Google eliminó su API de Flights en 2018, pero los precios de los vuelos siguen cambiando: en una sola ruta doméstica. Si quieres acceso programático a esos datos, el scraping es, en la práctica, la única salida real.
He dedicado bastante tiempo a probar distintas formas de extraer datos de vuelos desde Google, y el panorama ha cambiado muchísimo, sobre todo desde que Google implementó SearchGuard en enero de 2025. En esta guía te mostraré cómo construir un scraper funcional en Python para Google Flights con Playwright, cómo esquivar las medidas antibots que suelen bloquear a la mayoría, y cómo convertirlo en un rastreador automático de precios con alertas. Si prefieres evitar el código por completo, también te enseñaré una alternativa sin código con que logra el mismo resultado en unos dos minutos.
¿Por qué hacer scraping de Google Flights con Python?
Google Flights domina la búsqueda de vuelos. Su visibilidad en móviles en EE. UU. , superando a todas las grandes OTAs. El mercado de metabuscadores de viajes que lo respalda está valorado en , con un crecimiento anual compuesto del 30.2%. Sin embargo, desde que la API QPX Express , no existe una vía oficial para acceder a estos datos de forma programática.
Mientras tanto, los precios de los vuelos fluctúan para el mismo itinerario, con una diferencia media de unos 20 dólares entre la tarifa más baja y la más alta. Aerolíneas como Delta usan 77 niveles de tarifa para su pricing dinámico. La media de un vuelo redondo en EE. UU. a inicios de 2026 ronda los 408 dólares, con tarifas .
Plataforma dominante, sin API y con precios muy volátiles. Por eso hacer scraping de Google Flights con Python se ha convertido en uno de los proyectos más populares en GitHub y en foros de viajes.
Esto es para quién sirve y en qué casos:
| Tipo de usuario | Caso de uso | Beneficio principal |
|---|---|---|
| Viajeros individuales | Seguir precios de rutas concretas a lo largo del tiempo | Ahorrar 50 dólares por vuelo de media |
| Agencias de viajes | Inteligencia competitiva de precios | Monitorización de paridad de tarifas en tiempo real |
| Equipos de viajes corporativos | Optimización de costes en distintas rutas | Ahorros del 10–30% en viajes corporativos |
| Desarrolladores | Crear apps de comparación de tarifas | Acceso programático a datos de precios |
| Investigadores | Analizar la volatilidad de los precios de aerolíneas | Investigación académica y de mercado |
En los foros, muchos usuarios son claros sobre por qué recurrieron al scraping: "Google Flights API was discontinued and I should use web scraping instead" es una idea que se repite mucho. Y el retorno es real: analizando más de 5 mil millones de cotizaciones al día, mientras que los datos de Expedia para 2026 muestran que reservar entre 8 y 15 días antes ahorra unos .
¿Qué datos puedes extraer de Google Flights?
Una página de resultados de Google Flights contiene una cantidad sorprendente de campos útiles. Normalmente puedes obtener:
- Nombre de la aerolínea (y su logo)
- Hora de salida y código del aeropuerto
- Hora de llegada y código del aeropuerto
- Duración total del vuelo
- Número de escalas y detalles de la escala (aeropuerto, duración, si es nocturna)
- Precio del billete (según la moneda)
- Emisiones de CO2 (kg CO2e, con diferencia porcentual frente a vuelos típicos)
- Clase de viaje, número de vuelo, modelo de avión
- Espacio para las piernas
- Servicios adicionales (Wi‑Fi, enchufes, streaming multimedia)
- Indicador del nivel de precio (bajo/normal/alto)
- Avisos de retraso ("A menudo se retrasa más de 30 min")
La disponibilidad de los datos varía según la ruta, la fecha y el tipo de billete (solo ida o ida y vuelta). Así se vería un único registro de vuelo extraído en formato JSON:
1{
2 "search_date": "2026-04-16",
3 "route": "SFO-JFK",
4 "departure_date": "2026-05-15",
5 "flights": [
6 {
7 "airline": "United Airlines",
8 "flight_number": "UA123",
9 "departure_time": "08:00",
10 "departure_airport": "SFO",
11 "arrival_time": "16:35",
12 "arrival_airport": "JFK",
13 "duration_minutes": 335,
14 "stops": 0,
15 "price_usd": 287,
16 "price_level": "low",
17 "co2_kg": 156,
18 "co2_vs_typical": "-12%",
19 "travel_class": "Economy"
20 }
21 ]
22}Preparar tu entorno Python
Antes de escribir código de scraping, necesitas dejar listo un par de cosas.
