

La web ya no es lo que era. Hoy en día, casi todos los sitios que visitas están impulsados por JavaScript y cargan contenido sobre la marcha: piensa en scroll infinito, ventanas emergentes y paneles que solo muestran sus secretos después de uno o dos clics. De hecho, un asombroso 98,7 % de todos los sitios web usa JavaScript, lo que significa que las herramientas de scraping de siempre, que solo leen HTML estático, se están perdiendo una gran cantidad de datos valiosos. Si alguna vez has intentado extraer precios de productos de un sitio moderno de comercio electrónico o recopilar anuncios inmobiliarios desde un mapa interactivo, conoces la frustración: los datos que quieres simplemente no están en el código fuente.
Ahí es donde entra en juego el scraping con Selenium. Como alguien que ha pasado años creando herramientas de automatización —y, sí, extrayendo más sitios web de los que me corresponde— puedo decirte que dominar Selenium es casi un superpoder para cualquiera que necesite datos dinámicos y actualizados. En este tutorial práctico de web scraping con Selenium, te guiaré por los pasos clave, desde la configuración hasta la automatización, y te mostraré cómo combinar Selenium con Thunderbit para obtener datos estructurados y listos para exportar. Tanto si eres analista de negocio, profesional de ventas o simplemente un usuario curioso de Python, te llevarás habilidades prácticas y alguna que otra risa (porque, seamos sinceros, depurar selectores XPath también forja el carácter).
Prueba el Raspador Web IA de Thunderbit
¿Qué es Selenium y por qué usarlo para hacer web scraping?
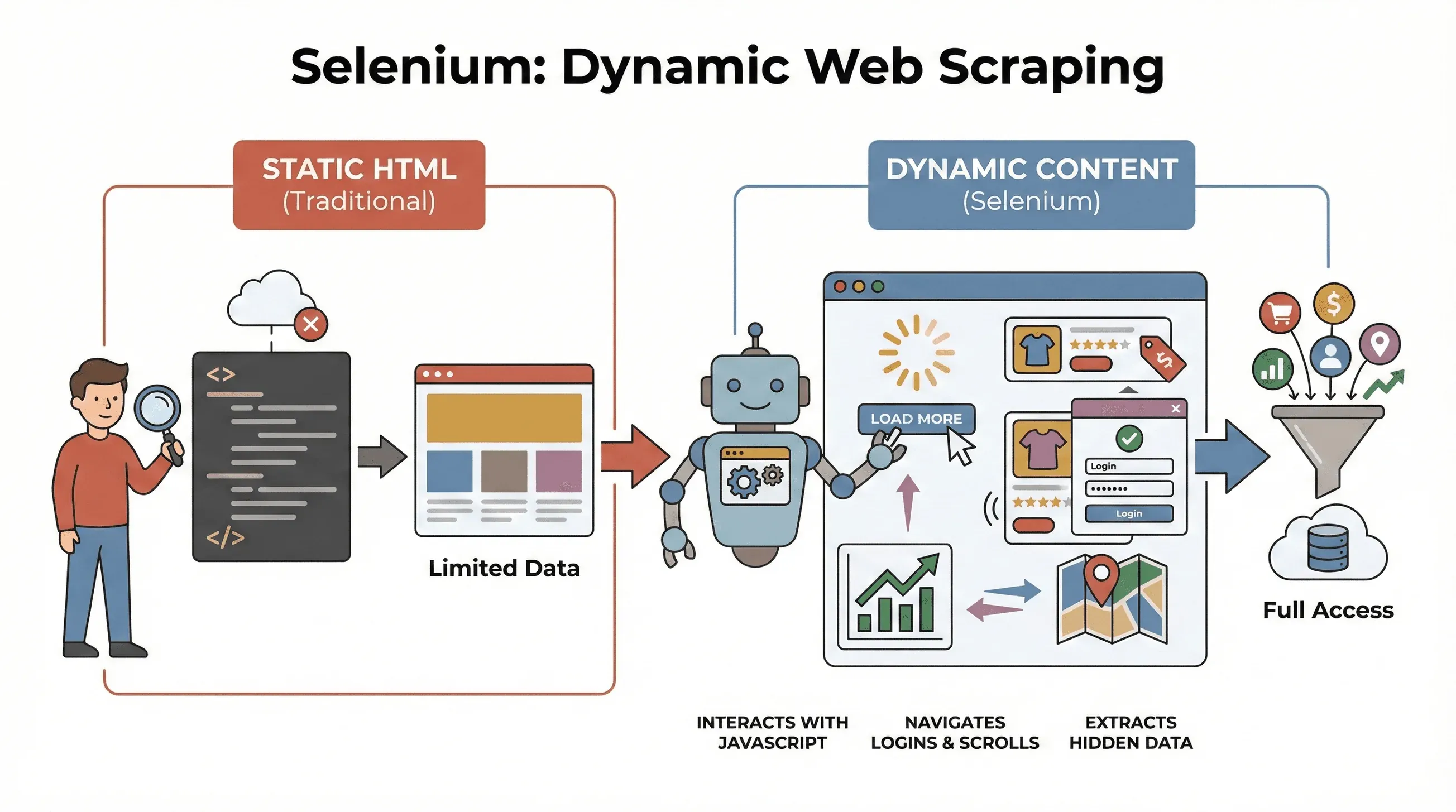 Empecemos por lo básico. Selenium es un framework de código abierto que te permite controlar un navegador web real —como Chrome o Firefox— mediante código. Piensa en él como un robot capaz de abrir páginas, hacer clic en botones, rellenar formularios, desplazarse por la página e incluso ejecutar JavaScript, igual que una persona. Esto es muy importante porque la mayoría de los sitios modernos no muestran todos sus datos de entrada. En su lugar, cargan contenido de forma dinámica, a menudo después de que interactúas con la página.
Empecemos por lo básico. Selenium es un framework de código abierto que te permite controlar un navegador web real —como Chrome o Firefox— mediante código. Piensa en él como un robot capaz de abrir páginas, hacer clic en botones, rellenar formularios, desplazarse por la página e incluso ejecutar JavaScript, igual que una persona. Esto es muy importante porque la mayoría de los sitios modernos no muestran todos sus datos de entrada. En su lugar, cargan contenido de forma dinámica, a menudo después de que interactúas con la página.
