Imagina la escena: estamos en 2025, te tomas tu café de la mañana y te preguntas si Walmart ya bajó el precio de ese televisor de 65 pulgadas que tienes fichado. O tal vez llevas un negocio de e-commerce y necesitas estar al tanto, en tiempo real, de los precios, el stock y las reseñas de los clientes en Walmart. ¿Te imaginas revisar manualmente la web de Walmart para cada producto, todos los días? Sería un trabajo de locos (y nada entretenido). Pero con un poco de Python y algo de maña con el scraping, puedes automatizar todo ese proceso y tener acceso a un montón de datos en minutos.
Llevo años armando herramientas de automatización e IA para empresas. El scraping de Walmart es uno de esos “trucos secretos” que convierte horas de trabajo aburrido en unas cuantas líneas de código, y aquí te voy a mostrar cómo hacerlo. En esta guía te explico qué es el scraping de Walmart, por qué es tan útil para los negocios en 2025 y cómo crear tu propio raspador web de Walmart en Python, paso a paso, con ejemplos reales y consejos prácticos. Así que prepárate tu café (o tu snack favorito para debuggear) y ¡vamos al lío!
¿Qué es el Scraping de Walmart? Conceptos Básicos para 2025
En pocas palabras, el scraping de Walmart es extraer automáticamente datos de productos, precios y reseñas del sitio de Walmart usando software, normalmente un script que actúa como un navegador rapidísimo. En vez de copiar y pegar información a mano (que nadie disfruta), escribes un script en Python que descarga las páginas de Walmart, saca los datos que te interesan y los guarda para analizarlos después.
¿Y por qué Python? Porque es el cuchillo multiusos del raspado web: fácil de leer, con librerías buenísimas (Requests, BeautifulSoup, pandas) y una comunidad enorme que comparte trucos y código. Tanto si eres freelance como si trabajas en equipo, Python hace que el scraping de Walmart sea accesible, incluso si no eres un programador profesional.
También hay que diferenciar entre scraping para uso personal (por ejemplo, seguir precios de algunos productos para tus compras) y para uso empresarial (como monitorear miles de SKUs para inteligencia competitiva). A mayor escala, la cosa se complica, sobre todo porque Walmart no tiene una API pública de productos en 2025 ().
¿Por Qué Hacer Scraping de Walmart? Valor Real para Negocios
Walmart no solo es el rey de las tiendas físicas en EE. UU., ahora también es un monstruo digital, con ventas online que superaron los y el e-commerce ya representa casi el 18% de sus ventas totales (). Eso significa un montón de productos, precios, reseñas y tendencias listos para analizar.
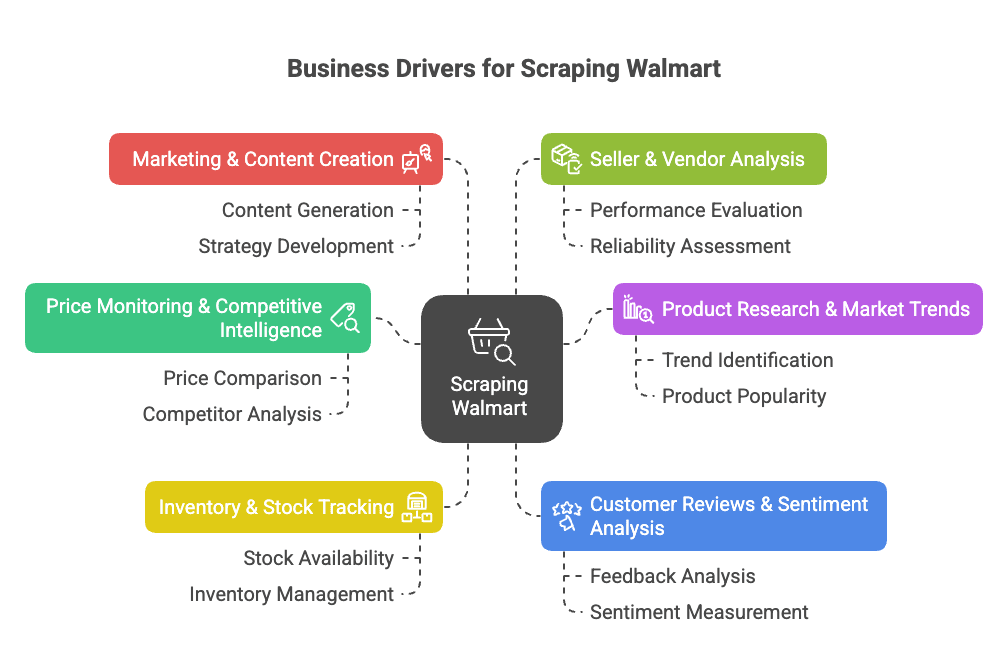
Entonces, ¿por qué hacer scraping de Walmart? Aquí van los motivos top para negocios:
- Monitoreo de Precios e Inteligencia Competitiva: Sigue al instante los precios, promociones y cambios de catálogo de Walmart para ajustar tu propia estrategia ().
