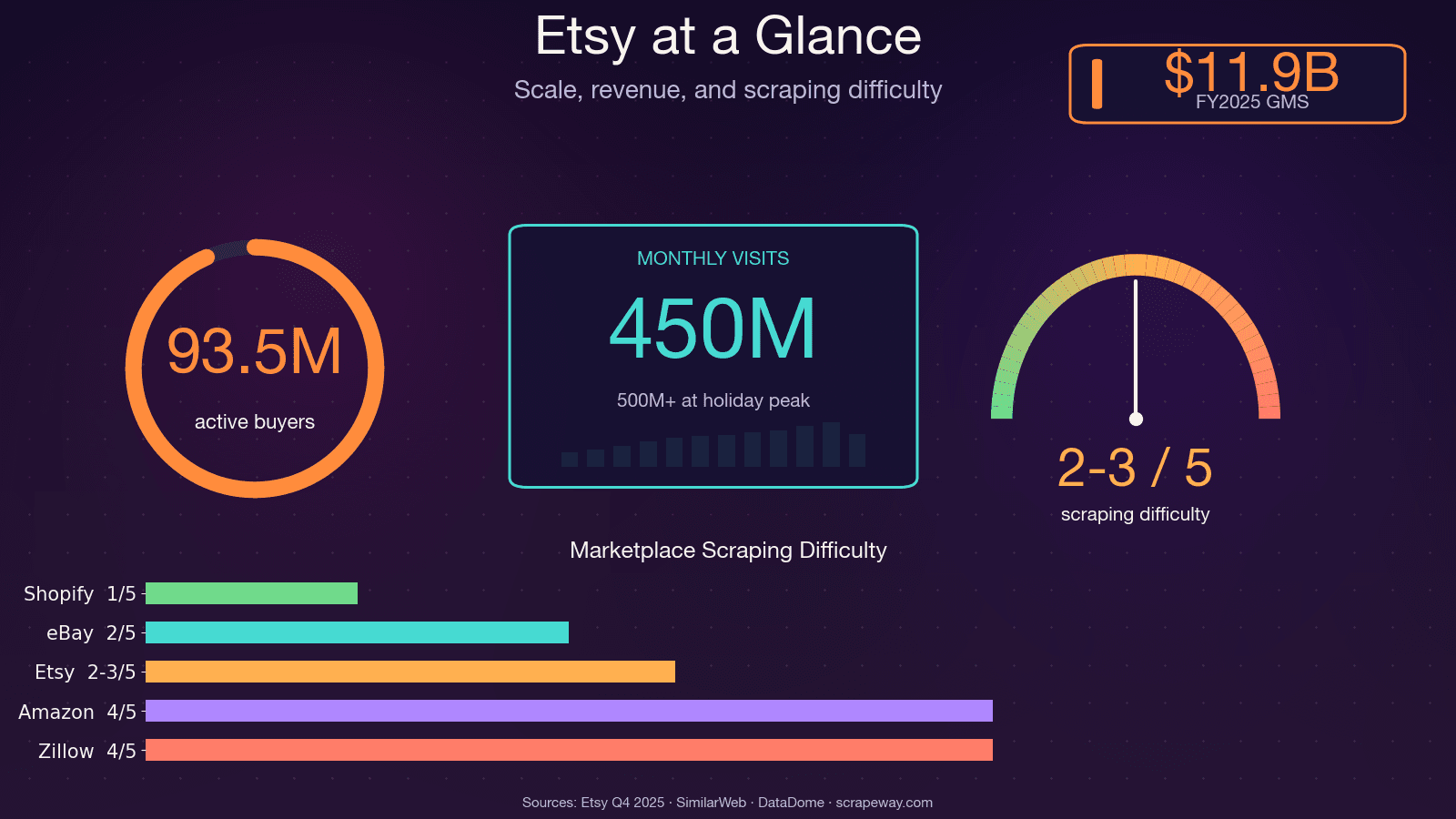
Etsy tiene más de 100 millones de anuncios activos, 5,6 millones de vendedores y unas 450 millones de visitas mensuales. Eso es una gran cantidad de datos públicos sobre precios, tendencias, reseñas y competidores; y si alguna vez has intentado recopilarlos a mano, sabes lo doloroso que puede llegar a ser.
Una vez pasé un fin de semana intentando catalogar manualmente productos de la competencia para un proyecto de estudio de mercado. Para el producto número 30, ya estaba cuestionándome todas las decisiones de vida que me habían llevado a esa hoja de cálculo. El punto es este: los datos de Etsy son increíblemente valiosos para análisis de precios, desarrollo de productos, descubrimiento de nichos y evaluación comparativa de vendedores, pero solo si realmente puedes obtenerlos a escala. De eso va esta guía: un tutorial único que explica cómo extraer datos de Etsy con Python en los cuatro tipos principales de páginas (resultados de búsqueda, páginas de producto, páginas de tiendas y reseñas), además de una guía honesta sobre las defensas anti-bot de Etsy y una alternativa sin código para quienes prefieran saltarse por completo la programación.
¿Qué significa extraer datos de Etsy con Python?
La extracción de datos web, en términos sencillos, consiste en escribir código que visita páginas web y extrae automáticamente la información que te interesa — nombres de productos, precios, descripciones, imágenes, valoraciones, reseñas, detalles de la tienda — y la organiza en un formato estructurado como una hoja de cálculo o una base de datos.