Requisitos previos:
- Nivel: Intermedio
- Tiempo estimado: ~1–2 horas para el tutorial completo
- Necesitarás: Python 3.7+, conocimientos básicos de Python, un navegador basado en Chrome
Instalar las librerías necesarias
Vamos a usar Playwright para automatizar el navegador (Google Flights está renderizado 100% con JavaScript — las peticiones HTTP estáticas no devuelven nada útil), además de algunas utilidades:
1pip install playwright playwright-stealth pandas
2playwright install chromium- Playwright — automatización de navegador sin interfaz, maneja el renderizado JavaScript y tiene esperas integradas
- playwright-stealth — reduce señales comunes de detección de bots
- pandas — para análisis de datos y exportación a CSV más adelante
Por qué Playwright y no Selenium o requests
Google Flights no funciona solo con requests + BeautifulSoup: el contenido de la página se renderiza por completo con JavaScript. Necesitas un navegador real.
| Función | Playwright | Selenium | requests + BS4 |
|---|---|---|---|
| Renderizado JS | Compatibilidad total | Compatibilidad total | Ninguna |
| Velocidad | 42% más rápido en general | Base | N/A para este caso |
| Soporte asíncrono | Nativo | Solo secuencial | N/A |
| Uso de memoria | 30% menos | Más alto | Mínimo |
| Evasión de detección de bots | Buena (con stealth) | Más fácil de detectar | N/A |
Playwright es más rápido, más moderno y ofrece mejor soporte asíncrono. Para Google Flights, es la opción más sólida.
Paso a paso: cómo hacer scraping de Google Flights con Python
Esta es la parte central del tutorial. Vamos a construir el scraper poco a poco.
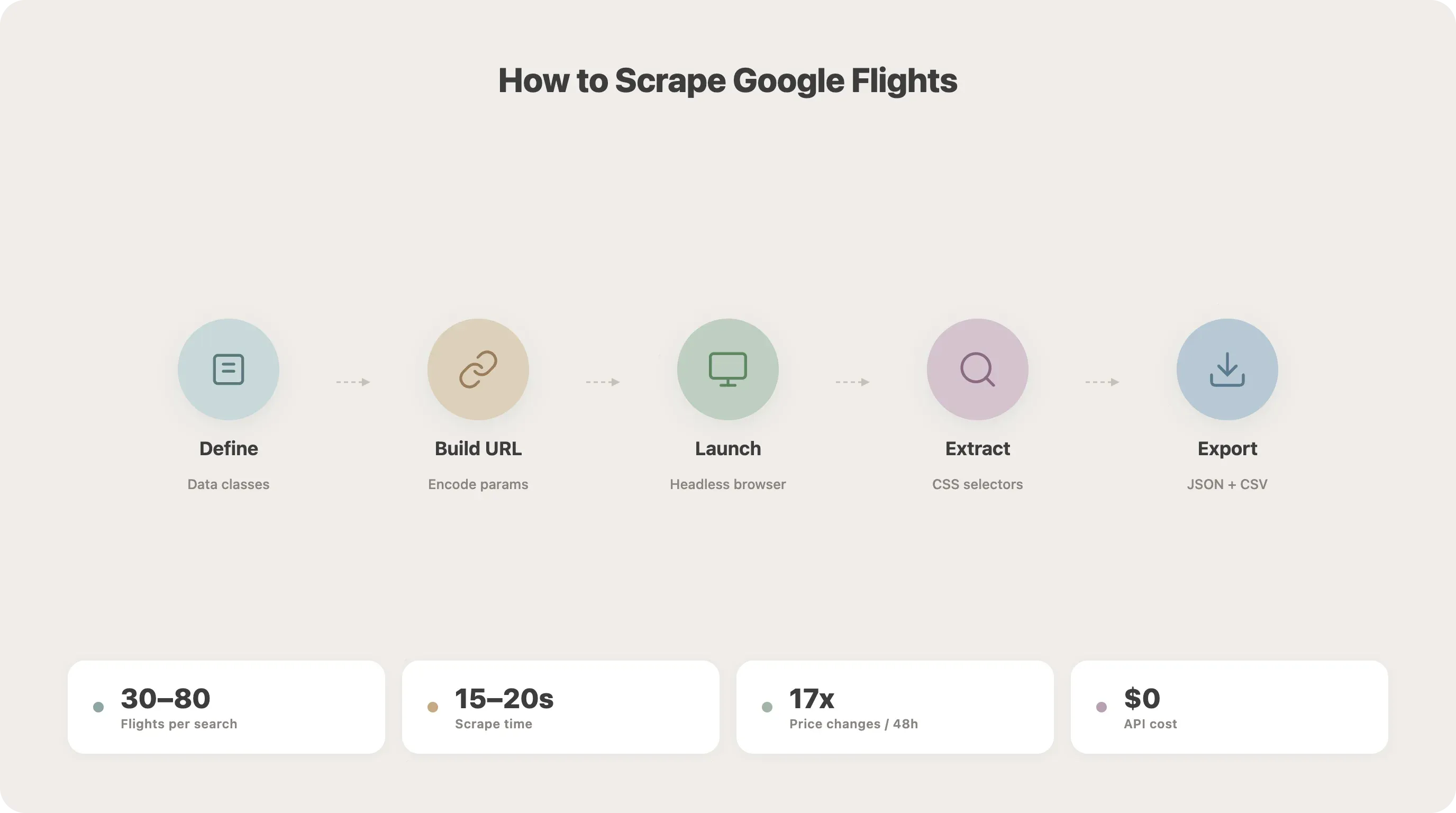
Paso 1: Define tus clases de datos
Empieza organizando los parámetros de búsqueda y los datos de vuelo con dataclasses de Python. Eso mantiene todo limpio y facilita ampliar el código después.
