La web rebosa de datos, pero aquí está el problema: recopilarlos manualmente es tan divertido como ver secarse la pintura y, además, tan productivo como eso. En 2025, las empresas nadan en más contenido web que nunca, con la media de datos web diarios de una compañía saltando de 1,2 TB en 2020 a 8 TB en 2025 (). Tanto si trabajas en ventas, marketing, ecommerce u operaciones, la necesidad de contar con datos web rápidos, estructurados y precisos ya no es un simple “plus”: es una necesidad operativa. Y seamos sinceros: nadie tiene tiempo para maratones interminables de copiar y pegar.
Por eso las herramientas de rastreo de contenido se han disparado en popularidad. Estas herramientas —desde extensiones de Chrome con IA hasta plataformas de nivel empresarial— te permiten automatizar todo el proceso y convertir páginas web caóticas en hojas de cálculo limpias, bases de datos o paneles en tiempo real. Llevo años trabajando en SaaS y automatización, y te lo puedo decir claro: la herramienta adecuada no solo ahorra tiempo, también puede transformar la forma en que trabaja tu equipo. Así que vamos a ver las 18 mejores herramientas de rastreo de contenido para hacer web scraping de forma eficiente en 2025, centrándonos en qué hace única a cada una, cómo encajan en distintas necesidades de negocio y cómo elegir la mejor para tu flujo de trabajo.
Por qué las empresas necesitan las mejores herramientas de rastreo de contenido
Si alguna vez has intentado crear una lista de leads, vigilar los precios de la competencia o seguir el sentimiento del mercado a mano, sabes lo rápido que la recopilación manual de datos se convierte en una pesadilla. Es lenta, propensa a errores y, cuando terminas, tus datos quizá ya estén desactualizados. Por eso, más del 70% de las empresas han adoptado la extracción web automatizada para 2025, reduciendo el esfuerzo manual en alrededor de un 60% ().
Las herramientas de rastreo de contenido automatizan la extracción de datos estructurados de sitios web, lo que permite:
- Alimentar tu CRM con nuevos leads (sin más copiar y pegar desde directorios)
- Supervisar precios y niveles de stock de la competencia en tiempo real
- Agrupar reseñas, noticias y menciones en redes sociales para obtener insights de marketing
- Crear conjuntos de datos personalizados para investigación o analítica
- Programar extracciones recurrentes de datos para informes continuos
Y el ROI es real: las empresas que usan web scraping reportaron ahorros conjuntos de más de 500 millones de dólares entre 2020 y 2025, con mejoras de eficiencia operativa del 20–40% (). ¿La conclusión? Las herramientas de rastreo de contenido liberan a tu equipo para centrarse en la estrategia, no en el trabajo tedioso.
Cómo seleccionamos las mejores herramientas de rastreo de contenido
No todos los web scrapers son iguales. Al elaborar esta lista, analicé las herramientas desde la perspectiva de usuarios reales de negocio: equipos de ventas, marketing, operaciones e investigación que necesitan resultados, no dolores de cabeza. Esto fue lo más importante:
- Facilidad de uso: ¿Pueden empezar rápido los usuarios no técnicos? ¿Hay interfaz de apuntar y hacer clic o ayuda con IA?
- Automatización y funciones: ¿La herramienta gestiona paginación, subpáginas, programación y contenido dinámico? ¿Puede ejecutarse en la nube para ganar velocidad y escala?
- Salida de datos e integración: ¿Puedes exportar a Excel, CSV, Google Sheets, Airtable, Notion o conectar por API?
- Escalabilidad: ¿Sirve para tareas puntuales o para proyectos grandes y continuos?
- Personalización: ¿Puedes ajustar la lógica de extracción, añadir campos personalizados o gestionar sitios complicados?
- Cumplimiento y privacidad: ¿La herramienta te ayuda a mantenerte del lado correcto del RGPD, la CCPA y los términos del sitio?
- Soporte y comunidad: ¿Hay documentación, soporte o comunidad de usuarios para ayudarte a resolver problemas?
- Coste: ¿Hay plan gratuito o prueba? ¿El precio encaja con tu escala y presupuesto?
Y, por supuesto, puse un foco especial en Thunderbit —la herramienta que mi equipo y yo construimos— porque de verdad creo que es la forma más fácil de que los usuarios de negocio empiecen con web scraping impulsado por IA.
Las 18 mejores herramientas de rastreo de contenido para hacer web scraping eficiente
Vamos a revisar lo mejor de lo mejor, desde la sencillez impulsada por IA hasta potencias para desarrolladores, y todo lo demás.
