La web está llena de datos—tanto que se espera que el mercado global de software de 웹 스크래퍼 llegue a los . Ya seas analista de negocios, marketero o simplemente alguien curioso, saber extraer datos de una página web se ha vuelto una habilidad clave. Y si eres como yo, seguro quieres saltarte el copiar y pegar y pasar directo a lo bueno: conseguir información útil, hojas de cálculo limpias y, por qué no, un poco de automatización.
Aquí es donde Python se vuelve tu mejor amigo. Es como el cuchillo multiusos para los datos: fácil para quienes recién empiezan, pero lo suficientemente potente para tareas que van desde extraer una sola página hasta rastrear miles. En este tutorial práctico, te voy a guiar por lo básico del tutorial de web scraping con Python, te mostraré cómo lidiar con sitios dinámicos y te presentaré , nuestro Raspador Web IA sin código, que hace que extraer datos sea tan fácil como pedir delivery. Ya sea que quieras aprender a programar o prefieras una solución rápida, aquí vas a encontrar lo que buscas.
¿Qué es el 웹 스크래퍼 y por qué usar Python para extraer datos de una web?
El 웹 스크래퍼 es el proceso automático de sacar información de páginas web y convertirla en un formato ordenado—como hojas de cálculo, archivos CSV o bases de datos—para analizarla o usarla en tu negocio (). En vez de copiar y pegar a mano, un 웹 스크래퍼 imita lo que haría una persona, pero a toda velocidad y en gran escala.
¿Y por qué es tan valioso? Porque hoy, tomar decisiones basadas en datos es fundamental. El confía en los datos (muchos de ellos extraídos) para definir desde precios hasta estudios de mercado y generación de leads. Imagina poder monitorear los precios de la competencia todos los días, recolectar listados inmobiliarios o armar tu propia base de clientes potenciales—todo sin despeinarte.
¿Y por qué Python? Aquí te van las razones por las que es el lenguaje favorito para el tutorial de web scraping:
- Fácil de leer y escribir: La sintaxis de Python es clara y directa, perfecta para scripts de scraping ().
- Ecosistema potente: Bibliotecas como
requests,BeautifulSoup,ScrapyySeleniumhacen que extraer, analizar y automatizar acciones en el navegador sea pan comido. - Comunidad gigante: Python es , así que siempre vas a encontrar tutoriales, foros y ejemplos de código.
- Escalable: Python aguanta desde scripts sencillos hasta rastreadores de datos enormes.
