
Si necesitas datos web en 2026, la pregunta difícil ya no es "¿se puede extraer?" sino "¿qué capa de herramientas me da datos útiles con el menor gasto posible en configuración, mantenimiento e infraestructura?" Por eso esta página está organizada pensando primero en la adecuación: extractores web con IA para ir rápido, herramientas sin código para tareas repetibles en el navegador, APIs para escalar y lidiar con anti-bots, y bibliotecas de Python para equipos que quieren control total.
Respuesta rápida
- Elige un Raspador Web IA si quieres pasar de una página a una hoja de cálculo lo más rápido posible, con una configuración mínima.
- Elige un raspador sin código si necesitas más control explícito sobre la paginación, la programación, el manejo de inicios de sesión o las tareas repetitivas.
- Elige una API de scraping si el renderizado, la protección anti-bots, la concurrencia y la tasa de desbloqueo importan más que la sencillez de la interfaz.
- Elige una biblioteca de Python si tu equipo quiere controlar por completo las solicitudes, el parseo, la automatización del navegador, los reintentos y el despliegue.
Para la mayoría de los equipos de negocio, el error es bajar de nivel demasiado pronto. Empieza con la herramienta más ligera que pueda hacer el trabajo de forma fiable y luego pasa de IA a no code, de ahí a APIs y, por último, a código solo cuando tu flujo de trabajo lo exija.
Descarga aquí el paquete visual completo: .
Tabla comparativa rápida: herramientas para extraer sitios web de un vistazo
Las señales de precio de abajo se verificaron en las páginas oficiales de producto, precios o documentación el 12 de mayo de 2026. Cuando los proveedores usan facturación personalizada o basada en uso, describo el modelo de precios en lugar de forzar un número mensual falso de comparación directa.
| Herramienta | Categoría | Mejor para | Por qué entró en esta lista de 2026 | Señal de precio (verificada en mayo de 2026) |
|---|---|---|---|---|
| Thunderbit | Raspador Web IA | Ventas, operaciones, ecommerce, inmobiliaria | La forma más rápida y técnica de una página web a una tabla estructurada | Plan gratis, planes de pago, precios para empresas |
| Kadoa | Plataforma de extracción con IA | Equipos de datos y programas recurrentes de mayor tamaño | Muy buen encaje para flujos de extracción tipo agente y con autorreparación | Evaluación gratuita, planes por uso y para empresas |
| Octoparse | Raspador sin código | Analistas y tareas operativas recurrentes | Scraping en la nube maduro y generador visual de tareas | Plan gratis, Standard desde $69/mes, niveles superiores |
| ParseHub | Raspador de bajo código | Usuarios técnicos sin programar e investigadores | Lógica de navegación flexible para sitios más difíciles | Plan gratis, planes de pago desde $189/mes |
| Web Scraper | Raspador sin código para navegador | Principiantes y tareas ligeras repetibles | Modelo de sitemap sencillo con capa en la nube opcional | Extensión gratis, Cloud desde $50/mes |
