Si tu extraer glassdoor con python funcionaba perfecto en 2022 y ahora solo te devuelve errores 403, no eres el único. En foros y comunidades aparece una y otra vez la misma duda: "¿Alguien sabe por qué este scraper ya no funciona?"
La respuesta corta: Glassdoor cambió por completo. Recruit Holdings integró Glassdoor en Indeed en julio de 2025, despidió a y reforzó tanto su sistema antibots que los scrapers básicos con Selenium o basados en requests quedan bloqueados antes de que cargue el primer byte del HTML. A febrero de 2026, los inicios de sesión de Glassdoor se gestionan por completo mediante Indeed Login, así que cualquier tutorial que use un formulario de acceso específico de Glassdoor ya está roto desde la base. Mientras tanto, la plataforma sigue concentrando en . Esos datos tienen un valor enorme para benchmarking de RR. HH., inteligencia competitiva y prospección comercial — si logras acceder a ellos. Esta guía es la versión que sí funciona después de todos esos cambios, y cubre los tres tipos de datos de Glassdoor (empleos, reseñas y salarios) en un solo lugar. Te mostraré el enfoque con Python y código funcional para 2025, explicaré exactamente qué te bloquea y cómo superarlo, y también te enseñaré una alternativa sin código para quien prefiera evitar por completo el trabajo técnico.
¿Por qué extraer Glassdoor con Python en 2025?
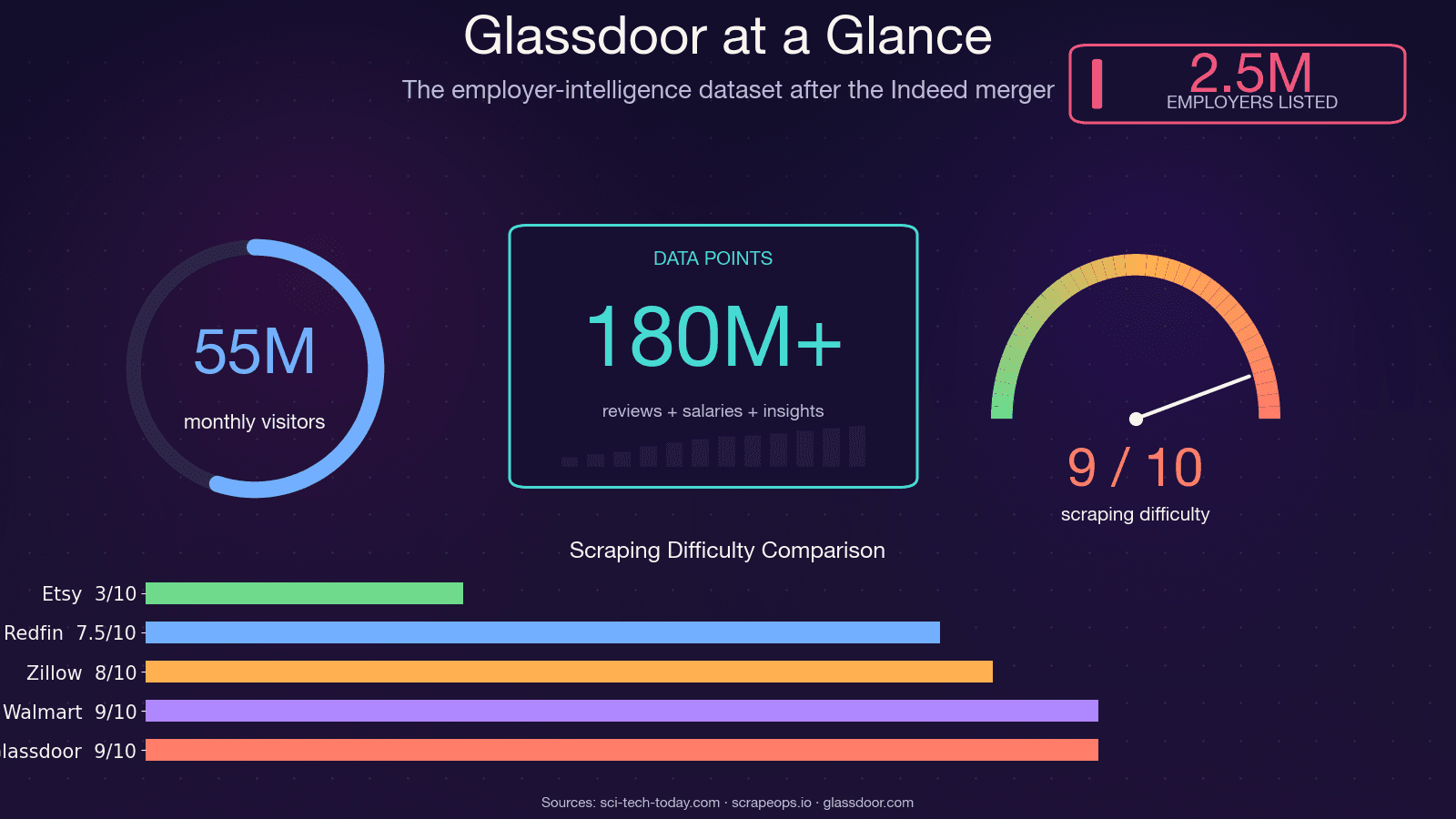
Glassdoor no es solo una bolsa de empleo. Es uno de los conjuntos de datos de inteligencia sobre empleadores más ricos de la web — lo usa aproximadamente y recibe unos 55 millones de visitantes únicos al mes. La información detrás de esas páginas impulsa decisiones reales en distintos equipos.