Python es el lenguaje de referencia para este tipo de trabajo. Es fácil para principiantes, tiene una comunidad enorme y ofrece un ecosistema de bibliotecas muy sólido para la extracción: Requests (para obtener páginas), BeautifulSoup (para analizar HTML), Selenium y Playwright (para automatización del navegador) y pandas (para organizar y exportar datos). Python se mantiene de forma constante entre los 3 lenguajes más populares en la encuesta anual de desarrolladores de Stack Overflow, y sus bibliotecas de scraping figuran entre las más descargadas en PyPI.
Cuando extraes datos de Etsy, estás obteniendo información del HTML y, a veces, de JSON oculto que Etsy envía a tu navegador. Entre los datos que puedes extraer están:
- Nombres de productos, precios, descripciones, imágenes y variaciones
- Información del vendedor o la tienda (nombre, número de ventas, ubicación, valoración)
- Valoraciones y texto completo de las reseñas
- Resultados de búsqueda, categorías y señales de tendencia
¿Por qué extraer datos de Etsy? Casos de uso reales que impulsan el ROI
Extraer datos de Etsy no es solo un ejercicio técnico: es una ventaja competitiva. Tanto si eres vendedor, gestor de producto o analista de datos, tener datos estructurados de Etsy al alcance puede influir directamente en tus resultados.
| Caso de uso | Qué extraes | Quién se beneficia | Impacto empresarial |
|---|---|---|---|
| Análisis de precios competitivos | Resultados de búsqueda + precios de productos | Operaciones de e-commerce, vendedores | El precio dinámico puede aumentar los ingresos entre un 5–22%, de media |
| Descubrimiento de nichos y tendencias | Resultados de búsqueda, anuncios en tendencia | Fundadores, analistas | Detecta nichos en tendencia antes que nadie (por ejemplo, "preppy pajamas" tuvo un crecimiento de búsquedas de +1.112%) |
| Desarrollo y mejora de productos | Reseñas, detalles de producto | Equipos de producto | Una marca de utensilios de cocina recuperó el puesto #1 de superventas en 60 días usando datos de sentimiento de reseñas |
| SEO e investigación de palabras clave | Resultados de búsqueda, títulos/tags de productos | Equipos de marketing | Identifica palabras clave con alta demanda y poca competencia |
| Evaluación comparativa de vendedores | Páginas de tienda, número de ventas | Equipos de ventas, analistas | Crea listas de leads cualificados por 0,01–0,10 USD por registro frente a listas compradas |
| Monitorización de inventario y stock | Disponibilidad de producto | Operaciones de e-commerce | Reacciona más rápido a los cambios de stock de la competencia |
Cada uno de estos casos de uso requiere datos de distintos tipos de páginas de Etsy, y precisamente por eso este tutorial cubre los cuatro.
Ahorro de tiempo: manual vs. automatizado
- Investigación manual en Etsy: 30–45 minutos por producto (50–75 horas para 100 productos)
- Extracción automatizada: 100 anuncios en 2–5 minutos
- La extracción con IA es entre y puede alcanzar hasta un 99,5% de precisión
API de Etsy vs. extracción web: ¿cuál deberías elegir?
Antes de escribir una sola línea de código, conviene hacerse la pregunta: ¿debería usar la API oficial de Etsy o extraer el sitio directamente? Es una duda que veo constantemente en foros, y la respuesta depende de qué datos necesites.
Lo que la API de Etsy puede y no puede hacer
Etsy ofrece una API v3 con autenticación OAuth 2.0. Sirve para acceder a los datos de tu propia tienda — anuncios, pedidos, recibos. Pero tiene limitaciones reales:
- Datos de la competencia: la API está restringida en gran medida a tu propia tienda. No puedes extraer precios, ventas o anuncios de otro vendedor.
- Reseñas: no hay un endpoint robusto para el texto completo de reseñas en bloque.
- Límites de uso: 10 solicitudes por segundo, 10.000 solicitudes al día por defecto. El límite de offset es de 12.000 registros.
- Uso para IA/ML: rechazado explícitamente en la revisión de aplicaciones.
- Documentación: abundan las quejas de la comunidad — ejemplos pobres, endpoints obsoletos, soporte lento.
Cuándo la extracción web es la mejor opción
Si necesitas inteligencia sobre la competencia, sentimiento de reseñas, análisis entre tiendas o datos más allá de lo que expone la API, la extracción es el camino adecuado. La contrapartida: te enfrentarás a las defensas anti-bot de Etsy (más sobre eso abajo) y tendrás que dedicar tiempo a la configuración.
Tabla comparativa: API vs. extracción vs. sin código
| Criterio | API oficial de Etsy | Extracción web con Python | Thunderbit (sin código) |
|---|---|---|---|
| Acceso a precios de productos | ✅ (campos limitados) | ✅ HTML/JSON-LD completo | ✅ La IA extrae cualquier campo visible |
| Datos de reseñas | ❌ No disponible en bloque | ✅ Mediante endpoint de reseñas/HTML | ✅ Extracción de subpáginas |
| Datos de tiendas de la competencia | ❌ Solo tu propia tienda | ✅ Cualquier tienda pública | ✅ Cualquier tienda pública |
| Se requiere autenticación | ✅ OAuth 2.0 | ⚠️ Cookies para datos con sesión iniciada | ⚠️ Extracción en navegador para login |
| Riesgo anti-bot | Ninguno | ALTO (DataDome) | Gestionado (nativo del navegador) |
| Tiempo de configuración | Medio (claves API, OAuth) | Alto (código + proxies) | ~2 minutos |
Si necesitas datos de la competencia, reseñas o análisis entre tiendas, la API simplemente no llega. Esa es la realidad.
