es una extensión de Chrome de AI Web Scraper que ayuda a usuarios de negocio a extraer datos de sitios web con IA. La gran tensión está aquí: lo que en la página de precios de ScrapingBee parece económico puede cambiar por completo cuando empiezas a ejecutar cargas reales y ves cómo los créditos se consumen a una velocidad de 5× a 75× sobre la tarifa base. Esta reseña analiza cinco ángulos que la mayoría de artículos pasa por alto: el costo real a escala, la extracción basada en selectores frente a la impulsada por IA, la facilidad de uso para personas no técnicas, los flujos de trabajo después de extraer los datos y los benchmarks de fiabilidad de 2026. Si estás evaluando ScrapingBee para tu equipo —ya seas desarrollador, responsable de operaciones de ventas o fundador—, este es el desglose que necesitas.
¿Qué es ScrapingBee? Resumen rápido
ScrapingBee es una API de scraping web que se encarga de la rotación de proxies, el renderizado de JavaScript y la resolución de CAPTCHA para que los desarrolladores puedan extraer datos de sitios web sin montar su propia infraestructura de scraping. Envías una solicitud HTTP con parámetros y recibes HTML de vuelta (o JSON en ciertos endpoints). No ofrece una interfaz visual ni de clics para crear extracciones.
Entre sus funciones principales están:
- Proxies rotativos y premium (clásicos, premium, stealth, residenciales)
- Renderizado con navegador headless (Chrome completo, activado por defecto)
- Bypass automático de CAPTCHA
- Google Search API (JSON estructurado: resultados orgánicos, anuncios, mapas, knowledge graph, People Also Ask, imágenes, noticias)
- Captura de capturas de pantalla (estándar, página completa o dirigida por selector CSS)
- Segmentación geográfica mediante el parámetro
country_code - Reglas de extracción CSS/XPath (declarativas, basadas en JSON, devuelven JSON estructurado)
- APIs dedicadas para extraer datos de Amazon, Walmart, YouTube y ChatGPT
- Extracción con IA (añadida ~2024–2025): parámetros
ai_query,ai_extract_rules,ai_selector(+5 créditos por solicitud) - Herramienta CLI (lanzada ~2025–2026): procesamiento por lotes, crawling, análisis de sitemaps, enriquecimiento CSV, tareas cron programadas y escalado de proxies
Fundada en 2019 en Francia, ScrapingBee creció hasta alrededor de a inicios de 2026, con más de 2.500 clientes (SAP, Zapier, Deloitte, Zillow), todo ello autofinanciado y con un equipo de 4 a 6 personas. En junio de 2025, en una operación de ocho cifras. La marca y el liderazgo siguen siendo independientes, y el equipo de soporte para ofrecer una mejor cobertura horaria.
Un punto importante: ScrapingBee todavía no tiene un constructor visual nativo, una GUI de arrastrar y soltar ni un programador integrado en un panel web. La programación requiere la herramienta CLI, cron jobs o automatización de terceros (Zapier, Make, n8n). Las guías “no-code” que publican se refieren al uso de integraciones con Make y Zapier, no a una interfaz nativa sin código.
¿Para quién está realmente pensado ScrapingBee?
ScrapingBee está pensado para desarrolladores que se sientan cómodos escribiendo llamadas en Python o cURL, leyendo HTML y construyendo selectores CSS/XPath. La documentación está muy orientada al código, con ejemplos centrados en Python y cURL. Un reseñador en comentó que “no proporcionan ejemplos en JavaScript”, y otro describió la documentación como “voluminosa, toma de un día a una semana leerla por completo”.
Pero la audiencia que busca “reseña de ScrapingBee” en 2026 es más amplia que los ingenieros backend. Incluye a responsables de marketing que crean listas de leads, equipos de sales ops que enriquecen datos de CRM, operaciones de ecommerce que monitorean precios de la competencia y fundadores que evalúan herramientas para sus equipos. En cada sección a continuación indicaré si una función o limitación importa a desarrolladores, a usuarios de negocio o a ambos.
