Redfin actualiza desde que salen publicados. Ese nivel de frescura es oro puro para cualquiera que esté armando una canalización de datos inmobiliarios — y justo por eso tantos scrapers apuntan a Redfin y acaban bloqueados en cuestión de minutos.
He pasado años trabajando en herramientas de extracción de datos en , y te lo digo sin rodeos: la distancia entre "extraer datos de Redfin" y "extraer datos de Redfin sin que te bloqueen" es donde se caen la mayoría de los tutoriales. Te enseñan el código con BeautifulSoup, se saltan la parte en la que Cloudflare se come tus peticiones, y te dejan mirando una página 403 sin entender qué pasó. Esta guía es diferente. Te voy a mostrar tres enfoques reales — análisis de HTML, la API oculta de Redfin y una opción sin código con Thunderbit — y me voy a detener de verdad en las defensas anti-bots que importan. Al final vas a saber exactamente qué método encaja con tu nivel técnico, tu volumen de trabajo y tu paciencia para el mantenimiento.
¿Qué es Redfin y por qué importan tanto sus datos?
Redfin es una inmobiliaria impulsada por tecnología, con agentes asalariados que toman los anuncios directamente de los feeds de MLS. Cubre y recibe casi 50 millones de visitantes al mes. A diferencia de los portales que solo agregan información, los datos de Redfin están verificados por agentes, y su AVM propietario, Redfin Estimate, cubre con un error mediano de solo 1,96% en viviendas en venta.
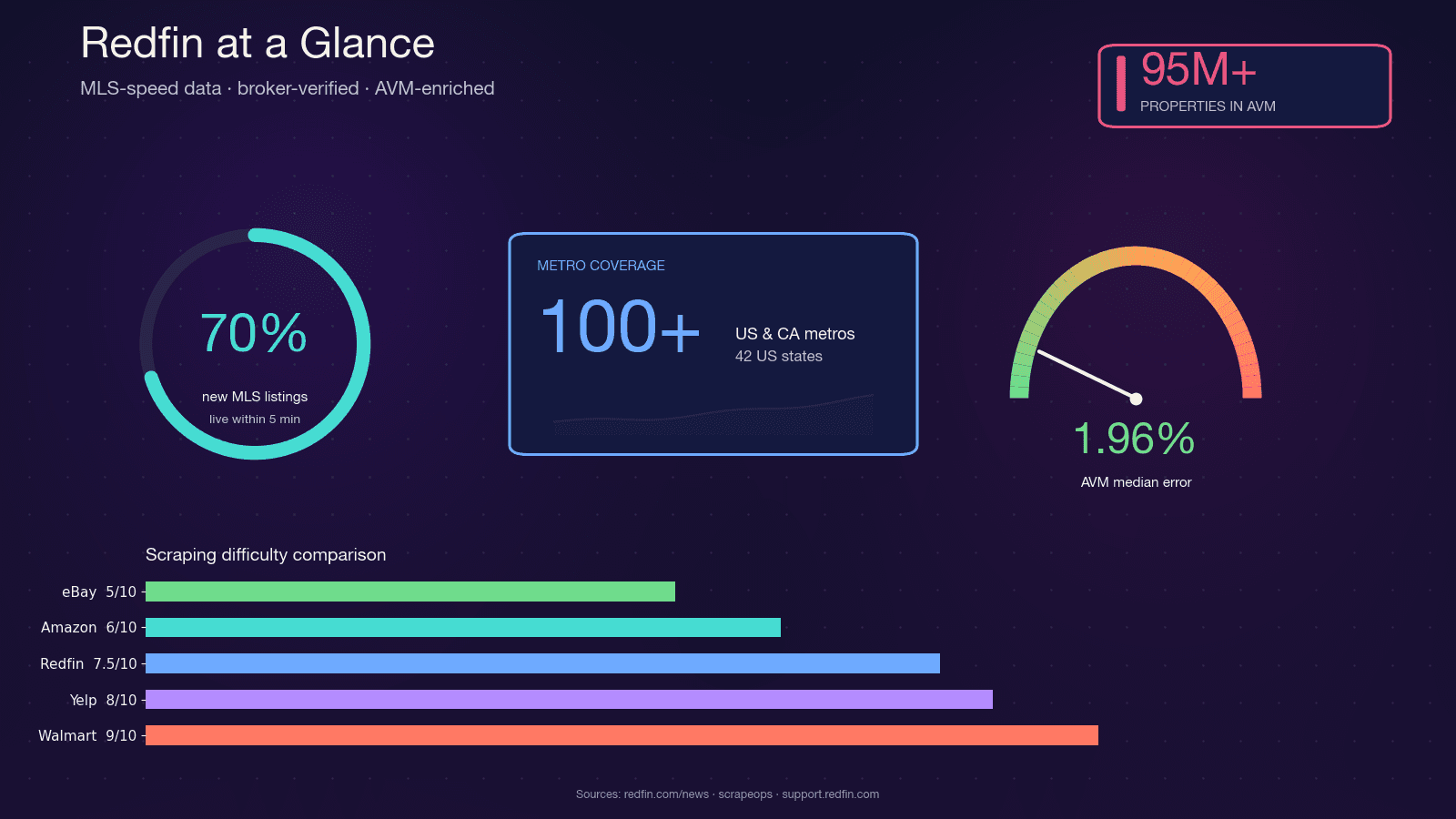
Esa mezcla — frescura casi al ritmo del MLS, calidad verificada por corredores y un AVM muy afinado — es la razón por la que inversores inmobiliarios, agentes, startups de proptech y analistas de datos quieren acceder programáticamente a Redfin. Python es una opción natural: su ecosistema de scraping (requests, BeautifulSoup, Selenium, Playwright) está súper maduro, la comunidad es enorme y se integra directo con pandas y Jupyter para analizar los datos.
