Resumen ejecutivo
planteaba una pregunta de política: ¿cuántos de los sitios web más visitados del mundo les están diciendo a los crawlers de IA qué pueden hacer y qué no?
Este seguimiento plantea la pregunta operativa que hay detrás: ¿qué tan fiable es robots.txt como infraestructura para sostener esa política hoy?
La respuesta es incómoda. robots.txt sigue funcionando porque es público, barato, legible por máquinas y los crawlers ya lo entienden. Pero también se le está pidiendo mucho más de lo que fue diseñado para hacer. En 2026, el mismo archivo de texto plano puede incluir controles de rastreo SEO, índices de sitemaps, extensiones heredadas de motores de búsqueda, exclusiones de entrenamiento para IA, vocabulario de políticas inyectado por Cloudflare, reservas de copyright y lenguaje legal pensado para futuras disputas.
Eso es deuda de configuración.
El conjunto de datos detrás de este informe es el mismo rastreo de Tranco Top 10,000 usado en el estudio original sobre crawlers de IA. De los 10,000 dominios, 6,638 devolvieron un robots.txt legible; otros 610 devolvieron 404, que el protocolo trata como permiso implícito. Esto deja 7,248 sitios analizables para decisiones de acceso de bots y 6,638 archivos concretos para analizar la complejidad de configuración.
Destacan seis hallazgos:
-
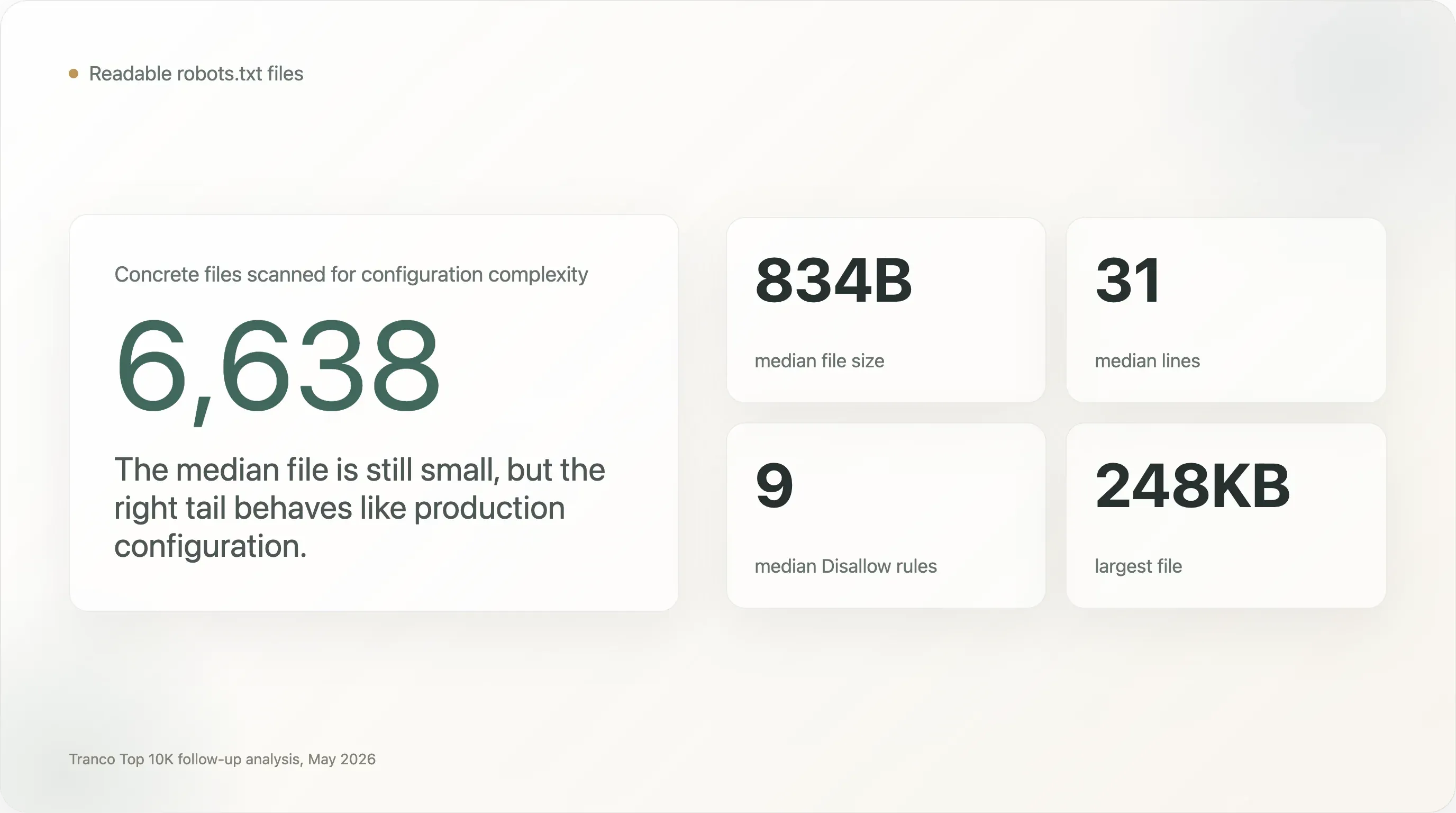
La mayoría de los archivos
robots.txtson pequeños, pero la cola derecha es extremadamente compleja. El archivo mediano pesa solo 834 bytes y tiene 31 líneas. Pero 1,005 archivos tienen al menos 5 KB, 273 al menos 20 KB y 28 al menos 100 KB. El archivo más grande de la muestra pesa 248 KB. -
Cientos de sitios web importantes ejecutan archivos que se parecen más a configuraciones de producción que a notas de política. El archivo mediano tiene 9 directivas
Disallow. Pero 707 sitios tienen al menos 100 reglasDisallow, 13 tienen al menos 1,000, 240 nombran al menos 50 user agents y 110 nombran al menos 100 user agents. -
La deriva del protocolo no es teórica. Entre los 6,638 archivos legibles, 685 contienen
Crawl-delay, 303 contienenHost, 200 contienenClean-param, 9 contienenRequest-rate, 5 contienenVisit-timey 271 contienen lenguaje deContent-Signalal estilo Cloudflare. No todas estas directivas forman parte de un estándar limpio y único. Son folclore acumulado de los crawlers. -
Googlebot recibe un trato especial. 562 dominios analizables bloquean al menos un crawler de búsqueda tradicional. En 404 de esos casos, Googlebot está permitido mientras al menos otro crawler de búsqueda está bloqueado. La discriminación entre crawlers de IA no apareció en un ecosistema neutral;
robots.txtya codificaba una jerarquía entre motores de búsqueda. -
La política de IA hace más visible la deuda. 1,377 archivos legibles contienen lenguaje de política de IA; 719 contienen lenguaje sobre copyright, términos, licencias o permisos; y 501 contienen ambos. El archivo se ha convertido a la vez en interfaz para máquinas y en artefacto legal. Eso es útil, pero frágil.
-
Los archivos más riesgosos no siempre son los más anti-IA. Ecommerce, viajes, redes sociales, finanzas, academia y noticias generan archivos complejos por razones distintas: control del presupuesto de rastreo, rutas heredadas, contenido generado por usuarios, reservas de derechos y excepciones específicas para bots. Las reglas de IA se están superponiendo sobre una base ya caótica.