Así es como se usa realmente la información de Glassdoor en distintos equipos:
| Caso de uso | Tipo de dato necesario | Quién se beneficia |
|---|---|---|
| Benchmark salarial | Distribuciones salariales, tamaño de muestra | RR. HH., Compensación Total, Operaciones |
| Seguimiento de contratación de competidores | Ofertas de empleo, velocidad de publicación | Ventas, Estrategia, VC/Desarrollo corporativo |
| Monitoreo de marca empleadora | Texto de reseñas, tendencias de calificación, aprobación del CEO | RR. HH., Marketing, Comunicación |
| Generación de leads (empresas en crecimiento) | Ofertas de empleo + información de la empresa | Equipos de ventas, SDRs |
| Investigación de mercado o académica | Los tres | Analistas, consultores, investigadores |
Cuando el BLS no pudo publicar datos de empleo durante el cierre del gobierno de octubre de 2025, el propio equipo de Economic Research de Glassdoor basado en su propia base de datos. Así de en serio se toma hoy esta información el sector analítico.
Python sigue siendo el lenguaje preferido porque su ecosistema no tiene rival: Playwright para automatización de navegador, parsel/lxml para parseo, curl_cffi para esquivar el fingerprint TLS, y una enorme comunidad que comparte patrones funcionales. El problema no es Python. El problema es que Glassdoor se volvió mucho más difícil de extraer.
Si quieres una alternativa sin código para extraer datos de Glassdoor, Thunderbit puede ayudarte a extraer empleos, reseñas y páginas de salarios sin construir ni mantener una pila personalizada en Python.
¿Qué datos de Glassdoor sí puedes extraer?
La mayoría de los tutoriales solo cubren ofertas de empleo. Pero la demanda real de usuarios — basada en hilos de foros, issues de GitHub y preguntas en Reddit que he ido siguiendo — se concentra en los dos tipos de datos que casi nadie enseña: reseñas y salarios. Aquí tienes el desglose completo de lo que se puede extraer en las tres categorías.
Ofertas de empleo
El tipo de dato más accesible. Puedes obtener: título del puesto, nombre de la empresa, ubicación, estimación salarial, calificación de la empresa, fecha de publicación, insignia de postulación fácil y enlace de la oferta. Las ofertas están disponibles parcialmente sin iniciar sesión, aunque Glassdoor puede mostrar una ventana de acceso tras varias páginas.
Reseñas de empresa
Aquí es donde la cosa se pone interesante para el análisis de marca empleadora. Los campos extraíbles incluyen: calificación general, subcalificaciones (equilibrio vida-trabajo, cultura y valores, diversidad e inclusión, oportunidades de carrera, compensación y beneficios, alta dirección), texto de pros, texto de contras, cargo del autor, fecha de la reseña y estado laboral. El texto completo de la reseña exige iniciar sesión — verás un extracto, pero los pros y contras completos están protegidos.
Datos salariales
El tipo de dato más solicitado y también el más frustrante. Puedes extraer: título del puesto, rango salarial base, rango de compensación total, número de reportes salariales y ubicación. Pero las páginas de salarios están completamente protegidas por login, y además Glassdoor a veces añade un flujo de "contribute to unlock", donde tienes que aportar tu propio salario antes de ver los de otros. No hay ningún tutorial competidor con código funcional para esto — lo solucionaremos aquí.
Qué requiere login y qué no
Esta tabla te ahorra descubrir por las malas qué páginas devolverán datos vacíos:
| Tipo de dato | ¿Disponible sin iniciar sesión? | Notas |
|---|---|---|
| Títulos de ofertas y datos básicos | En su mayoría sí | Puede aparecer una ventana emergente tras varias páginas |
| Descripciones completas de empleo | Parcial | A menudo bloqueado después de 2–3 vistas |
