Zillow se apoya en , y extraer esos datos a gran escala es una de las tareas más pedidas —y más pesadas— en el trabajo con datos del sector inmobiliario. Si alguna vez intentaste extraer datos de Zillow y acabaste viendo una página de CAPTCHA en vez de los anuncios, tranquilo: no eres el único.
He dedicado bastante tiempo a investigar y probar distintas formas de extraer datos de Zillow, tanto con Python como con herramientas sin código que hemos creado en Thunderbit. Esta guía cubre ambos caminos. Tanto si buscas un tutorial completo en Python con estrategias anti-bot como si solo necesitas 200 anuncios en una hoja de cálculo antes de comer, aquí vas a encontrar tu camino. Veremos por qué importan los datos de Zillow, cómo está estructurado el sitio por dentro, un tutorial paso a paso en Python, las razones exactas por las que se rompen los scrapers y cómo automatizar extracciones recurrentes para seguir los precios.
¿Por qué extraer datos de Zillow?
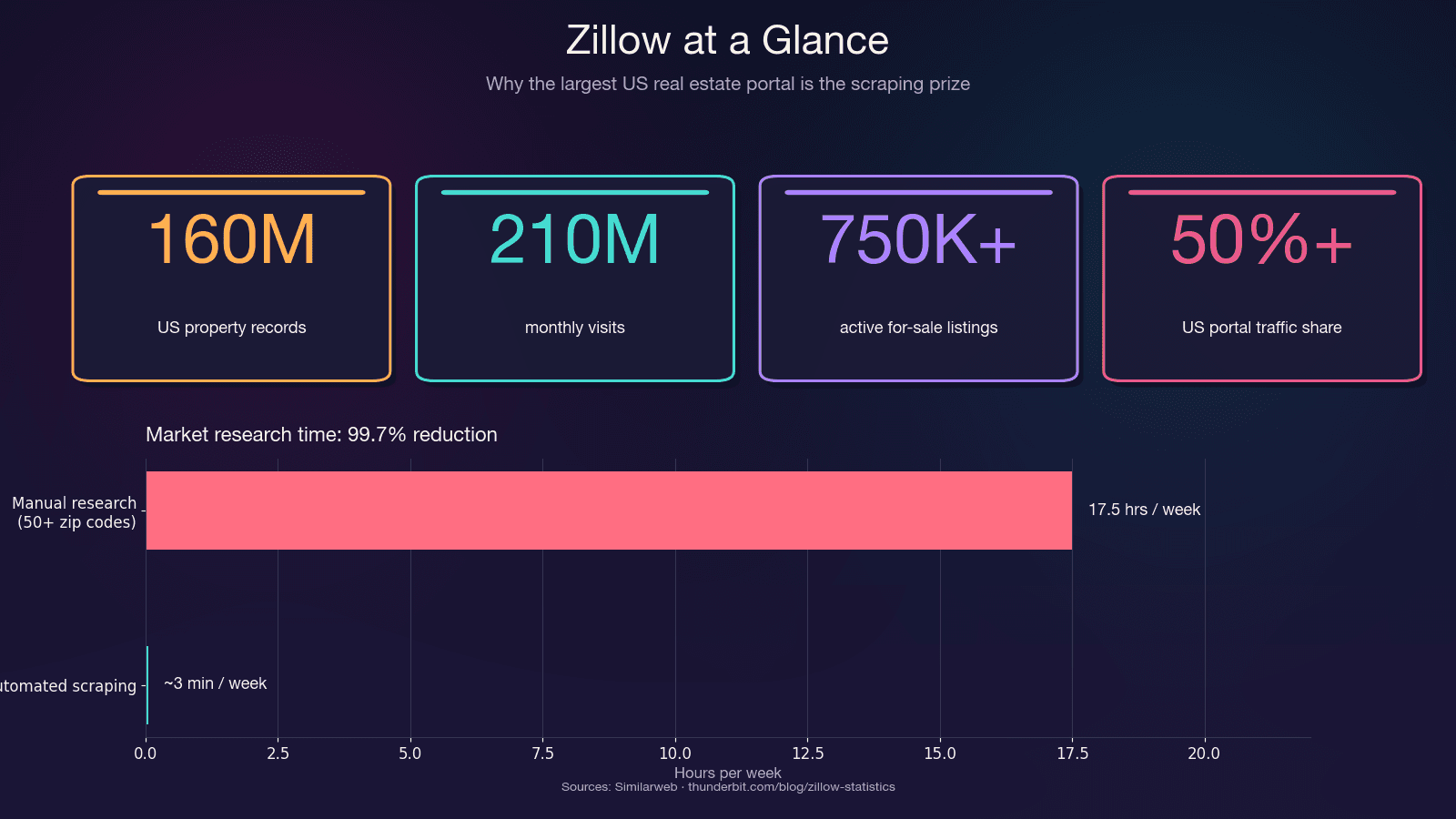
Zillow es el repositorio más grande de datos de bienes raíces residenciales en EE. UU. Recibe y alberga unas 750.000+ propiedades activas en venta, además de 1,9 millones de anuncios de alquiler. La plataforma concentra más del 50% del tráfico total de portales inmobiliarios de EE. UU., más del doble que su competidor más cercano.
