La extracción de datos de Facebook sigue mereciendo la pena en 2026, pero solo si eliges el modelo de recopilación adecuado. Pew Research Center informó el 20 de noviembre de 2025 que , y Meta dijo el 29 de abril de 2026 que su en marzo de 2026. Esa escala sigue haciendo que Facebook sea útil para vigilar Marketplace, investigar páginas públicas, generar leads y seguir de cerca a la competencia. Lo difícil no es encontrar casos de uso. Lo difícil es obtener datos limpios sin quedarse atascado con muros de inicio de sesión, cargas dinámicas, bloqueos temporales o configuraciones de scraping frágiles.
Esta selección anual está pensada para decidir rápido. Revalidé las páginas oficiales de producto, la documentación y las señales de precios el 8 de mayo de 2026, y luego mantuve la lista centrada en herramientas que todavía tienen sentido para usuarios reales de negocio. Si tu flujo de trabajo es, sobre todo, “tomar los datos de esta página y enviarlos a una hoja de cálculo”, empieza con Thunderbit. Si necesitas infraestructura a escala de API, Bright Data, Apify y Nimble by Nimbleway deberían estar entre las primeras opciones. Si tu trabajo incluye automatizaciones en la nube o acciones de seguimiento después de la recopilación, PhantomBuster merece una mirada más atenta.
Selección rápida según la tarea
- ¿Necesitas la exportación más rápida sin código de Facebook o Marketplace? Empieza con .
- ¿Necesitas escala empresarial de API y desbloqueo gestionado? Selecciona .
- ¿Necesitas flujos de trabajo de scraping en la nube flexibles? Mira de cerca .
- ¿Necesitas recopilación web pública orientada a API con menos mantenimiento del scraper? Considera .
- ¿Necesitas una API asequible para trabajos más ligeros? sigue siendo relevante.
- ¿Necesitas scraping más automatización de flujos? encaja mejor.
- ¿Necesitas un generador de flujos visual con programación? sigue siendo una opción sólida sin código.
Por qué sigue siendo difícil extraer datos de Facebook en 2026
La recopilación de datos en Facebook rara vez es solo un problema de selectores. En la práctica, la mayoría de los equipos se encuentra con uno o varios de estos problemas:
- Acceso público parcial: Algunas páginas siguen siendo públicas, mientras que otros flujos te empujan a iniciar sesión para ver más detalles.
- Contenido dinámico: Las vistas de Marketplace, los hilos largos de comentarios y el contenido de las páginas suelen cargarse de forma incremental.
- Defensas anti-bot: Límites de velocidad, comprobaciones de comportamiento, CAPTCHA y bloqueos temporales de acciones rompen las automatizaciones ingenuas.
- Riesgo operativo: La recopilación que depende de sesión es mucho más arriesgada que el scraping de páginas públicas, especialmente si te importa la seguridad de la cuenta y la repetibilidad.
