La mayoría de los tutoriales para scrapear eBay tienen una vida útil de unos tres meses. Lo sé porque en Thunderbit hemos visto a desarrolladores ir pasando de fragmentos de código rotos a selectores CSS obsoletos y repositorios de GitHub que “funcionaban” pero dejaron de hacerlo discretamente hace dos rediseños de eBay.
eBay alberga — el mayor conjunto de datos de precios de larga cola en la web abierta, después de Amazon. Esa información impulsa desde estrategias de precios para revendedores hasta inteligencia competitiva. Pero acceder a ella por programación es un objetivo en movimiento: el frontend de eBay basado en React cambia constantemente los nombres de las clases CSS, los tests A/B muestran estructuras DOM distintas según el usuario y Akamai Bot Manager se interpone entre tú y el HTML. Esta guía te da código en Python que funciona hoy, explica por qué se rompen los scrapers para que puedas construir uno resistente, compara con honestidad la API de eBay frente al scraping y muestra una salida sin código para cuando Python no compense la configuración.
¿Qué significa scrapear eBay con Python?
Scrapear eBay con Python significa escribir scripts que descargan páginas de eBay de forma programática, analizan el HTML (o JSON oculto) y extraen datos estructurados — títulos, precios, información del vendedor, fechas de venta, variantes — para llevarlos a un formato útil, como CSV, una hoja de cálculo o una base de datos.
Puedes scrapear varios tipos de páginas de eBay:
- Resultados de búsqueda (por ejemplo, todos los anuncios de “AirPods Pro”)
- Páginas de detalle de producto (especificaciones completas, imágenes, información del vendedor)
- Anuncios vendidos/completados (precios y fechas reales de transacción)
- Perfiles de vendedor y reseñas
Python es el lenguaje más habitual para este trabajo. Su ecosistema — Requests, BeautifulSoup, lxml, pandas — hace sencillo descargar páginas, analizar HTML y procesar datos. Aun así, existe una diferencia importante entre scrapear el HTML del sitio y usar la API oficial de eBay, y eso lo veremos enseguida.
¿Por qué scrapear eBay? Casos de uso reales para equipos de negocio
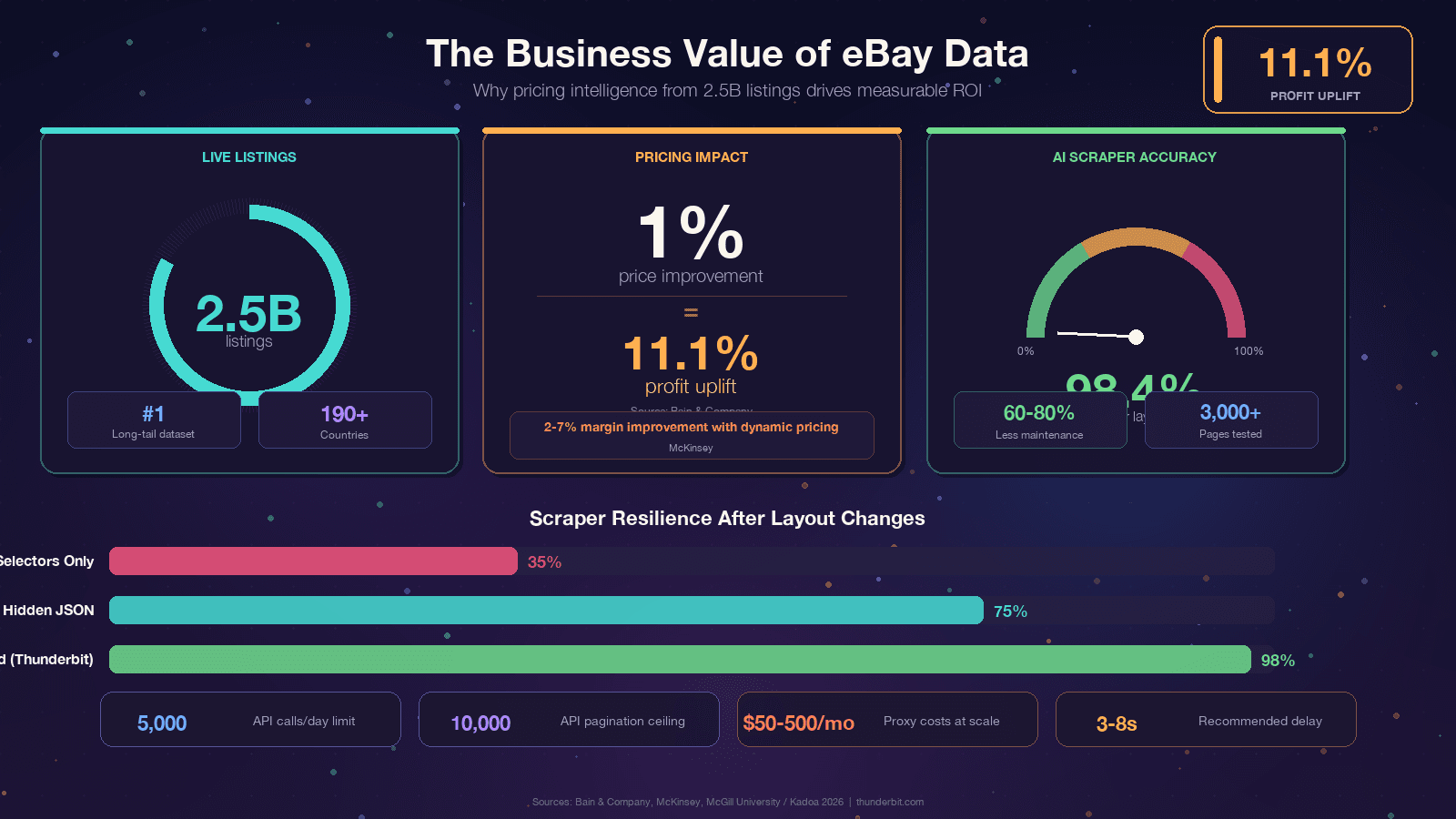
Si estás leyendo esto, probablemente ya tengas un motivo. Aun así, conviene aterrizar el tema en valor de negocio concreto, porque el retorno de los datos de eBay es realmente notable. Bain encontró que una en miles de empresas. McKinsey atribuye a la fijación de precios dinámica en retail.
