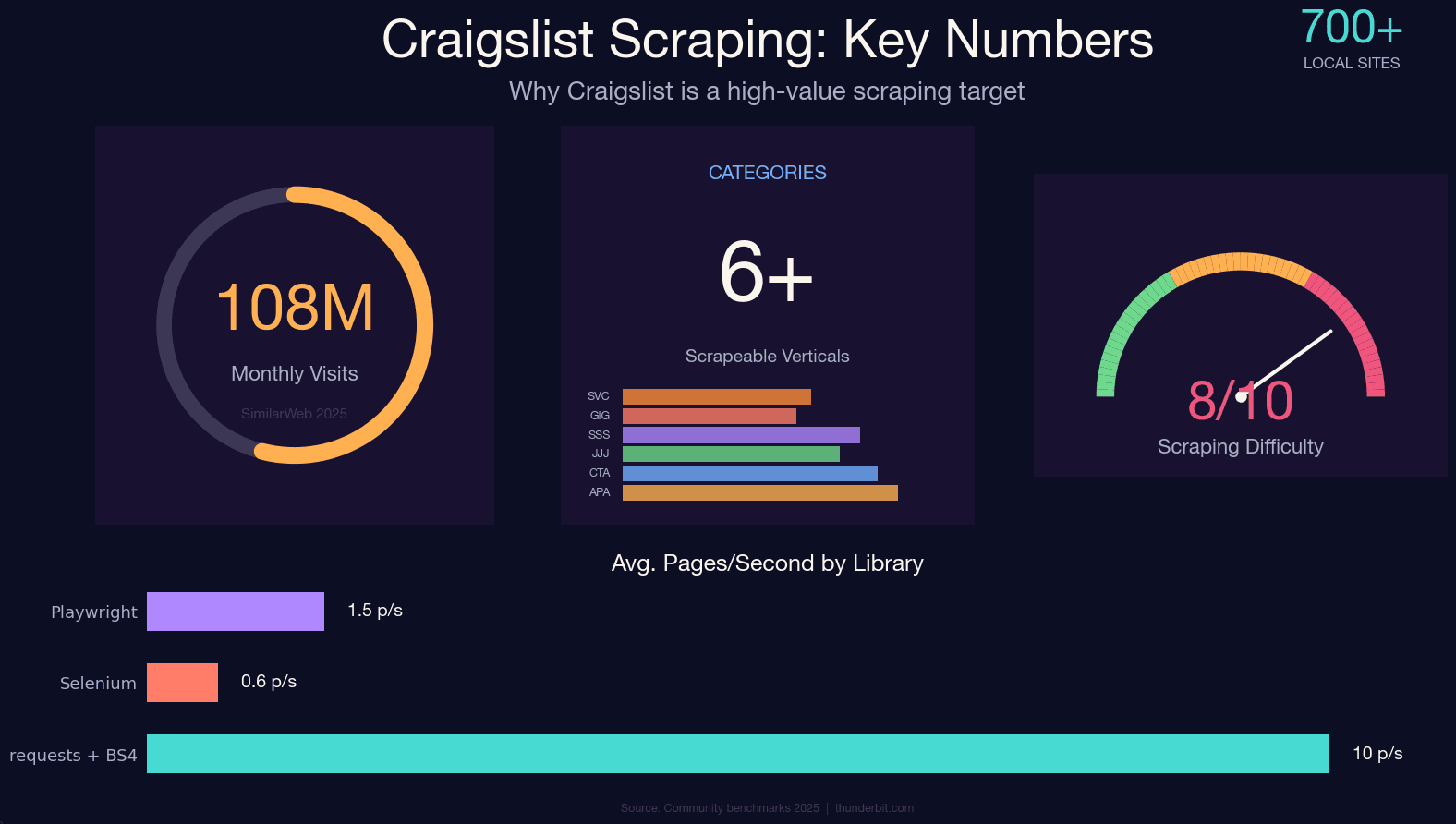
Craigslist sigue atrayendo alrededor de en unos 700 sitios locales, y todavía no tiene API pública. Si quieres datos estructurados de anuncios de departamentos, autos usados, ofertas de trabajo o gigs, hacer scraping es prácticamente la única opción.
Eso sí: el sistema anti-bots personalizado de Craigslist es durísimo. No usa Cloudflare ni DataDome; funciona con su propio limitador de frecuencia basado en nginx, perfeccionado durante más de una década. Si lo activas mal, te puede devolver un 403 rotundo antes de tu segundo café. He pasado mucho tiempo probando distintos enfoques contra sus defensas, y esta guía es el resultado: un tutorial en Python actualizado a 2025, válido para cualquier categoría, que cubre el método de extracción JSON-LD (la mejora más importante frente a las guías antiguas), estrategias reales para evitar bloqueos, el panorama legal y una alternativa sin código para quien solo quiere los datos sin escribir una sola línea.