| Reseñas de empresa (texto completo) | No — requiere login | Se ve un extracto, el texto completo está bloqueado |
| Datos salariales | No — requiere login | También puede requerir "contribute to unlock" |
Por qué tu viejo scraper de Glassdoor probablemente ya no funciona
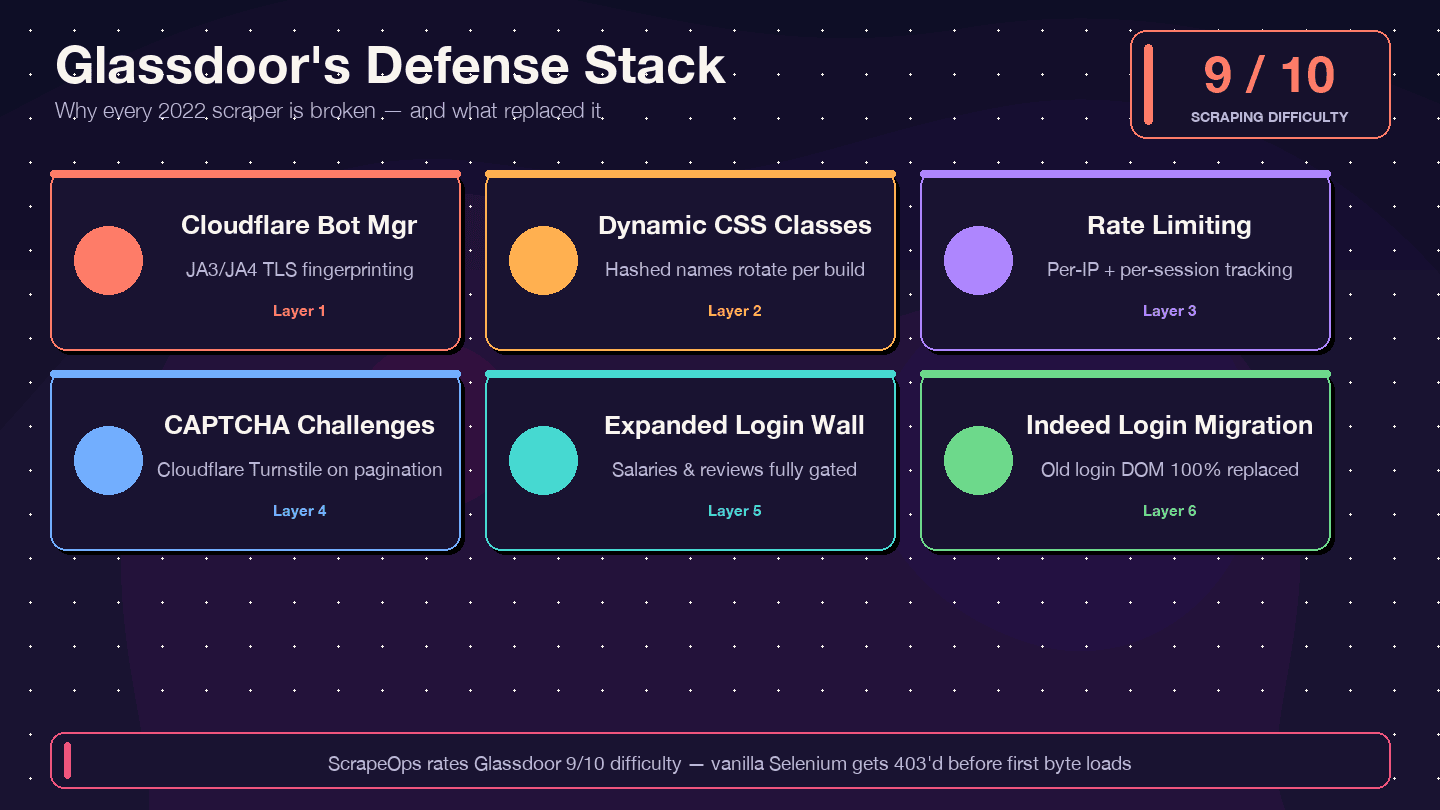
Voy a ser claro: si estás copiando código de un tutorial de 2021–2023, no va a funcionar. El scraper Selenium de Glassdoor más popular en GitHub (, ~1.4k estrellas) acumula más de 12 issues abiertos sin resolver, incluyendo "Glassdoor new UI design", "Cloudflare anti-bot protection" y "NoSuchElementException". El repositorio está prácticamente abandonado. . y la dificultad de bypass con 8/10.
Esto es lo que cambió y por qué el código antiguo falla:
| Capa de defensa | Qué cambió | Impacto en scrapers antiguos |
|---|---|---|
| Cloudflare Bot Management | Fingerprinting JA3/JA4 más estricto desde 2024 | Los scripts básicos con requests/Selenium reciben 403 al instante |
| Nombres de clase CSS dinámicos | Las clases se aleatorizan en cada compilación | Los selectores CSS viejos dejan de funcionar sin aviso |
| Rate limiting + seguimiento de sesión | Límites más duros por IP y por sesión | Los scrapers se bloquean tras menos páginas |
| Desafíos CAPTCHA (probablemente Cloudflare Turnstile) | Más frecuentes, sobre todo al paginar | Los navegadores headless disparan retos |
| Muro de login más amplio | Más tipos de página requieren autenticación | Las páginas de salarios y reseñas devuelven datos vacíos |
| Migración a Indeed Login (febrero 2026) | El formulario de acceso de Glassdoor fue reemplazado por completo | Cualquier código que apunte al DOM antiguo de login está muerto |
La incluye una advertencia explícita: "Glassdoor is known for its high blocking rate, so if you get None values while running the Python code, it's likely you're getting blocked." Y un lo dice sin rodeos: "Simple HTTP requests with requests or httpx get blocked instantly."
Las contramedidas que te mostraré — Patchright (un fork sigiloso de Playwright), selectores con atributos data-test, proxies residenciales rotativos y sesiones persistentes autenticadas — están diseñadas precisamente para lidiar con cada una de esas capas.
Glassdoor API vs. scraping con Python: elige primero el enfoque correcto
En varios foros preguntan: "¿Mejor uso la API de Glassdoor?" — y la respuesta es: no puedes.
La . El portal para desarrolladores todavía existe técnicamente, pero . Nunca existió un endpoint público para reseñas; el scraper de MatthewChatham se creó precisamente "because Glassdoor doesn't have an API for reviews." Y tampoco hay una vía de migración para reseñas o salarios dentro de la Publisher API de Indeed.
Aquí tienes la comparación honesta:
| Factor | Glassdoor Partner API v1 | Scraping con Python | Thunderbit (sin código) |
|---|---|---|---|
| Acceso | Cerrado a nuevos solicitantes | Abierto (lo implementas tú) | Extensión de Chrome |
| Ofertas de empleo | Limitadas / en retirada | Disponibles con esfuerzo | Disponibles |
| Reseñas de empresa | Nunca existieron públicamente | Sí (requiere login) | Sí (mediante Browser Mode) |
| Datos salariales | Nunca existieron públicamente | Sí (requiere login) | Sí |
| Límites de velocidad | No documentados | Tú controlas el ritmo | Basado en créditos |
| Esfuerzo de configuración | No se pueden registrar apps nuevas | Horas o días | ~2 minutos |
| Mantenimiento | N/A | Alto (cambios HTML rompen el código) | Bajo (la IA sugiere campos de nuevo) |
Si necesitas reseñas o datos salariales — y la mayoría de quienes leen esto sí los necesitan — el scraping con Python o una herramienta sin código es tu única opción realista.