Planes de precios de ScrapingBee de un vistazo
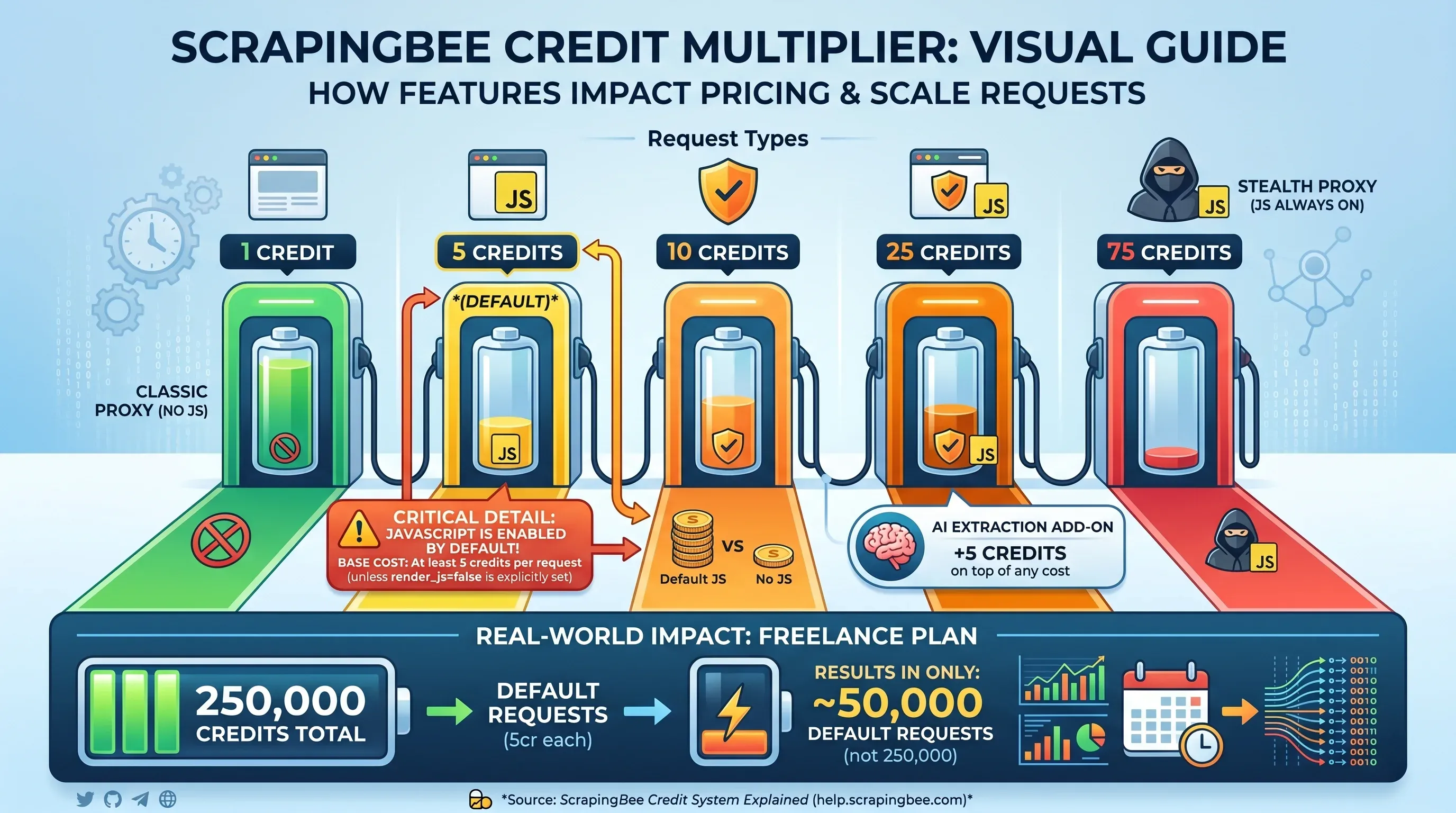
Estos son los niveles de plan actuales de ScrapingBee (a abril de 2026):
| Plan | Precio mensual | Créditos API/mes | Solicitudes simultáneas |
|---|---|---|---|
| Freelance | $49 | 250.000 | 10 |
| Startup | $99 | 1.000.000 | 50 |
| Business | $249 | 3.000.000 | 100 |
| Business+ | $599 | 8.000.000 | 200 |
| Enterprise | Contactar ventas | 41M+ | Personalizado |
La facturación anual ofrece un . La prueba gratuita incluye 1.000 créditos API sin necesidad de tarjeta de crédito. La Google Search API se por llamada tras la adquisición.
Esas cifras de créditos parecen generosas. Pero no son lo que aparentan.
La tabla del multiplicador de créditos
Aquí es donde los precios de ScrapingBee se complican. La cifra de créditos destacada no equivale al número de páginas que puedes extraer: depende de las funciones que actives en cada solicitud:
| Tipo de solicitud | Créditos por solicitud |
|---|---|
Proxy clásico, sin renderizado JS (render_js=false) | 1 crédito |
| Proxy clásico, renderizado JS (predeterminado) | 5 créditos |
| Proxy premium, sin renderizado JS | 10 créditos |
| Proxy premium, renderizado JS | 25 créditos |
| Proxy stealth (JS siempre activo) | 75 créditos |
| Complemento de extracción con IA | +5 créditos adicionales |
Detalle clave: el renderizado de JavaScript está . Si no configuras explícitamente render_js=false, cada solicitud cuesta al menos 5 créditos. Eso significa que los 250.000 créditos del plan Freelance cubren solo 50.000 solicitudes por defecto, no 250.000.
El cálculo oculto de créditos que nadie muestra
Esto es lo que realmente cuesta ScrapingBee para 10.000 páginas en distintos escenarios y niveles de plan:
| Escenario | Créditos necesarios | Freelance ($49/250K) | Startup ($99/1M) | Business ($249/3M) |
|---|---|---|---|---|
| 10K páginas (HTML estático, 1 cr) | 10.000 | ✅ Cubierto ($0.20/1K) | ✅ Cubierto ($0.10/1K) | ✅ Cubierto ($0.08/1K) |
| 10K páginas (renderizado JS, 5 cr) | 50.000 | ✅ Cubierto ($0.98/1K) | ✅ Cubierto ($0.50/1K) | ✅ Cubierto ($0.42/1K) |
| 10K páginas (proxy premium + JS, 25 cr) | 250.000 | ⚠️ Justo al límite ($4.90/1K) | ✅ Cubierto ($2.48/1K) | ✅ Cubierto ($2.08/1K) |
| 10K páginas (proxy stealth, 75 cr) | 750.000 | ❌ Muy por encima del límite | ✅ Apenas cubierto ($7.43/1K) | ✅ Cubierto ($6.23/1K) |
Las mismas 10.000 páginas pueden costar entre $0.20 y $7.43 por cada mil según la configuración del proxy y del renderizado. Y no siempre sabrás qué configuración necesitas hasta que la pruebes.