Elige tu enfoque de extracción en Python antes de escribir una línea de código
Una pregunta que veo constantemente en Reddit y Stack Overflow: "¿Debería usar Requests + BeautifulSoup, Selenium, una API de proxies u otra cosa?" La respuesta correcta depende de tu nivel, presupuesto y caso de uso.
| Enfoque | Ideal para | Curva de aprendizaje | ¿Maneja JS? | Gestión anti-bot | Coste |
|---|---|---|---|---|---|
| Requests + BeautifulSoup | Desarrolladores que quieren control total | Media | ❌ | Manual (headers, proxies) | Gratis + coste de proxies |
| Selenium / Playwright | Páginas con mucho JS, flujos de login | Alta | ✅ | Parcial (huella del navegador) | Gratis + coste de proxies |
| Servicios de API de proxies | Escala + evasión anti-bot | Media | ✅ (vía API) | ✅ Integrado | 49 USD+/mes |
| Thunderbit (sin código) | No desarrolladores, extracción rápida | Muy baja | ✅ (nativo del navegador) | ✅ (sesión del navegador) | Hay plan gratis |
Si quieres control total y te sientes cómodo con Python, ve con Requests + BeautifulSoup. Si necesitas renderizado JS o flujos de login, usa Selenium. Si quieres evasión anti-bot a escala, considera un servicio de proxies. Y si quieres datos de Etsy sin escribir ni mantener código, Thunderbit merece una mirada — más adelante te cuento por qué.
Cómo se defiende Etsy: entender la protección anti-bot DataDome
La mayoría de las guías de scraping te dirán "usa un proxy" y seguirán adelante. Con Etsy eso no basta. Etsy utiliza DataDome, uno de los sistemas anti-bot más agresivos de la web. Un presenta Etsy como un caso de éxito y señala que, en su día, los scrapers representaban alrededor del 1% de los costes de computación de Etsy.
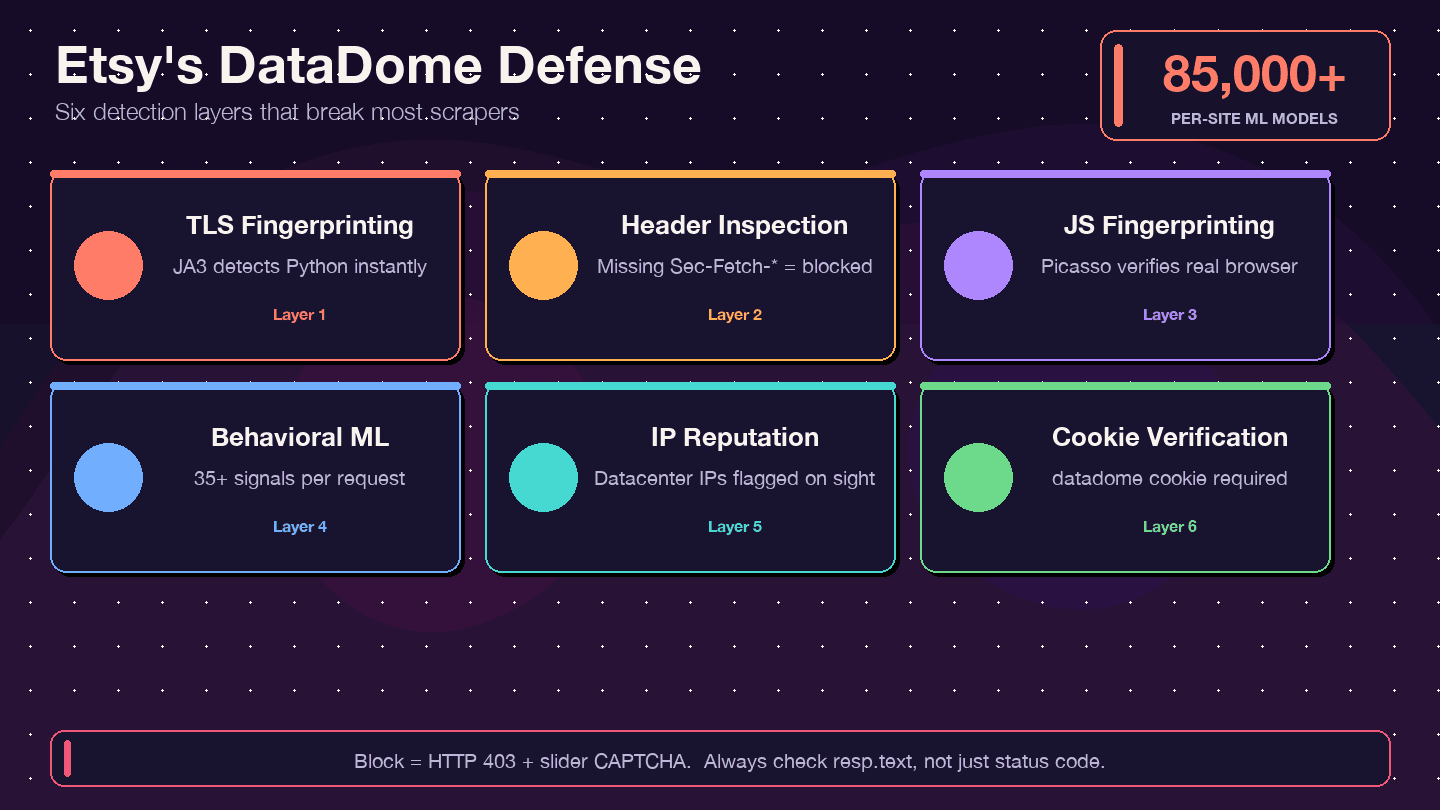
Qué es DataDome y cómo funciona
DataDome no se limita a comprobar tu dirección IP. Ejecuta una detección multicapa:
- Fingerprinting TLS (JA3): la biblioteca
requestsde Python tiene una firma TLS distintiva que DataDome puede detectar al instante. - Inspección de cabeceras/protocolo HTTP: comprueba que las cabeceras del navegador sean completas y coherentes; si faltan o están desordenadas, es una señal de alerta.
