Walmart cambia los precios de algunos artículos . Si alguna vez has intentado hacer ese seguimiento de forma programática, ya sabes lo frustrante que puede ser: tu script funciona durante 20 minutos y luego, sin avisar, empieza a devolver páginas CAPTCHA disfrazadas de respuestas normales 200 OK.
He dedicado mucho tiempo a trabajar en las defensas antibots de Walmart como parte de nuestro trabajo de extracción de datos en , y quiero compartir todo lo que he aprendido: los métodos que de verdad funcionan en 2025, los fallos silenciosos que contaminan tus datos y las comparaciones honestas entre escribir tu propio scraper, pagar por una API de scraping o simplemente usar una herramienta sin código. Esta guía cubre tres métodos de extracción (análisis de HTML, JSON de __NEXT_DATA__ e interceptación de API interna), manejo de errores listo para producción que la mayoría de los tutoriales omiten por completo y un marco de decisión claro para elegir el enfoque correcto. Aquí hay algo útil tanto si programas en Python como si solo quieres una hoja de cálculo llena de precios para la hora de comer.
¿Por qué extraer datos de Walmart con Python?
Walmart es el minorista más grande del mundo por ingresos: en el ejercicio fiscal 2025, y ha ocupado el . El sitio alberga aproximadamente , y el director financiero de Walmart ha hablado de en el marketplace. Alrededor del , lo que hace que el catálogo sea muy volátil: los vendedores cambian, las variantes se modifican y el stock fluctúa a diario.
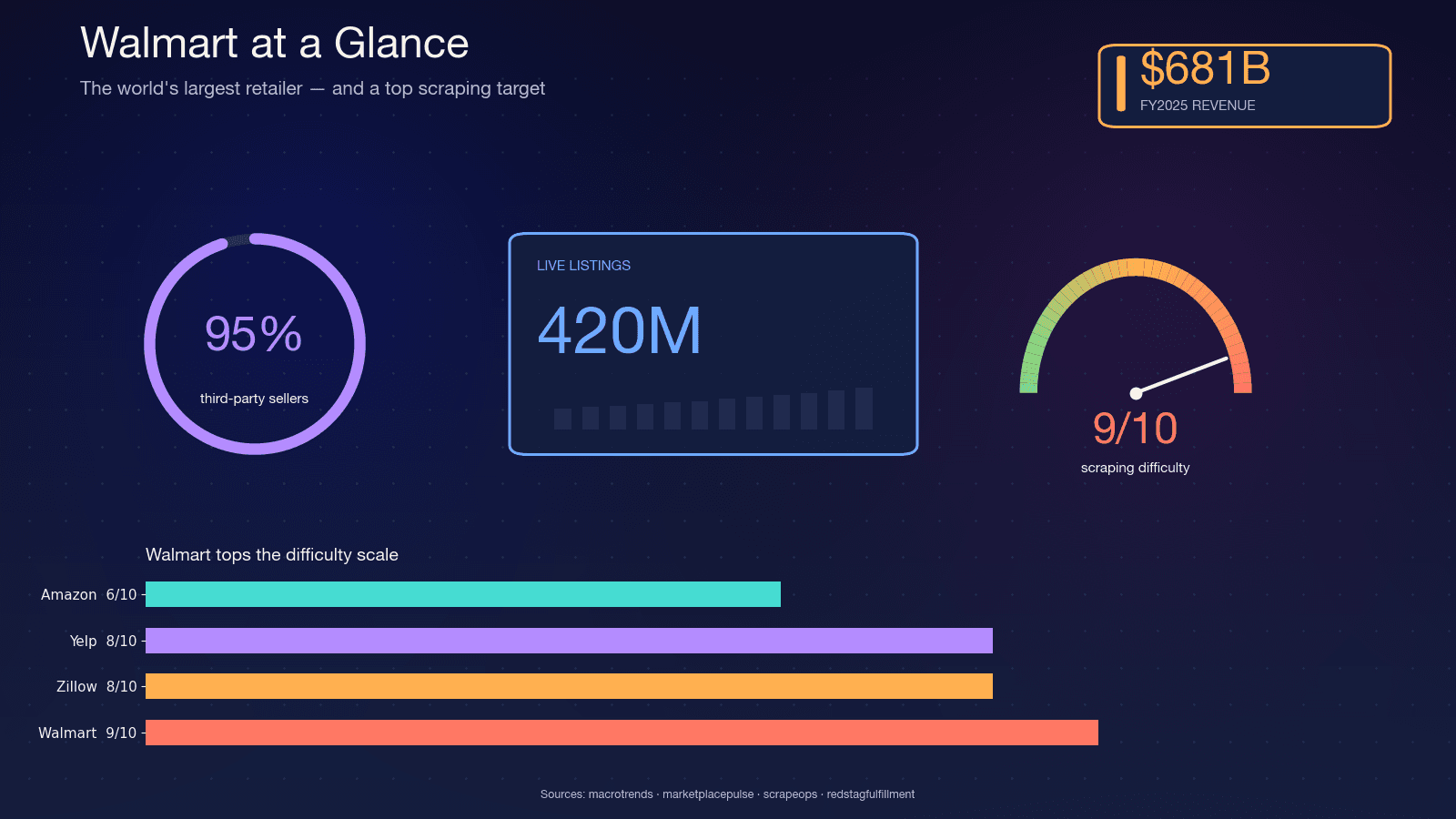
Esa volatilidad es precisamente por lo que el scraping importa. Un informe trimestral no puede captar lo que sí ve un scraping nocturno. Estos son los casos de uso más comunes que veo:
| Caso de uso | Quién lo necesita | Qué extraen |
|---|---|---|
| Monitoreo de precios de la competencia | Operaciones de e-commerce, herramientas de repricing | Precios, promociones, cumplimiento de MAP |
| Enriquecimiento de catálogos de productos | Equipos de ventas y merchandising | Descripciones, imágenes, especificaciones, variantes |
| Seguimiento de disponibilidad de stock | Cadena de suministro, dropshippers | Estado de inventario, información del vendedor |
| Investigación de mercado y análisis de tendencias | Marketing, gestores de producto | Valoraciones, reseñas, surtido por categoría |
| Generación de leads | Equipos de ventas | Nombres de vendedores, cantidad de productos, categorías |
El mercado de software de monitoreo de precios de la competencia por sí solo alcanzó y se prevé que llegue a 5.09 mil millones para 2033. El comportamiento del consumidor impulsa ese gasto: , y el 83 % compara en varios sitios.