Antes de pasar al código Python, conviene tener claro que extraer datos de Zillow con Python no es la única opción, y elegir el método equivocado te puede hacer perder horas. Las herramientas Python como httpx y BeautifulSoup requieren conocimientos intermedios, manejo manual de encabezados y proxies, funcionan a velocidad moderada (1–3 segundos por página) y necesitan mantenimiento frecuente, aunque son gratis; Selenium o Playwright mejoran el manejo anti-bot al renderizar JavaScript, pero son más lentas (5–15 segundos por página) y siguen pidiendo bastante mantenimiento; las APIs de scraping como ScraperAPI o ScrapFly son más rápidas, traen soporte anti-bot integrado y requieren mantenimiento medio, pero cuestan entre 30 y 599 USD al mes; la API oficial de Zillow a través de Bridge Interactive es rápida y de bajo mantenimiento, pero limitada y ronda los 500 USD al mes; y las herramientas sin código como Thunderbit son fáciles para principiantes, rápidas, no requieren mantenimiento gracias a la adaptación con IA y normalmente ofrecen un modelo freemium.
El ahorro de tiempo por sí solo ya es enorme. La investigación manual en más de 50 códigos postales puede comerse 15–20 horas por semana. La extracción automatizada hace el mismo trabajo en minutos —una reducción del 99,7% del tiempo invertido.
Todas las formas de extraer datos de Zillow: Python vs. API vs. sin código
Antes de entrar al código Python, ten en cuenta que "extraer Zillow con Python" no es la única ruta. Elegir mal el método te puede hacer perder horas. Aquí tienes una comparación directa para decidir con cabeza:
| Método | Nivel técnico | Manejo anti-bot | Velocidad | Mantenimiento | Costo |
|---|---|---|---|---|---|
| Python + httpx/BeautifulSoup | Intermedio | Manual (encabezados, proxies) | Moderada (1–3 s/página) | Alto (se rompen los selectores) | Gratis |
| Python + Selenium/Playwright | Intermedio | Mejor (renderiza JS) | Lenta (5–15 s/página) | Alto | Gratis |
| API de scraping (ScraperAPI, ScrapFly) | Intermedio | Integrado | Rápida | Medio | 30–599 USD/mes |
| API oficial de Zillow (Bridge Interactive) | Principiante–Intermedio | N/A | Rápida | Bajo | ~500 USD/mes, acceso limitado |
| Herramienta sin código (Thunderbit) | Principiante | Integrado (la IA se adapta) | Rápida | Ninguno (la IA relee la página) | Freemium |
Si necesitas datos ya mismo sin escribir código, empieza con Thunderbit. Si quieres entender la mecánica interna o necesitas una personalización total, sigue leyendo el tutorial en Python.
La forma más rápida: extraer Zillow con Thunderbit (sin código)
Antes de meternos de lleno en Python, aquí va la ruta para quien solo necesita datos de Zillow rápido —sin configurar Python, sin proxies y sin pelear con selectores. En Thunderbit diseñamos este flujo justo para sacar datos inmobiliarios estructurados sin carga técnica.
Dificultad: Principiante
Tiempo necesario: ~2 minutos
Necesitas: Navegador Chrome, (la versión gratis sirve)
Paso 1: Instala Thunderbit y abre Zillow
Instala la extensión de Thunderbit desde Chrome Web Store. Entra en una página de resultados de búsqueda de Zillow —por ejemplo, busca casas en Houston, TX.
Paso 2: Haz clic en "AI Suggest Fields"
Abre la barra lateral de Thunderbit y haz clic en "AI Suggest Fields". La IA lee la página y te sugiere automáticamente columnas como precio, dirección, habitaciones, baños, metros cuadrados, Zestimate, URL del anuncio y más. En mis pruebas, normalmente detecta más de 20 campos sin tocar nada manualmente.
Paso 3: Haz clic en "Scrape"
Pulsa el botón Scrape. Los datos se cargan en una tabla estructurada dentro de la extensión. Thunderbit maneja automáticamente la paginación de Zillow, tanto por clic como con scroll infinito.
Paso 4: Enriquécelo con extracción de subpáginas
¿Quieres datos de la página de detalle, como historial fiscal, calificaciones escolares o historial de precios? Usa "Scrape Subpages" para enriquecer la tabla. Thunderbit abre cada URL del anuncio y extrae los campos extra —sin escribir código.
Paso 5: Exporta
Exporta a Google Sheets, Excel, Airtable o Notion. La exportación es gratis.
Por qué Thunderbit funciona bien con Zillow
La gran ventaja aquí es la resistencia. La IA de Thunderbit relee la estructura de la página cada vez que extraes datos. Cuando Zillow cambia su diseño —algo que pasa bastante seguido— no hay selectores CSS frágiles que andar corrigiendo. La IA se adapta sola. Eso resuelve de verdad la parte “se rompe con facilidad” de los scrapers con código, que tanta rabia da a muchos usuarios.
