

En algún momento, hacia la quincuagésima vez que copié y pegué un título de puesto de Indeed en una hoja de cálculo, empecé a cuestionarme mis decisiones profesionales. Si alguna vez has intentado extraer de forma programática datos estructurados de Indeed, ya sabes cuál es la broma: el error 403 no es un fallo; es una función del sistema defensivo de Indeed.
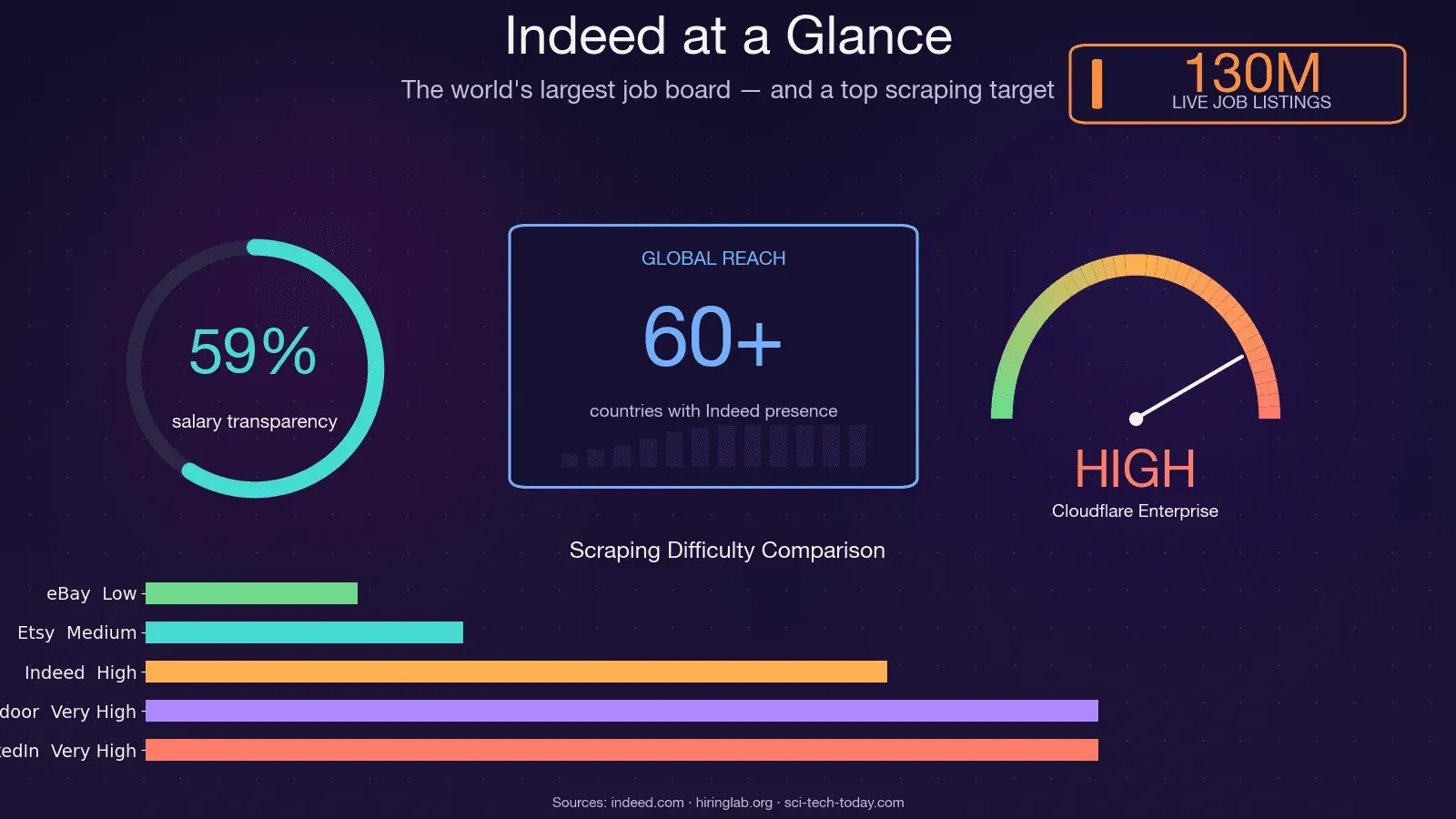
Indeed es la mayor bolsa de empleo del mundo, con aproximadamente 350 millones de visitantes únicos mensuales, 130 millones de ofertas de empleo en cualquier momento y operaciones en más de 60 países. Eso la convierte en una de las fuentes de datos del mercado laboral más ricas del planeta y, a la vez, en una de las más difíciles de extraer. El extractor de código abierto JobFunnel (con miles de estrellas en GitHub) fue literalmente archivado por su mantenedor en diciembre de 2025, tras años perdiendo la carrera armamentística contra los bots. Palabras del propio mantenedor: "Todos los usuarios pueden extraer algunos empleos, pero rápidamente se encuentran con un captcha, y la extracción falla, sin devolver empleos." Otro colaborador informó de que recibió un CAPTCHA en la primera solicitud. Así que sí: este no es un objetivo de scraping trivial. En esta guía te voy a mostrar todos los métodos prácticos para extraer Indeed con Python, cómo sobrevivir de verdad al muro de 403 y, para quienes prefieran saltarse por completo la depuración, una alternativa sin código con Thunderbit.
¿Qué significa extraer Indeed con Python?
El web scraping, en esencia, es la extracción automatizada de datos estructurados desde páginas web. Cuando hablamos de extraer Indeed con Python, nos referimos a escribir un script que visite las páginas de resultados y de detalle de empleo de Indeed, lea el HTML subyacente (o los datos incrustados) y extraiga campos como el título del puesto, la empresa, la ubicación, el salario y la descripción en un formato útil: CSV, base de datos o Google Sheets.