Python es el lenguaje por defecto para este trabajo. El Infrastructure Report 2026 de Apify estima que , y la librería principal (requests) recibe . Si haces scraping a cualquier escala, casi seguro lo harás en Python.
Por qué Walmart es uno de los sitios más difíciles de extraer
Walmart es especialmente difícil porque ejecuta dos productos comerciales antibots en serie: , como capa perimetral de WAF y fingerprinting TLS, y , como capa de desafíos JavaScript basados en comportamiento. Scrape.do llama a esta combinación “rara y extremadamente difícil de eludir”.
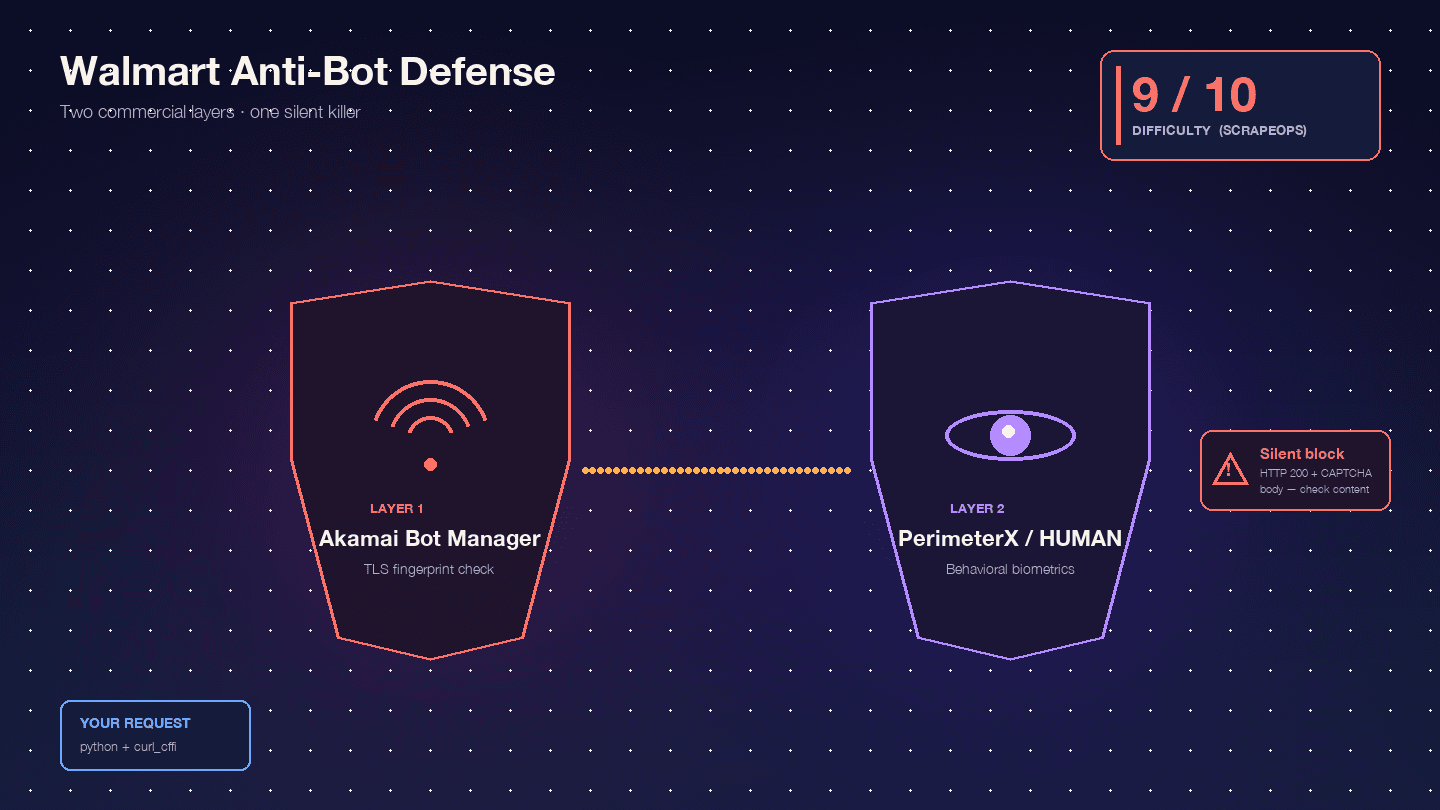
, y solo Akamai ya recibe 9/10. Por experiencia, esa valoración es bastante acertada.
Esto es a lo que te enfrentas realmente:
Akamai Bot Manager inspecciona tu huella TLS (hash JA3/JA4), el orden de los frames HTTP/2, el orden y el uso de mayúsculas en las cabeceras, y las cookies de sesión (_abck, ak_bmsc). Una llamada estándar de Python requests emite una huella TLS que ningún navegador real produce: Akamai la detecta antes de que tu solicitud siquiera llegue a los servidores de Walmart.
