

Déjame llevarte de vuelta a la primera vez que intenté extraer datos de productos de un sitio de comercio electrónico. Tenía Python, una taza de café y un sueño: crear un rastreador de precios para Amazon. Unas horas después, mi “proyecto rápido” se había convertido en un enredo de selectores XPath, dolores de cabeza con la paginación y más depuración de la que me gustaría admitir. Si alguna vez has intentado manejar datos web con código, seguro conoces esa sensación: mitad emoción, mitad “¿por qué esto es tan complicado?”.
La cosa es esta: el web scraping ya no es solo para científicos de datos o ingenieros. Se ha convertido en una habilidad imprescindible para equipos de ventas, responsables de e-commerce, especialistas en marketing y cualquiera que quiera convertir el caos de la web en inteligencia de negocio. De hecho, el mercado de software de web scraping alcanzó 1.010 millones de dólares en 2024 y se proyecta que llegue a 2.490 millones en 2032, y la curva no se está aplanando. Pero aunque Python y frameworks como Scrapy siguen siendo el estándar de oro para scraping personalizado a gran escala, no son precisamente fáciles para principiantes. Por eso, en este tutorial, te guiaré paso a paso por Scrapy —usando un caso real con Amazon— y te mostraré una alternativa mucho más sencilla, impulsada por IA, para quienes no programan: Thunderbit.
¿Qué es Scrapy en Python? Tu herramienta potente para web scraping
Empecemos por lo básico. Scrapy es un framework de Python de código abierto creado específicamente para rastreo web y web scraping. Piensa en él como un conjunto de herramientas todo en uno para crear spiders personalizados (así llama Scrapy a sus rastreadores) que pueden navegar sitios web, seguir enlaces, manejar paginación y extraer datos estructurados a escala.
¿En qué se diferencia Scrapy de usar solo requests y BeautifulSoup en Python? Pues bien, aunque esas bibliotecas son excelentes para extracciones simples y puntuales, Scrapy está diseñado para proyectos grandes y complejos, de esos en los que necesitas:
- Rastrear miles de páginas (piensa en: cada producto de un catálogo de e-commerce)
