

¿Es ilegal el web scraping? Esa es la gran pregunta que me hacen cada semana fundadores, profesionales del marketing y amantes de los datos.
Con el 51 % de todo el tráfico de internet procediendo ahora de bots —la primera vez que el tráfico automatizado supera al humano— y una parte enorme de ese tráfico dedicada al web scraping para inteligencia de negocio, ventas y entrenamiento de IA, no sorprende que todo el mundo quiera saber dónde están los límites legales.
Un día ves un titular sobre una sentencia que dice que extraer datos públicos es perfectamente legal. Al siguiente, los reguladores advierten sobre la “obtención ilegal” de datos en redes sociales. Es confuso, incluso para quienes nos pasamos el día construyendo herramientas de AI Web Scraper en Thunderbit.
Entonces, ¿es ilegal el web scraping? La respuesta no es un sí o un no rotundos. Depende de qué extraes, de dónde lo extraes, de cómo usas los datos y de lo que diga la ley en tu país.
En este análisis en profundidad, desglosaré el panorama legal, desmontaré algunos mitos comunes y compartiré consejos prácticos —además de alguna que otra historia de trinchera— para ayudarte a cumplir la normativa, tanto si eres un fundador en solitario como si formas parte de un equipo de datos de una empresa Fortune 500.
Web scraping y la ley: ¿existe una línea clara?
Si esperabas una respuesta en una sola frase, te ahorro tiempo: la ley no ha trazado una línea clara y nítida sobre el web scraping.
En su lugar, existe un mosaico de normas que se solapan: propiedad de los datos, privacidad, propiedad intelectual, leyes contra el hackeo y los famosos Términos de Servicio (ToS). Cada una puede entrar en juego, y la respuesta suele depender de tu caso concreto (multilogin.com).
Veamos las tres grandes categorías legales:
- Propiedad de los datos: En general, los hechos y la información pública (como precios o números de teléfono) no están protegidos por copyright. Pero el contenido creativo (artículos, imágenes) y las bases de datos propietarias sí pueden estarlo, sobre todo en la UE, donde existen los “derechos sobre bases de datos” (cliffordchance.com).
- Privacidad: Las leyes modernas de privacidad (piensa en el RGPD en Europa o la PIPL en China) tratan los datos personales como un activo regulado, incluso si se publican abiertamente. Extraer nombres, correos electrónicos o perfiles sociales sin una base legal puede meterte en problemas (ico.org.uk).
- Contratos (Términos de Servicio): Muchos sitios prohíben expresamente el scraping en sus ToS. Aunque los ToS no son leyes, los tribunales pueden tratarlos como contratos vinculantes. Incumplirlos puede derivar en demandas y, en algunos casos, incluso activar estatutos contra el hackeo si se burlan bloqueos técnicos (cliffordchance.com).
Entonces, ¿es ilegal el web scraping? A veces sí, a veces no, y muchas veces “depende”. El diablo está en los detalles.
Comparación de perspectivas legales: EE. UU., UE, Reino Unido y China
Aquí tienes una tabla rápida para ver cómo abordan el web scraping distintas regiones:
| Región | Extracción de datos públicos | Extracción de datos personales/privados | Aplicación y puntos destacados |
|---|---|---|---|
| EE. UU. | Generalmente permitida para datos públicos (ver hiQ v. LinkedIn). Violar los ToS puede dar lugar a demandas civiles. | Restringida o ilegal si se eluden accesos o se usan mal datos personales. Pueden aplicarse leyes estatales (como la CCPA). | Cartas de cese y desistimiento, bloqueo de IP, demandas. La CFAA aplica si se sortean barreras técnicas. |
| UE | Permitida con condiciones para datos públicos no personales. Pueden aplicarse derechos sobre bases de datos. La Ley de IA de la UE (2026) añade requisitos de transparencia para datos de entrenamiento de IA. | Muy regulada bajo el RGPD, incluso los datos personales públicos requieren una base legal. | Las Autoridades de Protección de Datos pueden multar por infracciones de privacidad. También se aplican los derechos de autor y los derechos sobre bases de datos. La Ley de IA de la UE prohíbe la extracción de imágenes faciales para IA. |
| Reino Unido | Similar a la UE. Se pueden extraer datos públicos no personales, pero hay que respetar los derechos de datos y los contratos. | Estricto con los datos personales: se aplica el UK GDPR. La Computer Misuse Act criminaliza el acceso no autorizado. | La ICO puede sancionar por violaciones de protección de datos. Los tribunales pueden hacer cumplir los ToS. |
| China | Fuertemente controlado. Los datos públicos no personales pueden extraerse para uso interno, pero el entorno es cauteloso. | Muy restringido: la PIPL exige consentimiento para datos personales. Se aplican las leyes contra la competencia desleal. | Casos penales por extracción a gran escala. Los tribunales usan la ley de competencia desleal para frenar el scraping no autorizado. |
¿Es ilegal el web scraping? Factores legales clave a tener en cuenta
Entonces, ¿qué determina de verdad si tu proyecto de scraping es legal o arriesgado? Estos son los factores principales:
- Datos públicos frente a privados: Extraer datos que cualquiera puede ver en la web abierta suele ser más seguro. ¿Extraer algo detrás de un inicio de sesión, un muro de pago o una barrera técnica? Eso probablemente sea ilegal (thunderbit.com).