La conclusión principal: robots.txt sigue siendo la superficie pública más importante de política para crawlers en la web, pero es una base débil para una gobernanza de IA de alto impacto a menos que el ecosistema estandarice la identidad de los crawlers, el vocabulario de uso de IA y la auditabilidad de la política.
Metodología
Este informe reutiliza el conjunto de datos del análisis original de Thunderbit sobre la política de crawlers de IA en los dominios Tranco Top 10,000.
Los materiales de entrada fueron:
tranco_top10k.csv— la lista original de dominios Tranco Top 10K.out/fetch_meta.csv— estado de la extracción, conteo de bytes, esquema, resultado de redirección y metadatos de error.out/sites.csv— dominio, ranking, categoría, idioma y estado derobots.txt.out/site_meta.csv— una fila analítica por sitio, incluida la clase de plantilla, las banderas de bloqueo de IA, el tamaño del archivo y los campos resumen de la política de bots.out/bot_status.csv— una fila por dominio y crawler, incluida la información de si ese bot está bloqueado y si existe una regla específica.raw_robots/— cuerpos derobots.txtalmacenados en caché para los 6,638 sitios que devolvieron estado200.
Para este seguimiento, cada archivo robots.txt legible se analizó buscando:
- tamaño del archivo y número de líneas;
- líneas activas que no son comentarios;
- recuentos de directivas
User-agent,Disallow,AllowySitemap; - directivas heredadas o no centrales como
Crawl-delay,Host,Clean-param,Request-rateyVisit-time; - vocabulario de la era de la IA, incluidos
Content-Signal,llms.txt, AI, LLM, machine learning, TDM y2019/790; - vocabulario legal como copyright, términos de servicio, licencias, permisos y lenguaje de reserva de derechos;
- tratamiento de crawlers de búsqueda para Googlebot, Bingbot, DuckDuckBot, Slurp, Baiduspider y YandexBot.
El informe también define una puntuación simple de deuda de configuración para priorizar revisiones. Combina el tamaño del archivo, el conteo de user agents, el conteo de Disallow, el conteo de Allow, el número de directivas no estándar y la mezcla de lenguaje de política de IA y lenguaje legal. La puntuación no pretende ser una medida universal de corrección. Es una forma de identificar archivos que probablemente sean difíciles de mantener, revisar o interpretar.
Todas las tablas y gráficos derivados se incluyen en la carpeta de entrega.
Hallazgo 1: El archivo mediano es simple; la cola no lo es
El archivo robots.txt típico en la web de mayor tráfico sigue siendo pequeño.
Entre los 6,638 archivos legibles:
| Métrica | Mediana | P90 | P95 | P99 | Máximo |
|---|---|---|---|---|---|
| Tamaño del archivo | 834 bytes | 6.7 KB | 15.8 KB | 76.0 KB | 248.3 KB |
| Líneas | 31 | 238 | 332 | 1,008 | 4,998 |
| Líneas activas | 23 | 198 | 282 | 837 | 4,998 |
Directivas User-agent | 1 | 21 | 39 | 137 | 823 |
Directivas Disallow | 9 | 103 | 176 | 422 | 4,997 |
Directivas Allow | 1 | 17 | 33 | 69 | 890 |
Esta distribución importa porque a menudo se habla de robots.txt como si fuera una declaración pequeña:
1User-agent: *
2Disallow: /private/Ese modelo mental es incorrecto para una parte significativa de la web de alto tráfico.
En este conjunto de datos:
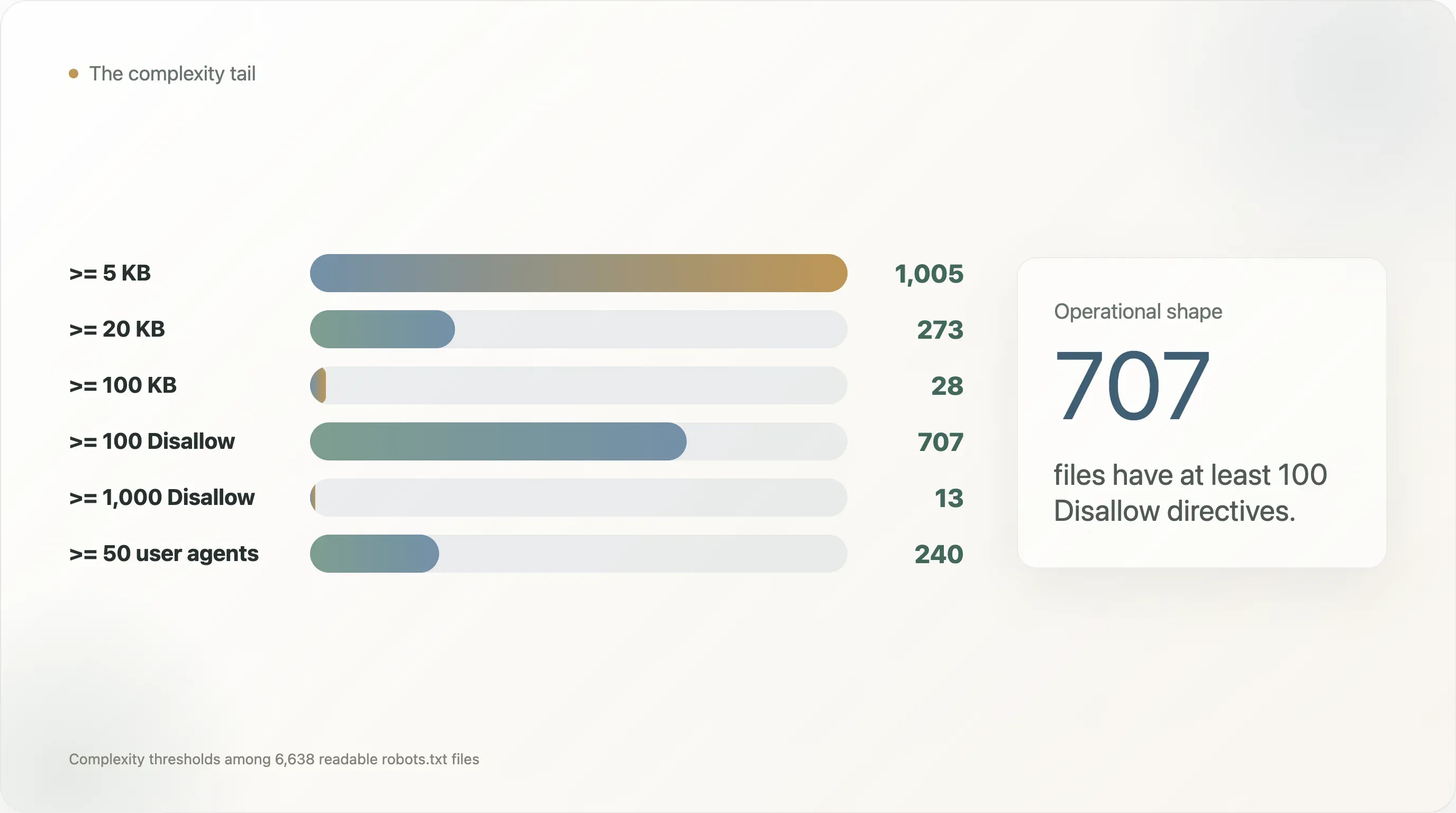
This paragraph contains content that cannot be parsed and has been skipped.