Escenario de presupuesto: generación de leads a 10.000 páginas/mes
Un equipo de ventas extrae 10.000 páginas de empresas al mes para generar leads. La mayoría de los sitios B2B modernos usan React o Vue, así que hace falta renderizado JS:
- Créditos necesarios: 50.000 (10K × 5 créditos)
- Plan Freelance ($49): lo cubre y aún sobran 200K créditos
- Pero si los objetivos requieren proxies premium: 250.000 créditos — exactamente la asignación de un plan Freelance, sin margen
- Si se necesitan proxies stealth: 750.000 créditos — requiere el plan Startup a $99/mes
Escenario de presupuesto: seguimiento de precios en ecommerce a 100.000 páginas/mes
Un equipo de ecommerce supervisa 100.000 páginas de productos en sitios de la competencia:
| Configuración | Créditos necesarios | Plan requerido | Costo mensual |
|---|---|---|---|
| HTML estático (1 cr) | 100.000 | Freelance | $49 |
| Renderizado JS (5 cr) | 500.000 | Startup | $99 |
| Proxy premium + JS (25 cr) | 2.500.000 | Business | $249 |
| Proxy stealth (75 cr) | 7.500.000 | Business+ | $599 |
El mismo trabajo va de $49 a $599 al mes. Eso no es un error de redondeo: es una diferencia de coste de 12× según la configuración.
“El precio de entrada de $49 es la cifra más engañosa del mercado de APIs de scraping.” —
“Los créditos se consumen rápido cuando se usa renderizado de JavaScript o funciones avanzadas, lo que dificulta justificarlo para proyectos pequeños o equipos con volúmenes de scraping impredecibles.” — Nick S, Manager, Computer Software,
Y los créditos no utilizados de un mes al siguiente.
Cómo se comparan los costos de ScrapingBee con los de la competencia

Usando planes de nivel medio para una comparación justa:
| Escenario (por 1K páginas) | ScrapingBee ($99/1M) | ScraperAPI ($149/1M) | Scrapfly ($100/1M) |
|---|---|---|---|
| HTML estático | $0.10 | $0.15 | $0.10 |
| Páginas renderizadas con JS | $0.50 | $1.64 | $0.60 |
| Premium + JS | $2.48 | $3.73 | $3.00 |
| Stealth/ultra premium + JS | $7.43 | $11.18 | N/A |
En general, ScrapingBee es el más barato o está empatado como el más barato en páginas estáticas y renderizadas con JS. es de forma consistente el más caro: su renderizado JS cuesta +10 créditos frente a +5 en ScrapingBee y Scrapfly. Pero las pruebas independientes de cuentan otra historia cuando se tiene en cuenta la complejidad real de los sitios:
| Servicio | Costo medio por 1K solicitudes | Tasa de éxito | Tiempo medio de respuesta |
|---|---|---|---|
| Scrape.do | $0.80 | 98.19% | 4.7s |
| ScrapingBee | $3.90 | 92.69% | 11.7s |
| Scrapfly | $4.11 | — | — |
| ZenRows | $4.48 | 92.64% | 10.0s |
| ScraperAPI | $8.49 | 92.70% | 15.7s |
El modelo de créditos de Thunderbit: un enfoque distinto
usa un modelo de precios mucho más simple: 1 crédito = 1 fila de salida, sin multiplicadores por renderizado JS, tipo de proxy o dominio de destino. El scraping de subpáginas cuesta 2 créditos por fila.
| Plan | Precio mensual | Créditos | Costo por fila |
|---|---|---|---|
| Free | $0 | 6 páginas/mes | Gratis |
| Starter | $15 | 500 | $0.030 |
| Pro 1 | $38 | 3.000 | $0.013 |
| Pro 2 | $75 | 6.000 | $0.013 |
| Pro 3 | $125 | 10.000 | $0.013 |
| Pro 4 | $249 | 20.000 | $0.012 |
Un usuario de Thunderbit que extrae 10.000 listados de productos de sitios ecommerce muy cargados de JS paga $125/mes, sin importar si esos sitios requieren renderizado JavaScript, proxies premium o bypass antibots. Con ScrapingBee, el mismo trabajo puede costar entre $49 y $599 según la configuración. La previsibilidad presupuestaria sí importa.
Selectores CSS frente a extracción con IA: el costo de mantenimiento que deberías conocer
La mayoría de las reseñas de ScrapingBee omiten esto por completo. Y, probablemente, es la consideración más importante para cualquiera que planee extraer datos a escala durante meses o años.