- Naturaleza de los datos: Los datos personales (nombres, correos, perfiles) activan las leyes de privacidad. El contenido protegido por copyright (artículos, imágenes) no puede copiarse en bloque. Los hechos puros (precios, clima) suelen estar permitidos (oxylabs.io).
- Uso previsto: El análisis interno o la investigación se miran con más indulgencia que volver a publicar o vender los datos extraídos. ¿Usar datos extraídos para competir directamente con la fuente? Eso es una demanda esperando a ocurrir (thunderbit.com).
- Cumplimiento de las normas del sitio: Revisa siempre robots.txt y los ToS. Robots.txt no es vinculante legalmente, pero conviene respetarlo como buena práctica. Incumplir los ToS puede acabar en demandas civiles o peor (promptcloud.com).
- Medidas técnicas: La clave está en extraer a velocidades parecidas a las humanas y no eludir medidas de seguridad. Machacar un servidor o esquivar CAPTCHAs puede cruzar la línea hacia el hackeo (cliffordchance.com).
Qué cambió entre 2024 y 2026: casos judiciales y regulaciones clave
El panorama legal del web scraping ha cambiado muchísimo desde 2023. Estos son los desarrollos que todo scraper debe conocer:
Principales sentencias judiciales
-
Meta v. Bright Data (2024): Un tribunal federal de EE. UU. dictaminó que los Términos de Servicio de Meta no prohíben extraer datos públicos por parte de usuarios que no han iniciado sesión. El juez concluyó que “un visitante no se considera un ‘usuario’ a menos que tenga una cuenta”. Poco después, Meta retiró el resto de sus reclamaciones. Es una victoria histórica para la extracción de datos públicos.
-
X Corp v. Bright Data (2024): Twitter (ahora X) perdió una demanda similar, reforzando el mismo principio: extraer datos accesibles públicamente sin iniciar sesión no viola los ToS, porque el scraper nunca aceptó esas condiciones.
-
Reddit v. Perplexity AI (octubre de 2025): Reddit demandó a Perplexity AI y a varios proveedores de scraping, invocando la DMCA y alegando la elusión de sistemas antibots. Esto apunta a una nueva estrategia legal: las plataformas están recurriendo a reclamaciones por copyright y anti-elusión en lugar de la CFAA.
-
NYT v. OpenAI (marzo de 2025): Un juez federal permitió que siguiera adelante el caso de copyright del New York Times contra OpenAI, rechazando la moción de OpenAI para desestimar. Esto podría sentar un precedente importante sobre si extraer contenido para entrenar modelos de IA cuenta como “uso legítimo”.
-
Acuerdo de Anthropic (septiembre de 2025): Anthropic aceptó pagar 1.500 millones de dólares para resolver una demanda colectiva en EE. UU. por usar textos protegidos por copyright para entrenar su modelo de IA, lo que demuestra que el coste del scraping para IA es muy real.
La gran tendencia: de la CFAA al derecho contractual y al copyright
El patrón es claro: la CFAA (Computer Fraud and Abuse Act) está perdiendo fuerza como arma contra los scrapers de datos públicos. Las empresas que intentaron usar la CFAA contra la extracción de datos públicos —Meta, X, LinkedIn— han fracasado en gran medida. En cambio, el campo de batalla legal se está desplazando hacia:
- Derecho contractual (incumplimiento de ToS, aunque los tribunales dicen que los no usuarios no quedan vinculados por esos términos)
- Reclamaciones por copyright (especialmente para datos de entrenamiento de IA)
- Leyes anti-elusión (DMCA, sección 1201)
Para quienes hacen scraping, esto significa que el riesgo legal no ha desaparecido: solo se ha desplazado.
