

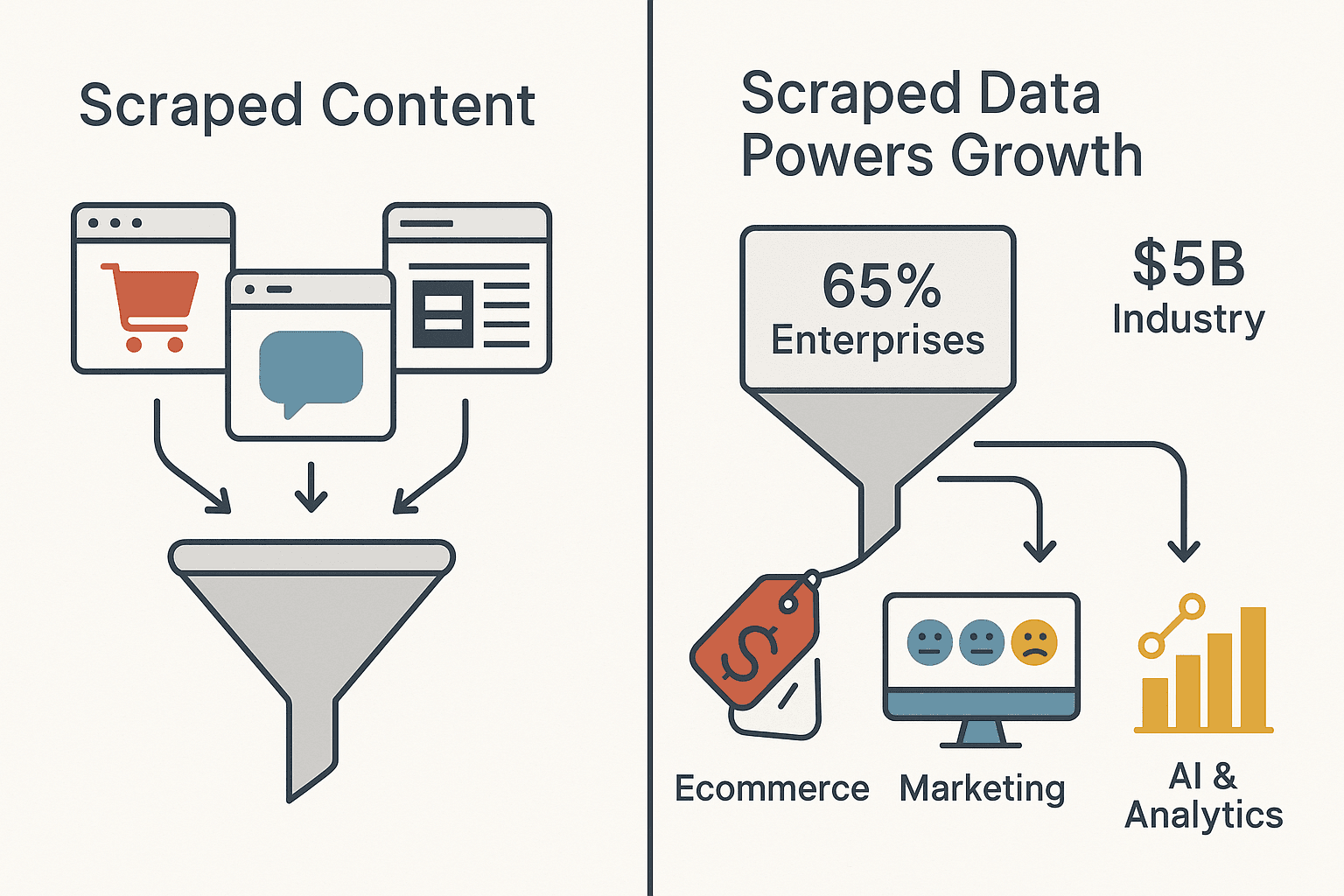
¿Alguna vez te has preguntado cómo algunas empresas parecen saber siempre cuánto cobran sus competidores, qué productos están en tendencia o qué dicen los clientes antes que nadie? No es magia, y tampoco es solo una sala llena de becarios pegados a la pantalla. El secreto es el contenido extraído mediante scraping: datos recopilados automáticamente de sitios web y fuentes en línea, y luego convertidos en inteligencia empresarial accionable. En el panorama digital actual, el contenido extraído mediante scraping está impulsando desde las guerras de precios en ecommerce hasta el análisis de sentimiento en tiempo real en marketing. De hecho, el 65 % de las empresas ya usan web scraping para potenciar la IA y la analítica, y la industria global del web scraping ya vale casi 5.000 millones de dólares.