- Seguir enlaces automáticamente y manejar la paginación
- Procesar datos de forma asíncrona para ganar velocidad
- Estructurar, limpiar y exportar datos de manera repetible
En pocas palabras, Scrapy es como la navaja suiza del web scraping: potente, flexible y, para bien o para mal, un poco intimidante para quienes empiezan.
¿Por qué usar Scrapy en Python para web scraping?
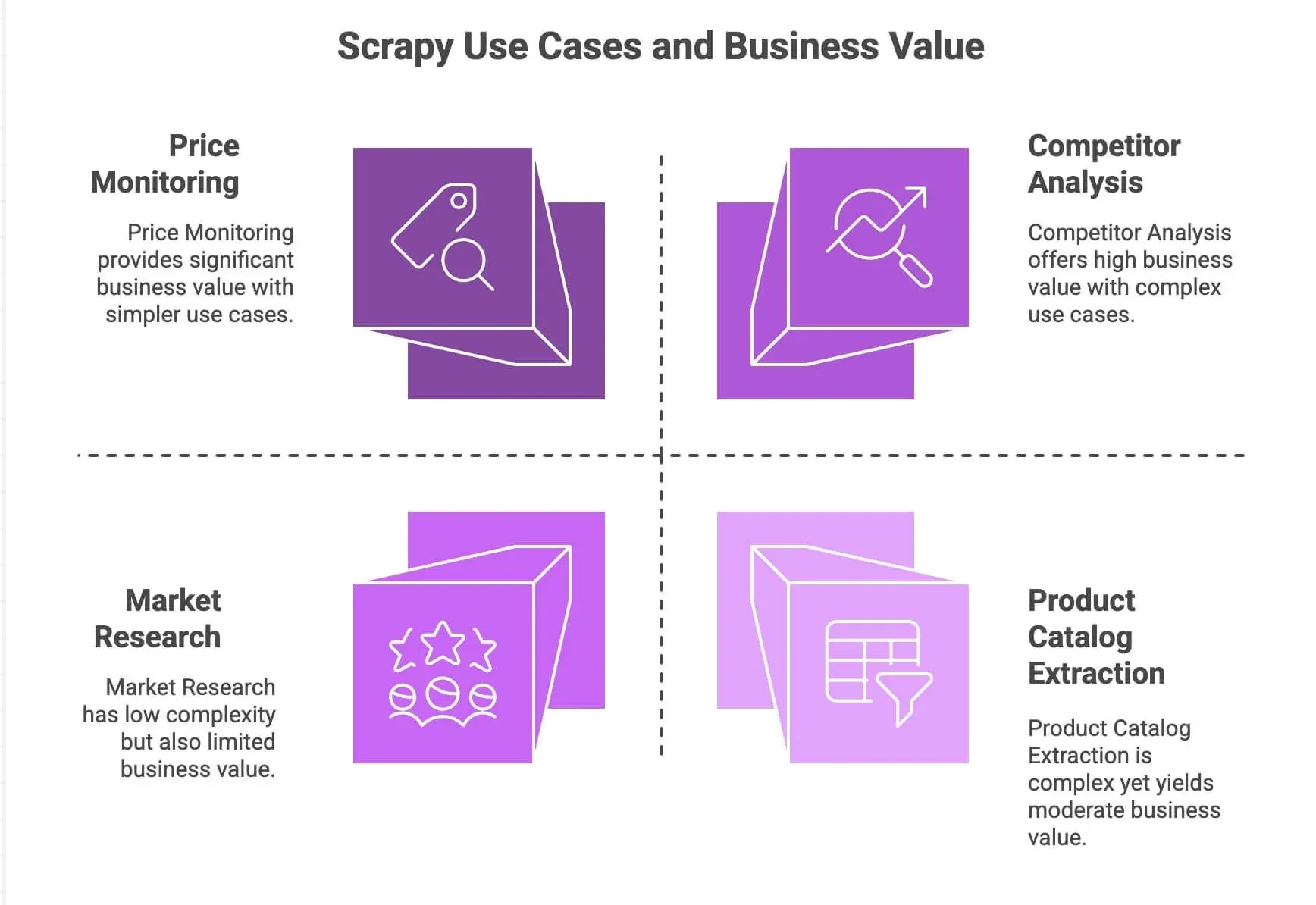
Entonces, ¿por qué desarrolladores y equipos de datos siguen recurriendo a Scrapy? Aquí tienes un resumen rápido de lo que lo hace destacar:
| Caso de uso | Fortalezas de Scrapy | Valor para el negocio |
|---|---|---|
| Seguimiento de precios | Maneja paginación, solicitudes asíncronas y programación | Adelántate a la competencia, precios dinámicos |
| Extracción de catálogos de productos | Sigue enlaces, extrae datos estructurados | Crea bases de datos de productos, alimenta analíticas |
| Análisis de la competencia | Escalable, resistente a cambios en el sitio | Sigue tendencias, nuevos lanzamientos, niveles de stock |
| Investigación de mercado | Pipelines modulares para limpiar y transformar datos | Agrega reseñas, realiza análisis de sentimiento |
El motor asíncrono de Scrapy (basado en Twisted) le permite obtener varias páginas en paralelo, lo que lo hace rápido y escalable. Su diseño modular te deja añadir lógica personalizada, como proxies, user-agents o pasos de limpieza de datos. Y con los pipelines, puedes procesar, validar y exportar datos como quieras: CSV, JSON, bases de datos, lo que sea.
Para equipos con conocimientos de Python, Scrapy es una máquina. Pero seamos honestos: no es precisamente de “enchufar y usar” para el usuario empresarial promedio.
Configurar tu entorno de Scrapy en Python
¿Listo para ensuciarte las manos? Así se configura Scrapy desde cero:
1. Instala Scrapy
Primero, asegúrate de tener instalado Python 3.10+ (Scrapy 2.15.x dejó de dar soporte a 3.9 en 2026). Luego, abre tu terminal y ejecuta:
pip install scrapy
Comprueba la instalación con:
scrapy version
Si usas Windows o Anaconda, quizá te convenga crear un entorno virtual para evitar conflictos. Scrapy funciona en Windows, macOS y Linux.