Cambios regulatorios
- Actualizaciones de la CCPA en 2026: Las regulaciones revisadas de California bajo la CCPA entraron en vigor el 1 de enero de 2026, añadiendo nuevas normas sobre tecnología de toma de decisiones automatizada (ADMT), evaluaciones de riesgo y obligaciones para data brokers.
- Nuevas leyes estatales de privacidad en EE. UU.: Indiana, Kentucky y Rhode Island aprobaron leyes integrales de privacidad que entraron en vigor en 2026.
- Ley de IA de la UE: La aplicación completa comienza el 2 de agosto de 2026 y exige a los desarrolladores de IA revelar las fuentes de datos de entrenamiento, respetar las exclusiones de copyright y prohibir la extracción de imágenes faciales para sistemas de IA.
- AI Accountability for Publishers Act (febrero de 2026): Una propuesta de ley en EE. UU. que exigiría a las empresas de IA pedir permiso y pagar a los editores antes de extraer su contenido.
Políticas de scraping de las principales plataformas: lo que necesitas saber
No todos los sitios web tratan el scraping del mismo modo. Aquí tienes un desglose plataforma por plataforma de lo que permiten los grandes sitios, lo que bloquean y lo que han dicho los tribunales:
| Plataforma | ToS sobre scraping | Defensas técnicas | Aplicación legal | Qué es seguro en la práctica |
|---|---|---|---|---|
| Google (Búsqueda y Maps) | Prohíbe el acceso automatizado en sus ToS. Maps Platform incluye una cláusula explícita de “No Scraping”. | Desafíos SearchGuard JS, CAPTCHAs, limitación de velocidad. Actualizó robots.txt en 2025 para bloquear rastreadores de IA. | Demandó a scrapers en diciembre de 2025 usando la DMCA. Bloquea activamente rastreadores de IA (Anthropic, Meta, OpenAI). | Extraer datos públicos de negocios en Google Maps es defendible legalmente (precedente hiQ), pero espera bloqueos técnicos. Usa APIs oficiales cuando sea posible. |
| Amazon | Prohíbe expresamente todo scraping en sus Condiciones de uso (“sin robot, spider, scraper ni otros medios automatizados”). | Detección agresiva de bots, CAPTCHA, bloqueo de IP. robots.txt bloquea a todos los bots excepto Googlebot/Bingbot. Bloquea explícitamente rastreadores de IA desde 2025. | Demandó a Perplexity AI en noviembre de 2025. Envía cartas de cese y desistimiento con regularidad. Actualizó su BSA en marzo de 2026 con normas para agentes de IA. | Los datos públicos de productos (precios, listados) son hechos y pueden extraerse bajo la ley de EE. UU., pero Amazon responde con dureza. Limita la frecuencia de solicitudes y evita los datos personales. |
| Prohíbe el scraping en sus ToS; exige aceptar los términos para acceder a sus servicios. | Muros de inicio de sesión para la mayoría de datos de perfiles, detección antibots, limitación de velocidad. | El caso hiQ confirmó que extraer perfiles públicos no viola la CFAA, pero LinkedIn ganó en reclamaciones por contrato y competencia desleal cuando se usaron cuentas falsas. | Los perfiles públicos (visibles sin iniciar sesión) son legalmente defendibles para extraer. Nunca crees cuentas falsas ni extraigas datos detrás de inicio de sesión. | |
| Meta (Facebook e Instagram) | Los ToS prohíben el scraping; hay reglas distintas para datos con y sin sesión iniciada. | Muros de inicio de sesión para la mayor parte del contenido, detección avanzada de bots. | Perdió frente a Bright Data en 2024: el tribunal resolvió que los ToS no se aplican a scrapers sin sesión iniciada. Retiró el resto de sus reclamaciones. | Los datos públicos (páginas de empresa, publicaciones públicas) visibles sin iniciar sesión están en una posición más segura. Nunca extraigas perfiles privados ni datos detrás del login. |
| X (Twitter) | Actualizó sus ToS en 2023 para prohibir todo scraping y crawling sin consentimiento por escrito. Eliminó la antigua excepción de robots.txt. | robots.txt bloquea todos los crawlers (Disallow: /). Desafíos de Cloudflare Turnstile. Límites de velocidad estrictos (300 req/h). Puntuación de reputación de IP. | Perdió frente a Bright Data en datos públicos, pero limita de forma agresiva el acceso técnico. | Los tuits y perfiles públicos son legalmente defendibles, pero las barreras técnicas de X son de las más duras en 2026. Espera bloqueos si no tienes infraestructura premium de proxies. |
La conclusión: Los tribunales han dictaminado de forma consistente que extraer datos visibles públicamente sin iniciar sesión no viola la CFAA. Pero las plataformas todavía pueden ir a por ti por derecho contractual, copyright o anti-elusión, y te pondrán las cosas muy difíciles con barreras técnicas. Haz scraping con responsabilidad.