| Browse AI | Raspador robot sin código | Equipos que priorizan el monitoreo y las hojas de cálculo | Muy fuerte para monitoreo repetible y alertas de cambios | Plan gratis, planes de pago, nivel gestionado |
| Bardeen | Automatización de navegador con IA | Automatización de GTM y revops | Ideal cuando extraer datos es solo un paso dentro de un flujo mayor | Plan gratis, Basic desde $10/mes, Premium y Enterprise |
| ScrapeStorm | Raspador visual asistido por IA | Usuarios que quieren una configuración visual rápida | Un puente útil entre selectores manuales y ayuda de IA | Prueba gratis, planes de pago, precios para empresas |
| ScraperAPI | API de scraping | Desarrolladores que escalan volumen de solicitudes | API sencilla más proxy, CAPTCHA y descarga de renderizado | Prueba de 7 días, planes de pago desde $49/mes |
| Bright Data Web Scraper | Plataforma de scraping empresarial | Programas con muchas compras y enfoque en cumplimiento | La pila de recopilación de datos más amplia del grupo | Precios por producto y por uso |
| Zyte | API + pila anti-bot | Equipos de desarrollo y de datos | Buenas acciones en navegador, renderizado JS y rotación de IP | Crédito de prueba de $5, planes por uso |
| ZenRows | API de scraping | Startups y equipos de desarrollo | API anti-bot limpia con adopción de baja fricción | Prueba gratis, Developer desde $69/mes |
| ScrapingBee | API de scraping | Equipos que extraen sitios con mucho JavaScript | Muy útil cuando el renderizado es el principal dolor de cabeza | Prueba gratis, planes de pago desde $49/mes |
| Selenium | Automatización de navegador de código abierto | Flujos tipo QA y scraping con mucha interacción | Sigue siendo relevante donde la interacción exacta importa | Gratis y de código abierto |
| Beautiful Soup | Biblioteca de parseo en Python | Scraping ligero en Python | El parser más fácil de la pila para HTML desordenado | Gratis y de código abierto |
| Playwright | Automatización de navegador moderna | Aplicaciones web modernas y equipos de desarrollo | La mejor opción moderna para scraping de navegador programado | Gratis y de código abierto |
| urllib3 | Biblioteca HTTP de Python | Desarrolladores que quieren control de solicitudes de bajo nivel | Base útil cuando quieres controlar directamente el comportamiento del transporte | Gratis y de código abierto |
Cómo elegir la herramienta adecuada para extraer sitios web
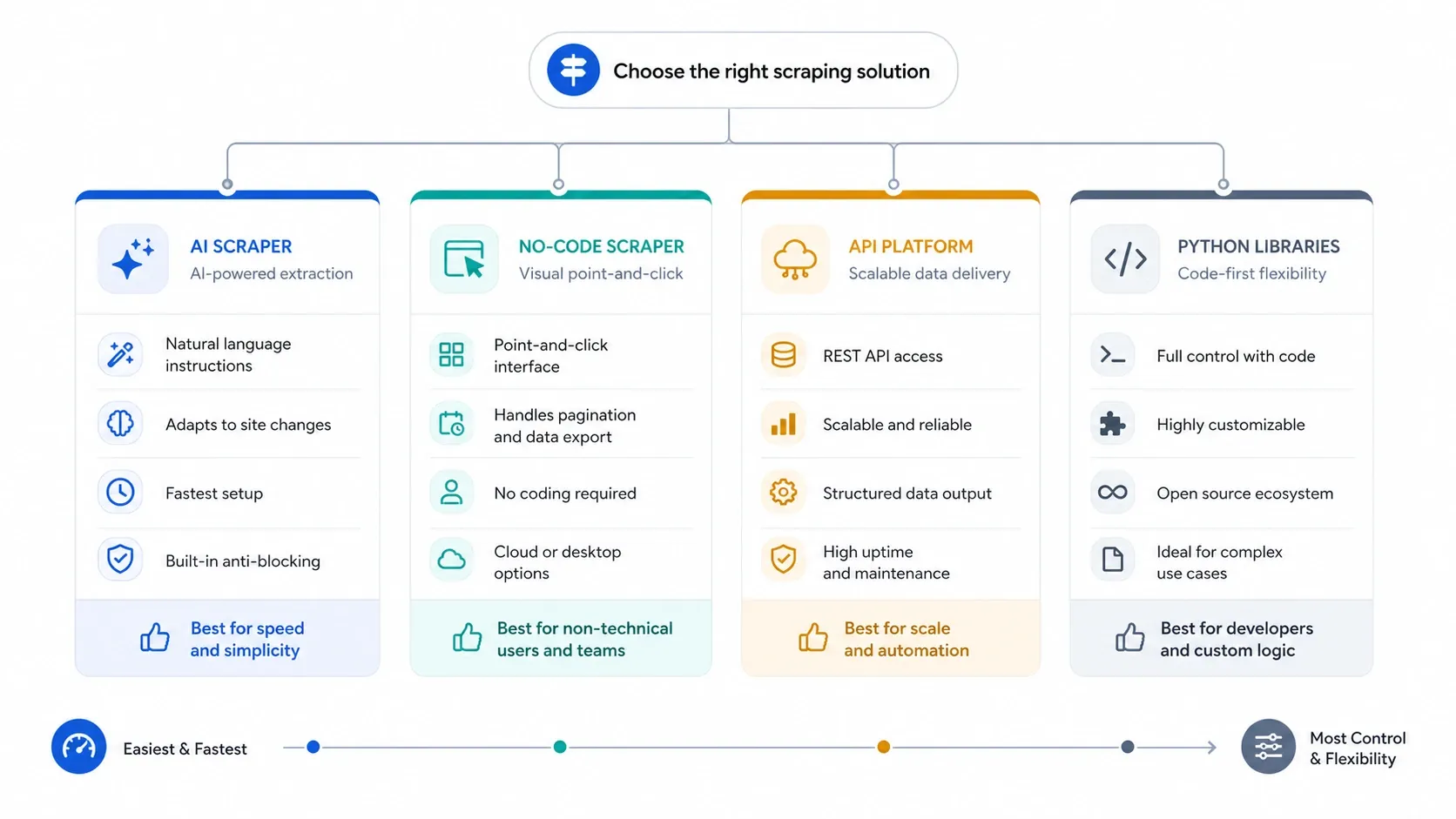
Usa cuatro filtros antes de comparar marcas:
- Tiempo hasta obtener el primer resultado útil
Si la herramienta no puede sacar una tabla real con rapidez, ya está perdiendo en la mayoría de los casos de negocio. - Carga de mantenimiento
Un raspador barato que se rompe cada vez que cambia el diseño no es realmente barato. - Techo de escala
Una extensión del navegador puede ser perfecta para 50 páginas a la semana y terrible para 5 millones de solicitudes mensuales. - Encaje con el flujo de trabajo
El mejor raspador para revops rara vez es el mejor para un ingeniero de plataforma.