Extrae datos de cualquier sitio web con IA Get Started Free
Como alguien que ha pasado años construyendo herramientas de automatización e IA (y, sí, extrayendo una buena cantidad de datos web), he visto de primera mano cómo el contenido extraído mediante scraping está redefiniendo la estrategia empresarial. Pero con grandes datos viene una gran responsabilidad, sobre todo cuando hablamos de cumplimiento legal y calidad de los datos. Veamos qué es realmente el contenido extraído mediante scraping, por qué importa, cómo usarlo de forma responsable y por qué Thunderbit es mi opción favorita para sacar el máximo partido a este potente recurso.
Contenido extraído mediante scraping: conceptos básicos
Empecemos por lo básico. El contenido extraído mediante scraping es cualquier dato obtenido de sitios web o plataformas en línea usando herramientas automáticas, como bots, scripts o agentes de IA. En lugar de copiar y pegar información manualmente, un software de web scraping puede recopilar desde precios y reseñas de productos hasta imágenes y datos de contacto, a gran escala y en un formato estructurado.
Fuentes de referencia como DataDome definen el data scraping como “el proceso de extraer datos específicos en forma estructurada desde sitios web o fuentes en línea de acceso público”. En palabras simples: un scraper visita una página web, extrae la información que te interesa (como nombres, precios o fechas) y la coloca en una hoja de cálculo o base de datos para analizarla con facilidad.
Recopilación manual vs. automatizada
Antes, si querías datos de un sitio web, o los copiabas a mano o confiabas en que el sitio ofreciera una API. El contenido extraído mediante scraping cambia por completo este enfoque al automatizar el proceso. Los scrapers modernos pueden manejar sitios dinámicos (con JavaScript, scroll infinito o botones de “Cargar más”) e incluso imitar la navegación humana para acceder a contenido que solo aparece después de una interacción del usuario.
¿Qué se puede extraer?
Casi todo lo que sea visible en una página web se puede extraer, incluyendo:
- Texto: descripciones de productos, precios, artículos de noticias, publicaciones en redes sociales.
- Imágenes: fotos de anuncios, redes sociales o galerías de productos.
- Enlaces y metadatos: URLs, etiquetas u otros atributos HTML.
- Registros estructurados: tablas, directorios, datos bursátiles, anuncios inmobiliarios.
- Contenido generado por usuarios: reseñas, valoraciones, comentarios.
Las empresas suelen enfocarse en puntos de datos concretos que se alinean con sus objetivos, como extraer precios de productos de la competencia en ecommerce o agrupar reseñas de clientes para análisis de sentimiento en marketing.
La base de la ciencia de datos y la investigación
Una vez extraído, este contenido se guarda en un formato estructurado, como CSV, Excel o JSON. Se convierte en la materia prima para analítica, paneles de control y modelos de aprendizaje automático. Ya sea para optimizar precios, seguir tendencias de mercado o crear una lista de leads, el contenido extraído mediante scraping suele ser la columna vertebral de la toma de decisiones basada en datos.