Datos de entrenamiento para IA y web scraping: la nueva frontera legal
Si sigues las noticias de 2026, sabrás que extraer datos para entrenar modelos de IA se ha convertido en el frente legal más caliente. Esto es lo que está ocurriendo:
- Se acumulan las demandas por copyright. The New York Times, autores y editores han demandado a OpenAI, Anthropic y otras compañías, alegando que la extracción masiva de contenido protegido para entrenar LLM no constituye “uso legítimo”. Anthropic resolvió una importante demanda colectiva por 1.500 millones de dólares en 2025, señal de que el coste del scraping para IA es muy real.
- La defensa del “uso legítimo” es endeble. Los tribunales de EE. UU. aún no han emitido una resolución definitiva sobre si entrenar IA con datos extraídos entra dentro del uso legítimo. Las primeras decisiones sugieren que depende en gran medida de cómo se obtuvieron los datos y qué se hace con la salida de la IA.
- Se acerca nueva legislación. El AI Accountability for Publishers Act (presentado en febrero de 2026) busca obligar a las empresas de IA a pedir permiso y pagar a los editores antes de extraer su contenido.
- La Ley de IA de la UE (aplicación completa en agosto de 2026) exige a los desarrolladores de IA revelar las fuentes de datos de entrenamiento, respetar las exclusiones de copyright legibles por máquina (según la excepción de TDM de la Directiva de Copyright) y etiquetar el contenido generado por IA. También prohíbe los sistemas de IA que extraen imágenes faciales de internet.
- Los rastreadores de IA/LLM están explotando. Los rastreadores de IA cuadruplicaron su cuota de tráfico web del 2,6 % al 10,1 % en solo ocho meses. Solo GPTBot de OpenAI creció un 305 %. En respuesta, los principales sitios (Amazon, Reddit, The New York Times) están actualizando robots.txt para bloquear explícitamente a los rastreadores de IA.
Qué significa esto para ti: si extraes datos para fines empresariales tradicionales (generación de leads, seguimiento de precios, investigación de mercado), es posible que estas normas específicas de IA no te afecten directamente. Pero si vas a alimentar modelos de IA con datos extraídos, avanza con muchísima cautela y busca asesoramiento legal.
Leyes de web scraping en el mundo: una comparación rápida
Demos un paso atrás y veamos cómo encajan las normas a nivel global:
- Estados Unidos: No existe una prohibición general. Extraer datos de sitios públicos suele ser legal (hiQ v. LinkedIn), y las sentencias de 2024 en Meta y X Corp han reforzado aún más el caso de la extracción de datos públicos. Pero extraer datos detrás de inicios de sesión o barreras técnicas todavía puede activar la CFAA. La tendencia ahora es que las empresas recurran a derecho contractual y reclamaciones por copyright. Las leyes de privacidad se están expandiendo rápido: la CCPA recibió importantes actualizaciones con efecto desde el 1 de enero de 2026, incluidas nuevas normas sobre toma de decisiones automatizada y obligaciones para data brokers. Indiana, Kentucky y Rhode Island también aprobaron leyes integrales de privacidad en 2026.
- Unión Europea: Leyes de privacidad estrictas. El RGPD se aplica incluso a los datos personales públicos. Los derechos sobre bases de datos pueden bloquear la extracción masiva de datos estructurados (cliffordchance.com). NOVEDAD: La Ley de IA de la UE entra en aplicación total el 2 de agosto de 2026, exigiendo a los desarrolladores de IA divulgar las fuentes de datos de entrenamiento y respetar las exclusiones de copyright. La ley prohíbe extraer imágenes faciales de internet para sistemas de IA.
- Reino Unido: Refleja las normas de la UE tras el Brexit. Se pueden extraer datos públicos, pero la extracción de información personal está muy regulada. La Computer Misuse Act puede criminalizar el acceso no autorizado.
- China: Muy restrictiva. La PIPL y la Ley de Seguridad de Datos exigen consentimiento para los datos personales. Los tribunales usan la ley de competencia desleal para bloquear scraping que perjudica a las empresas (malwarebytes.com).
