

Cuando me metí por primera vez en el mundo del raspado web, pensé: “¿Qué tan complicado puede ser? Solo hay que sacar el HTML y ya está, ¿no?” Pero pronto me di cuenta de que el raspado web se ha vuelto una habilidad clave para quienes trabajan en ventas, e-commerce o análisis de mercado. Internet está lleno de datos—más de mil millones de páginas web y subiendo—y las empresas quieren aprovechar toda esa información. El problema es que la mayoría de esos datos están escondidos detrás de páginas dinámicas, JavaScript y elementos interactivos que las herramientas básicas no pueden alcanzar.
Aquí es donde entran en juego herramientas de Python scraper como Selenium. Selenium Python te permite automatizar un navegador real, lo que hace posible extraer datos incluso de los sitios más dinámicos. Pero, como verás en este tutorial selenium python para principiantes, no siempre es tan fácil como parece. Vamos a ver un ejemplo práctico—raspando datos de productos de allbirds.com—para que veas cómo funciona Selenium en la vida real. Y, porque siempre busco simplificarte la vida, también te mostraré cómo nuevas herramientas con IA como Thunderbit pueden hacer el mismo trabajo en mucho menos tiempo (y casi sin escribir código).
Por qué el raspado web es clave (y por qué los sitios modernos complican todo)
Para que te hagas una idea: el raspado web ya no es solo cosa de frikis. Es parte fundamental del día a día para equipos de ventas, marketing, e-commerce y operaciones. ¿Quieres vigilar los precios de la competencia? ¿Buscar leads? ¿Analizar opiniones de clientes? El raspado web es la respuesta. De hecho, más de un tercio de los desarrolladores dicen que los datos de precios son su principal objetivo, y entre el 80 y 90% de los datos online no están estructurados—es decir, no puedes simplemente copiarlos y pegarlos en Excel.
Pero aquí viene el lío: los sitios modernos son dinámicos. Cargan contenido con JavaScript, esconden datos tras botones o te obligan a hacer scroll infinito. Herramientas simples como requests o BeautifulSoup solo ven el HTML estático—es como leer un periódico que nunca se actualiza. Si la información que buscas aparece solo después de hacer clic, desplazarte o iniciar sesión, necesitas una herramienta que actúe como un usuario real.
¿Qué es Selenium Python y por qué usarlo para raspado web?
Entonces, ¿qué es Selenium Python? Básicamente, Selenium es una herramienta para automatizar navegadores. Te permite escribir scripts en Python que controlan un navegador real—pueden hacer clic en botones, rellenar formularios, desplazarse por páginas y, por supuesto, extraer datos que solo aparecen después de esas acciones.
Cómo Selenium Python se diferencia de los scrapers básicos
- Selenium Python: Automatiza un navegador real (como Chrome), ejecuta JavaScript, interactúa con elementos dinámicos y espera a que el contenido cargue—igual que lo haría una persona.
- Requests/BeautifulSoup: Solo obtiene el HTML estático. Es rápido y ligero, pero no puede con JavaScript ni con contenido generado en el momento.
Piensa en Selenium como tu robot personal: puede hacer todo lo que tú harías en el navegador, pero necesita instrucciones claras (y un poco de paciencia).
¿Cuándo deberías usar Selenium?
- Feeds con scroll infinito (por ejemplo: redes sociales, listados de productos)
- Filtros interactivos o menús desplegables (como elegir talla de zapato en allbirds.com)
- Contenido tras inicio de sesión o pop-ups
- Aplicaciones de una sola página (React, Vue, etc.)
Si solo necesitas extraer texto estático de una página sencilla, BeautifulSoup te basta. Pero para cualquier cosa dinámica, Selenium es tu mejor amigo.
Configurando tu entorno de Selenium Python
Antes de ponernos manos a la obra, vamos a preparar el terreno. Te guío paso a paso—no necesitas experiencia previa.
