

Google Shopping procesa más de 1.2 mil millones de búsquedas de productos al mes. Eso quiere decir que hay una barbaridad de datos sobre precios, tendencias de productos e información de vendedores, todo reunido en tu navegador y sacado de miles de comercios.
Sacar esos datos de Google Shopping y llevarlos a una hoja de cálculo no siempre es pan comido. He probado bastantes enfoques, desde extensiones sin código hasta scripts completos en Python, y la experiencia va de “vaya, esto fue facilísimo” a “llevo tres días depurando CAPTCHAs y ya quiero tirar la toalla”. La mayoría de las guías sobre este tema da por hecho que eres desarrollador Python, pero, en mi experiencia, mucha de la gente que necesita datos de Google Shopping son responsables de ecommerce, analistas de precios y profesionales de marketing que solo quieren los números, sin ponerse a programar. Por eso, esta guía cubre tres métodos, ordenados de más fácil a más técnico, para que elijas el camino que mejor encaje con tu nivel y el tiempo que tengas.
¿Qué es exactamente la información de Google Shopping?
Google Shopping es un buscador de productos. Escribe “auriculares inalámbricos con cancelación de ruido” y Google te muestra resultados de decenas de tiendas online: títulos, precios, vendedores, valoraciones, imágenes y enlaces. Es como un catálogo vivo, siempre al día, de todo lo que se vende en internet.
¿Por qué extraer datos de Google Shopping?
Una sola ficha de producto dice muy poco. Pero cientos de fichas, organizadas en una hoja de cálculo, sí dejan ver patrones.
Estos son los casos de uso más habituales que he visto:
| Caso de uso | Quién se beneficia | Qué se busca |
|---|---|---|
| Análisis de precios de la competencia | Equipos de ecommerce, analistas de precios | Precios de rivales, patrones de rebajas, cambios de precio a lo largo del tiempo |
| Detección de tendencias de producto | Equipos de marketing, product managers | Productos nuevos, categorías en crecimiento, velocidad de reseñas |
| Inteligencia publicitaria | Responsables de PPC, equipos de growth | Listados patrocinados, qué vendedores pujan, frecuencia de anuncios |
| Investigación de vendedores/leads | Equipos de ventas, B2B | Comercios activos, nuevos vendedores que entran en una categoría |
| Monitorización de MAP | Brand managers | Distribuidores que incumplen las políticas de precio mínimo anunciado |
| Seguimiento de inventario y surtido | Category managers | Disponibilidad de stock, huecos en el surtido de productos |
El 78% de los minoristas en EE. UU. ya usa herramientas de precios con IA. Las empresas que invierten en inteligencia de precios competitivos han reportado retornos de hasta 29x. Amazon actualiza precios aproximadamente cada 10 minutos. Si todavía revisas los precios de la competencia a mano, la matemática no te favorece.
Extrae datos de Google Shopping con IA Get Started Free
Thunderbit es una extensión de Chrome de AI Web Scraper que ayuda a usuarios de negocio a extraer datos de sitios web mediante IA. Resulta especialmente útil para equipos de ecommerce, analistas de precios y profesionales de marketing que necesitan datos estructurados de Google Shopping sin escribir código.
¿Qué datos se pueden extraer realmente de Google Shopping?
Antes de elegir una herramienta o escribir una sola línea de código, conviene tener claro qué campos están disponibles y cuáles requieren un poco más de trabajo.