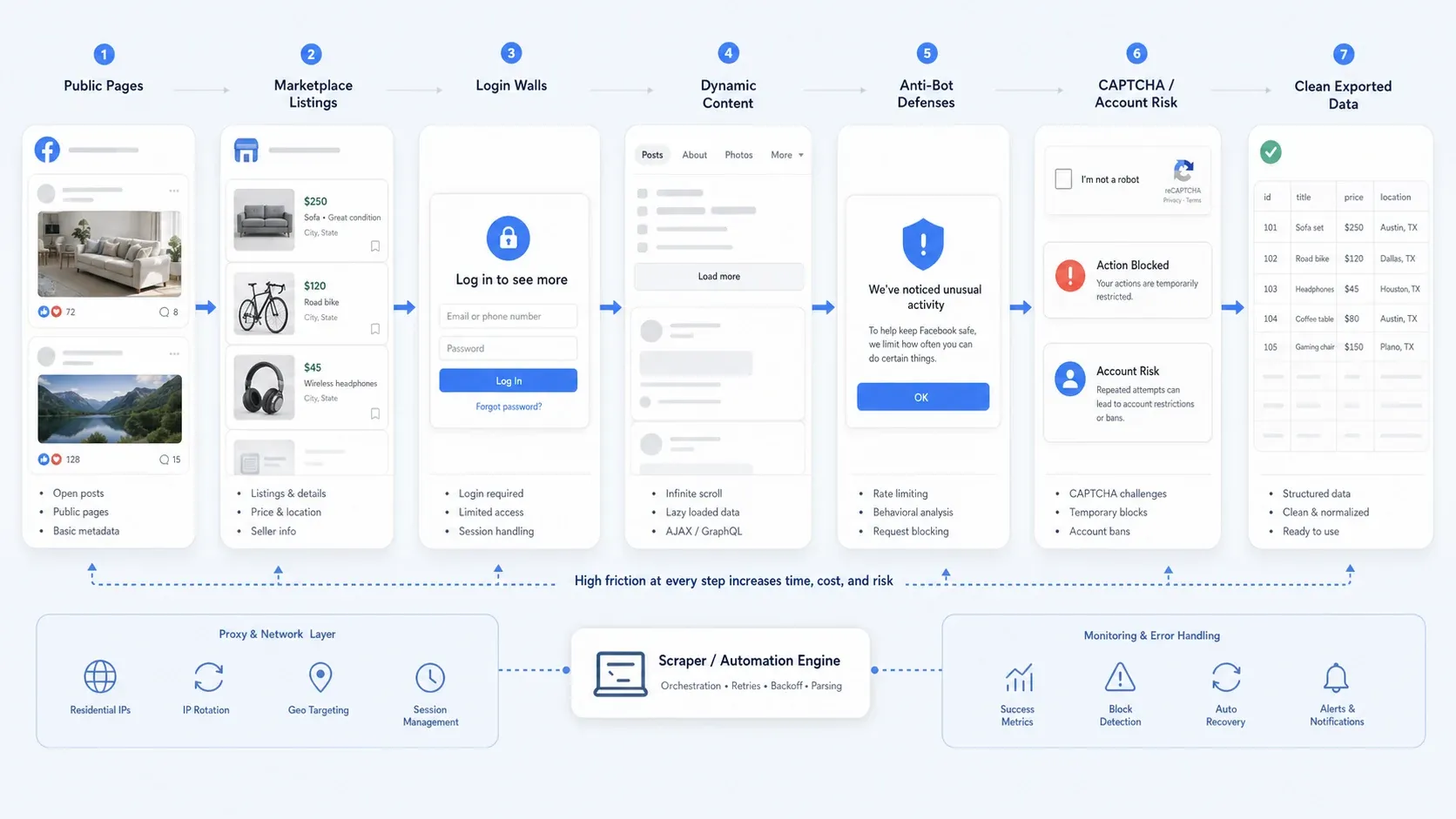
Cómo evalué estas herramientas
Optimicé esta página para construir una lista corta, no para inflarla con funciones. Las herramientas de aquí se compararon según:
- Ajuste al flujo de trabajo: ¿El producto realmente encaja con las tareas de recopilación de Facebook y Marketplace que hacen los equipos reales?
- Facilidad de uso: ¿Pueden los no desarrolladores o los equipos pequeños obtener resultados útiles rápidamente?
- Escala y fiabilidad: ¿La herramienta sigue teniendo sentido cuando pasas de una extracción puntual a un uso continuo?
- Gestión anti-bot y de sesiones: ¿Cuánto dolor de infraestructura elimina el producto?
- Calidad del resultado: ¿Puedes llevar datos estructurados a CSV, Sheets o sistemas posteriores sin mucha limpieza?
- Señal de precios: ¿Es un producto práctico para evaluar o requiere un proceso empresarial pesado?
- Postura de cumplimiento: ¿La herramienta está claramente orientada a la recopilación de datos públicos y al uso responsable?
¿Qué tipo de scraper de Facebook necesitas?