¿Qué significa hacer scraping de Craigslist con Python?
Hacer web scraping de Craigslist con Python consiste en usar scripts para visitar páginas de Craigslist de forma programática, extraer la información estructurada que te interesa — títulos, precios, descripciones, imágenes, ubicaciones, fechas de publicación — y guardarla en una hoja de cálculo, base de datos o archivo JSON.
Python es el lenguaje preferido para esto por su ecosistema de librerías. Entre requests, BeautifulSoup, lxml y curl_cffi, puedes montar un scraper funcional de Craigslist en menos de 100 líneas. Además, la comunidad es enorme; así que cuando Craigslist cambia algo (y lo hace), casi siempre ya hay alguien que encontró la solución.
Lo importante aquí es esto: Craigslist . La única interfaz programática oficial es la Bulk Posting Interface (BAPI), que es de solo escritura: permite a publicadores de pago aprobados enviar anuncios, no recuperarlos. Cualquier producto tipo "Craigslist API" que veas en plataformas de terceros es un scraper no oficial, no un endpoint autorizado. Si quieres datos masivos, toca hacer scraping.
¿Por qué scrapear Craigslist? Casos reales de uso
Craigslist no es solo un sitio para buscar un sofá usado. Es un conjunto de datos enorme y en constante actualización en decenas de verticales. Estas son algunas de las personas que realmente se benefician de extraerlo:
| Caso de uso | Quién se beneficia | Qué se extrae |
|---|---|---|
| Seguimiento de precios de alquileres y departamentos | Agentes inmobiliarios, inquilinos, empresas PropTech | Precio, m², dormitorios, barrio, latitud/longitud |
| Análisis del mercado de autos usados | Concesionarios, apps de consumo, investigadores | Precio, marca, modelo, año, kilometraje, estado |
| Investigación del mercado laboral | Reclutadores, economistas laborales, analistas de workforce | Título, compensación, tipo de empleo, fecha de publicación |
| Generación de leads | Equipos de ventas, proveedores de servicios | Información de contacto, nombres de empresas, zona de servicio |
| Precios competitivos | Proveedores locales, operaciones de ecommerce | Tarifas de servicio, descripciones, zonas atendidas |
El ejemplo académico más citado es el : unas 500.000 publicaciones de autos usados en EE. UU. con 26 variables, que ha servido de base para decenas de trabajos, incluido un estudio de 2024 en ResearchGate sobre la dinámica del mercado de autos usados en EE. UU. También hay fondos de cobertura que compraron datos agregados de alquileres de Craigslist para estudiar tendencias de renta. Y los equipos de ventas suelen scrapear las categorías de servicios y gigs para generar leads.
La cuenta es simple: 8 horas de copiar y pegar manualmente frente a unos 10 minutos con un scraper bien construido.
Scrapea Craigslist con Python: todas las categorías, no solo autos
Casi todas las guías que he encontrado sobre scraping de Craigslist solo cubren autos en venta, que es como hacer un tutorial de Google y limitarlo a la búsqueda de imágenes. Craigslist tiene decenas de categorías, y los patrones de URL cambian según cada una.
La estructura siempre es esta: https://{city}.craigslist.org/search/{category_slug}
Cambia el subdominio de la ciudad y el slug, y estarás extrayendo un vertical totalmente distinto. Aquí tienes una tabla de referencia con las categorías más populares (verificado en abril de 2025):
| Categoría | Slug de URL | Campos típicos a extraer |
|---|---|---|
| Departamentos / Vivienda | /search/apa | Precio, m², dormitorios, ubicación, política de mascotas |
| Autos y camiones | /search/cta | Precio, marca, modelo, año, kilometraje |
| Empleos | /search/jjj | Título, empresa, salario, tipo de empleo |
| Servicios | /search/bbb | Título, descripción, número de teléfono, zona |
| Gigs | /search/ggg | Título, compensación, fecha, categoría |
| En venta (general) | /search/sss | Título, precio, estado, ubicación |
También puedes combinar parámetros de búsqueda para filtrar:
| Parámetro | Para qué sirve | Ejemplo |
|---|---|---|
query | Palabra clave de texto completo | ?query=studio |
min_price / max_price | Rango de precio | &min_price=1500&max_price=3000 |
hasPic | Solo publicaciones con imágenes | &hasPic=1 |
postedToday | Últimas 24 horas | &postedToday=1 |
sort | Ordenamiento | &sort=priceasc |
s | Desplazamiento de paginación (120 por página) | ?s=120 |
Así, una URL como https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1 te da departamentos en Nueva York entre $1.500 y $3.000 con fotos. Todos los scrapers de Python de esta guía funcionan en estas categorías; solo cambia el slug.