Los archivos más grandes y complejos no son curiosidades académicas. Pertenecen a propiedades reales y de alto tráfico:
| Dominio | Ranking | Categoría | Bytes | User-agent | Disallow | Allow |
|---|---|---|---|---|---|---|
linkedin.com | 17 | social | 114,341 | 76 | 4,184 | 281 |
runescape.com | 5,226 | unknown | 113,393 | 1 | 4,997 | 0 |
academia.edu | 832 | academia | 57,384 | 63 | 2,044 | 227 |
etsy.com | 286 | ecommerce | 51,320 | 3 | 1,621 | 120 |
thepaper.cn | 9,395 | news | 56,867 | 1 | 1,496 | 0 |
opentable.com | 4,137 | unknown | 70,494 | 32 | 1,683 | 176 |
alfabank.ru | 2,625 | finance | 73,158 | 2 | 1,566 | 133 |
Estos archivos se parecen más a tablas de enrutamiento de producción que a consignas de política. Codifican años de lanzamientos de productos, rutas heredadas, patrones de parámetros bloqueados, excepciones para crawlers, experimentos de SEO, decisiones de CDN y, ahora, reglas para crawlers de IA.
La cola no es solo una historia de IA. De los 273 archivos de 20 KB o más, 131 contienen lenguaje de política de IA y 142 no. De los 707 archivos con al menos 100 directivas Disallow, solo 207 contienen lenguaje de política de IA. En otras palabras, la IA no creó el problema de los archivos grandes. Llegó después de que años de operaciones web normales ya hubieran llenado el archivo de reglas de rutas, referencias a sitemaps y excepciones para crawlers.
Eso importa porque la mantenibilidad depende de la forma, no solo de la intención. Un archivo pequeño con un bloqueo directo de IA puede ser fácil de auditar. Un archivo de 70 KB de ecommerce o viajes puede ser difícil de auditar aunque no diga nada sobre IA. El riesgo no es que todos los archivos grandes estén mal. El riesgo es que la política efectiva sea demasiado difícil de verificar para quienes son responsables de ella.
El riesgo operativo es sencillo: a medida que robots.txt crece, resulta más difícil que un editor, un ingeniero de plataforma, un abogado o un responsable de SEO responda a la pregunta básica: ¿qué permite realmente este archivo?
Esa pregunta ya no es trivial. Según el análisis estilo RFC, un crawler puede coincidir con un grupo de user agents más específico en lugar de User-agent: *; los patrones de ruta más largos pueden prevalecer sobre los más cortos; las directivas Allow y Disallow interactúan por precedencia; y las reglas genéricas de denegación total pueden atrapar accidentalmente nuevos crawlers que no existían cuando se escribió el archivo.
Para un archivo de 30 líneas, una persona puede razonar sobre eso. Para un archivo de 4,000 líneas con docenas de bots nombrados, nadie debería.
Hallazgo 2: robots.txt está cargando con más que reglas de rastreo
El debate sobre crawlers de IA hizo que robots.txt se volviera políticamente visible, pero el archivo subyacente ya venía acumulando responsabilidades no relacionadas.
Un robots.txt moderno de un sitio importante puede incluir:
- controles de rutas para crawlers;
- descubrimiento de sitemaps;
- extensiones específicas para motores de búsqueda;
- sugerencias de ritmo de rastreo;
- sugerencias de canonización de host;
- sugerencias para limpiar parámetros de URL;
- vocabulario de políticas inyectado por la CDN;
- texto de reserva de copyright;
- exclusiones para entrenamiento de IA;
- comentarios legales legibles por humanos.
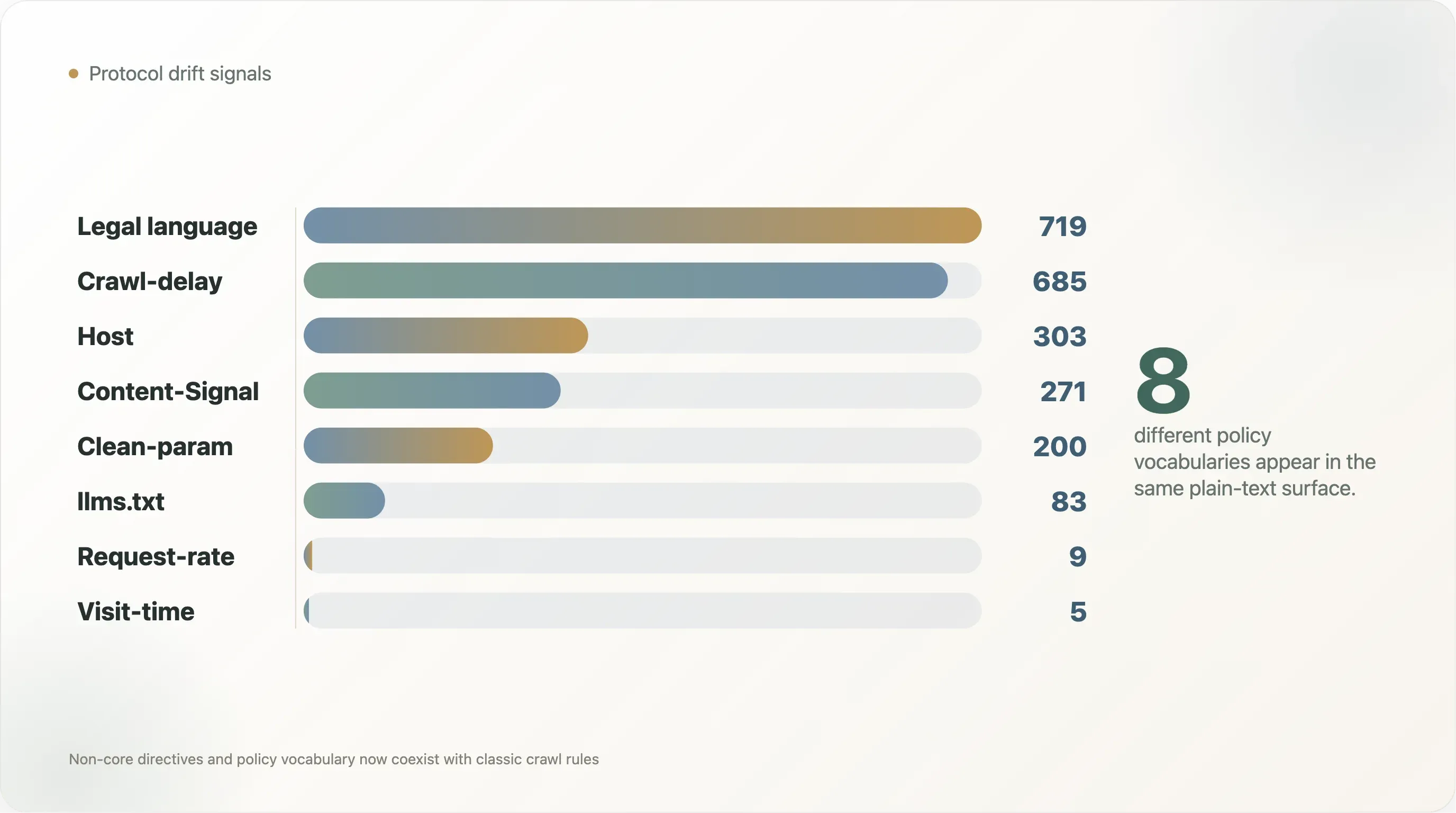
El conjunto de datos muestra esta superposición con claridad.
| Señal | Archivos | Proporción de archivos legibles |
|---|---|---|
Crawl-delay | 685 | 10.3% |
Host | 303 | 4.6% |
Clean-param | 200 | 3.0% |
Content-Signal | 271 | 4.1% |
Request-rate | 9 | 0.1% |
Visit-time | 5 | 0.1% |
Mención de llms.txt | 83 | 1.3% |
| Lenguaje de copyright, términos, licencias o permisos | 719 | 10.8% |
| Lenguaje de política de IA | 1,377 | 20.7% |
Algunas de estas directivas son ampliamente reconocidas por crawlers específicos. Algunas son convenciones heredadas. Algunas dependen del proveedor. Otras ni siquiera son directivas para crawlers, sino lenguaje legal o de producto incrustado en comentarios.