¿Qué datos puedes extraer de Zillow? (más de 20 campos)
La mayoría de las guías se quedan en precio y dirección. En realidad, los anuncios de Zillow traen muchos más datos extraíbles de lo que la gente suele pensar —aquí tienes una tabla de referencia:
| Campo | Dónde se encuentra | Dificultad de extracción |
|---|---|---|
| Precio de lista | Búsqueda + detalle | Fácil |
| Dirección / código postal | Búsqueda + detalle | Fácil |
| Zestimate | Búsqueda + detalle | Fácil |
| Historial de precios (cada evento) | Detalle | Difícil (JSON anidado) |
| Historial de impuestos | Detalle | Difícil (JSON anidado) |
| Habitaciones / baños / m² | Búsqueda + detalle | Fácil |
| Año de construcción | Detalle | Fácil |
| Cuota HOA | Detalle | Media |
| Walk Score / Transit Score | Detalle (iframe) | Difícil (requiere renderizado JS) |
| Calificaciones de escuelas | Detalle | Media |
| Tamaño del lote | Detalle | Fácil |
| Días en Zillow | Búsqueda | Fácil |
| Agente / correduría | Búsqueda + detalle | Media |
| Número MLS | Detalle | Fácil |
| Tipo de propiedad | Búsqueda + detalle | Fácil |
| Latitud / longitud | JSON de __NEXT_DATA__ | Media |
| Descripción | Detalle | Fácil |
| URLs de fotos | Búsqueda + detalle | Media |
| Rent Zestimate | Detalle | Media |
| Ventas comparables cercanas | Detalle | Difícil |
Los campos “difíciles” —historial de precios, historial de impuestos, ventas comparables— viven en JSON anidado dentro de las páginas de detalle. La sección de Python más abajo muestra exactamente cómo extraerlos. Y si prefieres saltarte el código, AI Suggest Fields de Thunderbit detecta automáticamente la mayoría de estas columnas, y su función de extracción de subpáginas recoge los campos de detalle sin que tengas que intervenir.
Preparar tu entorno Python para extraer Zillow
Dificultad: Intermedia
Tiempo necesario: ~5 minutos para la configuración, ~30 minutos para el tutorial completo
Necesitas: Python 3.8+, navegador Chrome (para inspeccionar páginas), un editor de texto o IDE
Instala las librerías necesarias:
1pip install httpx beautifulsoup4 pandas lxmlEsto es lo que hace cada una:
- httpx — cliente HTTP con mejor rendimiento que
requestsy soporte asíncrono - beautifulsoup4 + lxml — análisis de HTML
- pandas — exportación de datos a CSV/Excel
- Opcionalmente: selenium o playwright si necesitas renderizar páginas con mucho JavaScript
Entender la estructura de Zillow antes de extraer datos
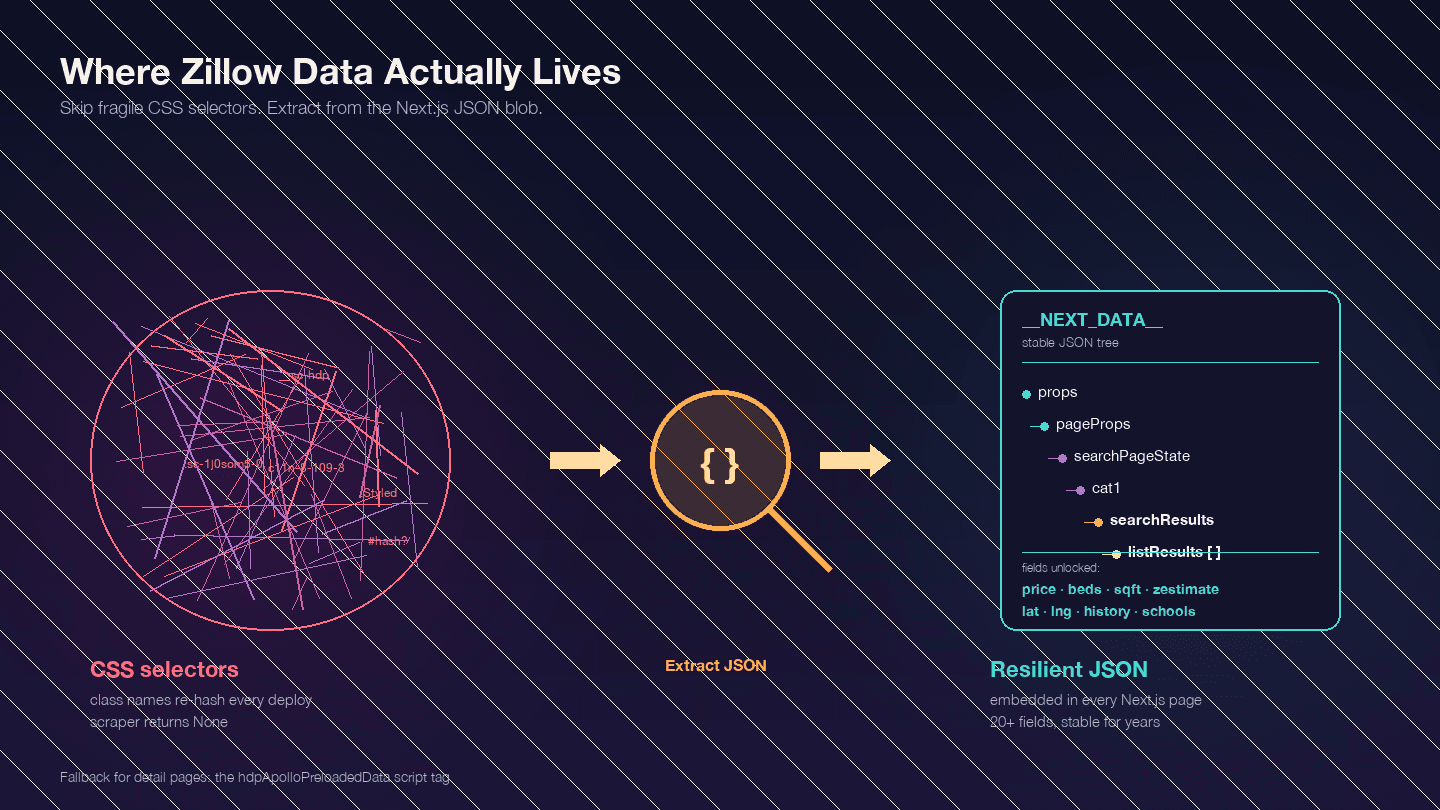
Esto es lo más importante que debes entender antes de escribir código. Zillow es una aplicación Next.js —confirmado por . Eso significa que la mayor parte de los datos que te interesan no está en el HTML visible. Está incrustada en un bloque JSON dentro de <script id="__NEXT_DATA__">.
Abre cualquier página de propiedad en Zillow, pulsa F12, ve a Elements y busca __NEXT_DATA__. Vas a encontrar un objeto JSON enorme con todos los datos del anuncio: precios, coordenadas, detalles de la propiedad, historial de precios, registros fiscales, calificaciones escolares y más.