Qué es el data scraping y cómo hacerlo en 2026 Get Started Free
¿Por qué importa esto para el scraping? Herramientas tradicionales como BeautifulSoup o Scrapy son geniales para HTML estático, pero no pueden “ver” nada que se cargue con JavaScript después de la carga inicial de la página. Selenium, en cambio, puede interactuar con la página en tiempo real, lo que lo hace perfecto para:
- Extraer listas de productos que solo aparecen después de hacer clic en “Cargar más”
- Obtener precios o reseñas que se actualizan dinámicamente
- Navegar por formularios de inicio de sesión, ventanas emergentes o scroll infinito
- Extraer datos de paneles, mapas u otros elementos interactivos
En resumen, Selenium es tu herramienta de referencia cuando necesitas extraer datos que solo aparecen después de que la página termina de cargar, o tras una acción del usuario.
Pasos clave para hacer web scraping con Selenium en Python
El scraping con Selenium se resume en tres pasos esenciales:
| Paso | Qué haces | Por qué importa |
|---|---|---|
| 1. Configuración del entorno | Instalas Selenium, WebDriver y bibliotecas de Python | Dejas listas tus herramientas y evitas dolores de cabeza en la instalación |
| 2. Localización de elementos | Encuentras los datos que quieres con IDs, clases, XPath, etc. | Apuntas a la información correcta, aunque esté oculta por JavaScript |
| 3. Extracción y guardado de datos | Extraes texto, enlaces o tablas y los guardas en CSV/Excel | Conviertes datos web en bruto en algo que realmente puedes usar |
Vamos a profundizar en cada paso con ejemplos prácticos y código que puedes copiar, retocar y presumir ante tus amigos.
Paso 1: Configurar tu entorno de Selenium en Python
Lo primero es lo primero: necesitas instalar Selenium y un controlador del navegador (como ChromeDriver para Chrome). ¿La buena noticia? Ahora es más fácil que nunca.
Instalar Selenium
Abre tu terminal y ejecuta:
pip install selenium
Obtener un WebDriver
- Chrome: Descarga ChromeDriver (asegúrate de que coincida con tu versión de Chrome).
- Firefox: Descarga GeckoDriver.
Consejo profesional: Con Selenium 4.6 o superior, puedes usar Selenium Manager para descargar automáticamente los controladores, así que quizá ya ni necesites tocar las variables PATH (documentación).
Tu primer script de Selenium
Aquí tienes un “hola mundo” rápido para Selenium:
from selenium import webdriver
driver = webdriver.Chrome() # O webdriver.Firefox()
driver.get("https://example.com")
print(driver.title)
driver.quit()
Consejos para solucionar problemas:
- Si recibes un error de “driver not found”, revisa tu PATH o usa Selenium Manager.