En resumen: Python es tu puerta de entrada al mundo de los datos web, tanto si recién arrancás como si ya tenés cancha.
Primeros pasos: Conceptos básicos del tutorial de web scraping con Python
Antes de meternos con el código, repasemos el paso a paso para extraer datos de una web con Python:
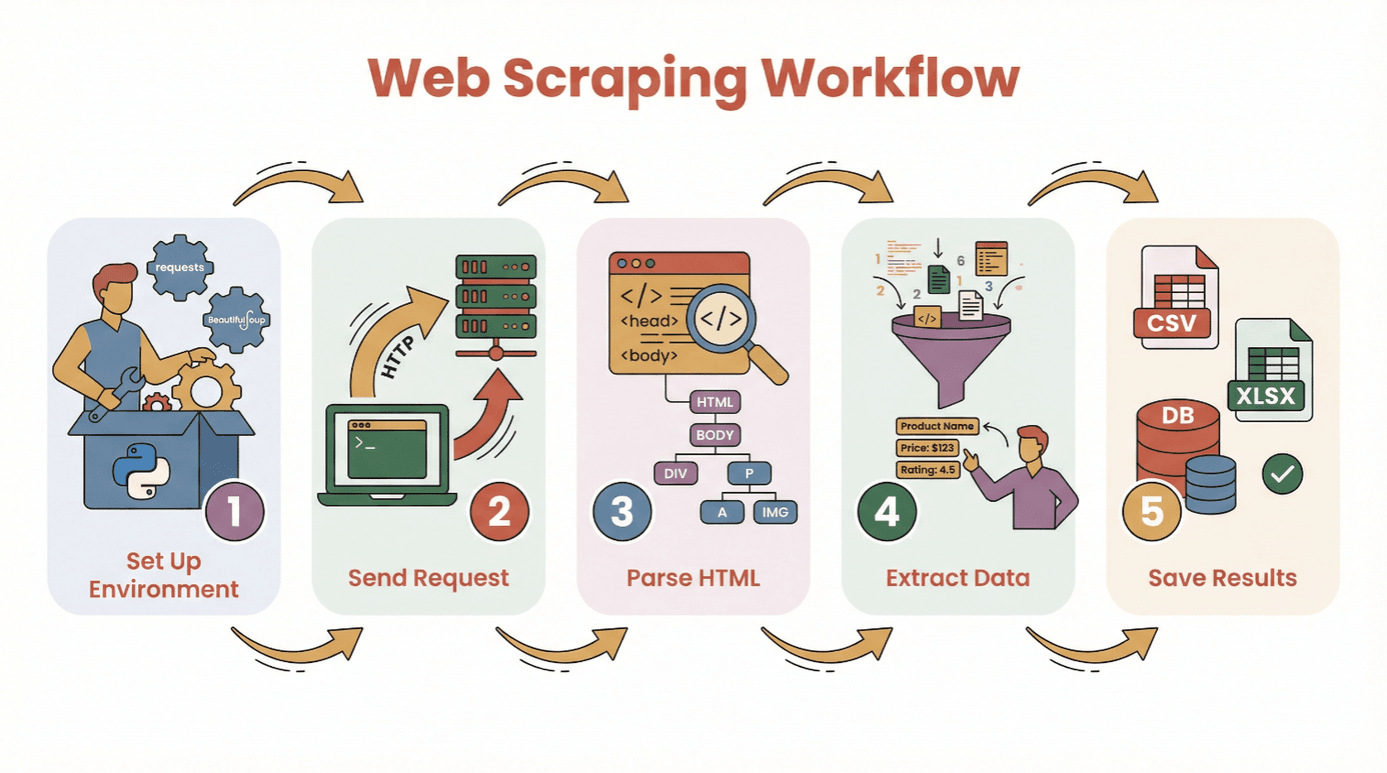
- Prepara tu entorno: Instalá Python y las bibliotecas necesarias (
requests,BeautifulSoup, etc.). - Hacé una solicitud: Usá Python para traer el HTML de la página que te interesa.
- Analizá el HTML: Usá un parser para navegar la estructura de la página.
- Extraé los datos: Encontrá y sacá la info que necesitás.
- Guardá los resultados: Mandá los datos a un archivo CSV, Excel o base de datos para analizarlos.
No hace falta ser un crack de la programación para empezar. Si sabés instalar Python y correr un script, ya tenés medio camino hecho. Para quienes recién arrancan, recomiendo usar un o un notebook de Jupyter, aunque cualquier editor de texto sirve.
Bibliotecas clave:
requests— para traer páginas webBeautifulSoup— para analizar HTMLpandas— para guardar y limpiar datos (opcional, pero muy útil)
¿Qué biblioteca de Python elegir para web scraping: BeautifulSoup, Scrapy o Selenium?
No todas las herramientas de scraping en Python son iguales. Acá te dejo un resumen de las tres más populares:
| Herramienta | Ideal para | Ventajas | Desventajas |
|---|---|---|---|
| BeautifulSoup | Páginas simples y estáticas; principiantes | Fácil de usar, configuración mínima, buena documentación | No es ideal para grandes volúmenes o contenido dinámico |
| Scrapy | Rastreo a gran escala, múltiples páginas | Rápido, asincrónico, pipelines integrados, gestiona rastreo y almacenamiento | Curva de aprendizaje mayor, excesivo para tareas pequeñas, no ejecuta JS |
| Selenium | Sitios dinámicos/con JavaScript, automatización | Puede renderizar JS, simula acciones de usuario, soporta logins y clics | Más lento, consume más recursos, configuración más compleja |
BeautifulSoup: La opción ideal para analizar HTML sencillo
BeautifulSoup es perfecta para quienes recién empiezan y para proyectos chicos. Te deja analizar HTML y extraer elementos con pocas líneas de código. Si el sitio es estático (sin JavaScript complicado), BeautifulSoup junto con requests te alcanza y sobra.
