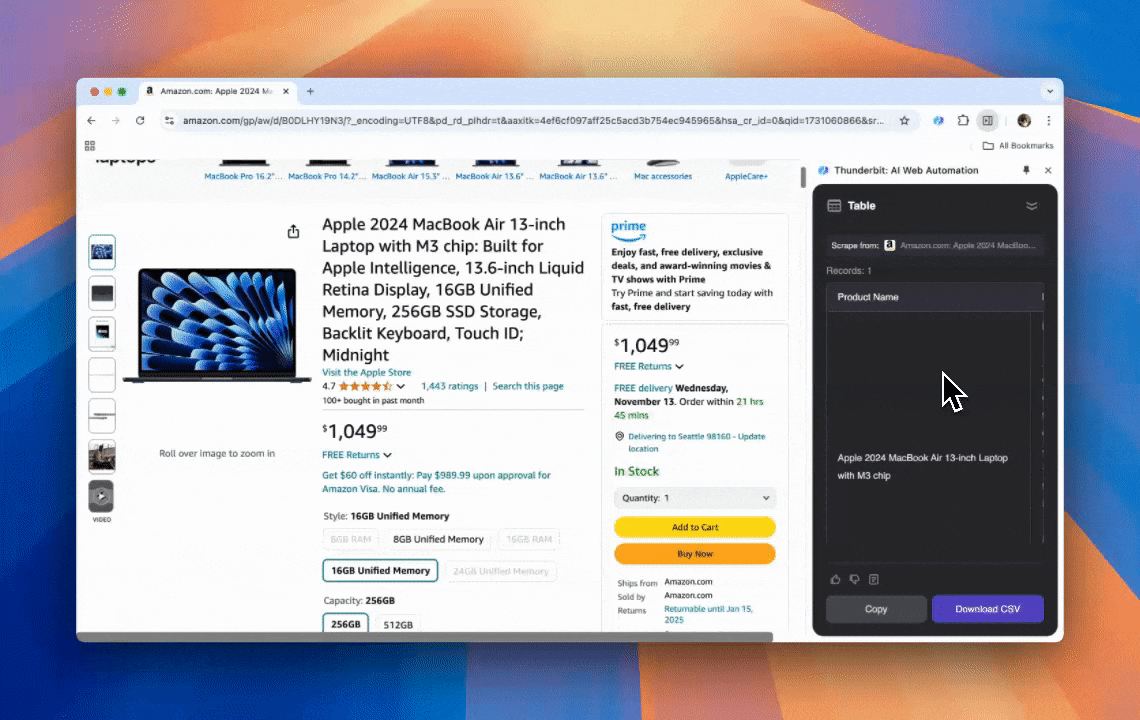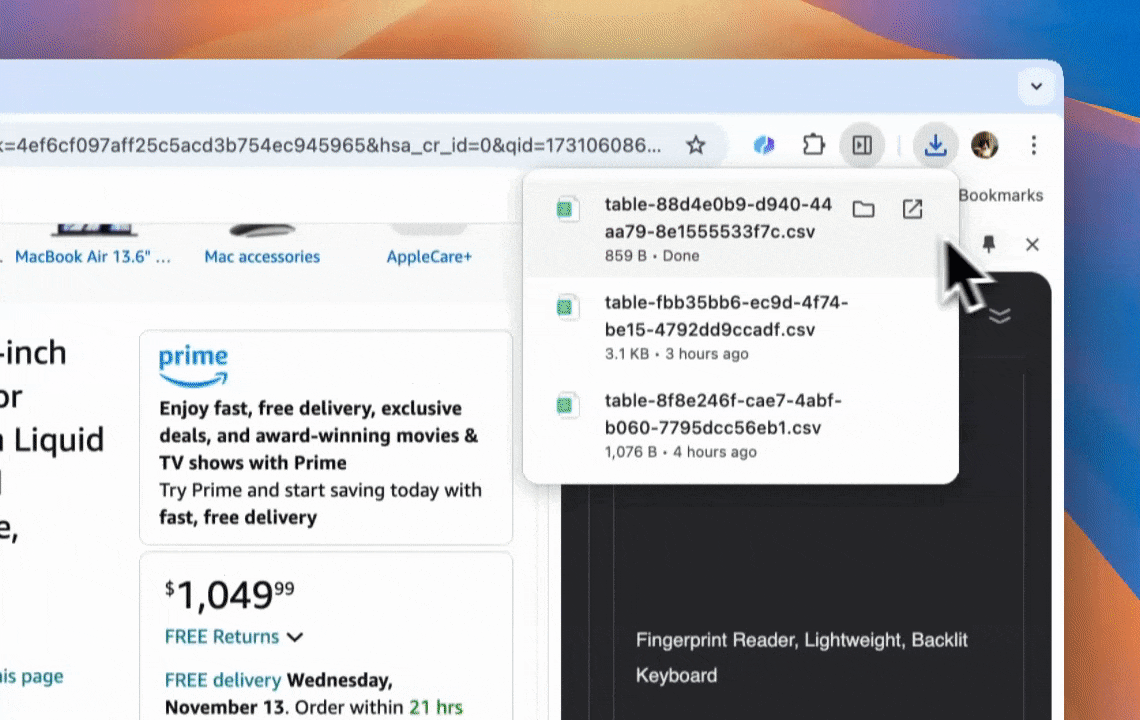
Thunderbit es una potente y fácil de usar herramienta de automatización web con IA que permite a usuarios sin conocimientos de programación extraer y organizar datos con facilidad. Con su , el de Thunderbit simplifica la extracción de datos: los usuarios pueden obtener datos web rápidamente sin interactuar manualmente con los elementos de la página ni configurar raspadores individuales para distintos diseños.
Funciones clave
- Flexibilidad impulsada por IA: el Raspador Web IA de Thunderbit detecta y formatea automáticamente los datos web, eliminando la necesidad de usar selectores CSS.
- La experiencia de scraping más sencilla: todo lo que tienes que hacer es hacer clic en “AI suggest column” y luego en “Scrape” en la página de la que quieras extraer datos. Eso es todo.
- Compatibilidad con varios formatos de datos: Thunderbit puede extraer URLs, imágenes y mostrar los datos capturados en múltiples formatos.
- Procesamiento automatizado de datos: la IA de Thunderbit puede reformatear los datos sobre la marcha, incluyendo resumirlos, categorizarlos y traducirlos al formato requerido.
- Exportación de datos fácil: exporta datos a Google Sheets, Airtable o Notion con un clic, simplificando la gestión de datos.
- Interfaz fácil de usar: una interfaz intuitiva lo hace accesible para usuarios de todos los niveles.