- Asegúrate de que las versiones del navegador y del controlador coincidan.
- Si estás en un servidor sin interfaz gráfica (sin GUI), consulta los consejos sobre modo headless más abajo.
Paso 2: Localizar elementos web para extraer datos
Ahora viene la parte divertida: decirle a Selenium qué datos quieres. Los sitios web están construidos con elementos —divs, spans, tablas, lo que se te ocurra— y Selenium te ofrece varias formas de encontrarlos.
Estrategias comunes de localización
By.ID: encuentra un elemento con un ID únicoBy.CLASS_NAME: encuentra elementos por clase CSSBy.XPATH: usa expresiones XPath (muy flexibles, pero pueden ser frágiles)By.CSS_SELECTOR: usa selectores CSS (ideales para consultas complejas)
Así es como podrías utilizarlos:
from selenium.webdriver.common.by import By
# Buscar por ID
price = driver.find_element(By.ID, "price").text
# Buscar por XPath
title = driver.find_element(By.XPATH, "//h1").text
# Buscar todas las imágenes de productos por selector CSS
images = driver.find_elements(By.CSS_SELECTOR, ".product img")
for img in images:
print(img.get_attribute("src"))
Consejo profesional: Usa siempre el localizador más simple y estable posible (ID > clase > CSS > XPath). Y si estás extrayendo datos de una página que carga con retraso, usa esperas explícitas:
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
wait = WebDriverWait(driver, 10)
price_elem = wait.until(EC.presence_of_element_located((By.CSS_SELECTOR, ".price")))
Así evitas que tu script se rompa si los datos tardan un segundo en aparecer.
Paso 3: Extraer y guardar datos
Una vez que hayas encontrado los elementos, toca sacar los datos y guardarlos en un lugar útil.
Extraer texto, enlaces y tablas
Imagina que estás extrayendo una tabla de productos:
data = []
rows = driver.find_elements(By.XPATH, "//table/tbody/tr")
for row in rows:
cells = row.find_elements(By.TAG_NAME, "td")
data.append([cell.text for cell in cells])
Guardar en CSV con Pandas
import pandas as pd
df = pd.DataFrame(data, columns=["Name", "Price", "Stock"])
df.to_csv("products.csv", index=False)
También puedes guardarlo en Excel (df.to_excel("products.xlsx")) o incluso enviarlo a Google Sheets mediante su API.
Ejemplo completo: extraer títulos y precios de productos
from selenium import webdriver
from selenium.webdriver.common.by import By
import pandas as pd
driver = webdriver.Chrome()
driver.get("https://example.com/products")
data = []
products = driver.find_elements(By.CLASS_NAME, "product-card")
for p in products:
title = p.find_element(By.CLASS_NAME, "title").text
price = p.find_element(By.CLASS_NAME, "price").text
data.append([title, price])
driver.quit()
df = pd.DataFrame(data, columns=["Title", "Price"])
df.to_csv("products.csv", index=False)
Selenium vs. BeautifulSoup y Scrapy: ¿qué hace único a Selenium?