Antes de empezar
- Dificultad: Intermedia (debes sentirte cómodo con Python y la terminal)
- Tiempo requerido: ~30–60 minutos para la configuración completa; ~10 minutos por tipo de dato después
- Lo que necesitas:
- Python 3.10+ (recomendado 3.11 o 3.12)
- Chrome instalado
- Una cuenta de Glassdoor (gratis — necesaria para datos salariales y reseñas)
- Proxies residenciales rotativos (para extraer más de unas pocas páginas)
- Opcional: si quieres la ruta sin código
Herramientas y librerías para extraer Glassdoor con Python en 2025
El panorama de herramientas cambió muchísimo. Esto es lo que realmente funciona contra las defensas actuales de Glassdoor.
Por qué Patchright es la mejor opción para Glassdoor
es un fork sigiloso de Playwright que corrige la filtración CDP de Runtime.Enable — la razón técnica concreta por la que Playwright puro falla en sitios protegidos por Cloudflare. Usa exactamente la misma API que Playwright, así que si conoces Playwright, ya sabes usar Patchright. La versión 1.58.2 (marzo de 2026) es la actual y se mantiene activamente.
Comparado con las alternativas:
- Playwright puro: Glassdoor lo detecta en la página de login por la filtración de Runtime.Enable
- Selenium + undetected-chromedriver: la última versión de undetected-chromedriver fue en febrero de 2024 — ya es básicamente una solución heredada. encontró que "failed on every domain in our test"
- requests + BeautifulSoup: no puede renderizar JavaScript y Cloudflare lo bloquea de inmediato por fingerprint TLS
- : excelente para la vía rápida (10–20 veces más rápido que un navegador) cuando las páginas incluyen
__NEXT_DATA__en el HTML inicial, pero no puede manejar login ni desafíos intermedios
Librerías de apoyo
- parsel (1.11.0) o lxml (6.0.4): parseo HTML/XPath rápido
- csv o pandas: exportación de datos
- asyncio: scraping asíncrono para paginación más rápida
Proxies: solo residenciales
La capa Cloudflare de Glassdoor desafía con mucha agresividad a los ASN de centros de datos. . El precio inicial ronda (promocional) o 3.00 USD/GB en . Para scraping en producción, calcula un presupuesto de 3–8 USD/GB según el volumen.
Los retrasos aleatorios entre solicitudes (mínimo 3–8 segundos, 5–15 segundos en ejecuciones largas) son esenciales independientemente de la calidad del proxy.
Paso 1: configura tu entorno Python
Crea la carpeta del proyecto e instala el stack recomendado:
1mkdir glassdoor-scraper && cd glassdoor-scraper
2python3.11 -m venv .venv
3source .venv/bin/activate
4pip install --upgrade pip
5# Stack principal
6pip install patchright==1.58.2 parsel==1.11.0
7# Instala los binarios del navegador
8patchright install chromium
9# Opcional: vía rápida para extraer __NEXT_DATA__
10pip install "curl_cffi==0.15.0"Deberías ver que Patchright descarga un binario de Chromium. Si patchright install chromium falla, verifica que tengas suficiente espacio en disco (~300MB) y que tu versión de Python sea 3.10+.
Paso 2: inicia Patchright y navega a Glassdoor
Este es el patrón base de arranque que funciona contra la capa Cloudflare de Glassdoor:
1from patchright.sync_api import sync_playwright
2import random, time
3with sync_playwright() as p:
4 browser = p.chromium.launch(
5 headless=False, # headless sigue siendo más detectable
6 channel="chrome", # usa Chrome real, no Chromium empaquetado
7 )
8 context = browser.new_context(
9 viewport={"width": 1440, "height": 900},
10 locale="en-US",
11 timezone_id="America/New_York",
12 user_agent=(
13 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) "
14 "AppleWebKit/537.36 (KHTML, like Gecko) "
15 "Chrome/134.0.0.0 Safari/537.36"
16 ),
17 )
18 page = context.new_page()
19 page.goto(
20 "https://www.glassdoor.com/Job/new-york-data-engineer-jobs-"
21 "SRCH_IL.0,8_IC1132348_KO9,22.htm"
22 )
23 # Oculta el overlay de login — el contenido sigue en el DOM
24 page.add_style_tag(content="""
25 #HardsellOverlay, .LoginModal { display: none !important; }
26 body { overflow: auto !important; position: initial !important; }
27 """)
28 page.wait_for_selector("[data-test='jobListing']")
29 print("Page loaded — job listings visible.")Hay varios detalles importantes aquí. La bandera channel="chrome" le indica a Patchright que use tu binario instalado de Chrome en lugar del Chromium empaquetado — esto genera una huella del navegador más auténtica. El truco de add_style_tag oculta el modal de login de Glassdoor (llamado #HardsellOverlay) sin necesidad de hacer clic en nada. que "all of the content is still there, it's just covered up by the overlay" — el HTML contiene los datos independientemente de que el modal esté visible.
Deberías ver cómo se abre una ventana de Chrome, navega a la página de búsqueda de empleos de Glassdoor y muestra las tarjetas de trabajo sin que la ventana emergente de login bloquee la vista.
Paso 3: extraer ofertas de empleo de Glassdoor
Identifica selectores estables
Glassdoor randomiza los nombres de clase CSS en cada compilación — así que el selector .jobCard_xyz123 de un tutorial de 2023 hoy devolverá nada sin avisar. En su lugar, usa atributos data-test, que son una convención interna de QA de Glassdoor y se mantienen estables entre despliegues.