1. Thunderbit
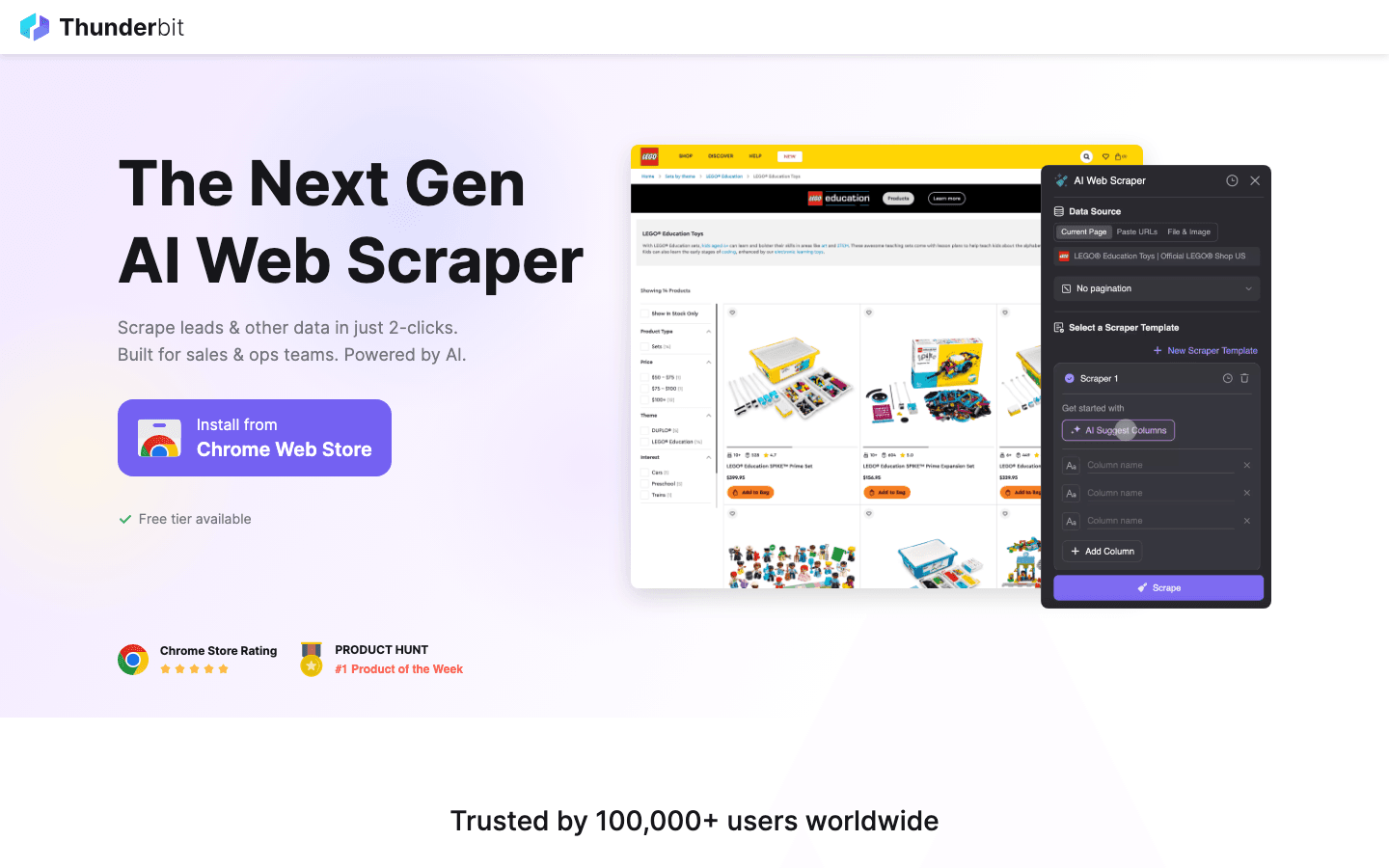 es una extensión de Chrome de AI Web Scraper diseñada para usuarios de negocio que quieren resultados, y rápido. Su función estrella es AI Suggest Fields: solo tienes que visitar una página web, hacer clic en “AI Suggest” y la IA de Thunderbit lee la página, recomienda los campos que extraer y configura el scraper por ti. Sin código, sin pelearte con selectores: solo haz clic, extrae y exporta.
es una extensión de Chrome de AI Web Scraper diseñada para usuarios de negocio que quieren resultados, y rápido. Su función estrella es AI Suggest Fields: solo tienes que visitar una página web, hacer clic en “AI Suggest” y la IA de Thunderbit lee la página, recomienda los campos que extraer y configura el scraper por ti. Sin código, sin pelearte con selectores: solo haz clic, extrae y exporta.
- Extracción de subpáginas: Thunderbit puede visitar automáticamente cada subpágina (como detalles de producto o perfil) y enriquecer tu conjunto de datos, ideal para generación de leads o investigación ecommerce.
- Paginación y plantillas: Gestiona listas de varias páginas y ofrece plantillas instantáneas para sitios como Amazon, Zillow e Instagram.
- Exportación gratuita de datos: Exporta a Excel, Google Sheets, Airtable, Notion, CSV o JSON, sin muro de pago.
- AI Autofill: Automatiza el relleno de formularios online con IA, ampliando la automatización más allá del scraping.
- Scraping en la nube y en navegador: Elige scraping rápido en la nube para sitios públicos o modo navegador para sesiones con inicio de sesión.
- Precio: Gratis hasta 6 páginas (o 10 con prueba), con planes de pago desde solo 15 $/mes.
Thunderbit es perfecto para equipos de ventas, marketing y operaciones que quieren automatizar la recopilación de datos sin complicaciones técnicas. Es la herramienta que me habría gustado tener hace años: ahora cualquiera puede crear una lista de leads o vigilar a la competencia en minutos.
2. Scrapy
 es una potencia de código abierto para desarrolladores. Es un framework basado en Python que te permite escribir spiders personalizados para rastrear y extraer datos a gran escala. Scrapy está pensado para velocidad y flexibilidad, con compatibilidad para rastreo asíncrono, pipelines personalizados, rotación de proxies e integración con bases de datos o API.
es una potencia de código abierto para desarrolladores. Es un framework basado en Python que te permite escribir spiders personalizados para rastrear y extraer datos a gran escala. Scrapy está pensado para velocidad y flexibilidad, con compatibilidad para rastreo asíncrono, pipelines personalizados, rotación de proxies e integración con bases de datos o API.
- Ideal para: desarrolladores e ingenieros de datos que construyen proyectos de scraping grandes, complejos o recurrentes.
- Fortalezas: control total, extensibilidad, comunidad enorme y fiabilidad probada.
- Desventajas: curva de aprendizaje pronunciada para quienes no programan; sin interfaz visual.
Si dominas Python y quieres construir crawlers robustos y escalables, Scrapy es el estándar de oro.
3. Octoparse
 es un web scraper sin código y basado en la nube, con una interfaz visual de arrastrar y soltar. Puedes señalar y hacer clic para seleccionar datos, configurar paginación e incluso usar detección de patrones asistida por IA para acelerar la configuración.
es un web scraper sin código y basado en la nube, con una interfaz visual de arrastrar y soltar. Puedes señalar y hacer clic para seleccionar datos, configurar paginación e incluso usar detección de patrones asistida por IA para acelerar la configuración.
- Plantillas preconstruidas: extrae datos de sitios populares como Amazon, Twitter y Google Maps en minutos.