1from dataclasses import dataclass, field
2from typing import Optional, List
3@dataclass
4class SearchParams:
5 origin: str # e.g., "SFO"
6 destination: str # e.g., "JFK"
7 departure_date: str # e.g., "2026-05-15"
8 return_date: Optional[str] = None
9 trip_type: str = "one-way" # "one-way" or "round-trip"
10 travel_class: str = "economy"
11@dataclass
12class FlightData:
13 airline: str = ""
14 departure_time: str = ""
15 arrival_time: str = ""
16 duration: str = ""
17 stops: str = ""
18 price: str = ""
19 co2_emissions: str = ""Cada campo se corresponde directamente con lo que vamos a extraer de la página. Tener esta estructura desde el principio evita estar moviendo diccionarios desordenados más adelante.
Paso 2: Entender la estructura de la URL de Google Flights
Google Flights codifica los parámetros de búsqueda usando Protobuf con Base64 en el parámetro tfs de la URL. Puedes intentar revertir esa codificación o ir por el camino más simple: construir una URL de consulta en lenguaje natural.
La forma más sencilla es usar este formato de búsqueda:
1https://www.google.com/travel/flights?q=flights+from+SFO+to+JFK+on+2026-05-15&curr=USDSi quieres más control, puedes generar las URLs por código:
1def build_flights_url(origin: str, destination: str, date: str) -> str:
2 base = "https://www.google.com/travel/flights"
3 query = f"flights from {origin} to {destination} on {date}"
4 return f"{base}?q={query.replace(' ', '+')}&curr=USD"La alternativa — revertir la codificación Protobuf — da más precisión, pero se rompe cuando Google cambia el formato interno. Librerías como en GitHub usan decodificación Protobuf para saltarse por completo el parseo HTML, aunque es un enfoque más avanzado.
Paso 3: Abre el navegador y entra en Google Flights
Aquí va la configuración con Playwright. Usamos playwright-stealth para reducir el riesgo de detección desde el principio.
1import asyncio
2from playwright.async_api import async_playwright
3from playwright_stealth import Stealth
4async def scrape_flights(params: SearchParams) -> List[FlightData]:
5 async with Stealth().use_async(async_playwright()) as pw:
6 browser = await pw.chromium.launch(
7 headless=True,
8 args=[
9 "--disable-blink-features=AutomationControlled",
10 "--disable-dev-shm-usage",
11 "--no-first-run",
12 ]
13 )
14 context = await browser.new_context(
15 viewport={"width": 1920, "height": 1080},
16 user_agent=(
17 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
18 "AppleWebKit/537.36 (KHTML, like Gecko) "
19 "Chrome/125.0.0.0 Safari/537.36"
20 ),
21 locale="en-US",
22 timezone_id="America/New_York",
23 )
24 # Pre-set cookie consent to skip the popup
25 await context.add_cookies([{
26 "name": "SOCS",
27 "value": "CAESHwgBEhJnd3NfMjAyNTAyMjctMF9SQzIaBXpoLUNOIAEaBgiAy6O-Bg",
28 "domain": ".google.com",
29 "path": "/"
30 }])
31 page = await context.new_page()Estamos ejecutándolo en modo headless para producción (cambia a headless=False para depurar), configurando un viewport y un user agent realistas, y estableciendo por adelantado la cookie SOCS para saltarnos el popup de consentimiento; en la sección antibots explicaré esto con más detalle.
Paso 4: Ir a los resultados de búsqueda
Carga la URL construida y espera a que aparezcan los resultados de vuelos:
1 url = build_flights_url(
2 params.origin, params.destination, params.departure_date
3 )
4 await page.goto(url, wait_until="networkidle")
5 # Wait for flight results to load
6 await page.wait_for_selector(
7 "li.pIav2d", timeout=15000
8 )Si ves un timeout aquí, normalmente significa que el popup de consentimiento bloqueó la página (consulta la corrección con la cookie del Paso 3) o que Google está mostrando un CAPTCHA. Veremos ambos casos en la sección antibots.