El marco de decisión suele ser más simple de lo que los equipos imaginan:
- Si quieres extraer leads, listados o páginas de producto sin tocar selectores, empieza con IA.
- Si necesitas tareas repetibles, ejecuciones en la nube y un control más explícito, pasa a constructores visuales sin código.
- Si el verdadero problema es la anti-bot, el renderizado de JavaScript y la concurrencia, salta a APIs.
- Si quieres controlar cada capa por tu cuenta, usa bibliotecas de Python y asume la carga de mantenimiento.
Los mejores raspadores web con IA para flujos de trabajo rápidos
Esta es la primera categoría que probaría si lo que quieres es obtener datos listos para hoja de cálculo con la mínima configuración posible.
1. Thunderbit
Thunderbit sigue siendo el punto de partida más fácil para quienes no programan. La ventaja principal no es solo la "IA" en abstracto, sino que el producto comprime el ciclo de configuración. Abres una página, pides a la IA que sugiera campos, enriqueces mediante subpáginas cuando hace falta y envías el resultado directamente a las herramientas que tu equipo ya usa.
- Ideal para: prospección comercial, monitoreo de ecommerce, recopilación inmobiliaria y equipos de operaciones que viven dentro del navegador.
- Por qué destaca: la ruta más rápida de una página desordenada a una tabla estructurada.
- A tener en cuenta: si necesitas lógica de nivel crawler o flujos de ingeniería muy personalizados, acabarás pasando a APIs o código.
- Señal de precio: plan gratis, niveles de pago autoservicio y precios para empresas.
Este recorrido sigue siendo la forma más rápida de comprobar si el scraping con IA basta para tu flujo de trabajo:
2. Kadoa
Kadoa es la opción de IA más orientada a infraestructura dentro de este grupo. Tiene sentido cuando quieres extracción con autorreparación y tareas recurrentes a una escala operativa mayor de la que la mayoría de las extensiones del navegador están diseñadas para manejar.
- Ideal para: equipos de datos, programas internos de inteligencia y cargas de extracción recurrentes de mayor tamaño.
- Por qué destaca: orquestación tipo agente y una propuesta más sólida para reducir mantenimiento.
- A tener en cuenta: es más pesado de lo que la mayoría de usuarios de negocio necesita para scraping rápido de una sola vez.
- Señal de precio: evaluación gratuita, planes por uso y para empresas.
Las mejores herramientas de extracción web sin código para tareas repetibles
Cuando el trabajo de scraping pasa a ser recurrente, los constructores visuales de flujos y la ejecución en la nube empiezan a importar más que la velocidad pura de un clic.
3. Octoparse
Octoparse sigue siendo una de las herramientas sin código más creíbles cuando el trabajo es más grande que una extensión del navegador, pero todavía no un proyecto de ingeniería a medida. Su valor está en la combinación de ejecuciones en la nube, plantillas y un constructor visual de tareas maduro.
- Ideal para: analistas, equipos de precios y tareas recurrentes de recopilación con verdadera importancia operativa.
- Por qué destaca: más profundidad que los plugins del navegador, sin obligarte a programar.
- A tener en cuenta: pagas esa flexibilidad con una curva de aprendizaje más pronunciada que las herramientas centradas en IA.