ScrapingBee usa selectores CSS/XPath para extraer datos de HTML. Defines las reglas de extracción como objetos JSON con selectores CSS, y ScrapingBee devuelve los datos coincidentes. Al principio funciona bien. El problema es lo que viene después.
El problema de rotura de selectores
Cuando un sitio objetivo cambia su diseño —nombres de clases, estructura del DOM, versión del framework— tus selectores CSS se rompen. En sistemas de scraping maduros que operan sobre más de 2.500 trabajos activos, la investigación muestra una , lo que exige 30–35 correcciones por semana solo para mantener los extractores funcionando. Para organizaciones que extraen datos de 50 sitios, el mantenimiento anual alcanza entre 850 y 1.300 horas, con un costo de $64.000–$156.000 según tarifas cargadas completas de ingeniería.
Los equipos suelen subestimar esto. Las estimaciones iniciales suelen hablar de 10–15 horas de mantenimiento al mes, pero la realidad suele ser (40–90 horas/mes). Un solo fallo silencioso —cuando un selector se rompe pero sigue devolviendo datos vacíos sin alertar a nadie— puede costar entre $38.000 y $57.000 en ventas perdidas, recuperación de ranking y tiempo del personal.
Causas comunes: renombrado de clases CSS durante actualizaciones de framework, inserción de nuevos contenedores alrededor de los objetivos, actualizaciones de versiones de React/Vue/Angular que reestructuran el DOM, pruebas A/B con nombres de clase dinámicos y ofuscación anti-scraping.
La extracción con IA reduce el mantenimiento entre un 60% y un 80%
Un estudio de DataRobot de 2025 encontró que los scrapers impulsados por IA requieren que los scrapers tradicionales basados en selectores después de rediseños de sitios. La proporción de tiempo cambia por completo:
| Métrica | Tradicional (selectores CSS) | Impulsado por IA |
|---|---|---|
| Mantenimiento tras rediseños | Línea base | 70% menos |
| Reparto de tiempo (configuración : mantenimiento) | 20% : 80% | 5% : 95% usando datos |
| Reducción total de mantenimiento | Línea base | 60–80% menos |
| Velocidad en páginas con mucho JS | Línea base | 30–40% más rápido |
Tiempo de configuración: escribir selectores vs. campos sugeridos por IA
Configuración en ScrapingBee: inspeccionar el código fuente de la página → identificar selectores CSS → escribir reglas de extracción como JSON → probar y depurar → manejar casos extremos de variaciones de página → monitorizar roturas → corregir selectores cuando los sitios se actualizan.
Configuración en Thunderbit: abrir la página en Chrome → hacer clic en “AI Suggest Fields” → la IA lee la página y propone columnas con tipos de datos adecuados → hacer clic en “Scrape”. Sin escribir selectores, sin inspeccionar el código fuente. La IA de Thunderbit está impulsada por varios modelos fundacionales (ChatGPT, Gemini, Claude, DeepSeek R1) que leen visualmente las páginas web como lo haría una persona.
Los de Thunderbit añaden otra capa: cada columna puede tener una instrucción personalizada de IA que transforma los datos durante la extracción —formatear fechas, traducir texto, categorizar productos, separar nombres, normalizar números de teléfono—. Esto elimina un paso de posprocesamiento separado que los usuarios de ScrapingBee tienen que construir por su cuenta.
Salida estructurada: HTML en bruto frente a filas listas para usar
| Dimensión | ScrapingBee (basado en selectores) | Thunderbit (impulsado por IA) |
|---|---|---|
| Salida predeterminada | HTML en bruto | Filas estructuradas con columnas tipadas |
| Extracción estructurada | Requiere reglas CSS/XPath o usar IA (+5 créditos) | IA detecta los campos automáticamente |
| Tipos de datos compatibles | Texto (se requiere parseo HTML) | Texto, número, fecha, URL, email, teléfono, imagen |
| Resistencia a cambios de diseño | ⚠️ Se necesitan actualizaciones manuales de selectores | ✅ La IA vuelve a leer la página desde cero cada vez |
| Habilidad técnica requerida | Python/cURL, selectores CSS, comprensión de HTML | Ninguna — extensión de Chrome con flujo de 2 clics |
| Mantenimiento a lo largo del tiempo | Continuo (tasa de rotura semanal del 1–2%) | Mínimo (la IA se adapta automáticamente) |
ScrapingBee ha añadido funciones de extracción con IA (ai_query, ai_extract_rules) que abordan parcialmente el problema de mantenimiento de selectores. Pero estas añaden +5 créditos por solicitud sobre el costo base, y la herramienta sigue siendo fundamentalmente API-first, sin interfaz visual.
ScrapingBee para no desarrolladores: una evaluación honesta de usabilidad
ScrapingBee no está pensado para usuarios no técnicos. Es una API. Tienes que escribir código para usarla. Si eres un responsable de marketing o de operaciones de ventas leyendo esto, esa es la historia completa.