Los casos de uso que veo con más frecuencia:
| Caso de uso | Datos necesarios | Resultado de negocio |
|---|---|---|
| Monitorización de precios y repricing | Precios de anuncios activos, envío, estado | Precios competitivos, protección del margen |
| Análisis de la competencia | Catálogo de productos, promociones, condiciones de envío | Posicionamiento estratégico, huecos en el surtido |
| Estudio de mercado y detección de tendencias | Ritmo de publicación, tendencias de categoría, patrones de demanda | Identificación de nuevos productos, previsión de demanda |
| Precios para revendedores / tasaciones | Precios de venta, fechas de venta, estado | Valor de mercado justo, decisiones de compra |
| Análisis de sentimiento | Reseñas, valoraciones, política de devoluciones | Información sobre calidad del producto, satisfacción del cliente |
| Generación de leads | Perfiles de vendedor, información de tienda, datos de contacto | Prospección B2B hacia vendedores con alto GMV |
El hilo conductor es claro: eBay tiene los datos, pero están encerrados en páginas web.
El scraping es la forma de convertirlos en ventaja competitiva.
API oficial de eBay vs. scraping web con Python: ¿cuál deberías elegir?
Esta es la pregunta que ojalá más tutoriales respondieran con sinceridad. eBay ofrece APIs oficiales — sobre todo la — y muchos usuarios se preguntan si conviene usarlas o ir directos al scraping. La respuesta depende por completo de los datos que necesites.
| Criterio | API eBay Browse/Finding | Scraping web con Python |
|---|---|---|
| Anuncios vendidos/completados | Limitado — existe Marketplace Insights API, pero el acceso suele ser rechazado | Acceso completo mediante parámetros de URL LH_Sold=1&LH_Complete=1 |
| Límites de uso | 5.000 llamadas/día en el nivel básico | Lo gestionas tú (depende de proxies) |
| Campos disponibles | Predefinidos (título, precio, categoría, datos básicos del vendedor) | Todo lo visible en la página (reseñas, especificaciones completas, matriz de variantes) |
| Complejidad de configuración | OAuth 2.0, registro de app, claves API | pip install + código |
| Estabilidad | Endpoints estables | Se rompe cuando cambia el HTML |
| Coste | Hay plan gratuito; pago por volumen | Código gratis, pero coste de proxies a escala |
| Datos de variantes/MSKU | Parcial — en muchos casos solo SKU padre | Completo (mediante análisis de JSON oculto) |
| Profundidad de paginación | Límite duro de 10.000 elementos | Sin límite en teoría |
Un apunte importante: la antigua Finding API (que tenía findCompletedItems) fue . Si usas ebaysdk-python o cualquier biblioteca que llame al módulo Finding, ahora mismo está rota en producción.
Mi recomendación: usa la Browse API para consultas estables, de volumen moderado y con estructura, sobre anuncios activos. Usa scraping con Python cuando necesites precios de venta, reseñas, datos de variantes o cualquier campo que la API no exponga. Muchos equipos combinan ambas cosas.
Herramientas y librerías que necesitas para scrapear eBay con Python
Antes de escribir código, aquí tienes el kit básico. No necesitas un navegador sin interfaz para la mayoría de las páginas de eBay: los datos ya vienen incrustados en el HTML renderizado en servidor.
| Librería | Uso |
|---|---|
requests o httpx | Cliente HTTP para descargar páginas de eBay |
curl_cffi | Cliente HTTP con fingerprint TLS real de navegador (clave para esquivar Akamai) |
beautifulsoup4 | Analizador HTML para extraer con selectores CSS |
lxml | Backend de análisis rápido para BeautifulSoup |
jmespath | Lenguaje de consulta para analizar JSON anidados |
pandas | Manipulación de datos y exportación a CSV/Excel |
gspread | Integración con Google Sheets |
Instala todo con un solo comando:
1pip install requests httpx curl_cffi beautifulsoup4 lxml jmespath pandas gspreadUsa Python 3.11 o superior: pandas 3.0 requiere 3.10+, y 3.11 te da mejoras de rendimiento del 10–60% en tareas con mucho I/O.
Merece una mención especial una librería: curl_cffi es la mejora más relevante que puede hacer un scraper de eBay en 2026. eBay usa , y el principal vector de detección de Akamai es el fingerprint TLS. requests sin más genera una huella JA3 con aspecto de Python que suele ser bloqueada al instante. curl_cffi imita el handshake TLS de un navegador Chrome real, lo que resuelve aproximadamente el 90% de los objetivos protegidos por Akamai sin necesidad de navegador sin interfaz.
Paso a paso: cómo scrapear resultados de búsqueda de eBay con Python
Este es el tutorial principal. Vamos a scrapear páginas de resultados de búsqueda de eBay para obtener listados de productos.