Campos de los resultados de búsqueda de Google Shopping
Cuando haces una búsqueda en Google Shopping, cada tarjeta de producto en la página de resultados incluye:
| Campo | Tipo | Ejemplo | Notas |
|---|---|---|---|
| Título del producto | Texto | "Sony WH-1000XM5 Wireless Headphones" | Siempre aparece |
| Precio | Número | $278.00 | Puede mostrar precio rebajado + precio original |
| Vendedor/Tienda | Texto | "Best Buy" | Un mismo producto puede tener varios vendedores |
| Valoración | Número | 4.7 | Sobre 5 estrellas; no siempre se muestra |
| Número de reseñas | Número | 12,453 | A veces no aparece en productos nuevos |
| URL de imagen del producto | URL | https://... | Puede devolver un marcador base64 en la carga inicial |
| Enlace del producto | URL | https://... | Lleva a la página del producto en Google o a la tienda |
| Información de envío | Texto | "Free shipping" | No siempre está presente |
| Etiqueta patrocinado | Booleano | Sí/No | Indica una posición pagada, útil para inteligencia publicitaria |
Campos de las páginas de detalle del producto (datos de subpáginas)
Si entras en la página de detalle de un producto concreto dentro de Google Shopping, puedes acceder a información más rica:
| Campo | Tipo | Notas |
|---|---|---|
| Descripción completa | Texto | Requiere visitar la página del producto |
| Todos los precios de vendedores | Número (varios) | Comparación lado a lado entre comercios |
| Especificaciones | Texto | Varía según la categoría del producto (dimensiones, peso, etc.) |
| Texto de reseñas individuales | Texto | Contenido completo de las opiniones de compradores |
| Resumen de pros y contras | Texto | Google a veces lo genera automáticamente |
Acceder a estos campos implica visitar la subpágina de cada producto después de extraer los resultados de búsqueda. Las herramientas con capacidad de extracción de subpáginas lo hacen automáticamente; más abajo te explico el flujo.
Tres formas de extraer datos de Google Shopping (elige tu camino)

Tres métodos, ordenados de más fácil a más técnico. Elige la fila que encaje contigo y ve directo a esa sección:
| Método | Nivel de dificultad | Tiempo de configuración | Gestión anti-bots | Ideal para |
|---|---|---|---|---|
| Sin código (Thunderbit extensión de Chrome) | Principiante | ~2 minutos | Se gestiona automáticamente | Operaciones de ecommerce, marketing, búsquedas puntuales |
| Python + SERP API | Intermedio | ~30 minutos | La API lo gestiona | Desarrolladores que necesitan acceso programático y repetible |
| Python + Playwright (automatización del navegador) | Avanzado | ~1 hora o más | La gestionas tú | Flujos personalizados, casos límite |
Método 1: extraer datos de Google Shopping sin código (con Thunderbit)
- Dificultad: Principiante
- Tiempo necesario: ~2–5 minutos
- Lo que necesitas: navegador Chrome, extensión Thunderbit para Chrome (el plan gratuito sirve), una búsqueda en Google Shopping
Es la forma más rápida de pasar de “necesito datos de Google Shopping” a “aquí está mi hoja de cálculo”. Sin código, sin claves de API, sin configurar proxies. He guiado a compañeros no técnicos por este flujo docenas de veces y nadie se ha quedado atascado.
Paso 1: instala Thunderbit y abre Google Shopping
Instala Thunderbit AI Web Scraper desde Chrome Web Store y regístrate para una cuenta gratuita.
Después, ve a Google Shopping. Puedes entrar directamente en shopping.google.com o usar la pestaña Shopping en una búsqueda normal de Google. Busca el producto o la categoría que te interese; por ejemplo, “wireless noise-cancelling headphones”.
Deberías ver una cuadrícula de productos con precios, vendedores y valoraciones.
Paso 2: haz clic en “AI Suggest Fields” para detectar columnas automáticamente
Haz clic en el icono de la extensión de Thunderbit para abrir la barra lateral y pulsa “AI Suggest Fields.” La IA analiza la página de Google Shopping y propone columnas como: título del producto, precio, vendedor, valoración, número de reseñas, URL de imagen y enlace del producto.
Revisa los campos sugeridos. Puedes renombrar columnas, quitar las que no necesites o añadir campos personalizados. Si quieres afinar más —por ejemplo, “extraer solo el precio numérico sin el símbolo de moneda”— puedes añadir un Field AI Prompt a esa columna.
Deberías ver una vista previa de la estructura de columnas en el panel de Thunderbit.
Paso 3: haz clic en “Scrape” y revisa los resultados
Pulsa el botón azul “Scrape”. Thunderbit lleva todos los productos visibles a una tabla estructurada.