- Investigación de Productos y Tendencias de Mercado: Analiza el surtido, especificaciones y tendencias de categorías para detectar oportunidades ().
- Seguimiento de Inventario y Stock: Monitorea el estado de existencias para optimizar tu cadena de suministro o aprovechar faltantes de la competencia ().
- Análisis de Opiniones y Sentimiento del Cliente: Agrupa y analiza reseñas para mejorar productos o detectar problemas ().
- Marketing y Creación de Contenidos: Descubre qué productos son “Bestseller”, cómo se presentan y qué contenido impulsa las ventas ().
- Análisis de Vendedores y Proveedores: Identifica a los mejores vendedores externos o listados no autorizados ().
Aquí tienes una tabla resumen de los casos de uso, quién se beneficia y qué obtienes:
| Caso de Uso | Quién se Beneficia | Beneficios y ROI |
|---|---|---|
| Monitoreo de Precios | Equipos de Precios y Ventas | Precios de la competencia en tiempo real, precios dinámicos, protección de márgenes |
| Análisis de Surtido y Catálogo | Gestión de Producto, Merchandising | Detectar vacíos, lanzar nuevos productos, mejorar el catálogo |
| Seguimiento de Stock | Operaciones y Cadena de Suministro | Mejor pronóstico de demanda, evitar quiebres de stock, optimizar distribución |
| Opiniones y Sentimiento | Desarrollo de Producto, Experiencia Cliente | Mejoras basadas en datos, mayor satisfacción |
| Tendencias de Mercado y Analítica | Estrategia e Investigación de Mercado | Detectar tendencias, tomar decisiones estratégicas, entrar en nuevos segmentos |
| Estrategia de Contenido y Precios | Marketing y E-commerce | Refinar precios, aprender de contenido exitoso |
| Monitoreo de Vendedores | Ventas y Alianzas | Encontrar socios, proteger marca, vigilar vendedores no autorizados |
En resumen: el scraping de Walmart te ahorra tiempo, te ayuda a ganar más y te da ventaja con los datos. En vez de revisar 50 páginas cada mañana, tu script puede extraer miles de listados en minutos ().
El scraping de Walmart marca un antes y un después para equipos de e-commerce, ventas e investigación de mercado. Con las herramientas adecuadas, puedes automatizar la recolección de datos y dedicarte a analizar, no a hacer tareas repetitivas.
Scraping de Walmart con Python: Lo Que Necesitas
Antes de arrancar, deja tu entorno de Python listo. Esto es lo que vas a necesitar:
- Python 3.9 o superior (te recomiendo 3.11 o 3.12 si ya estamos en 2025)
- Requests: Para descargar páginas web
- BeautifulSoup (bs4): Para analizar HTML
- pandas: Para organizar y exportar datos
- json: Para manejar datos JSON (ya viene con Python)
- Un navegador con herramientas de desarrollador: Para inspeccionar la estructura de las páginas de Walmart (F12 es tu mejor amigo)
- pip: Para instalar paquetes de Python
Instala todo rápido con:
1pip install requests beautifulsoup4 pandasOpcional: Si quieres tener todo ordenado, crea un entorno virtual:
1python3 -m venv walmart-scraper
2source walmart-scraper/bin/activate # En Mac/Linux
3# o
4walmart-scraper\\Scripts\\activate.bat # En WindowsHaz una prueba rápida:
1import requests, bs4, pandas
2print("¡Librerías cargadas correctamente!")Si ves ese mensaje, ya estás listo.