- Señal de precio: plan gratis, Standard desde $69/mes, niveles de pago superiores.
Si quieres evaluar un espacio de trabajo sin código más tradicional antes de apostar por herramientas centradas en IA, este resumen oficial de Octoparse sigue siendo útil:
4. ParseHub
ParseHub sigue siendo relevante porque hay muchos equipos que quieren una lógica de tareas más paso a paso de la que ofrece un raspador ligero con IA. No es el producto más bonito de la categoría, pero sigue siendo flexible.
- Ideal para: investigadores, periodistas y usuarios técnicos sin programar que toleran más configuración.
- Por qué destaca: lógica condicional y control de navegación más fuertes que en muchas herramientas para principiantes.
- A tener en cuenta: más lento de aprender y con una sensación menos moderna que la de competidores más recientes.
- Señal de precio: plan gratis, planes de pago desde $189/mes.
5. Web Scraper
Web Scraper es una de las opciones más limpias para "aprender lo básico sin comprar una plataforma". Si te gusta el modelo de sitemap, sigue siendo una buena puerta de entrada.
- Ideal para: principiantes, proyectos de hobby y trabajos más pequeños guiados desde el navegador.
- Por qué destaca: configuración sencilla y transición fácil desde la extensión local a planes en la nube.
- A tener en cuenta: se vuelve limitante cuando necesitas una lógica más adaptativa o mejor manejo de bloqueos.
- Señal de precio: extensión gratis, Cloud desde $50/mes.
6. Browse AI
Browse AI sigue siendo una gran opción cuando extraer y monitorear importan por igual. Su modelo de robots resulta intuitivo para usuarios de negocio que piensan en términos de "vigila esta página y dime qué cambió".
- Ideal para: monitoreo de competidores, seguimiento de precios y equipos que trabajan primero en hojas de cálculo.
- Por qué destaca: incorporación pulida, monitoreo recurrente y resultados fáciles de automatizar.
- A tener en cuenta: los trabajos complejos y de gran volumen pueden encarecerse más rápido que en pilas centradas en APIs.
- Señal de precio: plan gratis, planes de pago, nivel gestionado.
Para equipos que evalúan monitoreo de páginas más que extracción puntual, este breve resumen oficial sigue siendo una buena señal:
7. Bardeen
Bardeen se centra menos en la profundidad pura del scraping y más en lo que pasa después. Es especialmente fuerte cuando la extracción web es solo un paso dentro de un flujo más amplio de automatización del navegador.
- Ideal para: operaciones de GTM, enrutamiento de leads, traspaso a CRM y automatización nativa del navegador.
- Por qué destaca: una historia sólida de automatización de flujos alrededor del propio scraping.
- A tener en cuenta: no es la mejor opción cuando la única prioridad es la precisión de la extracción.
- Señal de precio: plan gratis, Basic desde $10/mes, niveles Premium y Enterprise.
8. ScrapeStorm
ScrapeStorm sigue cubriendo un punto medio útil para usuarios que quieren ayuda de IA pero también esperan un entorno de scraping visual más tradicional.
- Ideal para: scraping de directorios, recopilación de páginas de ecommerce y tareas recurrentes configuradas visualmente.
- Por qué destaca: más fácil de empezar que muchas herramientas visuales más antiguas.
- A tener en cuenta: está menos pulido que los líderes de la categoría y puede sentirse más limitado en sitios difíciles.
- Señal de precio: prueba gratis, planes de pago, precios para empresas.

Las mejores APIs de scraping cuando importan la escala y el manejo anti-bot
Esta es la categoría a la que conviene pasar cuando la restricción real ya no es "¿cómo selecciono los datos?" sino "¿cómo mantengo esto fiable bajo carga?"
9. ScraperAPI
ScraperAPI sigue siendo uno de los productos API-first más accesibles para desarrolladores que quieren dejar de pensar en proxies y tasas de éxito de las solicitudes.
- Ideal para: desarrolladores que necesitan pasar de prototipo a producción con rapidez.
- Por qué destaca: API sencilla más soporte de proxy, CAPTCHA y renderizado.
- A tener en cuenta: tú sigues siendo responsable del parseo, los reintentos y la calidad de los datos posteriores.
- Señal de precio: prueba de 7 días, planes de pago desde $49/mes.