¿Hay varias páginas? Thunderbit gestiona la paginación automáticamente, ya sea pasando de página o desplazándose para cargar más resultados, según el diseño. Si tienes muchos resultados, puedes elegir entre Cloud Scraping (más rápido, admite hasta 50 páginas a la vez y se ejecuta en la infraestructura distribuida de Thunderbit) o Browser Scraping (usa tu propia sesión de Chrome, útil si Google muestra resultados por región o pide iniciar sesión).
En mis pruebas, extraer 50 productos llevó unos 30 segundos. Hacer lo mismo a mano —abrir cada producto, copiar título, precio, vendedor y valoración— me habría llevado más de 20 minutos.
Paso 4: enriquece los datos con subpáginas
Después de la extracción inicial, haz clic en “Scrape Subpages” en el panel de Thunderbit. La IA visita la página de detalle de cada producto y añade campos adicionales —descripción completa, todos los precios de vendedores, especificaciones y reseñas— a la tabla original.
No hace falta configurar nada más: la IA detecta la estructura de cada página de detalle y extrae los datos relevantes. Yo llegué a montar una matriz completa de precios competitivos (producto + precios de todos los vendedores + especificaciones) para 40 productos en menos de 5 minutos con este método.
Prueba Thunderbit para extraer Google Shopping
Paso 5: exporta a Google Sheets, Excel, Airtable o Notion
Haz clic en “Export” y elige tu destino: Google Sheets, Excel, Airtable o Notion. Todo gratis. También están disponibles descargas en CSV y JSON.
Dos clics para extraer, un clic para exportar. ¿El equivalente en Python? Unas 60 líneas de código, configuración de proxies, gestión de CAPTCHA y mantenimiento continuo.
Método 2: extraer datos de Google Shopping con Python + una SERP API
- Dificultad: Intermedio
- Tiempo necesario: ~30 minutos
- Lo que necesitas: Python 3.10 o superior, librerías
requestsypandas, una clave de SERP API (ScraperAPI, SerpApi o similar)
Si necesitas acceso programático y repetible a datos de Google Shopping, una SERP API es el enfoque en Python más fiable. Medidas anti-bots, renderizado JavaScript, rotación de proxies: todo se resuelve por detrás. Tú envías una petición HTTP y recibes JSON estructurado.
Paso 1: prepara tu entorno de Python
Instala Python 3.12 (la opción más segura para producción en 2025–2026) y los paquetes necesarios:
pip install requests pandas
Regístrate en un proveedor de SERP API. SerpApi ofrece 100 búsquedas gratis al mes; ScraperAPI da 5.000 créditos gratis. Obtén tu clave de API desde el panel.
Paso 2: configura la petición a la API
Aquí tienes un ejemplo mínimo usando el endpoint de Google Shopping de ScraperAPI:
import requests
import pandas as pd
API_KEY = "YOUR_API_KEY"
query = "wireless noise cancelling headphones"
resp = requests.get(
"https://api.scraperapi.com/structured/google/shopping",
params={"api_key": API_KEY, "query": query, "country_code": "us"}
)
data = resp.json()
La API devuelve JSON estructurado con campos como title, price, link, thumbnail, source (vendedor) y rating.
Paso 3: analiza la respuesta JSON y extrae los campos
products = data.get("shopping_results", [])
rows = []
for p in products:
rows.append({
"title": p.get("title"),
"price": p.get("price"),
"seller": p.get("source"),
"rating": p.get("rating"),
"reviews": p.get("reviews"),
"link": p.get("link"),
"thumbnail": p.get("thumbnail"),
})
df = pd.DataFrame(rows)
Paso 4: exporta a CSV o JSON
df.to_csv("google_shopping_results.csv", index=False)
Ideal para lotes: puedes recorrer 50 palabras clave y generar un dataset completo en una sola ejecución. La contrapartida es el coste: las SERP APIs cobran por consulta y, cuando subes a miles de consultas al día, la factura crece. Más sobre precios abajo.