Esto es lo que realmente experimenta un usuario no técnico con ScrapingBee:
- Escribir una llamada a la API en Python, cURL u otro lenguaje
- Entender parámetros HTTP como
render_js=true,premium_proxy=true,country_code=us - Analizar respuestas HTML en bruto con una biblioteca como BeautifulSoup
- Escribir selectores CSS para extraer campos de datos específicos
- Gestionar la paginación escribiendo lógica de rastreo personalizada (ScrapingBee solo maneja solicitudes de una sola página)
- Construir una canalización de datos para limpiar, estructurar y almacenar la información extraída
No hay constructor drag-and-drop. No hay interfaz de apuntar y hacer clic. No hay vista previa visual de lo que estás extrayendo.
“Hay una curva de aprendizaje. Y la documentación es voluminosa, toma de un día a una semana leerla por completo.” — Arvind K, Proprietor, Financial Services,
“Su sistema es muy particular y lleva tiempo aprender sus códigos y su estructura.” —
A los desarrolladores les encanta. Un reseñador lo describió como “totalmente basado en API: muy moderno y elegante: simplemente funciona”. Pero la “facilidad de uso” para un desarrollador que evalúa APIs es muy distinta de la “facilidad de uso” para alguien que intenta crear una lista de leads sin escribir código.
Cuándo tiene más sentido una alternativa sin código
La ofrece una experiencia radicalmente distinta:
- Abre una página web en Chrome con la extensión instalada
- Haz clic en “AI Suggest Fields” — la IA analiza la página y propone columnas (Product Name, Price, Rating, URL, etc.) con tipos de datos adecuados
- Revisa y personaliza — añade, elimina o renombra columnas; agrega Field AI Prompts para transformar datos
- Haz clic en “Scrape” — los datos se extraen en filas estructuradas
- Exporta — un clic a Google Sheets, Airtable, Notion, Excel, CSV o JSON (todas las exportaciones son gratuitas)
Sin llamadas a la API, sin selectores, sin código. Thunderbit admite a abril de 2026.
Para sitios comunes, Thunderbit también ofrece — plantillas preconstruidas y mantenidas para Amazon, Zillow, Shopify, LinkedIn, Google Maps, Instagram, eBay, Apollo y más. Ni siquiera tienes que esperar a que la IA sugiera los campos; la plantilla ya está lista.
Además, Thunderbit incluye varias que no requieren plan: extractor de emails, extractor de números de teléfono y extractor de imágenes — muy útiles para equipos de ventas y marketing que solo necesitan obtener datos rápido.
Marco de decisión: quién debería usar qué
| Si eres… | Mejor opción |
|---|---|
| Desarrollador cómodo con APIs y parseo de HTML | ScrapingBee o ScraperAPI |
| Usuario técnico que quiere datos estructurados sin trabajar con selectores | Thunderbit API (endpoint Extract) |
| Usuario de negocio (ventas, marketing, operaciones de ecommerce) sin conocimientos de código | Thunderbit Chrome Extension |
| Equipo que necesita monitorización programada sin DevOps | Thunderbit Scheduled Scraper (programación en lenguaje natural) |
| Construyes pipelines LLM/RAG y necesitas Markdown limpio | Thunderbit Distill API o Firecrawl |
| Priorizas presupuesto predecible y no quieres multiplicadores de créditos | Thunderbit (1 crédito = 1 fila) |
Después de la extracción: ¿a dónde van realmente tus datos?
Extraer datos es solo la mitad del trabajo. La otra mitad —hacer que esos datos lleguen a un lugar útil— es donde la mayoría de las reseñas de ScrapingBee se quedan en silencio.
ScrapingBee: salida en HTML en bruto, construye tu propia canalización
ScrapingBee devuelve HTML en bruto por defecto. A partir de ahí, tienes que:
- Analizar el HTML con BeautifulSoup o lxml
- Eliminar navegación, pies de página, scripts y estilos (que componen )
- Extraer campos de datos concretos
- Convertirlos a formatos estructurados
- Gestionar paginación y estados de error
- Almacenar y distribuir los datos
“ScrapingBee devuelve HTML en bruto. Los agentes de IA necesitan Markdown limpio, búsqueda semántica y webhooks.” —
ScrapingBee sí ofrece return_page_markdown=true y return_page_text=true como alternativas opcionales, y la Google Search API devuelve JSON estructurado. Pero el flujo predeterminado —y la experiencia general de scraping— sigue siendo HTML en bruto que tienes que procesar tú mismo.
Normalmente los usuarios necesitan herramientas adicionales: BeautifulSoup/lxml para el parseo, Pandas para la limpieza de datos, cron/Airflow para la programación, lógica de rastreo personalizada para scraping multipágina y . Es mucha ingeniería entre “ya lo extraje” y “ya puedo usarlo”.
Thunderbit: salida estructurada con exportación integrada
Thunderbit devuelve filas estructuradas con tipos de datos definidos (texto, número, fecha, URL, email, teléfono, imagen) listas para exportar. Todas las exportaciones son gratuitas en todos los niveles de plan:
| Destino de exportación | Costo |
|---|---|
| Excel (.xlsx) | Gratis |
| Google Sheets | Gratis (integración directa) |
| Airtable | Gratis (integración directa) |
| Notion | Gratis (integración directa) |
| CSV | Gratis |
| JSON | Gratis |
Para equipos que ya usan Google Sheets o Airtable como su CRM o centro operativo, esto elimina toda una capa de ingeniería. Al exportar a Notion o Airtable, las imágenes se suben a la biblioteca de imágenes para que los usuarios puedan verlas insertadas en línea —un detalle pequeño, pero muy importante en la práctica.