La forma más rápida de elegir bien es elegir primero la categoría correcta. Las herramientas para extraer datos de Facebook suelen caer en cuatro modelos operativos:
- Herramientas de navegador sin código: Son ideales cuando quieres extraer rápido desde la página que ya tienes abierta delante de ti.
- APIs de scraper: Son la mejor opción cuando necesitas una recopilación fiable y repetible a mayor volumen.
- Flujos de automatización: Son mejores cuando el scraping es solo un paso dentro de un proceso de go-to-market más amplio.
- Stacks de desarrollo hechos a medida: Son ideales cuando tu equipo quiere el máximo control y está dispuesto a asumir la carga de mantenimiento.
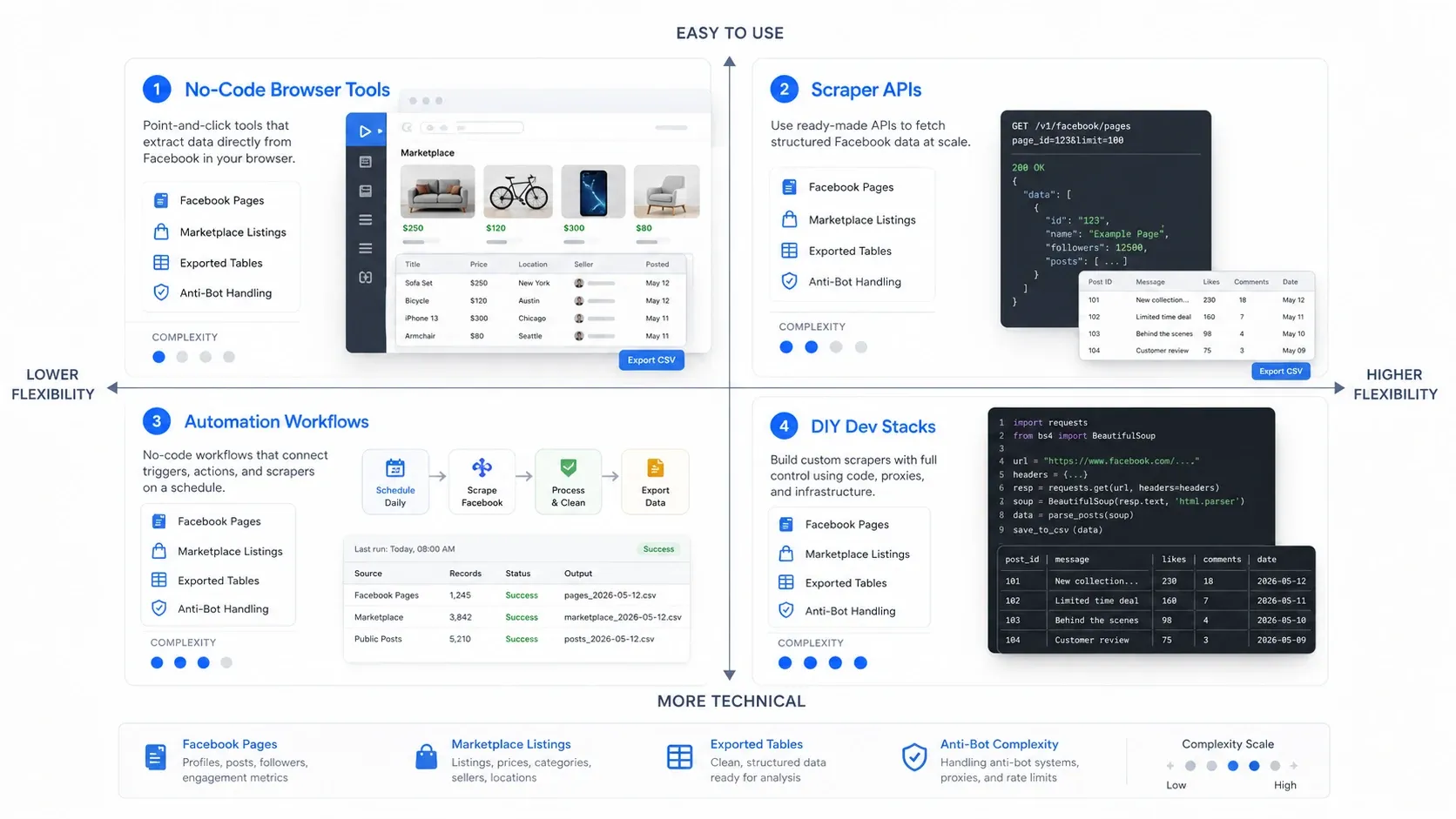
Tabla comparativa
| Herramienta | Ideal para | Por qué entró en la lista | Señal de precio |
|---|---|---|---|
| Thunderbit | Equipos no técnicos y trabajos ad hoc rápidos | Detección de campos con IA, manejo nativo del navegador para páginas dinámicas, exportaciones rápidas | Prueba gratis; planes de pago basados en créditos |
| Bright Data | Canales de datos sociales públicos a gran escala | APIs dedicadas para scraping de redes sociales, desbloqueo gestionado, gran escala | Precios por uso y empresariales |