Paso 5: Cargar todos los resultados de vuelos
Google Flights oculta más resultados detrás del botón "Show more flights". Debes hacer clic repetidamente hasta que todos los vuelos sean visibles:
1 # Click "Show more flights" until all results are loaded
2 while True:
3 try:
4 more_button = page.locator(
5 'button:has-text("Show more flights")'
6 )
7 if await more_button.is_visible(timeout=3000):
8 await more_button.click()
9 await page.wait_for_timeout(2000)
10 else:
11 break
12 except Exception:
13 breakEste bucle hace clic en el botón, espera 2 segundos a que se rendericen nuevos resultados y se detiene cuando el botón deja de estar visible. En mis pruebas, la mayoría de rutas tienen entre 1 y 3 páginas de resultados.
Paso 6: Extraer los datos de vuelo con selectores CSS
Ahora parseamos los datos reales desde la página cargada. Estos son los selectores (verificados a abril de 2026 — más abajo explico por qué esa fecha importa):
1 flights = []
2 cards = await page.query_selector_all("li.pIav2d")
3 for card in cards:
4 flight = FlightData()
5 # Airline name
6 airline_el = await card.query_selector(
7 "div.sSHqwe span:not([class])"
8 )
9 if airline_el:
10 flight.airline = (await airline_el.inner_text()).strip()
11 # Departure time
12 dep_el = await card.query_selector(
13 'span[aria-label*="Departure time"]'
14 )
15 if dep_el:
16 flight.departure_time = (await dep_el.inner_text()).strip()
17 # Arrival time
18 arr_el = await card.query_selector(
19 'span[aria-label*="Arrival time"]'
20 )
21 if arr_el:
22 flight.arrival_time = (await arr_el.inner_text()).strip()
23 # Duration
24 dur_el = await card.query_selector("div.gvkrdb")
25 if dur_el:
26 flight.duration = (await dur_el.inner_text()).strip()
27 # Stops
28 stops_el = await card.query_selector("div.EfT7Ae span")
29 if stops_el:
30 flight.stops = (await stops_el.inner_text()).strip()
31 # Price
32 price_el = await card.query_selector(
33 "div.FpEdX span"
34 )
35 if price_el:
36 flight.price = (await price_el.inner_text()).strip()
37 # CO2 emissions
38 co2_el = await card.query_selector("div.O7CXue")
39 if co2_el:
40 flight.co2_emissions = (
41 await co2_el.get_attribute("aria-label") or ""
42 ).strip()
43 flights.append(flight)
44 await browser.close()
45 return flightsOjo: clases como pIav2d, sSHqwe y FpEdX las genera Closure Compiler de Google y pueden cambiar en cualquier build. Los selectores con aria-label son mucho más estables. Más abajo te explico una estrategia completa de mantenimiento.
Paso 7: Guardar los resultados en JSON o CSV
Por último, guarda los datos extraídos con una marca temporal (clave para el seguimiento de precios más adelante):
1import json
2from datetime import datetime
3from dataclasses import asdict
4async def main():
5 params = SearchParams(
6 origin="SFO",
7 destination="JFK",
8 departure_date="2026-05-15"
9 )
10 flights = await scrape_flights(params)
11 output = {
12 "search_date": datetime.now().isoformat(),
13 "params": asdict(params),
14 "flights": [asdict(f) for f in flights],
15 }
16 with open("flights.json", "w") as f:
17 json.dump(output, f, indent=2)
18 # Also save as CSV
19 import pandas as pd
20 df = pd.DataFrame([asdict(f) for f in flights])
21 df["search_date"] = datetime.now().isoformat()
22 df["route"] = f"{params.origin}-{params.destination}"
23 df.to_csv("flights.csv", index=False)
24 print(f"Scraped {len(flights)} flights")
25asyncio.run(main())Ejecuta esto y deberías obtener un flights.json y un flights.csv con los resultados. En mis pruebas, una búsqueda SFO-JFK suele devolver entre 30 y 80 opciones de vuelo y tarda unos 15–20 segundos en completarse.
Guía de supervivencia antibots para hacer scraping de Google Flights
La mayoría de los tutoriales se queda aquí. La mayoría de los scrapers falla aquí. Google lanzó , lo que rompió casi todos los scrapers de SERP de la noche a la mañana. Google lo describe como "el resultado de decenas de miles de horas de trabajo humano y millones de dólares de inversión". Google Flights tiene una dificultad de para scraping.
Ningún artículo de la competencia entra en este nivel de detalle, y sin embargo esta es la razón número uno por la que dejan de funcionar los scrapers. Esto es a lo que te enfrentas y cómo resolverlo.

Retrasos aleatorios entre solicitudes
La defensa más simple contra el rate limiting. Dos líneas de código, efectividad media:
1import time
2import random
3time.sleep(random.uniform(3, 7))Añádelo entre navegaciones de página. Los intervalos fijos (como exactamente 5 segundos cada vez) son una señal sospechosa: mejor aleatorizar.