PerimeterX/HUMAN actúa después de Akamai, ejecutando fingerprinting JavaScript (px.js) que comprueba propiedades de navigator, renderizado canvas, WebGL, contexto de audio y biometría de comportamiento (movimiento del ratón, velocidad de desplazamiento, dinámica de pulsaciones). El fallo visible es el infame desafío : un botón que debes mantener pulsado unos 10 segundos mientras se muestrean señales de comportamiento. Oxylabs lo dice sin rodeos: “Walmart usa el modelo CAPTCHA ‘Press & Hold’, ofrecido por PerimeterX, y se sabe que es casi imposible resolverlo desde tu código”.
El comportamiento realmente peligroso es el bloqueo silencioso. Walmart devuelve HTTP 200 con un cuerpo CAPTCHA en lugar de un 403. : “Walmart devuelve un código de estado 200 OK incluso cuando sirve una página CAPTCHA. No puedes depender solo del código de estado para saber si tu solicitud tuvo éxito”. Tu script analiza tranquilamente el HTML del CAPTCHA como si fuera “producto no encontrado” y sigue adelante. La mitad de tu dataset es basura, y ni siquiera lo sabes.
Luego está el problema de los datos por tienda. Los precios y el inventario de Walmart dependen de la ubicación y están controlados por cookies como locDataV3 y assortmentStoreId. Sin las cookies correctas, obtienes datos “nacionales por defecto” que pueden parecer completos, pero no coinciden con lo que ve un comprador real. Las cookies que faltan no producen una página de bloqueo: producen datos incorrectos sin fallo visible, lo cual es peor.
Tres métodos para extraer datos de Walmart (y cómo se comparan)
Antes de entrar paso a paso, aquí tienes los tres enfoques principales de extracción. La mayoría de los tutoriales de la competencia solo cubren uno o dos. Voy a repasar los tres para que puedas elegir el que mejor se adapte a tu caso.
| Método | Fiabilidad | Completitud de datos | Dificultad antibot | Carga de mantenimiento |
|---|---|---|---|---|
| HTML + BeautifulSoup | ⚠️ Baja (los selectores se rompen en cada despliegue) | Moderada | Alta | Alta |
JSON de __NEXT_DATA__ | ✅ Buena | Alta | Media-alta | Media |
| Interceptación de API interna | ✅ La mejor | Máxima (variantes, stock, reseñas) | Media-alta | Baja (JSON estructurado) |
| Thunderbit (sin código) | ✅ Buena | Alta | Baja (gestionada por IA) | Ninguna |
El análisis de HTML es la peor opción para Walmart: el sitio usa paquetes de Next.js con nombres de clase CSS con hash que cambian en cada despliegue. El método JSON de __NEXT_DATA__ es la elección pragmática que usan todos los scrapers serios de Walmart de código abierto entre 2024 y 2026. La interceptación de API interna es la más potente, pero trae matices que la mayoría de los tutoriales pasan por alto. Y Thunderbit es la opción correcta cuando no necesitas un pipeline personalizado en absoluto.
Configurar tu entorno de Python para extraer datos de Walmart
Esto es lo que necesitas:
- Dificultad: Intermedia
- Tiempo necesario: unos 30 minutos de preparación, más el tiempo de programación
- Qué necesitarás: Python 3.10 o superior, pip, un editor de código y, para uso en producción, un servicio de proxies o una API de scraping
Crea la carpeta del proyecto y el entorno virtual:
1mkdir walmart-scraper && cd walmart-scraper
2python -m venv venv
3source venv/bin/activate # En Windows: venv\Scripts\activateInstala las librerías necesarias:
1pip install curl_cffi parsel beautifulsoup4 lxmlcurl_cffi es el estándar de 2025 para extraer datos de objetivos difíciles. Es un binding de libcurl que puede imitar con exactitud las huellas TLS de un navegador. : “Walmart usa fingerprinting TLS como parte de su detección de bots, e incluso establecer el User-Agent para simular un navegador real no lo evitará”. Ni requests ni httpx puros pueden superar Akamai sin importar qué cabeceras establezcas. curl_cffi con impersonate="chrome124" es lo que marca la diferencia.
También te conviene usar json (incluido en la biblioteca estándar), csv (incluido), time, random y logging para los patrones de producción que veremos más adelante.
Paso a paso: extraer páginas de productos de Walmart con Python
Paso 1: obtener la página de producto de Walmart
Tu primera tarea es hacer una solicitud HTTP que no sea bloqueada de inmediato. Esta es la cabecera canónica que usan Scrapfly, Scrapingdog, Oxylabs y ScrapeOps en 2024–2026:
1from curl_cffi import requests
2HEADERS = {
3 "User-Agent": (
4 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
5 "AppleWebKit/537.36 (KHTML, like Gecko) "
6 "Chrome/124.0.0.0 Safari/537.36"
7 ),
8 "Accept": (
9 "text/html,application/xhtml+xml,application/xml;q=0.9,"
10 "image/avif,image/webp,*/*;q=0.8"
11 ),
12 "Accept-Language": "en-US,en;q=0.9",
13 "Accept-Encoding": "gzip, deflate, br",
14 "Upgrade-Insecure-Requests": "1",
15 "Sec-Fetch-Dest": "document",
16 "Sec-Fetch-Mode": "navigate",
17 "Sec-Fetch-Site": "none",
18 "Sec-Fetch-User": "?1",
19 "Referer": "https://www.google.com/",
20}
21session = requests.Session(impersonate="chrome124")
22url = "https://www.walmart.com/ip/Apple-AirPods-Pro-2nd-Generation/1752657021"
23response = session.get(url, headers=HEADERS)El parámetro impersonate="chrome124" es lo que hace el trabajo pesado aquí. Le dice a curl_cffi que coincida con el ClientHello TLS exacto de Chrome 124, el orden de los frames HTTP/2 y la secuencia de pseudoencabezados. Sin eso, Akamai ve un hash JA3 específico de Python y te bloquea antes de que tu solicitud siquiera llegue a la capa de aplicación de Walmart.