- Dificultad: Principiante–intermedio
- Tiempo estimado: unos 30 minutos para conseguir el primer scrape funcional
- Lo que necesitas: Python 3.11+, las librerías anteriores, una terminal y una URL de búsqueda objetivo de eBay
Paso 1: prepara tu proyecto en Python
Crea un directorio para el proyecto e instala las dependencias:
1mkdir ebay-scraper && cd ebay-scraper
2python -m venv venv
3source venv/bin/activate # Windows: venv\Scripts\activate
4pip install requests curl_cffi beautifulsoup4 lxml pandasCrea un archivo llamado scrape_ebay.py. Ese será tu espacio de trabajo.
Paso 2: construye la URL de búsqueda de eBay
La estructura de búsqueda de eBay es bastante simple. El parámetro clave es _nkw (keyword):
1import urllib.parse
2keyword = "airpods pro"
3base_url = "https://www.ebay.com/sch/i.html"
4params = {
5 "_nkw": keyword,
6 "_ipg": "120", # elementos por página: 60, 120 o 240 (240 puede activar señales de bot)
7 "_pgn": "1", # número de página
8}
9url = f"{base_url}?{urllib.parse.urlencode(params)}"
10print(url)
11# https://www.ebay.com/sch/i.html?_nkw=airpods+pro&_ipg=120&_pgn=1Otros parámetros útiles:
LH_BIN=1— solo Comprar ahora_sacat=175673— categoría específica_sop=12— ordenar por mejor coincidencia (10 = precio+envío más bajo, 13 = recién publicado)LH_Complete=1&LH_Sold=1— anuncios vendidos/completados (lo cubrimos en una sección específica más abajo)
Paso 3: envía la petición y gestiona la respuesta
Aquí es donde curl_cffi marca la diferencia. Un requests.get() normal suele devolver un 403 por parte de Akamai. Con curl_cffi, imitamos un navegador Chrome real:
1from curl_cffi import requests as cffi_requests
2import random, time
3USER_AGENTS = [
4 "Mozilla/5.0 (Macintosh; Intel Mac OS X 10_15_7) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
5 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/143.0.0.0 Safari/537.36",
6 "Mozilla/5.0 (X11; Linux x86_64; rv:124.0) Gecko/20100101 Firefox/124.0",
7]
8HEADERS = {
9 "User-Agent": random.choice(USER_AGENTS),
10 "Accept-Language": "en-US,en;q=0.9",
11 "Accept-Encoding": "gzip, deflate, br",
12}
13def fetch_page(url, max_retries=5):
14 delay = 2
15 for attempt in range(max_retries):
16 try:
17 r = cffi_requests.get(url, impersonate="chrome124", headers=HEADERS, timeout=30)
18 if r.status_code == 200:
19 return r.text
20 if r.status_code in (403, 429, 503):
21 retry_after = r.headers.get("Retry-After")
22 sleep_for = float(retry_after) if retry_after else delay + random.uniform(0, 1)
23 print(f" Status {r.status_code}, retrying in {sleep_for:.1f}s...")
24 time.sleep(sleep_for)
25 delay *= 2
26 continue
27 r.raise_for_status()
28 except Exception as e:
29 print(f" Request error: {e}, retrying...")
30 time.sleep(delay)
31 delay *= 2
32 raise RuntimeError(f"Failed after {max_retries} retries: {url}")El backoff exponencial con jitter es importante: los intervalos fijos de espera también delatan comportamiento de bot.
Paso 4: analiza los listados de productos de la página de búsqueda
eBay está actualmente en plena migración entre dos diseños de resultados de búsqueda. Un scraper resistente debe manejar ambos:
| Campo | Diseño anterior | Diseño nuevo |
|---|---|---|
| Contenedor de tarjeta | li.s-item | li.s-card o div.su-card-container |
| Título | .s-item__title | .s-card__title |
| URL | a.s-item__link[href] | a.su-link[href] |
| Precio | span.s-item__price | .s-card__price |
Código de análisis que soporta ambos diseños:
1from bs4 import BeautifulSoup
2def parse_search_results(html):
3 soup = BeautifulSoup(html, "lxml")
4 cards = soup.select("li.s-item, li.s-card, div.su-card-container")
5 results = []
6 for card in cards:
7 # Título — probamos ambos diseños
8 title_el = card.select_one(".s-item__title, .s-card__title")
9 title = title_el.get_text(strip=True) if title_el else None
10 # Omitimos la tarjeta fantasma "Shop on eBay"
11 if not title or "Shop on eBay" in title:
12 continue
13 # Precio
14 price_el = card.select_one("span.s-item__price, .s-card__price")
15 price = price_el.get_text(strip=True) if price_el else None
16 # URL
17 link_el = card.select_one("a.s-item__link[href], a.su-link[href]")
18 url = link_el["href"].split("?")[0] if link_el else None
19 # Imagen
20 img_el = card.select_one("img.s-item__image-img, .s-card__image img")
21 image = None
22 if img_el:
23 image = img_el.get("src") or img_el.get("data-src")
24 # Envío
25 ship_el = card.select_one("span.s-item__shipping, span.s-item__logisticsCost, .s-card__attribute-row")
26 shipping = ship_el.get_text(strip=True) if ship_el else None
27 results.append({
28 "title": title,
29 "price": price,
30 "url": url,
31 "image": image,
32 "shipping": shipping,
33 })
34 return resultsLa trampa de la primera tarjeta fantasma es un clásico. Muchos resultados de búsqueda de eBay muestran primero un li.s-item oculto con el título "Shop on eBay" y sin precio real. Filtralo siempre.