2. Crea un nuevo proyecto de Scrapy
Empecemos un proyecto nuevo llamado amazonscraper:
scrapy startproject amazonscraper
Obtendrás una estructura de carpetas como esta:
amazonscraper/
├── scrapy.cfg
├── amazonscraper/
│ ├── __init__.py
│ ├── items.py
│ ├── pipelines.py
│ ├── middlewares.py
│ ├── settings.py
│ └── spiders/
¿Para qué sirve cada archivo?
scrapy.cfg: configuración del proyecto (casi nunca tendrás que tocarlo)items.py: define tus modelos de datos (como un producto con nombre, precio, etc.)pipelines.py: donde limpias, validas y exportas tus datosmiddlewares.py: cosas más avanzadas (proxies, cabeceras personalizadas)settings.py: ajusta el comportamiento de Scrapy (concurrencia, retrasos, etc.)spiders/: donde vive tu lógica real de scraping
Si ya te sientes un poco abrumado, no eres el único. Aquí es donde muchos no programadores empiezan a sudar.
Crear un raspador en Python: extraer datos de productos de Amazon con Scrapy
Veamos un ejemplo real: extraer datos de productos de los resultados de búsqueda de Amazon. (Aviso: los términos de servicio de Amazon no permiten scraping y además aplican medidas agresivas contra bots. ¡Esto es solo con fines educativos!)
1. Crea un spider
Dentro de la carpeta spiders/, crea un archivo llamado amazon_spider.py:
import scrapy
class AmazonSpider(scrapy.Spider):
name = "amazon_example"
allowed_domains = ["amazon.com"]
start_urls = ["https://www.amazon.com/s?k=smartphones"]
def parse(self, response):
products = response.xpath("//div[@data-component-type='s-search-result']")
for product in products:
yield {
'name': product.xpath(".//span[@class='a-size-medium a-color-base a-text-normal']/text()").get(),
'price': product.xpath(".//span[@class='a-price-whole']/text()").get(),
'rating': product.xpath(".//span[@aria-label]/text()").get()
}
next_page = response.xpath("//li[@class='a-last']/a/@href").get()
if next_page:
yield scrapy.Request(url=response.urljoin(next_page), callback=self.parse)
¿Qué está pasando aquí?
- Empezamos en una página de resultados de búsqueda de Amazon para “smartphones”.
- Para cada producto, extraemos el nombre, el precio y la valoración usando selectores XPath.
- Buscamos el enlace de “siguiente página” y le decimos a Scrapy que lo siga para extraer más productos.
2. Ejecuta tu spider
Desde la raíz de tu proyecto, ejecuta:
scrapy crawl amazon_example -o products.json
Listo: Scrapy recorrerá los resultados de búsqueda, seguirá la paginación y guardará tus datos en un archivo JSON.
Manejo de paginación y contenido dinámico
El soporte integrado de Scrapy para seguir enlaces y manejar paginación es una de sus superpoderes. ¿Pero qué pasa con el contenido dinámico, es decir, páginas que cargan datos con JavaScript? De fábrica, Scrapy solo ve HTML estático. Si necesitas extraer contenido cargado por JavaScript (como scroll infinito o reseñas emergentes), tendrás que integrarlo con herramientas como Selenium o Splash. Y eso ya es otro agujero de conejo.
Procesar y exportar datos con Scrapy en Python
Una vez que hayas extraído tus datos, probablemente querrás limpiarlos y exportarlos a un lugar útil.
- Pipelines: en
pipelines.py, puedes escribir clases de Python para limpiar, validar o enriquecer tus datos (como convertir precios a números, eliminar filas incompletas o incluso llamar a una API de traducción). - Exportación: Scrapy puede exportar directamente a CSV, JSON o XML con la bandera
o. Para exportaciones más avanzadas (como enviar datos a Google Sheets), tendrás que escribir código adicional o usar bibliotecas de terceros.
¿Quieres hacer análisis de sentimiento o traducir descripciones de productos? Tendrás que integrarlo con APIs externas o bibliotecas de Python: no viene incorporado.