1. Instalando Python y Selenium
Primero, asegúrate de tener Python 3 instalado. Descárgalo desde la web oficial de Python. Para comprobarlo, ejecuta:
python --version
Luego, instala Selenium usando pip:
pip install selenium
Esto descargará la última versión de Selenium para Python. Fácil, ¿no?
2. Descargando y configurando ChromeDriver
Selenium necesita un “driver” para controlar tu navegador. Para Chrome, es ChromeDriver.
- Averigua tu versión de Chrome: Abre Chrome, ve a Menú → Ayuda → Acerca de Google Chrome.
- Descarga el ChromeDriver correspondiente: Elige la versión que coincida con tu navegador.
- Extrae y coloca el driver: Pon
chromedriver.exe(o el equivalente en Mac/Linux) en tu PATH del sistema, o simplemente en la carpeta de tu proyecto.
Tip: Hay paquetes de Python como webdriver_manager que pueden descargar los drivers automáticamente, pero para empezar, hacerlo a mano está bien.
3. Probando tu configuración
Vamos a comprobar que todo funciona. Crea un archivo Python llamado test_selenium.py:
from selenium import webdriver
driver = webdriver.Chrome()
driver.get("https://www.example.com")
print(driver.title)
driver.quit()
Ejecuta el script. Deberías ver que Chrome se abre, visita example.com, imprime el título y se cierra. Si ves el mensaje “Chrome está siendo controlado por un software de pruebas automatizadas”, ¡ya lo tienes listo!
Tu primer script con Selenium Python: Raspando allbirds.com
Vamos a poner Selenium en acción. Nuestra misión: extraer nombres y precios de productos de allbirds.com/collections/mens.
Paso 1: Abre el navegador y navega a la página
from selenium import webdriver
from selenium.webdriver.common.by import By
driver = webdriver.Chrome()
driver.get("https://www.allbirds.com/collections/mens")
Paso 2: Espera a que cargue el contenido dinámico
Los sitios dinámicos no siempre cargan al instante. Usaremos las funciones de espera de Selenium:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.CSS_SELECTOR, "div.product-card"))
)
(Te recomiendo inspeccionar el sitio para confirmar los selectores CSS correctos. En este ejemplo, asumimos que las tarjetas de producto usan div.product-card.)
Paso 3: Localiza los elementos y extrae los datos
products = driver.find_elements(By.CSS_SELECTOR, "div.product-card")
print(f"Found {len(products)} products")
data = []
for prod in products:
name = prod.find_element(By.CSS_SELECTOR, ".product-name").text
price = prod.find_element(By.CSS_SELECTOR, ".price").text
data.append((name, price))
print(name, "-", price)
Deberías ver una salida como:
Found 24 products
Wool Runner - $110
Tree Dasher 2 - $135
...
Paso 4: Guarda los datos en un archivo CSV
Vamos a guardar los resultados en un CSV:
import csv
with open("allbirds_products.csv", "w", newline="") as f:
writer = csv.writer(f)
writer.writerow(["Product Name", "Price"])
writer.writerows(data)
Y no olvides cerrar el navegador:
driver.quit()
Abre tu archivo CSV y listo—nombres y precios de productos listos para analizar.
Cómo resolver los problemas más comunes del raspado web con Selenium Python
En la práctica, el raspado rara vez sale perfecto a la primera. Aquí tienes cómo enfrentarte a los problemas más habituales:
Esperar a que los elementos carguen
Los sitios dinámicos pueden tardar. Usa esperas explícitas:
WebDriverWait(driver, 10).until(
EC.visibility_of_element_located((By.CSS_SELECTOR, ".product-card"))
)
Así te aseguras de que tu script no intente extraer elementos antes de que existan.