Rotación de User-Agent
Enviar la misma cadena de user-agent en cada solicitud es una pista obvia. Rótalos desde una lista:
1import random
2USER_AGENTS = [
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/125.0.0.0 Safari/537.36",
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 14_5) AppleWebKit/605.1.15 Safari/605.1.15",
5 "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:126.0) Gecko/20100101 Firefox/126.0",
7]
8user_agent = random.choice(USER_AGENTS)Evitar la detección en modo headless
Google comprueba la bandera navigator.webdriver y otras señales de automatización. La librería playwright-stealth cubre la mayoría, pero además deberías usar los argumentos de arranque que viste en el Paso 3. Las banderas clave son:
1args=[
2 "--disable-blink-features=AutomationControlled",
3 "--disable-dev-shm-usage",
4 "--no-first-run",
5]Esto te ayuda a superar la detección básica. SearchGuard va más allá —vigila la velocidad del ratón, los tiempos de teclado y los patrones de scroll—, pero para scraping de volumen moderado, el modo stealth más retrasos realistas suele ser suficiente.
Rotación de proxies: datacenter vs. residential
Para algo más que unas pocas búsquedas, necesitarás proxies. La diferencia importa:
Los proxies residenciales son aproximadamente al hacer scraping de sitios protegidos. Precios de proveedores en 2026: Smartproxy desde $7/GB, Bright Data $8.40/GB, Oxylabs $8/GB.
Puedes añadir un proxy a Playwright así:
1browser = await pw.chromium.launch(
2 proxy={"server": "http://proxy-host:port",
3 "username": "user", "password": "pass"}
4)Manejo del popup de consentimiento de cookies
Los usuarios señalan constantemente el popup de "acepto los términos" como un obstáculo: "first google will show you the 'I agree to terms and conditions' popup." La solución más limpia es preconfigurar la cookie SOCS (como en el Paso 3). Si eso no funciona, haz clic para cerrarlo:
1try:
2 accept_btn = page.locator('button:has-text("Accept all")')
3 if await accept_btn.is_visible(timeout=3000):
4 await accept_btn.click()
5 await page.wait_for_timeout(1000)
6except Exception:
7 pass # No popup presentNota: el texto del botón cambia según el idioma: "Alle akzeptieren" en alemán, "Tout accepter" en francés.
Referencia rápida antibots
| Técnica | Dificultad | Efectividad | ¿Necesita código? |
|---|---|---|---|
| Retrasos aleatorios (2–7 s) | Baja | Media | 2 líneas |
| Rotación de user-agent | Baja | Media | 5 líneas |
| Evitar detección headless | Media | Alta | Argumentos de arranque de Playwright |
| plugin playwright-stealth | Media | 60–80% en sitios básicos | pip install |
| Rotación de proxies (datacenter) | Media | Media | Configuración |
| Rotación de proxies (residenciales) | Media | 85–95% de éxito | Configuración |
| Preajuste de consentimiento de cookies (SOCS) | Baja | Obligatorio | 1 línea |
Como referencia de ritmos seguros: mantén retrasos de 10–20 segundos entre solicitudes con rotación de IP. Los umbrales de Google están alrededor de 100 solicitudes/minuto por IP antes de que llegue un 429, y volúmenes sostenidos por encima de 1,000 solicitudes/día por IP pueden activar bloqueos temporales.
Por qué tus selectores de Google Flights se rompen todo el tiempo (y cómo solucionarlo)
Este es, con diferencia, el mayor dolor de cabeza. Los foros están llenos de versiones de "todo lo que consigo son 14 listas vacías". Todos los tutoriales te dan selectores. Ninguno explica por qué se rompen.
Por qué cambian los selectores de Google Flights
Se reduce a tres cosas:
-
Ofuscación con Closure Compiler. Google usa para generar nombres de clase como
BVAVmfyYMlIzmediantegoog.setCssNameMapping(). Cambian en cada build, a veces semanalmente. -
Pruebas A/B. Distintos usuarios ven estructuras HTML distintas al mismo tiempo. Tu scraper puede funcionar en tu máquina y fallar para otra persona en otra región.
-
Diferencias de localización. Los usuarios de la UE ven términos, diseños e incluso campos de datos distintos a los de EE. UU.