¿Por qué extraer datos de Redfin con Python?
Los casos de uso son tan variados como la gente que necesita estos datos. Así suelen aprovecharse los datos extraídos de Redfin:
| Audiencia | Objetivo principal del scraping | Caso de uso de ejemplo |
|---|---|---|
| Agentes inmobiliarios | Generación de leads, inteligencia de mercado | Nuevos anuncios y anuncios caducados en su zona; directorio de agentes para comparar la competencia |
| Inversores inmobiliarios | Flujo de oportunidades, análisis de cap rate | Búsqueda de rentabilidad de alquiler, detección de propiedades infravaloradas, alertas diarias de nuevos anuncios |
| Startups de proptech | Canales de datos para producto | Datos de entrenamiento para AVM, paneles de mercado, motores de adquisición para iBuyer |
| Analistas de datos | Investigación de mercado, BI | Tendencias del precio medio por ZIP, series temporales de días en mercado, ratio de venta vs. precio de listado |
| Mayoristas / house flippers | Seguimiento de propiedades en dificultades | Detección de rebajas, ejecuciones hipotecarias, comparables fuera de mercado |
La tendencia general lo confirma: ya usan analítica predictiva para detectar oportunidades y gestionar riesgos. Se proyecta que el mercado de PropTech alcance con un CAGR del 16,4%. Los datos inmobiliarios estructurados ya no son un extra: son imprescindibles.
Todos los campos de datos de Redfin que puedes extraer (guía completa)
Antes de escribir una sola línea de código, necesitas saber qué hay realmente disponible. He auditado las páginas de resultados de búsqueda de Redfin, las páginas de detalle de propiedades y los perfiles de agentes — y lo he cruzado con wrappers de código abierto de la API Stingray, como los proyectos y . El total suma 117 campos distintos entre tipos de página.
Esta tabla conviene tenerla a mano. Conocer el esquema de datos antes de programar te ahorra horas de prueba y error buscando selectores.
Campos de la página de resultados de búsqueda
Estos son los campos ligeros disponibles en las tarjetas de anuncios — muchas veces se pueden extraer sin renderizar todo el JavaScript:
| Campo | Tipo de dato | Notas |
|---|---|---|
| ID de la propiedad | Número | Entero interno de Redfin, extraído de /home/{id} en el href |
| Precio de listado | Número | |
| Dirección completa | Texto | |
| Dormitorios / Baños / m² | Número | Tres valores en secuencia |
| Tipo de propiedad | Selección única | SFH, Condo, Townhouse, Multi |
| Estado | Texto | Active, Pending, Contingent |
| Días en el mercado | Número | |
| Indicador de rebaja | Número | Diferencia respecto al precio original |
| Foto principal | URL de imagen | Una foto por tarjeta |
| Insignia de Hot Home | Booleano | |
| Fecha/hora de open house | Texto | |
| Atribución de correduría | Texto |
Campos de la página de detalle de la propiedad
La página de detalle es donde está la profundidad real. Muchos de estos campos requieren renderizado JavaScript o la API Stingray:
| Campo | Tipo de dato | Notas |
|---|---|---|
| Redfin Estimate (en venta) | Número | Vía /stingray/api/home/details/avm |
| Redfin Estimate (fuera de mercado) | Número | Vía /stingray/api/home/details/owner-estimate; error mediano del 7,52% |
| Año de construcción / reforma | Número | |
| Tamaño del terreno | Número | |
| Cuotas HOA | Número | Mensuales, si aplican |
| Impuesto sobre la propiedad (anual) | Número | |
| Valor fiscal tasado | Número | |
| Tabla de historial de ventas | Tabla | Precio, fecha, tipo de evento |
| Descripción de la propiedad | Texto | Párrafo comercial |
| URLs de fotos (carrusel) | URLs de imagen | 20+ por anuncio |
| Nombre, teléfono y email del agente | Texto / Teléfono / Email | El teléfono suele estar oculto |
| Calificaciones escolares (primaria/secundaria/preparatoria) | Número | Más el nombre del distrito |
| Puntuación de caminabilidad / transporte / bicicleta | Número | |
| Puntuaciones de riesgo climático | Número | Inundación, incendio, calor, viento |
| Viviendas similares activas / vendidas / cercanas | URLs | Datos del carrusel |
| Estacionamiento, garaje, calefacción, refrigeración | Texto | Grupos de comodidades |
Campos del perfil del agente
| Campo | Tipo de dato | Notas |
|---|---|---|
| Nombre del agente, foto, correduría, biografía | Texto / Imagen | |
| Teléfono, formulario de contacto | Teléfono / Texto | Se muestra al hacer clic |
| Número de anuncios activos | Número | |
| Ventas de los últimos 12 meses / volumen total | Número | |
| Ratio medio entre precio de listado y precio de venta | Número | |
| Valoración por estrellas / número de reseñas | Número | |
| Años de experiencia / nº de licencia | Texto / Número |
Cuando usas la función AI Suggest Fields de Thunderbit en una página de Redfin, detecta automáticamente la mayoría de estas columnas y asigna el tipo de dato correcto — sin necesidad de mapear selectores CSS a mano. Más adelante te cuento más.
Cómo funcionan las defensas anti-bots de Redfin (no es solo "usa un proxy")
Aquí quiero marcar una línea, porque la mayoría de los tutoriales pasan de largo el problema del bloqueo y saltan directo a "compra proxies a nuestro patrocinador". Eso no sirve. Si no entiendes qué hace Redfin para detectar scrapers, vas a gastar créditos de proxy y te van a bloquear igual. , y — "menos agresiva que el WAF empresarial de Zillow, y basada en limitación de tasa personalizada y desafíos JavaScript".