| Apify | Flujos de trabajo de scraping flexibles en la nube | Actores de Facebook listos para usar, programación, acceso por API, margen de personalización | Planes de plataforma de pago más uso medido |
| Nimble by Nimbleway | Recopilación web pública orientada a API | Flujo de API centrado en URL y menor carga de mantenimiento del scraper | Precios gestionados por ventas |
| ScrapingBot | Trabajos pequeños con datos públicos y prototipos | API sencilla, compatibilidad con renderizado, menor precio de entrada | Nivel gratuito; planes de pago desde unos 22 $/mes |
| PhantomBuster | Flujos de automatización de GTM | Automatizaciones en la nube, flujos de trabajo basados en acciones del navegador, encaje para generación de leads | Prueba gratis; planes de pago desde unos 56 $/mes |
| Octoparse | Scraping programado visual sin código | Generador de arrastrar y soltar, extracción en la nube, flujos repetibles | Plan gratuito; planes de pago desde unos 119 $/mes |
1. Thunderbit
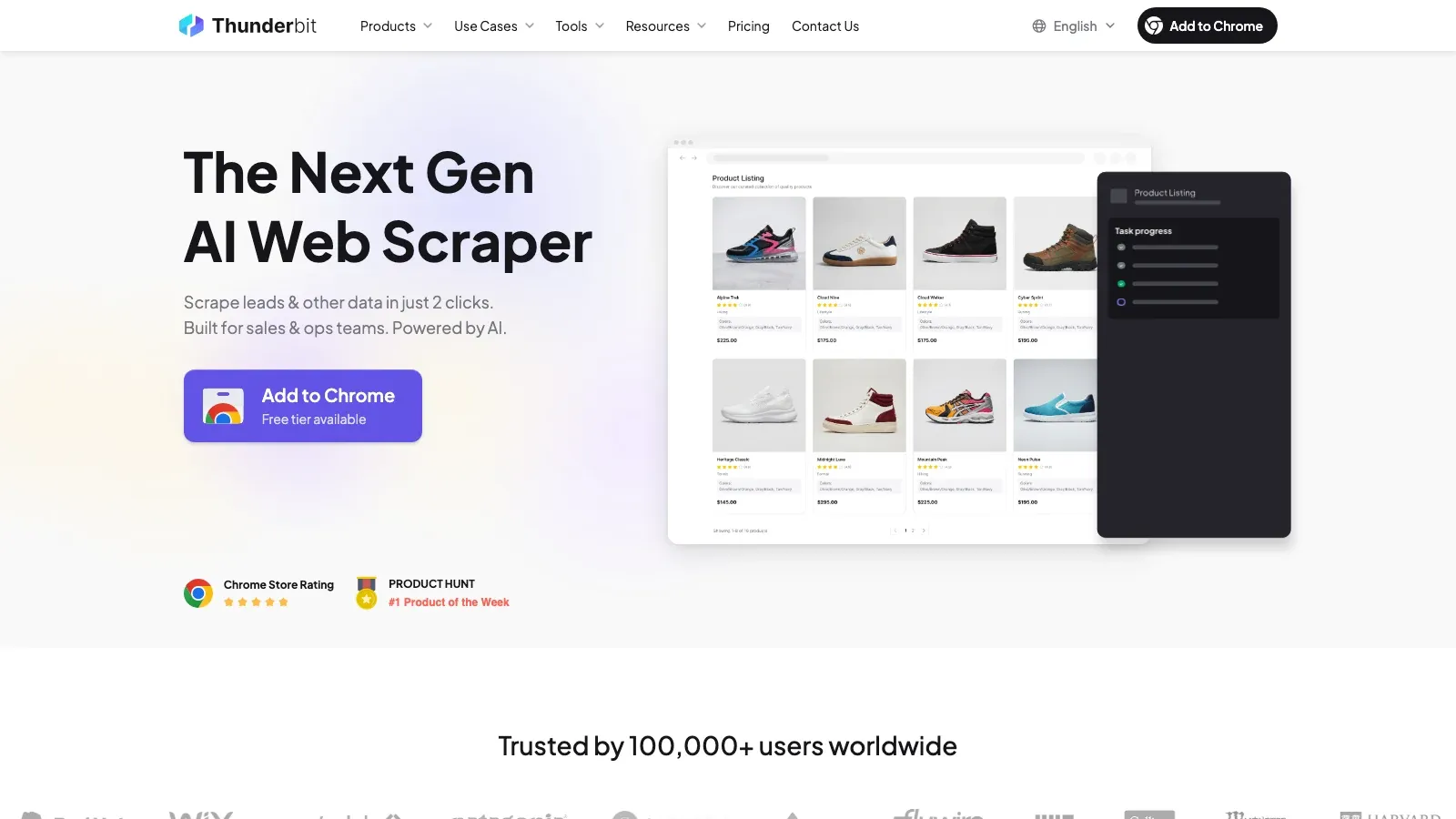