- Fingerprinting JavaScript (protocolo Picasso): ejecuta desafíos JS en el navegador para verificar que eres un usuario real.
- ML de comportamiento: analiza más de 35 señales por solicitud, con más de 85.000 modelos por sitio.
- Puntuación de reputación de IP: las IP de centros de datos se marcan de inmediato.
- Verificación de cookies: la cookie
datadomedebe estar presente y ser válida.
Señales de que te han bloqueado (y cómo comprobarlo)
Uno de los fallos más comunes: recibes una respuesta 200 OK, pero el HTML en realidad es una página de CAPTCHA, no los datos que querías. Otras señales:
- Errores 403 Forbidden
- Bucles de redirección
- El cuerpo de la respuesta contiene un objeto JavaScript
ddo HTML de CAPTCHA con deslizador
Comprueba siempre el cuerpo de la respuesta, no solo el código de estado. Una verificación rápida:
1if "captcha" in resp.text.lower() or "datadome" in resp.text.lower():
2 print("¡Bloqueado! Se obtuvo una página CAPTCHA en lugar de datos.")Headers y cookies que reducen la detección
No puedes garantizar que no te bloqueen, pero unas cabeceras realistas y una buena gestión de cookies ayudan mucho:
1session = requests.Session()
2session.headers.update({
3 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/133.0.0.0 Safari/537.36",
4 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,image/avif,image/webp,*/*;q=0.8",
5 "Accept-Language": "en-US,en;q=0.9",
6 "Accept-Encoding": "gzip, deflate, br",
7 "Sec-Ch-Ua": '"Chromium";v="133", "Not-A.Brand";v="99", "Google Chrome";v="133"',
8 "Sec-Ch-Ua-Mobile": "?0",
9 "Sec-Ch-Ua-Platform": '"Windows"',
10 "Sec-Fetch-Dest": "document",
11 "Sec-Fetch-Mode": "navigate",
12 "Sec-Fetch-Site": "none",
13 "Upgrade-Insecure-Requests": "1",
14})También es importante:
- Persistir las cookies entre solicitudes usando
requests.Session(). - Añadir retardos aleatorios (2–7 segundos) entre solicitudes.
- Simular una cadena de referer: visita primero la página principal, luego la búsqueda y después las páginas de producto.
- A escala, la rotación de proxies residenciales es esencial. Las IP de centros de datos se marcan casi al instante.
Estas técnicas reducen la detección, pero no la eliminan. Para scraping de alto volumen, probablemente necesitarás un servicio de proxies o un enfoque basado en navegador.
Preparar tu entorno Python para extraer datos de Etsy
Antes de empezar:
- Dificultad: intermedia
- Tiempo requerido: ~30–60 minutos (configuración + primera extracción)
- Lo que necesitas: Python 3.8+, pip, un editor de código, navegador Chrome (para inspección con DevTools)
Instalar dependencias
Crea una carpeta de proyecto, configura un entorno virtual e instala las bibliotecas que necesitarás:
1mkdir etsy-scraper && cd etsy-scraper
2python -m venv venv
3source venv/bin/activate # En Windows: venv\Scripts\activate
4pip install requests beautifulsoup4 lxml pandas- requests — obtiene páginas web
- beautifulsoup4 — analiza HTML
- lxml — analizador HTML más rápido (opcional pero recomendable)
- pandas — estructura y exporta datos a CSV/Excel
Si más adelante necesitas automatización del navegador (para login o páginas con mucho JS), instala también:
1pip install seleniumEntiende la estructura de las páginas de Etsy antes de programar
Aquí va un consejo que ahorra muchísimo tiempo: Etsy incrusta datos estructurados del producto dentro de etiquetas <script type="application/ld+json"> en la mayoría de las páginas. Esos datos JSON-LD ya están organizados — nombre del producto, precio, valoración, imágenes — así que no tienes que pelearte con selectores CSS frágiles para cada campo.