Las bibliotecas de Python que suelen intervenir son Requests (para llamadas HTTP), BeautifulSoup (para analizar HTML) y Selenium o Playwright (para automatización del navegador). Pero Indeed no es un sitio estático sencillo. Es un híbrido: HTML renderizado en el servidor con un bloque JSON incrustado, protegido por Cloudflare Bot Management. Eso significa que tu scraper tiene que lidiar con contenido renderizado por JavaScript, nombres de clase CSS que rotan y protecciones anti-bot agresivas, todo antes de analizar un solo título de puesto.
Tampoco existe en 2026 una API oficial, gratuita y de solo lectura de Indeed. La antigua Publisher Jobs API se descontinuó alrededor de 2020, y lo que queda es solo para empleadores (Job Sync, Sponsored Jobs). Así que extraer datos o pagar a un proveedor externo son las únicas opciones realistas.
¿Por qué extraer datos de empleos de Indeed?
La lógica de negocio para extraer Indeed es sencilla: navegar manualmente por miles de anuncios no es práctico, y los datos de esos anuncios son realmente valiosos.
| Caso de uso | Quién se beneficia | Ejemplo |
|---|---|---|
| Generación de leads | Equipos de ventas y reclutamiento | Crear listas de empresas que están contratando, con información de contacto |
| Investigación del mercado laboral | Analistas, equipos de RR. HH. | Identificar habilidades de tendencia y rangos salariales por región |
| Inteligencia competitiva | Empleadores, agencias de selección | Supervisar patrones de contratación y ofertas salariales de la competencia |
| Automatización personal de la búsqueda de empleo | Personas en búsqueda de trabajo | Agrupar ofertas que encajen con tus criterios en distintas ubicaciones |
| Datos de entrenamiento para modelos de ML | Científicos de datos | Crear modelos de predicción salarial a partir de datos históricos |
La propia investigación de Indeed Hiring Lab confirma que los datos de las publicaciones reflejan de cerca los datos BLS JOLTS y pueden servir como proxy casi en tiempo real de las condiciones del mercado laboral estadounidense. Los hedge funds usan la velocidad de publicación de vacantes como señal de datos alternativos. Los equipos de RR. HH. comparan la compensación usando rangos salariales extraídos. Y los reclutadores construyen listas de prospectos a partir de empresas que están contratando activamente.
Un apunte práctico: los datos salariales en Indeed están mejorando, pero siguen incompletos. A mediados de 2025, aproximadamente el 59% de las ofertas en EE. UU. incluían información salarial, pero solo alrededor del 22% daban una cifra exacta; el resto mostraba rangos. Cualquier análisis salarial basado en datos de Indeed debe tener en cuenta esa escasez.
Cómo elegir tu método para extraer Indeed con Python
No existe una única forma "correcta" de extraer Indeed. La mejor opción depende de tu nivel, de cuántos datos necesites y de cuánto mantenimiento estés dispuesto a asumir. He probado los cuatro enfoques principales, y así se comparan:
| Criterio | BS4 + Requests | Selenium | JSON oculto (window.mosaic) | Sin código (Thunderbit) |
|---|---|---|---|---|
| Dificultad | Principiante | Intermedio | Intermedio-avanzado | Ninguna (2 clics) |
| Velocidad | Rápida | Lenta (renderizado del navegador) | Rápida | Rápida (scraping en la nube) |
| Contenido renderizado por JS | No | Sí | Sí (datos incrustados) | Sí |
| Resistencia anti-bot | Baja | Media (detectable) | Media-alta | Alta (gestionada automáticamente) |
| Mantenimiento cuando cambia el HTML | Alto (los selectores se rompen) | Alto | Medio (la estructura JSON es más estable) | Ninguno (la IA se adapta) |
| Mejor para | Prototipos rápidos | Páginas dinámicas, contenido tras inicio de sesión | Datos estructurados a gran escala | Personas no técnicas, resultados rápidos |
Esta guía recorre cada método. Si eres desarrollador de Python, te conviene leer las secciones de BS4, JSON oculto y Selenium. Si no programas, o simplemente estás cansado de depurar errores 403, salta directamente a la sección de Thunderbit.
Antes de empezar
- Dificultad: Principiante a intermedio (secciones de Python); ninguna (sección de Thunderbit)
- Tiempo necesario: ~20–60 minutos para configurar Python y hacer la primera extracción; ~2 minutos con Thunderbit
- Lo que necesitarás: Python 3.9+, un editor de código, navegador Chrome y, para la ruta sin código, la extensión de Chrome de Thunderbit
Configurar tu entorno de Python para extraer Indeed
Antes de escribir código de scraping, deja listo el entorno.
Instala las bibliotecas necesarias
Crea un entorno virtual e instala los paquetes que vas a necesitar:
python -m venv indeed_env
source indeed_env/bin/activate # En Windows: indeed_env\Scripts\activate
# Para el enfoque HTTP + análisis
pip install requests beautifulsoup4 lxml httpx
# Para el enfoque de JSON oculto (recomendado)
pip install curl_cffi parsel tenacity
# Para el enfoque de automatización del navegador
pip install selenium
Algunas notas:
curl_cffies el valor predeterminado en 2026 para extraer sitios protegidos por Cloudflare. Imita huellas TLS reales de navegadores, algo querequestsyhttpxno pueden hacer. Más adelante explico por qué esto importa en la sección anti-bot.- Selenium 4.6+ incluye Selenium Manager, así que ya no necesitas descargar ChromeDriver manualmente: gestiona el binario del navegador automáticamente.
- Usa
lxmlcomo backend del analizador de BeautifulSoup. Es aproximadamente 1,5 veces más rápido quehtml.parserde la biblioteca estándar.
Crea la estructura de tu proyecto
Mantenlo simple:
indeed_scraper/
├── scraper.py
├── requirements.txt
└── output/
Todos los ejemplos de código de abajo se basan en scraper.py.