Manejar la paginación
¿Quieres más que la primera página de resultados? Haz un bucle por las páginas:
while True:
try:
next_btn = driver.find_element(By.LINK_TEXT, "Next")
next_btn.click()
WebDriverWait(driver, 10).until(EC.presence_of_element_located((By.CSS_SELECTOR, ".product-card")))
except Exception:
break # No hay más páginas
O, para scroll infinito:
import time
last_height = driver.execute_script("return document.body.scrollHeight")
while True:
driver.execute_script("window.scrollTo(0, document.body.scrollHeight);")
time.sleep(2)
new_height = driver.execute_script("return document.body.scrollHeight")
if new_height == last_height:
break
last_height = new_height
Gestionar pop-ups e inicios de sesión
¿Un pop-up bloqueando tu camino? Ciérralo así:
driver.find_element(By.CSS_SELECTOR, ".modal-close").click()
¿Necesitas automatizar un login? Rellena los campos y envía:
driver.find_element(By.ID, "email").send_keys("user@example.com")
driver.find_element(By.NAME, "login").click()
Recuerda: los CAPTCHAs y la autenticación en dos pasos son difíciles de automatizar.
Desventajas de usar Selenium Python para raspado web
Seamos sinceros—Selenium es potente, pero no siempre es la opción más cómoda:
- Lento: Cada página carga un navegador completo, con imágenes y scripts. ¿Vas a extraer 1,000 páginas? Prepárate para esperar.
- Consume muchos recursos: Usa bastante CPU y memoria. Si ejecutas muchos navegadores a la vez, necesitas un equipo potente.
- Configuración compleja: Hacer coincidir la versión de ChromeDriver, gestionar actualizaciones, escribir código para cada sitio—el mantenimiento puede ser tedioso.
- Frágil: Si el sitio cambia su diseño, tu script puede dejar de funcionar de la noche a la mañana.
- Limpieza de datos manual: ¿Quieres traducir descripciones o analizar sentimientos? Tendrás que añadir librerías o APIs extra.
Para usuarios de negocio sin perfil técnico, o quienes solo quieren datos estructurados rápidamente, Selenium puede sentirse como usar un tanque para una pelea de bolas de nieve.

Descubre Thunderbit: la alternativa con IA a Selenium Python
Ahora hablemos de una herramienta que está revolucionando el raspado web para usuarios de negocio: Thunderbit. Thunderbit es un Raspador Web IA en formato de extensión de Chrome que te permite extraer datos de cualquier sitio—sin código, sin líos, solo unos clics.
Extrae datos de cualquier sitio web usando IA Get Started Free
Por qué Thunderbit es diferente
- Detección de campos con IA: Haz clic en “Sugerir campos con IA” y la IA de Thunderbit identifica automáticamente qué extraer—nombres de productos, precios, imágenes, lo que necesites.
- Raspado de subpáginas: ¿Necesitas detalles de páginas de producto? Thunderbit puede navegar y extraer información adicional automáticamente.
- Enriquecimiento de datos: Traduce descripciones, resume textos o analiza sentimientos—todo mientras extraes los datos.
- Exportación con un clic: Envía tus datos directamente a Excel, Google Sheets, Notion o Airtable. Sin código, sin complicaciones.
- Interfaz sin código: Pensado para quienes no programan. Si sabes usar un navegador, puedes usar Thunderbit.
No lo niego (¡ayudé a crear Thunderbit!), pero sinceramente creo que es la forma más rápida para que equipos de negocio obtengan datos web estructurados—especialmente en ventas, e-commerce e investigación.