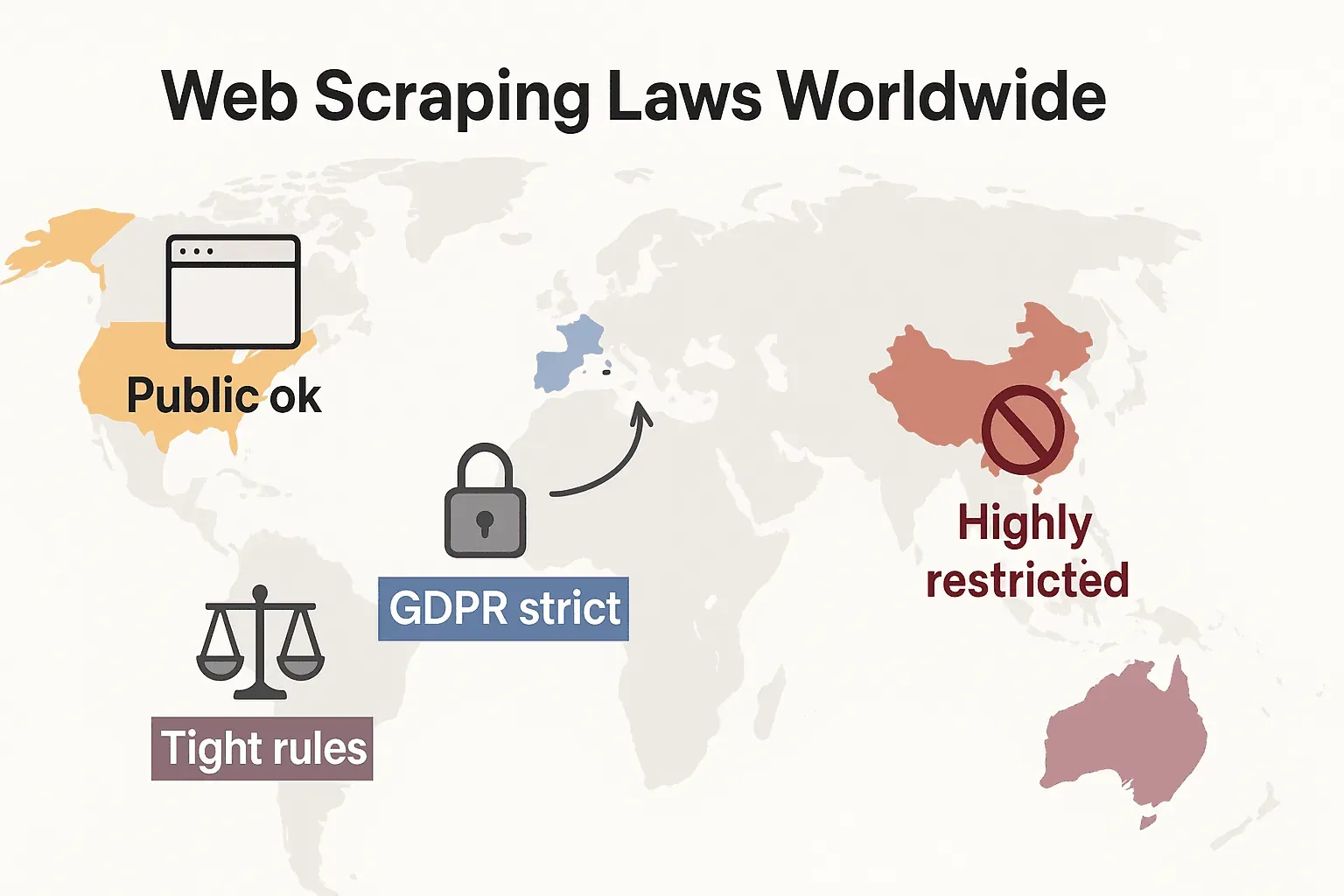
En resumen: extraer datos públicos y no personales para uso interno suele ser lo más seguro. ¿Todo lo demás? Consulta las leyes locales y avanza con cuidado.
Mitos comunes sobre la legalidad del web scraping
Desmontemos algunos mitos que oigo constantemente:
- Mito 1: “El web scraping es ilegal, sin más”.
Falso. No existe una ley que prohíba todo el web scraping. Lo que importa es cómo y qué extraes (oxylabs.io). - Mito 2: “Si los datos son públicos, puedo hacer lo que quiera con ellos”.
No exactamente. Los datos públicos también pueden estar protegidos por leyes de privacidad o copyright, y los ToS pueden restringir ciertos usos (ico.org.uk). - Mito 3: “El web scraping es lo mismo que hackear”.