Método 3: extraer datos de Google Shopping con Python + Playwright (automatización del navegador)
- Dificultad: Avanzado
- Tiempo necesario: ~1 hora o más, más mantenimiento continuo
- Lo que necesitas: Python 3.10+, Playwright, proxies residenciales y paciencia
El enfoque de “control total”. Inicias un navegador real, navegas a Google Shopping y extraes datos de la página renderizada. Es el más flexible, pero también el más frágil: los sistemas anti-bots de Google son agresivos y la estructura de la página cambia varias veces al año.
Aviso honesto: he hablado con usuarios que pasaron semanas peleándose con CAPTCHAs y bloqueos de IP con este método. Funciona, pero prepárate para mantenimiento constante.
Paso 1: configura Playwright y los proxies
pip install playwright
playwright install chromium
Vas a necesitar proxies residenciales. Las IPs de centros de datos se bloquean casi al instante; un usuario de un foro lo resumió sin rodeos: “Todas las IPs de AWS serán bloqueadas o recibirán CAPTCHA después de 1/2 resultados”. Servicios como Bright Data, Oxylabs o Decodo ofrecen pools de proxies residenciales desde unos 1–5 dólares/GB.
Configura Playwright con un user-agent realista y tu proxy:
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
browser = p.chromium.launch(
headless=True,
proxy={"server": "http://your-proxy:port", "username": "user", "password": "pass"}
)
context = browser.new_context(
user_agent="Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 ..."
)
page = context.new_page()
Paso 2: entra en Google Shopping y maneja las medidas anti-bots
Construye la URL de Google Shopping y navega:
query = "wireless noise cancelling headphones"
url = f"https://www.google.com/search?udm=28&q={query}&gl=us&hl=en"
page.goto(url, wait_until="networkidle")
Si aparece el aviso de cookies de la UE, ciérralo:
try:
page.click("button#L2AGLb", timeout=3000)
except:
pass
Añade pausas parecidas a las humanas entre acciones: entre 2 y 5 segundos de espera aleatoria entre cargas de página. Los sistemas de detección de Google señalan patrones de solicitudes rápidos y uniformes.
Paso 3: desplázate, pagina y extrae los datos del producto
Google Shopping carga los resultados de forma dinámica. Desplázate para activar la carga diferida y luego extrae las tarjetas de producto:
import time, random
# Desplazarse para cargar todos los resultados
for _ in range(3):
page.evaluate("window.scrollBy(0, 1000)")
time.sleep(random.uniform(1.5, 3.0))
# Extraer las tarjetas de producto
cards = page.query_selector_all("[jsname='ZvZkAe']")
results = []
for card in cards:
title = card.query_selector("h3")
price = card.query_selector("span.a8Pemb")
# ... extraer otros campos
results.append({
"title": title.inner_text() if title else None,
"price": price.inner_text() if price else None,
})
Nota importante: los selectores CSS anteriores son aproximados y van a cambiar. Google rota los nombres de clase con frecuencia. Solo entre 2024 y 2026 se han documentado tres juegos de selectores distintos. Apóyate en atributos más estables como jsname, data-cid, etiquetas <h3> e img[alt] en lugar de nombres de clase.
Paso 4: guarda en CSV o JSON
import json
from datetime import datetime
filename = f"shopping_{datetime.now().strftime('%Y%m%d_%H%M')}.json"
with open(filename, "w") as f:
json.dump(results, f, indent=2)
Cuenta con tener que mantener este script con regularidad. Cuando Google cambia la estructura de la página —algo que ocurre varias veces al año— tus selectores se rompen y vuelves a la fase de depuración.
El mayor dolor de cabeza: CAPTCHAs y bloqueos anti-bot
Foro tras foro, la misma historia: “Pasé unas semanas, pero acabé rindiéndome ante los métodos anti-bot de Google”. Los CAPTCHAs y los bloqueos de IP son la principal razón por la que mucha gente abandona sus raspadores caseros de Google Shopping.