Así se ve la deriva del protocolo.
Crawl-delay es un buen ejemplo. Muchos operadores de sitios lo conocen, pero el soporte entre los principales crawlers es desigual. Host y Clean-param históricamente se han asociado con el comportamiento de Yandex. Content-Signal forma parte del vocabulario de políticas de Cloudflare para la era de la IA. llms.txt es un formato adyacente propuesto para descubrimiento, no un estándar universalmente respetado. Sin embargo, todos estos elementos aparecen en el mismo tipo de archivo, a menudo junto a las reglas clásicas User-agent y Disallow.
Las cifras también muestran cómo conviven ahora las convenciones antiguas y nuevas. Crawl-delay aparece en 685 archivos, más del doble que los 271 archivos con Content-Signal. Host aparece en 303 archivos y Clean-param en 200, lo que refleja sobre todo convenciones de la era de los motores de búsqueda. llms.txt, pese a la atención que recibe en el entorno de búsqueda con IA, se menciona en solo 83 archivos legibles. La web real no está convergiendo en un solo vocabulario. Está apilando vocabularios.
El problema no es que cada extensión por separado sea incorrecta. El problema es que el archivo se ha convertido en un contenedor sin versión para varios sistemas de gobernanza que se solapan.
Eso genera tres tipos de deuda:
- Deuda semántica. Distintos crawlers pueden interpretar el mismo archivo de forma diferente.
- Deuda de propiedad. Equipos de SEO, legales, infraestructura, seguridad y producto pueden tener razones para editar el archivo, pero ningún equipo tiene por qué poseer toda la política.
- Deuda de auditoría. Un sitio puede publicar una política que parezca intencional, mientras que solo un parser puede determinar su comportamiento efectivo.
La IA hace esto más importante porque los riesgos han cambiado. Cuando se ignora una sugerencia heredada de ritmo de rastreo, el resultado puede ser tráfico adicional. Cuando una exclusión de entrenamiento para IA es ambigua, el resultado puede convertirse en evidencia en una disputa de copyright o de licencias.
Hallazgo 3: El archivo se ha convertido a la vez en interfaz de máquina y artefacto legal
El informe original sobre crawlers de IA mostró que el 17.0% de los sitios analizables había escrito reglas explícitas específicas para IA. Este seguimiento examina la carga textual que añaden esas políticas.
Entre los 6,638 archivos robots.txt legibles:
- 1,377 contienen lenguaje de política de IA;
- 719 contienen lenguaje sobre copyright, términos, licencias, derechos o permisos;
- 271 contienen
Content-Signal; - 83 mencionan
llms.txt.
La intersección es donde la historia se vuelve más interesante:
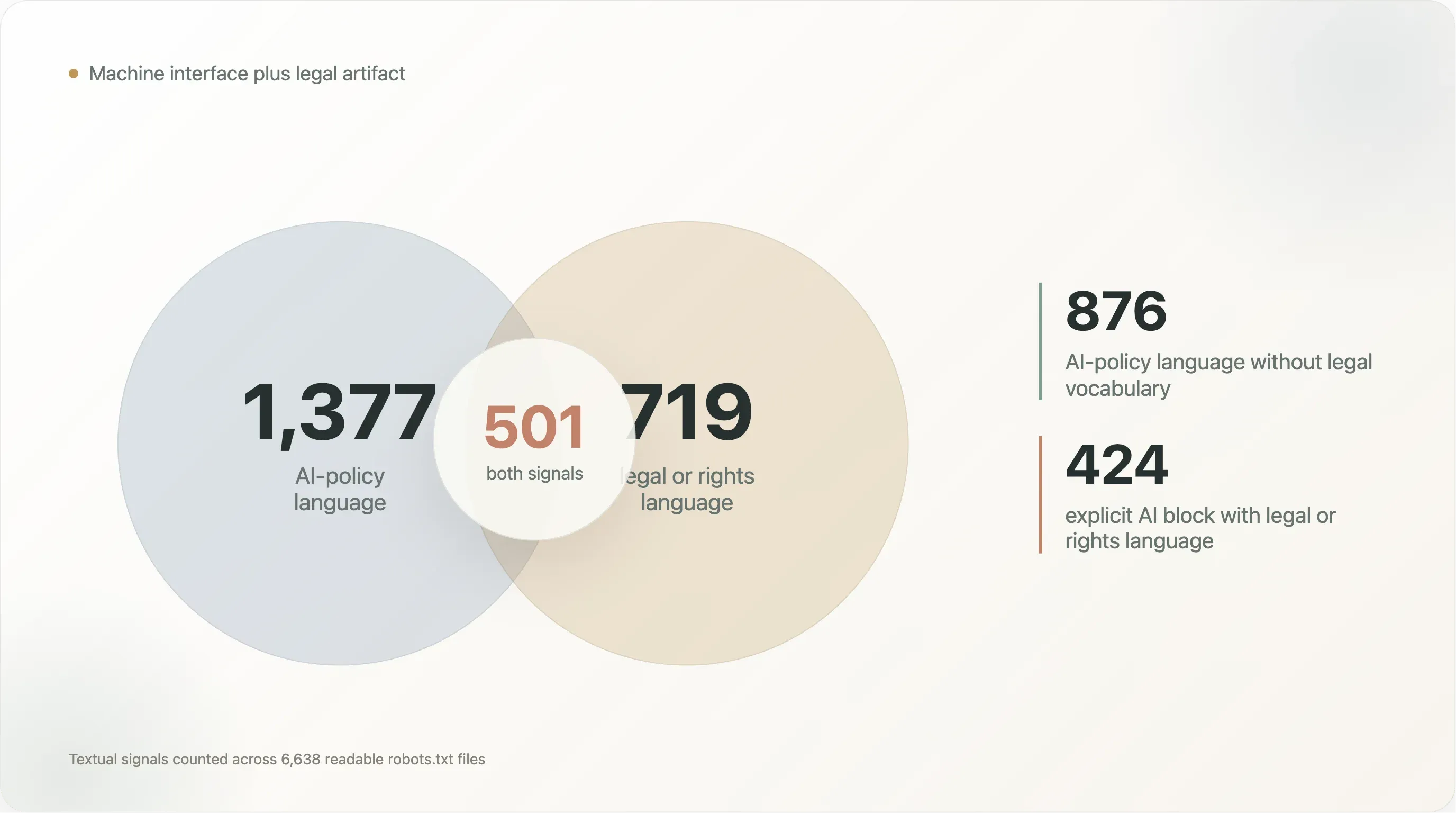
| Patrón textual | Archivos |
|---|---|
| Lenguaje de política de IA y lenguaje legal/de derechos | 501 |
| Lenguaje de política de IA sin lenguaje legal/de derechos | 876 |
| Lenguaje legal/de derechos sin lenguaje de política de IA | 218 |
Content-Signal con lenguaje legal/de derechos | 242 |
| Bloqueo explícito de IA con lenguaje legal/de derechos | 424 |
Este es un tipo de archivo nuevo.