Selectores HTML de Craigslist en 2025: antes vs. ahora (y el atajo JSON)
La principal razón por la que se rompen los scrapers de Craigslist son los cambios en la estructura HTML. Si sigues un tutorial de 2022 que te dice que apuntes a .result-row o .result-info, tu scraper ya está muerto.
Craigslist reescribió el marcado de resultados de búsqueda en 2023–2024. Los nombres de clase antiguos siguen anidados dentro de nuevos contenedores, pero apuntar a ellos en la raíz del DOM devuelve una lista vacía. Esto fue lo que cambió:
| Elemento | Selector antiguo (antes de 2024) | Selector actual (2025) |
|---|---|---|
| Contenedor del anuncio | .result-info | .cl-search-result |
| Enlace del título | .result-title | .posting-title a |
| Precio | .result-price | .priceinfo |
| Metadatos (zona) | .result-hood | .meta |
Pero aquí está la verdadera clave — la que separa un scraper actualizado a 2025 de todo lo demás: no necesitas parsear HTML para los resultados de búsqueda.
Ahora Craigslist incrusta cada anuncio visible dentro de una etiqueta <script id="ld_searchpage_results"> como datos estructurados JSON-LD. Una sola llamada requests.get() devuelve el ItemList de schema.org completo con todos los anuncios de la página: título, precio, moneda, ubicación, URL de la imagen y enlace a la ficha. No hace falta renderizar JavaScript. No hay fragilidad de selectores CSS.
El enfoque JSON-LD es más rápido, más estable y muchísimo menos propenso a romperse cuando Craigslist cambia la interfaz. Es el método que usan todos los repositorios de GitHub que siguen mantenidos activamente, y es el que usaremos en el tutorial de abajo.
Un matiz: el bloque JSON-LD está — departamentos (apa), en venta (sss), autos (cta), vivienda (hhh). Suele estar ausente o ser escaso en empleos (jjj), gigs (ggg), comunidad (ccc) y servicios (bbb) porque esos anuncios no tienen pricing de schema.org/Offer. En esas categorías, conviene volver al camino HTML con .cl-search-result.
Cómo elegir tu stack en Python: Requests + BS4 vs. Selenium vs. Playwright
Esta es la pregunta que aparece en todos los foros de scraping: "¿Qué librería debería usar?" Para Craigslist en particular, la respuesta es más clara que en la mayoría de los sitios.
| Factor | requests + BeautifulSoup | Selenium | Playwright |
|---|---|---|---|
| Velocidad | 5–15 páginas/seg (limitada por red) | 0,3–1 páginas/seg | 0,5–2 páginas/seg |
| Contenido renderizado con JS | No | Sí | Sí |
| Memoria | ~30–60 MB | ~400–700 MB | ~300–500 MB |
| Complejidad de configuración | Baja | Media | Media |
| Resistencia anti-bots | Baja (requiere headers/proxies) | Media (navegador real) | Media-alta |
| Mejor caso de uso en Craigslist | Resultados de búsqueda (JSON-LD) | Páginas de detalle con contenido dinámico | Scraping asíncrono a gran escala |
| Curva de aprendizaje | Ideal para principiantes | Moderada | Moderada |
Las páginas de Craigslist se renderizan del lado del servidor. El bloque JSON-LD ya viene en el HTML inicial. No hay ningún reto de JavaScript en las rutas de lectura. Todos los que siguen activos usan requests + BeautifulSoup o Scrapy. Ninguno usa Selenium ni Playwright. No es casualidad: automatizar un navegador suma cientos de MB de memoria, multiplica por 10–100 la penalización de velocidad y deja una huella más evidente sin aportar beneficios.
Mi recomendación:
- requests + BS4: empieza aquí. Encaja perfecto con la extracción JSON-LD y cubre el 95% de las necesidades de scraping en Craigslist.
- Selenium: solo si necesitas interactuar con contenido dinámico en páginas concretas de detalle (algo raro en Craigslist).
- Playwright: si vas a escalar a miles de páginas con concurrencia asíncrona; pero, sinceramente, el cuello de botella en Craigslist es el limitador de frecuencia, no el rendimiento de tu librería.