Abre cualquier página de producto de Etsy, haz clic derecho, "Ver código fuente de la página" y busca application/ld+json. Encontrarás un bloque con @type: Product que contiene la mayor parte de los datos que necesitas. Las páginas de resultados de búsqueda tienen @type: ItemList.
Los selectores CSS siguen siendo útiles como respaldo (para datos que no están en JSON-LD, como detalles de envío o texto de reseñas), pero JSON-LD debería ser tu primera parada.
Paso 1: extraer resultados de búsqueda de Etsy con Python
Los resultados de búsqueda son el punto de partida de la mayoría de los proyectos de scraping de Etsy — tanto si estás monitorizando un nicho, siguiendo precios de competidores o creando una base de datos de productos.
Construir la URL de búsqueda
Las URLs de búsqueda de Etsy siguen este patrón:
1https://www.etsy.com/search?q=\{keyword\}&ref=pagination&page=\{page_number\}Para consultas de varias palabras, codifica los espacios en la URL (por ejemplo, handmade+jewelry o handmade%20jewelry). El parámetro ref=pagination hace que la solicitud se parezca más a una navegación real del navegador.
Otros parámetros útiles: order (most_relevant, price_asc, price_desc, date_desc), min_price, max_price, ship_to, free_shipping=true. Cada página devuelve 48 elementos.
Enviar la solicitud y analizar el HTML
1import requests
2from bs4 import BeautifulSoup
3import json
4import time
5import random
6headers = {
7 "User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 Chrome/124.0.0.0 Safari/537.36",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
10}
11def scrape_etsy_search(query, max_pages=3):
12 all_products = []
13 for page in range(1, max_pages + 1):
14 url = f"https://www.etsy.com/search?q=\{query\}&ref=pagination&page=\{page\}"
15 resp = requests.get(url, headers=headers, timeout=30)
16 if "captcha" in resp.text.lower():
17 print(f"Bloqueado en la página \{page\}. Prueba a añadir retardos o proxies.")
18 break
19 soup = BeautifulSoup(resp.text, "lxml")
20 for script in soup.find_all("script", type="application/ld+json"):
21 data = json.loads(script.string)
22 if data.get("@type") == "ItemList":
23 for item in data.get("itemListElement", []):
24 all_products.append({
25 "name": item.get("name"),
26 "url": item.get("url"),
27 "image": item.get("image"),
28 "price": item.get("offers", {}).get("price"),
29 "currency": item.get("offers", {}).get("priceCurrency"),
30 "position": item.get("position"),
31 })
32 time.sleep(random.uniform(2, 5))
33 return all_productsExtraer datos de los anuncios desde JSON-LD
El array itemListElement te da el nombre, la URL, la imagen, el precio y la moneda de cada anuncio. Si también necesitas valoraciones con estrellas o el número de resultados (no siempre están en JSON-LD), recurre a selectores CSS:
- Tarjeta del anuncio:
.v2-listing-card - Título:
h3.v2-listing-card__title - Precio:
span.currency-value - Enlace:
a.listing-link(href)
Gestionar la paginación
Recorre las páginas y añade un retraso aleatorio entre cada solicitud. Etsy suele devolver hasta 20–250 páginas según la consulta.
1results = scrape_etsy_search("handmade+jewelry", max_pages=5)
2print(f"Se extrajeron {len(results)} productos.")Para una extracción de 5 páginas, esto me llevó unos 20 segundos en las pruebas, frente a más de 30 minutos de copiar y pegar manualmente.
Paso 2: extraer páginas de producto de Etsy con Python
Una vez que tienes una lista de URLs de productos desde la búsqueda, el siguiente paso es obtener datos detallados de cada página de anuncio.
Obtener la página de producto
1def scrape_etsy_product(url):
2 resp = requests.get(url, headers=headers, timeout=30)
3 soup = BeautifulSoup(resp.text, "lxml")
4 for script in soup.find_all("script", type="application/ld+json"):
5 data = json.loads(script.string)
6 if data.get("@type") == "Product":
7 offers = data.get("offers", {})
8 price = offers.get("price") or offers.get("lowPrice")
9 rating_data = data.get("aggregateRating", {})
10 return {
11 "name": data.get("name"),
12 "description": data.get("description", "")[:500],
13 "brand": data.get("brand", {}).get("name") if isinstance(data.get("brand"), dict) else data.get("brand"),
14 "category": data.get("category"),
15 "price": price,
16 "currency": offers.get("priceCurrency"),
17 "availability": offers.get("availability"),
18 "rating": rating_data.get("ratingValue"),
19 "review_count": rating_data.get("reviewCount"),
20 "images": data.get("image", []),
21 "sku": data.get("sku"),
22 "material": data.get("material"),
23 }
24 return NoneGestionar variaciones de precio
Algunos productos tienen un único offers.price. Otros, con variaciones como talla o color, usan offers.lowPrice y offers.highPrice. El código anterior cubre ambos casos al recurrir primero a price y, si no existe, a lowPrice.
Analizar campos adicionales con selectores CSS
Para datos que no están en JSON-LD — información de envío, opciones de variación, detalles completos del vendedor — necesitarás selectores CSS:
- Título:
h1[data-buy-box-listing-title] - Variaciones:
select[data-selector-id]odiv[data-option-set] - Envío:
div.wt-text-captioncerca de la sección de envío
La contrapartida es clara: JSON-LD es más limpio y más estable frente a cambios de diseño. Los selectores CSS son frágiles, pero cubren más campos.