Aquí tienes la referencia de selectores para campos de ofertas de empleo:
| Campo | Selector |
|---|---|
| Contenedor de tarjeta de empleo | [data-test="jobListing"] |
| Título del empleo | [data-test="job-title"] |
| Enlace del empleo | a[data-test="job-link"] |
| Nombre de la empresa | [data-test="employer-name"] |
| Ubicación | [data-test="emp-location"] |
| Rango salarial | [data-test="detailSalary"] |
| Calificación de la empresa | [data-test="rating"] |
| Fecha de publicación | [data-test="job-age"] |
| Siguiente página | [data-test="pagination-next"] |
Extrae los datos de empleo
1from parsel import Selector
2import csv, random, time
3def scrape_jobs(page, max_pages=5):
4 all_jobs = []
5 for page_num in range(1, max_pages + 1):
6 html = page.content()
7 sel = Selector(text=html)
8 cards = sel.css('[data-test="jobListing"]')
9 if not cards:
10 print(f"Página {page_num}: no se encontraron tarjetas — posible bloqueo o cambio de selector.")
11 break
12 for card in cards:
13 job = {
14 "title": card.css('[data-test="job-title"]::text').get("").strip(),
15 "company": card.css('[data-test="employer-name"]::text').get("").strip(),
16 "location": card.css('[data-test="emp-location"]::text').get("").strip(),
17 "salary": card.css('[data-test="detailSalary"]::text').get("").strip(),
18 "rating": card.css('[data-test="rating"]::text').get("").strip(),
19 "link": card.css('a[data-test="job-link"]::attr(href)').get(""),
20 "posted": card.css('[data-test="job-age"]::text').get("").strip(),
21 }
22 if job["link"] and not job["link"].startswith("http"):
23 job["link"] = "https://www.glassdoor.com" + job["link"]
24 all_jobs.append(job)
25 print(f"Página {page_num}: se extrajeron {len(cards)} empleos")
26 # Paginación
27 next_btn = page.query_selector('[data-test="pagination-next"]')
28 if next_btn and page_num < max_pages:
29 next_btn.click()
30 time.sleep(random.uniform(3, 8))
31 page.wait_for_selector("[data-test='jobListing']")
32 else:
33 break
34 return all_jobsGuardar en CSV
1def save_to_csv(jobs, filename="glassdoor_jobs.csv"):
2 if not jobs:
3 print("No hay empleos para guardar.")
4 return
5 keys = jobs[0].keys()
6 with open(filename, "w", newline="", encoding="utf-8") as f:
7 writer = csv.DictWriter(f, fieldnames=keys)
8 writer.writeheader()
9 writer.writerows(jobs)
10 print(f"Guardados {len(jobs)} empleos en {filename}")Una nota sobre los límites de paginación: Glassdoor suele limitar los resultados de búsqueda a unas 30 páginas, independientemente del número total. Si necesitas más cobertura, usa filtros (ubicación, tipo de empleo, rango salarial) para acotar cada búsqueda en lugar de intentar superar ese límite con paginación.
En mis pruebas, extraer 5 páginas de ofertas de empleo (unas 75 vacantes) tomó alrededor de 45 segundos con retrasos aleatorios. Hacer lo mismo manualmente habría llevado al menos 20 minutos de copiar y pegar.
Paso 4: extraer reseñas de Glassdoor
Esta es la sección que ningún otro tutorial ofrece con código funcional. Las reseñas son donde vive la verdadera inteligencia sobre empleadores: análisis de sentimiento, señales culturales, alertas de gestión.
Navega a la página de reseñas
Las URLs de reseñas siguen este patrón: /Reviews/{Company}-Reviews-E{id}.htm. Puedes encontrar el ID del empleador buscando una empresa en Glassdoor y revisando la URL.
1def navigate_to_reviews(page, company_reviews_url):
2 page.goto(company_reviews_url)
3 page.add_style_tag(content="""
4 #HardsellOverlay, .LoginModal { display: none !important; }
5 body { overflow: auto !important; position: initial !important; }
6 """)
7 page.wait_for_selector('[data-test="review"]', timeout=15000)El endpoint BFF oculto (la vía más limpia)
Este es el hallazgo más importante de mi investigación: las reseñas de Glassdoor tienen una API JSON interna funcional que evita por completo el parseo HTML. El documenta este endpoint, y es mucho más fiable que raspar el DOM.
1import json, re, requests
2def get_review_ids(page):
3 """Extrae employerId y dynamicProfileId del HTML de la página de reseñas."""
4 html = page.content()
5 sel = Selector(text=html)
6 script_text = sel.xpath(
7 "//script[contains(text(), 'profileId')]/text()"
8 ).get("")
9 employer_match = re.search(r'"employer"\s*:\s*(\{[^}]+\})', script_text)
10 if employer_match:
11 meta = json.loads(employer_match.group(1))
12 return meta.get("id"), meta.get("profileId")
13 return None, None
14def fetch_reviews_bff(page, employer_id, profile_id, max_pages=5):
15 """Llama al endpoint BFF interno de Glassdoor para obtener reseñas estructuradas."""