Cómo bloquea Google a los scrapers y qué hacer al respecto
| Desafío anti-bot | Qué hace Google | Solución |
|---|---|---|---|
| Huella de IP | Bloquea IPs de centros de datos tras unas pocas solicitudes | Proxies residenciales o scraping basado en navegador |
| CAPTCHAs | Se activan por patrones de solicitud rápidos o automatizados | Limitación de ritmo (10–20 s entre solicitudes), pausas parecidas a las humanas, servicios de resolución de CAPTCHA |
| Renderizado JavaScript | Los resultados de Shopping se cargan dinámicamente vía JS | Navegador sin interfaz (Playwright) o API que renderice JS |
| Detección de user-agent | Bloquea user-agents habituales de bots | Rotar cadenas de user-agent realistas y actualizadas |
| Huella TLS | Detecta firmas TLS que no parecen de navegador | Usar curl_cffi con suplantación de navegador o un navegador real |
| Bloqueo de IPs AWS/nube | Bloquea rangos de IP conocidos de proveedores cloud | Evitar por completo IPs de centros de datos |
En enero de 2025, Google hizo obligatorio el uso de JavaScript para los resultados de SERP y Shopping, rompiendo muchos scrapers de HTML estático —incluidos flujos usados por SemRush y SimilarWeb. Luego, en septiembre de 2025, Google dejó obsoletas las URLs antiguas de detalle de producto y las redirigió a una nueva superficie “Immersive Product” que carga mediante AJAX asíncrono. Cualquier tutorial escrito antes de finales de 2025 ya está, en gran parte, desactualizado.
Cómo resuelve cada método estos problemas
Las SERP APIs lo gestionan todo por detrás: proxies, renderizado y resolución de CAPTCHA. Tú ni te preocupes.
Cloud Scraping de Thunderbit usa infraestructura distribuida en EE. UU., la UE y Asia para gestionar automáticamente el renderizado JS y las medidas anti-bot. El modo Browser Scraping usa tu propia sesión autenticada de Chrome, lo que evita la detección porque parece un usuario normal navegando.
Playwright hecho por tu cuenta te deja toda la carga encima: gestión de proxies, ajuste de pausas, resolución de CAPTCHA, mantenimiento de selectores y supervisión constante por si algo se rompe.
El coste real de extraer datos de Google Shopping: comparación honesta
“50 dólares por unas 20k solicitudes… algo caro para mi proyecto de hobby”. Ese comentario aparece constantemente en foros. Pero normalmente se ignora el mayor coste de todos.
Tabla comparativa de costes
| Enfoque | Coste inicial | Coste por consulta (estimado) | Carga de mantenimiento | Costes ocultos |
|---|---|---|---|---|
| Python casero (sin proxy) | Gratis | $0 | ALTA (errores, CAPTCHAs) | Tu tiempo depurando |
| Python casero + proxies residenciales | Código gratis | ~$1–5/GB | MEDIA-ALTA | Tarifas del proveedor de proxies |
| SERP API (SerpApi, ScraperAPI) | Plan gratis limitado | ~$0.50–5.00/1K consultas | BAJA | Escala rápido con volumen |
| Extensión Chrome de Thunderbit | Plan gratis (6 páginas) | Basado en créditos, ~1 crédito/fila | MUY BAJA | Plan de pago para volumen |
| Thunderbit Open API (Extract) | Basado en créditos | ~20 créditos/página | BAJA | Pago por extracción |
El coste oculto que todo el mundo ignora: tu tiempo
Una solución casera de coste cero que se come 40 horas de depuración no es gratis. A 50 dólares la hora, son 2.000 dólares en trabajo, para un scraper que quizá vuelva a romperse el mes que viene cuando Google cambie su DOM.

El estudio Technology Outlook de McKinsey sitúa el punto de equilibrio entre construir y comprar solo por encima de 3,6 millones de solicitudes diarias. Por debajo de ese umbral, construirlo internamente “consume presupuesto sin ofrecer ROI”. Para la mayoría de equipos de ecommerce que hacen unas pocas cientos o miles de búsquedas por semana, una herramienta sin código o una SERP API sale mucho más rentable que hacerlo a medida.