Un robots.txt tradicional se dirige a crawlers. Un robots.txt con preámbulo legal se dirige al menos a cuatro audiencias al mismo tiempo:
- operadores de crawlers, que necesitan directivas legibles por máquinas;
- proveedores de búsqueda e IA, que necesitan señales de política;
- abogados, que quieren una reserva explícita de derechos;
- futuros auditores, tribunales o periodistas, que pueden leer los comentarios como evidencia de intención.
Ese diseño para múltiples audiencias explica por qué algunos archivos ya se leen como documentos de política. Pero también debilita la separación limpia entre lo que un crawler puede analizar y lo que un abogado quiere declarar.
Los 876 archivos con lenguaje de política de IA pero sin vocabulario legal son, en su mayoría, archivos de política para máquinas: nombres de bots, bloques Disallow y lenguaje de plantillas. Los 501 archivos con lenguaje de IA y lenguaje legal a la vez son distintos. Intentan ser instrucciones para crawlers y reservas de derechos simultáneamente. Los 218 archivos con lenguaje legal pero sin vocabulario de IA muestran que este patrón no empezó con los LLM; robots.txt ya se usaba como lugar para declarar términos, límites de permiso y reclamaciones de derechos.
Por ejemplo, un comentario puede decir que el machine learning está prohibido, mientras que el bloque de directivas real solo desautoriza un subconjunto de user agents conocidos. Un sitio puede reclamar derechos de forma global, pero nombrar solo a unos pocos crawlers. Una plantilla de CDN puede inyectar vocabulario relacionado con IA en un archivo cuyo operador nunca escribió manualmente el lenguaje legal. Un sitio puede escribir una regla amplia User-agent: * que bloquee por accidente a futuros crawlers.
Desde el punto de vista de gobernanza, robots.txt se ha vuelto atractivo precisamente porque es público y legible por máquinas. Pero cuanto más política contiene, más pesan sus limitaciones:
- no hay una capa de autenticación que demuestre que una política específica fue revisada por el titular de derechos y no heredada de la infraestructura;
- no hay historial de versiones nativo;
- no hay un campo estructurado para el uso previsto, como entrenamiento, recuperación, indexación de búsqueda, resumen, caché o evaluación de modelos;
- no hay un registro universal de identidades de crawlers de IA;
- no hay mecanismo de aplicación.
Eso no hace que el archivo sea inútil. Lo hace frágil.
La mejor interpretación es que robots.txt se está convirtiendo en una capa de aviso: una declaración pública e inspeccionable de preferencia e intención. Por sí solo, no es un sistema completo de gestión de derechos.
Hallazgo 4: La búsqueda ya era desigual antes de que llegara la IA
Uno de los hallazgos más sólidos del informe original fue que muchos editores distinguen entre crawlers de entrenamiento para IA y crawlers de búsqueda. Bloquean CCBot, GPTBot o Google-Extended mientras preservan la visibilidad en la búsqueda de Google.
Este seguimiento añade otro punto: los crawlers de búsqueda tradicionales tampoco reciben el mismo trato.
Analizamos seis crawlers de búsqueda:
- Googlebot;
- Bingbot;
- DuckDuckBot;
- Slurp;
- Baiduspider;
- YandexBot.
Entre los 7,248 sitios analizables:
| Tratamiento del crawler de búsqueda | Sitios |
|---|---|
| Bloquea al menos un crawler de búsqueda | 562 |
| Permite Googlebot pero bloquea al menos otro crawler de búsqueda | 404 |
| Bloquea los seis crawlers de búsqueda revisados | 152 |
Los conteos de bots bloqueados no están distribuidos de manera uniforme:
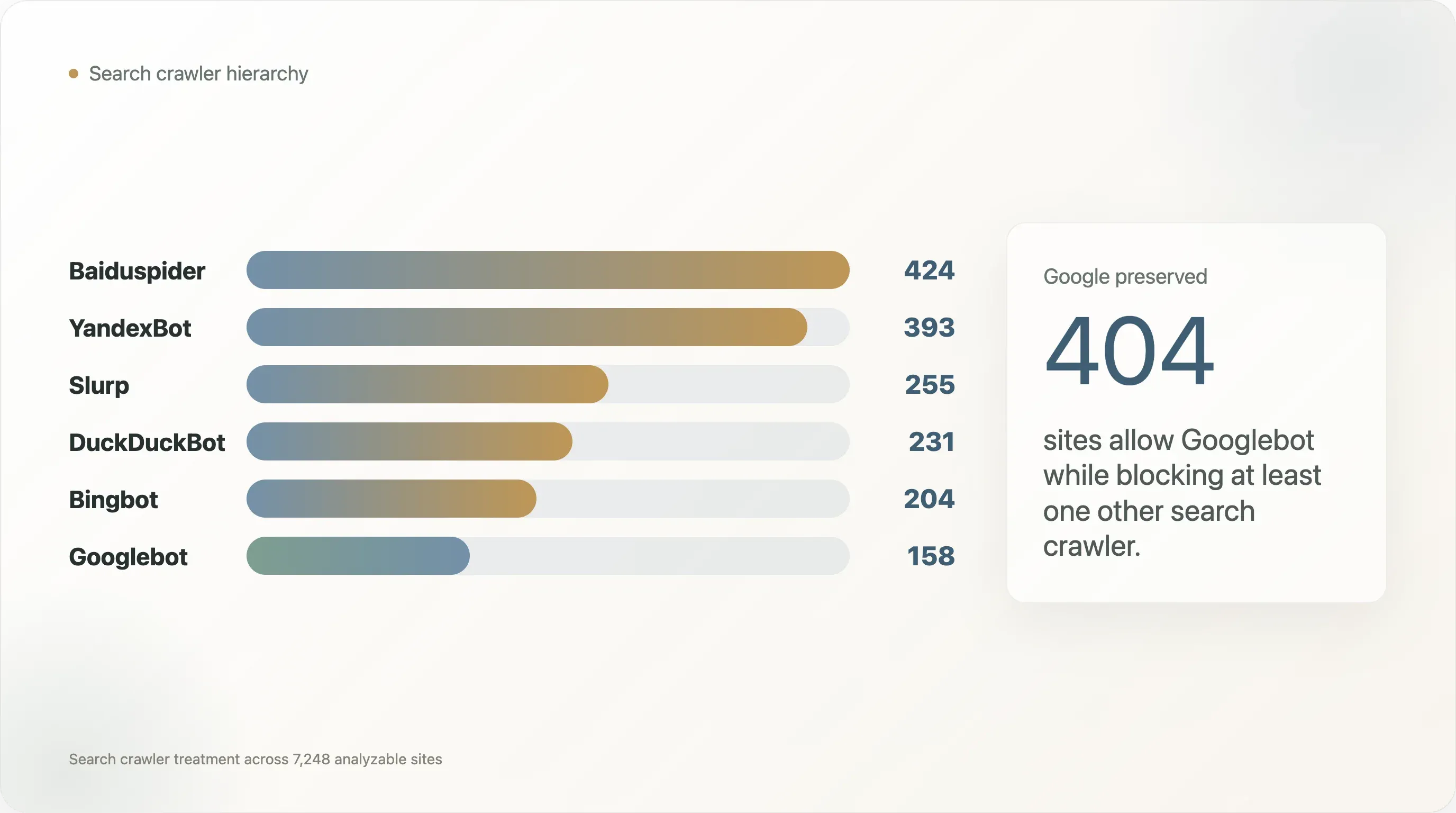
| Crawler de búsqueda | Sitios que lo bloquean |
|---|---|
| Baiduspider | 424 |
| YandexBot | 393 |
| Slurp | 255 |
| DuckDuckBot | 231 |
| Bingbot | 204 |
| Googlebot | 158 |
Googlebot es el crawler menos bloqueado de este conjunto. Baiduspider y YandexBot se bloquean con mucha más frecuencia, y en la mayoría de esos casos Googlebot sigue estando permitido. Entre los 404 sitios que permiten Googlebot mientras bloquean otro crawler de búsqueda, 269 bloquean Baiduspider y 240 bloquean YandexBot.