16 all_reviews = []
17 cookies = {c["name"]: c["value"] for c in page.context.cookies()}
18 for pg in range(1, max_pages + 1):
19 payload = {
20 "applyDefaultCriteria": True,
21 "employerId": employer_id,
22 "dynamicProfileId": profile_id,
23 "employmentStatuses": ["REGULAR", "PART_TIME"],
24 "language": "eng",
25 "onlyCurrentEmployees": False,
26 "page": pg,
27 "pageSize": 10,
28 "sort": "DATE",
29 "textSearch": "",
30 }
31 resp = requests.post(
32 "https://www.glassdoor.com/bff/employer-profile-mono/employer-reviews",
33 json=payload,
34 cookies=cookies,
35 headers={"Content-Type": "application/json"},
36 )
37 if resp.status_code != 200:
38 print(f"BFF devolvió {resp.status_code} en la página {pg}")
39 break
40 data = resp.json()
41 reviews = data.get("data", {}).get("employerReviews", {}).get("reviews", [])
42 total_pages = data.get("data", {}).get("employerReviews", {}).get("numberOfPages", 1)
43 for r in reviews:
44 all_reviews.append({
45 "title": r.get("summary", ""),
46 "rating": r.get("ratingOverall"),
47 "pros": r.get("pros", ""),
48 "cons": r.get("cons", ""),
49 "author_role": r.get("jobTitle", {}).get("text", ""),
50 "date": r.get("reviewDateTime", ""),
51 "recommend": r.get("isRecommend"),
52 })
53 print(f"Página de reseñas {pg}/{total_pages}: se obtuvieron {len(reviews)} reseñas")
54 if pg >= total_pages:
55 break
56 time.sleep(random.uniform(3, 6))
57 return all_reviewsEl endpoint BFF te entrega JSON limpio con todos los campos de reseñas — sin parseo HTML ni roturas por cambios de selectores. Necesitas cookies de sesión desde un contexto autenticado de Playwright (cubierto en el Paso 6 más abajo), y primero debes extraer employerId y dynamicProfileId del HTML de la página de reseñas.
Selectores HTML de respaldo para reseñas
Si el endpoint BFF cambia o prefieres parsear el DOM, estos son los selectores data-test estables:
| Campo | Selector |
|---|---|
| Contenedor de reseña | [data-test="review"] |
| Titular | [data-test="review-title"] |
| Calificación general | [data-test="overall-rating"] |
| Pros | [data-test="pros"] |
| Contras | [data-test="cons"] |
| Fecha | [data-test="review-date"] |
| Cargo del autor | [data-test="author-jobTitle"] |
Paso 5: extraer datos salariales de Glassdoor
Las páginas de salarios están totalmente protegidas por login. Debes tener una sesión autenticada (Paso 6) antes de que este código devuelva datos reales.
Navega a la página de salarios
Las URLs de salarios siguen este patrón: /Salary/{Company}-Salaries-E{id}.htm, con paginación como _P{n}.htm.
1def scrape_salaries(page, salary_url, max_pages=3):
2 all_salaries = []
3 for pg in range(1, max_pages + 1):
4 url = salary_url if pg == 1 else salary_url.replace(".htm", f"_P{pg}.htm")
5 page.goto(url)
6 page.add_style_tag(content="""
7 #HardsellOverlay { display: none !important; }
8 body { overflow: auto !important; position: initial !important; }
9 """)
10 time.sleep(random.uniform(3, 7))
11 html = page.content()
12 sel = Selector(text=html)
13 items = sel.css('[data-test="salary-item"]')
14 if not items:
15 print(f"Página de salarios {pg}: no se encontraron elementos — posible bloqueo o muro de login.")
16 break
17 for item in items:
18 salary = {
19 "job_title": item.css('[class*="SalaryItem_jobTitle__"]::text').get("").strip(),
20 "salary_range": item.css('[class*="SalaryItem_salaryRange__"]::text').get("").strip(),
21 "count": item.css('[class*="SalaryItem_salaryCount__"]::text').get("").strip(),
22 }
23 all_salaries.append(salary)
24 print(f"Página de salarios {pg}: se extrajeron {len(items)} registros")
25 return all_salariesFíjate en el patrón de coincidencia por prefijo [class*="SalaryItem_jobTitle__"]. La página de salarios de Glassdoor usa nombres de clase CSS generados por CSS modules (por ejemplo, SalaryItem_jobTitle__XWGpT) donde el sufijo hash cambia en cada despliegue. El prefijo se mantiene estable; el hash no. Nunca hardcodees el nombre completo de la clase.
Paso 6: supera el muro de login de Glassdoor
Esta es la pieza clave que desbloquea los datos salariales y el texto completo de las reseñas. El enfoque: iniciar sesión una vez manualmente en un navegador visible, guardar el estado autenticado y reutilizarlo en todas las ejecuciones posteriores.
Guarda tu sesión autenticada
Ejecuta este script una vez. Abre una ventana de Chrome, navega a la página de login de Glassdoor (que ahora redirige a Indeed Login) y espera a que inicies sesión manualmente:
1import asyncio
2from pathlib import Path
3from patchright.async_api import async_playwright
4STATE_FILE = Path("glassdoor_state.json")
5async def login_and_save():
6 async with async_playwright() as p:
7 browser = await p.chromium.launch(headless=False, channel="chrome")
8 context = await browser.new_context(
9 viewport={"width": 1366, "height": 800},
10 locale="en-US",
11 )
12 page = await context.new_page()
13 await page.goto("https://www.glassdoor.com/profile/login_input.htm")
14 print("Inicia sesión en la ventana del navegador y luego presiona Enter aquí...")
15 input()
16 await context.storage_state(path=str(STATE_FILE))
17 print(f"Sesión guardada en {STATE_FILE}")
18 await browser.close()
19asyncio.run(login_and_save())Después de iniciar sesión y pulsar Enter, Patchright guarda todas las cookies y el local storage en glassdoor_state.json. Ese archivo contiene tus gdId, GSESSIONID, cf_clearance y tokens de autenticación.
Reutiliza la sesión para hacer scraping
Cada ejecución posterior carga el estado guardado — sin necesidad de volver a iniciar sesión manualmente:
1async def scrape_with_auth(target_url):
2 async with async_playwright() as p:
3 browser = await p.chromium.launch(headless=True, channel="chrome")
4 context = await browser.new_context(
5 storage_state="glassdoor_state.json"
6 )
7 page = await context.new_page()
8 await page.goto(target_url)
9 await page.add_style_tag(
10 content="#HardsellOverlay{display:none!important}"
11 )
12 await page.wait_for_load_state("networkidle")
13 html = await page.content()
14 await browser.close()
15 return htmlLa sesión guardada suele durar entre 20 y 30 minutos de uso activo antes de que Glassdoor vuelva a desafiarla. Para sesiones de scraping más largas, incluye una comprobación: si una página que debería tener datos devuelve cero resultados, vuelve a ejecutar el script de login para refrescar el archivo de estado.