Paso 1: Configura tu Walmart Scraper en Python
Organízate así:
- Crea una carpeta de proyecto (por ejemplo,
walmart_scraper/). - Abre tu editor de código (VSCode, PyCharm o el que prefieras).
- Crea un nuevo script (por ejemplo,
walmart_scraper.py).
Aquí tienes una plantilla básica para arrancar:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pd
4import jsonYa puedes pasar a lo bueno: descargar páginas de productos de Walmart.
Paso 2: Descarga Páginas de Productos de Walmart con Python
Para hacer scraping de Walmart, necesitas conseguir el HTML de la página del producto. Pero ojo: Walmart es muy estricto bloqueando bots. Si usas solo requests.get(url), probablemente te salga un “¿Eres un robot o un humano?” antes de que puedas decir “precios bajos”.
¿El truco? Simular un navegador real. Eso significa poner cabeceras como User-Agent y Accept-Language para parecerte a Chrome o Firefox.
Así se hace:
1headers = {
2 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
3 "Accept-Language": "en-US,en;q=0.9"
4}
5response = requests.get(url, headers=headers)
6html = response.textTip: Usa requests.Session() para mantener cookies y parecer aún más humano:
1session = requests.Session()
2session.headers.update(headers)
3session.get("<https://www.walmart.com/>") # Visita la página principal para establecer cookies
4response = session.get(product_url)Siempre revisa response.status_code (debe ser 200). Si ves una página rara o un CAPTCHA, baja la velocidad, cambia de IP o espera un rato. El sistema anti-bots de Walmart va en serio ().
Cómo Evitar los Filtros Anti-Bot de Walmart
Walmart usa herramientas como Akamai y PerimeterX para detectar bots revisando tu IP, cabeceras, cookies e incluso tu huella digital TLS. Para pasar desapercibido:
- Pon cabeceras realistas (como arriba).
- Espacia tus peticiones—espera entre 3 y 6 segundos entre cada página.
- Varía los tiempos de espera para no parecer un robot hiperactivo.
- Rota proxies si vas a hacer scraping a lo grande (más adelante te cuento).
- Si ves un CAPTCHA, para—no intentes forzar el acceso.
Si quieres ir más allá, librerías como curl_cffi pueden hacer que tus peticiones en Python se parezcan aún más a las de Chrome (). Pero para la mayoría, con cabeceras y paciencia basta.
Paso 3: Extrae Datos de Productos de Walmart con BeautifulSoup
Ahora viene lo bueno: sacar los datos que te interesan. El sitio de Walmart está hecho con Next.js, así que la mayoría de la info de productos está en una etiqueta <script id="__NEXT_DATA__"> como un gran JSON.
Así puedes extraerlo:
1from bs4 import BeautifulSoup
2import json
3soup = BeautifulSoup(html, "html.parser")
4script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
5if script_tag:
6 json_text = script_tag.string
7 data = json.loads(json_text)Ahora tienes un diccionario de Python con toda la info del producto. Normalmente, los detalles están en:
1product_data = data["props"]["pageProps"]["initialData"]["data"]["product"]Luego, saca lo que necesites:
1name = product_data.get("name")
2price_info = product_data.get("price", {})
3current_price = price_info.get("price")
4currency = price_info.get("currency")
5rating_info = product_data.get("rating", {})
6average_rating = rating_info.get("averageRating")
7review_count = rating_info.get("numberOfReviews")
8description = product_data.get("shortDescription") or product_data.get("description")¿Por qué usar el JSON? Porque es estructurado, robusto y menos propenso a fallar si Walmart cambia el HTML. Además, puedes acceder a detalles que a veces ni siquiera se ven en la página ().