Cómo se ve una respuesta bloqueada: si ves "Robot or human?" en el título HTML de la respuesta, o si la respuesta redirige a walmart.com/blocked, te han detectado. La parte complicada es que Walmart suele devolver un código 200 con el cuerpo CAPTCHA, así que comprobar solo response.ok no basta.
Para cualquier uso repetido o en producción, necesitarás proxies residenciales. Las IP de centros de datos se queman enseguida por el sistema de reputación de IP de Akamai. Cubriré la estrategia completa de manejo de errores y proxies en la sección de producción más abajo.
Paso 2: analizar datos del producto desde el JSON de __NEXT_DATA__
Walmart.com es una aplicación de Next.js, y el HTML renderizado en el servidor incrusta el payload completo de hidratación dentro de una sola etiqueta script: <script id="__NEXT_DATA__" type="application/json">. Esa es la mina de oro.
: “En 2026, Walmart usa Next.js con JSON estructurado en etiquetas script de __NEXT_DATA__, lo que hace que la extracción de datos ocultos sea más fiable que el análisis tradicional con selectores CSS”. Todos los scrapers de Walmart de código abierto de alto perfil — , , — usan este método.
Así es como se extrae:
1import json
2from parsel import Selector
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6product = data["props"]["pageProps"]["initialData"]["data"]["product"]
7idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})La mayoría de los tutoriales se quedan aquí. A continuación tienes un mapa completo de rutas JSON de los campos que realmente te importan, verificado con páginas reales de Walmart entre 2024 y 2026:
| Campo de datos | Ruta JSON (dentro de initialData) | Tipo | Notas |
|---|---|---|---|
| Nombre del producto | data > product > name | Cadena | — |
| Marca | data > product > brand | Cadena | — |
| Precio actual (número) | data > product > priceInfo > currentPrice > price | Flotante | Puede variar según la cookie de tienda |
| Precio actual (cadena) | data > product > priceInfo > currentPrice > priceString | Cadena | Formato, por ejemplo "$9.99" |
| Descripción corta | data > product > shortDescription | Cadena HTML | Analizar con BeautifulSoup para obtener texto |
| Descripción larga | data > idml > longDescription | Cadena HTML | Vive en idml, NO dentro de product — esta es la trampa que los tutoriales antiguos suelen interpretar mal |
| Todas las imágenes | data > product > imageInfo > allImages | Array | Lista de objetos {id, url} |
| Valoración media | data > product > averageRating | Flotante | La clave es averageRating, no el antiguo rating |
| Número de reseñas | data > product > numberOfReviews | Entero | — |
| Variantes | data > product > variantCriteria | Array | Grupos de opciones (talla, color) |
| Disponibilidad | data > product > availabilityStatus | Cadena | IN_STOCK, OUT_OF_STOCK, LIMITED_STOCK |
| Vendedor | data > product > sellerDisplayName | Cadena | — |
| Fabricante | data > product > manufacturerName | Cadena | — |
La ruta longDescription es la trampa que más gente hace caer. Una publicación de ScrapeHero de 2023 la colocaba en product.longDescription, pero las fuentes de 2024 en adelante la sitúan de forma consistente en la clave hermana idml. Lee siempre primero idml.longDescription y recurre a product.longDescription solo para páginas antiguas.
Aquí está el patrón de extracción seguro usando cadenas .get():
1def extract_product(data):
2 product = data["props"]["pageProps"]["initialData"]["data"]["product"]
3 idml = data["props"]["pageProps"]["initialData"]["data"].get("idml", {})
4 price_info = product.get("priceInfo", {})
5 current_price = price_info.get("currentPrice", {})
6 image_info = product.get("imageInfo", {})
7 return {
8 "name": product.get("name"),
9 "brand": product.get("brand"),
10 "price": current_price.get("price"),
11 "price_string": current_price.get("priceString"),
12 "short_desc": product.get("shortDescription"),
13 "long_desc": idml.get("longDescription", product.get("longDescription")),
14 "images": [img.get("url") for img in image_info.get("allImages", [])],
15 "rating": product.get("averageRating"),
16 "review_count": product.get("numberOfReviews"),
17 "variants": product.get("variantCriteria"),
18 "availability": product.get("availabilityStatus"),
19 "seller": product.get("sellerDisplayName"),
20 "manufacturer": product.get("manufacturerName"),
21 }Para quienes no quieren lidiar en absoluto con la navegación por rutas JSON, la identifica y estructura automáticamente estos campos: no hace falta mapear rutas manualmente. Haces clic en “Sugerir campos con IA”, lee la página y obtienes una tabla. Pero si estás construyendo un pipeline personalizado, el mapa anterior es tu referencia.
Paso 3: interceptar los endpoints de la API interna de Walmart para obtener datos más ricos
Ningún artículo de la competencia cubre bien este método. Es el camino de extracción más potente, y también el más complejo.
El frontend de Walmart llama a un . Los endpoints viven bajo www.walmart.com/orchestra/*:
/orchestra/pdp/graphql/...— hidratación de detalles del producto + cambios de variantes/orchestra/snb/graphql/...— paginación de búsqueda y exploración/orchestra/reviews/graphql/...— reseñas paginadas
Devuelven JSON limpio y estructurado con datos que __NEXT_DATA__ a veces recorta: precios por variante, recuentos de stock en tiempo real y paginación completa de reseñas.
La trampa que los artículos de blog esquivan: Walmart usa . El cuerpo de la solicitud envía solo un hash SHA-256 (persistedQuery.sha256Hash), no el texto de la consulta. Si el hash no existe en el servidor, obtienes PersistedQueryNotFound. Walmart rota estos hashes en cada despliegue. Por eso ninguno de los scrapers de Walmart de código abierto más conocidos publica código copiablle y pegable para /orchestra/.