¿Por qué importa esto? Los nombres de clase CSS de Zillow están hasheados (generados por styled-components) y cambian con cada despliegue. Una clase como StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0 tendrá un hash totalmente distinto la semana siguiente. Cualquier scraper que dependa de selectores CSS se romperá con frecuencia.
El enfoque basado en JSON de __NEXT_DATA__ es mucho más estable porque no depende en absoluto de la estructura visual del HTML.
Rutas JSON clave para resultados de búsqueda:
| Ruta | Contenido |
|---|---|
props.pageProps.searchPageState.cat1.searchResults.listResults | Matriz de resultados de búsqueda |
props.pageProps.searchPageState.cat1.searchResults.mapResults | Resultados de la vista de mapa |
props.pageProps.searchPageState.cat1.searchList.totalPages | Total de páginas disponibles |
Para las páginas de detalle, algunas usan __NEXT_DATA__ y otras usan una etiqueta script alternativa llamada hdpApolloPreloadedData. El código de abajo maneja ambos casos.
Paso a paso: cómo extraer Zillow con Python
Paso 1: configura los encabezados HTTP para evitar bloqueos inmediatos
Enviar un simple httpx.get() a Zillow devuelve una página CAPTCHA, no los datos de los anuncios. Zillow usa PerimeterX (HUMAN Security) junto con Cloudflare —ambos clasificados con por los benchmarks de scraping. El sistema revisa tu huella TLS, los encabezados HTTP y la reputación de tu IP.
Estos son los encabezados mínimos que funcionan a partir de 2025:
1import httpx
2headers = {
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
4 "(KHTML, like Gecko) Chrome/124.0.0.0 Safari/537.36",
5 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
6 "image/avif,image/webp,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Ch-Ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
10 "Sec-Ch-Ua-Platform": '"Windows"',
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "none",
14 "Sec-Fetch-User": "?1",
15 "Upgrade-Insecure-Requests": "1",
16}Los encabezados Sec-Ch-Ua son clave. Muchos tutoriales los omiten —y justo por eso su código no funciona frente a PerimeterX.
Paso 2: extrae resultados de búsqueda de Zillow
Las URLs de búsqueda de Zillow siguen un patrón predecible. Para Houston, TX:
- Página 1:
https://www.zillow.com/houston-tx/ - Página 2:
https://www.zillow.com/houston-tx/2_p/ - Página 3:
https://www.zillow.com/houston-tx/3_p/
Cada página contiene alrededor de 41 anuncios. Zillow limita los resultados a 20 páginas (~820 anuncios). Para conjuntos de datos más grandes, tendrás que dividir por geografía (más sobre eso después).
Aquí tienes el código para extraer resultados de búsqueda sacando los datos del JSON de __NEXT_DATA__:
1from bs4 import BeautifulSoup
2import json
3import time
4import random
5def scrape_zillow_search(url):
6 """Extrae datos de anuncios desde una página de resultados de búsqueda de Zillow."""