Paso 5: maneja la paginación para scrapear varias páginas
eBay pagina mediante el parámetro _pgn. El enlace a la siguiente página usa a.pagination__next:
1import urllib.parse
2def scrape_ebay_search(keyword, max_pages=5):
3 all_results = []
4 for page_num in range(1, max_pages + 1):
5 params = {"_nkw": keyword, "_ipg": "120", "_pgn": str(page_num)}
6 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
7 print(f"Scraping page {page_num}: {url}")
8 html = fetch_page(url)
9 results = parse_search_results(html)
10 if not results:
11 print(f" No hay resultados en la página {page_num}, deteniendo.")
12 break
13 all_results.extend(results)
14 print(f" Encontrados {len(results)} anuncios (total: {len(all_results)})")
15 # Pausa prudente — de 3 a 8 segundos con jitter
16 time.sleep(random.uniform(3, 8))
17 return all_resultsEl jitter aleatorio de 3 a 8 segundos no es opcional.
eBay y Akamai detectan peticiones sostenidas por encima de 1 req/s desde una sola IP.
Paso 6: exporta tus datos a CSV o JSON
1import pandas as pd
2results = scrape_ebay_search("airpods pro", max_pages=3)
3df = pd.DataFrame(results)
4df.to_csv("ebay_airpods.csv", index=False)
5df.to_json("ebay_airpods.json", orient="records", indent=2)
6print(f"Exported {len(df)} listings to CSV and JSON.")Ya deberías tener una hoja de cálculo limpia con anuncios de eBay. En mi equipo, scrapear 3 páginas (360 anuncios) tardó unos 45 segundos incluyendo las pausas.
Cómo scrapear páginas de detalle de producto de eBay con Python
Los resultados de búsqueda te dan un resumen. Las páginas de detalle del producto traen lo interesante: descripciones completas, puntuación del vendedor, especificaciones del artículo, carruseles de imágenes y datos de variantes.
Analizar una página de anuncio individual
Las páginas de artículos de eBay viven en /itm/<ITEM_ID>. La vía de extracción más estable es JSON-LD: eBay incrusta un bloque de esquema Product que sobrevive a casi todos los cambios de CSS:
1import json
2def parse_item_page(html):
3 soup = BeautifulSoup(html, "lxml")
4 item = {}
5 # 1. JSON-LD — la vía de extracción más estable
6 for tag in soup.find_all("script", type="application/ld+json"):
7 try:
8 data = json.loads(tag.string or "")
9 except (json.JSONDecodeError, TypeError):
10 continue
11 if isinstance(data, dict) and data.get("@type") == "Product":
12 item["title"] = data.get("name")
13 item["brand"] = (data.get("brand") or {}).get("name")
14 item["images"] = data.get("image")
15 offers = data.get("offers") or {}
16 item["price"] = offers.get("price")
17 item["currency"] = offers.get("priceCurrency")
18 break
19 # 2. Fallbacks CSS para campos que no estén en JSON-LD
20 def first_text(selectors):
21 for sel in selectors:
22 el = soup.select_one(sel)
23 if el and el.get_text(strip=True):
24 return el.get_text(strip=True)
25 return None
26 item.setdefault("title", first_text([
27 "h1.x-item-title__mainTitle",
28 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
29 ]))
30 item["condition"] = first_text([
31 ".x-item-condition-text .ux-textspans",
32 ])
33 item["seller"] = first_text([
34 ".x-sellercard-atf__info__about-seller a .ux-textspans",
35 ])
36 item["shipping"] = first_text([
37 "div.ux-labels-values--shipping .ux-textspans--BOLD",
38 ])
39 # 3. Especificaciones del artículo
40 specifics = {}
41 for dl in soup.select(".ux-layout-section-evo__item--table-view dl.ux-labels-values"):
42 k = dl.select_one(".ux-labels-values__labels-content .ux-textspans")
43 v = dl.select_one(".ux-labels-values__values-content .ux-textspans")
44 if k and v:
45 specifics[k.get_text(strip=True).rstrip(":")] = v.get_text(strip=True)
46 item["specifics"] = specifics
47 return itemEse patrón — primero JSON-LD, luego fallback CSS — es la clave para construir scrapers que no se rompan cada trimestre. Más abajo profundizo en ello.
Scrapear variantes de producto de eBay (datos MSKU)
Algunos anuncios de eBay tienen varias variantes: colores, tallas, capacidades de almacenamiento distintas. El DOM visible solo muestra un rango de precio tipo "$899 a $1,099" hasta que el usuario elige una opción. El precio real por variante vive en un objeto JavaScript oculto llamado MSKU.
Este es uno de esos casos en los que la API de eBay solo ofrece datos parciales (SKU padre), así que scrapear resulta mejor.
1import re, json
2def extract_variants(html):
3 # El patrón no codicioso es crítico — .+ codicioso se traga toda la página
4 m = re.search(r'"MSKU"\s*:\s*(\{.+?\})\s*,\s*"QUANTITY"', html, re.DOTALL)
5 if not m:
6 return []
7 try:
8 msku = json.loads(m.group(1))
9 except json.JSONDecodeError:
10 return []
11 item_labels = {str(k): v["displayLabel"] for k, v in msku.get("menuItemMap", {}).items()}
12 skus = []
13 for combo_key, variation_id in msku.get("variationCombinations", {}).items():
14 option_ids = combo_key.split("_")
15 options = [item_labels.get(oid, oid) for oid in option_ids]
16 var = msku.get("variationsMap", {}).get(str(variation_id), {})
17 bin_model = var.get("binModel", {})
18 price_spans = bin_model.get("price", {}).get("textSpans", [{}])
19 price = price_spans[0].get("text") if price_spans else None
20 qty = var.get("quantity")
21 skus.append({
22 "options": options,
23 "price": price,
24 "quantity_available": qty,
25 "variation_id": variation_id,
26 })
27 return skusEse (.+?) no codicioso en la expresión regular es donde tropieza la mayoría de los scrapers de eBay. .+ codicioso se traga todo hasta el último "QUANTITY" de la página y produce JSON mal formado. He visto ese fallo en al menos tres tutoriales que decían “funcionar”.