Escribe selectores resistentes
Prefiere selectores ligados al significado, no a la apariencia:
1# Fragile — breaks on every build
2price_el = await card.query_selector("div.BVAVmf > div.YMlIz")
3# More resilient — tied to accessibility labels
4dep_el = await card.query_selector('span[aria-label*="Departure time"]')
5# Also resilient — text-based matching
6more_btn = page.locator('button:has-text("Show more flights")')Jerarquía de estabilidad de selectores (de más estable a menos estable):
- Atributos
aria-label— ligados a accesibilidad, rara vez cambian - Atributos
data-*— añadidos explícitamente para funcionalidad - Atributos
role— roles ARIA con valor semántico - Selectores basados en texto — coinciden con contenido visible
- Coincidencia parcial de clases — por ejemplo,
[class*="price"] - Nombres de clase completos ofuscados — evítalos siempre que puedas
Añade una función de validación
No dejes que unos selectores rotos produzcan datos vacíos sin avisar. Detecta el problema pronto:
1import logging
2logger = logging.getLogger(__name__)
3def validate_flight(data: FlightData) -> bool:
4 required = ["airline", "price", "departure_time",
5 "arrival_time", "duration"]
6 valid = True
7 for field_name in required:
8 if not getattr(data, field_name, ""):
9 logger.warning(
10 f"Missing '{field_name}' — selectors may need updating"
11 )
12 valid = False
13 return validEjecuta esto con cada vuelo extraído. Si empiezas a ver advertencias, toca inspeccionar la página y actualizar los selectores.
Estrategia de mantenimiento de selectores
- Revisa los selectores cada mes, o de inmediato si baja la calidad de salida
- Mantén los selectores en un diccionario de configuración aparte para poder actualizarlos fácilmente
- Los selectores de este artículo se verificaron por última vez en abril de 2026
- Considera la como alternativa: usa decodificación Protobuf en lugar de selectores CSS, evitando este problema por completo (aunque también depende de que Google no cambie sus formatos internos)
De un scrape puntual a un rastreador automático de precios de Google Flights
La mayoría de los tutoriales termina en "guardar en JSON". El título de este artículo dice "Price Alerts". Vamos a cumplirlo.
![]()
Programa tu scraper para que se ejecute automáticamente
Opción 1: librería schedule de Python (la más simple y multiplataforma):
1import schedule
2import time
3def run_scraper():
4 asyncio.run(main())
5schedule.every().day.at("06:00").do(run_scraper)
6schedule.every().day.at("18:00").do(run_scraper)
7while True:
8 schedule.run_pending()
9 time.sleep(60)Opción 2: tarea cron (Linux/Mac):
1# Run at 6 AM and 6 PM daily
20 6,18 * * * cd /path/to/scraper && python scraper.pyOpción 3: Programador de tareas de Windows — crea una tarea básica que ejecute python scraper.py con la frecuencia que prefieras.
La desventaja: todas estas opciones requieren una máquina encendida todo el tiempo. Si lo haces en un portátil que entra en suspensión, te perderás ejecuciones.
Guardar histórico de precios
Pasa de sobrescribir un archivo JSON a ir guardando registros en una base de datos SQLite:
1import sqlite3
2from datetime import datetime
3def init_db():
4 conn = sqlite3.connect("flights.db")
5 conn.execute("""
6 CREATE TABLE IF NOT EXISTS flights (
7 id INTEGER PRIMARY KEY AUTOINCREMENT,
8 scrape_date TEXT NOT NULL,
9 route TEXT NOT NULL,
10 airline TEXT,
11 departure_time TEXT,
12 arrival_time TEXT,
13 duration TEXT,
14 stops TEXT,
15 price_usd REAL,
16 co2_emissions TEXT
17 )
18 """)
19 conn.execute(
20 "CREATE INDEX IF NOT EXISTS idx_route_date "
21 "ON flights(route, scrape_date)"
22 )
23 conn.commit()
24 return conn
25def save_flight(conn, route: str, flight: FlightData):
26 price_num = float(
27 flight.price.replace("$", "").replace(",", "")
28 ) if flight.price else None
29 conn.execute(
30 "INSERT INTO flights "
31 "(scrape_date, route, airline, departure_time, "
32 "arrival_time, duration, stops, price_usd, co2_emissions) "
33 "VALUES (?, ?, ?, ?, ?, ?, ?, ?, ?)",
34 (datetime.now().isoformat(), route, flight.airline,
35 flight.departure_time, flight.arrival_time,
36 flight.duration, flight.stops, price_num,
37 flight.co2_emissions)
38 )
39 conn.commit()Tras una semana con dos scrapes al día, tendrás suficientes datos para empezar a detectar tendencias.