Redfin usa una pila por capas: Cloudflare en el borde (desafío JavaScript, Turnstile, fingerprinting TLS/JA3) más un limitador de tasa de capa de aplicación específico de Redfin. No hay ninguna directiva Crawl-delay en su robots.txt porque la aplicación de las reglas ocurre a nivel WAF.
Por qué requests + BeautifulSoup falla en Redfin
Si haces un requests.get() básico a una página de propiedad de Redfin con los headers por defecto, normalmente pasa esto:
- HTTP 403 — no se resolvió el desafío JavaScript de Cloudflare, así que recibes la página del reto en vez del anuncio.
- Una página intermedia de desafío — el cuerpo HTML contiene el widget Turnstile de Cloudflare, no los datos de la propiedad.
- HTTP 200 con HTML parcial — obtienes una carcasa con un gran bloque JSON incrustado bajo
root.__reactServerState.InitialContext, pero sin tarjetas de búsqueda renderizadas, sin historial de precios y sin calificaciones escolares.
Redfin usa su propio (no Next.js), y la clave de hidratación es específica de Redfin — root.__reactServerState.InitialContext con los datos del anuncio anidados bajo ReactServerAgent.cache.dataCache. No es __NEXT_DATA__ ni window.__INITIAL_STATE__.
¿La causa más común de los 403 silenciosos? Faltan los headers Sec-Fetch-*. Redfin/Cloudflare valida explícitamente Sec-Fetch-Site, Sec-Fetch-Mode, Sec-Fetch-Dest y Sec-Fetch-User. Si no están, te marcan al instante.
Plan de mitigación: retrasos, headers, proxies y sesiones
Aquí tienes el desglose completo defensa por defensa, con la mitigación concreta de cada una:
| Defensa de Redfin | Qué hace | Señal de detección | Estrategia de mitigación |
|---|---|---|---|
| Desafío JS de Cloudflare | Intersticial que emite la cookie cf_clearance | 403 + cuerpo HTML de Cloudflare | curl_cffi con impersonate="chrome120"; calentar la sesión desde la página principal; proxy residencial de EE. UU. |
| Cloudflare Turnstile | CAPTCHA interactivo en sesiones de alto riesgo | 403 + widget Turnstile | Navegador headless con stealth + proxy residencial |
| Error 1020 de Cloudflare (bloqueo ASN) | Bloquea IPs/ASNs marcados en el WAF | Cuerpo 403 con "Error 1020 Access Denied" | Rotar a proxy residencial o móvil; nunca usar ASNs de centros de datos |
| Fingerprinting TLS/JA3 | Detecta stacks TLS que no son de navegador | 403 silencioso incluso con headers perfectos | Impersonación con curl_cffi o navegador real |
| Fingerprinting HTTP/2 | Comprueba SETTINGS de HTTP/2 y el orden HPACK | Bloqueo silencioso | curl_cffi habla HTTP/2 como Chrome |
| Validación de headers (UA, Sec-Fetch-*) | Conjunto de headers coherente con un navegador | 403 en la primera petición | Set completo de headers de Chrome, incluidos Sec-Fetch-Site/Mode/Dest/User y un Referer realista |
| Continuidad de cookies/sesión | Sigue cf_clearance, RF_BROWSER_ID | Desafíos en accesos fríos a URLs profundas | Sesión persistente; calentar primero desde la página principal |
| Límite de tasa de la app | Limitador por IP | 429 | Retraso de 2–5 s con jitter; backoff exponencial |
| Reputación de IP de centro de datos | Bloquea ASNs de DC conocidos | 1020/403 inmediato | Solo proxies residenciales o móviles de EE. UU. |
| Detección de concurrencia | Varias solicitudes en paralelo desde una misma IP | Escalada súbita a Turnstile | Máximo 2 peticiones concurrentes por IP |
Umbrales prácticos obtenidos de pruebas de la comunidad:
- Cadencia segura: 1 solicitud cada 2–3 segundos por IP
- Más de 20–30 solicitudes/minuto sostenidas desde una sola IP de centro de datos activa un desafío en pocos minutos
- Los límites suaves suelen levantarse en 5–15 minutos si se detiene el tráfico
- Los bloqueos a IPs de centros de datos (AWS, GCP, Azure, OVH) pueden durar de horas a días
El requests estándar de Python (urllib3 + OpenSSL) genera una — y eso provoca bloqueos silenciosos incluso con los headers correctos. La solución habitual del sector es curl_cffi con impersonate="chrome120", que reproduce TLS + HTTP/2 de Chrome con bastante precisión.