Ejemplo:
1import requests
2from bs4 import BeautifulSoup
3url = "https://example.com"
4response = requests.get(url)
5soup = BeautifulSoup(response.text, 'html.parser')
6titles = [h2.text for h2 in soup.find_all('h2', class_='product-title')]
7print(titles)Cuándo usarla: Extracciones puntuales, blogs simples, páginas de productos o directorios.
Scrapy: Para rastreos grandes o estructurados
Scrapy es un framework completo para rastrear sitios enteros o manejar miles de páginas. Es asincrónico (o sea, rapidísimo), te deja limpiar y guardar datos fácil, y sigue enlaces automáticamente.
Ejemplo:
1import scrapy
2class ProductSpider(scrapy.Spider):
3 name = "products"
4 start_urls = ["https://example.com/products"]
5 def parse(self, response):
6 for item in response.css('div.product'):
7 yield {
8 'name': item.css('h2::text').get(),
9 'price': item.css('span.price::text').get()
10 }Cuándo usarla: Proyectos grandes, rastreos programados o cuando necesitás velocidad y estructura.
Selenium: Para sitios dinámicos y con JavaScript
Selenium controla un navegador real (como Chrome o Firefox), así que puede manejar sitios que cargan datos con JavaScript, requieren login o necesitan interacción.
Ejemplo:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3driver = webdriver.Chrome()
4driver.get("https://example.com/login")
5driver.find_element(By.NAME, "username").send_keys("myuser")
6driver.find_element(By.NAME, "password").send_keys("mypassword")
7driver.find_element(By.XPATH, "//button[@type='submit']").click()
8dashboard = driver.find_element(By.ID, "dashboard").text
9print(dashboard)
10driver.quit()Cuándo usarla: Redes sociales, sitios de bolsa, scroll infinito o cualquier página que se vea vacía al ver el código fuente.
Paso a paso: Cómo extraer datos de una web con Python (tutorial para principiantes)
Vamos a ver un ejemplo real usando requests y BeautifulSoup. Vamos a extraer títulos y precios de un sitio de libros.
Paso 1: Prepara tu entorno de Python
Primero, instalá las bibliotecas necesarias:
1pip install requests beautifulsoup4 pandasDespués, importalas en tu script:
1import requests
2from bs4 import BeautifulSoup
3import pandas as pdPaso 2: Hacé una solicitud a la web
Traé el HTML de la página:
1url = "http://books.toscrape.com/catalogue/page-1.html"
2response = requests.get(url)
3if response.status_code == 200:
4 html = response.text
5else:
6 print(f"No se pudo obtener la página: \{response.status_code\}")Paso 3: Analizá el contenido HTML
Creá un objeto BeautifulSoup:
1soup = BeautifulSoup(html, 'html.parser')Buscá todos los contenedores de libros:
1books = soup.find_all('article', class_='product_pod')
2print(f"Se encontraron {len(books)} libros en esta página.")Paso 4: Extraé los datos que necesitás
Recorré cada libro y sacá los detalles:
1data = []
2for book in books:
3 title = book.h3.a['title']
4 price = book.find('p', class_='price_color').text
5 data.append({"Título": title, "Precio": price})Paso 5: Guardá los datos para analizarlos
Convertí a DataFrame y guardá:
1df = pd.DataFrame(data)
2df.to_csv('books.csv', index=False)¡Listo! Ahora tenés un archivo CSV limpio para analizar.
Tips para solucionar problemas:
- Si te salen resultados vacíos, fijate si los datos se cargan con JavaScript (ver la siguiente sección).
- Inspeccioná la estructura HTML con las herramientas de desarrollador del navegador.
- Manejá datos faltantes con
get_text(strip=True)y condicionales.