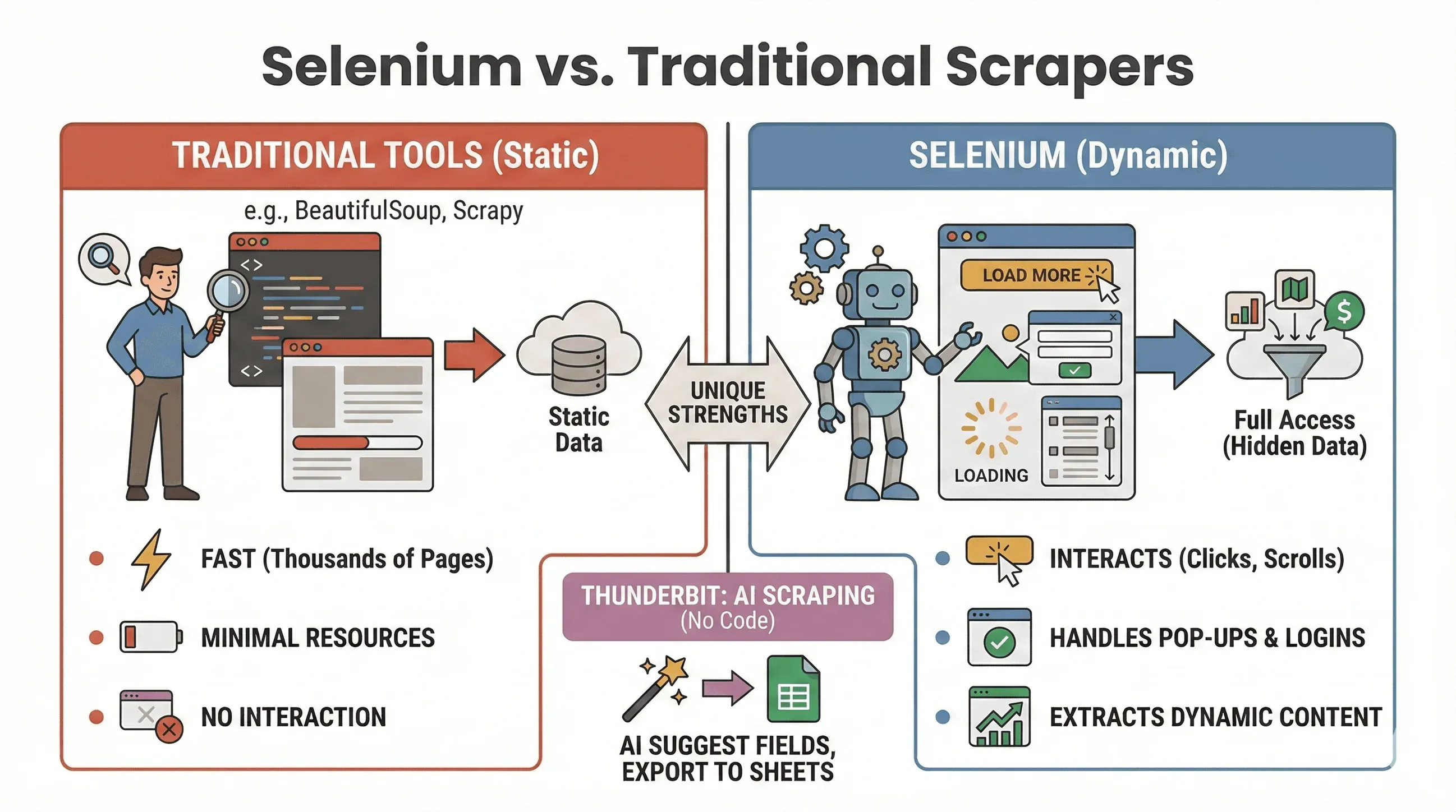 Vamos a zanjar el debate: ¿cuándo deberías usar Selenium y cuándo te conviene más algo como BeautifulSoup o Scrapy? Aquí tienes una comparación rápida:
Vamos a zanjar el debate: ¿cuándo deberías usar Selenium y cuándo te conviene más algo como BeautifulSoup o Scrapy? Aquí tienes una comparación rápida:
| Herramienta | Ideal para | ¿Maneja JavaScript? | Velocidad y consumo de recursos |
|---|---|---|---|
| Selenium | Sitios dinámicos/interactivos | Sí | Más lento, usa más memoria |
| BeautifulSoup | Extracción simple de HTML estático | No | Muy rápido, ligero |
| Scrapy | Rastreo masivo de sitios estáticos | Limitado* | Súper rápido, asíncrono, poca RAM |
| Thunderbit | Scraping empresarial sin código | Sí (IA) | Rápido para trabajos pequeños/medianos |
*Scrapy puede manejar parte del contenido dinámico con complementos, pero no es su punto fuerte (ScrapingBee).
Cuándo usar Selenium:
- Los datos solo aparecen después de hacer clic, desplazarte o iniciar sesión
- Necesitas interactuar con ventanas emergentes, scroll infinito o paneles dinámicos
- Los extractores estáticos simplemente no dan la talla
Cuándo usar BeautifulSoup/Scrapy:
- Los datos ya están en el HTML inicial
- Necesitas extraer miles de páginas rápidamente
- Quieres un consumo mínimo de recursos
Y si quieres evitar programar por completo, Thunderbit te permite extraer sitios dinámicos con IA: solo haz clic en “AI Suggest Fields” y exporta a Sheets, Notion o Airtable. (Más sobre eso abajo.)
Cómo extraer cualquier sitio web usando IA Get Started Free
Automatizar tareas de web scraping con Selenium y Python
Seamos sinceros: nadie quiere despertarse a las 2 de la mañana para ejecutar un script de scraping. La buena noticia es que puedes automatizar tus trabajos con Selenium usando las herramientas de programación de Python o el programador de tareas de tu sistema operativo (como cron en Linux/Mac o el Programador de tareas en Windows).