Por qué el contenido extraído mediante scraping importa en las empresas modernas
El contenido extraído mediante scraping no es solo una palabra de moda: es un recurso práctico que está cambiando la forma en que operan las empresas. Estas son las razones por las que se ha vuelto tan importante:

- Inteligencia competitiva: los minoristas extraen precios e información de productos de la competencia para ajustar sus propias ofertas en tiempo real. Para 2025, se espera que el 81 % de los minoristas de EE. UU. use herramientas automatizadas de scraping de precios.
- Velocidad y escala: el scraping permite a las empresas recopilar enormes volúmenes de datos en minutos, lo que respalda decisiones ágiles y actualizadas al minuto.
- Decisiones basadas en datos: los equipos de ventas, marketing, producto y operaciones dependen del contenido extraído mediante scraping para inteligencia de precios, análisis de tendencias, generación de leads y mucho más.
Aquí tienes una vista rápida de cómo distintas industrias usan el contenido extraído mediante scraping:
| Sector/Equipo | Caso de uso del contenido extraído mediante scraping | Beneficio para el negocio |
|---|---|---|
| Ecommerce/Retail | Extraer precios y listados de productos de la competencia | Precios dinámicos en tiempo real, optimización de la estrategia de producto |
| Marketing y marca | Extraer reseñas, valoraciones y comentarios en redes sociales | Análisis de sentimiento, seguimiento de la reputación de marca |
| Ventas y generación de leads | Extraer directorios, LinkedIn e información de contacto | Creación de listas de leads segmentadas, prospección más eficiente |
| Bienes raíces | Extraer anuncios de propiedades de varios sitios | Análisis de mercado, agregación de inventario, estrategia de precios |
| Finanzas/Inversión | Extraer noticias financieras, datos bursátiles y documentos públicos | Datos alternativos para trading, gestión de riesgos, información de mercado en tiempo real |
El contenido extraído mediante scraping ofrece un retorno tangible de la inversión: las empresas que usan herramientas de scraping impulsadas por IA informan ahorros de tiempo del 30 al 40 % en la extracción de datos, liberando a los equipos para centrarse en el análisis y la estrategia.
Contenido extraído mediante scraping y cumplimiento legal: lo que necesitas saber
Con todas estas oportunidades viene una gran salvedad: el scraping no es una zona libre de reglas. Las normas que rodean al contenido extraído mediante scraping están determinadas por la ley de propiedad intelectual, las condiciones de servicio y las regulaciones de privacidad de datos. Esto es lo que debes saber:
¿Es legal el web scraping?
En general, extraer información pública no es ilegal por sí mismo en la mayoría de los lugares, pero la forma en que recopilas y usas los datos puede generar problemas legales. En EE. UU., un caso judicial histórico (hiQ Labs contra LinkedIn) concluyó que extraer datos disponibles públicamente no viola las leyes contra el hacking, pero infringir las condiciones de servicio (ToS) de un sitio web aún puede dar lugar a demandas (meitar.com).
Principales marcos legales:
- Propiedad intelectual: los hechos, como precios o cifras bursátiles, no están protegidos, pero copiar y volver a publicar contenido creativo, como artículos o imágenes, puede activar reclamaciones por copyright. Usa el contenido extraído mediante scraping para análisis interno o asegúrate de que entra dentro del “uso legítimo”.
- Privacidad de datos: leyes como el RGPD europeo y la CCPA de California se aplican si extraes datos personales. Incluso los perfiles públicos pueden estar protegidos, y el incumplimiento puede acarrear multas elevadas.
- Condiciones de servicio: infringir las ToS de un sitio, por ejemplo, extraer datos cuando está expresamente prohibido, puede derivar en demandas civiles, incluso si los datos son públicos.
Diferencias regionales: la UE es mucho más estricta con la extracción de datos personales, y a menudo exige consentimiento explícito o un interés legítimo sólido. EE. UU. es más permisivo con los datos públicos, pero sigue haciendo cumplir los derechos de copyright y de contrato.