La versión práctica y honesta de este método consiste en trabajar con DevTools:
- Abre una página de producto de Walmart en Chrome
- Abre DevTools → pestaña Network, filtra por “Fetch/XHR”
- Navega por la página con normalidad: haz clic en variantes, desplázate hasta las reseñas, cambia la ubicación de la tienda
- Busca solicitudes a endpoints
/orchestra/*que devuelvan JSON con datos del producto - Haz clic derecho en la solicitud → “Copy as cURL”
- Convierte el comando cURL a Python usando
curl_cffi
Así luce una llamada a la API reproducida:
1import json
2from curl_cffi import requests
3session = requests.Session(impersonate="chrome124")
4# Primero, calienta la sesión visitando la página del producto
5session.get("https://www.walmart.com/ip/some-product/1234567", headers=HEADERS)
6# Luego reproduce la llamada a la API interna (copiada desde DevTools)
7api_url = "https://www.walmart.com/orchestra/pdp/graphql"
8api_headers = {
9 **HEADERS,
10 "accept": "application/json",
11 "content-type": "application/json",
12 "referer": "https://www.walmart.com/ip/some-product/1234567",
13 "wm_qos.correlation_id": "your-copied-correlation-id",
14}
15payload = {
16 # Pega aquí el cuerpo exacto de la solicitud desde DevTools
17 "variables": {"productId": "1234567"},
18 "extensions": {
19 "persistedQuery": {
20 "version": 1,
21 "sha256Hash": "the-hash-you-copied"
22 }
23 }
24}
25api_response = session.post(api_url, headers=api_headers, json=payload)
26api_data = api_response.json()El paso de calentar la sesión es fundamental. Las cookies PerimeterX de Walmart (_px3, _pxhd, ACID) deben establecerse con la primera solicitud HTML antes de que la llamada a la API funcione. Sin ellas, obtendrás un 412 o un 403.
Cuándo usar este método: cuando necesitas datos que __NEXT_DATA__ no incluye — precios profundos por variante, reseñas paginadas más allá del primer lote o recuentos de inventario en tiempo real. Para la mayoría de los casos, __NEXT_DATA__ es suficiente y mucho más sencillo.
Extraer resultados de búsqueda de Walmart y varias páginas
Los resultados de búsqueda siguen un patrón similar de __NEXT_DATA__, pero con una ruta JSON distinta:
1search_url = "https://www.walmart.com/search?q=laptops&page=1"
2response = session.get(search_url, headers=HEADERS)
3sel = Selector(text=response.text)
4raw = sel.xpath('//script[@id="__NEXT_DATA__"]/text()').get()
5data = json.loads(raw)
6search_result = data["props"]["pageProps"]["initialData"]["searchResult"]
7items = search_result["itemStacks"][0]["items"]
8# Filtra los productos patrocinados
9organic_items = [i for i in items if i.get("__typename") == "Product"]
10for item in organic_items:
11 print(item.get("name"), item.get("priceInfo", {}).get("currentPrice", {}).get("price"))La paginación funciona incrementando el parámetro page: &page=1, &page=2, etc. Pero aquí está el límite no documentado: Walmart limita los resultados de búsqueda a 25 páginas, independientemente del total real. : “Walmart establece en 25 el número máximo de páginas de resultados a las que se puede acceder, independientemente del número total de páginas disponibles”.
Formas de conseguir una cobertura más amplia:
- Alternar el orden de clasificación: ejecuta la misma consulta con
&sort=price_lowy luego con&sort=price_highpara obtener unas 50 páginas de cobertura - Dividir por rango de precios: añade
&min_price=X&max_price=Ypara partir el catálogo en ventanas más pequeñas - Dividir por categoría: busca dentro de categorías específicas en lugar de hacerlo en todo el sitio
Ten en cuenta que itemStacks es un array. Scrapfly fija [0] en su repositorio, pero las páginas de categoría y exploración a veces contienen varias pilas (“Top picks”, “More results”). El patrón robusto itera por todas las pilas:
1for stack in search_result.get("itemStacks", []):
2 for item in stack.get("items", []):
3 if item.get("__typename") == "Product":
4 # procesar el elemento
5 passTambién conviene señalar que el robots.txt de Walmart . Las páginas de detalle de producto (/ip/...) y la mayoría de las páginas de categoría (/cp/...) no están bloqueadas. Si te preocupa el cumplimiento, empieza por las páginas de producto y los árboles de categorías en lugar de la búsqueda.
No dejes que los bloqueos silenciosos arruinen tus datos: manejo de errores listo para producción
La mayoría de los tutoriales se desmoronan aquí. Te enseñan a obtener una página, analizar un producto y dar el día por terminado. En producción, estás obteniendo miles de páginas, y Walmart intenta activamente detenerte. La diferencia entre un scraper de demostración y uno que realmente funciona está en cómo maneja los fallos.
Detecta los bloqueos silenciosos antes de que corrompan tus datos
La función más importante de un scraper de Walmart es el detector de bloqueos. Basándose en el consenso de proveedores como , , y , necesitas cuatro comprobaciones independientes:
1BLOCK_MARKERS = (
2 "Robot or human",
3 "Press & Hold",
4 "Press & Hold",
5 "px-captcha",
6 "perimeterx",
7)
8def is_walmart_blocked(response) -> bool:
9 # 1. Redirección al endpoint de bloqueo dedicado
10 if "/blocked" in str(response.url):
11 return True
12 # 2. Códigos de estado duros
13 if response.status_code in (403, 412, 428, 429, 503):
14 return True
15 # 3. 200 OK con cuerpo CAPTCHA (el caso de bloqueo silencioso)
16 body = response.text or ""
17 if any(m.lower() in body.lower() for m in BLOCK_MARKERS):
18 return True
19 # 4. Sanidad por longitud de respuesta: los PDP reales pesan entre 300 y 900 KB
20 if len(response.content) < 50_000 and "/ip/" in str(response.url):
21 return True
22 return FalseLa cuarta comprobación —la longitud de la respuesta— detecta los casos en que Walmart devuelve una página reducida que no contiene marcadores obvios de CAPTCHA, pero tampoco contiene los datos del producto que necesitas.