Cómo scrapear anuncios vendidos y completados de eBay con Python
Este es el caso que justifica usar scraping en lugar de la API. Los datos de artículos vendidos — qué se vendió realmente, a qué precio y en qué fecha — son el estándar de oro para estudios de mercado, precios para revendedores y tasaciones. La Browse API de eBay no lo ofrece explícitamente. La técnicamente sí, pero el acceso es una “Limited Release” que .
Los parámetros de URL que necesitas son LH_Complete=1 (anuncios completados) y LH_Sold=1 (filtrar solo los vendidos). Tienes que incluir ambos. Si pasas solo LH_Sold=1, en algunas categorías eBay vuelve silenciosamente a anuncios activos; ese es el error más común de la comunidad.
1def scrape_sold_listings(keyword, max_pages=3):
2 all_sold = []
3 for page_num in range(1, max_pages + 1):
4 params = {
5 "_nkw": keyword,
6 "_ipg": "120",
7 "_pgn": str(page_num),
8 "LH_Complete": "1",
9 "LH_Sold": "1",
10 }
11 url = f"https://www.ebay.com/sch/i.html?{urllib.parse.urlencode(params)}"
12 print(f"Scraping sold page {page_num}...")
13 html = fetch_page(url)
14 soup = BeautifulSoup(html, "lxml")
15 cards = soup.select("li.s-item")
16 for card in cards:
17 title_el = card.select_one(".s-item__title")
18 title = title_el.get_text(strip=True) if title_el else None
19 if not title or "Shop on eBay" in title:
20 continue
21 # Solo incluir artículos realmente vendidos (precio verde POSITIVE)
22 sold_tag = card.select_one(
23 ".s-item__title--tag .POSITIVE, .s-item__caption--signal.POSITIVE"
24 )
25 if sold_tag is None:
26 continue # Anuncio completado pero no vendido — saltar
27 price_el = card.select_one("span.s-item__price")
28 price = price_el.get_text(strip=True) if price_el else None
29 # Analizar fecha de venta
30 sold_date = None
31 import re, datetime as dt
32 card_text = card.get_text()
33 m = re.search(r"Sold\s+([A-Z][a-z]{2}\s+\d{1,2},\s*\d{4})", card_text)
34 if m:
35 sold_date = dt.datetime.strptime(m.group(1), "%b %d, %Y").strftime("%Y-%m-%d")
36 link_el = card.select_one("a.s-item__link[href]")
37 url = link_el["href"].split("?")[0] if link_el else None
38 all_sold.append({
39 "title": title,
40 "sold_price": price,
41 "sold_date": sold_date,
42 "url": url,
43 })
44 if not cards:
45 break
46 time.sleep(random.uniform(3, 8))
47 return all_soldLa diferencia clave en el HTML: los artículos vendidos muestran el precio en verde (dentro de un contenedor .POSITIVE), mientras que los anuncios completados pero no vendidos muestran el precio en rojo tachado. Filtra siempre por esa clase .POSITIVE.
Por qué se rompen los scrapers de eBay (y cómo construir uno resistente)
Si tu scraper de eBay dejó de funcionar, no estás solo. Este es el principal problema en cualquier hilo de foros sobre scraping de eBay que haya leído. La pregunta no es si se romperá tu scraper, sino cuándo.
Por qué ocurre:
- eBay usa renderizado con React y nombres de clase generados dinámicamente que cambian con cada despliegue
- Los tests A/B muestran estructuras DOM distintas a distintos usuarios (el doble diseño
s-item/s-cardes un ejemplo real ahora mismo) - Los rediseños periódicos del sitio cambian la anidación HTML aunque los datos sigan siendo los mismos
- Selectores antiguos como
#itemTitley#prcIsumse eliminaron hace años, pero siguen apareciendo en tutoriales
Como dice la : “El verdadero reto del scraping web de eBay es lidiar con los cambios de selectores CSS. eBay actualiza su frontend con regularidad, rompiendo scrapers que dependen de nombres de clase concretos.”