Cómo extraer Indeed con Python usando BeautifulSoup
Este es el enfoque apto para principiantes: usar requests para obtener la página y BeautifulSoup para analizar el HTML. Es el más rápido de montar, pero también el más frágil en Indeed.
Paso 1: construye la URL de búsqueda de Indeed
Las URL de búsqueda de Indeed siguen un patrón predecible:
https://www.indeed.com/jobs?q=<query>&l=<location>&start=<offset>
Por ejemplo, buscar "data analyst" en "Austin, TX" empezando desde la primera página:
from urllib.parse import urlencode
params = {
"q": "data analyst",
"l": "Austin, TX",
"start": 0,
}
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
print(url)
# https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX&start=0
Indeed pagina en incrementos de 10, con un tope duro de 1.000 resultados (start <= 990). Cualquier valor por encima de 990 devuelve silenciosamente la misma página.
Paso 2: envía una solicitud HTTP con cabeceras adecuadas
Indeed bloquea al instante las solicitudes con cadenas de user-agent por defecto de Python. Necesitas cabeceras realistas:
import requests
headers = {
"User-Agent": (
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36"
),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br",
"Referer": "https://www.indeed.com/",
}
response = requests.get(url, headers=headers, timeout=30)
print(response.status_code)
Si obtienes un 200, entraste; por ahora. Si obtienes un 403, Cloudflare te ha detectado. Más abajo explico cómo sobrevivir a eso.
Paso 3: analiza las ofertas desde el HTML
Usa BeautifulSoup para seleccionar los elementos de las tarjetas de empleo. Apunta a atributos data-testid, que son más estables que los nombres de clase CSS aleatorios de Indeed:
from bs4 import BeautifulSoup
soup = BeautifulSoup(response.text, "lxml")
cards = soup.find_all("div", attrs={"data-testid": "slider_item"})
jobs = []
for card in cards:
title_el = card.find("h2", class_="jobTitle")
title = title_el.get_text(strip=True) if title_el else None
company = card.find(attrs={"data-testid": "company-name"})
location = card.find(attrs={"data-testid": "text-location"})
link = title_el.find("a")["href"] if title_el and title_el.find("a") else None
jobs.append({
"title": title,
"company": company.get_text(strip=True) if company else None,
"location": location.get_text(strip=True) if location else None,
"url": f"https://www.indeed.com{link}" if link else None,
})
print(f"Encontrados {len(jobs)} empleos")
Paso 4: maneja la paginación
Recorre las páginas incrementando el parámetro start:
import time, random
all_jobs = []
for page in range(0, 50, 10): # Primeras 5 páginas
params["start"] = page
url = f"https://www.indeed.com/jobs?{urlencode(params)}"
response = requests.get(url, headers=headers, timeout=30)
# ... analizar como arriba ...
all_jobs.extend(jobs)
time.sleep(random.uniform(3, 6))
Limitaciones de este enfoque
Voy a ser claro: BS4 + Requests es el método más débil para Indeed en 2026. requests usa la biblioteca TLS estándar de Python, que produce una huella JA3 que Cloudflare identifica al instante como "no es un navegador". Tampoco admite HTTP/2, que es lo que sirve Indeed. Probablemente te bloquearán después de unas pocas páginas. ¿Y los selectores CSS? Indeed rota nombres de clase como css-1m4cuuf y jobsearch-JobComponent-embeddedBody-1n0gh5s con frecuencia, así que cualquier selector que se apoye en ellos es una bomba de tiempo.
Usa este método para prototipos rápidos de una sola página. Para cualquier cosa a escala, usa el enfoque de JSON oculto.
Cómo extraer Indeed con Python usando datos JSON ocultos
Este es el método que recomiendo para la mayoría de los desarrolladores de Python. En lugar de analizar elementos HTML frágiles, extraes datos estructurados de una variable JavaScript incrustada en el código fuente de Indeed: window.mosaic.providerData["mosaic-provider-jobcards"].
Cada campo que te interesa —título del puesto, empresa, ubicación, salario, clave del empleo, fecha de publicación, indicador de remoto— ya está en ese bloque JSON. No hace falta ejecutar JavaScript. El esquema ha sido estable al menos desde 2023, así que es mucho más resistente que los selectores del DOM.
Paso 1: obtén el HTML de la página
Usa curl_cffi en lugar de requests: imita huellas TLS reales de navegadores, algo crítico para sobrevivir a Cloudflare:
from curl_cffi import requests as cffi_requests
response = cffi_requests.get(
"https://www.indeed.com/jobs?q=python+developer&l=Remote&start=0",
impersonate="chrome124",
headers={
"Accept-Language": "en-US,en;q=0.9",
"Referer": "https://www.indeed.com/",
},
timeout=30,
)
print(response.status_code, len(response.text))
¿Por qué curl_cffi? Es un binding de Python sobre curl-impersonate, que reproduce exactamente el ClientHello TLS, el frame HTTP/2 SETTINGS y el orden de las cabeceras de navegadores reales. Es el único cliente HTTP de Python mantenido activamente que derrota tanto JA3/JA4 como la huella H2 de Akamai en una sola llamada. Los objetivos de impersonación compatibles incluyen chrome120, chrome124, chrome131, Safari y variantes de Edge.