Cómo extraer datos de sitios con contenido dinámico (JavaScript)
Muchos sitios modernos usan JavaScript para cargar datos. Si tu 웹 스크래퍼 no encuentra nada, probablemente sea por esto.
¿Cómo lo resolvés?
- Selenium: Simula un navegador real, espera a que cargue el contenido y puede hacer clics o scroll.
- Playwright/Puppeteer: Más avanzados, pero la idea es la misma (navegadores sin interfaz).
Mini guía de Selenium:
- Instalá Selenium y un driver de navegador (por ejemplo, ChromeDriver).
- Usá esperas explícitas para que cargue el contenido.
- Extraé el HTML renderizado y analizalo con BeautifulSoup si hace falta.
Ejemplo:
1from selenium import webdriver
2from selenium.webdriver.common.by import By
3from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5driver = webdriver.Chrome()
6driver.get("https://example.com/dynamic")
7WebDriverWait(driver, 10).until(
8 EC.presence_of_element_located((By.CLASS_NAME, "dynamic-content"))
9)
10html = driver.page_source
11soup = BeautifulSoup(html, 'html.parser')
12# Extraé los datos como antes
13driver.quit()¿Cuándo necesitás Selenium?
- Si
requests.get()te devuelve HTML vacío, pero los datos sí aparecen en el navegador. - Si el sitio tiene scroll infinito, pop-ups o requiere login.
Simplificá el web scraping con IA: Usá Thunderbit para extraer datos de una web
Seamos sinceros: a veces solo querés los datos, no el código. Para eso está . Thunderbit es una extensión de Chrome con IA que te deja extraer datos de cualquier web en un par de clics—sin necesidad de Python.
¿Cómo funciona Thunderbit?
- Instalá la .
- Abrí la web que te interesa.
- Hacé clic en el icono de Thunderbit y tocá “AI Suggest Fields”. La IA analiza la página y te sugiere qué datos extraer (por ejemplo, nombres de productos, precios, emails).
- Ajustá los campos si hace falta y hacé clic en “Scrape”.
- Exportá tus datos directo a Excel, Google Sheets, Notion o Airtable.
¿Por qué Thunderbit está buenísimo?
- No necesitás programar. Hasta mi mamá puede usarlo (y todavía me llama por el Wi-Fi).
- Maneja subpáginas y paginación. ¿Querés extraer detalles de productos en varias páginas? Thunderbit navega y une los datos por vos.
- Instrucciones en lenguaje natural. Solo decile lo que querés (“extraé todos los títulos y precios de productos”) y dejá que la IA lo resuelva.
- Plantillas instantáneas para sitios populares. Amazon, Zillow, LinkedIn y más—un clic y listo.
- Exportación gratuita de datos. Bajá en CSV, Excel o mandá directo a tus herramientas favoritas.
Thunderbit ya lo usan más de , y el plan gratis te deja extraer hasta 6 páginas (o 10 con un impulso de prueba). Para empresas, ahorra muchísimo tiempo—y para usuarios técnicos, es ideal para prototipar antes de armar tu propio 웹 스크래퍼 en Python.
Después del scraping: Limpieza y análisis de datos con Pandas y NumPy
Extraer datos es solo el primer paso. Los datos web suelen venir desordenados—duplicados, valores faltantes, formatos raros. Acá es donde brillan las bibliotecas pandas y NumPy de Python.
Tareas comunes de limpieza:
- Eliminar duplicados:
df.drop_duplicates(inplace=True) - Manejar valores faltantes:
df.fillna('Desconocido')odf.dropna() - Convertir tipos de datos:
df['Precio'] = df['Precio'].str.replace('$','').astype(float) - Parsear fechas:
df['Fecha'] = pd.to_datetime(df['Fecha']) - Filtrar valores atípicos:
df = df[df['Precio'] > 0]
Análisis básico:
- Estadísticas resumidas:
df.describe() - Agrupar por categoría:
df.groupby('Categoría')['Precio'].mean() - Gráficas rápidas:
df['Precio'].hist()odf.groupby('Categoría')['Precio'].mean().plot(kind='bar')
Para operaciones matemáticas más avanzadas o manejo rápido de arrays, NumPy es tu aliado. Pero para la mayoría de los que trabajan con datos, pandas cubre casi todo lo necesario.