Lógica de reintento con backoff exponencial y jitter
Cuando una solicitud falla, no quieres bombardear Walmart de inmediato. El patrón estándar usa backoff exponencial con jitter para desincronizar los reintentos:
1import time
2import random
3import logging
4from curl_cffi import requests as cffi_requests
5log = logging.getLogger("walmart")
6def fetch_with_retry(session, url, max_retries=5, base_delay=2, max_delay=60):
7 for attempt in range(max_retries):
8 try:
9 response = session.get(url, headers=HEADERS, timeout=15)
10 if response.status_code in (429, 503):
11 raise Exception(f"Limitado: \{response.status_code\}")
12 if is_walmart_blocked(response):
13 raise Exception("Se detectó un bloqueo silencioso")
14 return response
15 except Exception as e:
16 if attempt == max_retries - 1:
17 raise
18 wait = min(max_delay, base_delay * (2 ** attempt)) + random.uniform(0, 3)
19 log.warning(f"El intento {attempt + 1} falló: \{e\}. Reintentando en {wait:.1f}s")
20 time.sleep(wait)
21 return NoneEl jitter (random.uniform(0, 3)) no es decorativo: desincroniza a los workers para que una flota de scrapers no vuelva a intentar todos en el mismo segundo y active los detectores de velocidad de Akamai.
Limitación de ritmo
Tanto como convergen en un retraso aleatorio de 3 a 6 segundos por solicitud para Walmart: “limita el ritmo de tus solicitudes esperando entre 3 y 6 segundos entre cargas de página y aleatoriza tus retrasos”.
1import time
2import random
3def rate_limited_fetch(session, url):
4 response = fetch_with_retry(session, url)
5 time.sleep(random.uniform(3.0, 6.0))
6 return responseA escala, considera usar aiolimiter para limitar el ritmo de forma asíncrona:
1from aiolimiter import AsyncLimiter
2limiter = AsyncLimiter(max_rate=10, time_period=60) # 10 solicitudes por minutoValidación de datos
Incluso cuando la respuesta no está bloqueada, los datos analizados podrían ser incorrectos (tienda equivocada, payload degradado). Valida antes de escribir el resultado:
1def validate_product(product):
2 """Devuelve True si los datos del producto parecen legítimos."""
3 if not product.get("name"):
4 return False
5 price = (product.get("priceInfo") or {}).get("currentPrice", {}).get("price")
6 if not isinstance(price, (int, float)) or price <= 0:
7 return False
8 if product.get("availabilityStatus") not in ("IN_STOCK", "OUT_OF_STOCK", "LIMITED_STOCK"):
9 return False
10 return TrueRegistro de sesión
Haz seguimiento de tu tasa de éxito por sesión. Cuando baje del 80 % durante 10 minutos, algo ha cambiado: o tu IP está quemada, o tus cookies expiraron, o Walmart desplegó una nueva regla antibots.
1class ScrapeMetrics:
2 def __init__(self):
3 self.total = 0
4 self.success = 0
5 self.blocks = 0
6 self.errors = 0
7 def record(self, result):
8 self.total += 1
9 if result == "success":
10 self.success += 1
11 elif result == "blocked":
12 self.blocks += 1
13 else:
14 self.errors += 1
15 @property
16 def success_rate(self):
17 return (self.success / self.total * 100) if self.total > 0 else 0
18 def check_health(self):
19 if self.total > 20 and self.success_rate < 80:
20 log.critical(f"La tasa de éxito bajó a {self.success_rate:.1f}% — considera rotar proxies o pausar")No es glamuroso. Pero es lo que mantiene limpios tus datos.
Python casero vs. API de scraping vs. sin código: cómo elegir el enfoque correcto para extraer Walmart
Muchos desarrolladores se lanzan directamente a escribir un scraper personalizado sin preguntarse si esa es la decisión correcta. . En los foros lo describen como “básicamente 9/10” y se preguntan “si una API dedicada de web scraping sería demasiado”. La respuesta depende del volumen, el presupuesto y la capacidad de ingeniería.
| Factor | Python casero (requests + proxies) | API de scraping (Oxylabs, Bright Data, etc.) | Herramienta sin código (Thunderbit) |
|---|---|---|---|
| Tiempo de configuración hasta la primera fila | Horas | 15–60 min | ~2 min |
| Tiempo de configuración hasta producción | 40–80 h | 4–16 h | ~30 min |
| Gestión antibot | La gestionas tú (difícil) | La gestiona el proveedor | La gestiona automáticamente |
| Coste a pequeña escala (<1K páginas/mes) | Bajo (los proxies cuestan aprox. 4–8 USD/GB) | Tiers de entrada de 40–49 USD/mes | Gratis–15 USD/mes |
| Coste a escala (100K+ páginas/mes) | Menor por solicitud | Mayor por solicitud | Varía |
| Personalización | Control total | Parámetros de API | Limitada por la interfaz y los campos |
| Mantenimiento continuo | 4–8 h/mes | Casi nulo | Ninguno (la IA se adapta) |
| Lo mejor para | Desarrolladores que crean pipelines personalizados | Scraping de producción a escala media | Usuarios de negocio, extracciones puntuales rápidas |
Cuándo tiene sentido un Python casero
El enfoque casero gana cuando ya tienes un contrato de proxies, necesitas control estricto sobre cabeceras, geolocalización por código postal o cohortes de vendedores, indexas millones de páginas al mes y las comisiones por registro de la API se acumulan, o necesitas garantías de cumplimiento o despliegue on-premise. El coste real es tiempo de ingeniería: un spider de Scrapy listo para producción con paginación, reintentos, rotación de proxies, impersonación TLS y varios esquemas de tipo de página requiere , más 4–8 horas al mes de mantenimiento cuando Walmart rota las huellas.