Los ejemplos son de alto perfil:
| Dominio | Crawlers de búsqueda bloqueados mientras Googlebot está permitido |
|---|---|
facebook.com | Baiduspider, YandexBot |
apple.com | Baiduspider |
twitter.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
netflix.com | DuckDuckBot, Slurp |
x.com | DuckDuckBot, Slurp, Baiduspider, YandexBot |
tiktok.com | Baiduspider |
baidu.com | Bingbot, DuckDuckBot, Slurp, YandexBot |
washingtonpost.com | YandexBot |
wsj.com | YandexBot |
bilibili.com | DuckDuckBot, Slurp, YandexBot |
temu.com | Slurp |
t-mobile.com | Baiduspider, YandexBot |
Esto importa para el debate sobre IA porque muestra que robots.txt no era un protocolo neutral de acceso universal ni siquiera antes de que llegaran los crawlers de LLM. La web pública ya tenía una jerarquía:
- Googlebot suele conservarse porque el tráfico de búsqueda de Google es demasiado valioso para arriesgarlo.
- Los crawlers regionales o de competidores se bloquean con más facilidad.
- Algunos sitios tratan el acceso de crawlers de búsqueda como una decisión por mercado o por proveedor.
Los crawlers de IA llegaron a un ecosistema en el que el acceso diferenciado ya era normal.
Eso hace más fácil entender la transición de políticas. Un editor que escribe "bloquear Google-Extended, permitir Googlebot" no está inventando una nueva forma de discriminación. Está aplicando un patrón antiguo a una nueva clase de crawler: preservar la distribución, restringir la extracción.
La pregunta sin resolver es si ese patrón antiguo escala. Con la búsqueda, solo había unos pocos crawlers con peso económico. Con la IA, la identidad de los crawlers se fragmenta entre proveedores de modelos, bots de recuperación, intermediarios de datos, crawlers académicos, agentes de navegador sintético y extractores a nivel de infraestructura. El número de user agents nombrados seguirá creciendo a menos que el ecosistema converja en un conjunto más pequeño de señales basadas en propósito.
Así se acumula la deuda de configuración.
Hallazgo 5: La complejidad varía por sector, pero no como lo hacen las tasas de bloqueo de IA
El informe original mostró una amplia dispersión sectorial en el bloqueo de IA: noticias bloquea a tasas altas; telecomunicaciones, gobierno y SaaS bloquean a tasas bajas.
La complejidad de configuración corta la web de otra manera.
Entre las categorías seleccionadas con suficientes archivos robots.txt legibles para hacer una comparación útil:
| Categoría | n | Bytes medianos | Bytes P90 | Disallow mediano | Disallow P90 | User-agent mediano | User-agent P90 |
|---|---|---|---|---|---|---|---|
| ecommerce | 215 | 1,738 | 10,388 | 37 | 164 | 3 | 49 |
| travel | 63 | 2,074 | 27,368 | 41 | 779 | 5 | 34 |
| news | 647 | 1,534 | 7,039 | 19 | 114 | 6 | 68 |
| finance | 121 | 1,002 | 8,337 | 17 | 132 | 2 | 23 |
| academia | 253 | 839 | 3,959 | 14 | 75 | 1 | 11 |
| government | 151 | 1,227 | 3,263 | 13 | 46 | 1 | 4 |
| SaaS | 368 | 485 | 12,606 | 4 | 56 | 1 | 10 |
| dev tools | 119 | 273 | 9,255 | 3 | 58 | 1 | 10 |
This paragraph contains content that cannot be parsed and has been skipped.
Las noticias son políticamente complejas porque escriben reglas explícitas de IA y texto legal. Pero ecommerce y viajes son operativamente complejos porque tienen catálogos grandes, navegación facetada, páginas de resultados de búsqueda, filtros, rutas de cuenta de usuario y URL parametrizadas.
Esa distinción es importante.
Viajes es el ejemplo más claro. Tiene solo 63 archivos legibles en este corte de categoría, pero su robots.txt P90 es de 27.4 KB y su conteo P90 de Disallow es 779, muy por encima de noticias. Eso no significa que los sitios de viajes tengan una política de IA más desarrollada. Significa que tienen más superficies en las que los operadores de crawlers pueden desperdiciar presupuesto sin querer: búsquedas por fecha, páginas de disponibilidad, paginación de reseñas, flujos de reserva, combinaciones de filtros y rutas de inventario localizadas.
SaaS es el otro tipo de sorpresa. Su archivo mediano pesa solo 485 bytes, pero el archivo P90 sube a 12.6 KB. La mayoría de los sitios SaaS son abiertos y ligeros; un subconjunto más pequeño lleva archivos largos de control de rutas, a menudo porque la documentación, las superficies de inicio de sesión, las rutas de la app y las páginas de marketing conviven bajo el mismo dominio.
Las noticias quedan en el medio desde el punto de vista operativo pero casi en la cima desde el punto de vista político. Su conteo P90 de User-agent es 68, superior al de ecommerce, viajes, finanzas, academia, gobierno, SaaS y dev tools en esta tabla. Eso es una señal de política específica por bot, no solo de higiene de rutas.
El robots.txt de un editor puede ser complejo por la política de derechos. El de un marketplace puede ser complejo por la gestión del presupuesto de rastreo. El de una universidad puede ser complejo porque miles de rutas heredadas se acumularon bajo un mismo dominio. El de una plataforma social puede ser complejo porque tiene que exponer algunas superficies y suprimir otras a gran escala.
La política de IA se superpone encima de todo eso. No reemplaza las razones existentes por las que un archivo es complejo.