Trabajando con Contenido Dinámico y Datos JSON
A veces, cosas como reseñas o stock se cargan dinámicamente vía JavaScript o llamadas a APIs. La buena noticia: el JSON inicial suele tener lo que necesitas. Si no, revisa la pestaña Network en las herramientas de desarrollador para encontrar los endpoints de API que usa Walmart y replica esas peticiones.
Pero para la mayoría de los datos de producto, el JSON de __NEXT_DATA__ es tu mejor amigo.
Paso 4: Guarda y Exporta los Datos de Walmart
Una vez que tienes los datos, guárdalos en un formato estructurado—CSV, Excel o JSON son buenas opciones. Así lo haces con pandas:
1import pandas as pd
2product_record = {
3 "Nombre del Producto": name,
4 "Precio (USD)": current_price,
5 "Calificación": average_rating,
6 "Cantidad de Reseñas": review_count,
7 "Descripción": description
8}
9df = pd.DataFrame([product_record])
10df.to_csv("walmart_products.csv", index=False)Si extraes varios productos, solo agrega cada registro a una lista y crea el DataFrame al final.
¿Prefieres Excel? Usa df.to_excel("walmart_products.xlsx", index=False) (asegúrate de tener openpyxl). Para JSON: df.to_json("walmart_products.json", orient="records", indent=2).
Tip: Revisa siempre tus datos exportados para asegurarte de que coinciden con la web. Nada peor que pensar que extrajiste 1,000 precios y que todos sean “None” porque Walmart cambió un nombre de campo.
Paso 5: Escala tu Walmart Scraper
¿Listo para ir a lo grande? Así puedes extraer varios productos:
1product_urls = [
2 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
3 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
4 # ...más URLs
5]
6all_records = []
7for url in product_urls:
8 resp = session.get(url)
9 # ...analiza y extrae como antes...
10 all_records.append(product_record)
11 time.sleep(random.uniform(3, 6)) # ¡Sé educado!Si no tienes una lista de URLs, puedes empezar desde una página de resultados de búsqueda, extraer los enlaces de productos y luego procesar cada uno ().
Pero ojo: Extraer cientos o miles de páginas rápido casi seguro hará que bloqueen tu IP. Ahí es donde entran los proxies.
Uso de Proxies y APIs de Scraper para Walmart
Los proxies te permiten rotar tu dirección IP, haciendo más difícil que Walmart te bloquee. Puedes comprar proxies residenciales (que parecen usuarios reales) o usar pools de proxies. Así se usan con requests:
1proxies = {
2 "http": "<http://tu.proxy.direccion>:puerto",
3 "https": "<https://tu.proxy.direccion>:puerto"
4}
5response = session.get(url, proxies=proxies)Para scraping a gran escala, quizá prefieras usar una API de scraper—estos servicios gestionan proxies, CAPTCHAs e incluso el renderizado JavaScript por ti. Solo envías la URL de Walmart y recibes los datos (a veces ya en JSON).
Aquí tienes una comparación rápida:
| Enfoque | Ventajas | Desventajas | Ideal para |
|---|---|---|---|
| Python + Proxies DIY | Control total, económico para tareas pequeñas | Mantenimiento, coste de proxies, riesgo de bloqueos | Desarrolladores, necesidades personalizadas |
| API de Scraper de Terceros | Fácil, gestiona anti-bots, escala bien | Coste a gran escala, menos flexibilidad, dependencia externa | Empresas, grandes volúmenes, resultados rápidos |
Si no eres desarrollador o solo quieres los datos rápido, herramientas como la hacen todo esto en un par de clics—sin código, sin proxies, sin líos. (Más sobre esto en breve.)
Retos Comunes en el Scraping de Walmart (y Cómo Solucionarlos)
El scraping de Walmart no es solo precios bajos y ofertas. Estos son los problemas más frecuentes—y cómo resolverlos:
- Medidas Anti-Bot Avanzadas: Walmart detecta bots por IP, cabeceras, cookies, huella TLS y JavaScript. Solución: Cabeceras realistas, sesiones, pausas y rotación de proxies ().