El ecosistema de integraciones de ScrapingBee
ScrapingBee sí ofrece integraciones de terceros: (más de 8.000 conexiones de apps), (más de 3.000 apps), n8n y Microsoft Power Automate. Estas pueden servir de puente entre el HTML en bruto y tus herramientas de destino, pero añaden costo, complejidad y otro punto de fallo.
Para desarrolladores: la API abierta de Thunderbit
Para quienes sí quieren pipelines programáticos, Thunderbit ofrece una Open API con dos endpoints clave:
- Endpoint Distill — convierte páginas en Markdown limpio, ideal para pipelines LLM/RAG (1 crédito por llamada)
- Endpoint Extract — devuelve JSON estructurado que coincide con un esquema definido por el usuario (20 créditos por llamada)
- Procesamiento por lotes — hasta 100 URLs por solicitud
Eso significa que Thunderbit atiende tanto a usuarios sin código (extensión de Chrome) como a desarrolladores (Open API) desde el mismo motor de IA. No preguntes solo “¿puede extraer datos?”; pregunta “¿a dónde van los datos?”.
Revisión de fiabilidad 2026: ¿ScrapingBee aguanta en producción?
Hilos antiguos de Reddit (2021–2023) contienen quejas sobre la fiabilidad de ScrapingBee. ¿Siguen reflejando la realidad en 2026? Recopilé datos de seis benchmarks independientes. Los resultados son mixtos —y a veces contradictorios.
Benchmark quincenal de Scrapeway (abril de 2026)
Total: — puesto 7 de 9 servicios evaluados.
| Sitio web | Tasa de éxito |
|---|---|
| Amazon | 48% |
| 41% | |
| Indeed | 38% |
| Etsy | 21% |
| Booking | 17% |
| Realtor | 0% |
| StockX | 0% |
| Twitter/X | 0% |
| Zillow | 0% |
| Walmart | 0% |
| 0% |
Prueba cara a cara de Scrapingdog (2025)
| Sitio web | ScrapingBee | Scrapingdog | ScraperAPI |
|---|---|---|---|
| Amazon | 100% | 100% | 100% |
| Glassdoor | 0% | 100% | 100% |
| eBay | 100% | 100% | 100% |
| Walmart | 40% | 100% | 100% |
| 90% | 100% | 80% |
Benchmark de Proxyway (diciembre de 2025)
- 72,98% de éxito con 10 solicitudes/segundo — una caída de 12 puntos bajo carga
- 25,46 s de tiempo medio de respuesta — el más lento del grupo evaluado
Benchmark de Scrape.do (2025–2026)
- Muy fuerte en sitios individuales: Amazon 99,11%, Indeed 99,29%, GitHub 100%, X/Twitter 99,6%
- Débil en Capterra: solo 59% de éxito con tiempos de respuesta de 36 segundos
El patrón
Los datos revelan un patrón claro:
- ScrapingBee funciona bien en sitios convencionales con protección moderada — Amazon, eBay, GitHub e Indeed muestran de forma consistente tasas de éxito del 90–100%
- ScrapingBee falla por completo en sitios muy protegidos — 0% consistente en LinkedIn, Zillow, Realtor.com, StockX y Twitter en múltiples benchmarks
- El rendimiento se degrada notablemente bajo carga — del 84% a 2 req/s cae al 73% a 10 req/s
- Los resultados de los benchmarks varían muchísimo según la metodología — desde 33,3% (Scrapeway, mezcla amplia de sitios) hasta 92,69% (Scrape.do, objetivos moderados)
La de ScrapingBee (137 reseñas) es una señal positiva, pero las puntuaciones altas por facilidad de configuración inicial no siempre reflejan la fiabilidad a largo plazo en producción y a escala. Los usuarios que migran a otras herramientas suelen citar tasas crecientes de fallo y costos en aumento, no la dificultad de configuración inicial.
“Muy positivo. ScrapingBee ha sido estable, predecible y fácil de integrar en producción.” — Reseñador verificado, CEO,
ScrapingBee mostró una “fiabilidad inconsistente”, logrando específicamente una “tasa de éxito del 0% en Glassdoor” y “”.
Cómo el scraping impulsado por IA maneja la fiabilidad de forma distinta
La IA de Thunderbit lee la página renderizada en tiempo real y se adapta a las medidas antibot y a los cambios de diseño en cada sesión. Dos modos de scraping cubren distintos retos de fiabilidad:
- Cloud scraping — se ejecuta en los servidores en la nube de Thunderbit, gestiona hasta 50 páginas a la vez y es ideal para trabajos grandes de scraping público en sitios como Amazon, Zillow y Shopify
- Browser scraping — se ejecuta localmente en el navegador Chrome del usuario, usando su propia sesión autenticada; es ideal para sitios con inicio de sesión (LinkedIn, paneles privados, plataformas SaaS) donde las herramientas basadas en API como ScrapingBee no pueden acceder al contenido protegido por autenticación
Thunderbit también ofrece para sitios populares, preconstruidas y mantenidas, que siguen funcionando incluso cuando los sitios cambian de estructura. Para los sitios en los que ScrapingBee muestra 0% de éxito (LinkedIn, Zillow), el modo Browser scraping de Thunderbit —usando tu propia sesión iniciada— es un enfoque radicalmente distinto.