Usar la biblioteca schedule
import schedule
import time
def job():
# Tu código de scraping aquí
print("Extrayendo datos...")
schedule.every().day.at("09:00").do(job)
while True:
schedule.run_pending()
time.sleep(1)
O con cron (Linux/Mac)
Añade esto a tu crontab para ejecutarlo cada hora:
0 * * * * python /path/to/your_script.py
Consejos para la automatización:
- Ejecuta Selenium en modo headless (ver más abajo) para evitar ventanas emergentes de la interfaz.
- Registra los errores y envíate alertas si algo falla.
- Cierra siempre el navegador con
driver.quit()para liberar recursos.
Aumentar la eficiencia: consejos para que Selenium sea más rápido y fiable
Selenium es potente, pero puede ser lento y consumir muchos recursos si no tienes cuidado. Así puedes acelerar tus scripts y evitar dolores de cabeza comunes:
1. Ejecuta en modo headless
No hace falta ver cómo Chrome se abre y se cierra cien veces. El modo headless ejecuta el navegador en segundo plano:
from selenium.webdriver.chrome.options import Options
opts = Options()
opts.headless = True
driver = webdriver.Chrome(options=opts)
2. Bloquea imágenes y otro contenido innecesario
¿Por qué cargar imágenes si solo estás extrayendo texto? Bloquéalas para acelerar la carga de las páginas:
prefs = {"profile.managed_default_content_settings.images": 2}
opts.add_experimental_option("prefs", prefs)
3. Usa localizadores eficientes
- Prioriza IDs o selectores CSS simples frente a XPaths complejos.
- Evita usar
time.sleep(); mejor utiliza esperas explícitas (WebDriverWait).
4. Aleatoriza los retrasos
Añade pausas aleatorias para imitar la navegación humana y evitar bloqueos:
import random, time
time.sleep(random.uniform(1, 3))
5. Rota user agents e IPs (si hace falta)
Si estás extrayendo mucho volumen, rota tu cadena de user agent y considera usar proxies para evitar medidas antibot sencillas.
6. Gestiona sesiones y errores
- Usa bloques try/except para manejar con elegancia los elementos que faltan.
- Registra errores y captura capturas de pantalla para depurar.
Para más consejos de optimización, consulta la guía de BrowserStack.
Avanzado: combinar Selenium con Thunderbit para exportar datos estructurados
Aquí es donde la cosa se pone realmente interesante, sobre todo si quieres ahorrar tiempo en la limpieza y exportación de datos.
Después de extraer datos en bruto con Selenium, puedes usar Thunderbit para:
- Detectar campos automáticamente: la IA de Thunderbit puede leer las páginas o CSV que hayas extraído y sugerir nombres de columnas (“AI Suggest Fields”).
- Scraping de subpáginas: si tienes una lista de URLs (como páginas de productos), Thunderbit puede visitar cada una y enriquecer tu tabla con más detalles, sin necesidad de código adicional.
- Enriquecimiento de datos: traduce, categoriza o analiza datos sobre la marcha.
- Exportar a cualquier sitio: exportación con un clic a Google Sheets, Airtable, Notion, CSV o Excel.
Ejemplo de flujo de trabajo:
- Usa Selenium para extraer una lista de URLs y títulos de productos.
- Exporta los datos a CSV.
- Abre Thunderbit, importa tu CSV y deja que la IA sugiera campos.
- Usa el scraping de subpáginas de Thunderbit para obtener más detalles (como imágenes o especificaciones) de cada URL de producto.
- Exporta tu conjunto de datos final y estructurado a Sheets o Notion.
Esta combinación ahorra horas de limpieza manual y te permite centrarte en el análisis, no en pelearte con datos desordenados. Para saber más sobre este flujo, consulta la guía de Selenium de Thunderbit.
Exporta datos de Selenium con Thunderbit IA
Mejores prácticas y solución de problemas para el web scraping con Selenium
El web scraping es un poco como pescar: a veces sacas un pez enorme y otras te enredas en las algas. Así puedes mantener tus scripts fiables y éticos:
Mejores prácticas
- Respeta robots.txt y los términos del sitio: comprueba siempre si está permitido extraer datos.
- Limita el ritmo de tus solicitudes: no sobrecargues los servidores; añade pausas y vigila los errores HTTP 429.