Tres formas de extraer datos de Redfin con Python (y cuál elegir)
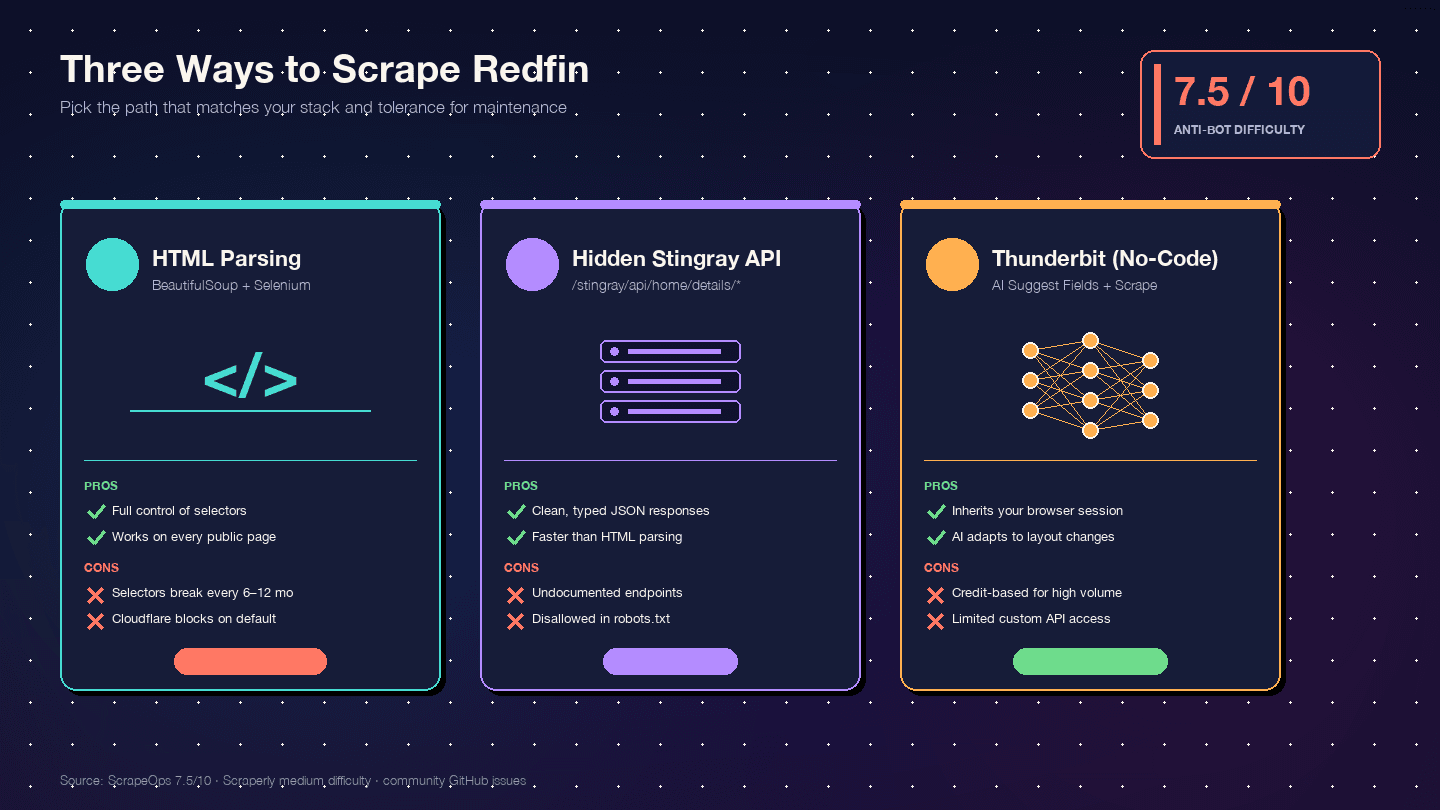
No he encontrado ni un solo tutorial de la competencia que compare los tres enfoques lado a lado. Esta es la matriz de decisión:
| Criterio | Análisis de HTML (BS4 + Selenium) | API oculta Stingray | Thunderbit (sin código) |
|---|---|---|---|
| Dificultad de configuración | Media (entorno Python + driver del navegador) | Alta (ingeniería inversa de endpoints) | Baja (instalar extensión de Chrome) |
| Riesgo anti-bot | Alto (las peticiones al DOM son las más visibles) | Medio (las peticiones tipo API parecen más limpias) | El más bajo (usa tu sesión real del navegador) |
| Calidad de la estructura de datos | Media (HTML sin estructura → parseo manual) | Excelente (JSON ya estructurado) | Alta (la IA detecta campos y tipos automáticamente) |
| Mantenimiento | Alto — cualquier cambio de diseño rompe selectores | Medio — los endpoints pueden cambiar sin aviso | El más bajo — la IA se adapta a cambios de diseño |
| Escala | Baja-media (cientos con proxies) | Media-alta (miles, peticiones más limpias) | Media (50 páginas por lote con scraping en la nube) |
| Ideal para | Desarrolladores que quieren control total | Desarrolladores que necesitan JSON limpio | No desarrolladores, proyectos rápidos, datos continuos sin equipo técnico |
El tema del mantenimiento merece énfasis. Redfin ha tenido dos generaciones de DOM para tarjetas — la antigua (homecardV2Price) y la actual (span.bp-Homecard__Price--value). El historial de issues en GitHub muestra roturas de selectores CSS más o menos cada 6–12 meses. Cuando eso pasa, un scraper con BeautifulSoup puede romperse de un día para otro. Un detector de campos basado en IA se adapta.
Antes de empezar
- Dificultad: Intermedia (enfoques 1 y 2), Principiante (enfoque 3)
- Tiempo necesario: ~30 minutos para el enfoque 1 o 2; ~5 minutos para el enfoque 3
- Lo que necesitas:
- Python 3.8+ con pip (enfoques 1 y 2)
- Navegador Chrome (todos los enfoques)
- (enfoque 3)
- Proxies residenciales de EE. UU. para scraping a gran escala (enfoques 1 y 2)
Enfoque 1: extraer datos de Redfin con Python usando análisis HTML (BeautifulSoup + Selenium)
Este es el camino de "control total". Tú escribes los selectores, tú administras el navegador, tú manejas los errores.
Es el enfoque que más enseña. También es el más frágil.
Paso 1: prepara tu entorno Python
Crea un entorno virtual e instala las librerías necesarias:
1python -m venv redfin-scraper
2source redfin-scraper/bin/activate # En Windows: redfin-scraper\Scripts\activate
3pip install requests beautifulsoup4 selenium webdriver-manager pandas curl_cfficurl_cffi es clave aquí: es lo que permite que tus peticiones HTTP imiten la huella TLS real de Chrome, en lugar de la huella estándar de Python requests que Cloudflare bloquea de inmediato.