Ya hemos cubierto la comparación y un resumen de las en otros artículos, si quieres el análisis completo.
La alternativa sin código: scrapea Craigslist sin escribir Python
Antes del código, una pequeña pausa: esta sección es para quienes no son desarrolladores. Agentes inmobiliarios, equipos de ventas, responsables de operaciones: si solo quieres los datos y no te interesa programar en Python, hay un camino más rápido.
es un AI web scraper que funciona como extensión de Chrome. Puede scrapear Craigslist en unos 2 clics, sin código. El flujo es este:
- Abre cualquier página de resultados de Craigslist (departamentos, autos, empleos, cualquier categoría).
- Haz clic en "AI Suggest Fields" en la barra lateral de Thunderbit. La IA lee la página y detecta automáticamente columnas como título del anuncio, precio, ubicación y enlace.
- Haz clic en "Scrape" — los datos se extraen en segundos.
- Usa Subpage Scraping para entrar en la ficha de cada anuncio y enriquecer los datos con descripciones completas, teléfonos, imágenes y atributos.
- Exporta directamente a Google Sheets, Excel, Airtable o Notion — completamente gratis.
Para necesidades recurrentes — por ejemplo, seguimiento diario de precios de departamentos o capturas semanales de anuncios de empleo — el Scheduled Scraper de Thunderbit te permite describir el horario en lenguaje natural y se ejecuta solo. Sin cron jobs, sin configurar servidores.
Thunderbit también gestiona las medidas anti-bot mediante su modo Cloud Scraping, así que no tienes que preocuparte por rotación de proxies ni por construir headers a mano. Si quieres probarlo, instala la y compruébalo tú mismo.
Si quieres control total y personalización, sigue leyendo con la guía paso a paso en Python.
Paso a paso: cómo scrapear Craigslist con Python (tutorial completo)
- Dificultad: intermedia
- Tiempo estimado: ~30 minutos (configuración + primera extracción)
- Lo que necesitas: Python 3.8+, navegador Chrome (para inspeccionar páginas), una terminal
Paso 1: prepara tu entorno de Python
Instala las librerías necesarias:
1pip install requests beautifulsoup4 lxmllxml es opcional, pero acelera bastante el parseo con BeautifulSoup. Si más adelante te encuentras con problemas de fingerprint TLS (lo veremos en la sección anti-bloqueo), también puedes instalar curl_cffi:
1pip install curl_cffiTu bloque de importación quedaría así:
1import requests
2from bs4 import BeautifulSoup
3import json
4import csv
5import time
6import randomYa deberías tener un entorno limpio de Python con todas las dependencias instaladas.
Paso 2: construye la URL de Craigslist para cualquier categoría
Genera la URL objetivo de forma dinámica usando ciudad + slug de categoría + filtros opcionales:
1from urllib.parse import urlencode
2BASE = "https://{city}.craigslist.org/search/{slug}"
3def build_url(city, slug, **params):
4 return f"{BASE.format(city=city, slug=slug)}?{urlencode(params)}"
5# Ejemplo: departamentos en Nueva York, $1500-$3000, con fotos
6url = build_url("newyork", "apa", min_price=1500, max_price=3000, hasPic=1)
7print(url)
8# https://newyork.craigslist.org/search/apa?min_price=1500&max_price=3000&hasPic=1Cambia "apa" por "cta" (autos), "jjj" (empleos), "bbb" (servicios) o cualquier slug de la tabla anterior. Cambia "newyork" por "sfbay", "chicago", "losangeles", etc.
Paso 3: descarga la página y extrae el JSON incrustado
Haz una petición GET con headers correctos y luego analiza el bloque JSON-LD:
1HEADERS = {
2 "User-Agent": (
3 "Mozilla/5.0 (Windows NT 10.0; Win64; x64) "
4 "AppleWebKit/537.36 (KHTML, like Gecko) "
5 "Chrome/124.0.0.0 Safari/537.36"
6 ),
7 "Accept": "text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8",
8 "Accept-Language": "en-US,en;q=0.9",
9 "Accept-Encoding": "gzip, deflate, br",
10 "Referer": "https://www.craigslist.org/",
11 "Sec-Fetch-Dest": "document",
12 "Sec-Fetch-Mode": "navigate",
13 "Sec-Fetch-Site": "same-origin",
14 "Upgrade-Insecure-Requests": "1",
15}
16session = requests.Session()
17r = session.get(url, headers=HEADERS, timeout=20)
18r.raise_for_status()
19soup = BeautifulSoup(r.text, "html.parser")
20tag = soup.select_one("script#ld_searchpage_results")
21data = json.loads(tag.text) if tag else {"itemListElement": []}Si tag es None, el bloque JSON-LD no está presente en esa categoría; en ese caso, vuelve al parseo HTML (consulta la tabla de selectores de arriba). Para departamentos, autos y categorías de venta, el bloque JSON-LD suele estar ahí de forma fiable.