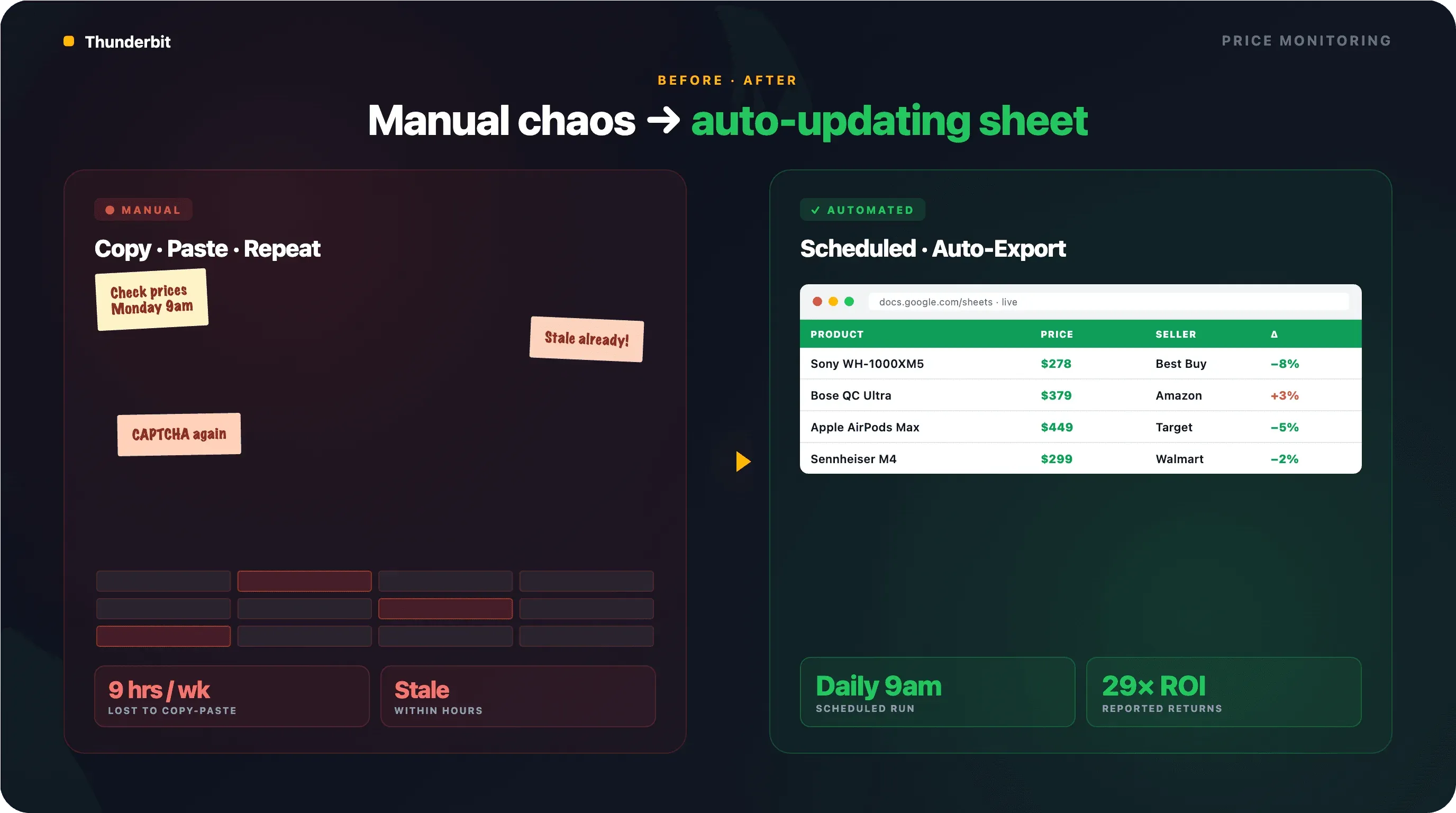
Cómo configurar una monitorización automática de precios en Google Shopping
La mayoría de las guías tratan la extracción como una tarea puntual. El caso real para equipos de ecommerce es la monitorización continua y automatizada. No necesitas solo los precios de hoy; necesitas los de ayer, la semana pasada y mañana.