Paso 3: extraer páginas de tiendas de Etsy con Python
Esta es la sección que la mayoría de las guías de la competencia se salta por completo, y probablemente sea la más valiosa para equipos de ventas y analistas competitivos.
Construir la URL de la tienda y obtener la página
1def scrape_etsy_shop(shop_name):
2 url = f"https://www.etsy.com/shop/\{shop_name\}"
3 resp = requests.get(url, headers=headers, timeout=30)
4 soup = BeautifulSoup(resp.text, "lxml")
5 # Metadatos de la tienda desde el HTML (no en JSON-LD)
6 sales_el = soup.select_one("div.shop-sales-reviews a")
7 rating_el = soup.find("input", {"name": "initial-rating"})
8 location_el = soup.select_one("div.shop-location")
9 shop_data = {
10 "name": shop_name,
11 "sales": sales_el.text.strip() if sales_el else None,
12 "rating": rating_el["value"] if rating_el else None,
13 "location": location_el.text.strip() if location_el else None,
14 }
15 # Anuncios desde JSON-LD
16 listings = []
17 for script in soup.find_all("script", type="application/ld+json"):
18 data = json.loads(script.string)
19 if data.get("@type") == "ItemList":
20 for item in data.get("itemListElement", []):
21 listings.append({
22 "name": item.get("name"),
23 "url": item.get("url"),
24 "price": item.get("offers", {}).get("price"),
25 })
26 shop_data["listings"] = listings
27 return shop_dataQué puedes extraer de las páginas de tienda
El JSON-LD de las páginas de tienda es @type: ItemList — cubre los anuncios de productos, pero no metadatos de la tienda como el número de ventas, la ubicación o la valoración. Para eso necesitas selectores CSS:
| Dato | Selector | Notas |
|---|---|---|
| Nombre de la tienda | h1 o meta title | Normalmente en el título de la página |
| Ventas totales | div.shop-sales-reviews a | Texto como "12.345 ventas" |
| Valoración con estrellas | valor de input[name="initial-rating"] | Numérico, de 1 a 5 |
| Ubicación | div.shop-location | Ciudad, país |
| Miembro desde | div.shop-info | Texto con la fecha |
Los datos de tienda son especialmente valiosos para crear listas de leads, comparar competidores o identificar a los vendedores más fuertes de un nicho.
Paso 4: extraer reseñas de Etsy con Python
Las reseñas están entre los datos más valiosos — y más difíciles — de Etsy. El texto completo, las valoraciones y las fechas no están en el HTML inicial de la página; se cargan mediante un endpoint interno de API.
Opción 1: descubrir el endpoint interno de reseñas de Etsy
Abre una página de producto en Chrome, abre DevTools (F12), ve a la pestaña Network y baja hasta la sección de reseñas. Verás una solicitud POST a algo como:
1https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviewsEste endpoint devuelve fragmentos HTML que contienen las tarjetas de reseñas. Para usarlo, necesitas:
- listing_id — el ID numérico de la URL del producto
- shop_id — extraído del HTML de la página del producto mediante regex
- csrf_nonce — extraído de una etiqueta
<meta>de la página
Extraer IDs y token CSRF
1import re
2def get_review_params(product_url):
3 resp = requests.get(product_url, headers=headers)
4 html = resp.text
5 listing_id = product_url.split("/")[-1].split("?")[0]
6 shop_id_match = re.search(r'"shopId"\s*:\s*(\d+)', html)
7 shop_id = shop_id_match.group(1) if shop_id_match else None
8 soup = BeautifulSoup(html, "lxml")
9 csrf_meta = soup.find("meta", {"name": "csrf_nonce"})
10 csrf = csrf_meta["content"] if csrf_meta else None
11 return listing_id, shop_id, csrfExtraer reseñas con paginación
1def scrape_reviews(listing_id, shop_id, csrf, max_pages=5):
2 session = requests.Session()
3 session.headers.update(headers)
4 all_reviews = []
5 for page in range(1, max_pages + 1):
6 payload = {
7 "specs": {
8 "deep_dive_reviews": {
9 "module_path": "neu/specs/deep_dive_reviews",
10 "listing_id": listing_id,
11 "shop_id": shop_id,
12 "page": page,
13 }
14 }
15 }
16 resp = session.post(
17 "https://www.etsy.com/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews",
18 json=payload,
19 headers={"x-csrf-token": csrf, "Content-Type": "application/json"},
20 )
21 data = resp.json()
22 html_fragment = data.get("output", {}).get("deep_dive_reviews", "")
23 review_soup = BeautifulSoup(html_fragment, "lxml")
24 for card in review_soup.select("div.review-card"):
25 rating_el = card.find("input", {"name": "rating"})
26 text_el = card.select_one("div.wt-text-body")
27 user_el = card.select_one("a[data-review-username]")
28 date_el = card.select_one("p.wt-text-body-small")
29 all_reviews.append({
30 "rating": rating_el["value"] if rating_el else None,
31 "text": text_el.text.strip() if text_el else None,
32 "reviewer": user_el.text.strip() if user_el else None,
33 "date": date_el.text.strip() if date_el else None,
34 })
35 time.sleep(random.uniform(2, 5))
36 return all_reviewsOpción 2: analizar reseñas desde el HTML (alternativa)
Si el enfoque de API falla (por ejemplo, por problemas con el token CSRF), puedes analizar la primera página de reseñas directamente desde el HTML de la página del producto. La limitación: solo el primer bloque de reseñas está en el HTML estático. Para más, necesitas la API o una herramienta de automatización del navegador como Selenium.