Paso 4: transforma los anuncios en registros estructurados
Recorre los elementos JSON y extrae los campos que necesites:
1listings = []
2for entry in data["itemListElement"]:
3 item = entry["item"]
4 offers = item.get("offers", {}) or {}
5 addr = (offers.get("availableAtOrFrom") or {}).get("address", {})
6 listings.append({
7 "name": item.get("name"),
8 "url": offers.get("url"),
9 "price": offers.get("price"),
10 "currency": offers.get("priceCurrency"),
11 "locality": addr.get("addressLocality"),
12 "region": addr.get("addressRegion"),
13 "image": item.get("image"),
14 })
15print(f"Encontrados {len(listings)} anuncios")Deberías ver algo como "Encontrados 120 anuncios" (Craigslist muestra 120 resultados por página). Algunos anuncios pueden tener None en el precio si el anunciante no lo incluyó; gestiona eso con cuidado en la lógica posterior.
Paso 5: scrapea las páginas de detalle para obtener más datos
Los resultados de búsqueda solo muestran un resumen. Para tener descripciones completas, atributos (dormitorios, m², política de mascotas), coordenadas lat/long e imágenes, debes visitar la URL de detalle de cada anuncio.
1def fetch_detail(url, session):
2 r = session.get(url, headers=HEADERS, timeout=20)
3 r.raise_for_status()
4 s = BeautifulSoup(r.text, "html.parser")
5 body = s.select_one("#postingbody")
6 mp = s.select_one("#map")
7 return {
8 "description": body.get_text("\n", strip=True) if body else None,
9 "attributes": [x.get_text(" ", strip=True)
10 for x in s.select("p.attrgroup span, div.attrgroup .attr")],
11 "lat": mp.get("data-latitude") if mp else None,
12 "lng": mp.get("data-longitude") if mp else None,
13 "images": [img["src"] for img in s.select("div.gallery img")],
14 }
15for item in listings:
16 item.update(fetch_detail(item["url"], session))
17 time.sleep(random.uniform(3, 6)) # crítico: jitter anti-bloqueoEl time.sleep(random.uniform(3, 6)) no es opcional. Si lo omites, en unas pocas decenas de solicitudes recibirás un 403. Las páginas de detalle se renderizan del lado del servidor con selectores estables (#titletextonly, #postingbody, #map) que apenas han cambiado desde ~2017; de las pocas cosas fiables que tiene Craigslist.
Paso 6: maneja la paginación para extraer todos los resultados
Craigslist usa el parámetro de desplazamiento ?s=120 para paginar. Cada página muestra 120 resultados y el offset máximo suele ser 2999.
1def iter_all(city, slug, max_pages=25, **filters):
2 for page in range(max_pages):
3 offset = page * 120
4 url = build_url(city, slug, s=offset, **filters)
5 r = session.get(url, headers=HEADERS, timeout=20)
6 r.raise_for_status()
7 soup = BeautifulSoup(r.text, "html.parser")
8 tag = soup.select_one("script#ld_searchpage_results")
9 if not tag:
10 break
11 data = json.loads(tag.text)
12 items = data.get("itemListElement", [])
13 if not items:
14 break
15 for entry in items:
16 item = entry["item"]
17 offers = item.get("offers", {}) or {}
18 yield {
19 "name": item.get("name"),
20 "url": offers.get("url"),
21 "price": offers.get("price"),
22 }
23 time.sleep(random.uniform(2.5, 5.0))No intentes scrapear miles de páginas seguidas. El limitador de Craigslist funciona por IP, y el rendimiento sostenible con una sola IP ronda aproximadamente 0,3–0,5 solicitudes/segundo, sin importar la librería que uses. Ese techo lo pone Craigslist, no Python.