Paso 2: extrae el JSON con una expresión regular
El bloque JSON está incrustado en una etiqueta <script>. Extráelo con una regex:
import re, json
MOSAIC_RE = re.compile(
r'window\.mosaic\.providerData\["mosaic-provider-jobcards"\]=(\{.+?\});',
re.DOTALL,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
print(f"Encontrados {len(results)} empleos en el JSON oculto")
else:
print("No se encontró el JSON oculto: posible bloqueo o cambio de página")
Paso 3: analiza los campos del empleo desde el JSON
Cada elemento de results contiene más datos de los que se ven en la página:
jobs = []
for job in results:
jobs.append({
"jobkey": job["jobkey"],
"title": job["title"],
"company": job.get("company"),
"location": job.get("formattedLocation"),
"remote": job.get("remoteLocation"),
"salary": (job.get("salarySnippet") or {}).get("text"),
"posted": job.get("formattedRelativeTime"),
"job_type": job.get("jobTypes"),
"easy_apply": job.get("indeedApplyEnabled"),
"url": f"https://www.indeed.com/viewjob?jk={job['jobkey']}",
})
El JSON suele incluir estimaciones salariales, atributos taxonómicos (etiquetas de habilidades) y valoraciones de empresa que no siempre son visibles en el HTML renderizado.
Paso 4: extrae varias páginas
Usa tierSummaries en el JSON para entender el total de resultados y luego recorre las páginas:
import time, random
all_jobs = []
for start in range(0, 50, 10): # Primeras 5 páginas
url = f"https://www.indeed.com/jobs?q=python+developer&l=Remote&start={start}&sort=date"
response = cffi_requests.get(
url,
impersonate="chrome124",
headers={"Accept-Language": "en-US,en;q=0.9", "Referer": "https://www.indeed.com/"},
timeout=30,
)
match = MOSAIC_RE.search(response.text)
if match:
data = json.loads(match.group(1))
results = data["metaData"]["mosaicProviderJobCardsModel"]["results"]
all_jobs.extend([{
"jobkey": j["jobkey"],
"title": j["title"],
"company": j.get("company"),
"location": j.get("formattedLocation"),
"salary": (j.get("salarySnippet") or {}).get("text"),
"url": f"https://www.indeed.com/viewjob?jk={j['jobkey']}",
} for j in results])
time.sleep(random.uniform(3, 7))
print(f"Total: {len(all_jobs)} empleos extraídos")
Por qué el JSON oculto es más resistente
La estructura window.mosaic.providerData cambia con menos frecuencia que los nombres de clase CSS. Obtienes datos limpios y estructurados sin analizar HTML desordenado. Dicho esto, sigues necesitando mitigación anti-bot —cabeceras, retrasos, proxies—, que veremos a continuación.
Cómo extraer Indeed con Python usando Selenium
Selenium es el enfoque de automatización del navegador. Es útil cuando necesitas interactuar con la página: hacer clic en paneles de detalle de empleo, manejar contenido tras inicio de sesión o extraer descripciones cargadas dinámicamente que no están en el HTML inicial.
Cuándo usar Selenium en lugar de clientes HTTP
- Indeed carga parte del contenido de forma dinámica (descripciones completas en el panel de la derecha)
- Necesitas extraer páginas que requieren estado de sesión o inicio de sesión
- Haces scraping a pequeña escala, donde la velocidad no es crítica
Guía rápida
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.chrome.options import Options
import time
options = Options()
options.add_argument("--disable-blink-features=AutomationControlled")
# options.add_argument("--headless=new") # El modo headless es más detectable; úsalo con cautela
driver = webdriver.Chrome(options=options)
driver.get("https://www.indeed.com/jobs?q=data+engineer&l=New+York")
time.sleep(3)
cards = driver.find_elements(By.CSS_SELECTOR, "[data-testid='slider_item']")
for card in cards:
try:
title = card.find_element(By.CSS_SELECTOR, "h2.jobTitle").text
company = card.find_element(By.CSS_SELECTOR, "[data-testid='company-name']").text
location = card.find_element(By.CSS_SELECTOR, "[data-testid='text-location']").text
print(f"{title} | {company} | {location}")
except Exception:
continue
driver.quit()
Limitaciones
Selenium es lento: cada página requiere renderizado completo del navegador. Chrome en modo headless es detectable por el sistema anti-bot de Indeed (Cloudflare comprueba navigator.webdriver, las cadenas del proveedor WebGL, el número de complementos y más). Incluso undetected-chromedriver solo retrasa la detección; no la evita de forma permanente. Y, como en BS4, tus selectores se romperán cuando Indeed actualice su interfaz.
Para la mayoría de los casos de uso, el enfoque de JSON oculto te da los mismos datos más rápido y con menos mantenimiento. Reserva Selenium para los casos límite en los que realmente necesites un navegador.
Cómo evitar errores 403 al extraer Indeed con Python
Esta es la sección que más importa. Si llegaste aquí tras una búsqueda frustrante en Google, estás en el lugar correcto.