Thunderbit vs. Selenium Python: Comparativa directa
Veamos las diferencias:
| Criterio | Selenium Python | Thunderbit (IA, Sin Código) |
|---|---|---|
| Tiempo de configuración | Moderado a complejo—instalar Python, Selenium, ChromeDriver, escribir código | Muy rápido—instala la extensión de Chrome, listo en minutos |
| Habilidad necesaria | Alta—requiere saber programar y conocer HTML | Baja—solo apuntar y hacer clic, la IA hace el trabajo pesado |
| Contenido dinámico | Excelente—puede manejar JS, clics, scroll | Excelente—funciona en el navegador, soporta AJAX, scroll infinito, subpáginas |
| Velocidad | Lento—por la carga del navegador | Rápido para trabajos pequeños/medianos—detección automática por IA, acceso directo al DOM |
| Escalabilidad | Difícil de escalar—consume muchos recursos | Ideal para cientos/miles de elementos; no para scraping masivo |
| Procesamiento de datos | Manual—hay que programar limpieza, traducción, análisis de sentimiento | Automático—la IA puede traducir, resumir, categorizar y enriquecer al instante |
| Opciones de exportación | Código personalizado para CSV, Sheets, etc. | Exportación con un clic a Excel, Google Sheets, Notion, Airtable |
| Mantenimiento | Alto—sensible a cambios en el sitio | Bajo—la IA se adapta a muchos cambios de diseño, mínimo mantenimiento |
| Funciones únicas | Automatización total del navegador, flujos personalizados | Insights con IA, plantillas predefinidas, enriquecimiento de datos, extractores gratuitos |
Para la mayoría de usuarios de negocio, Thunderbit es un soplo de aire fresco—adiós a pelear con código o drivers de navegador.
Caso práctico: Raspando allbirds.com con Thunderbit
Veamos cómo Thunderbit resuelve la misma tarea en allbirds.com:
- Instala la extensión de Chrome Thunderbit
- Navega a allbirds.com/collections/mens
- Haz clic en el icono de Thunderbit y pulsa “Sugerir campos con IA”
- La IA de Thunderbit detectará automáticamente columnas como “Nombre del producto”, “Precio”, “URL del producto”, etc.
- (Opcional) Añade una columna para “Descripción (Japonés)” o “Sentimiento”
- La IA de Thunderbit traducirá o analizará mientras extrae los datos.
- Haz clic en “Extraer”
- Thunderbit recopilará todos los datos de productos en una tabla.
- Exporta a Google Sheets, Notion o Excel con un solo clic
Sin código, sin esperar a que cargue el navegador, sin pelear con archivos CSV. Solo datos estructurados, listos para usar.
Prueba Thunderbit Raspador Web IA Gratis
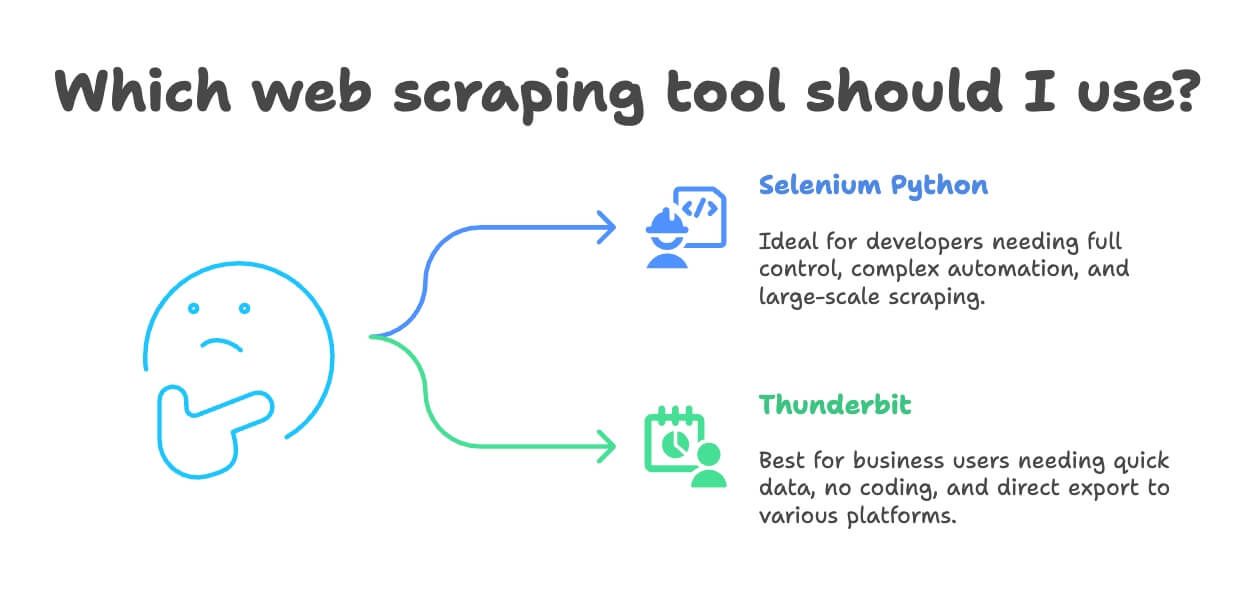
¿Cuándo usar Selenium Python y cuándo Thunderbit para raspado web?