Paso 7: exporta tus datos de Craigslist a CSV, JSON o Google Sheets
Guarda los resultados:
1# CSV
2with open("craigslist.csv", "w", newline="", encoding="utf-8") as f:
3 w = csv.DictWriter(f, fieldnames=listings[0].keys())
4 w.writeheader()
5 w.writerows(listings)
6# JSON
7with open("craigslist.json", "w", encoding="utf-8") as f:
8 json.dump(listings, f, indent=2, ensure_ascii=False)Si prefieres saltarte por completo el código de exportación, Thunderbit ofrece exportación gratuita a Google Sheets, Excel, Airtable o Notion directamente desde el navegador. Pero para flujos de Python, CSV y JSON son los formatos estándar. También puedes pasar los datos directamente a pandas para analizarlos o a una base de datos con sqlite3.
Cómo evitar que te baneen cuando haces scraping de Craigslist con Python
La mayoría de los tutoriales pasan por alto esta parte. El sistema anti-bots de Craigslist está hecho a medida, no es una solución genérica, y tiene varias particularidades.

Usa headers de solicitud realistas
Craigslist valida el orden y la completitud de los headers. Una petición sin Sec-Fetch-Dest o con un User-Agent desactualizado será marcada antes incluso de llegar al contenido. El conjunto completo de headers de Chrome 120+ (mostrado en el Paso 3) es el mínimo. Rota el User-Agent por sesión entre 5 y 10 cadenas recientes de Chrome/Firefox de escritorio, pero no lo cambies a mitad de sesión, porque eso parece artificial.
La ausencia de headers Sec-Fetch-* es la razón más común por la que los scrapers primerizos reciben bloqueos instantáneos.
Añade retrasos aleatorios entre peticiones
El consenso de la comunidad, basado en (ScrapingBee, Scraperly, Oxylabs, Multilogin), converge en 2–5 segundos aleatorios entre solicitudes de páginas de búsqueda y 3–6 segundos entre páginas de detalle. Los intervalos fijos parecen comportamiento de bot. Usa time.sleep(random.uniform(2, 5)); nunca time.sleep(2).
Rota proxies si vas a gran escala
Craigslist bloquea de antemano rangos enteros de IP de AWS, GCP y Azure. Los proxies de datacenter suelen estar muertos desde el primer intento. Para algo más que unas pocas centenas de páginas, necesitas proxies residenciales rotativos, cambiándolos cada 20–30 solicitudes. Los proxies móviles tienen el menor riesgo de detección, pero cuestan entre $8 y $30 por GB.
| Tipo de proxy | Riesgo de detección en Craigslist | Costo (2025) |
|---|---|---|
| Datacenter | Muy alto: a menudo bloqueado en la primera solicitud | $0,50–2/GB |
| Residencial rotativo | Bajo: recomendado | $5–15/GB |
| Móvil | El más bajo | $8–30/GB |
El modo Cloud Scraping de Thunderbit gestiona la rotación de proxies automáticamente si prefieres no encargarte de eso.
Gestiona los CAPTCHAs con calma
Los CAPTCHAs en Craigslist son poco frecuentes en las rutas de lectura; aparecen sobre todo al publicar o responder. Si aparece uno: detente al menos 60 segundos, cambia de IP, borra las cookies y baja la velocidad. Los CAPTCHAs persistentes son señal de que tu ritmo es demasiado agresivo, no un acertijo para resolver a la fuerza con un solver.
Respeta los límites de frecuencia e implementa backoff
Craigslist devuelve 403 y no 429 cuando alcanzas el límite. Un 403 significa que la IP actual está en una lista de bloqueo: no reintentes a ciegas. Cambia de IP, cambia el UA y espera.
1from requests.adapters import HTTPAdapter
2from urllib3.util.retry import Retry
3retry = Retry(
4 total=5,
5 backoff_factor=1.5, # 1.5, 3, 6, 12, 24s
6 status_forcelist=[429, 500, 502, 503, 504],
7 allowed_methods={"GET"},
8 respect_retry_after_header=True,
9)
10adapter = HTTPAdapter(max_retries=retry)
11session.mount("https://", adapter)Un consejo más: los reportes de la comunidad señalan de forma consistente la franja de 2 a 6 de la mañana en la hora local de la ciudad objetivo como la ventana más segura, con una tasa de bloqueos entre un 30% y un 40% menor que durante el día.
Fingerprinting TLS: la trampa oculta
La capa anti-bots de Craigslist inspecciona el ClientHello de TLS. La librería requests de Python (basada en OpenSSL) tiene una huella JA3 que no coincide con la de un navegador real. Un User-Agent perfecto combinado con una huella TLS que no sea de navegador es una discrepancia detectable. La solución es usar con impersonate="chrome124", que emula el handshake TLS de Chrome:
1from curl_cffi import requests as cffi_requests
2r = cffi_requests.get(url, headers=HEADERS, impersonate="chrome124")Si recibes 403 sin explicación, incluso con IPs residenciales limpias y headers correctos, el fingerprint TLS es casi con total seguridad el culpable.
robots.txt, términos de uso y scraping ético en Craigslist
La mayoría de las guías se saltan esto por completo o lo mencionan en una línea dentro de las FAQ. Dado que Craigslist ganó una sentencia de contra un scraper (RadPad, 2017), merece más que una nota al pie.