Paso 2: configura los headers y la sesión del navegador
Aquí es donde falla la mayoría de la gente que empieza. Necesitas el conjunto completo de headers de Chrome, incluidos los Sec-Fetch-* que Redfin/Cloudflare valida explícitamente:
1from curl_cffi import requests as curl_requests
2HEADERS = {
3 "User-Agent": "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/120.0.0.0 Safari/537.36",
6 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
7 "Accept-Language": "en-US,en;q=0.9",
8 "Accept-Encoding": "gzip, deflate, br",
9 "Sec-Fetch-Site": "none",
10 "Sec-Fetch-Mode": "navigate",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-User": "?1",
13}
14session = curl_requests.Session(impersonate="chrome120")
15session.headers.update(HEADERS)
16# Calienta la sesión — recopila las cookies cf_clearance y RF_BROWSER_ID
17session.get("https://www.redfin.com/")El paso de calentar la sesión es crítico: entrar directo a una URL profunda de propiedad (sin cookies previas ni Referer) hace que Cloudflare te puntúe peor.
Empieza siempre por la página principal.
Paso 3: extrae los resultados de búsqueda de Redfin
Con la sesión ya activada, puedes pedir una página de búsqueda por ciudad y analizar las tarjetas de anuncios. Selectores de la generación actual (2024–2026):
1import time
2import random
3from bs4 import BeautifulSoup
4base_url = "https://www.redfin.com/city/17151/CA/San-Francisco"
5listings = []
6for page_num in range(1, 6): # Páginas 1-5
7 url = f"{base_url}/page-{page_num}" if page_num > 1 else base_url
8 resp = session.get(url)
9 if resp.status_code != 200:
10 print(f"Bloqueado en la página {page_num}: HTTP {resp.status_code}")
11 break
12 soup = BeautifulSoup(resp.text, "html.parser")
13 cards = soup.select("[data-rf-test-id='property-card'], a.bp-Homecard")
14 for card in cards:
15 price_el = card.select_one("span.bp-Homecard__Price--value")
16 addr_el = card.select_one("a.bp-Homecard__Address")
17 stats = card.select("span.bp-Homecard__LockedStat--value")
18 listing = {
19 "price": price_el.text.strip() if price_el else None,
20 "address": addr_el.text.strip() if addr_el else None,
21 "beds": stats[0].text.strip() if len(stats) > 0 else None,
22 "baths": stats[1].text.strip() if len(stats) > 1 else None,
23 "sqft": stats[2].text.strip() if len(stats) > 2 else None,
24 "url": "https://www.redfin.com" + addr_el["href"] if addr_el else None,
25 }
26 listings.append(listing)
27 # Pausa aleatoria entre 2 y 5 segundos
28 time.sleep(random.uniform(2, 5))
29print(f"Se extrajeron {len(listings)} anuncios")Deberías ver una lista creciente de diccionarios, cada uno con el precio, la dirección, dormitorios/baños/m² y la URL de detalle de un anuncio de San Francisco. Si obtienes 0 tarjetas, revisa el código de estado HTTP: un 403 significa que Cloudflare te detectó y probablemente necesites proxies residenciales.
Paso 4: extrae las páginas de detalle de cada propiedad
Los resultados de búsqueda te dan lo básico. Las páginas de detalle te dan Redfin Estimate, año de construcción, HOA, historial de ventas, información del agente y fotos. Estas páginas requieren renderizado JavaScript, así que cambia a Selenium:
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service
3from webdriver_manager.chrome import ChromeDriverManager
4from selenium.webdriver.common.by import By
5import time
6options = webdriver.ChromeOptions()
7options.add_argument("--headless=new")
8options.add_argument("--disable-blink-features=AutomationControlled")
9options.add_argument("user-agent=Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
10 "AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Safari/537.36")
11driver = webdriver.Chrome(service=Service(ChromeDriverManager().install()), options=options)
12for listing in listings[:10]: # Enriquecer los primeros 10
13 driver.get(listing["url"])
14 time.sleep(random.uniform(3, 6)) # Esperar a que renderice JavaScript
15 try:
16 estimate_el = driver.find_element(By.CSS_SELECTOR, "[data-rf-test-name='avmLdpPrice']")
17 listing["redfin_estimate"] = estimate_el.text.strip()
18 except:
19 listing["redfin_estimate"] = None
20 try:
21 year_built = driver.find_element(By.XPATH, "//span[contains(text(),'Year Built')]/following-sibling::span")
22 listing["year_built"] = year_built.text.strip()
23 except:
24 listing["year_built"] = None
25driver.quit()Después de este paso, tus primeros 10 anuncios deberían tener Redfin Estimate y el año de construcción. Los selectores XPath suelen ser más robustos que CSS para estos campos anidados de comodidades, pero siguen siendo frágiles: cualquier reorganización del DOM puede romperlos.
Paso 5: gestiona bloqueos y errores
Implementa lógica de reintento con backoff exponencial:
1import time
2def fetch_with_retry(session, url, max_retries=3):
3 for attempt in range(max_retries):
4 resp = session.get(url)
5 if resp.status_code == 200:
6 return resp
7 elif resp.status_code in (403, 429, 503):
8 wait = (2 ** attempt) + random.uniform(1, 3)
9 print(f"Bloqueado ({resp.status_code}). Reintentando en {wait:.1f}s...")
10 time.sleep(wait)
11 else:
12 print(f"Estado inesperado: {resp.status_code}")
13 break
14 return NoneSeñales de que te han bloqueado: HTTP 403 con HTML de Cloudflare en el cuerpo, HTTP 429 (límite de tasa explícito), cuerpo vacío o "Error 1020 Access Denied" en el contenido de la página. Si te pasa de forma consistente, ya toca añadir proxies residenciales o cambiar al enfoque de API.
Enfoque 2: extraer datos de Redfin con Python usando la API oculta Stingray
Este es mi enfoque favorito. El frontend de Redfin habla con una API JSON interna en /stingray/api/home/details/*, y las respuestas vuelven como JSON limpio y tipado — sin necesidad de analizar HTML.