Analiza tendencias de precios y configura alertas
Busca la opción más barata en tus datos históricos:
1import pandas as pd
2import sqlite3
3conn = sqlite3.connect("flights.db")
4df = pd.read_sql_query(
5 "SELECT * FROM flights WHERE route = 'SFO-JFK'", conn
6)
7summary = df.groupby("scrape_date")["price_usd"].agg(
8 ["min", "max", "mean"]
9)
10cheapest = df.loc[df["price_usd"].idxmin()]
11print(
12 f"Cheapest: ${cheapest['price_usd']:.0f} on "
13 f"{cheapest['scrape_date']} ({cheapest['airline']})"
14)Activa una alerta por correo cuando el precio baje de tu umbral:
1import smtplib
2from email.mime.text import MIMEText
3def send_price_alert(route, price, threshold, recipient):
4 msg = MIMEText(
5 f"Price drop alert! {route}: ${price:.0f} "
6 f"(below your ${threshold:.0f} threshold)"
7 )
8 msg["Subject"] = f"Flight Deal: {route} at ${price:.0f}"
9 msg["From"] = "alerts@example.com"
10 msg["To"] = recipient
11 with smtplib.SMTP_SSL("smtp.gmail.com", 465) as server:
12 server.login("alerts@example.com", "your_app_password")
13 server.send_message(msg)
14# After each scrape, check for deals
15min_price = df["price_usd"].min()
16threshold = 250
17if min_price < threshold:
18 send_price_alert("SFO-JFK", min_price, threshold,
19 "you@email.com")Como frecuencia recomendada: dos veces al día es suficiente para vigilar precios personales (el horario aleatorio reduce el riesgo de detección). Cada 4–6 horas si supervisas esto para un negocio. Cada hora solo durante periodos de promociones puntuales y de forma temporal.
La vía fácil: el Scheduled Scraper de Thunderbit
Si gestionar tareas cron, un servidor encendido y configuraciones de proxy te parece más infraestructura de la que quieres mantener, el cubre el mismo caso de uso sin esa carga. Tú describes el intervalo de scraping en lenguaje natural, añades tus URLs de Google Flights y el scraper se ejecuta automáticamente en la infraestructura cloud de Thunderbit, con manejo antibots integrado y exportación directa a . No sustituye al enfoque completo en Python (pierdes personalización), pero para el caso concreto de "quiero una hoja de cálculo para rastrear precios" es la ruta más rápida. Puedes probarlo en el .
Cuando Python es demasiado: formas sin código de extraer Google Flights
Después de construir todo esto, siendo sincero: hay muchas piezas en movimiento. No todo el mundo necesita este nivel de control. Los selectores se rompen, los proxies se rotan, y las tareas programadas requieren supervisión. Si tu objetivo es "llevar los precios de vuelos a una hoja de cálculo de forma regular", hay opciones más rápidas.
Comparativa: Python casero vs. servicios API vs. Thunderbit
| Enfoque | Tiempo de configuración | Requiere código | Gestiona antibots | Programación | Coste |
|---|---|---|---|---|---|
| Playwright DIY (este tutorial) | 1–2 horas | Python (intermedio) | Configuración manual | Manual (cron) | Gratis + coste de proxies |
| Endpoint de Google Flights en SerpApi | 15 min | Solo llamadas API | Gestionado | Vía API | ~$50+/mes |
| Extensión de Chrome de Thunderbit | 2 min | Ninguno | Scraping en la nube | Programador integrado | Plan gratuito disponible |
Una nota sobre SerpApi: Google , alegando que sus solicitudes crecieron un 25,000% en dos años. Esa incertidumbre legal conviene tenerla en cuenta si estás evaluando proveedores de API.
Cómo Thunderbit extrae Google Flights
Abre tus resultados de búsqueda de Google Flights en Chrome, haz clic en el botón "AI Suggest Fields" de Thunderbit — la IA lee la página y te propone columnas como aerolínea, precio, hora de salida y escalas — revisa los campos sugeridos y pulsa "Scrape". Los resultados aparecen en una tabla que puedes exportar a Excel, Google Sheets, Airtable o Notion — todo dentro del .
Para el caso concreto de seguimiento de precios, el Scheduled Scraper de Thunderbit y su (capaz de procesar 50 páginas a la vez) sustituyen por completo la infraestructura de cron + proxy + servidor.
Python te da control total y personalización ilimitada. Thunderbit te da rapidez y cero mantenimiento. Elige según tu objetivo real. Si quieres saber más sobre scraping sin código, consulta nuestra guía sobre los .

¿Es legal hacer scraping de Google Flights? Lo que debes saber
Los usuarios de foros lo preguntan con frecuencia: "scraping Google Flights directly violates the TOS that Google has." Es una preocupación válida, especialmente porque la API se retiró y no hay una alternativa aprobada.
Incumplimiento de los Términos vs. responsabilidad legal
Los Términos de Servicio de Google (actualizados el 22 de mayo de 2024) indican que los usuarios no deben "acceder o usar los Servicios o cualquier contenido mediante el uso de medios automatizados (como robots, spiders o scrapers)". Violar los ToS es un incumplimiento contractual (materia civil), no es lo mismo que infringir la ley.