Qué dice realmente el robots.txt de Craigslist
El es sorprendentemente corto. Tiene un solo bloque User-agent: * con solo siete rutas bloqueadas:
1Disallow: /reply
2Disallow: /fb/
3Disallow: /suggest
4Disallow: /flag
5Disallow: /mf
6Disallow: /mailflag
7Disallow: /eafLas siete son endpoints interactivos o modificadores: responder, reportar, sugerir, email-a-friend. Las páginas de anuncios (/search/..., URLs individuales de publicaciones) no están bloqueadas. Tampoco hay directiva Crawl-delay, aunque Craigslist la aplica de facto mediante bloqueos por IP.
Los subdominios de ciudad sí publican sitemaps — por ejemplo, https://newyork.craigslist.org/sitemap/index.xml — que son la vía oficialmente descubrible para encontrar anuncios.
Precedentes legales: los casos que importan
Craigslist v. 3Taps (2013, acuerdo en 2015): 3Taps scrapeó anuncios de Craigslist y los revendió. Cuando Craigslist envió una orden de cese y bloqueó sus IPs, 3Taps rodeó el bloqueo con proxies rotativos. El tribunal sostuvo que eludir bloqueos IP tras una revocación explícita constituía acceso "sin autorización" bajo la CFAA. 3Taps .
Meta v. Bright Data (2024): una resolución más reciente concluyó que los términos de servicio de Meta no pueden prohibir el scraping de datos públicamente disponibles cuando el usuario no ha iniciado sesión. El tribunal sostuvo que un scraper desconectado estaba "en la misma posición que un visitante". Es la decisión más importante para scrapers de 2024–2025: si nunca creas una cuenta de Craigslist, nunca inicias sesión y solo accedes a páginas visibles públicamente, quizá los términos no sean ejecutables contra ti como contrato.
Conclusión práctica: el riesgo bajo la CFAA se redujo mucho después de Van Buren (2021) y hiQ v. LinkedIn (2022) para páginas de acceso público. Pero siguen existiendo reclamaciones estatales por daños civiles, como invasión de bienes muebles y apropiación indebida; eso fue lo que llevó tanto al acuerdo de 3Taps como a la sentencia de $60,5M contra RadPad.
Esto es información general, no asesoría legal. Si vas a scrapear Craigslist con fines comerciales, consulta con un abogado.
Checklist práctico de scraping ético
- ✅ Respeta todos los
Disallowde robots.txt, especialmente los siete endpoints de acción - ✅ Mantente muy por debajo de 1.000 páginas por cada período de 24 horas por IP (los términos de Craigslist fijan por encima de ese umbral como daños liquidados)
- ✅ Mantente desconectado: nunca crees una cuenta de Craigslist para scrapear
- ✅ Nunca eludas bloqueos IP con proxies después de un bloqueo explícito (eso fue lo que hundió a 3Taps)
- ✅ Añade pausas entre peticiones: mínimo 2–5 segundos
- ✅ No extraigas datos de contacto personales para spam
- ✅ No redistribuyas datos crudos de Craigslist ni los presentes como tu propia plataforma
- ✅ Usa los datos para investigación legítima, análisis o uso personal
- ✅ Si puedes, prioriza los sitemaps publicados en lugar de rastrear a la fuerza
- ✅ Elimina PII (emails, teléfonos) al ingerir los datos si los vas a almacenar
Hemos escrito una guía más profunda sobre las si quieres una visión completa.
Python vs. sin código: ¿qué enfoque te conviene?
| Factor | Python (requests + BS4) | Thunderbit (sin código) |
|---|---|---|
| Tiempo de configuración | 30–60 min (instalar, escribir código) | 2 minutos (instalar extensión de Chrome) |
| Conocimientos técnicos necesarios | Python intermedio | Ninguno |
| Personalización | Control total sobre lógica, campos y flujo | La IA detecta los campos automáticamente; el usuario puede ajustar |
| Escala | Ilimitada (con proxies y programación) | Scheduled Scraper para tareas recurrentes |
| Gestión anti-bloqueo | Manual (headers, pausas, proxies, TLS) | Integrada (Cloud Scraping) |
| Opciones de exportación | CSV, JSON (lo programas tú) | Google Sheets, Excel, Airtable, Notion — gratis |
| Ideal para | Desarrolladores, data scientists, pipelines personalizados | Equipos de ventas, agentes inmobiliarios, responsables de operaciones |
Usa Python si necesitas personalización completa, si vas a integrarlo en un pipeline de datos más grande o si quieres entender exactamente qué ocurre por debajo. Usa si quieres resultados rápidos sin escribir ni mantener código. Ambas opciones son válidas. Todo depende de tu caso de uso y de si prefieres pasar el tiempo en una terminal o en el navegador.