- CAPTCHAs: Si te aparece un CAPTCHA, espera y reintenta más tarde. Si es recurrente, considera servicios para resolver CAPTCHAs, aunque añaden coste y complejidad ().
- Cambios en la Estructura del Sitio: Walmart actualiza su web con frecuencia. Si tu scraper falla, revisa la estructura del JSON y actualiza tu código. Un código modular ayuda mucho.
- Paginación y Subpáginas: Para grandes volúmenes, gestiona la paginación con bucles y condiciones de parada. Verifica siempre si llegaste al final ().
- Volumen de Datos y Límites de Tasa: Si extraes mucho, haz lotes y guarda resultados parciales. No intentes cargar 100,000 productos en memoria de una vez.
- Cuestiones Legales y Éticas: Solo extrae datos públicos, respeta los términos de Walmart y no sobrecargues sus servidores. Si tu negocio depende de estos datos, revisa la normativa.
¿Cuándo cambiar a una solución gestionada? Si pasas más tiempo peleando con CAPTCHAs que analizando datos, quizá sea momento de usar una herramienta como Thunderbit o una API de scraper. Para quienes no programan, las herramientas no-code suelen ser la mejor opción ().
Scraping de Walmart con Python: Código de Ejemplo Completo
Vamos a juntar todo. Aquí tienes un script completo y comentado para extraer productos de Walmart:
1import requests
2from bs4 import BeautifulSoup
3import json
4import pandas as pd
5import time
6import random
7# Configura sesión y cabeceras
8session = requests.Session()
9session.headers.update({
10 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/115.0 Safari/537.36",
11 "Accept-Language": "en-US,en;q=0.9"
12})
13# Visita la página principal para establecer cookies
14session.get("<https://www.walmart.com/>")
15# Lista de URLs de productos a extraer
16product_urls = [
17 "<https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/720559357>",
18 "<https://www.walmart.com/ip/SAMSUNG-65-Class-QLED-4K-Q60C/180355997>",
19 # Agrega más URLs según necesites
20]
21all_products = []
22for url in product_urls:
23 try:
24 response = session.get(url)
25 except Exception as e:
26 print(f"Error de petición para \{url\}: \{e\}")
27 continue
28 if response.status_code != 200:
29 print(f"No se pudo obtener \{url\} (estado \{response.status_code\})")
30 continue
31 soup = BeautifulSoup(response.text, "html.parser")
32 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
33 if not script_tag:
34 print(f"No se encontró el script de datos para \{url\} - posiblemente bloqueado o formato cambiado.")
35 continue
36 try:
37 data = json.loads(script_tag.string)
38 except json.JSONDecodeError as e:
39 print(f"Error al parsear JSON para \{url\}: \{e\}")
40 continue
41 try:
42 product_info = data["props"]["pageProps"]["initialData"]["data"]["product"]
43 except KeyError:
44 print(f"No se encontró información de producto en el JSON para \{url\}.")
45 continue
46 name = product_info.get("name")
47 brand = product_info.get("brand", {}).get("name") or product_info.get("brand", "")
48 price_obj = product_info.get("price", {})
49 price = price_obj.get("price")
50 currency = price_obj.get("currency")
51 orig_price = price_obj.get("priceStrikethrough") or price_obj.get("price_strikethrough")
52 rating_obj = product_info.get("rating", {})
53 avg_rating = rating_obj.get("averageRating")
54 review_count = rating_obj.get("numberOfReviews")
55 desc = product_info.get("description") or product_info.get("shortDescription") or ""
56 product_record = {
57 "URL": url,
58 "Nombre": name,
59 "Marca": brand,
60 "Precio": price,
61 "Moneda": currency,
62 "PrecioOriginal": orig_price,
63 "CalificaciónPromedio": avg_rating,
64 "CantidadReseñas": review_count,
65 "Descripción": desc
66 }
67 all_products.append(product_record)
68 # Pausa aleatoria para evitar detección
69 time.sleep(random.uniform(3.0, 6.0))
70df = pd.DataFrame(all_products)
71print(df.head(5))
72df.to_csv("walmart_scrape_output.csv", index=False)Personaliza:
- Agrega más URLs a
product_urls. - Ajusta los campos que extraes según lo que necesites.