Cómo descubrir los endpoints ocultos de Redfin
Abre Chrome DevTools → pestaña Network → filtra por Fetch/XHR → navega a cualquier página de propiedad de Redfin. Vas a ver peticiones a endpoints como:
api/home/details/initialInfo— resuelve URL → propertyId, listingIdapi/home/details/aboveTheFold— precio, dormitorios, baños, m², fotos, estado, agente, MLS#api/home/details/belowTheFold— comodidades, HOA, impuestos, estacionamiento, año de construcción, terreno, historialapi/home/details/avm— Redfin Estimate en ventaapi/home/details/owner-estimate— Redfin Estimate fuera de mercadoapi/home/details/descriptiveParagraph— descripción comercial
Para páginas de alquiler, el rentalId (un UUID de 36 caracteres) se extrae de la URL de la etiqueta <meta property="og:image">.
Extracción de datos de propiedades mediante la API Stingray
Hay una particularidad importante: las respuestas JSON de Stingray llevan el prefijo literal {}&& como medida anti-CSRF. Debes eliminarlo antes de parsear:
1import json
2from curl_cffi import requests as curl_requests
3session = curl_requests.Session(impersonate="chrome120")
4session.headers.update(HEADERS)
5# Calentar sesión
6session.get("https://www.redfin.com/")
7# Obtener una página de propiedad para capturar cookies e ID de propiedad
8property_url = "https://www.redfin.com/CA/San-Francisco/123-Main-St-94102/home/12345678"
9page_resp = session.get(property_url)
10# Ahora llamar a la API Stingray
11api_url = "https://www.redfin.com/stingray/api/home/details/aboveTheFold?propertyId=12345678"
12api_resp = session.get(api_url, headers={"Referer": property_url})
13# Quitar el prefijo anti-CSRF
14payload = json.loads(api_resp.text.replace("{}&&", "", 1))
15# Extraer datos estructurados
16listing_data = payload.get("payload", {})
17print(json.dumps(listing_data, indent=2))La respuesta incluye campos tipados: precio como entero, dormitorios/baños como números, URLs de fotos como arrays e información del agente como objetos anidados. Nada de BeautifulSoup, nada de selectores CSS, nada de adivinar.
Ventajas y límites del enfoque de API oculta
Ventajas:
- JSON ya estructurado — mucho más limpio que analizar HTML
- Más rápido por petición (cargas más pequeñas, sin renderizado)
- Menor riesgo de bloqueo (las peticiones tipo API, con headers correctos, parecen más naturales)
Limitaciones:
- Los endpoints pueden cambiar sin aviso — no hay documentación oficial
robots.txtprohíbe explícitamente/stingray/para el agente genérico- Requiere ingeniería inversa para descubrir endpoints nuevos
- Aun así necesitas calentar la sesión y usar headers correctos para evitar Cloudflare
La alternativa sin código: extraer datos de Redfin con Thunderbit
Si necesitas datos de Redfin y no quieres mantener scripts en Python — o simplemente quieres resultados en cinco minutos — empieza por aquí. Construimos precisamente para esto: extracción estructurada de datos desde cualquier sitio web, sin necesidad de programar.
Paso 1: instala Thunderbit y entra en Redfin
Instala la desde Chrome Web Store. Abre Redfin y ve a una página de resultados de búsqueda — por ejemplo, viviendas en venta en San Francisco.
Paso 2: haz clic en "AI Suggest Fields"
Haz clic en el icono de Thunderbit en la barra de herramientas del navegador y luego en "AI Suggest Fields." La IA lee la página de Redfin y sugiere automáticamente columnas como "Address", "Price", "Beds", "Baths", "SqFt", "Property Type" y "Listing Photo" — asignando los tipos de datos correctos por defecto.
Puedes eliminar las columnas que no necesites o añadir otras personalizadas pulsando "+ Add Column" y describiendo en lenguaje natural lo que buscas (por ejemplo, "nombre del agente de listado" o "días en el mercado").
Deberías ver una vista previa de la tabla con las columnas configuradas, lista para rellenarse.
Paso 3: pulsa "Scrape" y deja que lleguen los datos
Haz clic en "Scrape". Thunderbit procesa los anuncios visibles y rellena la tabla. Si hay paginación, la gestiona automáticamente — sin necesidad de escribir bucles.
En mis pruebas, una tabla de 50 filas se completa en unos 45 segundos. Datos estructurados, listos para exportar.
Cómo maneja Thunderbit las protecciones anti-bot de Redfin
Como Thunderbit se ejecuta dentro de tu propio navegador, hereda tus cookies, sesión y huella del navegador de Redfin. Para Cloudflare, parece un usuario normal navegando Redfin — porque técnicamente lo es. No hay navegador headless, no hay IP de centro de datos y no hay huella TLS desalineada. En páginas públicas, el modo de scraping en la nube de Thunderbit puede procesar 50 páginas a la vez.
Eso es una postura completamente distinta a lanzar requests desde un script Python en un servidor.
Tu sesión del navegador ya es confiable.
Extraer subpáginas de Redfin con Thunderbit
Después de extraer los resultados de búsqueda, haz clic en "Scrape Subpages" para que la IA visite cada URL de detalle de propiedad y enriquezca la tabla con más campos — Redfin Estimate, año de construcción, cuotas HOA, información del agente, fotos de la propiedad e historial de ventas.
Es el equivalente al bucle de Selenium de 40 líneas del enfoque 1 — solo que con un clic y sin mantenimiento.
Cuando Redfin cambia su DOM de homecardV2Price a span.bp-Homecard__Price--value, la IA se adapta. Tus selectores de Python, no.
Más allá del CSV: exporta datos de Redfin a Google Sheets, Airtable y Notion
La mayoría de los tutoriales se quedan en df.to_csv(). Está bien para un análisis puntual. Pero si trabajas en un equipo inmobiliario, necesitas datos vivos y colaborativos, no archivos estáticos acumulándose en el escritorio de alguien.