Detectar y cerrar la ventana emergente de login
En páginas parcialmente protegidas (ofertas que muestran datos pero cubren todo con un modal), el método de inyección CSS de pasos anteriores funciona:
1page.add_style_tag(content="""
2 #HardsellOverlay, .LoginModal { display: none !important; }
3 body { overflow: auto !important; position: initial !important; }
4""")Esto solo funciona cuando el HTML ya contiene los datos debajo del overlay. En páginas totalmente protegidas por el servidor (salarios, páginas profundas de reseñas), la sesión autenticada del Paso 6 es la única vía.
Consejos para que tu scraper de Glassdoor siga funcionando
Glassdoor actualiza su frontend con frecuencia. Así puedes construir resiliencia en tu scraper.
Prefiere atributos data-test sobre nombres de clase
Glassdoor randomiza los nombres de clase CSS, pero tiende a mantener estables los atributos data-test. Siempre prefiere [data-test="jobListing"] frente a .jobCard_abc123. Cuando data-test no esté disponible (como ocurre con algunas clases de salarios), usa coincidencia por prefijo: [class*="SalaryItem_jobTitle__"].
Rota proxies y aleatoriza los retrasos
Usa proxies residenciales rotativos — las IPs de centros de datos reciben desafíos casi de inmediato. Añade retrasos aleatorios de 3–8 segundos entre cargas de página (5–15 segundos en ejecuciones largas). Si puedes, evita scrapear durante horario laboral de EE. UU., cuando la detección de comportamiento de Cloudflare es más agresiva.
Vigila las roturas
Incluye una comprobación simple: si una página que debería tener datos devuelve cero registros, trátalo como fallo de selectores, no como conjunto vacío, y envíate una alerta. Ejecuta una prueba pequeña cada semana para detectar roturas pronto — Glassdoor despliega cambios de frontend sin avisar.
Usa la vía rápida __NEXT_DATA__ cuando sea posible
Glassdoor es una app basada en Next.js + Apollo GraphQL. Muchas páginas incluyen una etiqueta <script id="__NEXT_DATA__"> con toda la caché GraphQL en JSON. Parsear eso es mucho más resistente que hacer scraping del DOM y :
1import json
2def extract_next_data(html):
3 sel = Selector(text=html)
4 raw = sel.css("script#__NEXT_DATA__::text").get()
5 if raw:
6 return json.loads(raw)["props"]["pageProps"].get("apolloCache", {})
7 return NoneEsto devuelve la caché estructurada de Apollo con todos los campos de empleo, reseñas y salarios — sin necesidad de selectores CSS. Es la estrategia de extracción más robusta disponible, porque usa los mismos datos que alimentan el frontend React de Glassdoor.
Omitir el código: extraer Glassdoor con Thunderbit (sin usar Python)
No todas las personas que leen esto son desarrolladores. Los equipos de RR. HH., reclutadores, analistas de operaciones comerciales e investigadores de mercado también necesitan datos de Glassdoor — y no deberían tener que gestionar contextos de Playwright ni rotación de proxies para conseguirlos.
es una extensión de Chrome con AI Web Scraper que puede extraer los mismos datos de empleos, reseñas y salarios sin escribir una sola línea de código. Trabajo en el equipo de Thunderbit, así que lo digo con transparencia — pero la razón por la que lo incluyo aquí es que realmente resuelve los dos problemas más difíciles del scraping de Glassdoor.
Cómo funciona Thunderbit en Glassdoor
El flujo son dos clics:
- Abre cualquier página de Glassdoor en Chrome (búsqueda de empleo, reseñas de empresa, página salarial)
- Haz clic en AI Suggest Fields en la barra lateral de Thunderbit — la IA lee el DOM de la página y propone columnas (título del empleo, empresa, calificación, rango salarial, pros, contras, etc.)
- Haz clic en Scrape — los datos se extraen en una tabla sin selectores CSS ni código de automatización del navegador
Thunderbit tiene una que extrae más de 23 campos por empresa en una sola ejecución. Para ofertas de empleo, reseñas o salarios, el flujo genérico de AI Suggest Fields funciona con cualquier URL de Glassdoor.
Cómo saltarse el muro de login sin código
Aquí está la ventaja estructural de Thunderbit para Glassdoor. Browser Mode se ejecuta dentro de tu propia sesión de Chrome — si ya has iniciado sesión en Glassdoor en Chrome, Thunderbit hereda automáticamente esas cookies. El muro de login que bloquea a los scrapers del lado del servidor simplemente deja de ser un problema. Sin gestión de cookies, sin contextos persistentes, sin código de sesión.
Scraping de subpáginas para enriquecer datos
Puedes empezar desde una lista (por ejemplo, 30 empresas de una búsqueda), dejar que Thunderbit enumere las filas y luego activar para visitar la página de reseñas o salarios de cada empresa y enriquecer la tabla con descripciones completas, texto de reseñas o detalles salariales.
Exporta a herramientas de negocio
A diferencia de los scripts en Python que generan CSV o JSON, Thunderbit exporta directamente a Google Sheets, Airtable, Notion o Excel — gratis en todos los planes. Es especialmente útil para equipos que necesitan compartir y analizar datos de forma colaborativa.