7 response = httpx.get(url, headers=headers, timeout=15)
8 if response.status_code != 200:
9 print(f"Recibido estado {response.status_code} para {url}")
10 return []
11 soup = BeautifulSoup(response.text, "lxml")
12 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
13 if not script_tag:
14 print("No se encontró __NEXT_DATA__ — probablemente bloqueado por CAPTCHA")
15 return []
16 next_data = json.loads(script_tag.string)
17 try:
18 results = (
19 next_data["props"]["pageProps"]["searchPageState"]
20 ["cat1"]["searchResults"]["listResults"]
21 )
22 except KeyError:
23 print("Estructura JSON inesperada — Zillow puede haber cambiado el formato")
24 return []
25 listings = []
26 for item in results:
27 listing = {
28 "zpid": item.get("zpid"),
29 "address": item.get("addressStreet"),
30 "city": item.get("addressCity"),
31 "state": item.get("addressState"),
32 "zipcode": item.get("addressZipcode"),
33 "price": item.get("unformattedPrice") or item.get("price"),
34 "beds": item.get("beds"),
35 "baths": item.get("baths"),
36 "sqft": item.get("area"),
37 "zestimate": item.get("zestimate"),
38 "days_on_zillow": item.get("daysOnZillow"),
39 "listing_url": item.get("detailUrl"),
40 "img_src": item.get("imgSrc"),
41 "property_type": item.get("hdpData", {}).get("homeInfo", {}).get("homeType"),
42 "latitude": item.get("latLong", {}).get("latitude"),
43 "longitude": item.get("latLong", {}).get("longitude"),
44 }
45 listings.append(listing)
46 return listingsPara extraer varias páginas, haz un bucle con pausas:
1all_listings = []
2base_url = "https://www.zillow.com/houston-tx/"
3for page in range(1, 6): # Primeras 5 páginas
4 url = base_url if page == 1 else f"{base_url}{page}_p/"
5 print(f"Extrayendo página {page}...")
6 page_listings = scrape_zillow_search(url)
7 all_listings.extend(page_listings)
8 # Pausa aleatoria entre 3 y 7 segundos
9 delay = random.uniform(3, 7)
10 time.sleep(delay)
11print(f"Total de anuncios extraídos: {len(all_listings)}")Deberías ver cómo los datos estructurados de los anuncios se van acumulando en all_listings. Si te salen resultados vacíos, revisa la sección "Por qué se rompen los scrapers" más abajo.
Paso 3: extrae páginas de detalle de propiedades de Zillow
Los resultados de búsqueda te dan lo básico. Las páginas de detalle contienen la información más profunda: historial de precios, historial fiscal, calificaciones escolares, datos del agente y descripción de la propiedad. Cada URL del anuncio obtenida en el Paso 2 apunta a una página de detalle.
Las páginas de detalle de Zillow usan dos formatos de datos posibles. Aquí tienes código para manejar ambos:
1def scrape_zillow_detail(url):
2 """Extrae datos detallados de una propiedad desde una página de Zillow."""
3 response = httpx.get(url, headers=headers, timeout=15)
4 if response.status_code != 200:
5 return None
6 soup = BeautifulSoup(response.text, "lxml")
7 # Primero intenta con __NEXT_DATA__ (lo más común)
8 script_tag = soup.find("script", {"id": "__NEXT_DATA__"})
9 if script_tag:
10 next_data = json.loads(script_tag.string)
11 try:
12 cache_str = next_data["props"]["pageProps"]["componentProps"]["gdpClientCache"]
13 cache = json.loads(cache_str)
14 first_key = next(iter(cache))
15 prop = cache[first_key]["property"]
16 return extract_property_fields(prop)
17 except (KeyError, StopIteration):
18 pass
19 # Alternativa: hdpApolloPreloadedData
20 apollo_tag = soup.find("script", {"id": "hdpApolloPreloadedData"})
21 if apollo_tag:
22 raw = json.loads(apollo_tag.string)
23 api_cache = json.loads(raw["apiCache"])
24 for key, value in api_cache.items():
25 if "ForSale" in key or "property" in str(value)[:100]:
26 prop = value.get("property", value)
27 return extract_property_fields(prop)
28 return None
29def extract_property_fields(prop):
30 """Extrae campos estructurados de un objeto JSON de propiedad de Zillow."""