Por qué Indeed bloquea tu scraper
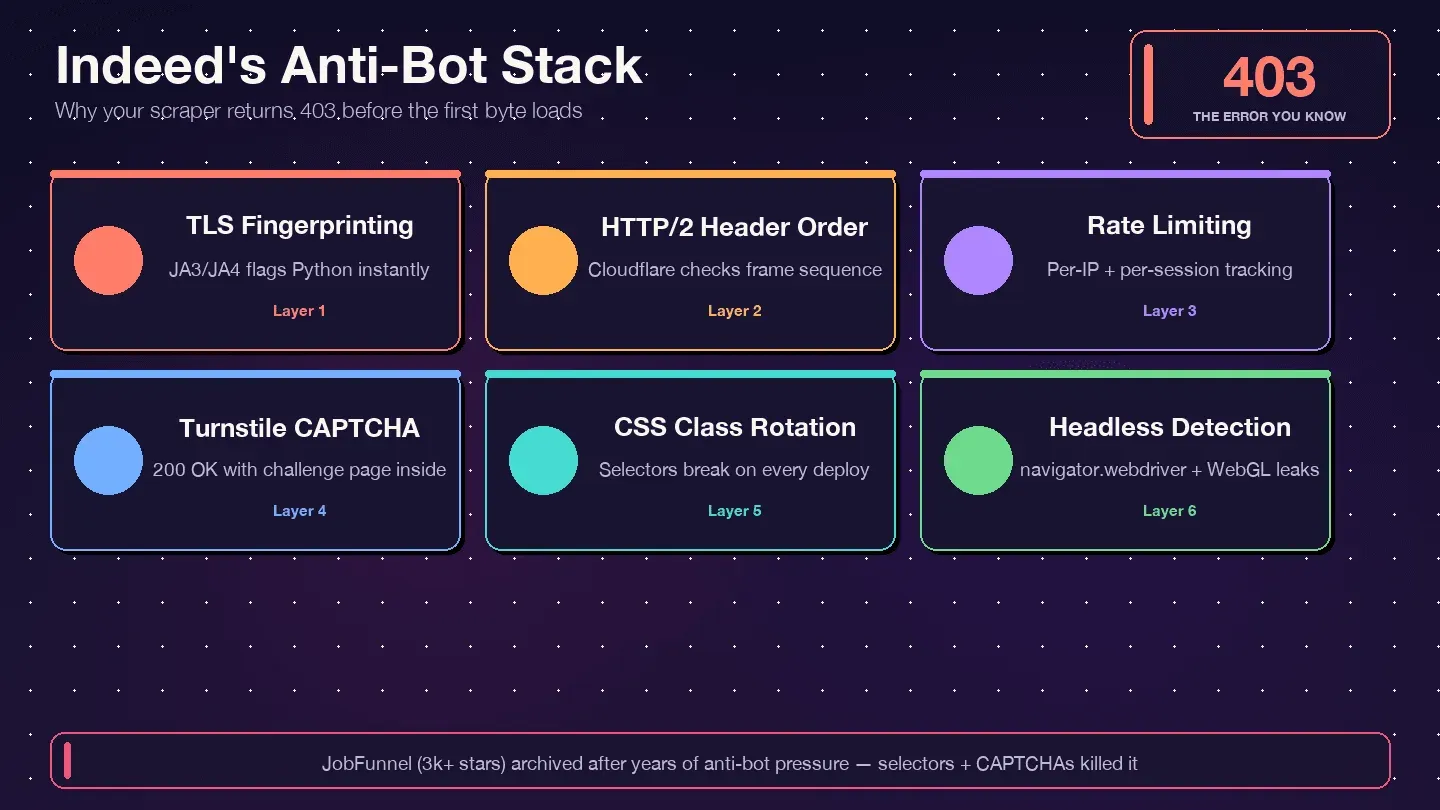
Indeed usa Cloudflare Bot Management junto con Cloudflare Turnstile — no DataDome, no PerimeterX. Las cabeceras de respuesta lo confirman: server: cloudflare, cf-ray y la cookie de gestión de bots __cf_bm. Cloudflare inspecciona tu huella TLS (JA3/JA4), el orden de las cabeceras HTTP/2, los patrones de solicitud y las señales de comportamiento del navegador. Si alguno de esos elementos parece no humano, recibes un 403, un 429, un 503 o, en el caso más engañoso, un 200 OK con una página de desafío de Turnstile en lugar de datos reales de empleo.
Rota el User-Agent y las cabeceras de la solicitud
Un único User-Agent estático es la forma más rápida de ser bloqueado. Rota entre un conjunto de cadenas actuales y realistas. Importante: los campos de versión menor de Chrome están fijados en 0.0.0 desde la reducción de User-Agent; no inventes versiones menores distintas de cero o los sistemas anti-bot lo detectarán.
import random
USER_AGENTS = [
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 "
"(KHTML, like Gecko) Chrome/145.0.0.0 Safari/537.36 Edg/145.0.3800.97",
"Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:128.0) Gecko/20100101 Firefox/128.0",
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/605.1.15 "
"(KHTML, like Gecko) Version/17.4 Safari/605.1.15",
]
headers = {
"User-Agent": random.choice(USER_AGENTS),
"Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
"Accept-Language": "en-US,en;q=0.9",
"Accept-Encoding": "gzip, deflate, br, zstd",
"Referer": "https://www.indeed.com/",
"Sec-Fetch-Dest": "document",
"Sec-Fetch-Mode": "navigate",
"Sec-Fetch-Site": "same-origin",
}
Asegúrate también de que tus Client Hints sec-ch-ua coincidan con la versión del User-Agent. Un sec-ch-ua: "Chrome";v="131" junto con un User-Agent que afirma ser Chrome 145 es una señal de alarma inmediata.
Añade retrasos aleatorios entre solicitudes
Los intervalos fijos se detectan por patrones. Usa variación aleatoria:
import time, random
# Entre cada solicitud
time.sleep(random.uniform(3, 6))
# Al reintentar tras un bloqueo
def backoff_sleep(attempt):
base = 4
sleep_time = base * (2 ** attempt) + random.uniform(0, 2)
time.sleep(min(sleep_time, 60))
El consenso práctico de ScrapeOps y WebScraping.AI es dejar entre 3 y 6 segundos entre solicitudes por IP, con un límite duro de unas 100 solicitudes por IP por sesión antes de rotar.
Usa rotación de proxies
Este es el mayor determinante del éxito. Los proxies de centros de datos de rangos AWS/GCP obtienen aproximadamente entre un 5% y un 15% de éxito en objetivos protegidos por Cloudflare Enterprise, lo que en la práctica los vuelve inutilizables en Indeed. Los proxies residenciales, junto con la huella TLS correcta, suben hasta un 80%–95% de éxito.
PROXIES = [
"http://user:pass@us.residential.example:7777",
"http://user:pass@us.residential.example:7778",
"http://user:pass@us.residential.example:7779",
]
proxy = random.choice(PROXIES)
response = cffi_requests.get(
url,
impersonate="chrome124",
headers=headers,
proxies={"https": proxy},
timeout=30,
)
En 2026, el precio de los proxies residenciales ronda los $4–8,50 por GB, según el proveedor y el nivel de compromiso. Para Indeed en concreto, empieza con un pequeño conjunto y escala según lo necesites.