No. Extraer páginas web públicas no es hackear. Eludir inicios de sesión o barreras técnicas es otra historia (calawyers.org). - Mito 4: “Si no me pillan, no pasa nada”.
Es una forma de pensar arriesgada. Muchos sitios usan tecnología antibots y se darán cuenta. El silencio no es consentimiento. - Mito 5: “Dar crédito o usar los datos internamente lo hace aceptable”.
Atribuir la fuente no anula la ley de copyright ni la de privacidad. El uso interno es más seguro, pero no es un pase libre. - Mito 6: “Todo web scraping vulnera la privacidad”.
No todo scraping implica datos personales. Pero extraer grandes volúmenes de información personal sin garantías casi siempre es ilegal (oxylabs.io). - Mito 7: “Si los ToS de un sitio prohíben el scraping, entonces siempre es ilegal hacerlo”.
No necesariamente. En 2024, los tribunales dictaminaron en Meta v. Bright Data y X Corp v. Bright Data que los ToS no pueden vincular a usuarios que nunca los aceptaron; es decir, si haces scraping sin iniciar sesión ni crear una cuenta, puede que los ToS del sitio no se te apliquen. El tema sigue evolucionando, pero es un cambio importante.
Cómo extraer datos de forma legal: mejores prácticas para cumplir la normativa
Esta es mi lista de comprobación para hacer web scraping legal y ético:
- Lee y respeta los Términos de Servicio del sitio. Si dicen “no scraping”, plantéate parar o pide permiso (ql2.com).
- Quédate con los datos públicos. Si necesitas una contraseña, está restringido: no lo extraigas (thunderbit.com).
- Revisa robots.txt y navega con respeto. No es vinculante legalmente, pero sí una buena etiqueta. No machaques servidores: espacia tus solicitudes (promptcloud.com).
- Evita los datos personales salvo que tengas una base legal. Si tienes que recopilarlos, cumple con el RGPD/CCPA y minimiza lo que recolectas.
- No vuelvas a publicar contenido extraído en bloque. Aporta valor o análisis, o pide permiso (thunderbit.com).
- No alimentes modelos de IA con contenido extraído sin revisar el copyright. El panorama legal cambia rápido: busca asesoramiento si ese es tu caso de uso.
- Usa APIs oficiales o exportaciones de datos cuando existan. Están diseñadas para eso y suelen ser más seguras (thunderbit.com).
- Sé transparente y responsable. Si recoges datos personales, informa a las personas y mantén un registro de tus actividades.
- Minimiza y protege tus datos. Recoge solo lo que necesites, mantén la exactitud y guárdalos de forma segura.
- Mantente informado y busca asesoramiento legal en casos límite. Las leyes y las sentencias cambian rápidamente, especialmente la Ley de IA de la UE y las leyes estatales de privacidad de EE. UU. Cuando tengas dudas, consulta a un profesional.
Prueba la extensión de Chrome de Thunderbit para un scraping conforme
Uso legal de herramientas de web scraping: lo que las empresas deben saber
Las herramientas de web scraping como Thunderbit hacen que la recopilación de datos sea accesible incluso para quienes no programan, pero aun así debes usarlas con responsabilidad:
- Elige herramientas centradas en el cumplimiento. Thunderbit, por ejemplo, solo extrae lo que puedes ver en tu navegador: sin trucos de API ni accesos no autorizados (thunderbit.com).
- Limítate a casos de uso legítimos. El análisis interno, la investigación de mercado y el seguimiento competitivo de precios suelen ser seguros. ¿Volver a publicar o vender datos extraídos? Mucho más arriesgado.
- Configura las herramientas para cumplir la normativa. Establece retrasos entre rastreos, respeta robots.txt y usa plantillas que recojan solo lo necesario.
- Mantenlo dentro de la empresa. Usar los datos extraídos internamente es más seguro que volver a publicarlos.
- Forma a tu equipo. Asegúrate de que todos entienden las normas y las buenas prácticas.
- Aprovecha las funciones de cumplimiento integradas. Thunderbit avisa sobre sitios de riesgo, extrae a velocidades similares a las humanas y no almacena tus datos en sus servidores.
- No fuerces la situación. Si una herramienta no puede extraer un sitio, no intentes saltarte la protección. No todos los datos se pueden obtener sin riesgo.
El enfoque de Thunderbit: facilitar un AI Web Scraper conforme a la normativa
En Thunderbit, hemos dedicado mucho tiempo a pensar en el cumplimiento normativo. Así es como nuestro AI Web Scraper ayuda a los usuarios a mantenerse dentro de la ley:
- Solo extrae lo que puedes ver. Thunderbit funciona dentro de tu sesión del navegador, así que no puede acceder a datos que no podrías copiar manualmente.