ScrapingBee frente a las principales alternativas: comparación lado a lado
| Dimensión | ScrapingBee | Thunderbit | ScraperAPI | Scrapfly |
|---|---|---|---|---|
| Tipo | Solo API | Extensión de Chrome + API | Solo API | Solo API |
| Precio inicial | $49/mes | Gratis ($0) | $49/mes | $30/mes |
| Modelo de créditos | Multiplicadores (1×–75×) | 1 crédito = 1 fila (sin multiplicadores) | Multiplicadores (1×–75×) | Multiplicadores (1×–30×) |
| Extracción con IA | Sí (+5 créditos/solicitud) | Integrada (AI Suggest Fields) | No IA nativa | Sí |
| Opción sin código | No (solo API) | Sí (extensión de Chrome) | No (solo API) | No (solo API) |
| Salida estructurada | Requiere reglas CSS o complemento de IA | Predeterminada (columnas tipadas) | Endpoints estructurados para sitios específicos | Variable |
| Destinos de exportación | HTML/JSON en bruto (lo construyes tú) | Excel, Sheets, Airtable, Notion, CSV, JSON (todo gratis) | HTML/JSON en bruto | HTML/JSON en bruto |
| Scraping de subpáginas | Manual (escribir lógica de rastreo) | Integrado (2 créditos/fila) | Manual | Manual |
| Scraping programado | Solo CLI (sin programador en dashboard) | Integrado (lenguaje natural) | No integrado | No integrado |
| Plan gratuito | Prueba de 1.000 créditos | 6 páginas/mes (de por vida) | 5.000 créditos (prueba de 7 días) | 1.000 créditos |
| Renderizado JS por defecto | ACTIVADO (coste 5×) | Incluido (sin coste extra) | DESACTIVADO | DESACTIVADO |
| Curva de aprendizaje | Alta (API + selectores) | Baja (flujo de 2 clics) | Alta (API + selectores) | Alta (API) |
| Mejor para | Desarrolladores que quieren control de proxies | Usuarios de negocio + desarrolladores | Desarrolladores + endpoints estructurados | Desarrolladores que quieren bypass de ASP |
| Valoración en Capterra | 4.9/5 (137 reseñas) | — | 4.6/5 (62 reseñas) | 4.9/5 (221 reseñas) |
ScrapingBee frente a Thunderbit: diferencias clave
Las diferencias más importantes se reducen a arquitectura y público objetivo:
- Solo API vs. Extensión de Chrome + API: ScrapingBee requiere código para cualquier interacción. Thunderbit ofrece una para usuarios sin código y una Open API para desarrolladores: el mismo motor de IA, dos interfaces.
- Basado en selectores vs. extracción impulsada por IA: ScrapingBee exige escribir y mantener selectores CSS/XPath. La IA de Thunderbit sugiere campos automáticamente y se adapta cuando los sitios cambian.
- Salida HTML en bruto vs. filas estructuradas con exportación gratuita: ScrapingBee devuelve HTML que tienes que analizar. Thunderbit devuelve filas tipadas y etiquetadas que puedes con un solo clic.
- Scraping de subpáginas: la IA de Thunderbit visita cada página de detalle y enriquece la tabla principal —viene integrado, sin lógica de rastreo personalizada. ScrapingBee requiere que escribas esa lógica por tu cuenta.
- Plantillas instantáneas: Thunderbit tiene plantillas preconstruidas para sitios populares (Amazon, Zillow, Shopify, LinkedIn, Google Maps, eBay) que funcionan desde el primer momento. ScrapingBee tiene APIs dedicadas para Amazon y Walmart, pero aun así debes escribir código para usarlas.
Otras alternativas destacadas
- — el menor costo independiente, con $0.80 por 1K solicitudes y una tasa de éxito del 98,19%; desde $29/mes
- Apify — plataforma basada en actores con más de 415 reseñas en G2 (4,7/5), pero “Pricing Issues” es la queja número 1
- — nativo para IA/LLM, devuelve Markdown con 67% menos tokens que HTML en bruto; núcleo open source; desde $16/mes
- — de nivel enterprise con más de 72M IPs, desde $499/mes; precios de tarifa fija
- ZenRows — 55M IPs residenciales, scrapers preconstruidos para Amazon/Walmart/Zillow, desde $69/mes
¿Qué herramienta de scraping es la adecuada para tu equipo?
Recomendaciones según el caso:
- Si eres desarrollador y construyes una canalización de scraping personalizada con control granular de proxies → ScrapingBee o ScraperAPI. Obtendrás parámetros HTTP detallados, selección del tipo de proxy y control total sobre el renderizado. Solo ten en cuenta los multiplicadores de créditos.
- Si eres un equipo de ventas o marketing que necesita leads de sitios web sin escribir código → . Dos clics para obtener datos estructurados, un clic para Google Sheets. Sin API, sin selectores, sin parseo.