Privacidad de datos y consentimiento del usuario en el contenido extraído mediante scraping
La privacidad es un tema candente, especialmente al extraer datos personales o sensibles:
- Público no significa libre uso: que una información sea pública no quiere decir que se pueda usar sin restricciones. Los reguladores esperan que las empresas minimicen la recopilación de datos y sean transparentes sobre cómo usan los datos extraídos.
- Desafíos con el consentimiento: obtener el consentimiento de cada persona cuyos datos extraes es complicado. Muchas empresas se basan en el “interés legítimo”, pero esta figura está cada vez más sometida a escrutinio en la UE.
- Buenas prácticas: anonimiza los datos cuando sea posible, recopila solo lo que necesites y publica un aviso de privacidad claro sobre tus actividades de scraping. Si alguien se opone, prepárate para eliminar sus datos.
Para más información sobre cumplimiento legal, consulta esta guía detallada.
Thunderbit: la forma más inteligente de gestionar el contenido extraído mediante scraping
Ahora sí, hablemos de cómo obtener estos datos de verdad, sin perder la cabeza ni tu posición legal. Thunderbit es una extensión de Chrome de web scraper impulsada por IA, diseñada para usuarios de negocio que buscan resultados, no dolores de cabeza.
¿Por qué Thunderbit?
- Increíblemente fácil de usar: con Thunderbit no necesitas saber programar. Solo abre una página web, haz clic en “AI Suggest Fields” y la IA determina qué extraer, como nombres de productos, precios o información de contacto.
- Estructuración de datos impulsada por IA: Thunderbit garantiza que tus datos extraídos queden limpios, estructurados y listos para el análisis. Incluso puedes añadir indicaciones personalizadas de IA para dar formato, categorizar o traducir los datos mientras se extraen.
- Scraping de subpáginas y paginación: ¿Necesitas obtener detalles de cada página de producto o manejar un scroll infinito? La IA de Thunderbit detecta subpáginas y contenido paginado, automatizando lo que antes era un proceso manual tedioso.
- Scraping en la nube o local: extrae en la nube para ir más rápido (hasta 50 páginas a la vez) o usa tu navegador para sitios protegidos con inicio de sesión.
- Exportación de datos gratuita: exporta directamente a Excel, Google Sheets, Airtable o Notion, sin costes extra ni complicaciones.
- Enfoque prioritario en el cumplimiento: Thunderbit fomenta un scraping responsable al permitirte controlar exactamente qué datos recopilas, ayudándote a evitar datos personales o sensibles salvo que realmente los necesites.
Más de 50.000 usuarios en todo el mundo confían en Thunderbit, desde equipos de ventas hasta operadores de ecommerce y profesionales inmobiliarios.
Prueba gratis Thunderbit AI Web Scraper
Cómo Thunderbit simplifica el flujo de trabajo del contenido extraído mediante scraping
Así se ve el flujo de trabajo con Thunderbit:
- AI Suggest Fields: abre una página web, haz clic en el icono de Thunderbit y deja que la IA sugiera qué campos extraer (por ejemplo, “Nombre del producto”, “Precio”, “URL de detalles”).
- Personaliza los campos: añade o renombra columnas, define tipos de datos o incorpora indicaciones de IA para dar formato o categorizar.
- Extrae: haz clic en “Scrape” y deja que Thunderbit haga el trabajo pesado. En sitios paginados o multinivel, Thunderbit navega automáticamente.
- Enriquecimiento de subpáginas: ¿necesitas más detalles? Usa “Scrape Subpages” para visitar cada enlace y extraer información adicional.
- Exporta: revisa tu tabla estructurada y expórtala a tu herramienta favorita: Excel, Sheets, Notion o Airtable.
- Programa: configura extracciones recurrentes (“cada lunes a las 9:00”) para mantener tus datos siempre actualizados.
Frente a las herramientas de scraping tradicionales, que a menudo requieren programación, configuración manual y mantenimiento constante, el enfoque AI-first de Thunderbit implica menos configuración, menos roturas y más tiempo para analizar, no para solucionar problemas.