- Usa APIs cuando estén disponibles: si los datos están públicos vía API, úsala; es más segura y fiable.
- Extrae solo datos públicos: evita información personal o sensible y ten presentes las leyes de privacidad.
- Gestiona ventanas emergentes y CAPTCHAs: usa Selenium para cerrar pop-ups, pero ten cuidado con los CAPTCHAs; son difíciles de automatizar.
- Aleatoriza user agents y retrasos: ayuda a evitar detección y bloqueos.
Errores comunes y soluciones
| Error | Qué significa | Cómo solucionarlo |
|---|---|---|
NoSuchElementException | No se puede encontrar el elemento | Revisa el localizador; usa esperas |
| Errores de timeout | La página o el elemento tardó demasiado | Aumenta el tiempo de espera; comprueba la velocidad de la red |
| Incompatibilidad entre driver y navegador | Selenium no puede abrir el navegador | Actualiza las versiones del driver y del navegador |
| Fallos de sesión | El navegador se cerró inesperadamente | Usa modo headless; gestiona los recursos |
Para más consejos de solución de problemas, consulta el tutorial de Selenium de Thunderbit.
Conclusión y conclusiones clave
El web scraping dinámico ya no es solo para desarrolladores muy técnicos. Con Python y Selenium, puedes automatizar cualquier navegador, interactuar con los sitios más complejos cargados de JavaScript y extraer los datos que tu negocio necesita, ya sea para ventas, investigación o simplemente por curiosidad. Recuerda:
- Selenium es la herramienta ideal para sitios dinámicos e interactivos.
- Los tres pasos clave: configurar, localizar, extraer y guardar.
- Automatiza tus scripts para actualizaciones periódicas de datos.
- Optimiza la velocidad y la fiabilidad con modo headless, esperas inteligentes y localizadores eficientes.
- Combina Selenium con Thunderbit para estructurar y exportar datos fácilmente, sobre todo si quieres ahorrarte los dolores de cabeza con hojas de cálculo.
¿Listo para probarlo tú mismo? Empieza con los ejemplos de código anteriores y, cuando estés listo para llevar tu scraping al siguiente nivel, prueba Thunderbit para limpiar y exportar datos al instante con IA. Y si quieres seguir aprendiendo, visita el Blog de Thunderbit para encontrar guías en profundidad, tutoriales y lo último en automatización web.
Feliz scraping, y que tus selectores encuentren siempre lo que buscas.
Prueba gratis el Raspador Web IA de Thunderbit Get Started Free
Preguntas frecuentes
1. ¿Por qué debería usar Selenium para hacer web scraping en lugar de BeautifulSoup o Scrapy?
Selenium es ideal para extraer datos de sitios web dinámicos en los que el contenido carga después de acciones del usuario o de la ejecución de JavaScript. BeautifulSoup y Scrapy son más rápidos para HTML estático, pero no pueden interactuar con elementos dinámicos ni simular clics o desplazamientos.
2. ¿Cómo hago para que mi scraper con Selenium funcione más rápido?
Usa modo headless, bloquea imágenes y recursos innecesarios, emplea localizadores eficientes y añade retrasos aleatorios para imitar la navegación humana. Consulta la guía de BrowserStack para más consejos.
3. ¿Puedo programar tareas de scraping con Selenium para que se ejecuten automáticamente?
¡Sí! Usa la biblioteca schedule de Python o el programador de tu sistema operativo (cron o el Programador de tareas) para ejecutar scripts a intervalos definidos. Automatizar el scraping ayuda a mantener los datos actualizados.
4. ¿Cuál es la mejor forma de exportar datos extraídos con Selenium?
Usa Pandas para guardar los datos en CSV o Excel. Para exportaciones más avanzadas (Google Sheets, Notion, Airtable), importa tus datos en Thunderbit y usa sus funciones de exportación con un clic.
5. ¿Cómo puedo manejar ventanas emergentes y CAPTCHAs en Selenium?
Puedes cerrar las ventanas emergentes localizando y haciendo clic en sus botones de cierre. Los CAPTCHAs son mucho más difíciles: si te encuentras con ellos, considera usar una solución manual o un servicio de resolución de captchas, y respeta siempre los términos del sitio.
¿Quieres ver más tutoriales de scraping, consejos de automatización con IA o las últimas novedades sobre herramientas de datos para empresas? Suscríbete al Blog de Thunderbit o visita nuestro canal de YouTube para ver demostraciones prácticas.
Más información