Los costes ocultos: retos de Scrapy en Python para usuarios de negocio
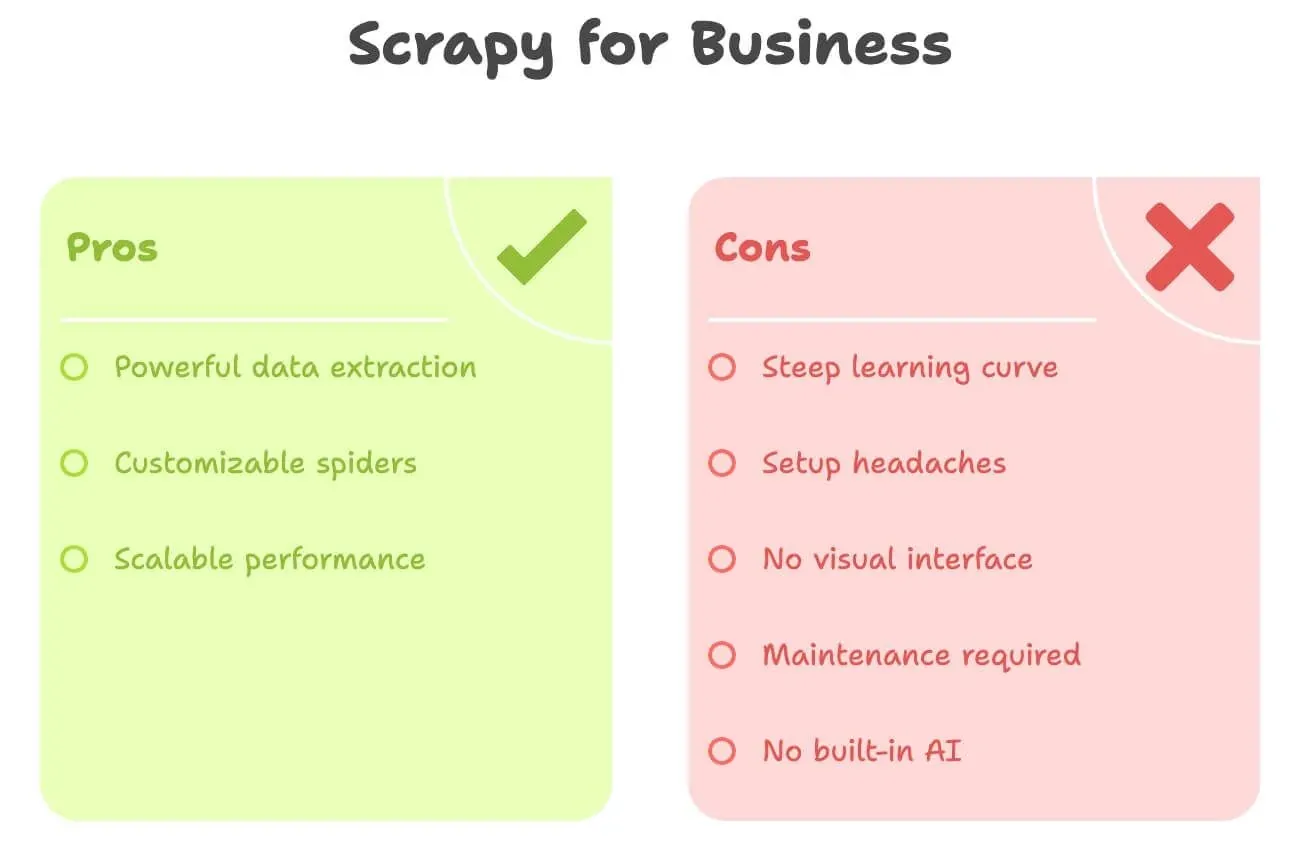
Seamos realistas: Scrapy es potente, pero no es precisamente amigable para quienes no desarrollan. Esto es lo que suele atascar a la mayoría de los usuarios de negocio:
- Curva de aprendizaje pronunciada: necesitas saber Python, HTML, selectores XPath/CSS y la estructura de proyectos de Scrapy. Puede llevar días o incluso semanas sentirse cómodo.