- Scraping en la nube y programación: ejecuta tareas en los servidores de Octoparse, programa tareas recurrentes y gestiona proyectos a gran escala.
- Opciones de exportación: CSV, Excel, JSON e integración por API.
- Precio: plan gratuito con límites; los planes de pago empiezan alrededor de 75 $/mes.
Octoparse es ideal para analistas de negocio y personas sin conocimientos de programación que quieren scraping potente sin escribir código.
4. ParseHub
 es un scraper visual que destaca al manejar contenido dinámico y estructuras complejas de sitios web. Su interfaz de apuntar y hacer clic te permite crear flujos de trabajo con lógica condicional, bucles y navegación multinivel.
es un scraper visual que destaca al manejar contenido dinámico y estructuras complejas de sitios web. Su interfaz de apuntar y hacer clic te permite crear flujos de trabajo con lógica condicional, bucles y navegación multinivel.
- Contenido dinámico: gestiona menús desplegables, scroll infinito y elementos interactivos.
- Ejecuciones en la nube y locales: ejecuta proyectos en la nube (de pago) o localmente para tareas pequeñas.
- Exportación: CSV, Excel, JSON, API.
- Precio: generoso plan gratuito; planes de pago desde 49 $/mes.
ParseHub es excelente para quienes no programan y necesitan flexibilidad y potencia para sitios web difíciles.
5. Data Miner
 es una extensión para Chrome/Edge pensada para scraping rápido basado en plantillas. Con más de 50.000 recetas públicas de extracción para más de 15.000 sitios web, muchas veces puedes extraer una página con un solo clic.
es una extensión para Chrome/Edge pensada para scraping rápido basado en plantillas. Con más de 50.000 recetas públicas de extracción para más de 15.000 sitios web, muchas veces puedes extraer una página con un solo clic.
- Integración con Google Sheets: sube los datos extraídos directamente a Sheets.
- Recetas personalizadas: crea tu propia lógica de extracción con apuntar y hacer clic o XPath.
- Paginación y automatización: gestiona scraping de varias páginas y ejecuciones programadas.
- Precio: plan gratuito; planes de pago desde 19 $/mes.
Perfecto para analistas y marketers que necesitan obtener datos rápidos de tamaño pequeño o medio directamente desde el navegador.
6. WebHarvy
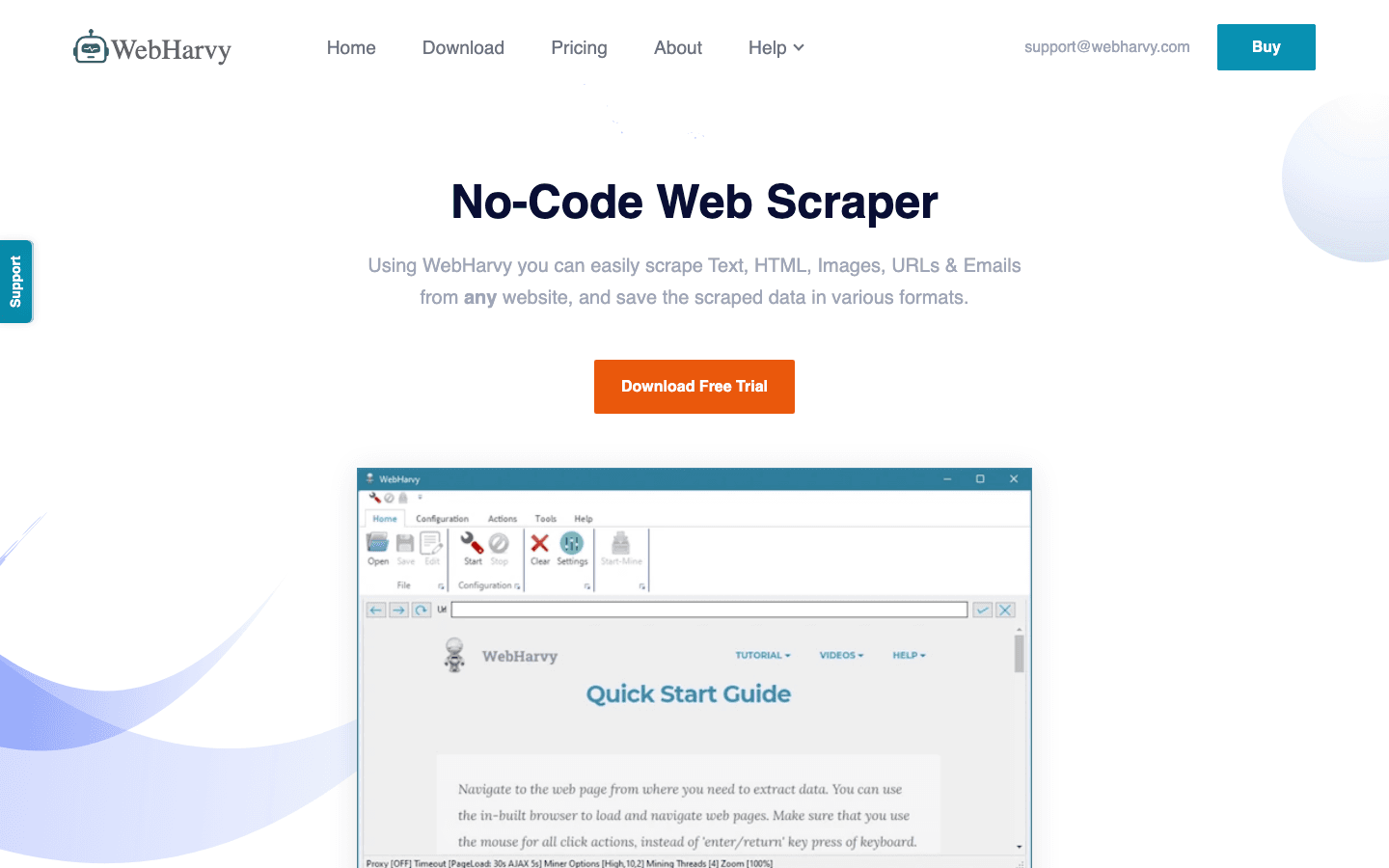 es una aplicación de escritorio para Windows con interfaz de apuntar y hacer clic y detección automática de patrones. Solo tienes que hacer clic en un elemento y WebHarvy resaltará todos los elementos similares para extraerlos.
es una aplicación de escritorio para Windows con interfaz de apuntar y hacer clic y detección automática de patrones. Solo tienes que hacer clic en un elemento y WebHarvy resaltará todos los elementos similares para extraerlos.