Maneja con gracia los códigos 403, 429 y 503
No vuelvas a intentar a ciegas. Cada código significa algo distinto:
def fetch_with_retry(url, proxy_pool, max_retries=5):
for attempt in range(max_retries):
proxy = random.choice(proxy_pool)
headers["User-Agent"] = random.choice(USER_AGENTS)
try:
r = cffi_requests.get(
url,
impersonate=random.choice(["chrome124", "chrome120", "edge101"]),
headers=headers,
proxies={"https": proxy},
timeout=30,
)
# Comprueba el caso engañoso de "200 con desafío"
if r.status_code == 200 and "cf-turnstile" not in r.text and "Just a moment" not in r.text:
return r
if r.status_code == 403:
print(f"403: bloqueado. Rotando proxy, intento {attempt + 1}")
elif r.status_code == 429:
print("429: límite de velocidad. Reduciendo el ritmo.")
elif r.status_code == 503:
print("503: servidor saturado o desafío JS.")
backoff_sleep(attempt)
except Exception as e:
print(f"Error en la solicitud: {e}")
backoff_sleep(attempt)
raise RuntimeError(f"Falló después de {max_retries} reintentos: {url}")
El caso de 200 con desafío es el más difícil. Busca siempre en el cuerpo de la respuesta marcadores como cf-turnstile o Just a moment antes de tratar un 200 como éxito.
La alternativa más fácil: deja que Thunderbit gestione el anti-bot por ti
Para quienes no quieren construir y mantener grupos de proxies, rotación de cabeceras e impersonación de huellas TLS, el scraping en la nube de Thunderbit gestiona automáticamente CAPTCHAs, rotación de proxies y protecciones anti-bot. Sin configuración de proxies, sin configuración de curl_cffi, sin librerías para resolver CAPTCHA. Es el camino de menor resistencia cuando solo necesitas los datos.
Por qué tu scraper de Indeed sigue rompiéndose (y cómo arreglarlo)
El muro 403 es el dolor agudo. El dolor crónico es el mantenimiento: scrapers que funcionan hoy se rompen la semana siguiente y devuelven silenciosamente datos vacíos o resultados obsoletos.
Cómo Indeed rompe tus selectores
Indeed rota con agresividad los nombres de clase CSS. La guía de Bright Data advierte explícitamente que clases como css-1m4cuuf y css-1rqpxry "parecen generadas aleatoriamente, probablemente en tiempo de compilación". Las pruebas A/B hacen que distintas sesiones vean diseños de página diferentes. Y la reestructuración del DOM ocurre sin aviso.
La historia de JobFunnel es ilustrativa. Un colaborador informó: "CaptchaBuster ha mitigado con éxito el captcha, y la razón de seguir extrayendo la página sin éxito [es] el uso de selectores obsoletos de Beautiful Soup." El scraper no estaba bloqueado: estaba leyendo los elementos equivocados.
Estrategia: prioriza el JSON oculto sobre el análisis del DOM
El bloque window.mosaic.providerData ha mantenido un esquema estable desde al menos 2023. La ruta metaData.mosaicProviderJobCardsModel.results[] sigue siendo la canónica en 2026. Los selectores del DOM se rompen mensualmente. La extracción JSON, si se rompe, lo hace como mucho una vez al año.
Estrategia: usa atributos de datos en lugar de nombres de clase
Cuando necesites tocar el DOM, apunta a atributos funcionales:
| Selector | Propósito |
|---|---|
[data-testid="slider_item"] | Contenedor de cada tarjeta de empleo |
[data-testid="job-title"] o h2.jobTitle > a | Enlace del título del empleo |
[data-testid="company-name"] | Nombre del empleador |
[data-testid="text-location"] | Texto de la ubicación |
data-jk="<jobkey>" en cada tarjeta | El punto de enganche más estable: sin cambios desde 2019 |
Añade comprobaciones de aserción para detectar selectores obsoletos
Nunca dejes que tu scraper siga funcionando en silencio con cero resultados. Añade una comprobación después de cada extracción:
results = parse_hidden_json(html)
assert len(results) > 0, (
f"Indeed devolvió un conjunto de resultados vacío en start={start} — "
"posible bloqueo, CAPTCHA o deriva en los selectores. "
f"Primeros 500 caracteres de la respuesta: {html[:500]}"
)
Registra los primeros 500–2000 caracteres de la respuesta bruta cuando falle. Así podrás saber enseguida si recibiste un desafío de Turnstile, un muro de inicio de sesión o un cambio de esquema. Ejecuta una prueba de humo diaria a nivel de CI contra una consulta fija (por ejemplo, q=python&l=remote) que verifique que el número de resultados no es cero.
La alternativa con IA: scrapers que no se rompen
La IA de Thunderbit lee la estructura de la página desde cero en cada ejecución; no depende de selectores hardcodeados ni de patrones regex. Cuando Indeed cambia su HTML, Thunderbit se adapta automáticamente. Esto aborda directamente la carga de mantenimiento que los usuarios de foros señalan constantemente como su principal frustración. Si alguna vez te has despertado con un mensaje en Slack diciendo "el scraper vuelve a devolver filas vacías", sabes lo valioso que es no tener que arreglarlo.
Extraer Indeed sin escribir Python: la alternativa sin código
Todas las guías competidoras asumen que vas a escribir código Python. Pero los datos de los foros cuentan otra historia. Los usuarios dicen cosas como "es simplemente muy difícil, con fallos y errores constantes" y algunos sugieren contratar a alguien en Fiverr solo para obtener los datos. Si eso te suena familiar, esta sección es tu salida de emergencia.