es la mejor opción aquí si tu objetivo es convertir rápidamente una página de Facebook o un listado de Marketplace en datos estructurados, sin construir ni mantener un scraper. Su ventaja principal es la extracción semántica: lee la página, sugiere campos útiles y te permite exportar el resultado sin lidiar con selectores, proxies ni código.
Por qué destaca:
- AI Suggest Fields: Thunderbit identifica campos probables como título, precio, vendedor, ubicación, datos de contacto y URLs.
- Manejo nativo del navegador: Como se ejecuta donde se renderiza la página, funciona bien en páginas dinámicas y con mucho scroll.
- Enriquecimiento de subpáginas: Puedes recopilar primero los datos de la lista y luego abrir cada anuncio o página para obtener más detalles.
- Exportaciones útiles: Excel, Google Sheets, Airtable y Notion son destinos naturales.
Si quieres ver un video antes de probar por tu cuenta un flujo nativo del navegador, este tutorial práctico de Thunderbit es el mejor punto de partida porque muestra el flujo real de extracción en lugar de quedarse en la promesa de funciones:
Ideal para: usuarios no técnicos, equipos de ventas, operaciones e investigadores que quieren resultados rápido.
Señal de precio: Hay prueba gratis; los planes de pago se basan en créditos. Consulta los .