El precedente legal clave es hiQ v. LinkedIn (Noveno Circuito, 2022), que estableció que extraer datos públicamente disponibles no viola la Computer Fraud and Abuse Act (CFAA). Sin embargo, el caso terminó en acuerdo, y la demanda de Google contra SerpApi en diciembre de 2025 se apoya en otra teoría legal — la Sección 1201 de la DMCA (elusión de medidas tecnológicas de protección) — que puede ser más seria.
Buenas prácticas para hacer scraping de forma responsable
- Limita la frecuencia de las solicitudes — retrasos de 10–20 segundos con rotación de IP
- No extraigas datos personales — los precios de vuelos son datos públicos y agregados
- No eludas CAPTCHAs por programación (esta es la zona de riesgo de la DMCA)
- Usa los datos para investigación personal, no para construir un producto comercial competidor sin la licencia adecuada
- Considera APIs oficiales cuando existan
Fuentes de datos alternativas
Si el scraping te parece demasiado arriesgado para tu caso, hay opciones de API legítimas:
| Proveedor | Coste | Plan gratuito | Notas |
|---|---|---|---|
| SerpApi | $75–$3,750+/mes | 250 búsquedas/mes | JSON directo de Google Flights (bajo escrutinio legal) |
| Kiwi Tequila | Gratis (modelo de afiliación) | Ilimitado | Ideal para startups y pruebas |
| Amadeus | Pago por uso | 2,000 req/mes | Más de 400 aerolíneas, con capacidad de reserva |
| Skyscanner | Personalizado | Requiere aprobación | 52 mercados, 30 idiomas |
Escribimos un análisis más profundo sobre las si quieres la visión completa.
Conclusión y puntos clave
Ha sido bastante contenido. Quédate con esto:
- Python + Playwright es el enfoque más flexible para extraer datos de Google Flights, pero requiere mantenimiento continuo
- Las medidas antibots (retrasos, rotación de user-agent, proxies residenciales) no son opcionales: son esenciales para que funcione de forma fiable, especialmente después de SearchGuard
- Los selectores se rompen con frecuencia: usa
aria-labely selectores basados en texto siempre que puedas, valida la salida y mantén un calendario de revisión - Automatiza con
scheduleo cron para convertir un scraping puntual en un rastreador real de precios con histórico y alertas por correo - ofrece una alternativa sin código con programación integrada, scraping en la nube y manejo antibots; ideal si quieres una hoja de cálculo de seguimiento de precios y no un proyecto de programación
- Respeta los límites legales: limita la frecuencia, extrae solo datos públicos y valora alternativas API para uso comercial
Descarga el código de este tutorial o instala la si prefieres ir por la vía rápida. En cualquier caso, estarás siguiendo los precios de vuelos en lugar de refrescar Google Flights manualmente.
Para más técnicas de scraping en Python, consulta nuestras guías sobre y .
Preguntas frecuentes
1. ¿Puedo hacer scraping de Google Flights sin Python?
Sí. Servicios API como SerpApi y Kiwi Tequila ofrecen datos estructurados de vuelos mediante llamadas API (sin necesidad de automatizar el navegador). Para un enfoque totalmente sin código, la puede extraer resultados de Google Flights directamente desde tu navegador con campos sugeridos por IA y exportación con un clic.
2. ¿Google bloquea el scraping de vuelos?
Google utiliza detección de bots (SearchGuard), CAPTCHAs y rate limiting. Con medidas antibots adecuadas — retrasos aleatorios, rotación de user-agent, proxies residenciales y configuración stealth del navegador — puedes mantener un scraping fiable a volumen moderado. Consulta la sección antibots anterior para ver técnicas y umbrales concretos.
3. ¿Con qué frecuencia debería hacer scraping de Google Flights para rastrear precios?
Dos veces al día (en horarios aleatorios) es suficiente para seguimiento personal y mantiene bajo el riesgo de detección. Para monitorización empresarial, cada 4–6 horas con rotación de proxies. Evita hacerlo cada hora salvo durante rebajas de tarifas a corto plazo, porque aumenta mucho la probabilidad de bloqueo.
4. ¿Existe una API gratuita de Google Flights?
La API oficial Google QPX Express . No hay un reemplazo oficial gratuito. La opción gratuita más cercana es la (modelo de afiliación, búsquedas ilimitadas). SerpApi ofrece 250 búsquedas gratis al mes. Para la mayoría de usuarios, el scraping o una herramienta sin código como Thunderbit es la ruta práctica.
5. ¿Por qué mis selectores CSS de Google Flights siguen devolviendo datos vacíos?
Google usa Closure Compiler para generar nombres de clase ofuscados que cambian en cada build. Las pruebas A/B y las diferencias de localización también hacen que la estructura HTML varíe entre usuarios. La solución: usa atributos aria-label y selectores basados en texto en lugar de clases, añade una función de validación para detectar roturas pronto y revisa los selectores cada mes. Mira la sección de mantenimiento de selectores para una estrategia detallada.
Saber más