Cómo extraer Indeed con Thunderbit (paso a paso)
Paso 1: Instala la extensión de Chrome de Thunderbit desde Chrome Web Store. Puedes empezar gratis.
Paso 2: Abre una página de resultados de búsqueda de Indeed en tu navegador; por ejemplo, https://www.indeed.com/jobs?q=data+analyst&l=Austin%2C+TX.
Paso 3: Haz clic en el icono de Thunderbit en la barra del navegador y luego en "AI Suggest Fields". La IA de Thunderbit analiza la página y detecta automáticamente columnas como título del puesto, empresa, ubicación, salario, URL del empleo y fecha de publicación. Puedes revisar y ajustar los campos sugeridos: quitar columnas que no necesites o añadir columnas personalizadas describiendo en lenguaje natural lo que quieres.
Paso 4: Haz clic en "Scrape". Thunderbit extrae los datos de la página y los muestra en una tabla estructurada. Verás filas de ofertas con los campos que configuraste.
Enriquecer con scraping de subpáginas
Después de extraer la página de listados, haz clic en "Scrape Subpages" para que Thunderbit visite cada página de detalle del empleo. Extrae descripciones completas, requisitos, beneficios y enlaces de solicitud, sin configuración adicional. Es el equivalente a escribir un segundo scraper en Python para visitar cada URL /viewjob?jk=<jobkey>, solo que se hace con un clic.
Manejar la paginación automáticamente
Thunderbit gestiona automáticamente la paginación basada en clics de Indeed. No hace falta construir manualmente URL con offsets ni escribir bucles de paginación. Va avanzando por las páginas y agregando los resultados.
Exporta a tus herramientas favoritas
Exporta los datos extraídos a CSV, Excel, Google Sheets, Airtable o Notion — totalmente gratis. No necesitas escribir código csv.writer() ni pandas.to_csv().
Cuándo usar Python frente a Thunderbit
| Escenario | Mejor herramienta |
|---|---|
| Canales de datos personalizados, automatización programada con cron/Airflow | Python |
| Integración en una base de código más grande | Python |
| Lógica de análisis altamente personalizada | Python |
| Investigación puntual o análisis de mercado | Thunderbit |
| Miembros del equipo sin perfil técnico necesitan datos | Thunderbit |
| Obtener los datos ya, sin depurar errores 403 | Thunderbit |
| Enriquecimiento de subpáginas sin configuración | Thunderbit |
Comparación de tiempo: configuración de Python + depuración anti-bot = horas o días (sobre todo la primera vez). Thunderbit = menos de 2 minutos para obtener los mismos datos. No digo que Python esté mal; digo que depende de lo que necesites.
¿Es legal extraer Indeed? Lo que necesitas saber
Ninguna de las guías mejor posicionadas sobre scraping de Indeed aborda la legalidad, lo cual sorprende dado lo frecuente que es la pregunta "¿es legal extraer Indeed?" en los foros. Esto no es asesoría legal, pero aquí va el panorama.
Los términos de servicio de Indeed
Los Términos de servicio de Indeed (indeed.com/legal) no contienen una cláusula general de "prohibido scrapear". La única prohibición explícita de automatización está en la sección A.3.5, que veta "el uso de cualquier automatización, scripting o bots para automatizar el proceso Indeed Apply". Eso es un alcance estrecho, limitado al flujo de solicitud, no a la lectura pasiva de ofertas públicas. La principal herramienta de aplicación de Indeed es técnica —desafíos de Cloudflare, bloqueos de IP, huellas de dispositivos—, no judicial.
Precedente legal relevante
El caso estadounidense más citado es hiQ Labs v. LinkedIn. El Noveno Circuito sostuvo en abril de 2022 que extraer datos de acceso público "probablemente no viola la CFAA" (Computer Fraud and Abuse Act). Sin embargo, más tarde se determinó que hiQ incurrió en incumplimiento de contrato porque sus empleados habían creado perfiles falsos de LinkedIn y aceptado los Términos de servicio.
Más recientemente, Meta v. Bright Data (N.D. Cal., enero de 2024) produjo una resolución aún más clara. La jueza Chen sostuvo que los Términos de Facebook e Instagram "no prohíben la extracción de datos públicos cuando la sesión está cerrada". Meta retiró voluntariamente las reclamaciones restantes al mes siguiente.
El robots.txt de Indeed
El robots.txt de Indeed desautoriza en general /jobs/ y /job/ para el User-agent: * por defecto, pero permite explícitamente a Googlebot y Bingbot acceder a /viewjob?, es decir, a las páginas individuales de detalle del empleo. Los rastreadores de entrenamiento de IA (GPTBot, CCBot, anthropic-ai) están fuertemente restringidos. robots.txt no es legalmente vinculante en EE. UU., pero respetarlo es una buena práctica y una prueba de buena fe.
Pautas prácticas para un scraping responsable
- Extrae solo datos de acceso público: nunca inicies sesión, nunca crees cuentas falsas
- Respeta los límites de velocidad: 1 solicitud cada 3–6 segundos por IP, concurrencia de un solo dígito
- No republiques los datos extraídos como si fueran tu propia bolsa de empleo
- Usa los datos para investigación personal o interna, no para reventa comercial sin permiso
- Elimina o hashea la PII que no necesites; fija un límite de retención para datos vinculados a personas
- Si operas a gran escala o en la UE/Reino Unido, consulta a un abogado: las obligaciones de transparencia del artículo 14 del RGPD se aplican a datos personales extraídos
El espectro de riesgo: la automatización personal de la búsqueda de empleo está en el extremo bajo. La reventa comercial a gran escala de los datos de Indeed está en el extremo alto.