2. Bright Data
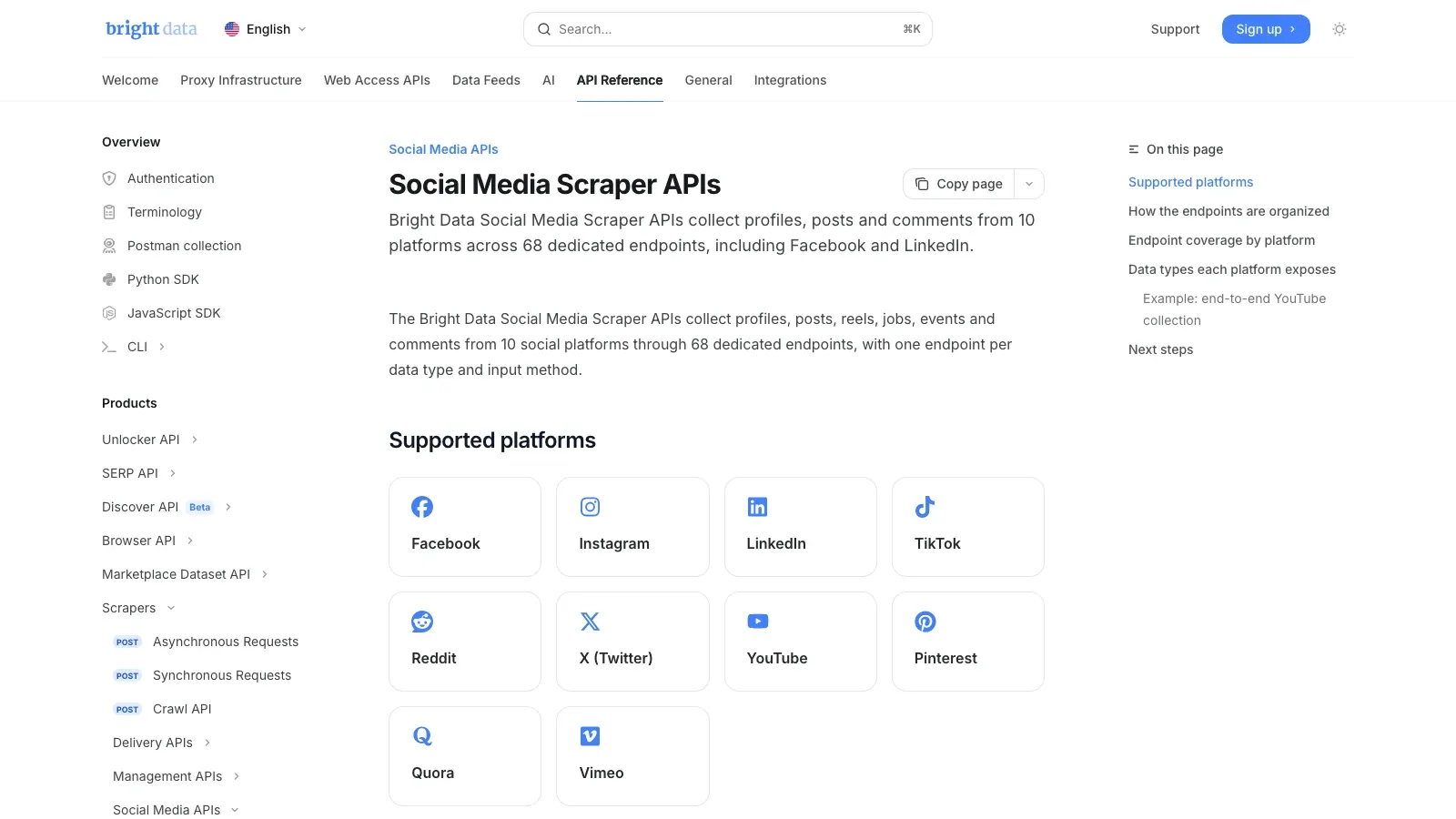
es la opción centrada en infraestructura. La propia documentación de Bright Data indica que sus cubren 10 plataformas y 68 endpoints dedicados, incluido Facebook. Si tu trabajo es la recopilación de datos públicos a gran escala, este tipo de stack de API gestionada suele ser mucho más realista que intentar escalar una extensión de navegador o un scraper hecho a mano.