10. Bright Data Web Scraper
Bright Data es la opción pesada cuando la capacidad de desbloqueo, el inventario de proxies, el enfoque de cumplimiento y las opciones gestionadas importan más que la simplicidad.
- Ideal para: recopilación a escala empresarial y programas sensibles al cumplimiento.
- Por qué destaca: la pila más amplia de esta comparación, desde proxies hasta productos de recopilación gestionada.
- A tener en cuenta: es fácil comprar de más si tu equipo todavía tiene un flujo de trabajo bastante simple.
- Señal de precio: precios por producto y por uso.
11. Zyte
Zyte sigue siendo una opción seria para equipos de desarrollo que quieren acciones de navegador, renderizado JS, IP rotativas y una postura anti-bot dentro de una misma historia de plataforma.
- Ideal para: programas de scraping liderados por ingeniería y sistemas de extracción repetibles.
- Por qué destaca: una sólida pila anti-detección y flujos de trabajo centrados en API.
- A tener en cuenta: mejor para equipos con responsabilidad de ingeniería que para usuarios de negocio.
- Señal de precio: crédito de prueba de $5, planes por uso.
12. ZenRows
ZenRows es una de las experiencias más limpias para desarrolladores dentro de la categoría API si quieres manejo anti-bot sin un proceso de compra estilo enterprise.
- Ideal para: startups, desarrolladores y equipos internos ligeros.
- Por qué destaca: adopción relativamente sencilla junto con un posicionamiento anti-bot fuerte.
- A tener en cuenta: sigue siendo un producto API, así que tú mantienes la lógica de la aplicación y la carga de QA.
- Señal de precio: prueba gratis, Developer desde $69/mes.
13. ScrapingBee
ScrapingBee tiene sentido cuando tu necesidad real es una página renderizada y menos trabajo de infraestructura, sobre todo en sitios con mucho JavaScript.
- Ideal para: desarrolladores que extraen sitios dinámicos y quieren descargar el renderizado.
- Por qué destaca: API sencilla alrededor de navegación sin interfaz y proxies.
- A tener en cuenta: elimina trabajo de infraestructura, no la necesidad de una buena lógica de scraping.
- Señal de precio: prueba gratis, planes de pago desde $49/mes.
Las mejores bibliotecas de web scraping en Python para stacks personalizados
Este grupo sigue siendo la respuesta correcta cuando el control importa más que la comodidad y tu equipo está listo para asumir el mantenimiento.
14. Selenium
Selenium no es la herramienta de navegador más nueva, pero sigue siendo relevante cuando la fidelidad de la interacción del usuario importa más que el rendimiento bruto del scraping.
- Ideal para: flujos con mucha interacción, solapamiento con QA y sitios donde el comportamiento del navegador es el desafío principal.
- Por qué destaca: ecosistema maduro y amplio soporte de navegadores.
- A tener en cuenta: más pesado y más lento que pilas de automatización más nuevas para muchas cargas de scraping.
- Señal de precio: gratis y de código abierto.
15. Beautiful Soup

Beautiful Soup sigue siendo el parser más fácil de la pila de scraping en Python. No es una plataforma completa de scraping, pero sigue siendo la forma más simple de convertir HTML desordenado en una estructura útil.
- Ideal para: trabajos ligeros en Python, páginas HTML estáticas y prototipos rápidos.
- Por qué destaca: baja carga cognitiva y parseo tolerante.
- A tener en cuenta: combínalo con
requests, una capa de navegador o un crawler; por sí solo solo hace parseo. - Señal de precio: gratis y de código abierto.
16. Playwright
Playwright es mi recomendación moderna por defecto para equipos de desarrollo que necesitan una automatización robusta del navegador en la web actual.
- Ideal para: sitios con mucho JavaScript, automatización moderna del navegador y equipos ya cómodos escribiendo código.
- Por qué destaca: buen comportamiento de espera, soporte multibrowser y APIs limpias.
- A tener en cuenta: tú sigues encargándote de la concurrencia, los selectores, la infraestructura del navegador y la validación de datos.
- Señal de precio: gratis y de código abierto.
17. urllib3
urllib3 está en la lista porque algunos equipos quieren control directo del comportamiento del transporte en lugar de una abstracción de nivel superior. No es un raspador para principiantes, pero sí una biblioteca fundamental útil cuando estás construyendo tu propia pila.
- Ideal para: desarrolladores que quieren control preciso sobre reintentos, proxies, sesiones y comportamiento HTTP.