Contenido extraído mediante scraping en acción: aplicaciones empresariales reales
Vamos a concretarlo. Estas son algunas formas en que las empresas usan el contenido extraído mediante scraping para obtener una ventaja real:
- Seguimiento de precios en ecommerce: los minoristas extraen a diario, e incluso cada hora, los precios de la competencia para ajustar los suyos en tiempo real. Esto se ha vuelto tan común que el 81 % de los minoristas de EE. UU. ya usan scraping automatizado para precios dinámicos.
- Análisis del sentimiento de los clientes: los equipos de marketing extraen reseñas y comentarios en redes sociales para medir la satisfacción del cliente y detectar problemas a tiempo. Una cadena hotelera usó reseñas extraídas mediante scraping para identificar propiedades con bajo rendimiento y volver a formar al personal, elevando las puntuaciones de satisfacción de los huéspedes.
- Generación de leads: los equipos de ventas crean listas de leads hipersegmentadas extrayendo directorios, LinkedIn o listas de asistentes a eventos. Con Thunderbit, incluso puedes enriquecer leads extrayendo subpáginas para obtener contexto adicional.
- Investigación de mercado inmobiliario: agentes e inversores extraen anuncios de propiedades de varios sitios para analizar tendencias de precios, inventario y cambios del mercado, ahorrando horas de investigación manual y detectando oportunidades más rápido.
- Automatización de operaciones: los equipos extraen sitios web de proveedores para vigilar niveles de stock o cambios de precio, automatizando un proceso que antes era manual y propenso a errores.
En todos estos casos, el contenido extraído mediante scraping no es solo un montón de datos: es un activo estratégico que impulsa decisiones más rápidas e inteligentes.
El panorama en evolución: de la cantidad a la calidad en el contenido extraído mediante scraping
Los primeros tiempos del web scraping se centraban en la idea de que “más es mejor”: recopilar tantos datos como fuera posible y ordenarlos después. Pero a medida que la IA y la analítica han madurado, el foco se ha desplazado hacia la calidad por encima de la cantidad:
- Scraping dirigido: ahora las empresas priorizan extraer las fuentes correctas y los puntos de datos correctos, no simplemente todo lo que encuentran.
- IA para enriquecer datos: herramientas como Thunderbit usan IA para limpiar, categorizar e incluso resumir datos mientras se extraen, haciéndolos más accionables.
- Actualidad y relevancia: el scraping en tiempo real o programado garantiza que los datos estén siempre al día, algo crítico para tareas como el seguimiento de precios o el análisis de sentimiento.
- Cumplimiento como métrica de calidad: los datos obtenidos de forma legal y ética son de mayor calidad porque se pueden usar con seguridad y no te meterán en problemas.
Thunderbit está hecho para esta nueva etapa: te ayuda a centrarte en los datos que importan, garantiza que estén estructurados y cumplan con la normativa, e integra todo sin fricciones en tu flujo de trabajo.
Qué es el data scraping y cómo hacerlo en 2025 Get Started Free
El scraping evoluciona rápidamente, y mantenerse a la vanguardia significa usar las herramientas y buenas prácticas adecuadas.
Retos comunes y cómo superarlos
El scraping no siempre es un camino fácil. Estos son algunos obstáculos comunes, y cómo Thunderbit te ayuda a superarlos:
- Duplicación de datos: extraer de varias fuentes puede crear registros duplicados. Thunderbit estructura los datos con claves únicas y facilita la deduplicación en Excel o Sheets.
- Calidad y precisión: los cambios en un sitio web pueden romper scrapers o provocar datos faltantes. La IA de Thunderbit se adapta a cambios de diseño, y puedes volver a ejecutar rápidamente “AI Suggest Fields” para corregir problemas.
- Defensas del sitio web: CAPTCHA, bloqueos de IP y contenido dinámico pueden descolocar a scrapers básicos. El enfoque basado en navegador de Thunderbit maneja sitios dinámicos, y el scraping en la nube usa varias IP para ofrecer rapidez y fiabilidad.