Por qué merece estar en la lista corta:
- Endpoints dedicados para scraping de redes sociales
- Desbloqueo y extracción gestionados
- Entrega de salida estructurada para canales de datos
- Mejor ajuste para tareas de monitorización y analítica sensibles a la fiabilidad
Ideal para: analistas, equipos de datos, proyectos de monitorización grandes y conjuntos de datos sociales públicos a escala.
Señal de precio: El precio varía según el producto y el volumen. Verifica los .
3. Apify
sigue siendo relevante porque ofrece un buen punto intermedio entre plantillas y personalización total. Su actor Facebook Pages Scraper es un punto de partida útil, mientras que la plataforma más amplia de Apify aporta ejecución en la nube, programación, APIs y espacio para ampliar el flujo si tus necesidades se vuelven más complejas.
Por qué entró en la lista:
- Actores de Facebook listos para usar
- Ejecución en la nube y programaciones recurrentes
- Exportaciones flexibles y acceso por API
- Más fácil de ampliar que un flujo puramente visual sin código
Ideal para: marketers técnicos, agencias, equipos de operaciones y trabajos de recopilación recurrentes en varios sitios.
Señal de precio: Los planes de plataforma son de pago y el uso de cada actor se mide por separado. Consulta los .
4. Nimble by Nimbleway
es la opción orientada a API para equipos que quieren enviar una URL y dejar que la plataforma se encargue del acceso, el renderizado y la entrega. Nimble presenta su como una recopilación integral de datos web públicos, lo que la hace útil cuando el scraping de Facebook es solo una parte de una infraestructura de datos más amplia.
Por qué merece evaluarse:
- Flujo de API centrado en URL
- Menor carga de mantenimiento del scraper para los equipos de ingeniería
- Buen ajuste para una extracción resiliente de la web pública
- Útil cuando los datos extraídos alimentan productos internos o paneles
Ideal para: equipos dirigidos por ingeniería, canalizaciones de datos de producto y organizaciones que quieren abstracción de infraestructura en lugar de herramientas puntuales.
Señal de precio: Nimble no destaca precios públicos de autoservicio en sus páginas principales de API, así que espera precios gestionados por ventas y verifica directamente con .
5. ScrapingBot
es la opción de API más asequible de esta lista. No es la plataforma más especializada en Facebook de aquí, pero sigue teniendo sentido para trabajos pequeños de datos públicos en los que quieres una API, compatibilidad con renderizado y un coste de entrada más bajo que el de una infraestructura empresarial de scraping.
Dónde encaja:
- Scraping público simple basado en API
- Precio de entrada más bajo
- Incluye renderizado y gestión de proxies
- Mejor para prototipos y extracciones ligeras recurrentes que para grandes programas de inteligencia
Ideal para: startups, pequeñas empresas y desarrolladores que prueban casos de uso de recopilación más ligera de páginas públicas.
Señal de precio: Hay nivel gratuito; la página pública de precios actual empieza los planes de pago en unos .
6. PhantomBuster
se centra menos en la infraestructura pura de scraping y más en lo que ocurre después de la recopilación. Si tu caso de uso es “recopila los datos y luego activa outreach, enriquecimiento o acciones de seguimiento”, PhantomBuster suele ser más útil que un extractor simple porque está diseñado alrededor de automatizaciones en la nube y flujos de trabajo basados en acciones del navegador.
Por qué los equipos siguen incluyéndolo en la lista corta:
- Flujos de automatización basados en la nube
- Útil para generación de leads y operaciones de GTM
- Mejor encaje cuando el scraping es solo un paso dentro de un proceso más amplio
- Práctico para operadores que se preocupan por las acciones, no solo por las exportaciones
Ideal para: equipos de GTM, equipos de growth, recruiters y operadores que enlazan la recopilación con acciones posteriores.
Señal de precio: Hay prueba gratis; los planes de pago en la página actual de precios comienzan en unos .
7. Octoparse
sigue siendo una de las mejores herramientas visuales sin código para usuarios que quieren flujos repetibles y ejecuciones programadas en la nube. No es tan ligera como Thunderbit para trabajos rápidos de Facebook de una sola vez, pero da a los no desarrolladores un control más explícito sobre cómo se construye y se repite la lógica de extracción.