Esto ayuda a explicar por qué la gobernanza de robots.txt en la era de la IA no se puede resolver con una lista de bloqueo universal. Los archivos subyacentes tienen funciones distintas:
- los sitios de ecommerce gestionan rutas duplicadas y superficies de inventario;
- los sitios de viajes gestionan listados, calendarios, reseñas y páginas de búsqueda dinámicas;
- los sitios de noticias gestionan copyright, archivos y postura de licencias;
- los sitios SaaS y de herramientas para desarrolladores a menudo quieren visibilidad en IA;
- los gobiernos suelen necesitar acceso público, pero aun así pueden tener sistemas sensibles que excluir;
- las plataformas sociales gestionan contenido generado por usuarios, superficies de perfiles y preocupaciones contra el abuso.
La misma regla de crawler de IA significa cosas distintas en cada entorno.
Hallazgo 6: Un índice de deuda de configuración identifica el riesgo de revisión, no el fracaso moral
Este análisis creó una puntuación simple de deuda de configuración para identificar archivos robots.txt que probablemente sean difíciles de revisar.
La puntuación pondera:
- el tamaño del archivo;
- el número de directivas
User-agent; - el número de directivas
Disallow; - el número de directivas
Allow; - el número de directivas no centrales;
- la presencia de lenguaje de política de IA;
- la mezcla de bloqueo explícito de IA con lenguaje legal o de copyright.
Esto no es una puntuación de corrección. Un archivo muy complejo puede ser totalmente intencional. Un archivo simple todavía puede estar mal. El objetivo es priorizar: si un archivo es grande, está cargado de política, es específico de ciertos bots y está lleno de excepciones, merece una revisión más rigurosa.
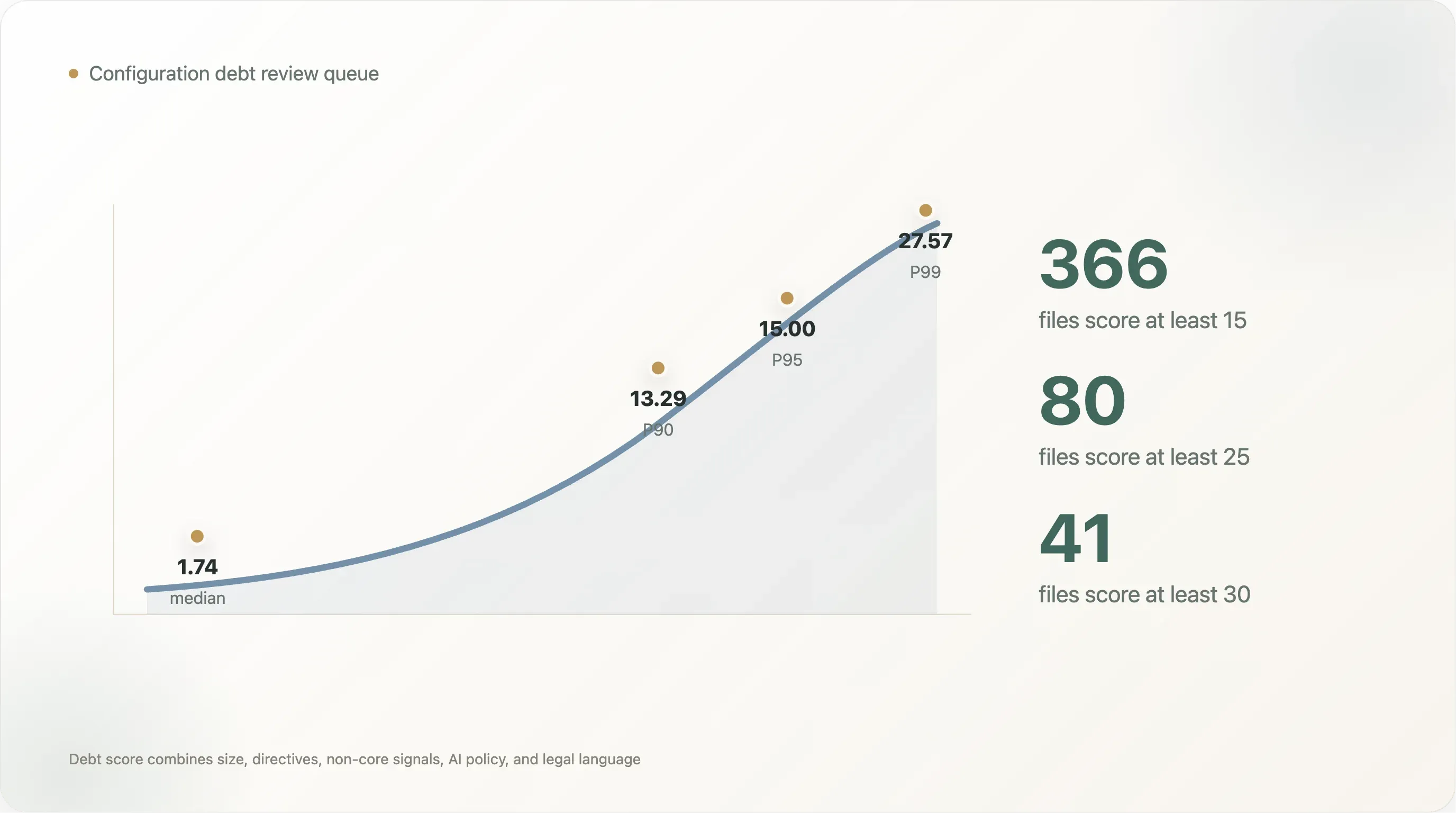
La distribución de la puntuación es pronunciada. El archivo legible mediano obtiene 1.74. El P90 es 13.29, el P95 es 15.00 y el P99 es 27.57. Solo 366 archivos alcanzan al menos 15, 80 alcanzan al menos 25 y 41 alcanzan al menos 30. Esa es la cola real de revisión: no todos los sitios necesitan un proyecto de gobernanza, pero la cola superior sí.
La vista por categoría también muestra por qué una sola etiqueta de "bloqueador de IA" es demasiado plana:
| Categoría | Puntuación mediana | Puntuación P90 |
|---|---|---|
| travel | 4.92 | 28.94 |
| search | 2.97 | 24.23 |
| social | 2.25 | 15.00 |
| news | 4.91 | 14.92 |
| finance | 1.67 | 12.61 |
| SaaS | 0.98 | 11.85 |
| ecommerce | 3.88 | 10.87 |
| government | 1.57 | 6.38 |
Travel y search tienen las puntuaciones P90 más altas porque una minoría de archivos se vuelve muy grande y muy cargada de reglas. News tiene una de las puntuaciones medianas más altas porque el lenguaje de política y el trato específico para bots son más comunes en toda la categoría. Ecommerce tiene un conteo mediano alto de Disallow, pero su puntuación de deuda P90 es menor que la de travel porque la complejidad está más concentrada en reglas de rutas que en señales mixtas de política y lenguaje legal.