- Compatibilidad con imágenes, texto y paginación: extrae fotos de productos, emails, URLs y mucho más.
- Programación en escritorio: programa extracciones en tu PC.
- Licencia única: alrededor de 199 $ por equipo.
Genial para pequeños negocios que quieren una herramienta sencilla, sin suscripción, para scraping periódico.
7. Import.io
 es una plataforma de nivel empresarial basada en la nube para extracción de datos a gran escala. Ofrece limpieza de datos con IA, monitorización en tiempo real y sólidas funciones de cumplimiento.
es una plataforma de nivel empresarial basada en la nube para extracción de datos a gran escala. Ofrece limpieza de datos con IA, monitorización en tiempo real y sólidas funciones de cumplimiento.
- Integraciones por API: entrega datos directamente a bases de datos, paneles de BI o aplicaciones.
- Cumplimiento: diseñada teniendo en cuenta el RGPD y la CCPA.
- Precio: contratos empresariales; gama alta.
La mejor opción para grandes organizaciones que necesitan pipelines de datos web fiables, escalables y compatibles.
8. Apify
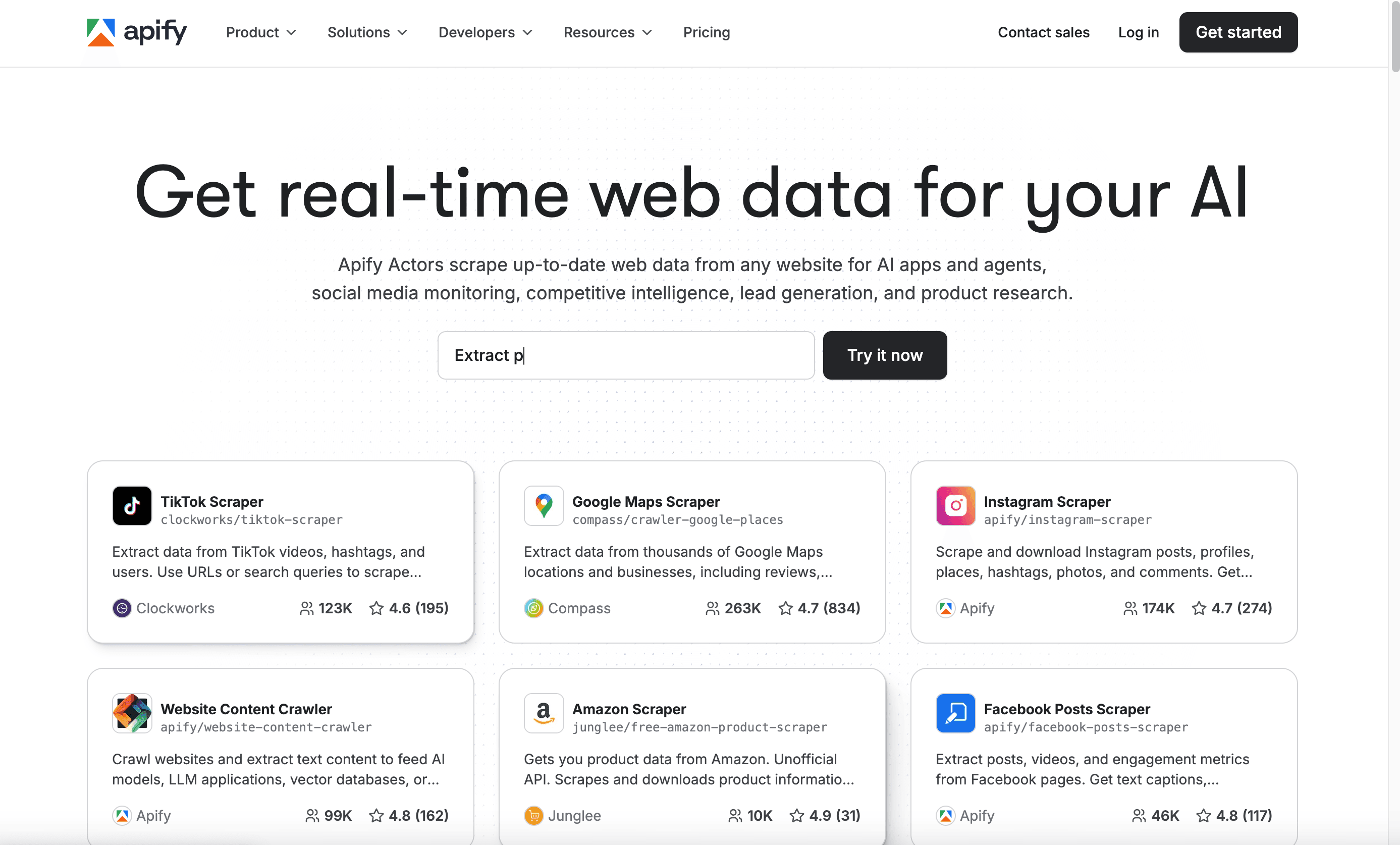 es una plataforma de automatización en la nube y un marketplace de “actors” para web scraping (bots). Usa actors preconstruidos para sitios comunes o crea los tuyos en JavaScript o Python.
es una plataforma de automatización en la nube y un marketplace de “actors” para web scraping (bots). Usa actors preconstruidos para sitios comunes o crea los tuyos en JavaScript o Python.
- Marketplace: cientos de scrapers listos para usar para sitios como LinkedIn, Amazon y más.
- Programación y API: ejecuta, programa e integra actors mediante API.