- Problemas de configuración: instalar Python, gestionar dependencias y resolver errores puede ser un dolor de cabeza, especialmente en Windows.
- Sin interfaz visual: todo es código. No puedes simplemente “hacer clic” en una página para seleccionar datos.
- Mantenimiento: si el sitio web cambia, tu spider se rompe. Te toca arreglarlo.
- Sin IA integrada: ¿quieres traducir, resumir o analizar sentimientos? Todo eso requiere código extra.
Aquí tienes una comparación rápida:
| Desafío | Scrapy (Python) | Necesidades del usuario de negocio |
|---|---|---|
| Requiere programación | Sí | Preferiblemente no code |
| Tiempo de configuración | Horas (o días) | Minutos |
| Mantenimiento | Continuo (cambios del sitio) | Mínimo |
| Exportación de datos | CSV/JSON (integración manual) | Directo a Excel/Sheets/Notion |
| Funciones de IA | Ninguna (integración casera) | Traducción/análisis de sentimiento integrados |
Si eres responsable de marketing, ventas u operaciones y trabajas solo, Scrapy puede sentirse como llevar una bazuca a una pelea de globos de agua.
Conoce Thunderbit: la alternativa sin código a Scrapy en Python
Aquí es donde entra Thunderbit. Como alguien que ha pasado años creando herramientas de automatización, te lo digo claro: la mayoría de los usuarios de negocio no quiere programar; solo quiere los datos, rápido.
Thunderbit es un Raspador Web IA entregado como extensión de Chrome. Está diseñado para usuarios no técnicos que quieren:
- Extraer datos de cualquier sitio web en unos pocos clics
- Usar lenguaje natural para describir lo que quieren (“nombre del producto, precio, valoración”)
- Manejar automáticamente la paginación y las subpáginas
- Exportar datos directamente a Excel, Google Sheets, Airtable o Notion
- Traducir, resumir o analizar sentimientos al vuelo
Sin Python. Sin selectores. Sin dolores de cabeza de mantenimiento.
Cómo extraer datos de cualquier sitio web usando IA Get Started Free
Thunderbit está pensado para usuarios de negocio que quieren moverse rápido y dejar que la IA haga el trabajo pesado.
Thunderbit vs. Scrapy en Python: comparación lado a lado
Vamos a ponerlos frente a frente:
| Aspecto | Scrapy (Python) | Thunderbit (herramienta de IA) |
|---|---|---|
| Conocimientos requeridos | Python, HTML, selectores | Ninguno: apuntar y hacer clic, lenguaje natural |
| Tiempo de configuración | Horas (instalar, programar, depurar) | Minutos (instalar la extensión de Chrome, iniciar sesión) |
| Estructuración de datos | Manual (definir items, pipelines) | La IA detecta columnas automáticamente y sugiere campos |
| Paginación/subpáginas | Requiere código | 1 clic (la IA se encarga) |
| Traducción | Código personalizado o integración con API | Integrada: solo activa “Traducir” |
| Análisis de sentimiento | Biblioteca/API externa | Integrado: añade una columna “Sentimiento” |
| Opciones de exportación | CSV/JSON (importación manual a Sheets/Excel) | Exportación con 1 clic a Excel, Google Sheets, Airtable, Notion |
| Mantenimiento | Manual (actualiza el código si cambia el sitio) | La IA se adapta automáticamente a pequeños cambios del sitio |
| Escala | Mejor para proyectos grandes y continuos | Mejor para tareas rápidas, escala moderada (cientos o miles de filas) |