Conclusión
Craigslist es una fuente de datos rica y en constante actualización sobre vivienda, autos, empleos, servicios, gigs y más, y como no tiene API pública, hacer scraping es la única forma de obtener datos estructurados a escala. El enfoque que realmente funciona en 2025 es este: extraer el JSON-LD incrustado de los resultados de búsqueda (no selectores CSS frágiles), usar requests + BeautifulSoup (no Selenium), añadir headers realistas con campos Sec-Fetch-*, aleatorizar los tiempos de espera y usar proxies residenciales si vas a superar unas pocas centenas de páginas.
El método JSON-LD es, con diferencia, la mejora más grande frente a las guías antiguas. Es más rápido, más resistente a cambios de diseño y no necesita renderizado JavaScript. Si lo combinas con las estrategias anti-bloqueo de arriba, evitarás la mayoría de los 403 que hacen tropezar a otros scrapers.
Si prefieres saltarte el código por completo, la puede scrapear cualquier categoría de Craigslist en un par de clics y exportar directamente a tu hoja de cálculo o base de datos favorita. Si quieres profundizar más, nuestras guías sobre y explican los fundamentos con más detalle.
Preguntas frecuentes
¿Es legal scrapear Craigslist?
Los Términos de uso de Craigslist prohíben el scraping automatizado e incluyen una cláusula de daños liquidados ($0,25 por página por encima de 1.000 al día). Sin embargo, resoluciones judiciales recientes — en particular Meta v. Bright Data (2024) y hiQ v. LinkedIn (2022) — han reducido la responsabilidad bajo la CFAA para el scraping desconectado de datos públicamente disponibles. Las reclamaciones estatales por daños civiles siguen siendo un riesgo, especialmente en redistribución comercial. Respeta robots.txt, mantente desconectado, añade pausas y no redistribuyas datos crudos. Esto es información general, no asesoría legal.
¿Craigslist tiene una API pública?
No. Craigslist solo ofrece una Bulk Posting Interface (BAPI) de solo escritura para publicadores de pago aprobados. No hay API pública de lectura, ni portal para desarrolladores, ni un nivel con límite de tasa para recuperar datos. Todo producto tipo "Craigslist API" que veas en plataformas de terceros es un scraper no oficial.
¿Por qué mi scraper de Craigslist se rompe todo el tiempo?
Casi siempre por cambios en la estructura HTML. Craigslist reescribió el marcado de resultados de búsqueda en 2023–2024, y las guías que usan selectores antiguos como .result-row o .result-info ya no funcionan. Cambia al método JSON-LD incrustado (parseando script#ld_searchpage_results) para una solución mucho más resistente. Revisa también que tus headers incluyan los campos Sec-Fetch-*; si faltan, el bloqueo es inmediato.
¿Puedo scrapear Craigslist sin Python?
Sí. La extensión de Chrome de Thunderbit, con su AI web scraper, funciona en cualquier página de Craigslist: departamentos, autos, empleos, servicios. Haz clic en "AI Suggest Fields" para detectar columnas automáticamente, luego en "Scrape" para extraer los datos, y exporta gratis a Google Sheets, Excel, Airtable o Notion. Sin código, sin configuración, sin gestionar proxies.
¿Con qué frecuencia puedo scrapear Craigslist sin que me baneen?
Con una sola IP residencial, el rendimiento sostenible es de aproximadamente 0,3–0,5 solicitudes por segundo con pausas aleatorias de 2–5 segundos entre páginas. Mantente por debajo de 1.000 páginas por cada período de 24 horas por IP para evitar tanto bloqueos como el umbral de daños liquidados en los Términos de Craigslist. Scrappear en horas valle (de 2 a 6 de la mañana, hora local de la ciudad objetivo) reduce la tasa de bloqueos en torno a un 30–40%. Para volúmenes mayores, rota proxies residenciales cada 20–30 solicitudes.
Más información