- Precio: plan gratuito; uso de pago desde 49 $/mes.
Ideal para desarrolladores y equipos técnicos que quieren automatización, flexibilidad y soluciones impulsadas por la comunidad.
9. Visual Web Ripper
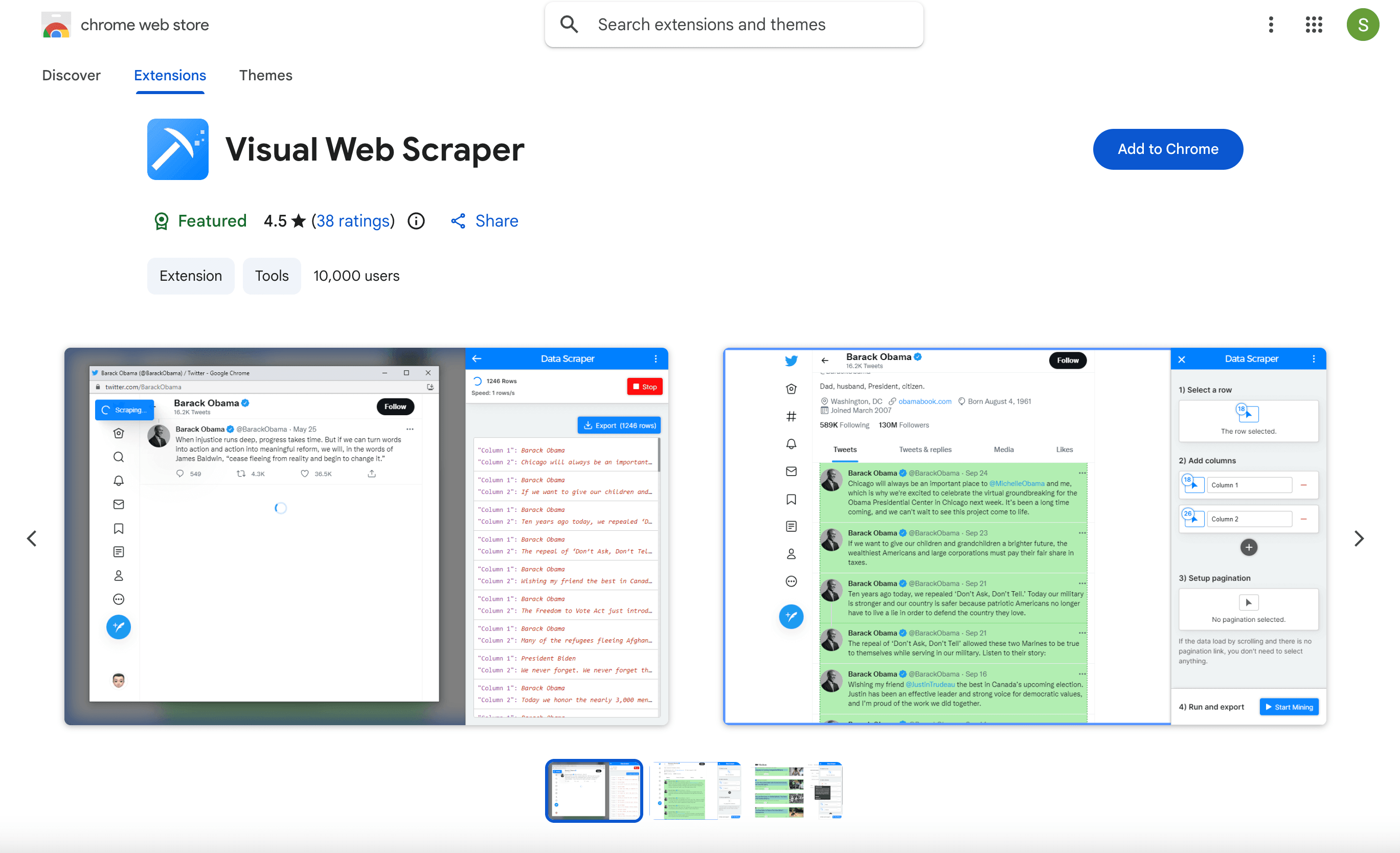 es una herramienta de escritorio para extracción avanzada de datos en volumen. Su creador de flujos de trabajo te permite diseñar rastreos multinivel y automatizar proyectos de gran escala.
es una herramienta de escritorio para extracción avanzada de datos en volumen. Su creador de flujos de trabajo te permite diseñar rastreos multinivel y automatizar proyectos de gran escala.
- Programación y automatización: ejecuta proyectos a intervalos definidos.
- Integración con bases de datos: exporta directamente a SQL, Excel, CSV, XML o JSON.
- Licencia única: alrededor de 349 $.
La mejor opción para equipos de TI o usuarios avanzados que necesitan extraer grandes conjuntos de datos de forma interna.
10. Dexi.io
 es una plataforma basada en la nube para proyectos colaborativos de datos web. Ofrece automatización de flujos de trabajo, programación y funciones de gestión de equipos.
es una plataforma basada en la nube para proyectos colaborativos de datos web. Ofrece automatización de flujos de trabajo, programación y funciones de gestión de equipos.
- Automatización de flujos de trabajo: crea y comparte pipelines de datos entre equipos.
- API y exportación: integra con bases de datos, almacenamiento en la nube o herramientas de BI.
- Precio: personalizado; orientado a equipos y empresas.
Excelente para organizaciones que gestionan proyectos de datos continuos y colaborativos.