31 return {
32 "zpid": prop.get("zpid"),
33 "zestimate": prop.get("zestimate"),
34 "rent_zestimate": prop.get("rentZestimate"),
35 "description": prop.get("description"),
36 "year_built": prop.get("yearBuilt"),
37 "lot_size": prop.get("lotSize"),
38 "hoa_fee": prop.get("monthlyHoaFee"),
39 "mls_id": prop.get("mlsid"),
40 "broker_name": prop.get("brokerName") or prop.get("attributionInfo", {}).get("brokerName"),
41 "price_history": [
42 {
43 "date": event.get("date"),
44 "event": event.get("event"),
45 "price": event.get("price"),
46 }
47 for event in prop.get("priceHistory", [])
48 ],
49 "tax_history": [
50 {
51 "year": record.get("time"),
52 "tax_paid": record.get("taxPaid"),
53 "value": record.get("value"),
54 }
55 for record in prop.get("taxHistory", [])
56 ],
57 "schools": [
58 {
59 "name": school.get("name"),
60 "rating": school.get("rating"),
61 "distance": school.get("distance"),
62 }
63 for school in prop.get("schools", [])
64 ],
65 }Haz un bucle sobre las URLs de los anuncios con pausas:
1detail_data = []
2for listing in all_listings[:10]: # Empieza con 10 para probar
3 detail_url = listing.get("listing_url")
4 if not detail_url:
5 continue
6 if not detail_url.startswith("http"):
7 detail_url = f"https://www.zillow.com{detail_url}"
8 print(f"Extrayendo detalle: {detail_url}")
9 detail = scrape_zillow_detail(detail_url)
10 if detail:
11 detail_data.append({**listing, **detail})
12 time.sleep(random.uniform(3, 8))Después de este paso, deberías tener una lista de diccionarios con datos del nivel de búsqueda y del nivel de detalle para cada propiedad.
Paso 4: maneja la paginación para extraer varias páginas
Para zonas con más de 820 anuncios (el límite de 20 páginas), necesitas dividir por geografía. La API interna de Zillow acepta parámetros mapBounds. La estrategia consiste en dividir el mapa en cuadrantes y extraer cada uno por separado.
1def split_bounds(bounds):
2 """Divide los límites del mapa en 4 cuadrantes."""
3 mid_lat = (bounds["north"] + bounds["south"]) / 2
4 mid_lng = (bounds["east"] + bounds["west"]) / 2
5 return [
6 {"north": bounds["north"], "south": mid_lat, "east": bounds["east"], "west": mid_lng},
7 {"north": bounds["north"], "south": mid_lat, "east": mid_lng, "west": bounds["west"]},
8 {"north": mid_lat, "south": bounds["south"], "east": bounds["east"], "west": mid_lng},
9 {"north": mid_lat, "south": bounds["south"], "east": mid_lng, "west": bounds["west"]},
10 ]Para la mayoría de los casos de uso —seguir 50–200 anuncios en una zona concreta— la paginación estándar por URL basta. El enfoque por cuadrantes es para extracciones a nivel de ciudad o de estado.
Paso 5: exporta tus datos de Zillow extraídos
Guarda todo en CSV con pandas:
1import pandas as pd
2df = pd.DataFrame(detail_data)
3df.to_csv("zillow_houston_listings.csv", index=False)
4print(f"Exportadas {len(df)} propiedades a zillow_houston_listings.csv")Para exportar a JSON:
1with open("zillow_houston_listings.json", "w") as f:
2 json.dump(detail_data, f, indent=2)Si quieres saltarte por completo la exportación, Thunderbit exporta gratis a Google Sheets, Airtable y Notion —muy útil si necesitas los datos en un formato colaborativo de inmediato.
Por qué se rompen los scrapers de Zillow (y cómo crear los más resistentes)
Esta es la guía de supervivencia.
Según mi experiencia, los scrapers se rompen en Zillow por tres razones concretas —y cada una tiene una solución clara.
PerimeterX y CAPTCHA: por qué tus solicitudes devuelven datos vacíos
La integración de PerimeterX de Zillow revisa varias señales a la vez: huella TLS, encabezados HTTP, reputación de IP y patrones de solicitud. Cuando detecta automatización, devuelve una página CAPTCHA de "Press & Hold" en lugar de los datos del anuncio.
El escenario exacto de fallo: envías una solicitud con los encabezados predeterminados de Python. El HTML de respuesta contiene scripts del desafío de PerimeterX en vez de los datos de la propiedad, y tu parseo con BeautifulSoup no encuentra ninguna etiqueta __NEXT_DATA__.
La solución: usa el conjunto completo de encabezados que imitan un navegador del Paso 1. Si vas a hacer más que unas pocas decenas de solicitudes, también necesitas rotación de proxies (lo cubrimos más abajo). Para scraping intensivo, considera una librería como curl_cffi con impersonate="chrome" —es el único cliente HTTP de Python que puede igualar la huella TLS de Chrome real.
Selectores CSS dinámicos: por qué BeautifulSoup devuelve None
Si usas selectores CSS como .list-card-price o nombres de clase con hashes, tu scraper se va a romper cada vez que Zillow despliegue nuevo código.
Zillow usa styled-components, que generan nombres de clase como StyledPropertyCardHomeDetailsList-c11n-8-109-3__sc-1j0som5-0. La parte hash cambia con cada compilación.
La solución: no uses selectores CSS en absoluto. Extrae los datos del bloque JSON __NEXT_DATA__ como se muestra en el código anterior. Este enfoque se ha mantenido estable durante años porque la estructura JSON cambia con mucha menos frecuencia que el HTML.
Si de verdad necesitas analizar HTML, busca atributos data-test (por ejemplo, data-test="property-card") o usa coincidencia parcial de clase como [class*="PropertyCard"]. Pero la extracción desde JSON es la ruta más fiable.
Rotación de proxies y backoff exponencial: código que sobrevive a bloqueos de IP
Las IP de centros de datos son por Zillow. Necesitas proxies residenciales para un acceso fiable. Ritmo seguro: 1 solicitud cada 3–8 segundos por IP, manteniéndote por debajo de unas 500 solicitudes por hora.
Aquí tienes un decorador de reintentos con backoff exponencial y jitter:
1import random
2import time
3def backoff_with_jitter(attempt, base_delay=2, max_delay=60):
4 """Backoff exponencial con jitter completo al estilo AWS."""
5 delay = min(max_delay, base_delay * (2 ** attempt))
6 return random.uniform(0, delay)
7def fetch_with_retry(url, max_retries=5):
8 for attempt in range(max_retries):
9 try:
10 response = httpx.get(url, headers=headers, timeout=15)
11 if response.status_code == 200:
12 return response
13 if response.status_code in (403, 429):
14 delay = backoff_with_jitter(attempt, base_delay=5)
15 print(f"Bloqueado ({response.status_code}). Reintentando en {delay:.1f}s...")
16 time.sleep(delay)
17 continue
18 except Exception as e:
19 if attempt == max_retries - 1:
20 raise
21 time.sleep(backoff_with_jitter(attempt))
22 return NoneY un pool simple de rotación de proxies:
1class ProxyPool:
2 def __init__(self, proxies):
3 self.proxies = proxies
4 self.index = 0
5 self.failures = {}
6 def get_next(self):
7 proxy = self.proxies[self.index % len(self.proxies)]
8 self.index += 1
9 return {"http://": proxy, "https://": proxy}
10 def report_failure(self, proxy):
11 self.failures[proxy] = self.failures.get(proxy, 0) + 1
12 if self.failures[proxy] > 3:
13 self.proxies.remove(proxy)
14# Uso:
15pool = ProxyPool(proxies=[
16 "http://user:pass@residential1.example.com:8080",
17 "http://user:pass@residential2.example.com:8080",
18])Entre los proveedores de proxies, ofrece proxies residenciales desde ~1 USD/GB (la opción más barata), mientras que IPRoyal y Smartproxy son opciones intermedias sólidas a 4–7 USD/GB.
La alternativa sin mantenimiento
Si extraes datos de Zillow con frecuencia y estás cansado de arreglar selectores rotos o gestionar pools de proxies, la IA de Thunderbit lee la estructura de la página en cada extracción. No hay selectores que mantener ni configuración de proxies. De verdad resuelve el problema de fragilidad que convierte a los scrapers con código en una molestia repetitiva.
Automatiza la extracción de Zillow: programación y seguimiento de precios
Todos los inversionistas inmobiliarios con los que he hablado quieren esto, y ninguna otra guía de Zillow lo cubre: extracciones automáticas recurrentes para seguimiento de precios.
Para usuarios de Python: cron jobs y detección de cambios de precio
Configura un cron job que ejecute tu scraper cada semana y detecte cambios de precio:
1import pandas as pd
2from datetime import datetime
3def detect_price_changes(new_data, historical_file, threshold=0.05):
4 """Compara una nueva extracción con datos históricos y marca cambios mayores al umbral."""
5 try:
6 old = pd.read_csv(historical_file)
7 except FileNotFoundError:
8 new_data.to_csv(historical_file, index=False)
9 print("Primera ejecución — datos base guardados.")
10 return pd.DataFrame()
11 merged = new_data.merge(old, on="zpid", suffixes=("_new", "_old"))
12 merged["price_change_pct"] = (
13 (merged["price_new"] - merged["price_old"]) / merged["price_old"]
14 )
15 alerts = merged[merged["price_change_pct"].abs() > threshold]
16 # Añade nuevos datos con marca temporal
17 new_data["scraped_at"] = datetime.now().isoformat()
18 new_data.to_csv(historical_file, mode="a", header=False, index=False)
19 return alertsAñádelo a tu crontab para que se ejecute todos los lunes a las 6 AM:
10 6 * * 1 cd /path/to/scraper && python zillow_monitor.pyUn ejemplo práctico: monitorea semanalmente 50 anuncios en Austin, TX. Cada lunes, el script extrae los precios actuales, los compara con la semana anterior y genera un CSV resaltando cualquier bajada de precio superior al 5%.
Para no programadores: Scheduled Scraper de Thunderbit
El Scheduled Scraper de Thunderbit te permite describir el intervalo en lenguaje natural ("cada lunes a las 9am"), introducir tus URLs de búsqueda de Zillow y hacer clic en Schedule. Los datos se exportan automáticamente a Google Sheets en cada ejecución. Sin Python, sin cron, sin servidor que mantener. Va genial para agentes inmobiliarios o equipos de operaciones que necesitan seguimiento de precios constante sin depender de ingeniería.
Consejos para extraer datos de Zillow de forma responsable
Algunas notas para mantenerte dentro de límites razonables:
- Extrae solo datos de acceso público. No entres en páginas detrás de inicio de sesión o autenticación.
- Usa ritmos de solicitud razonables. Entre 3 y 8 segundos entre solicitudes. No satures el servidor.
- No extraigas datos personales o privados. Los nombres de agentes y corredurías en los anuncios son públicos; los datos de cuentas de usuario no lo son.
- Guarda y usa los datos de forma ética. La investigación de mercado, el análisis de inversiones y la generación de leads son usos legítimos. El spam no lo es.
- Contexto legal: la sentencia estableció que extraer datos de acceso público no viola la CFAA. La sentencia Meta v. Bright Data (2024) mantuvo principios similares. Dicho esto, los Términos de Servicio de Zillow restringen el acceso automatizado, y Zillow aplica bloqueos de IP y CAPTCHA en lugar de acciones legales. Revisa siempre la guía vigente y respeta .
Elige el mejor enfoque para extraer Zillow con Python
La mejor ruta depende de tu caso:
¿Necesitas datos rápido y sin código? te lleva de una página de búsqueda de Zillow a una hoja de cálculo estructurada en unos 2 minutos. La IA se adapta a cambios de diseño, maneja la paginación y exporta gratis. Instala la y pruébala en una página de Zillow.
¿Quieres control total? Usa el código Python de esta guía. Extrae desde el JSON de __NEXT_DATA__ —no desde selectores CSS— para más estabilidad. Configura encabezados que imiten un navegador real. Rota proxies residenciales y usa backoff exponencial para ganar fiabilidad.
¿Necesitas escalar? Las APIs de scraping como (99% de tasa de éxito en Zillow) o ScraperAPI se encargan de la infraestructura de proxies y CAPTCHA por ti, por entre 30 y 599 USD al mes según el volumen.
¿Quieres hacer seguimiento de precios en el tiempo? Monta un cron job con el script de detección de cambios de precio, o usa el Scheduled Scraper de Thunderbit para algo sin mantenimiento.
Los datos están ahí. La única pregunta es cuánto tiempo de ingeniería quieres meter para conseguirlos. Para más información sobre cómo llevar datos web a hojas de cálculo, consulta nuestra guía sobre o nuestro para ver los datos más recientes de la plataforma. También puedes ver tutoriales en el .
Preguntas frecuentes
¿Se puede extraer Zillow con Python de forma gratuita?
Sí — httpx, BeautifulSoup y pandas son gratis y de código abierto. El intercambio es el tiempo: tendrás que encargarte tú mismo de los encabezados, la rotación de proxies y el mantenimiento de selectores. Calcula entre 4 y 8 horas para la configuración inicial y entre 4 y 10 horas al mes en mantenimiento cuando Zillow cambie su sitio. Thunderbit también ofrece un plan gratuito si quieres evitar por completo la carga de programación.
¿Zillow tiene una API oficial?
Zillow descontinuó su API pública gratuita en septiembre de 2021. Ahora el acceso pasa por Bridge Interactive, que requiere aprobación, cuesta aproximadamente 500 USD al mes y está orientado a profesionales inmobiliarios con licencia. Para la mayoría de usuarios —inversionistas, investigadores, agentes que hacen análisis de mercado— el scraping es la opción práctica. Zillow sí sigue publicando datos de investigación gratuitos en CSV descargables en , incluidos el Zillow Home Value Index y el Zillow Observed Rent Index.
¿Cómo evito que me bloqueen al extraer datos de Zillow?
Tres cosas: (1) usa encabezados de navegador realistas, incluido Sec-Ch-Ua —este es el encabezado que la mayoría de tutoriales omite y el primero que revisa PerimeterX; (2) rota proxies residenciales —las IP de centros de datos se bloquean de inmediato; (3) extrae datos del JSON de __NEXT_DATA__ en lugar de selectores HTML para evitar roturas por cambios de diseño. Mantén la tasa de solicitudes en 1 cada 3–8 segundos por IP. O usa una herramienta como Thunderbit que gestione la protección anti-bot automáticamente.
¿Cuál es la mejor forma de extraer Zillow sin programar?
Thunderbit AI Web Scraper es la ruta más rápida. Instala la , entra en una página de búsqueda de Zillow, haz clic en "AI Suggest Fields" para detectar columnas automáticamente y luego en "Scrape". Exporta a Google Sheets, Excel, Airtable o Notion sin escribir código. La IA relee la página cada vez, así que no se rompe cuando Zillow actualiza su diseño.
¿Con qué frecuencia cambia Zillow la estructura de su sitio y cómo afecta eso a los scrapers?
Zillow lanza actualizaciones con frecuencia —a veces cada semana. Como usa styled-components, los nombres de clase CSS cambian con cada despliegue y los scrapers basados en selectores CSS se rompen con regularidad. El enfoque más resistente en Python es extraer desde el bloque JSON __NEXT_DATA__, que cambia de estructura mucho menos a menudo. Para una solución sin mantenimiento, la IA de Thunderbit relee la estructura de la página en cada extracción y se adapta automáticamente a los cambios de diseño.
Más información