Cómo manejar datos que requieren login: extraer tu propia tienda de Etsy
Esta es una laguna que ninguna otra guía cubre, pero es una necesidad real, especialmente para vendedores de Etsy que quieren extraer sus propios pedidos, ingresos y estadísticas.
El problema: requests por sí solo no puede acceder a tu panel de Etsy porque no lleva las cookies de tu sesión iniciada.
Opción 1: Selenium con login manual y captura de cookies
Usa Selenium para abrir un navegador, iniciar sesión manualmente (o automatizar el login) y seguir extrayendo mientras estás autenticado:
1from selenium import webdriver
2driver = webdriver.Chrome()
3driver.get("https://www.etsy.com/signin")
4# Inicia sesión manualmente en la ventana del navegador y después:
5input("Pulsa Enter después de iniciar sesión...")
6cookies = driver.get_cookies()
7# Ahora usa driver.get() para navegar por las páginas de tu panel y extraer datosTambién puedes guardar las cookies de la sesión de Selenium y reutilizarlas con requests.Session() para una extracción más rápida y ligera después del inicio de sesión inicial.
Opción 2: exportar cookies del navegador para usarlas con Requests
Usa una extensión de navegador (como "EditThisCookie") para exportar las cookies activas de tu sesión de Etsy y luego cárgalas en una sesión de Requests:
1import requests
2session = requests.Session()
3# Añade las cookies exportadas desde tu navegador
4session.cookies.set("uaid", "YOUR_UAID_VALUE", domain=".etsy.com")
5session.cookies.set("user_prefs", "YOUR_USER_PREFS_VALUE", domain=".etsy.com")
6# ... añade otras cookies de sesión según sea necesario
7resp = session.get("https://www.etsy.com/your/orders", headers=headers)El camino fácil: el modo de scraping en navegador de Thunderbit
Como se ejecuta dentro de tu navegador Chrome, hereda automáticamente tu sesión activa de Etsy. Sin código de autenticación, sin exportar cookies: solo navega a tu panel de Etsy y extrae. Esto es realmente útil para obtener pedidos, ingresos, estadísticas y otros datos exclusivos para vendedores sin necesidad de programar.
Exportar y usar tus datos extraídos de Etsy
Guardar en CSV o JSON
1import pandas as pd
2df = pd.DataFrame(results)
3df.to_csv("etsy_products.csv", index=False, encoding="utf-8")
4df.to_json("etsy_products.json", orient="records", indent=2)Buenas prácticas: incluye marcas de tiempo en los nombres de archivo, usa codificación UTF-8 y maneja correctamente los caracteres especiales en los nombres de producto (a los vendedores de Etsy les encantan los emojis y los caracteres con acentos).
Exportar a Google Sheets, Airtable o Notion
Para usuarios de Python, bibliotecas como gspread (Google Sheets) o la API de Airtable permiten enviar datos de forma programática. Pero si usas , todas las exportaciones — a Google Sheets, Excel, Airtable y Notion — son gratis y con un solo clic. Sin claves API, sin configuración OAuth.
Salta el código: cómo extraer datos de Etsy con Thunderbit (alternativa sin código)
No todo el mundo quiere escribir scripts en Python, mantener configuraciones de proxies o depurar selectores CSS a las 2 de la madrugada. Si ese es tu caso, así puedes obtener datos de Etsy con .
Instala la extensión de Chrome de Thunderbit
Ve a la e instala Thunderbit. Crea una cuenta gratuita: el plan gratis te da y todas las exportaciones son gratuitas.
Usa "AI Suggest Fields" en cualquier página de Etsy
Navega a una página de búsqueda, producto o tienda de Etsy. Haz clic en "AI Suggest Fields" en la barra lateral de Thunderbit. La IA analiza la página y recomienda columnas: nombre del producto, precio, valoración, imágenes, nombre de la tienda, etiquetas, información de envío. Ajusta o añade columnas según necesites.
Haz clic en Scrape y exporta
Haz clic en "Scrape" para extraer datos de la página actual. Para resultados de varias páginas, usa el scraping de paginación de Thunderbit. Para enriquecer una lista de URLs de productos con detalles de cada página (descripciones, reseñas, envío), usa scraping de subpáginas: Thunderbit visita cada enlace y extrae automáticamente los datos adicionales.
Exporta a Excel, Google Sheets, Airtable o Notion, todo gratis.
Cuándo Thunderbit supera a Python para extraer Etsy
- No necesitas configurar proxies ni código anti-bot. Thunderbit funciona en tu navegador Chrome real, así que hereda tu sesión y para DataDome parece un usuario normal.
- La IA se adapta automáticamente a los cambios de diseño. No hay selectores rotos que arreglar cuando Etsy actualiza su interfaz.
- Genial para investigaciones puntuales, análisis competitivo o miembros del equipo sin perfil técnico. Si solo necesitas un conjunto de datos rápido, no hace falta un entorno Python.