11. Content Grabber
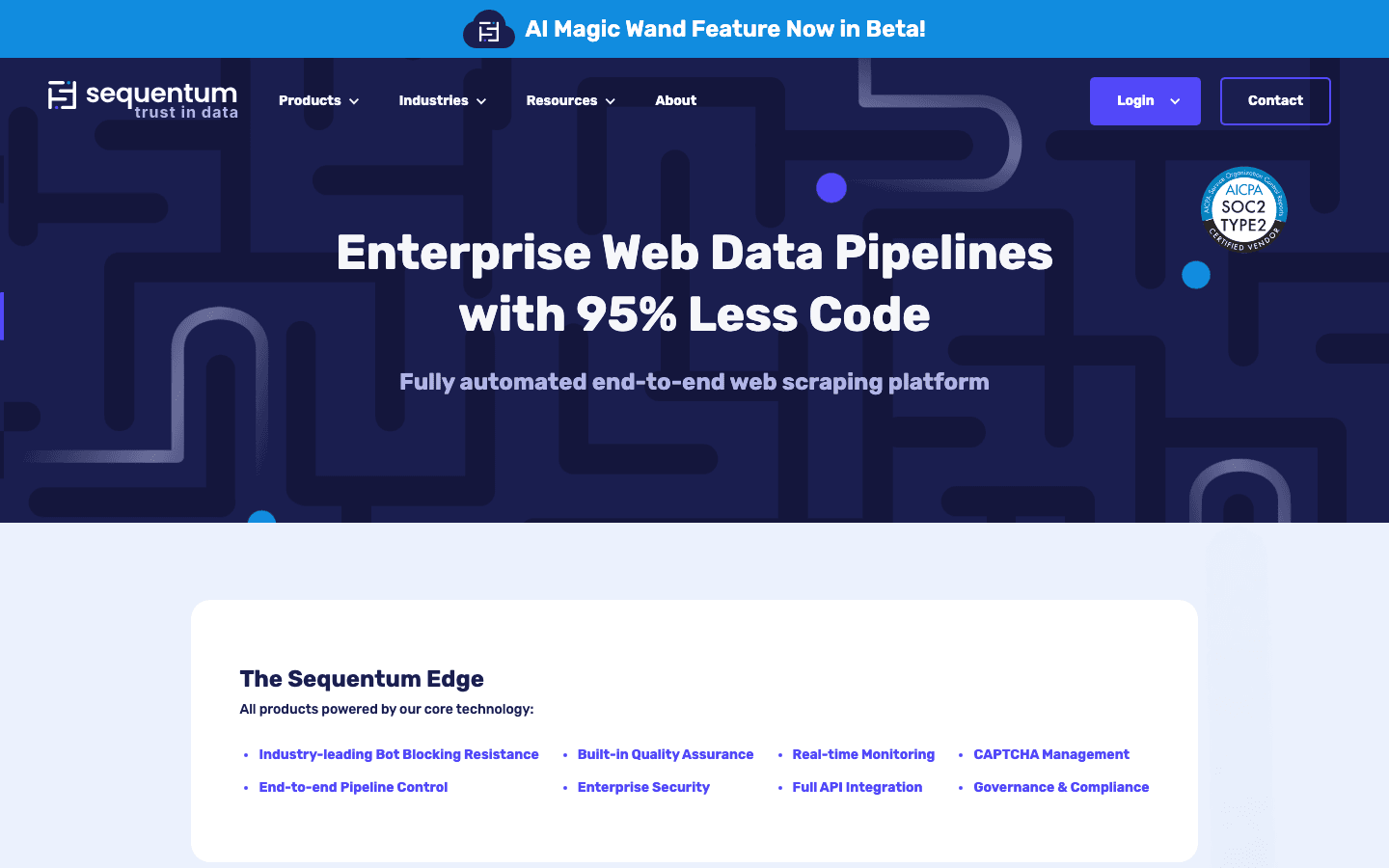 es una herramienta de scraping de nivel profesional para agencias y empresas. Ofrece automatización avanzada, gestión de errores e incluso opciones de white-label.
es una herramienta de scraping de nivel profesional para agencias y empresas. Ofrece automatización avanzada, gestión de errores e incluso opciones de white-label.
- Scripting y personalización: usa C# o VB.NET para tener control profundo.
- Recuperación ante errores y registro: diseñado para ser fiable en trabajos grandes.
- Precio empresarial: gama alta; hay prueba gratuita disponible.
La mejor opción para agencias o empresas que construyen soluciones de scraping personalizadas y repetibles para clientes.
12. Helium Scraper
 es una herramienta de escritorio que combina extracción visual con flexibilidad de scripting. Usa apuntar y hacer clic para la mayoría de tareas o pasa a JavaScript personalizado para lógica avanzada.
es una herramienta de escritorio que combina extracción visual con flexibilidad de scripting. Usa apuntar y hacer clic para la mayoría de tareas o pasa a JavaScript personalizado para lógica avanzada.
- Gestiona contenido dinámico: extrae sitios muy cargados de AJAX.
- Limpieza y transformación de datos: scripting integrado para flujos personalizados.
- Licencia única: alrededor de 99 $.
Perfecto para usuarios avanzados que quieren flexibilidad sin suscripción.
13. Web Scraper
 es una extensión gratuita de Chrome que introduce a muchas personas en el web scraping. Define un sitemap, haz clic para seleccionar elementos y exporta a CSV o JSON.
es una extensión gratuita de Chrome que introduce a muchas personas en el web scraping. Define un sitemap, haz clic para seleccionar elementos y exporta a CSV o JSON.
- Rastreo multinivel: sigue enlaces, gestiona paginación y extrae datos anidados.
- Gratis para uso local: versión de pago en la nube disponible para programación y escala.
Ideal para principiantes, estudiantes o cualquiera que necesite una solución rápida y gratuita para tareas pequeñas.
14. Mozenda
 es una plataforma empresarial en la nube centrada en cumplimiento, escalabilidad y servicios gestionados. Su interfaz de apuntar y hacer clic te permite crear “agents” para la extracción de datos.
es una plataforma empresarial en la nube centrada en cumplimiento, escalabilidad y servicios gestionados. Su interfaz de apuntar y hacer clic te permite crear “agents” para la extracción de datos.
- Servicios gestionados: el equipo de Mozenda puede crear y mantener scrapers por ti.
- Cumplimiento y soporte: fuerte enfoque en RGPD, CCPA y necesidades empresariales.
- Precio: desde unos 500 $/mes.
La mejor opción para grandes organizaciones que buscan una solución llave en mano y escalable de datos web con buen soporte.