Por qué sigue siendo relevante:
- Generador visual de flujos de arrastrar y soltar
- Extracción en la nube y programación
- Buena para tareas estructuradas y repetitivas
- Más adecuada para analistas que quieren repetibilidad sin código
Ideal para: analistas no técnicos, equipos de operaciones de pymes y tareas de recopilación repetibles con lógica de flujo más explícita.
Señal de precio: La página pública de precios de Octoparse indica planes de pago desde unos .
Lista corta por tipo de equipo
Si ya sabes qué tipo de equipo se encargará del flujo, empieza aquí:
- Operador individual o pequeña empresa: Thunderbit, ScrapingBot u Octoparse
- Equipo de ventas / GTM: Thunderbit o PhantomBuster
- Analista de operaciones: Thunderbit, Apify u Octoparse
- Equipo de automatización de growth: PhantomBuster o Apify
- Equipo de ingeniería de datos: Bright Data, Nimble o Apify

Cómo elegir el scraper de Facebook adecuado
- Elige Thunderbit si la velocidad y la simplicidad importan más que la máxima escala.
- Elige Bright Data si necesitas escala de datos públicos y fiabilidad gestionada.
- Elige Apify si quieres flexibilidad de plataforma y flujos basados en actores.
- Elige Nimble si quieres una capa de abstracción orientada a API con menos mantenimiento del scraper.
- Elige PhantomBuster si el scraping es solo un paso dentro de un flujo más amplio de automatización de GTM.
- Elige Octoparse si quieres repetibilidad visual sin código.
- Elige ScrapingBot si el presupuesto importa y la tarea es relativamente simple.
Conclusión final
La división del mercado es más clara en 2026 que hace un año. En realidad no estás eligiendo un “mejor scraper de Facebook” universal. Estás eligiendo un modelo de recopilación: extracción rápida sin código, escala gestionada por API, automatización en la nube o control práctico de flujos visuales. Empieza por ahí y la lista corta se vuelve mucho más fácil.
Si tu equipo quiere el camino más rápido desde una página de Facebook o un listado de Marketplace hasta datos estructurados útiles, Thunderbit sigue siendo el lugar más fácil para empezar. Si tu volumen o tus requisitos de ingeniería son mucho más altos, Bright Data, Apify y Nimble tienen más sentido. Si tu flujo empieza con scraping pero termina en acciones de seguimiento, PhantomBuster es la selección más inteligente.
Preguntas frecuentes
1. ¿Cuál es la herramienta más fácil para extraer datos de Facebook para usuarios no técnicos?
Thunderbit es el punto de partida más fácil para la mayoría de los usuarios no técnicos porque funciona en el navegador, sugiere campos automáticamente y exporta datos rápidamente sin código.
2. ¿Qué herramienta para extraer datos de Facebook es la mejor para la recopilación de datos públicos a gran escala?
Bright Data es la opción de infraestructura más sólida de esta lista cuando el trabajo consiste en recopilar datos sociales públicos a gran escala y la fiabilidad importa más que la facilidad de uso.
3. ¿Y si necesito scraping más automatización de seguimiento?
PhantomBuster es la mejor opción cuando la recopilación de datos es solo un paso dentro de un flujo más amplio de generación de leads o GTM.
4. ¿Sigue siendo difícil extraer datos de Facebook en 2026?
Sí. El contenido dinámico, los muros de inicio de sesión, los límites de velocidad, los sistemas anti-bot y los riesgos de cuenta siguen haciendo que Facebook sea más difícil que extraer datos de sitios públicos más simples.
5. ¿Cómo deberían pensar los equipos sobre el cumplimiento?
Mantente centrado en datos públicos, usa tasas razonables, evita el abuso de credenciales y revisa los términos de la plataforma y las normas de privacidad aplicables antes de escalar un flujo de trabajo.
Lecturas adicionales: