Yelp alberga repartidas en — y convertir esos datos en un formato útil nunca había sido tan complicado. La ofensiva anti-bots de Yelp de 2024–2025 ha roto, casi sin hacer ruido, la mayoría de los tutoriales de scraping con Python que siguen circulando.
Si últimamente has intentado ejecutar un scraper de Yelp y te has topado con una pared de errores 403, respuestas HTML vacías o CAPTCHAs que hace seis meses no estaban ahí, no te lo estás imaginando. Yelp ahora aplica fingerprinting TLS/JA3, nombres de clases CSS ofuscados y rotación, y una puntuación agresiva de reputación de IP — lo que significa que el viejo enfoque requests + BeautifulSoup que todavía recomiendan todos los tutoriales muere en la primera petición. He pasado semanas probando distintos métodos contra el stack actual de Yelp, y esta guía reúne todo lo que de verdad funciona en 2025: la API oficial Fusion (y por qué probablemente no te baste), un flujo completo de scraping con Python y una estrategia por capas para evitar bloqueos, y una alternativa sin código con solo 2 clics usando para quienes solo quieren los datos sin maratones de depuración.
Por qué extraer Yelp con Python (y quién se beneficia de verdad)
Antes de escribir una sola línea de código, ¿cuál es el caso de negocio real de los datos de Yelp? La plataforma no es solo un sitio de reseñas de restaurantes: en la práctica es una base de datos viva de negocios locales con información estructurada de contacto, valoraciones, categorías, horarios y cientos de millones de reseñas de clientes.
Estos son los perfiles que más se benefician y qué suelen extraer:
| Caso de uso | Campos de datos clave | Por qué importa |
|---|---|---|
| Ventas y generación de leads | Nombre del negocio, teléfono, sitio web, dirección, categoría, valoración | Crea listas segmentadas de prospectos locales — 4 de cada 5 usuarios de Yelp están listos para comprar al llegar |
| Inteligencia competitiva | Reseñas, estrellas, volumen de reseñas, sentimiento | Vigila la reputación de la competencia, detecta fallos de servicio y sigue tendencias |
| Investigación de mercado y NLP | Texto completo de reseñas, fechas, metadatos del revisor | Análisis de sentimiento, modelado temático — las reseñas de Yelp son uno de los corpus de NLP más usados en la investigación académica |
| Inmobiliario y selección de ubicaciones | Densidad de negocios, mezcla de categorías, calidad de reseñas por zona | Selección de ubicaciones para franquicias y retail — Yelp vende Location Intelligence como producto B2B licenciado precisamente para esto |
| Ecommerce y operaciones | Señales de precios, quejas de clientes, horarios de atención | Analiza cómo valoran a la competencia y detecta patrones operativos |
El hilo conductor es claro: el objetivo real son los datos estructurados, y Python solo es un medio para conseguirlos. Algunos lectores querrán control programático total. Otros solo necesitan una hoja de cálculo con contactos de fontaneros en Austin. Aquí cubrimos ambas rutas.
API de Yelp Fusion vs. scraping web con Python: ¿cuál deberías usar?
La mayoría de las guías omiten por completo esta decisión y saltan directamente al código, sin evaluar si la oficial —ahora rebautizada como "Yelp Places API"— habría sido suficiente. En mi experiencia, esa evaluación ahorra horas de esfuerzo inútil, porque la API es excelente para algunas cosas y totalmente insuficiente para otras.
Lo que realmente ofrece la API Fusion
La API Fusion proporciona búsqueda estructurada de negocios, detalles de negocio, autocompletado y un endpoint de reseñas. Está autorizada, bien documentada y no requiere trucos anti-bot.
Pero el problema empieza justo en el endpoint de reseñas. Esto es lo que el propio personal de Yelp ha confirmado en GitHub:
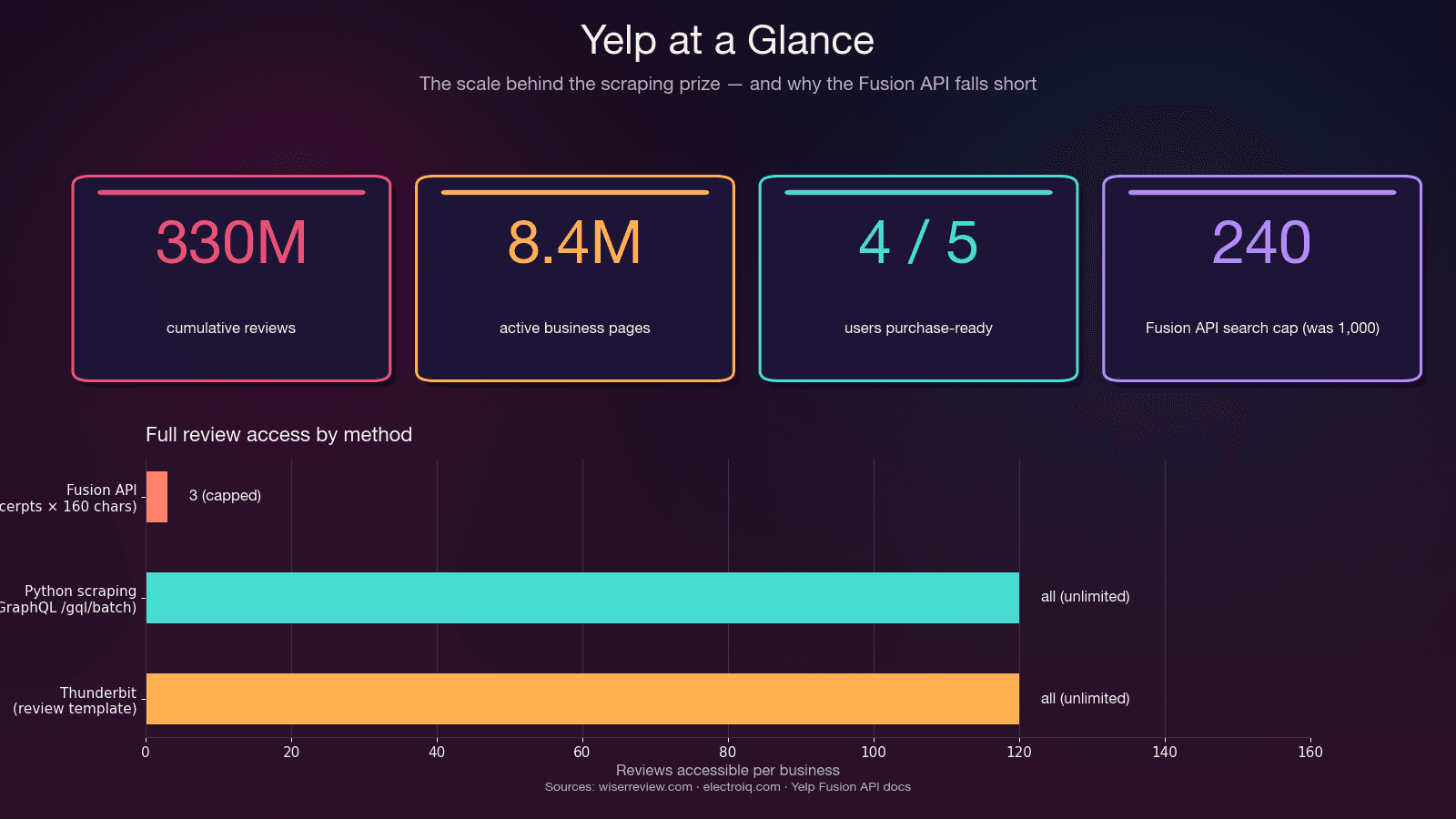
"La API de Yelp no devuelve el texto completo de las reseñas. De forma predeterminada se proporcionan tres fragmentos de reseña de 160 caracteres." —
No es un fallo: está hecho así a propósito. La API se limita físicamente a 3 fragmentos de reseña (7 en Premium), cada uno recortado a unos 160 caracteres. No hay metadatos de reseña (votos de útil/divertida/cool), no hay historial del revisor, no hay respuestas del propietario. Y el después de mayo de 2023 — frente a las 5.000 anteriores. El precio de entrada parte de .
Marco de decisión
| Factor | API Yelp Fusion | Scraping web con Python | Thunderbit (sin código) |
|---|---|---|---|
| Reseñas completas | ❌ Solo 3 fragmentos (~160 caracteres cada uno) | ✅ Todas las reseñas vía GraphQL | ✅ Todas las reseñas visibles |
| Límites de uso | 300–500/día (nuevos); 5.000 (heredados) | Lo gestionas tú (con presupuesto de proxies) | Basado en créditos |
| Esfuerzo de configuración | ~15 min (clave API + SDK) | Horas o días | ~2 minutos |
| Campos de negocio | ~20 campos estructurados | Ilimitados (parseando HTML/JSON) | Campos sugeridos por IA |
| Gestión anti-bot | N/A (autorizado) | Debes construirla tú | Gestionada automáticamente |
| Riesgo legal | ✅ Autorizado | ⚠️ Zona gris en los Términos | ⚠️ Igual que el scraping |
| Coste | Desde $29/mes | Gratis (+ coste de proxies de $0,75–$4/GB) | Hay plan gratis disponible |
| Mantenimiento | Bajo (API estable) | Alto (los selectores se rompen, la defensa anti-bot se endurece) | Bajo (la IA se reajusta) |
Usa la API Fusion si: necesitas información básica del negocio, consultas a pequeña escala o una integración autorizada — y te bastan 3 fragmentos de reseña por negocio.
Usa scraping con Python si: necesitas el texto completo de las reseñas, todas las reseñas de un negocio, metadatos de reseñas, más de 240 resultados por búsqueda o tu presupuesto es inferior a $29/mes.
Usa Thunderbit si: quieres los datos rápido sin escribir ni mantener código. Más sobre esto en la sección sin código más abajo.
El atajo sin código: extrae Yelp con Thunderbit (sin Python)
Antes de entrar en el detalle con Python, aquí tienes la ruta más rápida para quienes realmente quieren los datos, no hacer un ejercicio de programación. Todas las guías de la competencia asumen que dominas Python, pero en mi trabajo en Thunderbit he visto que una gran parte de quienes buscan "scrape Yelp" son comerciales, responsables de operaciones y dueños de pequeñas empresas que solo quieren una hoja de cálculo con negocios locales — no un curso intensivo de fingerprinting TLS.
ya incluye plantillas preconstruidas para Yelp:
- — extrae nombre del negocio, valoración, datos de contacto, dirección, horarios y categoría
- — extrae usuario del revisor, contenido de la reseña, valoración, fecha y ubicación del revisor
Cómo funciona en la práctica
- Abre una página de resultados de búsqueda de Yelp o una ficha de negocio en Chrome
- Haz clic en AI Suggest Fields en la — la IA lee la página y propone columnas (nombre del negocio, valoración, número de reseñas, rango de precio, categoría, dirección, teléfono, URL)
- Haz clic en Scrape — y listo
Con las plantillas de Yelp ya preparadas, es todavía más fácil: abre la plantilla y pulsa Scrape.
El scraping de subpáginas automatiza el ciclo de enriquecimiento — empiezas desde una página de resultados de Yelp, activas el scraping de subpáginas y Thunderbit visita cada ficha de negocio para extraer horarios, reseñas completas, sitio web, fotos y servicios. Sin configuración adicional.
La paginación es automática — tanto la basada en clics como la de desplazamiento, gestionada de serie. (Si quieres saber más, consulta nuestra .)
Las exportaciones son gratis en todos los planes — Excel, Google Sheets, Airtable, Notion, CSV, JSON. Sin pandas, sin código para escribir CSV.
Comparación de tiempo
| Tiempo | Scraper con Python | Thunderbit |
|---|---|---|
| Primera ejecución | Horas o días (escribir selectores, manejar paginación, proxies y lógica de reintentos) | ~30 segundos con la plantilla preconstruida de Yelp |
| Cuando Yelp cambia el marcado | Reescribir selectores manualmente | Vuelve a hacer clic en AI Suggest Fields — se reajusta solo |
| Cuando bloquean la IP | Depurar, rotar pools de proxies, volver a probar | El modo Cloud gestiona la rotación de IP |
| Exportar a Google Sheets | Escribir OAuth + pegar con pandas | Un clic, gratis |
Si pruebas Thunderbit primero y ves que cubre lo que necesitas, puedes saltarte el resto del artículo. Si necesitas control programático total, campos personalizados o escalar más allá de unos pocos miles de registros al mes, sigue leyendo.
Librerías de Python para extraer Yelp: cuál elegir
"¿Debería usar Scrapy, BS4+requests o Selenium?" es una de las preguntas más comunes en hilos de r/webscraping sobre Yelp. Y, aun así, cada tutorial elige su librería favorita y sigue adelante sin explicar por qué. Aquí va un resumen honesto.
La realidad de 2025: requests + BeautifulSoup está roto para Yelp
El stack que recomiendan todos los tutoriales clásicos de Yelp — pip install requests beautifulsoup4 — te bloquea en la primera petición en 2025. No en la 50. En la primera.
La razón: la librería requests de Python envía una huella TLS/JA3 que no coincide con la de un navegador real. La capa anti-bot de Yelp la detecta en el handshake TLS, antes incluso de leer tu cabecera User-Agent. Lo he probado repetidamente — IP nueva, cabeceras realistas, retrasos aleatorios — y aun así recibí un 403 Forbidden inmediato con requests puro.
Matriz de decisión de librerías
| Librería | Ideal para | ¿Maneja JS? | ¿Anti-bot? | Curva de aprendizaje | Velocidad |
|---|---|---|---|---|---|
requests + BeautifulSoup | ❌ | ❌ | Muy baja | Rápido (hasta que te bloquean) | |
httpx async + parsel | Scraping asíncrono a gran escala | ❌ | ❌ | Baja | Muy rápido |
curl_cffi + parsel | Específico para Yelp: suplantación TLS | ❌ | ✅ TLS/JA3/HTTP2 | Baja | Muy rápido |
Scrapy 2.14 | Pipelines completos con paginación | Parcial (vía scrapy-playwright) | AutoThrottle, middleware de reintentos | Media-alta | Rápido |
Selenium 4.43 / Playwright 1.58 | Páginas muy cargadas de JS, evasión de CAPTCHAs | ✅ | Parcial | Media | Lento (~10–30 páginas/min) |
| Thunderbit | Usuarios no técnicos, extracción rápida | ✅ (navegador) | Integrado (modo Cloud) | Muy baja | Rápido |
La revelación de curl_cffi
La librería que cambió mi flujo de trabajo para extraer Yelp es — un binding de Python para curl-impersonate. Emite exactamente la misma huella TLS/JA3 + HTTP/2 que Chrome real, y su API se puede usar como sustituto directo de requests:
1from curl_cffi import requests
2r = requests.get(
3 "https://www.yelp.com/biz/some-restaurant",
4 impersonate="chrome131",
5)
6print(r.status_code, len(r.text))Ese único cambio — from curl_cffi import requests más impersonate="chrome131" — sortea la sin levantar un navegador. En mis pruebas, la diferencia es pasar de 403 instantáneos a respuestas 200 limpias.
Mi stack recomendado para Yelp en 2025: curl_cffi + parsel + jmespath + proxies residenciales. Si necesitas un pipeline completo con programación, envuélvelo en Scrapy 2.14 con un middleware de descarga basado en curl_cffi.
Configurar tu entorno Python para extraer Yelp
- Dificultad: Intermedia
- Tiempo necesario: ~15 minutos para la configuración, 1–2 horas para un scraper funcional
- Lo que necesitas: Python 3.10+ (recomendado 3.12), una terminal y, opcionalmente, un proveedor de proxies residenciales
Paso 1: crea un entorno virtual e instala los paquetes
1python3.12 -m venv .venv
2source .venv/bin/activate # En Windows: .venv\Scripts\activate
3pip install "curl_cffi>=0.11" "parsel>=1.9" "jmespath>=1.0" pandasQué hace cada paquete:
curl_cffi— hace peticiones HTTP con la huella TLS de Chrome (el bypass anti-bot)parsel— selectores CSS/XPath para analizar HTML (el mismo motor que usa Scrapy, pero más ligero)jmespath— consultas declarativas sobre JSON (más limpio que acceder a diccionarios anidados en el JSON embebido de Yelp)pandas— exportación de datos a CSV/Excel
Opcional, pero útil:
1pip install fake-useragent # Nota: el repositorio fue archivado en abril de 2026, pero sigue siendo instalablePaso a paso: cómo extraer Yelp con Python
Este es el tutorial principal. La idea clave que hace todo mucho más resistente: salta los selectores CSS y extrae el JSON oculto. Yelp randomiza los nombres de las clases CSS en cada compilación (y-css-14xwok2 una semana, y-css-hcq7b9 la siguiente), así que cualquier scraper que dependa de ellos se rompe en cuestión de semanas. Las cargas JSON embebidas — application/ld+json y react-root-props — son estables.
Paso 2: extraer los resultados de búsqueda de Yelp
Las URLs de búsqueda de Yelp siguen un patrón predecible: https://www.yelp.com/search?find_desc={term}&find_loc={location}. Los datos de resultados están incrustados en una etiqueta <script data-id="react-root-props"> como JSON — no se renderizan en el caos de clases CSS.
1import re, json, jmespath
2from curl_cffi import requests
3from parsel import Selector
4HEADERS = {
5 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
6 "AppleWebKit/537.36 (KHTML, like Gecko) "
7 "Chrome/124.0.0.0 Safari/537.36",
8 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
9 "image/avif,image/webp,image/apng,*/*;q=0.8",
10 "accept-language": "en-US,en;q=0.9",
11 "accept-encoding": "gzip, deflate, br",
12 "cookie": "intl_splash=false",
13}
14def scrape_search(term: str, location: str, max_pages: int = 3):
15 results = []
16 for page in range(max_pages):
17 url = (f"https://www.yelp.com/search?"
18 f"find_desc={term}&find_loc={location}&start={page * 10}")
19 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
20 if r.status_code != 200:
21 print(f"Bloqueado en la página {page}: {r.status_code}")
22 break
23 sel = Selector(text=r.text)
24 script = sel.xpath(
25 "//script[@data-id='react-root-props']/text()"
26 ).get() or ""
27 m = re.search(r"react_root_props\s*=\s*(\{.*?\});", script, re.S)
28 if not m:
29 print(f"No se encontró react-root-props en la página {page} — posible bloqueo suave")
30 break
31 data = json.loads(m.group(1))
32 businesses = jmespath.search(
33 "legacyProps.searchAppProps.searchPageProps"
34 ".mainContentComponentsListProps"
35 "[?searchResultBusiness].searchResultBusiness.{"
36 "name: name, url: businessUrl, rating: rating, "
37 "reviews: reviewCount, phone: phone, "
38 "neighborhoods: neighborhoods}",
39 data,
40 ) or []
41 results.extend(businesses)
42 import time, random
43 time.sleep(random.uniform(3, 7))
44 return resultsDeberías obtener una lista de diccionarios con nombres de negocio, URLs, valoraciones y número de reseñas. Si react-root-props falta en la respuesta, te han servido un shell de bloqueo — rota tu IP y vuelve a intentarlo.
La cabecera Cookie: intl_splash=false es un truco estándar para evitar el redireccionamiento de la pantalla de país de Yelp. Sin ella, las IP fuera de EE. UU. acaban en una pantalla de aviso que parece un bloqueo suave pero no lo es.
Paso 3: extraer páginas de negocio de Yelp
Cada URL de negocio obtenida en los resultados lleva a una página de detalle con datos más ricos. El objetivo de extracción más estable es el bloque <script type="application/ld+json"> — contiene datos estructurados de schema.org que Yelp mantiene por SEO y no ofusca.
1def scrape_business(biz_url: str) -> dict:
2 url = f"https://www.yelp.com{biz_url}" if biz_url.startswith("/") else biz_url
3 r = requests.get(url, headers=HEADERS, impersonate="chrome131")
4 if r.status_code != 200:
5 return {"url": url, "error": r.status_code}
6 sel = Selector(text=r.text)
7 biz_id = sel.css('meta[name="yelp-biz-id"]::attr(content)').get()
8 for raw in sel.css('script[type="application/ld+json"]::text').getall():
9 try:
10 data = json.loads(raw)
11 except json.JSONDecodeError:
12 continue
13 for node in (data if isinstance(data, list) else [data]):
14 if node.get("@type") in (
15 "Restaurant", "LocalBusiness", "FoodEstablishment",
16 "HealthAndBeautyBusiness", "HomeAndConstructionBusiness",
17 ):
18 return {
19 "biz_id": biz_id,
20 "name": node.get("name"),
21 "rating": (node.get("aggregateRating") or {}).get("ratingValue"),
22 "review_count": (node.get("aggregateRating") or {}).get("reviewCount"),
23 "address": node.get("address"),
24 "telephone": node.get("telephone"),
25 "price_range": node.get("priceRange"),
26 "hours": node.get("openingHours"),
27 "url": url,
28 }
29 return {"biz_id": biz_id, "url": url}El valor de meta[name="yelp-biz-id"] es el ID de negocio codificado que necesitarás para el endpoint de reseñas. Consíguelo aquí: lo usarás en el siguiente paso.
Paso 4: extraer reseñas de Yelp con paginación
Aquí es donde la API Fusion se queda corta y el scraping gana. El endpoint interno GraphQL de Yelp devuelve el texto completo de la reseña, información del revisor, fechas, valoraciones y recuento de votos — todo lo que la API oculta.
El endpoint es https://www.yelp.com/gql/batch y usa un documentId estático para la operación GetBusinessReviewFeed. La paginación funciona mediante un cursor codificado en base64.
1import base64
2GQL_URL = "https://www.yelp.com/gql/batch"
3DOC_ID = "ef51f33d1b0eccc958dddbf6cde15739c48b34637a00ebe316441031d4bf7681"
4def fetch_reviews(enc_biz_id: str, num_pages: int = 5):
5 all_reviews = []
6 for page in range(num_pages):
7 offset = page * 10
8 cursor = base64.b64encode(
9 json.dumps({"version": 1, "offset": offset}).encode()
10 ).decode()
11 payload = [{
12 "operationName": "GetBusinessReviewFeed",
13 "variables": {
14 "encBizId": enc_biz_id,
15 "reviewsPerPage": 10,
16 "after": cursor,
17 "sortBy": "DATE_DESC",
18 "language": "en",
19 },
20 "extensions": {
21 "operationType": "query",
22 "documentId": DOC_ID,
23 },
24 }]
25 r = requests.post(
26 GQL_URL,
27 json=payload,
28 headers={
29 **HEADERS,
30 "content-type": "application/json",
31 "x-apollo-operation-name": "GetBusinessReviewFeed",
32 "apollographql-client-name": "yelp-main-frontend",
33 },
34 impersonate="chrome131",
35 )
36 if r.status_code != 200:
37 print(f"Falló la obtención de reseñas en el offset {offset}: {r.status_code}")
38 break
39 data = r.json()
40 # Navega la estructura de respuesta para extraer las reseñas
41 try:
42 reviews = data[0]["data"]["business"]["reviews"]["edges"]
43 for edge in reviews:
44 node = edge.get("node", {})
45 all_reviews.append({
46 "reviewer": node.get("author", {}).get("displayName"),
47 "rating": node.get("rating"),
48 "date": node.get("localizedDate"),
49 "text": node.get("text", {}).get("full"),
50 })
51 except (KeyError, IndexError, TypeError):
52 break
53 import time, random
54 time.sleep(random.uniform(3, 7))
55 return all_reviewsCada página devuelve 10 reseñas. Incrementa el offset en el cursor base64 para paginar. El parámetro sortBy admite DATE_DESC (más recientes primero), RATING_ASC, RATING_DESC y otros.
Paso 5: exportar tus datos de Yelp extraídos
1import pandas as pd
2# Suponiendo que ya has recopilado negocios y reseñas
3df_businesses = pd.DataFrame(businesses)
4df_businesses.to_csv("yelp_businesses.csv", index=False)
5df_reviews = pd.DataFrame(all_reviews)
6df_reviews.to_csv("yelp_reviews.csv", index=False)
7# O guárdalo como JSON para mayor flexibilidad
8import json
9with open("yelp_data.json", "w") as f:
10 json.dump({"businesses": businesses, "reviews": all_reviews}, f, indent=2)Para quienes siguen la ruta sin código, Thunderbit exporta los mismos datos directamente a Excel, Google Sheets, Airtable o Notion — sin pandas ni código para escribir archivos.
El manual anti-bloqueo: cómo extraer Yelp sin que te bloqueen
Esta sección es la razón de ser de todo el artículo. Las medidas anti-bot de Yelp se han endurecido notablemente desde finales de 2024 — están todas en juego. La mayoría de las guías existentes están desactualizadas porque se escribieron antes de esta ofensiva.
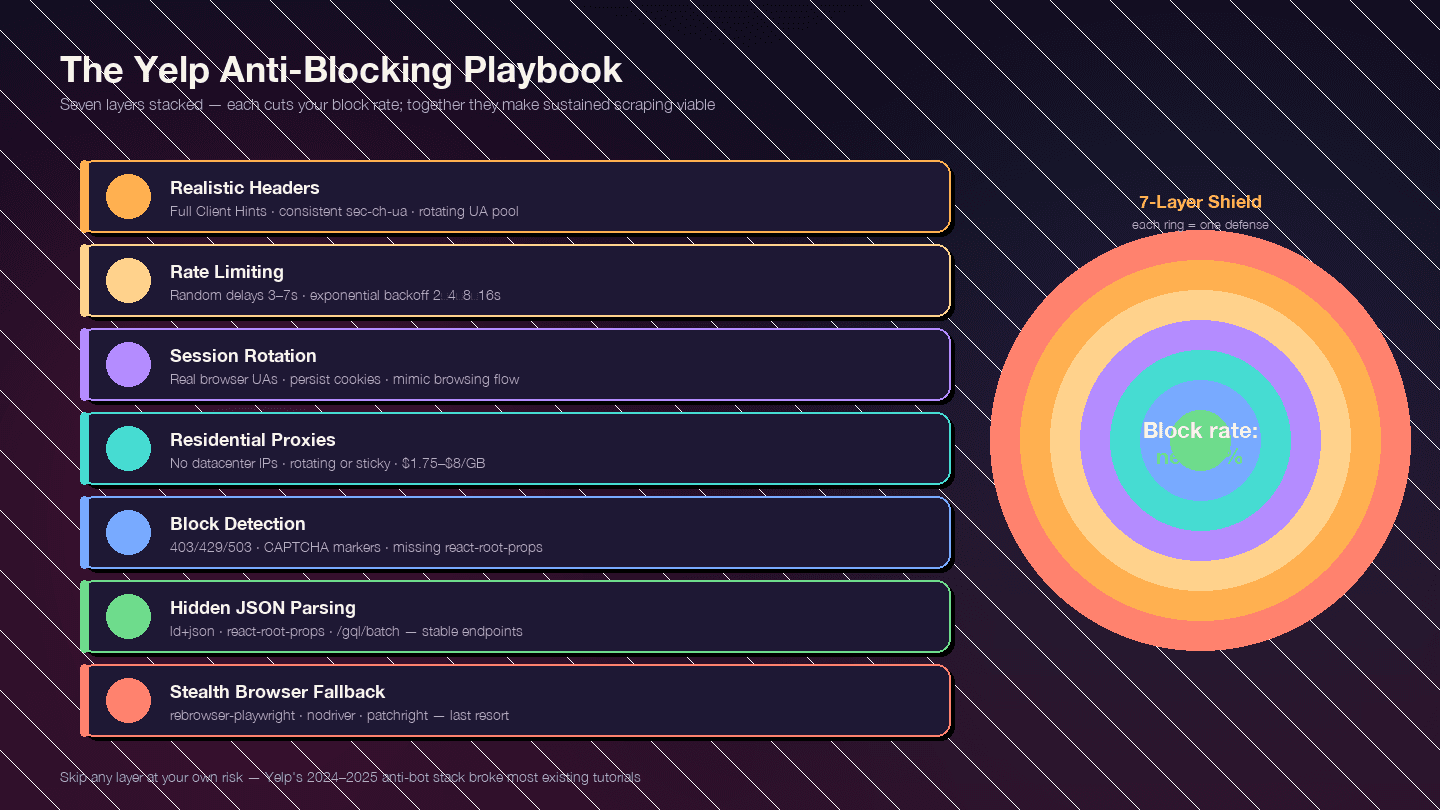
La estrategia debe ser por capas. Cada capa reduce la tasa de bloqueo; combinadas, hacen viable el scraping continuo.
Capa 1: cabeceras de petición realistas
Las cabeceras por defecto de requests envían User-Agent: python-requests/2.x — bloqueo inmediato. Pero ni siquiera un User-Agent realista basta. Yelp comprueba el conjunto completo de cabeceras para ver si todo encaja.
1FULL_HEADERS = {
2 "authority": "www.yelp.com",
3 "user-agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36",
6 "accept": "text/html,application/xhtml+xml,application/xml;q=0.9,"
7 "image/avif,image/webp,image/apng,*/*;q=0.8",
8 "accept-language": "en-US,en;q=0.9",
9 "accept-encoding": "gzip, deflate, br",
10 "sec-ch-ua": '"Chromium";v="124", "Google Chrome";v="124", "Not-A.Brand";v="99"',
11 "sec-ch-ua-mobile": "?0",
12 "sec-ch-ua-platform": '"Windows"',
13 "sec-fetch-dest": "document",
14 "sec-fetch-mode": "navigate",
15 "sec-fetch-site": "same-origin",
16 "sec-fetch-user": "?1",
17 "upgrade-insecure-requests": "1",
18 "referer": "https://www.yelp.com/",
19 "cookie": "intl_splash=false",
20}Tres errores que te hacen saltar las alarmas:
- El UA dice Chrome, pero
sec-ch-uafalta o contradice la versión del UA sec-ch-ua-platformdice "Windows", pero la cadena UA indica macOS- El mismo UA exacto en miles de peticiones desde una IP — rota entre 10–20 cadenas recientes de Chrome/Firefox/Safari
Capa 2: limitación de ritmo y pausas aleatorias
Los patrones temporales predecibles son una señal de alerta. Añade intervalos de sueño aleatorios e implementa backoff exponencial ante errores.
1import random, time
2def polite_get(client_get, url, attempt=0):
3 r = client_get(url, headers=FULL_HEADERS, impersonate="chrome131")
4 if r.status_code in (403, 429, 503):
5 if attempt >= 4:
6 raise RuntimeError(f"Bloqueado tras {attempt + 1} intentos en {url}")
7 backoff = 2 ** (attempt + 1) + random.random()
8 print(f" Recibido {r.status_code}, aplicando espera {backoff:.1f}s (intento {attempt + 1})")
9 time.sleep(backoff)
10 return polite_get(client_get, url, attempt + 1)
11 time.sleep(random.uniform(3, 7))
12 return r| Parámetro | Valor recomendado |
|---|---|
| Pausa aleatoria entre peticiones | random.uniform(3, 7) segundos |
| Backoff ante 429/403/503 | 2 → 4 → 8 → 16s, máximo 5 intentos |
| Trabajadores concurrentes por IP | 1 (serializa por IP; usa proxies para paralelismo) |
| Ritmo sostenido máximo por IP residencial | ~1 petición / 5s (~12 rpm) |
Capa 3: rotación de User-Agent y sesiones
Rota entre un conjunto de cadenas User-Agent de navegadores reales. Conserva sesiones y cookies para imitar el comportamiento de navegación auténtico: Yelp usa detección basada en cookies, así que crear una sesión nueva en cada petición también resulta sospechoso.
1UA_POOL = [
2 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
3 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:125.0) Gecko/20100101 Firefox/125.0",
5 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14.4; rv:125.0) Gecko/20100101 Firefox/125.0",
6 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_4_1) AppleWebKit/605.1.15 Safari/17.4.1",
7 # Añade 5-10 cadenas más recientes
8]Capa 4: rotación de proxies
A cualquier volumen real, necesitas proxies residenciales. Los proxies de datacenter y los gratuitos no funcionan en Yelp — su capa de reputación de IP bloquea por adelantado rangos de AWS, GCP y DigitalOcean.
| Proveedor | Precio inicial $/GB | Notas |
|---|---|---|
| IPRoyal | $1.75/GB | El más barato; ejecuta el tutorial de Yelp más citado |
| Decodo (antes Smartproxy) | $3.20–$3.50 | La mejor relación GB/precio en volumen |
| Bright Data | $4.00 (PAYG) | Pool de más de 150M IPs; página dedicada de Yelp Proxies |
| Oxylabs | $6.00–$8.00 | Premium; más de 10M IPs |
| Aluvia (SIM móvil) | $3.00 | IPs móviles reales de operadores de EE. UU., pensado para Yelp |
Los residenciales rotativos (una IP nueva por petición) funcionan mejor para rastreos masivos de búsquedas. Las sesiones persistentes (mantener una IP durante 10 minutos) son mejores cuando necesitas conservar cookies a lo largo de un flujo página de negocio → reseñas → paginación.
Capa 5: detectar y manejar bloqueos
No todos los bloqueos se ven igual. A menudo Yelp sirve una envoltura genérica de "página no disponible" en lugar de un CAPTCHA, por eso los scrapers ingenuos creen que reciben datos cuando en realidad están obteniendo respuestas vacías.
1BLOCK_MARKERS = (
2 "captcha", "px-captcha", "page not available",
3 "access denied", "unusual traffic",
4)
5def is_blocked(resp):
6 if resp.status_code in (401, 403, 429, 503):
7 return True
8 body = resp.text.lower()
9 if any(m in body for m in BLOCK_MARKERS):
10 return True
11 # Si es una página de búsqueda/negocio pero falta react-root-props,
12 # Yelp entregó una respuesta de bloqueo recortada
13 if "react-root-props" not in body and "/biz/" in str(resp.url):
14 return True
15 return False| Señal | Significado |
|---|---|
| HTTP 403 | Bloqueo duro — IP/cabeceras/TLS quemados |
| HTTP 429 | Límite de ritmo — suele poder recuperarse con backoff |
| HTTP 503 | Bloqueo genérico o reducción de carga |
Redirección a /error o cuerpo "page not available" | Bloqueo suave |
| vacío con solo | Página de desafío esperando JS |
captcha / g-recaptcha / px-captcha en el cuerpo | Escalada — se requiere CAPTCHA |
Falta react-root-props en una página de listado | Respuesta de bloqueo recortada |
Capa 6: el truco de análisis resistente — JSON oculto en lugar de selectores CSS
Conviene repetirlo: Yelp randomiza los nombres de las clases CSS en cada compilación. Un scraper anclado a h3.y-css-14xwok2 se romperá en pocas semanas cuando Yelp vuelva a desplegar con h3.y-css-hcq7b9.
Los payloads que no cambian son:
<script type="application/ld+json">— datos estructurados schema.org (nombre, dirección, teléfono, valoración, horarios)<script data-id="react-root-props">— todos los resultados de búsqueda como JSONhttps://www.yelp.com/gql/batch— endpoint GraphQL de reseñas condocumentIdestable
Si estás analizando clases CSS, estás construyendo sobre arena. Analiza el JSON en su lugar.
Capa 7: plan B con navegador sigiloso
Pasa a un navegador headless solo cuando curl_cffi + proxies residenciales no consigan pasar — normalmente cuando Yelp sirve una página de desafío JS o un CAPTCHA.
Para el 95% del scraping de negocios/búsquedas/reseñas, curl_cffi + JSON oculto + proxies residenciales es más rápido, barato y fiable que un navegador. Pero cuando de verdad necesites navegador:
| Herramienta | Estado (2025) | Notas |
|---|---|---|
| rebrowser-playwright | Punto de partida recomendado | Fork de Playwright con parches para corregir fugas de CDP |
| nodriver | Lo mejor para sigilo en Chrome | Sucesor de undetected-chromedriver; evita por completo el protocolo WebDriver |
| patchright | Fork de Playwright con mantenimiento activo | Supera pruebas modernas de detección |
| playwright-stealth | Madura | Corrige navigator.webdriver y elimina HeadlessChrome del UA |
Evita Selenium puro para Yelp. Se detecta demasiado fácil.
API Yelp Fusion vs. scraping con Python vs. Thunderbit: comparación completa
| Dimensión | API Yelp Fusion | Scraping con Python | Thunderbit |
|---|---|---|---|
| Texto completo de reseñas | ❌ 3 fragmentos × ~160 caracteres | ✅ Ilimitado (GraphQL) | ✅ Plantilla de reseñas integrada |
| Metadatos de reseñas (votos, respuestas del propietario) | ❌ | ✅ | ✅ Mediante campos sugeridos por IA |
| Fotos | ❌ (0 en Base) | ✅ Ilimitadas | ✅ |
| Máximo de resultados por búsqueda | 240 (eran 1.000 antes de 2024) | Ilimitado (paginado) | Ilimitado |
| Límite diario | 300–500 (nuevos) / 5.000 (heredados) | Solo tu presupuesto de proxies | Basado en créditos (3.000/mes en Pro) |
| Esfuerzo de configuración | ~15 min | Horas o días | ~2 minutos |
| Gestión anti-bot | N/A | Tu problema | Gestionada (modo Cloud) |
| Riesgo legal | Bajo (autorizado) | Medio (zona gris de ToS) | Medio (igual que el scraping) |
| Coste de entrada | $29/mes | ~ $0,75–$4/GB en proxies + tiempo de desarrollo | Plan gratis |
| Coste con uso intensivo | $643+/mes | $50–$500/mes en proxies + tiempo de desarrollo | $38–$49/mes |
| Exportación de datos | JSON | CSV/JSON (lo programas tú) | Excel / Sheets / Airtable / Notion — gratis |
| Mantenimiento | Bajo | Alto (los selectores se rompen, la defensa anti-bot se endurece) | Bajo (la IA se reajusta) |
Consejos legales y éticos para extraer Yelp
No soy abogado, y esto no es asesoramiento legal. Pero el panorama legal ha cambiado lo suficiente en los últimos dos años como para que convenga conocer lo básico antes de invertir tiempo en un proyecto de scraping de Yelp.