Estrategias defensivas para scrapers de eBay duraderos
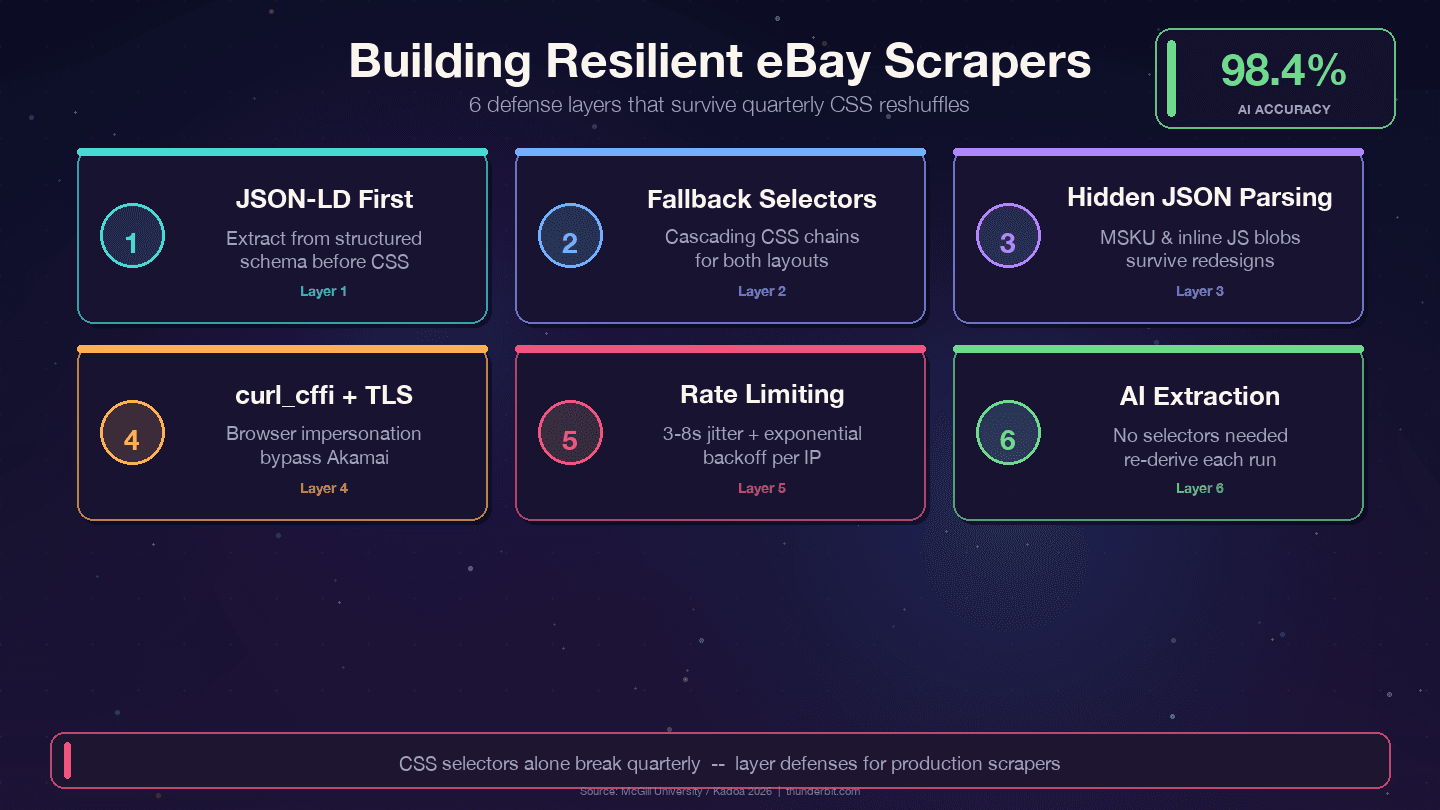
Cuatro estrategias que sobreviven a los cambios trimestrales de eBay:
1. Prioriza JSON-LD sobre selectores CSS. eBay incrusta datos estructurados de esquema Product en cada página de artículo. La capa de datos cambia mucho menos que la de presentación: los diseñadores refactorizan clases CSS cada trimestre, pero campos de backend como price, name y seller se mapean a APIs internas y rara vez cambian de nombre.
2. Usa selectores de reserva en cascada. Nunca dependas de un solo selector CSS. Siempre ofrece alternativas:
1def first_text(soup, selectors):
2 for sel in selectors:
3 el = soup.select_one(sel)
4 if el and el.get_text(strip=True):
5 return el.get_text(strip=True)
6 return None
7title = first_text(soup, [
8 "h1.x-item-title__mainTitle",
9 "h1.x-item-title__mainTitle .ux-textspans--BOLD",
10 "[data-testid='x-item-title'] h1",
11])3. Analiza blobs JSON ocultos. El objeto de variantes MSKU y los datos JavaScript en línea sobreviven a los cambios de CSS porque se generan del lado del servidor. Extraerlos con regex desde <script> requiere más trabajo al principio, pero reduce muchísimo el mantenimiento.
4. Registra los fallos de selectores. Añade monitorización para saber cuándo deja de coincidir un selector, no solo que los datos están vacíos:
1if title is None:
2 print(f"WARNING: title selector failed for {url}")5. Usa curl_cffi con suplantación de navegador. Así manejas el fingerprint TLS de Akamai sin necesidad de un navegador sin interfaz.
La alternativa con IA: sin mantenimiento de selectores
Si estás cansado de parchear selectores cada pocos meses, existe un enfoque radicalmente distinto. Herramientas como usan IA para leer la página de nuevo en cada ejecución y derivar la lógica de extracción sobre la marcha. Un estudio de la Universidad McGill comparó scrapers basados en IA con scrapers basados en selectores en 3.000 páginas y encontró que , con referencias del sector que citan una .
| Enfoque | Se rompe cuando eBay cambia el HTML? | Esfuerzo de mantenimiento |
|---|---|---|
| Selectores CSS hardcodeados | Sí, cada trimestre | Alto — parches continuos |
| Extracción de JSON oculto / JSON-LD | Rara vez | Bajo |
| Scraping basado en IA (Thunderbit) | No — la IA redescubre los selectores en cada ejecución | Ninguno |
Más adelante explicaré en detalle el flujo con Thunderbit. Por ahora, la idea clave es esta: si vas a construir un scraper que planeas ejecutar durante meses, apuesta por extracción JSON primero y selectores de reserva después. Si no quieres mantener selectores en absoluto, la opción con IA merece la pena.