- Guía a los usuarios con advertencias. Si intentas extraer un sitio con políticas muy estrictas contra el scraping, Thunderbit te avisará.
- Velocidades de scraping similares a las humanas. Tanto si extraes localmente como en la nube, Thunderbit evita sobrecargar los servidores.
- Selección de datos personalizable. Nuestra IA sugiere columnas relevantes para ayudarte a recoger solo lo que necesitas.
- Gestión de subpáginas y paginación. Thunderbit navega por los sitios como lo haría una persona real, respetando su estructura.
- Privacidad y seguridad. Tus datos se quedan contigo: Thunderbit no los almacena ni los reutiliza.
- Exportaciones pensadas para el cumplimiento. Exporta directamente a Google Sheets, Airtable, Notion o CSV para un uso interno y seguro.
- Programación y automatización. Configura extracciones recurrentes en intervalos responsables.
- Compatibilidad multilingüe. La interfaz de Thunderbit admite 34 idiomas, lo que facilita el cumplimiento a escala global.
- Actualizaciones periódicas de plantillas. Nuestras plantillas instantáneas para sitios populares se mantienen al día con los cambios legales y técnicos.
Al incorporar el cumplimiento en el producto, Thunderbit ayuda a los equipos a recopilar los datos que necesitan, sin dolores de cabeza legales.
Ir un paso por delante: adaptarse a los cambios legales y técnicos en el web scraping
Explora más guías de web scraping Get Started Free
El web scraping no es algo que configures una vez y te olvides. Las leyes y las estructuras de los sitios web evolucionan constantemente. Así es como puedes mantenerte al día:
- Sigue de cerca la evolución legal. El ritmo de cambio se aceleró en 2024–2026: sigue las noticias sobre derecho tecnológico, las actualizaciones de los reguladores y los blogs del sector (como el de Thunderbit). Presta atención a la aplicación de la Ley de IA de la UE (agosto de 2026), a las nuevas leyes estatales de privacidad en EE. UU. y a los casos de copyright en IA que siguen abiertos.
- Adáptate a los cambios técnicos. Los sitios actualizan sus diseños y sus defensas antibots continuamente. Las principales plataformas (Amazon, X, Google) endurecieron mucho sus defensas en 2025–2026. La IA y las plantillas de Thunderbit están diseñadas para adaptarse automáticamente.
- Apuesta por las APIs oficiales cuando existan. Si un sitio pasa a un modelo de API de pago, valora cambiarte por fiabilidad y cumplimiento.
- Audita tu scraping con regularidad. Documenta tus fuentes, comprueba si hay cambios en los ToS o en las políticas y ajusta tu estrategia según sea necesario.
- Aprovecha las actualizaciones de plantillas de Thunderbit. Nuestro equipo mantiene las plantillas al día, para que no tengas que preocuparte por cambios que rompan el flujo ni por nuevos requisitos de cumplimiento.
- Mantente flexible. Si una fuente de datos se vuelve demasiado arriesgada, cambia a otra o busca una colaboración.
Con las herramientas y la mentalidad adecuadas, puedes mantener en marcha tu canal de datos sin pisar minas legales.
Conclusión: navegar el panorama legal del web scraping
El web scraping no es ilegal por naturaleza: es una herramienta potente para el negocio, la investigación y la innovación. Pero, como cualquier herramienta, viene con normas. La clave está en entender qué extraes, cómo lo extraes y qué harás con los datos. Respeta las leyes locales, cumple las políticas de los sitios y usa herramientas orientadas al cumplimiento como Thunderbit para mantener tus operaciones en regla.
Las sentencias de 2024–2026 (Meta v. Bright Data, X Corp v. Bright Data) han reforzado el argumento a favor de extraer datos públicos, pero están surgiendo nuevos riesgos en torno a los datos de entrenamiento de IA, las reclamaciones por copyright y la Ley de IA de la UE. Las políticas específicas de cada plataforma varían mucho —Google, Amazon, LinkedIn, Meta y X aplican sus reglas de forma distinta—, así que conoce el terreno antes de extraer nada.
Si alguna vez tienes dudas, busca asesoramiento legal, especialmente en proyectos grandes o sensibles. Y recuerda: el panorama legal cambia constantemente, así que mantente informado y ágil.