Exportar con Python (gspread + API de Airtable)
Google Sheets con gspread:
1import gspread
2import pandas as pd
3from gspread_dataframe import set_with_dataframe
4df = pd.DataFrame(listings)
5gc = gspread.service_account(filename="service_account.json")
6sh = gc.open("Redfin Listings")
7ws = sh.worksheet("Sheet1")
8ws.clear()
9set_with_dataframe(ws, df, include_index=False, resize=True)
10# Mostrar fotos de propiedades dentro de la hoja con la fórmula IMAGE()
11image_col = df.columns.get_loc("image_url") + 1
12for row_idx, url in enumerate(df["image_url"], start=2):
13 ws.update_cell(row_idx, image_col, f'=IMAGE("{url}")')Ojo: Sheets tiene un límite duro de 10 millones de celdas por hoja de cálculo, y la API permite . Usa ws.batch_update() en lugar de bucles celda por celda para cualquier cosa que pase de unas pocas decenas de filas.
Airtable con pyairtable:
Cambio crítico de 2024: Airtable . Ahora debes usar Personal Access Tokens (PATs): cualquier tutorial que siga mostrando api_key=... ya no funciona.
1from pyairtable import Api
2api = Api("patXXXXXXXXXXXXXX.yyyyyyyyyyyyyyyyyyyy")
3table = api.table("appBaseId123", "Redfin Listings")
4records = [
5 {
6 "Address": row["address"],
7 "Price": row["price"],
8 "Beds": row["beds"],
9 "Photo": [{"url": row["image_url"]}], # Airtable la descarga y la vuelve a alojar
10 }
11 for row in listings
12]
13created = table.batch_create(records, typecast=True)El límite de Airtable es , con un bloqueo de 30 segundos si lo incumples. El campo de adjunto acepta payloads tipo [{"url": ...}] — los servidores de Airtable descargan la URL, la alojan de nuevo en su CDN y generan miniaturas automáticamente.
Exportar con Thunderbit (1 clic a Sheets, Airtable y Notion)
Thunderbit ofrece exportación nativa con 1 clic a Google Sheets, Airtable y Notion — y aquí viene una parte de la que estoy realmente orgulloso: las fotos de propiedades se suben y se renderizan como imágenes incrustadas en Notion y Airtable. Nada de trucos con =IMAGE(), nada de enlaces rotos de CDN. Pulsas "Export to Airtable" y tu equipo obtiene una base visual de propiedades con miniaturas que pueden revisar desde el móvil.
Para equipos inmobiliarios que hacen filtrado visual de anuncios, esa es la diferencia entre una herramienta útil y una pila de filas CSV.
¿Es legal extraer datos de Redfin? Qué dicen los Términos, robots.txt y la jurisprudencia
No soy abogado, y esto no es asesoramiento legal. Pero después de años en el mundo de la extracción de datos, te puedo decir que la pregunta "¿es legal?" es la que todo el mundo hace y la que la mayoría de los tutoriales esquiva.
El robots.txt de Redfin
El de Redfin es detallado. Puntos clave:
- Bots bloqueados por completo:
peer39_crawler/1.0,AmazonAdBot,FireCrawlAgent— Redfin nombra específicamente al popular servicio de scraping de la era LLM - Bloqueos destacados para
User-agent: *:/stingray/(todo el espacio de la API interna),/myredfin/,/api/v1/rentals/,/api/v1/properties/,/owner-estimate/ - No hay directiva
Crawl-delay:para ningún agente - Más de 50 sitemaps declarados — los sitemaps son la forma más limpia y menos agresiva para el WAF de enumerar URLs
Términos de uso de Redfin
La dice: "No puede rastrear ni consultar los Servicios de forma automatizada, para ningún propósito ni por ningún medio... salvo que haya recibido permiso expreso previo por escrito."
Esto es un acuerdo tipo browsewrap — aceptación por seguir usando el sitio, no por hacer clic en "acepto". Históricamente, los tribunales estadounidenses han sido escépticos a la hora de hacer valer browsewrap contra usuarios que no tenían aviso real (ver Nguyen v. Barnes & Noble, 9th Cir. 2014).
Jurisprudencia relevante (breve)
- Van Buren v. United States (Tribunal Supremo, 2021): la cláusula de "acceso no autorizado" de la CFAA usa un criterio de "puerta abierta o cerrada". Usar una puerta abierta para un fin no deseado no equivale a hacking federal.
- hiQ Labs v. LinkedIn (9th Cir., 2022): extraer datos públicos no viola la CFAA. Pero hiQ terminó pagando 500.000 dólares en un acuerdo por incumplimiento contractual — porque había creado cuentas en LinkedIn y hecho clic en "I agree".
- Meta Platforms v. Bright Data (N.D. Cal., enero de 2024): el tribunal concedió sentencia sumaria a Bright Data — el scraping de datos públicos sin iniciar sesión no convertía a Bright Data en un "usuario" sujeto a los Términos de Meta.
- X Corp. v. Bright Data (N.D. Cal., mayo de 2024): el juez Alsup desestimó las reclamaciones de X, sosteniendo que las reclamaciones de derecho estatal que intentaban controlar la copia de contenido público estaban preempted por la Copyright Act.