Python vs. Thunderbit: cuándo usar cada uno
| Escenario | Enfoque recomendado |
|---|---|
| Construir una tubería de datos recurrente | Python + Patchright |
| Investigación puntual o proyecto pequeño de equipo | Thunderbit |
| Necesitas control programático de cada campo | Python |
| No eres desarrollador y necesitas datos de Glassdoor hoy | Thunderbit |
| Extraer más de 1,000 páginas en una sola ejecución | Python + proxies |
| Extraer 30 empresas con enriquecimiento | Cualquiera sirve — Thunderbit es más rápido de configurar |
Thunderbit empieza con un plan gratis (6 páginas/mes), y el por 3,000 créditos. Con 1 crédito por fila de salida (2 créditos para scraping de subpáginas), eso alcanza para unas 33 ejecuciones de 30 empresas enriquecidas al mes.
¿Es legal extraer datos de Glassdoor?
Lo diré de forma breve y objetiva. Los de Glassdoor prohíben explícitamente el scraping automatizado: "You may not use any robot, spider, scraper... to access the Services for any purpose without our express written permission."
Sin embargo, el panorama legal es más matizado que una sola cláusula de ToS:
- (N.D. Cal., ene. 2024): el tribunal sostuvo que si nunca inicias sesión, nunca aceptaste las ToS, y el scraping público sin login no las viola
- hiQ Labs v. LinkedIn (9th Cir.): la CFAA no aplica a la recopilación automatizada de datos públicamente accesibles — pero las cuentas falsas y el scraping con sesión iniciada son otra historia
- Van Buren v. United States (Corte Suprema, 2021): restringió el concepto de "exceeds authorized access" bajo la CFAA
La conclusión práctica: extraer ofertas públicas sin iniciar sesión se sitúa en una zona legal comparativamente más segura. Scrapear con una sesión iniciada significa que aceptaste las ToS al registrarte, y estas lo prohíben explícitamente. Esto aplica por igual a scripts en Python y al Browser Mode de Thunderbit.
Pautas éticas que conviene seguir de todos modos:
- Limita la velocidad muy por debajo de la navegación humana
- No extraigas ni revendas información personal identificable de reseñas
- Respeta las directivas de robots.txt
- Extrae solo los campos que realmente necesitas
Conclusión: ¿qué método te conviene?
Esta guía cubrió los tres tipos de datos de Glassdoor — empleos, reseñas y salarios — con código funcional para 2025 que ya contempla la migración a Indeed Login, Cloudflare Bot Management y la rotación de nombres de clase CSS modules que rompió todos los tutoriales antiguos.
Aquí tienes el marco de decisión:
| Tu situación | Mejor camino |
|---|---|
| Desarrollador que construye una tubería de datos | Python + Patchright (sigue el paso a paso de arriba) |
| Investigación puntual o extracciones pequeñas recurrentes | Thunderbit (sin código, basado en navegador) |
| Solo necesitas ofertas básicas a pequeña escala | Primero comprueba si aún existe acceso a la API de Glassdoor (probablemente no) |
| Necesitas específicamente datos de salarios o reseñas | Debes usar Python o Thunderbit — la API nunca cubrió eso |
| Equipo sin perfil técnico que necesita datos compartidos | Thunderbit → exportar a Google Sheets |
Las defensas de Glassdoor seguirán evolucionando. Los selectores se romperán. Aparecerán nuevos desafíos. Guarda esta guía en favoritos — y si quieres profundizar en herramientas y técnicas de scraping web, revisa nuestros artículos sobre , y . También puedes ver tutoriales en el .
Preguntas frecuentes
1. ¿Se puede extraer Glassdoor sin iniciar sesión?
Sí, para la mayoría de los datos de ofertas de empleo y las calificaciones generales de la empresa. No, para desgloses salariales completos o el texto completo de las reseñas más allá de las primeras páginas. El #HardsellOverlay es un modal solo en CSS — el HTML subyacente sigue conteniendo los datos de la primera página — pero el contenido más profundo está protegido por el muro "give-to-get" de Glassdoor.
2. ¿Qué librería de Python funciona mejor para extraer Glassdoor en 2025?
Patchright (un fork sigiloso de Playwright) es la recomendación por defecto. Corrige la filtración Runtime.Enable CDP que tiene Playwright puro y que Cloudflare detecta explícitamente. Para páginas de listado que incluyen __NEXT_DATA__ en el HTML inicial, curl_cffi con impersonate="chrome124" es 10–20 veces más rápido, pero no puede manejar páginas protegidas por login.
3. ¿Cómo evito que me bloqueen al extraer Glassdoor?
Usa Patchright o rebrowser-playwright (no Playwright puro ni Selenium). Rota proxies residenciales — las IPs de centros de datos se desafían de inmediato. Añade retrasos aleatorios de 3–8 segundos entre páginas. Conserva las cookies (gdId, cf_clearance, GSESSIONID) entre solicitudes. Espera una ventana de sesión de 20–30 minutos antes de que te vuelvan a desafiar.
4. ¿Existe una API de Glassdoor que pueda usar en lugar de scraping?
En la práctica, no. La antigua Partner API , nunca existió un endpoint público para reseñas y no hay una ruta de migración bajo la Publisher API de Indeed. Para reseñas y datos salariales, scraping o una herramienta sin código como Thunderbit son las únicas opciones reales.
5. ¿Con qué frecuencia se rompe un scraper de Glassdoor?
Con frecuencia. Glassdoor despliega cambios de frontend sin aviso y los hashes de las clases CSS modules cambian en cada compilación. Las estrategias de extracción más estables son: (1) selectores con atributos data-test, (2) el bloque JSON __NEXT_DATA__ y (3) el endpoint BFF interno de reseñas. Incluye una comprobación de resultados vacíos y ejecuta una prueba pequeña cada semana para detectar roturas cuanto antes.
Más información