15. SimpleIndex
 es una herramienta de automatización tanto para extracción de documentos como de datos web, con foco en OCR e indexación.
es una herramienta de automatización tanto para extracción de documentos como de datos web, con foco en OCR e indexación.
- OCR para screen scraping: extrae datos de documentos escaneados, PDFs o incluso formularios web en pantalla.
- Integración: salida a bases de datos y sistemas de gestión documental.
- Licencia única: unos pocos cientos de dólares por estación de trabajo.
Excelente para organizaciones que combinan flujos de trabajo de documentos y datos web.
16. Spinn3r
 es una plataforma de rastreo de contenido en tiempo real para blogs, noticias y redes sociales. Su Firehose API ofrece un flujo continuo de contenido nuevo procedente de millones de fuentes.
es una plataforma de rastreo de contenido en tiempo real para blogs, noticias y redes sociales. Su Firehose API ofrece un flujo continuo de contenido nuevo procedente de millones de fuentes.
- Filtrado de spam y procesamiento de lenguaje: fuentes de datos limpias y estructuradas.
- Acceso por API: intégralo directamente en tus sistemas.
- Precio por suscripción: según el uso.
La mejor opción para monitorización de medios, agregación de noticias o equipos de investigación que necesitan flujos de contenido en tiempo real.
17. FMiner
 es un creador visual de flujos de trabajo para rastreos web complejos. Su interfaz de arrastrar y soltar te permite diseñar rutinas de scraping multinivel y condicionales.
es un creador visual de flujos de trabajo para rastreos web complejos. Su interfaz de arrastrar y soltar te permite diseñar rutinas de scraping multinivel y condicionales.
- Scripting en Python: inserta código personalizado para lógica avanzada.
- Multiplataforma: disponible para Windows y Mac.
- Licencia única: desde unos 168 $.
Perfecto para analistas o científicos de datos que quieren diseñar flujos de trabajo sofisticados de forma visual.
18. G2 Webscraper
 (en referencia a las herramientas mejor valoradas en G2) es elogiado por su sencillez y eficacia. A los usuarios les encantan las herramientas gratuitas, fáciles y que ahorran muchísimo tiempo, como la extensión Web Scraper para Chrome o Data Miner.
(en referencia a las herramientas mejor valoradas en G2) es elogiado por su sencillez y eficacia. A los usuarios les encantan las herramientas gratuitas, fáciles y que ahorran muchísimo tiempo, como la extensión Web Scraper para Chrome o Data Miner.
- Opiniones sólidas de usuarios: puntuaciones altas por facilidad de uso y fiabilidad.
- Configuración rápida: curva de aprendizaje mínima para tareas básicas e intermedias.
Si quieres una herramienta que “simplemente funcione” para scraping sencillo, las favoritas de los usuarios en G2 son una apuesta segura.
Tabla comparativa: las mejores herramientas de rastreo de contenido de un vistazo
| Herramienta | Facilidad de uso | Automatización y funciones | Formatos de exportación | Cumplimiento y privacidad | Precio | Ideal para |
|---|---|---|---|---|---|---|
| Thunderbit | ⭐⭐⭐⭐⭐ | Campos de IA, subpáginas, nube | Excel, CSV, Sheets, Notion, Airtable, JSON | Guiado por el usuario | Gratis, desde 15 $/mes | Personas sin código, ventas, ops |
| Scrapy | ⭐ | Código completo, async, plugins | CSV, JSON, BD | Gestionado por el usuario | Gratis, open source | Desarrolladores, grandes proyectos |
| Octoparse | ⭐⭐⭐⭐ | Visual, plantillas, nube | CSV, Excel, JSON, API | Guiado por el usuario | Gratis, desde 75 $/mes | Analistas, ecommerce, no-coders |
| ParseHub | ⭐⭐⭐⭐ | Visual, dinámico, nube | CSV, Excel, JSON, API | Guiado por el usuario | Gratis, desde 49 $/mes | No-coders, sitios complejos |
| Data Miner | ⭐⭐⭐⭐⭐ | Plantillas, navegador, Sheets | CSV, Excel, Sheets | Guiado por el usuario | Gratis, desde 19 $/mes | Tareas rápidas en el navegador |
| WebHarvy | ⭐⭐⭐⭐⭐ | Visual, detección de patrones | Excel, CSV, XML, JSON | Guiado por el usuario | 199 $ pago único | Usuarios de Windows, pequeños negocios |
| Import.io | ⭐⭐⭐⭐ | IA, nube, monitorización | CSV, API, BD | RGPD, CCPA | Empresarial | Grandes empresas, cumplimiento |
| Apify | ⭐⭐⭐ | Nube, marketplace, API | JSON, API, Sheets | Gestionado por el usuario | Gratis, desde 49 $/mes | Desarrolladores, automatización, integraciones |
| Visual Web Ripper | ⭐⭐⭐ | Flujo de trabajo, programación | CSV, Excel, BD | Guiado por el usuario | 349 $ pago único | Equipos de TI, datos masivos |
| Dexi.io | ⭐⭐⭐ | Nube, equipo, flujo | CSV, API, BD, almacenamiento | Guiado por el usuario | Personalizado | Equipos, proyectos continuos |
| Content Grabber | ⭐⭐⭐ | Scripting, automatización | CSV, XML, BD | Guiado por el usuario | Empresarial | Agencias, soluciones personalizadas |
| Helium Scraper | ⭐⭐⭐ | Visual + scripting | CSV, BD | Guiado por el usuario | 99 $ pago único | Usuarios avanzados, lógica personalizada |
| Web Scraper | ⭐⭐⭐⭐⭐ | Sitemap, navegador | CSV, JSON | Guiado por el usuario | Gratis (local) | Principiantes, tareas pequeñas |
| Mozenda | ⭐⭐⭐ | Nube, gestionado, cumplimiento | CSV, API, BD | RGPD, CCPA | 500 $+/mes | Empresa, servicio gestionado |
| SimpleIndex | ⭐⭐⭐ | OCR, web, documentos | BD, DMS | Guiado por el usuario | 500 $ pago único | Documentos + datos web |
| Spinn3r | ⭐⭐ | Tiempo real, API | JSON, API | Guiado por el usuario | Suscripción | Medios, noticias, investigación |
| FMiner | ⭐⭐⭐ | Flujo visual, Python | CSV, BD | Guiado por el usuario | 168 $ pago único | Flujos complejos y visuales |
| G2 Webscraper | ⭐⭐⭐⭐⭐ | Sencillo, navegador | CSV, JSON | Guiado por el usuario | Gratis/varía | Sencillez, resultados rápidos |
Cómo elegir la herramienta de rastreo de contenido adecuada para tu negocio
Elegir la herramienta correcta consiste, sobre todo, en alinear tus necesidades con las fortalezas de la herramienta. Aquí va mi lista rápida:
- Define tu caso de uso: ¿Es puntual o continuo? ¿Pequeña o gran escala? ¿Datos públicos o con inicio de sesión?