Orientación práctica
- Extrae solo datos públicamente accesibles — nunca te registres y luego hagas scraping (eso te expone a un contrato clickwrap)
- Respeta los límites de tasa — volúmenes agresivos pueden sustentar reclamaciones por trespass to chattels
- No republicar datos brutos ni fotos a gran escala — la demanda (presentada en julio de 2025, con daños potenciales superiores a 1.000 millones de dólares) recuerda que los derechos de autor de las fotos se toman en serio
- El enfoque basado en navegador de Thunderbit — ejecutado en tu propia sesión autenticada — se parece más a "navegación manual a velocidad de máquina" que a un bot headless en un centro de datos, y es la postura más defendible salvo que dispongas de una API con licencia
Consejos y errores comunes
Algunas lecciones duramente aprendidas construyendo herramientas de extracción y viendo a miles de usuarios scrapear sitios inmobiliarios:
- Calienta siempre tu sesión. Visita
redfin.com/antes de cualquier URL profunda. Entrar directo a una URL profunda es el disparador nº 1 de los desafíos de Cloudflare. - Rota los User-Agent de forma realista. No uses solo uno: alterna entre 5 y 10 UAs actuales de Chrome/Firefox. Pero no los rotas demasiado rápido (un UA distinto en cada petición parece sospechoso).
- Deduplica por ID de propiedad. La paginación de Redfin a veces se solapa. Extrae el
/home/{id}de cada URL y elimina duplicados antes de enriquecer. - Evita scrapear en horas punta si puedes. En mi experiencia, la madrugada o primeras horas de la mañana en hora de EE. UU. reciben menos escrutinio del WAF.
- Si recibes un 429, baja el ritmo exponencialmente. No reintentes enseguida: así conviertes un límite suave en un bloqueo duro de IP.
- Para proyectos grandes (1.000+ páginas), reserva presupuesto para proxies residenciales. Las IPs de centros de datos (AWS, GCP, Azure, OVH) están en listas negras del sistema de reputación ASN de Cloudflare. Te toparás con Error 1020 casi de inmediato.
Cómo elegir la mejor forma de extraer datos de Redfin
Entonces, ¿qué enfoque deberías elegir? Depende de quién eres y de lo que necesites.
Análisis de HTML (BeautifulSoup + Selenium): ideal para desarrolladores que quieren control total, se sienten cómodos manteniendo selectores CSS y no les importa rehacer cosas cuando Redfin cambia el DOM. Espera revisar el código cada 6–12 meses.
API oculta Stingray: ideal para desarrolladores que necesitan JSON limpio y estructurado y pueden lidiar con la ingeniería inversa de endpoints no documentados. Tiene menos mantenimiento que el análisis de HTML, pero los endpoints pueden cambiar sin aviso. Recuerda que /stingray/ está explícitamente prohibido en robots.txt.
Thunderbit (sin código): ideal para no desarrolladores, proyectos rápidos y equipos que necesitan datos continuos de Redfin sin recursos de desarrollo. La IA se adapta a cambios de diseño, el scraping de subpáginas enriquece datos con un clic y la exportación a , Airtable o Notion viene integrada. Si eres un equipo inmobiliario que necesita una base de datos viva de propiedades — no un CSV de una sola vez — este es el camino con menos fricción.
Elijas el camino que elijas: entiende primero las defensas anti-bots de Redfin, define qué campos necesitas, elige un formato de exportación que encaje con el flujo de trabajo de tu equipo y mantente dentro de las .
¿Listo para probar la opción sin código? El te permite experimentar con Redfin y ver resultados en minutos. Para los enfoques con Python, los fragmentos de código anteriores son un punto de partida funcional — solo añade proxies y paciencia.
Preguntas frecuentes
¿Redfin tiene una API pública?
No. Redfin no ofrece una API pública oficial. La API oculta Stingray (/stingray/api/home/details/*) devuelve JSON estructurado y la usa el propio frontend de Redfin, pero es no oficial, no está documentada, puede cambiar sin aviso y está explícitamente prohibida en el robots.txt de Redfin. Wrappers de código abierto como en PyPI ofrecen acceso desde Python, pero úsalos entendiendo los riesgos.
¿Puedo extraer datos de Redfin sin Python?
Sí. es una extensión de Chrome con IA que hereda tu sesión del navegador para resistir mejor a los anti-bots — instálala, entra en Redfin, pulsa "AI Suggest Fields" y exporta a Excel, Google Sheets, Airtable o Notion. También hay otras herramientas sin código y proveedores de datasets ya preparados en el mercado si quieres comparar alternativas.
¿Con qué frecuencia cambia el diseño web de Redfin?
El historial de issues de GitHub muestra roturas de selectores CSS aproximadamente cada 6–12 meses. Redfin ha lanzado dos generaciones de DOM para tarjetas — la antigua (homecardV2Price, homeAddressV2) y la actual (bp-Homecard__Price--value, bp-Homecard__Address). Los scrapers maduros prueban ambas en secuencia.
Las herramientas basadas en IA como Thunderbit porque detectan campos por su contenido y no por selectores CSS.
¿Qué tipo de proxy es mejor para extraer datos de Redfin?
Proxies residenciales de EE. UU. para scraping a gran escala — los benchmarks de la comunidad sitúan la tasa de éxito alrededor del 80%. Los proxies de centros de datos reciben el Error 1020 de Cloudflare casi de inmediato; rangos IP de AWS, GCP, Azure y OVH están bloqueados. Los proxies móviles tienen la mayor tasa de éxito, pero cuestan entre 5 y 10 veces más.
Para scraping personal a pequeña escala (<100 páginas), unos headers correctos + impersonación con curl_cffi + retrasos de 2–5 segundos pueden funcionar incluso sin proxies.
¿Puedo extraer datos de propiedades vendidas o fuera de mercado de Redfin?
Sí. Los datos de propiedades vendidas y el Redfin Estimate fuera de mercado (error mediano ) están disponibles en las páginas de detalle usando los mismos enfoques de scraping. Los campos cambian respecto a los anuncios activos: las páginas fuera de mercado exponen el precio de venta, la fecha de venta, el historial de la propiedad y el endpoint owner-estimate, pero no incluyen el precio de lista actual, los días en el mercado ni la información de open house. El endpoint de la API Stingray para estimaciones fuera de mercado es api/home/details/owner-estimate en lugar de api/home/details/avm.
Más información