- Escala y rendimiento: ¿necesitas extraer miles de páginas? El modo nube de Thunderbit procesa hasta 50 páginas a la vez, y puedes programar tareas recurrentes para necesidades continuas.
- Riesgos de cumplimiento: extraer por accidente datos personales o sensibles puede convertirse en un campo minado legal. Thunderbit te permite controlar exactamente qué recopilas, ayudándote a evitar riesgos innecesarios.
La clave es usar una herramienta flexible, impulsada por IA y pensada para usuarios de negocio, no solo para desarrolladores.
Conclusiones clave: sacar el máximo partido al contenido extraído mediante scraping
Cerremos con lo esencial:
- El contenido extraído mediante scraping es una piedra angular del negocio moderno basado en datos. Impulsa desde la inteligencia competitiva hasta la generación de leads, y cada vez es más importante.
- La calidad gana a la cantidad. Céntrate en datos relevantes, precisos y oportunos, no solo en recopilar todo lo que puedas.
- El cumplimiento legal y ético no es negociable. Entiende la propiedad intelectual, la privacidad y las condiciones de servicio antes de extraer datos.
- Thunderbit hace que el scraping sea accesible y responsable. Con sugerencias de campos impulsadas por IA, extracción de subpáginas y un diseño centrado en el cumplimiento, Thunderbit es la forma más fácil para que los usuarios de negocio conviertan datos web en valor empresarial.
- Integra el contenido extraído mediante scraping en tu toma de decisiones. El verdadero poder surge cuando usas estos datos para impulsar la estrategia, no cuando se quedan olvidados en una hoja de cálculo.
¿Listo para ver cómo el contenido extraído mediante scraping puede transformar tu flujo de trabajo? Descarga la extensión de Chrome de Thunderbit y pruébala tú mismo, sin necesidad de programar. Y para más consejos, visita el blog de Thunderbit.
Empieza a extraer datos con Thunderbit ahora
Preguntas frecuentes
1. ¿Qué es exactamente el contenido extraído mediante scraping?
Es un conjunto de datos recopilados automáticamente de sitios web o fuentes en línea mediante herramientas como web scrapers o agentes de IA. Puede incluir texto, imágenes, precios, reseñas, datos de contacto y más, todo estructurado para análisis y uso empresarial.
2. ¿Es legal el web scraping?
Extraer datos públicos suele ser legal, pero usar el contenido extraído mediante scraping de formas que violen la propiedad intelectual, las leyes de privacidad o las condiciones de servicio de un sitio puede generar problemas legales. Comprueba siempre la normativa local y haz scraping de forma responsable.
3. ¿Cómo usan las empresas el contenido extraído mediante scraping?
Las empresas lo usan para fijación de precios competitiva, generación de leads, análisis de sentimiento, investigación de mercado y mucho más. Ayuda a los equipos a tomar decisiones más rápidas y basadas en datos.
4. ¿Qué diferencia a Thunderbit de otras herramientas de scraping?
Thunderbit usa IA para hacer que el scraping sea fácil para usuarios no técnicos. Funciones como “AI Suggest Fields”, la extracción de subpáginas y paginación, y la exportación directa a Excel, Sheets, Notion y Airtable lo distinguen. Además, está diseñado pensando en el cumplimiento y la calidad de los datos.
5. ¿Cómo puedo asegurarme de que mi scraping sea conforme y ético?
Limítate a datos públicos, evita recopilar información personal o sensible salvo que sea necesario, respeta las condiciones de servicio del sitio y anonimiza los datos cuando sea posible. Herramientas como Thunderbit te ayudan a controlar exactamente lo que recopilas, reduciendo los riesgos de cumplimiento.
¿Te interesa profundizar más? Explora más guías y buenas prácticas en el blog de Thunderbit y convirtamos la web en tu próxima ventaja empresarial.
Prueba hoy Thunderbit AI Web Scraper Get Started Free