Configurar extracción programada con Thunderbit
El Scheduled Scraper de Thunderbit te permite describir el intervalo en lenguaje natural —“cada día a las 9:00” o “cada lunes y jueves al mediodía”— y la IA lo convierte en una programación recurrente. Introduce tus URLs de Google Shopping, haz clic en “Schedule” y listo.
Cada ejecución exporta automáticamente a Google Sheets, Airtable o Notion. El resultado final: una hoja de cálculo que se actualiza sola cada día con precios de la competencia, lista para tablas dinámicas o alertas.
Sin cron jobs. Sin gestionar servidores. Sin dolores de cabeza con funciones Lambda. (He visto publicaciones de desarrolladores que pasaron días intentando hacer funcionar Selenium en AWS Lambda; el programador de Thunderbit se salta todo eso.)
Si quieres profundizar en cómo construir flujos de monitorización de precios, tenemos una guía aparte.
Programación con Python (para desarrolladores)
Si usas el enfoque de SERP API, puedes programar las ejecuciones con cron jobs (Linux/Mac), el Programador de tareas de Windows o planificadores en la nube como AWS Lambda o Google Cloud Functions. Las librerías de Python como APScheduler también sirven.
La contrapartida: ahora tú eres responsable de vigilar que el script siga funcionando, gestionar fallos, rotar proxies según calendario y actualizar selectores cuando Google cambie la página. Para la mayoría de equipos, el tiempo de ingeniería necesario para mantener un scraper programado en Python supera el coste de una herramienta dedicada.
Consejos y buenas prácticas para extraer datos de Google Shopping
Independientemente del método, hay varias cosas que te ahorrarán problemas.
Respeta los límites de ritmo
No bombardees a Google con cientos de solicitudes en rápida sucesión: te bloquearán y tu IP puede quedar marcada durante un tiempo. En métodos caseros, separa las solicitudes entre 10 y 20 segundos con algo de variación aleatoria. Las herramientas y las APIs ya lo gestionan por ti.
Elige el método según el volumen
Guía rápida de decisión:
- < 10 consultas/semana → plan gratuito de Thunderbit o plan gratuito de SerpApi
- 10–1.000 consultas/semana → plan de pago de una SERP API o plan de pago de Thunderbit
- 1.000+ consultas/semana → plan empresarial de SERP API o Thunderbit Open API
Limpia y valida tus datos
Los precios vienen con símbolos de moneda, formatos según el país (1.299,00 € frente a $1,299.00) y, a veces, caracteres basura. Usa los Field AI Prompts de Thunderbit para normalizar durante la extracción o limpia después con pandas:
df["price_num"] = df["price"].str.replace(r"[^\d.]", "", regex=True).astype(float)
Comprueba si hay duplicados entre listados orgánicos y patrocinados; a menudo se solapan. Desduplica usando la tupla (título, precio, vendedor).
Conoce el marco legal
Extraer datos públicos de productos suele considerarse legal, pero el panorama jurídico está cambiando rápido. El desarrollo reciente más importante: Google demandó a SerpApi en diciembre de 2025 bajo la sección 1201 de la DMCA por eludir el sistema anti-extracción “SearchGuard” de Google. Se trata de una nueva vía de aplicación que esquiva defensas establecidas en casos anteriores como hiQ v. LinkedIn y Van Buren v. United States.
Pautas prácticas:
- Extrae solo datos de acceso público; no inicies sesión para acceder a contenido restringido
- No extraigas información personal (nombres de reseñadores, detalles de cuentas)
- Ten en cuenta que los Términos de Servicio de Google prohíben el acceso automatizado; usar una SERP API o una extensión de navegador reduce, pero no elimina, las zonas grises legales
- En operaciones en la UE, ten presente el GDPR, aunque los listados de productos son en su gran mayoría datos comerciales no personales
- Considera asesoría legal si vas a crear un producto comercial a partir de datos extraídos
Si quieres profundizar en las implicaciones legales del web scraping, lo tratamos en otro artículo.