Conclusión y puntos clave
Extraer Indeed con Python es posible, pero no es un proyecto de fin de semana que dejas configurado y te olvidas. La protección Cloudflare de Indeed, los selectores que rotan y las medidas anti-bot agresivas implican que debes abordar esto con las herramientas adecuadas y las expectativas correctas.
Esto es lo que me quedaría de todo esto:
- Indeed es la fuente más rica de datos del mercado laboral en la web — 350 millones de visitas mensuales, 130 millones de anuncios —, pero se defiende con fuerza contra los scrapers.
- La extracción de JSON oculto (
window.mosaic.providerData) es el enfoque de Python más resistente. El esquema ha sido estable durante años, mientras que los selectores CSS se rompen cada mes. curl_cfficon impersonación de navegador es el cliente HTTP predeterminado en 2026 para sitios protegidos por Cloudflare.requestsyhttpxse bloquean solo por la huella TLS.- Usa siempre cabeceras rotativas, retrasos aleatorios y proxies residenciales para evitar errores 403. Los proxies de centros de datos son casi inútiles frente a Cloudflare Enterprise.
- Añade comprobaciones de aserción para saber de inmediato cuándo se rompen los selectores o cuando te están sirviendo una página de desafío en lugar de datos de empleo.
- Para usuarios no técnicos o cualquiera que solo quiera resultados rápidos, Thunderbit ofrece una vía sin código, impulsada por IA, que se adapta automáticamente a los cambios del sitio: sin proxies, sin depuración, sin mantenimiento.
Si quieres probar la ruta sin código, Thunderbit ofrece un plan gratuito para que lo pruebes en Indeed sin compromiso. Y si vas por la ruta de Python, los ejemplos de código anteriores son un buen punto de partida; solo recuerda tratar la resistencia anti-bot como una prioridad de primer nivel, no como algo secundario.
Para más información sobre enfoques y herramientas de web scraping, consulta nuestras guías sobre cómo hacer web scraping con Python, las mejores herramientas automáticas de web scraping y cómo hacer web scraping sin que te bloqueen. También puedes ver tutoriales en el canal de YouTube de Thunderbit.
Prueba Thunderbit para extraer datos de Indeed más rápido Get Started Free
Preguntas frecuentes
¿Qué bibliotecas de Python son mejores para extraer Indeed?
Para solicitudes HTTP, curl_cffi es la mejor opción en 2026: imita huellas TLS reales de navegadores, algo esencial para saltarse Cloudflare. httpx con HTTP/2 es una alternativa razonable para objetivos menos protegidos. Para análisis HTML, BeautifulSoup4 con lxml sigue siendo el estándar. Para automatización del navegador, Playwright (con playwright-stealth) o undetected-chromedriver funcionan, aunque ambos son cada vez más detectables. El enfoque con regex sobre el JSON oculto (window.mosaic.providerData) evita por completo la necesidad de análisis pesado.
¿Por qué sigo recibiendo errores 403 al extraer Indeed?
Indeed usa Cloudflare Bot Management, que inspecciona tu huella TLS (JA3/JA4), el orden de las cabeceras HTTP/2, los patrones de solicitud y el comportamiento del navegador. Si usas requests sin más, tu huella TLS te identifica al instante como un script de Python: el 403 llega antes incluso de que lean tus cabeceras. Soluciónalo pasando a curl_cffi con impersonación de navegador, rotando cadenas realistas de User-Agent, añadiendo retrasos aleatorios (3–6 segundos) y usando proxies residenciales. También revisa el caso de "200 con desafío de Turnstile": busca marcadores cf-turnstile en el cuerpo de la respuesta.
¿Puedo extraer Indeed sin programar?
Sí. Herramientas como Thunderbit te permiten extraer ofertas de Indeed en unos pocos clics: instala la extensión de Chrome, abre una página de búsqueda de Indeed, haz clic en "AI Suggest Fields" y luego en "Scrape". La IA de Thunderbit detecta automáticamente campos como el título del puesto, la empresa, la ubicación y el salario. Gestiona automáticamente la paginación, el enriquecimiento de subpáginas (descripciones completas) y las protecciones anti-bot. Exporta a CSV, Google Sheets, Airtable o Notion gratis.
¿Con qué frecuencia cambia la estructura HTML de Indeed?
Indeed rota con regularidad los nombres de clase CSS (por ejemplo, css-1m4cuuf, cadenas hasheadas aleatorias) y reestructura elementos del DOM sin aviso. Las pruebas A/B hacen que distintos usuarios vean diseños diferentes al mismo tiempo. El enfoque de JSON oculto (window.mosaic.providerData) es mucho más estable: el esquema se ha mantenido consistente desde al menos 2023. Cuando tengas que usar selectores del DOM, apunta a atributos data-testid y data-jk (clave del empleo) en lugar de clases CSS.
¿Es legal extraer Indeed?
La extracción, con la sesión cerrada, de URL públicas de empleos en Indeed probablemente no genere responsabilidad bajo la CFAA en EE. UU., según la sentencia del Noveno Circuito en hiQ v. LinkedIn (2022) y la decisión de Meta v. Bright Data (2024). Los Términos de servicio de Indeed prohíben automatizar específicamente el proceso Apply, no la lectura pasiva de ofertas públicas. Dicho esto, actúa siempre con responsabilidad: no inicies sesión, no crees cuentas falsas, respeta los límites de velocidad, no republiques los datos como si fueran tu propia bolsa de empleo y maneja con cuidado cualquier dato personal (nombres de reclutadores, correos) bajo RGPD/CCPA. Para operaciones a escala comercial, consulta a un abogado.
Más información
- Cómo hacer web scraping sin que te bloqueen en Python
- Web scraping en Python: evita bloqueos con un uso inteligente de proxies
- Cómo escribir un web scraper con Python: de principio a fin
- Cómo extraer datos de un sitio web usando Python de forma eficiente
- Cómo extraer datos usando Python: tutorial para principiantes