- Por qué destaca: ligera, fiable y muy usada como infraestructura.
- A tener en cuenta: estás construyendo la mayor parte de la pila por tu cuenta.
- Señal de precio: gratis y de código abierto.
Herramientas gratuitas de extracción web que vale la pena probar primero
Si quieres probar antes de comprar, los mejores puntos de partida gratuitos de esta lista son Thunderbit, Octoparse, ParseHub, Web Scraper, Browse AI, Bardeen, Selenium, Beautiful Soup, Playwright y urllib3. La experiencia gratis es lo bastante buena para aprender qué tipo de raspador necesitas de verdad, y eso suele ser más importante que obsesionarse desde el primer día con una lista perfecta de funciones.
Mi selección corta por tipo de equipo

- Equipos de ventas, operaciones y ecommerce: empieza con Thunderbit y luego compara Browse AI si el monitoreo importa más que el enriquecimiento de subpáginas.
- Analistas y operadores manuales recurrentes: primero Octoparse; luego ParseHub si necesitas una lógica de tareas más personalizada.
- Equipos de automatización de GTM: Bardeen si el scraping necesita fluir directamente a CRM, Sheets o flujos del navegador.
- Equipos de desarrollo que construyen herramientas internas: ScraperAPI, ZenRows, Zyte o Playwright según cuánta propiedad del stack quieras asumir.
- Programas de datos empresariales: Bright Data y Zyte son las conversaciones de infraestructura más serias aquí, con Kadoa como alternativa liderada por IA cuando reducir mantenimiento es el objetivo principal.
Cuándo bajar de nivel en la pila
Usa esta ruta de actualización:
- Quédate con los Raspadores Web IA hasta que choques con límites de repetibilidad o de casos extremos.
- Pasa a constructores sin código cuando la programación, la paginación y la ejecución en la nube importen más que la simplicidad de un clic.
- Pasa a APIs cuando la tasa de desbloqueo, el renderizado y la concurrencia se conviertan en el cuello de botella.
- Pasa a bibliotecas de Python cuando la abstracción del proveedor cueste más que asumir tú mismo el sistema completo.
La mayoría de los equipos hace esto en el orden equivocado. Primero sobredimensionan la solución y solo después se dan cuenta de que una herramienta más ligera habría resuelto el flujo real.
Conclusión final
La mejor herramienta para extraer sitios web en 2026 no es la que tiene la lista de funciones más larga. Es la que lleva datos precisos al siguiente flujo de trabajo con el menor mantenimiento posible para tu equipo. Por eso las herramientas centradas en IA siguen ganando para operadores, las herramientas sin código siguen siendo valiosas para trabajos repetibles en navegador, las APIs dominan cuando importan la escala y los bloqueos, y las bibliotecas de Python siguen controlando el extremo de mayor control de la pila.
Si tu objetivo es conseguir datos útiles esta semana, empieza simple. Si tu carga de trabajo ya te está diciendo que la tasa de desbloqueo, el renderizado del navegador y el control de ingeniería son el verdadero problema, baja de nivel de forma deliberada en lugar de hacerlo por costumbre.
Preguntas frecuentes
1. ¿Cuál es la mejor herramienta para extraer sitios web para usuarios sin perfil técnico en 2026?
Para la mayoría de equipos sin conocimientos técnicos, las herramientas centradas en IA como Thunderbit y Browse AI siguen siendo la vía más rápida porque reducen el tiempo de configuración, el trabajo con selectores y la carga de mantenimiento.
2. ¿Qué debería elegir para sitios con mucho JavaScript o protegidos por anti-bot?
Normalmente ahí es donde ScraperAPI, Bright Data, Zyte, ZenRows, ScrapingBee, Playwright o Selenium empiezan a tener más sentido que las extensiones del navegador.
3. ¿Siguen siendo relevantes las herramientas de scraping sin código ahora que los raspadores con IA son mejores?
Sí. Octoparse, ParseHub, Web Scraper y Browse AI siguen siendo importantes cuando necesitas más control explícito de tareas, ejecuciones recurrentes o depuración visible en el navegador.
4. ¿Qué herramientas tienen más sentido para equipos de desarrollo?
ScraperAPI, Zyte, ZenRows, ScrapingBee, Playwright, Selenium, Beautiful Soup y urllib3 son las opciones más naturales cuando ingeniería es dueña del flujo de trabajo.
Lecturas relacionadas