Qué dicen los Términos de Servicio de Yelp: la prohíbe expresamente usar "cualquier robot, spider... u otro dispositivo automatizado" para "acceder, recuperar, copiar, extraer o indexar cualquier parte del Servicio". También añadió lenguaje sobre "AI Technologies y/o otras herramientas automatizadas".
: "Yelp no permite ningún tipo de scraping del sitio".
Qué dice robots.txt: el de Yelp tiene un comodín User-agent: * / Disallow: / y además bloquea específicamente GPTBot, ClaudeBot, PerplexityBot, CCBot y Meta-ExternalAgent. Solo Googlebot, Bingbot y algunos rastreadores de redes sociales están permitidos.
El precedente legal que importa: en (N.D. Cal. enero de 2024), el tribunal dictaminó que extraer datos públicos y cerrados a sesión no violaba los Términos de Servicio de Meta. La distinción clave: datos públicos sin iniciar sesión vs. datos con sesión iniciada. El caso estableció que el scraping de datos públicos probablemente no viola la CFAA, pero hiQ aún perdió en reclamaciones de derecho estatal (trespass to chattels, misappropriation) y recibió una sentencia de $500.000.
Pautas prácticas:
- Extrae solo páginas públicas, sin iniciar sesión
- Limita la velocidad de tus peticiones (los retrasos de esta guía sirven también como límites éticos)
- No revendas texto bruto de reseñas atribuido a usuarios con nombre — respeta la privacidad de los revisores
- Cumple las leyes locales de protección de datos (CCPA, GDPR)
- No te autentiques para hacer scraping — eso cruza la línea de autorización
- Trata la información del negocio (nombre/dirección/teléfono/valoración) como datos fácticos públicos; trata el texto de las reseñas como algo más sensible
Consulta a un profesional legal para tu caso concreto.
Cierre
Tres caminos, un mismo objetivo.
La API Yelp Fusion es la opción autorizada y de bajo mantenimiento — pero se limita a 3 fragmentos de reseña y parte de $29/mes. El scraping con Python te da control total sobre cada dato de Yelp, pero exige una inversión real: curl_cffi para suplantación de huella TLS, proxies residenciales, retrasos aleatorios, análisis de JSON oculto y mantenimiento continuo a medida que evolucionan las defensas de Yelp. Thunderbit te lleva de "necesito datos de Yelp" a "aquí está mi hoja de cálculo" en unos 30 segundos, sin código y sin configurar proxies.
Lo esencial para evitar bloqueos que sí funciona en 2025: cabeceras realistas con Client Hints completos, curl_cffi para suplantar la huella TLS, retrasos aleatorios con backoff exponencial, rotación de proxies residenciales y, sobre todo, analizar JSON oculto (application/ld+json y react-root-props) en lugar de selectores CSS frágiles.
¿No sabes qué ruta encaja mejor? Prueba primero el . Si cubre lo que necesitas, te habrás ahorrado horas. Si necesitas más control — pipelines programáticos completos, campos personalizados, integración estrecha con tu CRM — la guía de Python anterior te cubre. Y para una visión más amplia del panorama de herramientas de scraping, consulta nuestro resumen de las o nuestra guía para .
Preguntas frecuentes
¿Puedo extraer Yelp gratis con Python?
Sí — usando librerías gratuitas como curl_cffi, parsel y jmespath. Pero a cualquier volumen real (más de unas pocas decenas de páginas), necesitarás proxies residenciales de pago, que empiezan en torno a . Thunderbit también ofrece un plan gratis con 6 páginas al mes para extracción rápida sin código.
¿Yelp bloquea a los scrapers?
Sí, y de forma agresiva. Yelp usa . requests puro queda bloqueado en el primer intento. La estrategia por capas de esta guía — curl_cffi para suplantar la huella TLS, cabeceras realistas, retrasos aleatorios y proxies residenciales — es la que funciona en 2025.
¿La API Yelp Fusion es mejor que hacer scraping?
Depende de lo que necesites. La API está autorizada y tiene bajo riesgo, pero solo devuelve , limita los resultados de búsqueda a 240 y parte de $29/mes. Si necesitas texto completo de las reseñas, metadatos o más de unos pocos cientos de registros al día, el scraping es la única opción.
¿Cómo extraigo reseñas de Yelp con Python?
Usa curl_cffi con impersonate="chrome131" para obtener la página del negocio, extrae el ID codificado del negocio desde <meta name="yelp-biz-id"> y luego haz un POST a https://www.yelp.com/gql/batch con la operación GetBusinessReviewFeed, paginando mediante un cursor after codificado en base64. El código paso a paso está en la sección del tutorial de arriba. El también es una buena referencia.
¿Puedo extraer Yelp sin programar?
Sí — incluye plantillas preconstruidas de y . Abre una página de Yelp, haz clic en AI Suggest Fields y luego en Scrape. Las exportaciones a Google Sheets, Excel, Airtable y Notion son gratis en todos los planes, incluido el gratuito.
Más información