Automatizar scrapes recurrentes de eBay para monitorizar precios
Un scrape puntual es útil. Pero la monitorización de precios, el control de stock y el análisis de la competencia requieren recopilación de datos recurrente. Todos los artículos sobre competencia que he leído mencionan la monitorización de precios como caso de uso, pero casi ninguno explica cómo automatizarlo de verdad.
Opción 1: Cron jobs (Linux/macOS) o Programador de tareas (Windows)
La forma más sencilla. Envuélvelo en un cron job. Usa siempre la ruta absoluta al Python de tu entorno virtual: cron se ejecuta con un entorno mínimo:
1crontab -e
2# Diario a las 08:15
315 8 * * * /Users/me/ebay/venv/bin/python /Users/me/ebay/scrape_ebay.py >> /Users/me/ebay/scrape.log 2>&1En Windows, usa PowerShell:
1$A = New-ScheduledTaskAction -Execute "C:\Users\me\ebay\venv\Scripts\python.exe" -Argument "C:\Users\me\ebay\scrape_ebay.py"
2$T = New-ScheduledTaskTrigger -Daily -At 8:15am
3Register-ScheduledTask -TaskName "eBayScraper" -Action $A -Trigger $TEsto requiere una máquina siempre encendida, y tú gestionas proxies y medidas anti-bot.
Opción 2: funciones en la nube (serverless)
AWS Lambda o Google Cloud Functions te permiten ejecutar scrapers sin un servidor dedicado. La configuración es más compleja: tienes que empaquetar dependencias, gestionar timeouts (Lambda limita a 15 minutos) y seguir controlando proxies. Pero no hay mantenimiento de servidor.
Opción 3: programación sin código con Thunderbit
La función de Thunderbit te deja describir el intervalo en lenguaje natural (por ejemplo, “cada día a las 8am”), introducir URLs de eBay y hacer clic en Programar. Se ejecuta en la nube con gestión anti-bot integrada.
| Enfoque | Esfuerzo de configuración | Necesita servidor? | Gestiona anti-bot? |
|---|---|---|---|
| Cron + script de Python | Medio | Sí (máquina siempre activa) | Tú gestionas los proxies |
| Función en la nube (Lambda) | Alto | No (serverless) | Tú gestionas los proxies |
| Thunderbit Scheduled Scraper | Bajo (descripción en palabras) | No (basado en la nube) | Integrado |
Para guardar datos de scrapes recurrentes, una base de datos SQLite local es la mejor opción para el historial de precios. Usa ON CONFLICT ... DO UPDATE (no INSERT OR REPLACE, que ):
1CREATE TABLE IF NOT EXISTS listings (
2 item_id TEXT PRIMARY KEY,
3 title TEXT NOT NULL,
4 price REAL,
5 last_price REAL,
6 first_seen_at TEXT DEFAULT (datetime('now')),
7 last_seen_at TEXT DEFAULT (datetime('now'))
8);
9CREATE TABLE IF NOT EXISTS price_history (
10 item_id TEXT NOT NULL,
11 observed_at TEXT NOT NULL DEFAULT (datetime('now')),
12 price REAL NOT NULL,
13 PRIMARY KEY (item_id, observed_at)
14);¿No quieres programar? Cómo scrapear eBay en 2 minutos con Thunderbit
Ya he dedicado más de 2.000 palabras a código en Python. Ahora quiero ser honesto sobre cuándo no hace falta.
Si eres un usuario de negocio que hace un estudio de mercado puntual, un revendedor revisando comparables o un equipo de ecommerce que necesita datos hoy sin esperar a un sprint de desarrollo, Python es excesivo. La configuración, el mantenimiento de selectores, la gestión de proxies… es demasiado para “solo necesito estos 200 anuncios en una hoja de cálculo”.
Cómo scrapear eBay con Thunderbit, paso a paso
- Instala la — no necesitas tarjeta de crédito.
- Abre en Chrome cualquier página de resultados o de producto de eBay.
- Haz clic en “AI Suggest Fields” en la barra lateral de Thunderbit. La IA lee la página y propone columnas: Título, Precio, Estado, Envío, Vendedor, Valoración.
- Haz clic en “Scrape”. La extensión recorre la paginación y rellena la tabla de datos. En eBay, Thunderbit tiene que funcionan con un solo clic.
- Exporta a Google Sheets, Airtable, Notion, CSV, JSON o Excel — gratis.
Todo el proceso tarda menos de 2 minutos.
Lo cronometré.
Enriquecimiento de subpáginas: obtén datos de detalle sin código extra
Después de scrapear una página de resultados, Thunderbit puede visitar la página de detalle de cada anuncio y añadir campos extra — especificaciones completas, información del vendedor, descripción, todas las imágenes. Eso sustituye las 20+ líneas de código Python para scrapear subpáginas que escribimos antes por un solo clic.
Cuándo seguir usando Python
Python gana cuando necesitas:
- Scraping a gran escala (decenas de miles de páginas por ejecución)
- Lógica de análisis o transformación muy personalizada
- Integración en pipelines de datos existentes (Airflow, dbt, Kafka)
- Control fino de TLS/sesión para trabajos avanzados anti-bot
- Economía unitaria — a millones de filas, una pila mantenida supera a un SaaS basado en créditos
Para la mayoría de proyectos puntuales o de escala media, Thunderbit es más rápido y fácil. Para pipelines de producción a gran escala, Python te da control total.