| Coste | Gratis (pero consume tiempo y recursos de desarrollo) | Plan gratuito + planes de pago (desde 9 USD/mes, pero ahorra muchísimo tiempo y dolores de cabeza) |
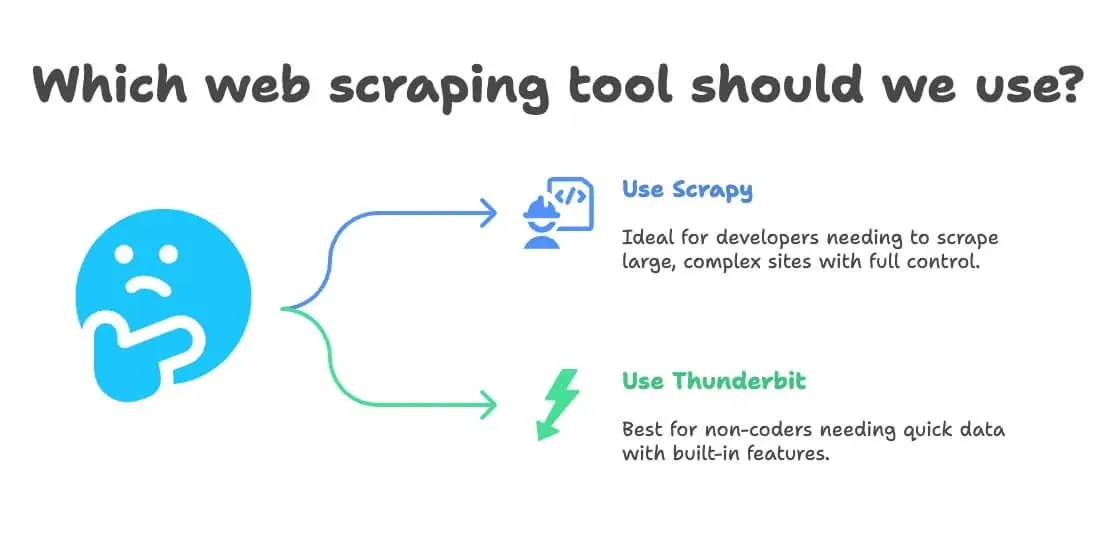
Cuándo elegir Scrapy en Python frente a Thunderbit para web scraping
Esta es mi regla general:
- Usa Scrapy si:
- Eres desarrollador o tienes uno en tu equipo
- Necesitas extraer decenas de miles de páginas o crear un pipeline personalizado y continuo
- El sitio es muy complejo o requiere lógica avanzada
- Quieres control total (y no te importa el mantenimiento)
- Usa Thunderbit si:
- No programas (o no quieres hacerlo)
- Necesitas datos rápido, para una tarea de negocio puntual o recurrente
- Quieres traducción, análisis de sentimiento o enriquecimiento de datos integrados
- Valoras la velocidad y la flexibilidad por encima de la personalización extrema
Aquí tienes un flujo rápido para decidir:
- ¿Sabes programar en Python?
- Sí → Scrapy o Thunderbit (para resultados rápidos)
- No → Thunderbit
- ¿Tu proyecto es enorme y continuo?
- Sí → Scrapy
- No → Thunderbit
- ¿Necesitas traducción o análisis de sentimiento?
- Sí → Thunderbit
- No → Cualquiera de los dos
Paso a paso: extraer datos de productos de Amazon con Thunderbit (sin código)
Repitamos nuestro ejemplo de Amazon, pero esta vez de la forma fácil.
1. Instala Thunderbit
- Descarga la extensión de Chrome de Thunderbit
- Regístrate (hay plan gratuito disponible)
Prueba gratis la extensión de Chrome de Thunderbit
2. Ve a Amazon y busca tu producto
- Abre Amazon.com y busca “laptops” (o cualquier producto)
3. Abre Thunderbit en la página
- Haz clic en el icono de Thunderbit en tu navegador
- Se abrirá el panel lateral y reconocerá la página de Amazon
4. Usa la sugerencia de campos con IA
- Haz clic en “Sugerir campos con IA”
- La IA de Thunderbit escaneará la página y propondrá columnas como “Nombre del producto”, “Precio”, “Valoración” y “Número de reseñas”
- Añade o elimina columnas según necesites (¿quieres “URL del producto” o “elegibilidad para Prime”? Solo escríbelo)
5. Activa la paginación y la extracción de subpáginas
- Activa Paginación: Thunderbit hará clic automáticamente en “Siguiente” y extraerá todas las páginas
- Activa Extracción de subpáginas: Thunderbit visitará la página de detalle de cada producto y capturará información adicional (como descripciones o números ASIN)
6. Ejecuta la extracción
- Haz clic en Extraer
- Mira cómo Thunderbit recopila datos en tiempo real, página por página
7. Traduce y analiza el sentimiento (opcional)
- ¿Quieres traducir descripciones de productos? Activa “Traducir” para esa columna
- ¿Quieres analizar el sentimiento de las reseñas? Añade una columna “Sentimiento”: la IA de Thunderbit la completará
8. Exporta tus datos
- Haz clic en Exportar
- Elige Excel, Google Sheets, Airtable o Notion
- Tus datos estarán listos para usar: sin importaciones manuales ni peleas con CSV
9. Programa extracciones recurrentes (opcional)
- Configura un calendario (por ejemplo, todos los días a las 8:00)
- Thunderbit ejecutará la extracción automáticamente y actualizará el destino que hayas elegido
Eso es todo. Sin código, sin selectores, sin mantenimiento. Solo datos, listos para el negocio.