- Modifica el tiempo de espera según tu tolerancia al riesgo.
Conclusión y Puntos Clave
Resumamos lo aprendido:
- El scraping de Walmart es una forma potente de acceder a datos de precios, productos y reseñas—clave para inteligencia competitiva, precios y desarrollo de productos en 2025.
- Python es tu mejor aliado: Con Requests, BeautifulSoup y pandas puedes crear un raspador web robusto, incluso si no eres experto en código.
- Las defensas anti-bot son reales: Simula cabeceras de navegador, usa sesiones, añade pausas y rota proxies si escalas.
- Extrae datos del JSON
__NEXT_DATA__: Es más limpio, robusto y menos propenso a fallos que extraer etiquetas HTML. - Exporta tus datos para analizarlos: Usa pandas para guardar en CSV, Excel o JSON.
- Escala con cuidado: Para grandes volúmenes, considera proxies o una API de scraper. Si no eres técnico, puede manejar Walmart (y otros sitios) en un par de clics—sin código. Incluso puedes exportar directamente a Excel, Google Sheets, Airtable o Notion gratis ().
Mi consejo:
Empieza de a poco—extrae un solo producto, luego unos cuantos. Asegúrate de que tus datos sean correctos. Respeta los términos de Walmart y no sobrecargues sus servidores. Si tus necesidades crecen, considera pasar a herramientas gestionadas o APIs para ahorrarte tiempo y dolores de cabeza. Y si te cansas de debuggear Python, recuerda: con Thunderbit puedes extraer datos de Walmart (y casi cualquier web) en dos clics, con IA haciendo todo el trabajo pesado ().
¿Quieres profundizar en scraping web, automatización de datos o productividad con IA? Descubre más guías en el .
¡Feliz scraping! Que tus datos siempre sean frescos, precisos y libres de CAPTCHAs.
P.D. Si alguna vez te encuentras scrapeando Walmart a las 2am y murmurando frente a la pantalla, recuerda: hasta los mejores hemos pasado por ahí. Depurar es parte del crecimiento para quienes amamos los datos.
Preguntas Frecuentes
1. ¿Es legal extraer datos de Walmart usando Python?
Extraer datos públicos para análisis personal o no comercial suele estar bien, pero el uso empresarial puede tener implicaciones legales y éticas. Consulta siempre los términos de servicio de Walmart y asegúrate de no violar límites de uso, sobrecargar sus servidores ni recolectar datos sensibles.
2. ¿Qué tipo de datos puedo extraer de Walmart con Python?
Puedes obtener nombres de productos, precios, marcas, descripciones, reseñas de clientes, calificaciones, estado de stock y más—especialmente analizando el JSON estructurado en la etiqueta <script id="__NEXT_DATA__"> de Walmart.
3. ¿Cómo evito ser bloqueado al hacer scraping de Walmart?
Usa cabeceras realistas, mantén sesiones, añade pausas aleatorias entre peticiones (3–6 segundos), rota proxies y evita hacer demasiadas peticiones en poco tiempo. Para proyectos grandes, considera APIs de scraper o herramientas como Thunderbit que gestionan la detección anti-bot automáticamente.
4. ¿Puedo escalar para extraer cientos o miles de productos de Walmart?
Sí, pero deberás gestionar proxies, implementar límites de velocidad y quizá usar una API de scraper para mayor eficiencia. Walmart tiene defensas anti-bot robustas, así que escalar sin preparación puede resultar en bloqueos o CAPTCHAs.
5. ¿Cuál es la forma más fácil de extraer datos de Walmart si no sé programar?
Herramientas como la extensión de Chrome Thunderbit AI Web Scraper te permiten extraer productos de Walmart sin escribir una sola línea de código. Gestiona protecciones anti-bot, permite exportar datos a Excel, Notion y Sheets, y es ideal para equipos de negocio o usuarios sin experiencia técnica.