¿Quieres aprender más sobre web scraping, cumplimiento y automatización? Visita el blog de Thunderbit para más guías o prueba por tu cuenta la extensión de Chrome de Thunderbit.
Empieza a hacer web scraping conforme a la normativa con Thunderbit
FAQs
1. ¿Es ilegal el web scraping en todas partes?
No. El web scraping no es ilegal por sí mismo, pero su legalidad depende de qué extraes, cómo lo haces y en qué lugar te encuentras. Extraer datos públicos y no personales para uso interno suele estar permitido en la mayoría de las regiones, pero extraer datos personales o protegidos por copyright, o incumplir las condiciones del sitio, puede ser ilegal (oxylabs.io).
2. ¿Robots.txt vuelve ilegal el scraping si lo ignoro?
Robots.txt no es vinculante legalmente, pero conviene respetarlo. Ignorarlo no te llevará a una demanda por sí solo, pero puede hacer que parezcas un “mal actor” si surge una disputa (promptcloud.com).
3. ¿Puedo extraer datos de Google, Amazon o LinkedIn?
Es complicado. Las tres plataformas prohíben el scraping en sus ToS, pero los tribunales han dictaminado que los ToS pueden no vincular a usuarios que no han iniciado sesión (véanse Meta v. Bright Data y X Corp v. Bright Data, ambas de 2024). Extraer datos visibles públicamente (precios de productos, fichas de negocio, perfiles públicos) suele ser defendible legalmente en EE. UU. Sin embargo, cada plataforma aplica sus reglas de forma distinta: Amazon es la más agresiva con las acciones legales (demandó a Perplexity AI en noviembre de 2025); LinkedIn se apoya en barreras técnicas y reclamaciones contractuales; Google está usando cada vez más la DMCA. Hazlo siempre con responsabilidad y espera contramedidas técnicas.
4. ¿Puedo extraer datos de Facebook o Instagram?
Después de Meta v. Bright Data (2024), extraer datos públicos de Facebook e Instagram sin iniciar sesión tiene una base legal más sólida. El tribunal resolvió que los ToS de Meta no se aplican a quienes no son usuarios. Pero nunca crees cuentas falsas ni extraigas datos detrás de muros de inicio de sesión: eso sí cruza la línea.
5. ¿Puedo extraer datos de X (Twitter)?
X actualizó sus ToS en 2023 para prohibir todo scraping sin consentimiento por escrito y ha desplegado defensas técnicas agresivas (Cloudflare Turnstile, límites de 300 solicitudes por hora, puntuación de reputación de IP). Aun así, Bright Data ganó en los tribunales en un caso similar: los datos públicos extraídos sin cuenta no quedan vinculados por los ToS de X. Técnicamente, X es una de las plataformas más difíciles de extraer en 2026.
6. ¿Es legal extraer datos para entrenar modelos de IA?
Esta es la gran pregunta abierta de 2026. Grandes demandas (NYT v. OpenAI, el acuerdo de Anthropic por 1.500 millones de dólares) sugieren un riesgo legal importante. La Ley de IA de la UE exige divulgar las fuentes de datos de entrenamiento y respetar las exclusiones de copyright. La propuesta de AI Accountability for Publishers Act exigiría permiso y pago. Si vas a extraer datos para entrenar IA, busca asesoramiento legal antes de seguir.
7. ¿Cuál es la forma más segura de usar herramientas de web scraping como Thunderbit?
Extrae solo datos públicos, respeta los términos del sitio, evita la información personal salvo que tengas una base legal y usa los datos internamente. Thunderbit está diseñado para ayudarte a cumplir: solo extrae lo que ves en tu navegador y te avisa sobre sitios de riesgo (thunderbit.com).
8. ¿Puedo extraer datos para uso comercial?
Depende. Usar datos extraídos para análisis interno o investigación suele ser más seguro. Volver a publicar o vender datos extraídos, especialmente si están protegidos por copyright o son personales, es mucho más arriesgado y puede requerir permiso o licencia.
9. ¿Cómo me mantengo al día con los cambios legales y técnicos en el web scraping?
Sigue las noticias sobre derecho tecnológico, vigila los cambios de ToS o políticas de tus sitios objetivo y utiliza herramientas como Thunderbit, que actualizan sus plantillas y funciones de cumplimiento con regularidad. Aspectos clave a vigilar en 2026: la aplicación de la Ley de IA de la UE (agosto), los casos en curso sobre copyright en IA y las nuevas leyes estatales de privacidad en EE. UU. Cuando tengas dudas, consulta a un profesional del derecho.
Prueba AI Web Scraper Get Started Free