Los archivos con mayor puntuación de este conjunto de datos incluyen:
| Dominio | Por qué obtiene una puntuación alta |
|---|---|
linkedin.com | Archivo muy grande, miles de reglas de rutas, muchos user agents nombrados, lenguaje explícito de política de IA |
lnkd.in | Misma superficie de política que la infraestructura de enlaces cortos de LinkedIn |
fragrantica.com | Cientos de bloques para user agents nombrados más lenguaje de política de IA |
sovcombank.ru | Cientos de bloques para user agents y lenguaje legal/de política |
academia.edu | Gran matriz de allow/disallow y política explícita de bloqueo de IA |
opentable.com | Gran conjunto de reglas de rutas, muchas directivas sitemap, superficie de política relacionada con IA |
etsy.com | Archivo grande de control de rutas para ecommerce con más de 1,600 reglas Disallow |
runescape.com | Casi 5,000 directivas Disallow bajo un solo grupo de user agent |
Estos archivos no deberían ser ridiculizados por ser complejos. La complejidad suele reflejar necesidades reales del negocio. Pero sí demuestran por qué la política de robots.txt merece la misma disciplina de ingeniería que otras configuraciones de producción:
- la propiedad debe ser explícita;
- los cambios deben revisarse;
- las secciones generadas deben etiquetarse;
- los comentarios legales deben separarse de las directivas de máquina siempre que sea posible;
- los casos de prueba deben afirmar el acceso esperado de bots críticos;
- el historial de versiones debe preservarse;
- los nombres antiguos de bots deben retirarse o documentarse;
- el entrenamiento de IA, la recuperación para IA, la indexación de búsqueda y el archivado deben tratarse como propósitos separados.
El último punto es el más importante. La gramática actual se basa primero en el user-agent: le pide al operador del sitio que nombre bots. La necesidad de la era de la IA es primero el propósito: le pide al operador del sitio que diga qué usos están permitidos.
No es lo mismo.
Ese desajuste es la razón por la que las listas de bloqueo cada vez más largas no envejecerán bien. Hoy un editor puede añadir GPTBot, ClaudeBot, CCBot, Google-Extended, Bytespider, Applebot-Extended y PerplexityBot, pero mañana puede aparecer el siguiente nombre de crawler, agente de recuperación o intermediario de dataset. Una política basada en propósito permitiría al sitio decir "sí a la indexación de búsqueda, no al entrenamiento de IA, quizá a la recuperación iniciada por el usuario" sin convertir robots.txt en una libreta de contactos de bots.
Qué significa esto para la gobernanza de IA
El debate público suele plantear robots.txt como algo significativo o bien obsoleto. Los datos sugieren una respuesta más práctica:
robots.txt es significativo, pero está sobrecargado.
Es significativo porque los sitios importantes lo usan, los crawlers pueden analizarlo y las decisiones de política son visibles para investigadores, periodistas, proveedores y tribunales. El informe original encontró que el 17.0% de los sitios principales analizables tenía reglas deliberadas y específicas para IA. Eso no es ruido simbólico.
Está sobrecargado porque el archivo ahora tiene que expresar más que el acceso de bots:
- "No entrenes con este contenido."
- "Puedes usar este contenido para indexación de búsqueda."
- "Puedes usar este contenido para recuperación en vivo."
- "No puedes crear conjuntos de datos en caché."
- "Esta reserva legal se aplica bajo la ley europea de text and data mining."
- "Este sitio gestionado por CDN envía
Content-Signal: ai-train=no." - "Este sitio quiere Googlebot, pero no YandexBot."
- "Este sitio tiene 1,000 rutas URL heredadas que no deberían rastrearse."
La gramática no fue diseñada para tantos trabajos.
Tres cambios reducirían la deuda:
-
La identidad de los crawlers necesita un registro. Los operadores de sitios no deberían tener que mantener una lista que crece sin parar de
GPTBot,ClaudeBot,anthropic-ai,CCBot,Google-Extended,Applebot-Extended,Bytespider,OAI-SearchBot,ChatGPT-Usery muchos más. Sin un registro, la política siempre irá por detrás del comportamiento de los crawlers. -
El uso de IA necesita vocabulario estructurado. Entrenamiento, recuperación, indexación, resumen, reventa de datasets, evaluación de modelos y navegación iniciada por el usuario son usos distintos. Expresarlos mediante nombres de user agent específicos de cada proveedor es frágil.
-
La política necesita auditabilidad. La web necesita una forma de distinguir las reservas de derechos escritas por humanos de los valores por defecto heredados de la CDN, las plantillas generadas por CMS, las reglas heredadas obsoletas y los bloqueos accidentales que abarcan todo. La distinción importa para la confianza y para el litigio.
Nada de esto significa reemplazar robots.txt de un día para otro. El mejor camino es por capas: mantener robots.txt como superficie de descubrimiento y compatibilidad, pero estandarizar una política legible por máquinas adyacente para usos específicos de IA.
llms.txt es un intento en esa dirección, pero su adopción en este conjunto de datos sigue siendo minúscula: solo 83 archivos legibles lo mencionan. Content-Signal es más visible porque Cloudflare puede distribuirlo a través de la infraestructura, y los 271 archivos con Content-Signal en este rastreo también coincidieron con lenguaje de política de IA. Aun así, distribución no es lo mismo que consenso. Una solución duradera probablemente necesite la maquinaria aburrida de la estandarización: campos claros, semántica clara, compromisos de los crawlers y suites de prueba públicas.
Conclusión
La pelea por los crawlers de IA ha convertido a robots.txt en un artefacto de gobernanza. Eso es útil y arriesgado a la vez.
Útil, porque el archivo es público. Los investigadores pueden auditarlo. Los editores pueden modificarlo. Los crawlers pueden respetarlo. Los tribunales pueden leerlo. Los proveedores de infraestructura pueden desplegarlo a escala.
Arriesgado, porque está cargando demasiado.
El archivo robots.txt mediano del Tranco Top 10K sigue siendo lo bastante pequeño como para entenderlo. Pero la larga cola de la web de alto tráfico está llena de archivos grandes, antiguos, en capas, específicos de proveedores y cargados jurídicamente. Cientos de sitios mantienen ahora configuraciones de robots.txt que se entienden mejor como sistemas de política de producción que como simples sugerencias para crawlers.
La lección central no es que robots.txt haya fallado. Es que la web lo amplió sin refactorizarlo.
Si la política de acceso de IA va a depender de declaraciones públicas legibles por máquinas, el siguiente paso no es otra lista de bloqueo más larga. Es una mejor infraestructura de política: permisos basados en propósito, identidad estable de los crawlers, plantillas revisables y trazabilidad de auditoría.
Hasta entonces, la capa de gobernanza de IA de la web pública seguirá descansando sobre un archivo de texto que nunca estuvo pensado para cargar tanto peso.
Notas de reproducibilidad
La carpeta de entrega incluye:
source_data/analysis.json— métricas agregadas originales.source_data/site_meta.csv— tabla analítica original por sitio.source_data/bot_status.csv— tabla original de política por dominio y bot.source_data/fetch_meta.csv— metadatos originales de extracción.source_data/sites.csv— tabla original de dominios/categorías/estado.derived_data/robots_complexity_by_site.csv— métricas de complejidad por sitio generadas para este informe.derived_data/search_bot_treatment.csv— matriz de tratamiento para crawlers de búsqueda.derived_data/category_complexity_summary.csv— resumen de complejidad por categoría.derived_data/top_config_debt_sites.csv— principales sitios según la puntuación de priorización descrita arriba.derived_data/summary_metrics.json— todas las métricas destacadas citadas en este informe.
Se agradecen correcciones de metodología, problemas del conjunto de datos y análisis de seguimiento en support@thunderbit.com. Este informe se publica de forma independiente de cualquier posición comercial que tenga Thunderbit; construimos un raspador web impulsado por IA y tenemos un interés estructural en que robots.txt siga siendo un contrato significativo y legible por máquinas en la web pública. Los datos de este informe se sostienen por sí solos. — El equipo de investigación de Thunderbit, mayo de 2026.