Cuándo una API de scraping te ahorra tiempo
Las APIs de scraping se encargan de la capa antibots para que tú no tengas que hacerlo. muestran tasas de éxito del y 98 % para Scrape.do en Walmart. Los precios de entrada rondan los 40–49 USD/mes para herramientas como , y . Si sois un equipo de 2 a 5 ingenieros y vuestro volumen de scraping está entre 10K y 1M páginas al mes, una API casi siempre es la mejor opción. Cambias coste por solicitud por cero mantenimiento.
Cuándo sin código es la opción correcta
encaja en un perfil distinto. Si eres PM, analista u operador de e-commerce y necesitas datos de productos de Walmart en una hoja de cálculo esta misma tarde —no en el próximo sprint—, una herramienta sin código es la respuesta honesta.
El flujo de trabajo: instala la , entra en una página de producto o búsqueda de Walmart, haz clic en “Sugerir campos con IA” y la IA de Thunderbit leerá la página y propondrá columnas (nombre del producto, precio, valoración, etc.). Haz clic en “Extraer” y los datos se rellenarán en una tabla. Exporta a Excel, Google Sheets, Airtable o Notion: todo gratis, sin muro de pago.
Thunderbit gestiona el antibot en la nube, así que no tienes que lidiar con CAPTCHAs, proxies ni fingerprinting TLS. La IA se adapta automáticamente a los cambios de diseño, así que no hay mantenimiento. Para usuarios que no quieren tratar con la navegación por rutas JSON en absoluto, este es el camino de menor resistencia.
Limitaciones honestas: Thunderbit no está diseñado para 100K+ páginas por día. Los presupuestos de créditos y los límites de la nube hacen que la ingesta de gran volumen sea poco económica frente a las APIs en bruto. Tampoco puedes fijar un código postal o ASN específico salvo que la herramienta lo admita. Para pipelines continuos y de gran volumen, el enfoque casero o una API de scraping sigue siendo lo mejor.
Precio orientativo: 1.000 filas de productos de Walmart en Thunderbit cuestan aproximadamente 2.000 créditos (unos 0.60–1.10 USD en los planes Starter/Pro). Eso es comparable a la API de Walmart de Oxylabs y más barato que la mayoría de APIs de scraping para hobby a bajo volumen. para ver los detalles actualizados.
Exportar los datos de Walmart que has extraído
Una vez que tengas los datos, necesitas ponerlos en un lugar útil. Tres formatos cubren la mayoría de las necesidades:
CSV — el formato más básico que los analistas sí abren:
1import csv
2def export_csv(products, filename="walmart_products.csv"):
3 fieldnames = ["name", "price", "availability", "rating", "review_count", "seller", "url"]
4 with open(filename, "w", newline="", encoding="utf-8-sig") as f:
5 writer = csv.DictWriter(f, fieldnames=fieldnames, quoting=csv.QUOTE_MINIMAL)
6 writer.writeheader()
7 for p in products:
8 writer.writerow({k: p.get(k) for k in fieldnames})Usa codificación utf-8-sig para que sea compatible con Excel. El marcador BOM evita que Excel destroce los caracteres especiales.
JSONL — el formato de producción para pipelines de scraping:
1import json
2import gzip
3def export_jsonl(products, filename="walmart_products.jsonl.gz"):
4 with gzip.open(filename, "at", encoding="utf-8") as f:
5 for p in products:
6 f.write(json.dumps(p, ensure_ascii=False) + "\n")(una escritura interrumpida solo pierde la última línea), se puede transmitir con memoria constante y mantiene intactos los datos anidados como variantes y reseñas.
Excel — para entregas puntuales a analistas:
1from openpyxl import Workbook
2def export_excel(products, filename="walmart_products.xlsx"):
3 wb = Workbook(write_only=True)
4 ws = wb.create_sheet("Products")
5 ws.append(["Nombre", "Precio", "Disponibilidad", "Valoración", "Reseñas", "Vendedor"])
6 for p in products:
7 ws.append([p.get("name"), p.get("price"), p.get("availability"),
8 p.get("rating"), p.get("review_count"), p.get("seller")])
9 wb.save(filename)Thunderbit cubre la exportación para usuarios que no programan: exportación con un clic a Google Sheets, Airtable, Notion, Excel, CSV y JSON, todo gratis en el plan básico. Para el monitoreo continuo, la función de scraper programado de Thunderbit puede ejecutar extracciones recurrentes automáticamente.
Una advertencia sobre la programación: . Los runners de GitHub Actions usan rangos de IP de Azure que el antibot de Walmart bloquea al instante. Usa APScheduler en un VPS o enruta todo el tráfico a través de proxies residenciales.
Guías legales y éticas para extraer datos de Walmart
Los usuarios de foros expresan esta preocupación de forma muy directa: “No me importa jugar al gato y al ratón con los desarrolladores, pero me preocupa jugar con su equipo legal”.
Los Términos de uso de Walmart usar “cualquier robot, spider… u otro dispositivo manual o automático para recuperar, indexar, ‘extraer’, ‘minar datos’ o recopilar de otro modo cualquier material” sin “consentimiento previo expreso por escrito”.
El robots.txt de Walmart /search, /account, /api/ y docenas de endpoints internos. Las páginas de detalle de producto (/ip/...) y las reseñas (/reviews/product/) no están bloqueadas.