Recursos: Si recién arrancás con pandas, mirá la guía .
Buenas prácticas y consejos para un web scraping exitoso con Python
El 웹 스크래퍼 es poderoso, pero hay que usarlo con responsabilidad. Acá va mi checklist para hacerlo bien (y evitar bloqueos o líos legales):
- Respetá robots.txt y los Términos de Servicio. Siempre fijate si el sitio permite scraping ().
- No satures los servidores. Agregá pausas entre solicitudes (
time.sleep(2)) y comportate como un usuario real. - Usá cabeceras realistas. Configurá el User-Agent para simular un navegador.
- Manejá errores correctamente. Usá bloques try/except y reintentá solicitudes fallidas.
- Rotá proxies si hace falta. Para scraping a gran escala, usá pools de proxies para evitar bloqueos de IP.
- Sé ético y legal. No extraigas datos personales ni contenido protegido sin permiso.
- Documentá tu proceso. Llevá registro de qué datos sacaste, de dónde y cuándo.
- Usá APIs oficiales si existen. A veces es mejor que raspar HTML.
Para más consejos, revisá la .
Conclusión y puntos clave
El tutorial de web scraping con Python es una herramienta tremenda para convertir el caos de la web en datos útiles y ordenados. Ya sea programando (con requests, BeautifulSoup, Scrapy o Selenium) o usando una herramienta sin código como , tenés todo lo necesario para extraer datos de una web y descubrir nuevas oportunidades.
Recordá:
- Empezá por lo simple—extraé una sola página antes de lanzarte a proyectos grandes.
- Elegí la herramienta adecuada (BeautifulSoup para lo básico, Scrapy para escala, Selenium para sitios dinámicos, Thunderbit para no programar).
- Limpiá y analizá tus datos con pandas y NumPy.
- Hacé scraping siempre de forma ética y responsable.
¿Listo para probar? Arrancá con un proyecto chico—por ejemplo, extraé los titulares del día o una lista de productos—y vas a ver lo rápido que pasás de una web desordenada a una hoja de cálculo ordenada. Y si preferís evitar el código, y dejá que la IA haga el trabajo pesado.
Para más tutoriales, tips y recursos sobre web scraping, pasate por el .
Preguntas frecuentes
1. ¿Qué es el web scraping y por qué Python es tan popular para ello?
El web scraping es la extracción automática de datos de páginas web. Python es popular porque su sintaxis es fácil de leer, tiene bibliotecas potentes (como BeautifulSoup, Scrapy y Selenium) y una comunidad muy activa ().
2. ¿Qué biblioteca de Python uso para web scraping?
Usá BeautifulSoup para páginas simples y estáticas; Scrapy para rastreos grandes o de varias páginas; y Selenium para sitios dinámicos o con mucho JavaScript. Cada una tiene ventajas según lo que necesites ().
3. ¿Cómo manejo sitios que cargan datos con JavaScript?
Para contenido generado por JavaScript, usá Selenium (o Playwright) para simular un navegador y esperar a que cargue el contenido antes de extraer los datos. A veces podés encontrar una API revisando el tráfico de red.
4. ¿Qué es Thunderbit y cómo simplifica el web scraping?
es una extensión de Chrome con IA que te deja extraer datos de cualquier web sin programar. Usa IA para sugerir campos, maneja subpáginas y paginación, y exporta datos directo a Excel, Google Sheets, Notion o Airtable.
5. ¿Cómo puedo limpiar y analizar los datos extraídos en Python?
Usá pandas para eliminar duplicados, manejar valores faltantes, convertir tipos de datos y analizar la información. NumPy es ideal para operaciones numéricas. Para visualizar, pandas se integra con Matplotlib para crear gráficos rápido ().
¡Feliz scraping! Que tus datos siempre estén limpios, ordenados y listos para usar.
Seguí aprendiendo