¿Qué método deberías usar para extraer datos de Google Shopping?
Después de probar los tres enfoques con las mismas categorías de producto, esta fue mi conclusión:
Si no eres técnico y necesitas datos rápido: usa Thunderbit. Abre Google Shopping, haz dos clics y exporta. Tendrás una hoja de cálculo limpia en menos de 5 minutos. El plan gratuito te permite probarlo sin compromiso, y la función de extracción de subpáginas te da más detalle que la mayoría de scripts en Python.
Si eres desarrollador y necesitas acceso repetible y programático: usa una SERP API. La fiabilidad compensa el coste por consulta y te ahorras todos los problemas anti-bot. SerpApi tiene la mejor documentación; ScraperAPI ofrece el plan gratuito más generoso.
Si necesitas el máximo control y estás montando un pipeline a medida: Playwright funciona, pero entra sabiendo lo que implica. Reserva bastante tiempo para gestionar proxies, mantener selectores y resolver CAPTCHAs. En 2025–2026, la base mínima de evasión viable es curl_cffi con suplantación de Chrome + proxies residenciales + ritmos de 10–20 segundos. Un script básico de requests con user-agents rotatorios está muerto.
El mejor método es el que te da datos precisos sin comerse tu semana. Para la mayoría, eso no es un script de 60 líneas en Python; son dos clics.
Mira los precios de Thunderbit si necesitas volumen, o consulta nuestros tutoriales en el canal de YouTube de Thunderbit para ver el flujo en acción.
Prueba Thunderbit para extraer Google Shopping Get Started Free
Preguntas frecuentes
¿Es legal extraer datos de Google Shopping?
Extraer datos públicos de productos suele ser legal según precedentes como hiQ v. LinkedIn y Van Buren v. United States. Sin embargo, los Términos de Servicio de Google prohíben el acceso automatizado, y la demanda de Google contra SerpApi en diciembre de 2025 introdujo una nueva teoría anti-elusión bajo la sección 1201 de la DMCA. Usar herramientas y APIs de confianza reduce el riesgo. Para usos comerciales, consulta con asesoría legal.
¿Puedo extraer datos de Google Shopping sin que me bloqueen?
Sí, pero el método importa. Las SERP APIs gestionan automáticamente las medidas anti-bot. Cloud Scraping de Thunderbit usa infraestructura distribuida para evitar bloqueos, mientras que su modo Browser Scraping usa tu propia sesión de Chrome, que parece navegación normal. Los scripts Python caseros requieren proxies residenciales, pausas parecidas a las humanas y gestión de huella TLS, e incluso así los bloqueos son frecuentes.
¿Cuál es la forma más fácil de extraer datos de Google Shopping?
La extensión de Chrome de Thunderbit. Entra en Google Shopping, haz clic en “AI Suggest Fields”, luego en “Scrape” y exporta a Google Sheets o Excel. Sin programar, sin claves de API, sin configurar proxies. Todo el proceso tarda unos 2 minutos.
¿Con qué frecuencia puedo extraer Google Shopping para monitorizar precios?
Con el Scheduled Scraper de Thunderbit, puedes configurar monitorización diaria, semanal o con intervalos personalizados usando descripciones en lenguaje natural. Con las SERP APIs, la frecuencia depende del límite de créditos de tu plan; la mayoría de proveedores ofrece suficiente para monitorizar a diario unos pocos cientos de SKU. Los scripts caseros pueden ejecutarse tan a menudo como tu infraestructura lo permita, pero cuanto mayor sea la frecuencia, más problemas anti-bot aparecerán.
¿Puedo exportar los datos de Google Shopping a Google Sheets o Excel?
Sí. Thunderbit exporta directamente a Google Sheets, Excel, Airtable y Notion de forma gratuita. Los scripts en Python pueden exportar a CSV o JSON, que luego puedes importar en cualquier herramienta de hojas de cálculo. Para la monitorización continua, las exportaciones programadas de Thunderbit a Google Sheets crean un dataset vivo que se actualiza automáticamente.
- Más información