- Hazlo coincidir con tu nivel técnico: quienes no programan deberían empezar con Thunderbit, Octoparse, ParseHub o WebHarvy. Los desarrolladores pueden ir directamente a Scrapy o Apify.
- Comprueba las necesidades de exportación: ¿Necesitas Excel, Sheets o integración por API? Asegúrate de que la herramienta lo soporte.
- Ten en cuenta el cumplimiento: si trabajas en un sector regulado o extraes datos personales, prioriza herramientas con funciones de cumplimiento (Import.io, Mozenda).
- Empieza pequeño: usa planes gratuitos o pruebas para testear con datos reales antes de comprometerte.
- Piensa a futuro: ¿Tus necesidades crecerán? Elige una herramienta con la que puedas escalar.
Y recuerda: a veces la herramienta más simple es la mejor opción. No compliques demasiado las cosas si solo necesitas una hoja de cálculo rápida.
Privacidad de datos y cumplimiento: en qué debes fijarte
El web scraping abre un mundo de posibilidades, pero también de responsabilidades. Así puedes mantenerte del lado correcto de la ley y de las buenas prácticas:
- Respeta robots.txt y las políticas del sitio: comprueba siempre si un sitio permite scraping y sigue sus directrices.
- Evita extraer datos personales salvo que tengas una razón legítima y consentimiento: el RGPD y la CCPA van muy en serio.
- No sobrecargues los servidores: usa limitación de velocidad, pausas y programación integradas para evitar bloqueos (y para comportarte como un buen ciudadano de internet).
- Usa herramientas con funciones de cumplimiento si trabajas en un sector sensible: Import.io y Mozenda están diseñadas teniendo en cuenta el RGPD y la CCPA.
- Documenta tus acciones: guarda registros de qué extraes y por qué, especialmente en casos de uso empresariales o regulados.
El scraping ético es scraping sostenible, y además mantiene a tu negocio fuera de problemas.
Conclusión: potencia a tu equipo con la herramienta de rastreo de contenido adecuada
La web es la base de datos más grande y caótica de tu negocio, y con la herramienta de rastreo de contenido adecuada, por fin puedes ponerla a trabajar. Tanto si estás creando listas de leads, siguiendo a la competencia o alimentando paneles en tiempo real, estas 18 herramientas cubren todos los escenarios, niveles técnicos y presupuestos.
Si quieres el camino más rápido hacia resultados, es mi primera recomendación para usuarios de negocio: impulsado por IA, sin código y listo para convertir cualquier sitio web en un conjunto de datos estructurado en minutos. Pero, sean cuales sean tus necesidades, empieza con una prueba gratuita, experimenta y descubre qué encaja mejor con tu flujo de trabajo.
¿Listo para dejar atrás el tedio de copiar y pegar? Descarga la y comprueba lo fácil que puede ser trabajar con datos web. Y si quieres profundizar más en web scraping, visita el para más guías, consejos y tutoriales.
Preguntas frecuentes
1. ¿Qué es una herramienta de rastreo de contenido y en qué se diferencia de un web scraper normal?
Una herramienta de rastreo de contenido es un tipo de web scraper diseñado para automatizar la extracción de datos estructurados de sitios web. Aunque todos los web scrapers recopilan datos, las herramientas de rastreo de contenido suelen ofrecer funciones como programación, navegación por subpáginas, detección de campos con IA e integración con flujos de trabajo empresariales, lo que las hace más potentes y fáciles de usar para equipos de negocio.
2. ¿Qué herramienta de rastreo de contenido es mejor para usuarios sin conocimientos técnicos?
Thunderbit, Octoparse, ParseHub, Data Miner y WebHarvy son excelentes para quienes no programan. Thunderbit destaca por su sencillez impulsada por IA y por exportar al instante a Excel, Sheets, Airtable o Notion.
3. ¿Cómo me aseguro de que mi web scraping sea legal y cumpla con las normas?
Respeta siempre los términos del sitio web, robots.txt y leyes de privacidad como el RGPD y la CCPA. Evita extraer datos personales salvo que tengas una razón legítima y consentimiento. Para sectores sensibles, elige herramientas con funciones de cumplimiento integradas (por ejemplo, Import.io, Mozenda).
4. ¿Pueden estas herramientas manejar sitios web dinámicos con JavaScript o scroll infinito?
Sí: herramientas como Thunderbit, Octoparse, ParseHub, Apify y FMiner pueden gestionar contenido dinámico, scroll infinito y navegación multinivel. Algunas pueden requerir configuración adicional o ejecuciones en la nube para sitios complejos.
5. ¿Qué debo tener en cuenta al elegir una herramienta de rastreo de contenido para mi empresa?
Considera las habilidades técnicas de tu equipo, la escala de tus necesidades de datos, los requisitos de exportación e integración, las preocupaciones de cumplimiento y el presupuesto. Empieza con un plan gratuito o una prueba y pon la herramienta a prueba en tu caso real antes de comprometerte.
Feliz scraping, y que tus datos estén siempre frescos, estructurados y listos para la acción.
Más información