- Si necesitas datos estructurados de sitios populares rápidamente → Thunderbit Instant Templates. Amazon, Zillow, Shopify, LinkedIn: preconstruidos y mantenidos, sin necesidad de configurar IA.
- Si necesitas monitorizar precios o inventario en un horario sin DevOps → Thunderbit Scheduled Scraper. Describe el intervalo en lenguaje natural (“cada lunes a las 9 AM”) y deja que se ejecute.
- Si estás construyendo pipelines LLM/RAG y necesitas Markdown limpio a escala → Thunderbit Distill API o Firecrawl. Ambos devuelven Markdown optimizado para consumo de IA.
- Si te importa la previsibilidad del presupuesto y no quieres multiplicadores de créditos → Thunderbit. 1 crédito = 1 fila, independientemente del renderizado JS o del tipo de proxy.
El costo total de propiedad no es solo el precio de la API. Es tiempo de configuración + horas de mantenimiento + ingeniería de parseo + flujo de exportación de datos. El precio visible de ScrapingBee es competitivo; el costo real completo, no tanto.
Conclusiones clave de esta reseña de ScrapingBee
Cinco aprendizajes que vale la pena recordar:
- Los costos de créditos se multiplican rápido a escala. El precio de entrada de $49 puede convertirse en $599+ cuando se necesitan renderizado JS y proxies premium. El modelo de Thunderbit de 1 crédito por fila elimina esta incertidumbre.
- Los selectores CSS implican un mantenimiento continuo que la extracción con IA evita. Espera con herramientas impulsadas por IA, y cero roturas de selectores cuando los sitios se actualizan.
- Los no desarrolladores se enfrentan a una curva de aprendizaje pronunciada con ScrapingBee. Es una herramienta solo API que requiere código, inspección de HTML y construcción de selectores. Los usuarios de negocio deberían considerar alternativas sin código.
- La exportación de datos requiere ingeniería personalizada. ScrapingBee devuelve HTML en bruto; tú construyes la canalización. Thunderbit exporta datos estructurados a gratis.
- La fiabilidad es sólida para algunos sitios, pero inconsistente para otros. ScrapingBee funciona bien en Amazon y eBay, pero muestra 0% en LinkedIn, Zillow y varios otros objetivos muy protegidos.
ScrapingBee sigue siendo una herramienta competente para desarrolladores que quieren acceso HTTP gestionado por proxies con control detallado. Pero el panorama del scraping web en 2026 se ha movido hacia herramientas impulsadas por IA y sin código —y está diseñado justo para ese cambio. Prueba el plan gratuito (6 páginas gratis, o más con la prueba) para ver la diferencia por ti mismo.
Preguntas frecuentes
¿Vale la pena ScrapingBee en 2026?
Depende de tus habilidades técnicas y de la escala. Para desarrolladores que extraen páginas estáticas con un volumen moderado, ScrapingBee ofrece una API sólida, bien documentada, con soporte ágil y una . Para usuarios de negocio, scraping de gran volumen o equipos que quieren datos estructurados sin programar, alternativas impulsadas por IA como Thunderbit ofrecen mejor valor y un costo total de propiedad mucho menor.
¿ScrapingBee funciona sin programar?
No. ScrapingBee es una herramienta solo API que requiere escribir código (Python, cURL o similar) y entender parámetros HTTP. No hay una interfaz visual para crear extracciones. Los usuarios no técnicos deberían considerar opciones sin código como la , que te permite extraer y exportar datos sin escribir una sola línea de código.
¿Cuánto cuesta realmente ScrapingBee por página?
Depende de las funciones activadas. Una página HTML estática cuesta 1 crédito. Una página renderizada con JS (la opción predeterminada) cuesta . Una página con proxy premium + JS cuesta 25 créditos. Una página con proxy stealth cuesta 75 créditos. La extracción con IA añade +5 créditos adicionales. En el plan Freelance ($49/250K créditos), eso equivale a $0.20 por cada 1.000 páginas estáticas o $14.70 por cada 1.000 páginas con proxy stealth. Consulta las tablas de costos detalladas arriba para el desglose completo.
¿Cuáles son las mejores alternativas a ScrapingBee en 2026?
Las principales alternativas incluyen (impulsado por IA, extensión de Chrome sin código + API, 1 crédito = 1 fila), (API para desarrolladores con endpoints estructurados para sitios específicos), (API para desarrolladores con fuerte bypass antibots), (el menor costo por solicitud en pruebas independientes) y (nativo para IA/LLM, devuelve Markdown limpio). Cada una tiene su punto fuerte: Thunderbit para usuarios de negocio y previsibilidad de presupuesto, ScraperAPI y Scrapfly para control de proxies por parte de desarrolladores, y Firecrawl para pipelines LLM.
¿Puede ScrapingBee extraer sitios web con mucho JavaScript?
Sí, pero cuesta 5× los créditos base con un proxy rotativo o 25× con un proxy premium. El renderizado de JavaScript está , así que ya estás pagando la tarifa de 5× salvo que lo desactives explícitamente. Thunderbit maneja el renderizado JS automáticamente sin multiplicadores de créditos: 1 crédito por fila, independientemente de cómo esté construida la página.
Más información