Consejos para evitar bloqueos al scrapear eBay con Python
eBay y Akamai van en serio. Esto es lo que realmente funciona en la práctica:
- Usa
curl_cfficonimpersonate="chrome124"— es la mejora individual más grande frente arequestspuro - Rota los User-Agent con una lista de versiones actuales de navegador (Chrome 143, Firefox 124, Safari 26)
- Añade pausas aleatorias de — los intervalos fijos dejan huella
- Usa proxies residenciales o rotativos para cualquier cosa que supere unas pocas decenas de páginas. Las IP de centros de datos (AWS, GCP, DigitalOcean) se detectan rápido con Akamai.
- Respeta
robots.txt— muchas URLs de navegación filtrada están explícitamente marcadas como Disallowed; las páginas de detalle (/itm/<id>) no lo están - Gestiona los CAPTCHAs con elegancia — detecta su aparición y reintenta con otra IP, o usa un servicio de resolución de CAPTCHA
- No machaques el servidor. El precedente indica que la invasión por uso indebido puede aplicarse cuando el scraping degrada realmente los servidores. Mantenerte en 1 req/s por IP te deja muy lejos de ese umbral.
Para uso comercial de alto volumen, conviene combinar la Browse API para anuncios activos con scraping selectivo solo para comparables vendidos y datos que la API no expone. Ese enfoque híbrido es más limpio tanto técnica como jurídicamente.
¿Es legal scrapear eBay con Python?
No soy abogado, y este artículo no es asesoramiento legal. Así que seré breve.
El panorama legal ha evolucionado a favor del scraping de datos públicos. Los precedentes clave:
- (9th Cir., 2022): scrapear datos públicamente accesibles no viola la CFAA
- Van Buren v. United States (SCOTUS, 2021): restringió la cláusula de la CFAA sobre “excede el acceso autorizado”
- (N.D. Cal., 2024): el scraping sin iniciar sesión no incumple los TOS de la plataforma porque el scraper no es un “usuario”
Dicho esto, la prohíbe explícitamente “agentes buy-for-me, bots impulsados por LLM o cualquier flujo de extremo a extremo que intente realizar pedidos sin revisión humana”. El límite está claro: el scraping de solo lectura de páginas públicas es una base sólida; automatizar el checkout no lo es.
Buenas prácticas: extrae solo datos visibles públicamente. No crees cuentas falsas ni saltes muros de inicio de sesión. No revendas en bloque imágenes protegidas por copyright de los anuncios. Y consulta a un abogado en proyectos a escala comercial.
Conclusión y puntos clave
Python es la forma más flexible de scrapear eBay, pero exige mantenimiento continuo conforme cambia el HTML del sitio. El marco de decisión es este:
- Usa la Browse API de eBay para consultas estables, de volumen moderado y estructuradas sobre anuncios activos
- Usa scraping con Python para anuncios vendidos, reseñas, datos de variantes y cualquier campo que la API no exponga
- Usa si quieres datos de eBay sin escribir ni mantener código
El código de esta guía prioriza la resistencia: primero extracción JSON-LD, después selectores CSS en cascada, y por último análisis de JSON oculto para variantes. Ese enfoque por capas hace que tu scraper no muera la próxima vez que el equipo de frontend de eBay publique un rediseño.
Si quieres probar la ruta sin código, el te permite probarlo ahora mismo en páginas de eBay. Y si quieres ver cómo funciona la , la tienes a un clic.
Para más información sobre herramientas de scraping web, consulta nuestras guías sobre , y . También puedes ver tutoriales en el .
Preguntas frecuentes
1. ¿Puedo scrapear eBay gratis con Python?
Sí. Todas las librerías (Requests, BeautifulSoup, curl_cffi, pandas) son gratuitas y de código abierto. Los costes aparecen a escala: los proxies residenciales para scraping de alto volumen suelen costar entre 50 y 500 USD al mes, según el ancho de banda. Para proyectos pequeños (unos pocos cientos de páginas), puedes scrapear desde tu IP doméstica con una limitación de ritmo cuidadosa.
2. ¿Cómo saco anuncios vendidos y completados de eBay con Python?
Añade LH_Complete=1&LH_Sold=1 a los parámetros de búsqueda de la URL. Debes pasar ambos: LH_Sold=1 por sí solo vuelve silenciosamente a anuncios activos en algunas categorías. Filtra los resultados comprobando la clase CSS .POSITIVE en el elemento del precio, que indica una venta real y no un anuncio completado sin vender.
3. ¿eBay bloquea el web scraping?
eBay usa Akamai Bot Manager, que detecta scrapers principalmente mediante fingerprint TLS y análisis de comportamiento. Las llamadas simples con requests suelen devolver 403. Usar curl_cffi con suplantación de navegador, rotación de User-Agent y pausas aleatorias de 3 a 8 segundos entre peticiones resuelve la mayoría de bloqueos. Los proxies residenciales ayudan a escala.
4. ¿Debería usar la API de eBay o scraping web?
Usa la Browse API para consultas estables y de volumen moderado sobre anuncios activos (hasta 5.000 llamadas/día). Usa scraping cuando necesites historial de precios de venta, datos completos de variantes/MSKU, reseñas o cualquier campo que la API no muestre. Marketplace Insights API, en teoría, ofrece datos de vendidos, pero el acceso está restringido y .
5. ¿Cuál es la forma más fácil de scrapear eBay sin programar?
La usa IA para leer páginas de eBay, sugerir columnas de datos y extraer anuncios con un solo clic. Gestiona la paginación, el enriquecimiento de subpáginas y la exportación a Google Sheets, Excel, Airtable o Notion. Las ya preparadas lo hacen todavía más rápido para casos de uso comunes.
Más información