El precedente hiQ contra LinkedIn (9.º Circuito, ) estableció que extraer datos disponibles públicamente probablemente no viola la CFAA federal. Pero el mismo tribunal luego dictaminó que y dictó un en su contra. Decisiones más recientes de 2024 (, ) restringieron aún más la CFAA y crearon defensas por preeminencia de copyright, pero esos fallos dependieron de un lenguaje específico de los Términos de uso que no encaja limpiamente con Walmart.
Pautas prácticas: no sobrecargues los servidores. Respeta los límites de ritmo. No extraigas datos personales ni de usuarios. Usa los datos de forma responsable. Extraer páginas públicas de productos de Walmart a un ritmo moderado para investigación personal es un perfil de riesgo muy distinto del scraping a escala comercial contra los Términos de Walmart. Si vas a construir un producto a partir de datos de Walmart, habla con un abogado e infórmate sobre las APIs oficiales de .
Aviso: esto es información educativa, no asesoramiento legal.
Conclusión y conclusiones clave
Extraer datos de Walmart con Python es un reto de debido a su doble capa antibot de Akamai + PerimeterX. No es imposible, pero necesitas las herramientas y patrones adecuados.
Conclusiones clave:
- La extracción JSON de
__NEXT_DATA__es la opción pragmática para la mayoría de los casos de uso. Es la que usan todos los scrapers serios de Walmart de código abierto entre 2024 y 2026. La ruta base esprops.pageProps.initialData.data.productpara las PDP ysearchResult.itemStackspara búsqueda/exploración. curl_cfficonimpersonate="chrome124"es obligatorio.requestsohttpxpuros no pueden superar el fingerprinting TLS de Akamai sin importar las cabeceras.- Los bloqueos silenciosos son el verdadero peligro. Walmart devuelve 200 OK con cuerpos CAPTCHA. Comprueba el contenido de la respuesta, no solo los códigos de estado.
- Los scrapers de producción necesitan más que código para el camino feliz. Backoff exponencial con jitter, detección de bloqueo con cuatro señales, limitación de ritmo a 3–6 segundos por solicitud, validación de datos y monitorización de salud de sesión son esenciales.
- La interceptación de la API interna mediante
/orchestra/*es potente, pero frágil. Úsala como ejercicio con DevTools para necesidades concretas de datos, no como tu método principal de extracción. - Walmart limita los resultados de búsqueda a 25 páginas. Amplía la cobertura alternando el orden de clasificación y dividiendo por rangos de precios.
- Elige tu enfoque con honestidad: Python casero para desarrolladores con necesidades personalizadas y mucho volumen. APIs de scraping para equipos de escala media sin ingeniero de scraping. para usuarios de negocio que quieren los datos en Google Sheets esta misma tarde.
Si quieres probar la ruta sin código, la tiene un plan gratuito: puedes extraer unas cuantas páginas de Walmart y ver los resultados por ti mismo. Si vas por la ruta de Python, los patrones de código de este artículo están probados en producción. En cualquier caso, ahora ya tienes un mapa de las defensas de Walmart y tres caminos para atravesarlas.
Para más información sobre técnicas de web scraping, consulta nuestras guías sobre , y . También puedes ver tutoriales en el .
Preguntas frecuentes
¿Es legal extraer datos de productos de Walmart?
Los Términos de uso de Walmart prohíben el scraping automatizado sin consentimiento por escrito. La sentencia del 9.º Circuito en hiQ v. LinkedIn (2022) estableció que la CFAA federal probablemente no se aplique al scraping de páginas públicas, pero el mismo caso terminó con una contra el scraper. Extraer páginas públicas de productos a ritmo moderado para investigación personal tiene un perfil de riesgo muy distinto del scraping a escala comercial. Consulta a un abogado si vas a montar un negocio con datos de Walmart.
¿Por qué mi scraper de Walmart sigue siendo bloqueado?
Las causas más comunes son: usar requests o httpx puros (que emiten una huella TLS específica de Python que Akamai detecta al instante), cabeceras faltantes o incorrectas, ausencia de rotación de proxies, una tasa de solicitudes más rápida que una página cada 3–6 segundos y cookies de sesión que faltan (_px3, _abck, locDataV3). Cambia a curl_cffi con impersonate="chrome124", usa proxies residenciales e implementa los patrones de detección de bloqueos y reintento descritos en este artículo.
¿Qué datos puedo extraer de Walmart con Python?
Nombres de productos, precios (actuales y rebajados), imágenes, descripciones cortas y largas, valoraciones, número de reseñas, estado de disponibilidad de stock, nombres de vendedores, información del fabricante, opciones de variante (talla, color) y ubicación en categorías. Usando el método __NEXT_DATA__, todo eso está disponible como JSON estructurado. La interceptación de API interna también puede devolver precios por variante, recuentos de inventario en tiempo real y datos de reseñas paginadas.
¿Necesito proxies para extraer Walmart?
Sí, para cualquier uso repetido o de producción. — incluso con cabeceras perfectas, una IP no residencial será detectada por el sistema de reputación de IP de Akamai. Se requieren proxies residenciales o móviles. Las IP de centros de datos se queman casi de inmediato. Presupuesta aproximadamente entre 3 y 17 USD por cada 1.000 páginas, según tu proveedor y plan de proxy.
¿Puedo extraer Walmart sin escribir código?
Sí. es una extensión de Chrome impulsada por IA que extrae Walmart en dos clics: “Sugerir campos con IA” para detectar automáticamente las columnas de datos del producto y luego “Extraer” para obtener los datos. Gestiona los desafíos antibots en la nube y exporta directamente a Excel, Google Sheets, Airtable o Notion, todo gratis. Está especialmente pensada para analistas, PMs y usuarios de negocio que necesitan datos rápido sin construir un pipeline personalizado. Para scraping de gran volumen o muy personalizado, Python o una API de scraping sigue siendo la mejor opción.
Más información