- El scraping de subpáginas te permite enriquecer una lista de URLs de producto con datos detallados sin escribir bucles anidados.
Para ver el proceso paso a paso, visita el .
Comparación de costes en 6 meses: Python vs. Thunderbit
| Factor | Python por tu cuenta | Thunderbit |
|---|---|---|
| Tiempo de configuración | 8–20 horas | Menos de 5 minutos |
| Coste en 6 meses (incl. trabajo, proxies) | 2.720–9.450 USD | 90–228 USD |
| Mantenimiento mensual | 4–10+ horas (las actualizaciones de selectores suponen más del 80% del sobrecoste) | 0–1 horas |
| Gestión anti-bot | Proxies residenciales con un coste de crédito 85x superior al normal | Basado en navegador, elude DataDome de forma nativa |
| Calidad de datos | Alta (con esfuerzo) | Alta (impulsada por IA) |
No digo que Python sea la opción incorrecta: si necesitas control total, lógica personalizada o integración en una canalización más amplia, el código manda. Pero para la mayoría de usuarios de negocio que solo necesitan datos de Etsy, la ecuación del ROI favorece una herramienta sin código.
Consejos legales y éticos para extraer datos de Etsy
Me preguntan por la legalidad en cada post sobre scraping, así que aquí va la versión corta:
- Los Términos de Uso de Etsy prohíben explícitamente el acceso automatizado. Dicho esto, Etsy se apoya en la aplicación técnica (DataDome) más que en litigios — no se conocen demandas específicas de Etsy dirigidas a scrapers.
- Extrae solo datos disponibles públicamente. No eludas la autenticación ni accedas a paneles privados de vendedores que no te pertenecen.
- Usa tasas de solicitud razonables. Esperas de 2–7 segundos entre solicitudes, y no bombardees los servidores de Etsy.
- Respeta
robots.txt. Etsy permite páginas de búsqueda, pero restringe algunas rutas. - Gestiona los datos personales de forma responsable conforme a leyes de privacidad como el RGPD.
- Consulta a un asesor legal para proyectos de scraping a escala comercial.
Para más contexto, consulta nuestra publicación sobre — incluyendo Meta v. Bright Data (2024), donde se respaldó la extracción de datos públicos.
Cierre: conclusiones clave
Hemos cubierto mucho terreno. Esto es lo que quiero que te lleves:
- Los datos estructurados JSON-LD de Etsy hacen que la extracción sea más limpia que el análisis de HTML bruto para la mayoría de los campos.
- DataDome es un obstáculo real: usa cabeceras correctas, retardos, gestión de cookies y proxies residenciales para extraer con Python a escala.
- La API de Etsy es limitada. Si necesitas reseñas, tiendas de la competencia o análisis entre vendedores, la extracción es la vía práctica.
- Thunderbit ofrece una alternativa sin código que gestiona de forma nativa el anti-bot y la autenticación: vale la pena probarlo si quieres datos de Etsy sin mantener scripts.
- Extrae siempre de forma responsable y respeta los términos de Etsy.
Si quieres empezar sin escribir código, . O usa el código Python de este tutorial para crear tu propio extractor personalizado — y que tus selectores nunca se rompan un viernes por la tarde.
Para más guías de extracción, consulta nuestra y el recopilatorio de .
Preguntas frecuentes
1. ¿Es legal extraer datos de Etsy con Python?
La extracción de datos disponibles públicamente suele ser admisible según precedentes legales recientes (por ejemplo, Meta v. Bright Data, hiQ v. LinkedIn). Sin embargo, los Términos de Uso de Etsy prohíben el acceso automatizado, así que revisa siempre sus ToS y robots.txt antes de extraer. Para uso a gran escala o comercial, consulta a un asesor legal.
2. ¿Puedo extraer datos de Etsy sin que me bloqueen?
Etsy usa DataDome, uno de los sistemas anti-bot más duros que existen. Cabeceras realistas, retardos entre solicitudes, persistencia de cookies y rotación de proxies residenciales ayudan a reducir bloqueos. El enfoque nativo en navegador de Thunderbit evita la mayoría de las detecciones porque opera dentro de tu sesión real de Chrome.
3. ¿Tiene Etsy una API que pueda usar en lugar de extraer el sitio?
Sí, Etsy ofrece una API v3, pero está mayormente limitada a los datos de tu propia tienda y no ofrece un acceso sólido a reseñas. La mayoría de los casos de inteligencia competitiva y análisis entre tiendas requieren extracción.
4. ¿Qué bibliotecas de Python necesito para extraer datos de Etsy?
Como mínimo: requests, beautifulsoup4, pandas (para exportar) y json (incluida en la biblioteca estándar). Para páginas con mucho JS o que requieren login, añade selenium. Para un análisis HTML más rápido, usa lxml.
5. ¿Cómo extraigo específicamente las reseñas de Etsy?
Las reseñas de Etsy se cargan mediante un endpoint interno de API (/api/v3/ajax/bespoke/member/neu/specs/deep_dive_reviews). Tendrás que extraer el listing ID, el shop ID y el token CSRF de la página del producto y luego hacer un POST al endpoint con paginación. Como alternativa, puedes analizar el primer bloque de reseñas desde el HTML de la página del producto; ambas vías se explican paso a paso en este tutorial.
Más información