Consejos extra: cómo sacar más partido a tus proyectos de web scraping
Tanto si usas Scrapy, Thunderbit o cualquier otra herramienta, estas son algunas buenas prácticas que he aprendido a las malas:
- Valida tus datos: comprueba siempre si hay valores faltantes o extraños (como precios de $0 o nombres vacíos)
- Cumple las normas: revisa los términos de servicio del sitio, respeta
robots.txty no sobrecargues los servidores - Automatiza con criterio: usa la programación para mantener los datos frescos, pero no extraigas más de lo necesario
- Aprovecha las herramientas gratis: Thunderbit incluye extractores gratuitos de email, teléfono e imágenes; son ideales para generación de leads o curación de contenido
- Organízate para analizar: exporta directamente a Sheets/Excel para filtrar, crear tablas dinámicas y visualizar rápido
Para más consejos, visita el blog de Thunderbit o su guía para extraer cualquier sitio web usando IA.
Cómo extraer datos de un sitio web a Excel usando IA Get Started Free
Para más consejos, visita el blog de Thunderbit o su guía para extraer cualquier sitio web usando IA.
Conclusión: el web scraping simplificado: elige la herramienta adecuada para tu equipo
En resumen: Scrapy es una bestia para desarrolladores, pero es demasiado para la mayoría de los usuarios de negocio. Si te sientes cómodo con Python y necesitas crear un raspador personalizado a gran escala, Scrapy es una gran opción. Pero si quieres ir rápido, evitar el código y obtener datos —con traducción y análisis de sentimiento integrados—, Thunderbit es el camino a seguir.
He visto de primera mano cuánto tiempo y frustración ahorra Thunderbit a los equipos no técnicos. Puedes pasar de “ojalá tuviera estos datos” a “ya están en mi hoja de cálculo” en minutos, no en horas o días. Y con funciones como Sugerir campos con IA, extracción de subpáginas y exportaciones con un clic, nunca ha sido tan fácil convertir la web en inteligencia de negocio.
Así que, la próxima vez que necesites extraer datos de productos, monitorizar precios o crear una lista de leads, pregúntate: ¿quieres escribir Python o quieres resultados? Prueba el plan gratuito de Thunderbit y descubre lo fácil que puede ser el web scraping.
¿Quieres saber más? Visita el sitio oficial de Thunderbit, descarga la extensión de Chrome o profundiza en las mejores prácticas de web scraping en el blog de Thunderbit.
Lecturas recomendadas:
- Qué es el data scraping y cómo hacerlo en 2026
- Cómo extraer datos de un sitio web a Excel usando IA
- Las mejores herramientas y software de web scraping en 2026
- Informe sobre el estado del web scraping
Aviso legal: asegúrate siempre de que tus actividades de web scraping cumplan con los términos del sitio web y las leyes locales. En caso de duda, consulta con un asesor legal: nadie quiere ser el “scraper” que reciba una carta de cese y desistimiento por una hoja de cálculo.
Escrito por Shuai Guan, cofundador y CEO de Thunderbit. He pasado años en SaaS, automatización e IA, para que tú no tengas que hacerlo.
Prueba AI Web Scraper Get Started Free