Entonces, ¿cuál herramienta te conviene? Aquí va mi consejo:
- Usa Selenium Python si:
- Eres desarrollador o necesitas control total sobre la automatización del navegador
- La tarea de raspado es muy personalizada o parte de un proyecto de software más grande
- Debes automatizar flujos complejos (logins, descargas, formularios de varios pasos)
- Vas a extraer datos a gran escala (y tienes la infraestructura adecuada)
- Usa Thunderbit si:
- Eres usuario de negocio, analista o marketer y necesitas datos rápido
- Quieres evitar programar y configurar herramientas
- Necesitas traducción, análisis de sentimiento o enriquecimiento de datos mientras extraes
- Tu proyecto es de pequeña o mediana escala (cientos o pocos miles de registros)
- Quieres exportar directamente a Excel, Google Sheets, Notion o Airtable
Sinceramente, he visto equipos pasar días creando scripts con Selenium para tareas que Thunderbit resuelve en 10 minutos. A menos que necesites mucha personalización o scraping masivo, Thunderbit suele ser la opción más rápida y amigable.
Extra: Consejos para un raspado web responsable y efectivo
Antes de lanzarte a recolectar datos, ten en cuenta estos consejos:
- Respeta robots.txt y los Términos de Servicio: Siempre revisa qué está permitido. Si un sitio prohíbe el raspado, no te arriesgues.
- Controla la frecuencia de tus solicitudes: No satures los servidores—añade pausas o usa límites de velocidad.
- Rota user agents/IPs si es necesario: Ayuda a evitar bloqueos simples, pero no lo hagas si va contra las políticas del sitio.
- Evita extraer datos personales o sensibles: Limítate a información pública y respeta leyes de privacidad como GDPR.
- Usa APIs si están disponibles: Si un sitio ofrece API, úsala—es más seguro y estable.
- No extraigas datos tras logins o muros de pago sin permiso: Eso es ilegal y poco ético.
- Registra tu actividad y maneja errores con cuidado: Si te bloquean, detente y ajusta tu estrategia.
Para más información sobre ética y legalidad del raspado, revisa esta guía.
Conclusión: Elige la herramienta adecuada para tus necesidades de raspado web
El raspado web ha evolucionado muchísimo—de scripts manuales a herramientas sin código con IA. Como hemos visto, Selenium Python es una opción potente para desarrolladores que enfrentan sitios complejos y dinámicos, pero implica una curva de aprendizaje y mantenimiento. Para la mayoría de usuarios de negocio, Thunderbit ofrece una vía más rápida y sencilla para obtener datos web estructurados—con traducción, análisis de sentimiento y exportación con un solo clic.
¿Mi consejo? Prueba ambos enfoques. Si eres desarrollador, crea un script con Selenium para un sitio como allbirds.com y experimenta. Si quieres resultados rápidos (o evitarte dolores de cabeza), dale una oportunidad a Thunderbit. Hay una versión gratuita, así que puedes probarlo hoy mismo en tu sitio favorito.
Y recuerda: haz raspado de forma responsable, usa los datos con criterio y que nunca te bloqueen la IP.
¿Quieres saber más? Mira estos recursos:
- Beautiful Soup vs Selenium: Comparativa detallada en 2025
- Las mejores herramientas y software de Web Scraping en 2025
- Cómo extraer datos de sitios web a Excel usando IA
- Página de descarga de la extensión Thunderbit para Chrome
Prueba Thunderbit Raspador Web IA Gratis Get Started Free