Precio
Thunderbit ofrece planes escalonados, desde 9 $ al mes por 5.000 créditos. Llega hasta 199 $ por 240.000 créditos. Además, en el plan anual recibirás todos los créditos por adelantado.
Ventajas:
- Un sólido soporte de IA simplifica la extracción y el procesamiento de datos.
- Sin código, accesible para usuarios de todos los niveles.
- Perfecto para scraping ligero, como directorios, tiendas en línea, etc.
- Gran capacidad de integración para exportar directamente a apps populares.
Desventajas:
- La extracción de datos a gran escala puede llevar tiempo para garantizar la precisión.
- Algunas funciones avanzadas pueden requerir una suscripción de pago.
¿Quieres más información? Empieza por , o descubre con Thunderbit.
Mejor raspador web para monitorización de datos y extracción masiva
Browse AI
Browse AI es una sólida herramienta de scraping de datos sin código diseñada para ayudar a los usuarios a extraer y monitorizar datos sin escribir ni una línea de código. Browse AI tiene algunas funciones de IA, pero no llega al nivel de un scraping totalmente basado en IA. Dicho esto, sí hace que empezar sea más fácil para los usuarios.
Funciones clave
- Interfaz sin código: permite crear flujos de trabajo personalizados con unos pocos clics.
- Monitorización en tiempo real: usa bots para seguir los cambios de una página web y entregar información actualizada.
- Extracción masiva de datos: capaz de gestionar hasta 50.000 registros de datos de una sola vez.
- Integración de flujos de trabajo: conecta varios bots para un procesamiento de datos más complejo.
Precio
Empieza en 48,75 $ al mes, con 2.000 créditos incluidos. Hay un plan gratuito disponible, que ofrece 50 créditos al mes para probar sus funciones básicas.
Ventajas:
- Ofrece integraciones con Google Sheets y Zapier.
- Los bots preconfigurados simplifican las tareas comunes de extracción de datos.
Desventajas:
- Puede requerir configuración adicional para páginas complejas.
- La velocidad del scraping masivo puede variar y, a veces, provocar tiempos de espera.
Mejor raspador web para integración de flujos de trabajo
Bardeen AI
Bardeen AI es una herramienta de automatización sin código diseñada para agilizar flujos de trabajo conectando distintas apps. Aunque usa IA para crear automatizaciones personalizadas, no tiene la adaptabilidad de una herramienta de scraping con IA completa.
Funciones clave
- Automatización sin código: permite a los usuarios crear flujos de trabajo con clics.
- MagicBox: describe tareas en lenguaje natural, que Bardeen AI convierte en flujos de trabajo.
- Amplias opciones de integración: se integra con más de 130 apps, incluidas Google Sheets, Slack y LinkedIn.
Precio
Empieza en 60 $ al mes, con 1.500 créditos (unas 1.500 filas de datos). Un plan gratuito ofrece 100 créditos al mes para probar las funciones básicas.
Ventajas:
- Las amplias opciones de integración cubren diversas necesidades empresariales.
- Flexible y escalable para empresas de todos los tamaños.
Desventajas:
- Los nuevos usuarios pueden necesitar tiempo para aprender a usar la plataforma completa.
- La configuración inicial puede llevar bastante tiempo.
Mejor raspador web visual para personas con experiencia
Web Scraper
Sí, lo has leído bien: la herramienta se llama "Web Scraper". Web Scraper es una popular extensión de navegador para Chrome y Firefox que permite a los usuarios extraer datos sin programar, ofreciendo una forma visual de crear tareas de scraping. Sin embargo, quizá tengas que pasar unos días viendo y aprendiendo de los tutoriales de arriba para dominarla por completo. Si quieres que el scraping sea fácil para tu cerebro, elige Raspador Web IA.
Funciones clave
- Creación visual: permite configurar tareas de scraping haciendo clic en elementos web.
- Compatibilidad con sitios dinámicos: puede manejar solicitudes AJAX y JavaScript en sitios dinámicos.
- Scraping en la nube: programa tareas mediante Web Scraper Cloud para scraping periódico.
Precio
Gratis para uso local; los planes de pago empiezan en 50 $/mes para funciones en la nube.
Ventajas:
- Funciona muy bien en sitios dinámicos.
- Gratis para uso local.
Desventajas:
- Requiere conocimientos técnicos para una configuración óptima.
- Se necesitan pruebas complejas para aplicar cambios.
Mejor raspador web para evitar el bloqueo de IP y la detección de bots
Octoparse
Octoparse es un software versátil para usuarios más técnicos que desean recopilar y monitorizar datos web específicos sin código; es ideal para necesidades de datos a gran escala. Octoparse no depende del navegador del usuario para funcionar; en su lugar, utiliza servidores en la nube para extraer datos. Así, puede ofrecer varios métodos para evitar el bloqueo de IP y cierta detección de bots por parte de los sitios web.
Funciones clave
- Funcionamiento sin código: los usuarios pueden crear tareas de scraping sin escribir código, lo que lo hace accesible para personas con distintos niveles técnicos.
- Detección automática inteligente: detecta automáticamente los datos de la página e identifica rápidamente los elementos disponibles para extraer, simplificando la configuración.
- Scraping en la nube: admite scraping de datos en la nube 24/7 con tareas programadas para una recuperación flexible de datos.
- Amplia biblioteca de plantillas: ofrece cientos de plantillas predefinidas, lo que permite acceder rápidamente a datos de sitios populares sin una configuración compleja.
Precio
El plan de precios de Octoparse empieza en 119 $ al mes, e incluye 100 tareas. También hay un plan gratuito con 10 tareas al mes para probar sus funciones básicas.
Ventajas:
- Sus potentes funciones permiten scraping de sitios dinámicos con gran adaptabilidad.
- Ofrece soluciones para gestionar restricciones de scraping y problemas de contenido dinámico.
Desventajas:
- Las estructuras de sitios web complejas pueden requerir más tiempo de configuración.
- Los nuevos usuarios pueden necesitar tiempo para aprender a usarlo.
Mejor raspador web para una API avanzada de extracción de datos con IA
Diffbot
Diffbot es una herramienta avanzada de extracción de datos web que usa IA para transformar contenido web no estructurado en datos estructurados. Con potentes APIs y un grafo de conocimiento, Diffbot ayuda a los usuarios a extraer, analizar y gestionar información de la web, y resulta adecuado para diversas industrias y aplicaciones.
Funciones clave
- API de extracción de datos: Diffbot ofrece una API de extracción de datos sin reglas, lo que permite a los usuarios simplemente proporcionar una URL para que la extracción sea automática, sin necesidad de definir reglas personalizadas para cada sitio web.
- API de procesamiento de lenguaje natural: extrae entidades estructuradas, relaciones y sentimiento a partir de texto no estructurado, ayudando a los usuarios a crear sus propios grafos de conocimiento.
- Grafo de conocimiento: Diffbot cuenta con uno de los grafos de conocimiento más grandes, que conecta amplios datos de entidades, incluidos detalles sobre personas y organizaciones.
Precio
El plan de precios de Diffbot empieza en 299 $ al mes e incluye 250.000 créditos (equivalentes a unas 250.000 extracciones de páginas web basadas en API).
Ventajas:
- Potentes capacidades de extracción de datos sin reglas, con gran adaptabilidad.
- Amplias opciones de integración por API para conectar fácilmente con sistemas existentes.
- Admite scraping a gran escala, apto para aplicaciones empresariales.
Desventajas:
- La configuración inicial puede requerir algo de tiempo de aprendizaje para usuarios no técnicos.
- Para usarlo, es necesario escribir un programa que llame a la API.
¿Para qué puedes usar los raspadores?
Si eres nuevo en el web scraping, aquí tienes algunos casos de uso populares para empezar. Mucha gente usa raspadores para obtener listados de productos de Amazon, extraer datos inmobiliarios de Zillow o recopilar información empresarial de Google Maps. Pero eso es solo el principio: puedes usar Thunderbit para recopilar datos de casi cualquier sitio web, agilizando tareas y ahorrando tiempo en tu flujo de trabajo diario. Ya sea para investigación, seguimiento de precios o creación de bases de datos, el web scraping abre muchísimas formas de poner a trabajar los datos de internet a tu favor.
Preguntas frecuentes
-
¿Es legal el web scraping?
El web scraping suele ser legal, pero debe respetar los términos de servicio del sitio web y la naturaleza de los datos a los que se accede. Revisa siempre las políticas pertinentes y cumple con las directrices legales.
-
¿Necesito conocimientos de programación para usar herramientas de web scraping?
La mayoría de las herramientas que se muestran aquí no requieren conocimientos de programación, pero herramientas como Octoparse y Web Scraper pueden aprovechar que el usuario tenga conocimientos básicos de estructuras web y una mentalidad de programación para un uso óptimo.
-
¿Hay herramientas gratuitas de web scraping?
Sí, hay herramientas gratuitas como BeautifulSoup, Scrapy y Web Scraper, y algunas herramientas también ofrecen planes gratuitos con funciones limitadas.
-
¿Cuáles son los desafíos más comunes del web scraping?
Los desafíos más comunes incluyen manejar contenido dinámico, CAPTCHAs, bloqueo de IP y estructuras HTML complejas. Las herramientas y técnicas avanzadas pueden resolver estos problemas con eficacia.
Más información:
-
Usa la IA para trabajar sin esfuerzo.